La désambiguà¯sation des toponymes( Télécharger le fichier original )par Imene BENSALEM Université Mentouri de Constantine, Algérie - magistère en informatique 2009 |

3.4 Les Heuristiques3.4.1 Qu'est ce qu'une heuristiques de désambiguïsation de toponymesNous définissons les heuristiques de désambiguïsation des toponymes comme les algorithmes qui manipulent les connaissances disponibles dans le contexte du toponyme ambigu ou extraites des différentes ressources en vue d'émerger parmi un ensemble de candidats, le référent le plus susceptible d'être le sens voulu par le toponyme ambigu. 3.4.2 Classification des heuristiques de désambiguïsation de toponymesDans les sections suivantes nous présentons une classification des heuristiques de résolution de toponymes (Bensalem et Kholladi 2009a). Nous distinguons trois classes globales : heuristique basées sur le contexte, heuristiques basées les règles de préférence, et heuristiques complémentaires. Généralement, une méthode de désambiguïsation combine plusieurs heuristiques dans un ordre particulier, ou dans une procédure ou formule de calcule de poids, dans le but d'augmenter le nombre de toponymes résolus. 3.4.2.1 Désambiguïsation par le contexteLes heuristiques que nous classifions sous cette catégorie cherchent des indices de désambiguïsation dans l'environnement textuel où le toponyme ambigu apparait. Il existe deux approches générales de la
désambiguïsation par le contexte, la
s'agit d'extraire des mots (toponymes ou/et termes) particuliers du document qui contient le toponyme à résoudre, puis, choisir parmi les référents candidats le référent le plus relié à ces mots. Cette relation peut être spatiale (H1), linguistique (H2, H3) ou statistique (H4). La deuxième approche consiste à résoudre plusieurs toponymes ambigus à la fois en effectuant des calculs géométriques sur les coordonnées spatiales des référents candidats des toponymes (H5, H6), ou en appliquant d'autres algorithmes comme le cas de des heuristiques H7 et H8. Les heuristiques de cette classe utilisent des techniques issues des domaines suivants: le Traitement Automatique des Langues Naturelles (TALN) y compris la DSM (H1, H2, H3, H4, H7, H9), les Systèmes d'Informations Géographiques (SIG)(H1, H5, H6), et la théorie des graphes (H7H8). H1 Distance aux voisins textuels non ambigus La résolution d'un toponyme t1 se fait par les étapes suivantes (Leidner 2007) :
Il convient de noter que cette heuristique n'est plus applicable dans le cas de l'absence des toponymes non ambigus dans le texte concerné. Cette heuristique est basée sur les calculs géométriques dans la 2ème étape donc elle nécessite l'utilisation des coordonnées géographiques de référents de chaque toponymes. Et elle est utilisée par Smith & Crane (2001). H2 Chevauchement entre les chemins hiérarchiques des référents et le texte Il s'agit de calculer le chevauchement (les mots identiques) entre les noms des lieux qui composent le chemin hiérarchique de chaque référent du toponyme
ambigu et ceux qui se trouvent dans le contexte. À partir d'une étude empirique, Clough (2005) a choisi un contexte de chevauchement de 2 mots à gauche et 8 mots à droite du toponyme ambigu. Une partie de notre heuristique de désambiguïsation est aussi basée sur l'intersection du chemin hiérarchique avec le contexte (Bensalem et Kholladi 2009a). Voir le chapitre suivant pour plus de détails. Une idée similaire est de chercher la mention du toponyme supérieure. Si t1 est un toponyme à résoudre, et un deuxième toponyme t2 apparaît d'ailleurs dans le même document, tel que, l'un des référents de t1 est situé dans l'un des référents de t2. Alors attribuer à t1 ce référent situé à t2. Cette heuristique est utilisée par (Hauptmann and Olligschlaeger 1999) et (Pouliquen, et al. 2004), et (Li, et al. 2006). Exemple Dans l'exemple6 donné dans le Tableau 3-2, le référent choisi pour résoudre le toponyme « Constantine » est « Africa>Algeria» car « Algeria » (le toponyme supérieur de Constantine7) existe dans le contexte ce qui a permis de lui attribuer le plus grand score de chevauchement. Tableau 3-2. Exemple sur l'application de l'heuristique H2 Les toponymes du contexte Skikda, Algeria, Constantine Le toponyme à désambiguïser Constantine
6 Les référents de l'exemple sont extraites du Gazetteer Getty. 7 On dit aussi que Algeria est holonyme de Constantine.
H3 L'appariement des patterns C'est une technique appliqué dans le TALN, elle est connue habituellement sous le nom anglais « patterns matching ». Dans le domaine de désambiguïsation des toponymes il s'agit de chercher dans le texte, des modèles prédéfinis - syntaxiques et/ou lexicales - sur les expressions qui contiennent le toponyme ambigu. Une fois le pattern est détecté dans le texte, les informations qu'il contient sont comparées aux référents candidats pour choisir le plus approprié parmi eux. Nous distinguons deux types d'heuristiques de résolution de toponymes qui utilisent les techniques d'appariement de patterns : des heuristiques qui servent à extraire des relations hiérarchiques (H3.1), et des heuristiques qui servent à extraire le type de toponyme (H3.2). Chacune de ces heuristiques est expliquées cidessous. Il y a des patterns qui détectent à la fois les relations hiérarchiques et le type de toponyme, comme ceux utilisés dans (Li, Srihari, et al. 2003). H3.1 Les patterns de relation hiérarchique Ils capturent les toponymes contigus dans le texte. Ce type de patterns peut prendre l'un des formats suivants (Leidner 2007) : t1, t2 t1/t2 t1 (t2) Si exactement le cas où l'un des référents candidats r1 du toponyme t1 est situé dans r2, tel que r2 est l'un des référents du toponyme t2. Alors attribuer r1 à t1. Ce format est beaucoup utilisé dans les adresses, et il peut contenir deux toponymes ou plus. Exemples En détectant le pattern t1(t2) dans la phrase ci-dessous, le toponyme ambigu Tripoli sera résolu à Tripoli>Liban au lieu de Tripoli>Libye. À l'époque des Omeyyades, Tripoli (Libon) devint une importante base navale.
Cette heuristique est utilisée dans : (Hauptmann and Olligschlaeger 1999), (Smith and Crane 2001), (Li, Srihari, et al. 2003), (Rauch, Bukatin and Baker 2003), (Amitay, et al. 2004). H3.2 Les patterns de type Si un toponyme apparaît dans le texte à coté d'un nom qui indique son type (ex. ville, capital, pays, commune...) alors éliminer les référents candidats qui ne sont pas de ce type. Exemple Soit la phrase suivante qui contient le toponyme ambigu Washington : L'état de Washington est situé dans le nord-ouest des États-Unis. Le pattern « état de toponyme » permet de résoudre le toponyme Washington à Washington l'état au lieu de Washington la capitale. Cette heuristique est utilisée dans : (Li, Srihari, et al. 2003), (Rauch, Bukatin and Baker 2003) et (Schilder, Versley et Habel 2004), (Li, et al. 2006), (Stokes, et al. 2008). H4 Modèle de cooccurrence Une cooccurrence (aussi appelée collocation) fait référence à des mots souvent utilisés ensemble (Zheng, et al. 2007). L'idée de base derrière cette méthode est que la distribution d'un mot dans un contexte lexical (les mots et les expressions qu'il apparaît avec) est fortement révélatrice de sa signification (Pekar, Krkoska et Staab 2004). Le modèle de cooccurrence renferme pour chaque sens d'un toponyme (c.-à-d. référent) les toponymes (ou les mots) fréquemment apparus avec lui. Un modèle de cooccurrence est construit à partir d'un corpus (Voir 3.6.2) puis appliqué sur le texte à main pour capturer les mots du contexte et ensuite, inférer à partir de ces mots le sens le plus approprié au toponyme ambigu.
Par exemple, on peut inférer à partir d'un corpus que le terme « palais d'Alhambra » est positivement corrélé avec le toponyme « Grenade » tel que le référent de ce dernier dans ce cas est Grenade>Espagne. Alors, en appliquant ce modèle de cooccurrence sur un nouveau texte, si « Alhambra » est mentionné à proximité du toponyme « Grenade », ce dernier sera attribué à la ville de Grenade dans l'Espagne au lieu de l'état de Grenade dans l'océan atlantique. La désambiguïsation en utilisant les modèles de cooccurrences est inspirée des méthodes de désambiguïsation des sens des mots. Cette heuristique est implémentée en utilisant un éventail de technique à savoir, l'apprentissage automatique. Cette heuristique a été utilisée par Overell et al. (2006a, 2006b, 2007) qui ont généré un modèle de cooccurrence à partir de l'encyclopédie libre Wikipedia. Elle a été utilisée aussi par (Smith et Mann 2003) qu'ils ont utilisé une méthode d'apprentissage supervisé pour construire un modèle de cooccurrence sous forme de classificateur. H5 Espace géométrique (polygone / distance) minimaliste Il s'agit d'attribuer à tous les toponymes qui émergent dans le même texte les référents qui diminuent le plus les distances spatiales bilatérales, et par conséquent, ils occupent ensemble espace géométrique le plus réduit. Cette heuristique prend en compte toutes les interprétations possibles pour chaque toponyme et fait des traitements d'optimisation à l'aide de la proximité géographique comme critère. Cette heuristique est utilisée dans (Leidner, Sinclair et Webber 2003), (Rauch, Bukatin and Baker 2003), et (Amitay, et al. 2004). H6 Contexte géographique unifié Consiste à la sélection dynamique d'une zone
géographique selon les toponymes
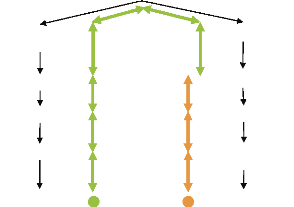
zone. Le contexte géographique est élaboré en calculant le centroïde (barycentre) géographique des référents des toponymes mentionnés dans le document, puis éliminer tous les référents candidats qui sont situés à plus d'une certaine distance loin du centre. Dans (Smith and Crane 2001) cette distance était définie 2 écartstypes. Cela peut être considéré comme une version dynamique de H16. H7 Le chemin le plus court entre les référents Une heuristique utilisée dans (Stokes, et al. 2008) consiste à désambiguïser les toponymes en cherchant le chemin le plus cours entre les référents candidats dans l'arbre hiérarchique de Getty : le Thésaurus des Noms Géographique8. Cette idée est déjà appliquée dans les méthodes de désambiguïsation des sens de mots mais en employant WordNet. World
North and Central Riverside county United States California Mecca 2 1 Saudi Arabia Makkah administrative Mecca Asia Figure 3-3. Chemins entre le toponyme ambigu Mecca et
Saudi Arabia dans l'arbre hiérarchique du monde Exemple Soit « Mecca » le toponyme à résoudre
sachant que le toponyme « Saudi Arabia» 8 Getty Thesaurus of Geographic Names: http://www.getty.edu/research/conductingresearch/vocabularies/tgn (dernière visite le 07/04/2009)
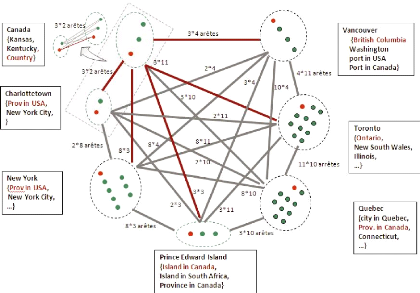
« Mecca>Saudi Arabia » comme c'est expliqué dans la Figure 3-3. H8 Les noeuds de l'arbre couvrant maximum Il s'agit de construire un graphe pondéré, où chaque noeud représente un sens d'un toponyme (un référent), et chaque arête représente une relation entre deux sens (voir Figure 3-4). Le poids représente la similarité entre chaque couple de référents. Le graphe est partiellement complet car il n'y a pas de liens entre les différents sens d'un toponyme. Les noeuds de l'arbre couvrant9 de poids maximal (maximum weight spanning tree (MST))10 sont les sens considérés les plus prometteurs pour les toponymes.
Figure 3-4. Le graphe des lieux et l'arbre couvrant maximum d'après (Li, Srihari, et al. 2003) 9 Un arbre couvrant d'un graphe est un sous-graphe sans cycle qui connecte tous les sommets ensemble. Un graphe peut comporter plusieurs arbres couvrants différents. 10 Un arbre couvrant de poids maximal est un arbre couvrant dont le poids est plus grand ou égal à celui de tous les autres arbres couvrants du graphe.
Cette heuristique est utilisée dans (Li, Srihari, et al. 2002) en appliquant l'algorithme Kruskal pour calculer l'arbre couvant maximum, puis optimisée par le même groupe d'auteur dans (Li, Srihari, et al. 2003) au moyen de l'algorithme Prim qui utilise un espace de recherche plus petit par rapport à Kruskal. H9 La densité conceptuelle La Densité Conceptuelle (DC) est une mesure de corrélation entre le sens d'un mot et son contexte. Elle a été présentée dans le domaine de DSM par Agirre et Rigau (1996) puis reformulée par Rosso et al. (2003). Cette dernière est ensuite adaptée à la désambiguïsation des toponymes par Buscaldi et Rosso (2008a). La formule de calcul de DC est :
Tel que m est le nombre de noeuds (synsets)11 pertinentes dans la sous-hiérarchie composée des lieux du contexte, n est le nombre total de synsets dans la soushiérarchie, et f est le poids de la fréquence du sens (par exemple 1 pour le sens le plus fréquent, 2 pour le second, etc.). Dans la méthode de Buscaldi et Rosso (2008a), la densité conceptuelle est calculée pour chaque référent candidat du toponyme ambigu. En suite, le référent qui maximise cette valeur ( c.-à-d. la densité conceptuelle) est celui qui sera attribué au toponyme ambigu. L'explication détaillée de cette heuristique est hors l'objet du présent chapitre, mais il est suffisant de dire que la densité conceptuelle est une quantification d'une certaine proximité entre les toponymes du contexte. C'est-à-dire que cette heuristique résout les toponymes ambigus par les référents les plus proches les uns aux autres. Cependant, la proximité quantifiée n'est pas spatiale comme le cas 11 Les mots synonymes dans WordNet sont regroupés dans des noeuds appelée synset.
des heuristiques H1, H5, H6 mais elle est plutôt une proximité dans l'arbre hiérarchique des lieux du monde comme le cas de H2, H3.1., H7. L'heuristique que nous proposons (Bensalem et Kholladi 2009a) se situe dans la même classe des heuristiques expliquée ci-dessus, c.-à-d. elle est basée sur le contexte, mais nous laissons son explication pour le chapitre suivant. |
|