3.4.2.2 Désambiguïsation par les règles
de préférences
Le choix d'un référent parmi les candidats dans
cette classe d'heuristiques dépend principalement des
préférences et des intuitions de l'Homme et il est
complètement indépendant du contexte (le contraire des
heuristiques de la première classe (Section 3.4.2.1)).
Chaque règle de préférence permet
directement de choisir un référent parmi les candidats, ou
d'affecter un poids à chacun d'eux, et celui qui a le plus grand score
(la somme des poids attribués par plusieurs heuristiques) sera ensuite
choisi comme le référent correct. Par exemple, les auteurs de
(Li, et al. 2006), ont utilisé une approche qui attribue des scores de
probabilité aux candidats en se basant sur plusieurs heuristiques comme
H10 et H13.
Une règle de préférence peut être
basée sur l'intuition humaine (H10, ..., H14, H16) ou sur des
statistiques effectué sur des corpus de référence (H15),
ou sur des exigences de l'application (H17).
Certaines heuristiques de cette classe ne sont qu'une
simplification du problème, c.-à-d. elles ne conduisent pas
directement au référent voulu mais plutôt elles
réduisent le nombre de référents candidats, c'est le cas
de H16 et H17.
Nous expliquons dans ce qui suit les heuristiques de la
catégorie règles de préférences.

H10 La plus grande population
Cette heuristique consiste à attribuer au toponyme ambigu
le référent avec la plus grande population, en s'appuyant sur une
source d'informations fiables.
Cette heuristique est utilisée dans (Rauch, Bukatin and
Baker 2003), (Amitay, et al. 2004) et (Pouliquen, et al. 2004), (Li, et al.
2006).
H11 Le référent de niveau
supérieur
Soit une taxonomie de toponymes dont la racine est le monde et
les feuilles sont les villes12.
Si un toponyme peut se référer à deux
référents candidats, dont l'un est un pays, et l'autre est une
ville, H11 choisit celui qui appartient à la classe la plus
supérieure, dans ce cas c'est le pays qui sera choisi.
Cette heuristique est utilisée dans (Smith and Crane
2001), (Li, Srihari, et al. 2003), (Clough 2005) et (Stokes, et al. 2008).
H12 Le référent le plus connu
Le choix du référent correct est basé sur
l'intuition humaine loin de toute connaissance fournie par les gazetteers ou
d'autres ressources. Li, Srihari, et al. (2002, 2003) ont
développé une procédure qui récupère le lieu
le plus connu pour un toponyme ambigu en se basant sur les mécanismes de
« ranking » des moteurs de recherche. Leur heuristique utilise le
moteur de recherche Yahoo!13.
Exemple
Si le toponyme « Cairo » est mentionné dans
un texte, cette heuristique lui attribue le référèrent
« Cairo>Egypte » au lieu de « Cairo>Alabama>USA »
par exemple. Car les premiers résultats retournés par la
requête « cairo » au moteur de recherche Yahoo!
représentent le référent « Cairo>Egypte »,
comme c'est illustré dans la Figure 3-5.
12 C'est ce que nous avons appelé l'arbre
hiérarchique des lieux du monde.
13
http://www.yahoo.com
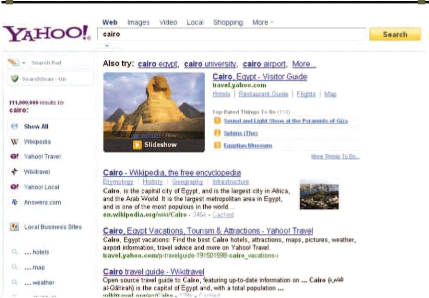
Figure 3-5. Les résultats de la requête
"cairo" dans le moteur de recherche Yahoo!
H13 Préférer un type
Par exemple préférer les référents
qui représentent des capitales, ou préférer les lieux
habités que les divisions administratives...etc.
Exemple
Constantine peut indiquer la wilaya de Constantine ou la ville
de Constantine, si le type préféré est « ville »
alors c'est la ville de Constantine qui est choisie comme
référent.
Cette heuristique est utilisée dans : (Li, Srihari, et al.
2003), (Li, et al. 2006).
H14 Ordre de préférence des
ressources
Lors de l'utilisation parallèle de plusieurs
gazetteers, il peut être utile de définir un ordre de
priorité statique entre eux. Clough (2005) a prouvé
l'efficacité de cette méthode en établissant un ordre de
préférence entre 3 ressources géographiques selon leurs
qualités.

H15 Le sens le plus fréquent dans un
corpus
Il s'agit de choisir le référent qui est
situé dans l'état ou le pays le plus fréquent. Ces
fréquences d'occurrence sont calculées sur un corpus
d'apprentissage.
Smith et Mann (2003) ont utilisé les résultats de
cette heuristique comme référence pour mesurer les performances
de leur méthode principale.
Stokes et al. (2008) ont supposé que l'emplacement le
plus fréquent pour un toponyme est celui représenté par la
page de Wikipedia14 qui contient le plus grand nombre d'occurrences
de ce toponyme. Le classement des pages de Wikipedia selon le nombre
d'occurrence d'un toponyme est obtenu par le service web GeoNames15.
L'intuition derrière cette heuristique16 est que les
contributeurs de Wikipédia ont tendance à écrire un
article plus long (conséquemment avec plus de mentions du toponyme) pour
l'emplacement le plus souvent associé à un toponyme ambigu.
Exemple
On ne s'attend pas d'avoir un long article sur Gaza
située aux États-Unis que celui sur Gaza de Palestine, donc
l'article de Gaza>États-Unis ne contient pas autant d'occurrence du
terme Gaza, par conséquence il ne sera pas classé le premier dans
les résultats de recherche fournies par GeoNames. Et donc c'est
Gaza>Palestine qui sera attribué au toponyme Gaza.
H16 Supprimer les petites places
Il s'agit de réduire la taille de la ressource des
lieux géographiques en fonction de la taille de la population. Cela
diminue l'ambiguïté, mais bien évidemment c'est une
simplification du problème plutôt que une véritable
solution. Toutefois, Pouliquen et al. (2004) ont démontré que
cette technique peut être utile dans certaines applications.
14
http://www.wikipedia.org
15
http://www.geonames.org
16 Cette clarification avec l'exemple utilisé
est obtenue par une communication personnelle avec Nicola Stokes (le premier
auteur de l'article).

H17 Concentration sur une zone
géographique
Cette heuristique consiste à ignorer les
référents qui se trouvent en dehors d'un polygone ou d'une zone
géographique (pays, région, continent...).
La zone géographique concernée est
sélectionnée d'une manière statique, c. à. d. elle
ne dépend pas formellement du texte mais plutôt, c'est une
décision faite par l'utilisateur ou le concepteur du système de
désambiguïsation. Cette heuristique peut être
considérée comme la version statique de H6, et elle est
utilisée dans (Pouliquen, et al. 2004).
| 

