Le marché de change marocain. évaluation et couverture des options européennes et américaines de change et modélisation du taux de change du dirham.par Youness TOUFIK Ecole Mohammadia d'Ingénieurs - Diplome d'ingénieur en modélisation et Informatique Scientifique 2019 |

6.2.3 Méthodologie d'estimation du modèle STARTZLe modèle STARTZ défini dans les équations (6.8)-(6.12) est notre paramétrisation la plus générale du modèle du taux de change à l'intérieur d'une bande de fluctuation. Afin de réaliser les travaux empiriques de manière ordonnée, Lundbergh et Teräsvirta (2005) [22] proposent une stratégie de modélisation que l'on peut décrire comme suit :
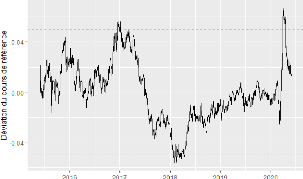
Toutes les estimations des paramètres sont obtenues à l'aide de la méthode des moindres carrées non linéaires. Nous souhaitons donc estimer le vecteur des paramètres Ð = ('P0, . . . , 'Pn, Y, 'ra, 0a, '0, . . . , 'q, 130, . . . , 13p, , 'rb, 0b) qui ajuste au mieux les données, au sens des moindres carrés. 6.2.4 Modélisation du taux de change du Dirham par le modèle STARTZDans cette section nous allons essayer de modéliser le taux de change USDMAD avec le modèle STARTZ, en suivant les étapes décrites dans la section précédente. Les données sont des observations quotidiennes du taux de change du 01 Juin 2015 au 01 Juin 2020, extraites de https://fr.investing.com/currencies/usd-mad-historical-data. Nous modélisons l'écart, en pourcentage, du taux de change par rapport au cours de référence. Nous nous sommes cantonnés au cas de l'USDMAD, puisque la même analyse pourra être faite pour le cas de l'EURMAD. L'élargissement de la bande de fluctuation pour le Dirham de #177;2,5% à #177;5%, a été mis en place depuis le 09 Mars 2020, donc nous n'auront pas suffisamment de données historique pour estimer notre modèle. Pour remédier à ce problème nous avons supposé que la bande de fluctuation de #177;5% a été mise en place depuis le 01 Juin 2015, et nous avons estimé le cour de référence comme une moyenne géométrique des taux USDMAD sur toute la période considérée. La figure 6.3 représente l'évolution de l'écart de l'USDMAD par rapport au cours de référence considéré pour la période allant du 01 Juin 2015 au 01 Juin 2020, les lignes rouges en pointillés représentent la bande de fluctuation de #177;5% autour d'une cours de référence de 9,6597.
83 FIGURE 6.3 - La déviation en pourcentage de l'USDMAD du cours de référence. Nous remarquons que le taux de change dépasse la bande pour quelques observation, mais cela ne contredit pas notre modèle, car on a prouvé que la probabilité que le taux de change dépasse la bande de fluctuation n'est pas nulle. Estimation du modèle AR(n) pour la moyenne conditionnelle La première étape de la modélisation est d'estimer un modèle AR(n) pour la moyenne conditionnelle mt, pour cela nous allons suivre la méthodologie de Box-Jenkins, c'est un outil systématique qui permet de déterminer le meilleur modèle de type ARMA décrivant le processus stochastique d'une série observée ou d'une transformation stationnaire de celle-ci, d'estimer ce modèle et de l'utiliser pour extrapoler les valeurs de la série. Les principales étapes de la méthodologie de Box-Jenkins sont:
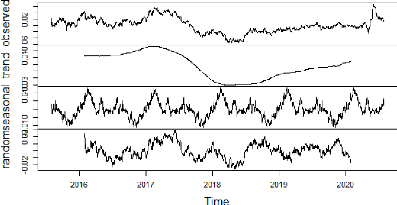
Tout d'abord, il faut tracer la série temporelle et repérer ses principales caractéristique. Pour cela nous allons décomposer la série en 3 composantes : Tendance, saisonnalité et résidu. La figures 6.4 représente les différentes composantes de notre série.
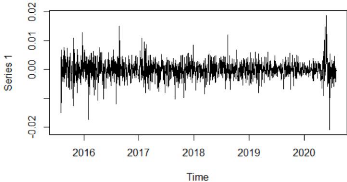
84 FIGURE 6.4 - Représentation de la de la série de l'USDMAD et de ses composantes. 85 Avant de travailler avec la série, il faut d'abord vérifier si elle est stationnaire ou pas, pour cela nous allons vérifier la stationnarité de la série à l'aide du test de Dickey-Fuller (1979) augmenté (ADF). Les hypothèses du test sont: -- H0 : La série n'est pas stationnaire. -- H1 : La série est stationnaire. TABLE 6.1 - Test de Dickey-Fuller Augmenté (ADF) sur la série yt. Série Dickey-Fuller Test Lag Order p-value 5% Conclusion yt -2,4992 10 0,367 Non Stationnaire Nous remarquons que la p - value> 0,05 donc l'hypothèse H0 est retenue au seuil 5% pour la série temporelle yt. D'après la méthodologie de Box-Jenkins, il faut stationnariser la série avant de l'utiliser pour estimer le modèle AR(n). La méthode utilisée pour stationnariser une série temporelle est la différenciation. Différencier une série temporelle signifie soustraire chaque point de données de la série de son successeur. Pour la plupart des modèles de séries chronologiques, une ou deux différences sont nécessaires pour en faire une série stationnaire. Notre nouvelle série temporelle, y0t, différenciée une seule fois, représentée dans la figure 6.5, s'écrit: y0 t = yt - yt-1
FIGURE 6.5 - Représentation de la de la série y0t. Nous allons vérifier de nouveau la stationnarité avec le test de Dickey-Fuller Augmenté (ADF). TABLE 6.2 - Test de Dickey-Fuller Augmenté (ADF) sur la série y0t. Série Dickey-Fuller Test Lag Order p-value 5% Conclusion y0t -10,876 10 0,01 Stationnaire 86 Nous remarquons que la p - value < 0,05 donc l'hypothèse H0 est rejetée au seuil 5% pour la série temporelle y0t. Dans cette étape, ont doit déterminer l'ordre n du processus AR(n), pour cela nous allons utiliser les critères Akaike information criterion (AIC) et Bayesian Information Criterion (BIC). Nous allons estimer différents modèles : AR(1), AR(2), AR(3), AR(4) et AR(5), puis nous allons choisir le modèle de plus adéquat suivant ces deux critères. Les résultats sont présentés dans la tableau 6.3 ci-dessous. TABLE 6.3 - Comparaisons des modèles AR(n), n = 1, . . . , 5, par les critères AIC et BIC.
Le modèle choisi est celui qui aura les plus faible valeurs d'AIC et BIC. Ces critères reposent sur un compromis entre la qualité de l'ajustement et la complexité du modèle, en pénalisant les modèles ayant un grand nombre de paramètres. Pour le critère AIC la pénalité dépend seulement du nombre des paramètres, par contre pour le critère BIC la pénalité dépend à la fois de la taille de l'échantillon et du nombre de paramètres. Donc d'après le tableau 6.3 le modèle choisi est AR(1). Avant de valider notre modèle il faut le diagnostiquer, pour cela il faut analyser les résidus du modèle, ces résidus doivent vérifier les trois hypothèses suivantes: -- Normalité. -- Absence d'auto-corrélation. -- Homoscédasticité. La normalité peut être soit testée graphiquement, en représentant l'histogramme des résidus ou par le graphe quantile-quantile (qq-plot), soit testée statistiquement avec le test de Shapiro-Wilk, les hypothèses du test sont: -- H0 : Les résidus sont normalement distribués. -- H1 : Les résidus ne sont pas normalement distribués. TABLE 6.4 - Test de Shapiro-Wilk pour les résidus du modèle AR(1). Modèle Shapiro-Wilk Test p-value 5% Conclusion AR(1) 0,96285 < 2,2 x 10-16 Non-normalité Nous remarquons que la p - value < 0,05 donc l'hypothèse H0 est rejetée au seuil 5% pour le modèle AR(1). Cela ne posera pas de problème, car nous essayons seulement de trouver les valeur initiales pour notre modèle final STARTZ. L'auto-corrélation des résidus peut être vérifiée avec le test de Ljung-Box (1978) ou celui de Box-Pierce (1970). Les hypothèses du test sont: 87 -- H0 : Absence d'auto-corrélation des résidus. -- H1 : Présence d'auto-corrélation des résidus. TABLE 6.5 - Test de Ljung-Box pour les résidus du modèle AR(1). Modèle ÷2 Lag Order p-value 5% Conclusion AR(1) 7,7444 x 10_5 1 0,993 Pas d'auto-corrélation Nous remarquons que la p _ value > 0.05 donc l'hypothèse H0 est retenue au seuil 5% pour le modèle AR(1). L'homoscédasticité des résidus peut être vérifiée avec le test de White (1980). Les hypothèses du test sont: -- H0 : Homoscédasticité des résidus. -- H1 : Hétéroscédasticité des résidus. TABLE 6.6 - Test de White pour les résidus du modèle AR(1). Modèle ÷2 Lag Order p-value 5% Conclusion AR(1) 5,1267 2 0,07705 Homoscédasticité Nous remarquons que la p _ value > 0.05 donc l'hypothèse H0 est retenue au seuil 5% pour le modèle AR(1). Estimation du modèle GARCH(p,q) pour la variance conditionnelle La deuxième étape de la modélisation est d'estimer un modèle GARCH(p,q) pour la variance conditionnelle ht. Dans la première étape, nous avons vu que le modèle AR(1) était suffisant pour estimer la moyenne conditionnelle mt, nous allons donc utiliser cette conclusion et suivre les mêmes étapes afin de choisir le modèle GARCH(p,q) le plus adéquat. De manière générale, on peut dire que la série yt suit le processus AR(1)-GARCH(p,q) suivant: yt = ö0 + ö1yt_1 + et (6.13) avec \/ et = zt ht (6.14) où zt iid(0, 1) et ht la variance conditionnelle de et qui suit le processus GARCH(p,q) suivant: ht = á0 + á1e2 t_1 + ... + ápe2 t_p + â1ht_1 + ... + âqht_q (6.15) De la même manière que l'étape précédente, ont doit décider les ordres p et q du modèle GARCH. pour cela nous allons estimer différents modèles : GARCH(1,1), GARCH(2,1), GARCH(1,2) et GARCH(2,2), puis nous allons choisir le modèle de plus adéquat suivant les critères AIC et BIC. Les résultats sont présentés dans la tableau 6.7 ci-dessous. 88 TABLE 6.7 - Comparaisons des modèles GARCH(p,q), p = 1,2, q = 1,2, par les critères AIC et BIC. Modèle Critère AIC Critère BIC GARCH(1,1) -8,7061 -8,6863 GARCH(2,1) -8,7029 -8,6792 GARCH(1,2) -8,7019 -8,6781 GARCH(2,2) -8,7026 -8,6749 Le modèle choisi est celui qui aura les plus faible valeurs d'AIC et BIC. Donc d'après le tableau 6.7 le modèle que nous allons choisir est GARCH(1,1). Donc finalement nous avons un modèle AR(1)-GARCH(1,1) dont les paramètres sont représentés dans le tableau ci-dessous. Ces paramètres vont nous servir pour initialiser l'algo-rithme qui nous permettra d'estimer les paramètre de notre modèle STARTZ. TABLE 6.8 - Paramètres du modèle AR(1)-GARCH(1,1).
Avant de valider notre modèle, on doit le diagnostiquer. Nous allons d'abord tester l'auto-corrélation des résidus avec le test de ARCH LM. Comme le test Ljung-Box, le test ARCH LM permet de tester la dépendance en série (auto-corrélation) due à un processus de variance conditionnelle en testant l'auto-corrélation dans le carré des résidus. Les hypothèses du test sont: -- H0 : Absence d'auto-corrélation des résidus pour un ensemble de retards k. -- H1 : Présence d'auto-corrélation des résidus pour un ensemble de retards k. TABLE 6.9 - Test de ARCH LM pour les résidus carrés du modèle AR(1)-GARCH(1,1). Modèle Lag Order Statistic p-value 5% Conclusion 3 0,4118 0,5210 Pas d'auto-corrélation AR(1)-GARCH(1,1) 5 1,2392 0,6635 Pas d'auto-corrélation 7 2,4429 0,6242 Pas d'auto-corrélation Nous remarquons que pour tout les ordres de retard, la p - value > 0.05 donc l'hypothèse H0 est retenue au seuil 5% pour le modèle GARCH(1,1). Nous allons maintenant tester si le modèle AR(1)-GARCH(1,1) ajuste bien les données en utilisant le test Pearson Goodness-of-Fit, ce test compare la distribution empirique des résidus standardisés avec la distribution théorique choisie. Les hypothèses du test sont: -- H0 : Le modèle ajuste bien les données -- H1 : Le modèle n'ajuste pas les données. TABLE 6.10 - Test de Pearson Goodness-of-Fit du modèle AR(1)-GARCH(1,1). Modèle Échantillon Statistic p-value 5% Conclusion
Nous remarquons que pour un échantillon de 20, la p - value < 0.05 donc le modèle n'ajuste pas bien les données. Par contre pour un échantillon = 30, la p - value> 0.05 donc l'hypo-thèse H0 est retenue au seuil 5%, c'est-à-dire que le modèle AR(1)-GARCH(1,1) ajuste bien les données de la série. Estimation du modèle STARTZ pour le taux de change Dans les deux parties précédentes, nous avons estimé un modèle AR(1) pour la moyenne conditionnelle et un modèle GARCH(1,1) pour la variance conditionnelle. Donc nous avons un modèle AR(1)-GARCH(1,1) pour le taux de change, l'équation de ce modèle s'écrit: yt = ö0 + ö1yt-1 + et (6.16) avec \/ et = zt ht (6.17) où zt ~ iid(0, 1) et ht la variance conditionnelle de et qui suit le processus GARCH(1,1) suivant: ht = á0 + á1e2 t-1 + â1ht-1 (6.18) avec les paramètres initiaux (ö0, ö1, á0, á1, â1) sont définis dans la tableau 6.8. Nous rappelons que le but de l'estimation d'un modèle AR(1)-GARCH(1,1) pour le taux change, est de trouver les paramètres initiaux qui nous permettrons d'initialiser notre algorithme pour estimer les paramètre finaux du modèle STARTZ. L'estimation des paramètres du modèle STARTZ est faite avec la méthode des moindres carrés non linéaires. Les résultats de l'estimation sont présentés dans le tableur ci-dessous. TABLE 6.11 - Résultats d'estimation des paramètres du modèle STARTZ. Modèle Paramètres cP0 cP1
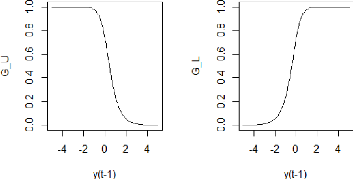
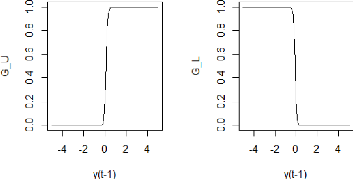
y Ya Va STARTZ á0 7, 15 × 10-8 -1, 19 × 10-3 á1 4,62 × 10-2 3,03 × 10-5 131 9,48 × 10-1 1,70 8 0,1 1,50 × 10-3 Yb 10 11,93 Vb 0,5 1,45 89 Les figures 6.6 et 6.7 ci-dessous représentent les fonctions de transition G'- et G1-' du modèle STARTZ, pour la moyenne et la variance conditionnelles.
FIGURE 6.6 - Les fonctions de transition G'- et G1-' pour la moyenne conditionnelle.
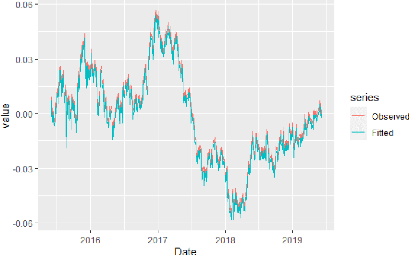
90 FIGURE 6.7 - Les fonctions de transition G'- et G1-' pour la variance conditionnelle. Afin de tester l'adéquation de notre modèle STARTZ, les données historiques du cours de l'USDMAD ont été divisés en deux ensembles: -- Ensemble d'apprentissage : Constitue 80% des données initialement choisies, cet ensemble représente l'écart yt du taux de change USDMAD par rapport au taux de référence pour la période allant du 01 Juin 2015 au 03 Juin 2019. Ce sont les données qui ont été utilisés pour estimer les paramètres du modèle STARTZ représentés dans le tableau 6.11. -- Ensemble de validation : Constitue les 20% restantes des données, cet ensemble représente l'écart yt du taux de change USDMAD par rapport au taux de référence pour la période allant du 04 Juin 2019 au 01 Juin 2020. Il sera utilisé pour évaluer la performance du modèle STARTZ. Afin de voir si le modèle ajuste bien l'ensemble des donnée d'apprentissage, nous avons représenté dans la figure 6.8 ci-dessous, la série yt des donnée réellement observés contre les résultats de l'ajustement du modèle.
91 FIGURE 6.8 - Représentation des données observés et ajustés par le modèle pour la série yt. Afin d'évaluer l'ajustement du modèle, nous allons calculer quelque indicateurs d'écart entre le valeur observés et les valeur données par le modèle. Ces indicateurs sont: -- La somme des carrés des résidus (SSE) :
-- L'erreur quadratique moyenne (RMSE) : \/ n 1 RMSE = (yi - àyi)2 n ? i=1
-- L'erreur absolue moyenne en pourcentage (MAPE) :
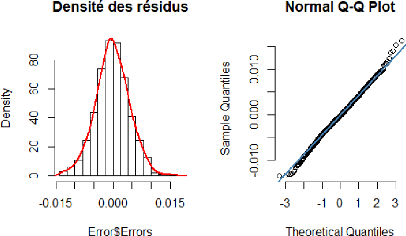
Les résultats sont présentés dans le tableau ci-dessous: TABLE 6.12 - Indicateurs d'écart du modèle STARTZ. SSE MSE RMSE MAE MAPE 2,094 x 10-2 2,003 x 10-5 4,475 x 10-3 3,501 x 10-3 4,59% D'après la figure 6.8 et le tableau 6.12, on peut remarque que l'écart entre le données observés et les données ajustés est très minime. Nous pouvons donc dire que le modèle ajuste bien les données. Pour valider notre modèle STARTZ, et de la même façon que les deux premières étapes, il faut tester la normalité, l'auto-corrélation et l'homoscédasticité des résidus. La normalité peut être testée graphiquement ou à l'aide du test de Shapiro-Wilk présenté plus haut, les résultats sont présentés dans la figure 6.9 et le tableau 6.13.
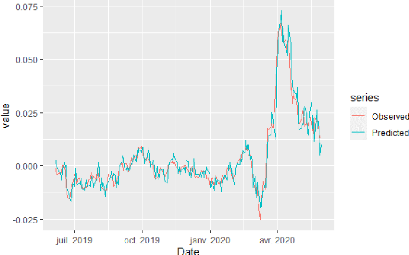
92 FIGURE 6.9 - L'histogramme et le graphe quantile-quantile des résidus du modèle STARTZ. 93 TABLE 6.13 - Test de Shapiro-Wilk pour les résidus du modèle STARTZ. Modèle Shapiro-Wilk Test p-value 5% Conclusion STARTZ 0,99774 0,1644 Normalité des résidus Nous remarquons que la p - value> 0,05 donc l'hypothèse H0 est retenue au seuil 5% pour le modèle STARTZ, ce qui signifie que les résidus sont normalement distribués. Nous allons maintenant vérifier l'auto-corrélation des résidus avec le test de Ljung-Box, présenté plus haut. Les résultats sont représentés dans le tableau 6.14 ci-dessous. TABLE 6.14 - Test de Ljung-Box pour les résidus du modèle STARTZ. Modèle ÷2 Lag Order p-value 5% Conclusion STARTZ 0,3607 1 0,5481 Pas d'auto-corrélation Nous remarquons que la p - value > 0.05 donc l'hypothèse H0 est retenue au seuil 5% pour le modèle STARTZ, , ce qui signifie l'absence d'auto-corrélation des résidus. L'homoscédasticité des résidus peut être vérifiée avec le test de White, présenté plus haut. Les résultats sont représentés dans le tableau 6.15 ci-dessous. TABLE 6.15 - Test de White pour les résidus du modèle STARTZ. Modèle ÷2 Lag Order p-value 5% Conclusion STARTZ 1,1744 2 0,5559 Homoscédasticité Nous remarquons que la p - value > 0.05 donc l'hypothèse H0 est retenue au seuil 5% pour le modèle STARTZ, ce qui signifie l'homoscédasticité des résidus. On peut conclure que les résidus vérifient les trois hypothèses : Normalité, absence d'auto-corrélation et homoscédasticité, ce qui valide le modèle STARTZ. Afin de s'assurer de la performance du modèle, nous allons l'appliquer sur l'ensemble de validation qui représente la période allant du 04 Juin 2019 au 01 Juin 2020. Nous avons représenté dans la figure 6.10 ci-dessous, la série yt des donnée réellement observés contre les résultats du modèle. Cette représentation nous permet de visualiser la qualité de l'estimation des paramètre, car l'ensemble de validation n'a pas été utilisé pour ajuster le modèle, et malgré cela on peut remarquer que le modèle donne une très bonne approximation de yt en fonction de (yt-1, ht-1, Ct-1).
94 FIGURE 6.10 - Représentation des données observés et prévues par le modèle pour yt. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||