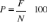Problematique sur la politique de rémuneration dans une entreprise industriel cas de Kamoto Copper Company( Télécharger le fichier original )par Laureine Nkankana Mbuyi Université de Kolwezi - Licence 2015 |

CHAPITRE III L'EVOLUTION DE REMUMERATION A KAMOTO COPPER COMPANYLa Statistique consiste à étudier un ensemble d'objets (on parle de population, composée d' individus ou unités statistiques) sur lesquels on observe des caractéristiques, appelées variables statistiques. Dans certains cas on peut obtenir les valeurs de ces variables sur l'ensemble de la population; en appliquant les méthodes de la statistique descriptive il est possible, au moyen de tableaux, graphiques, paramètres, d'analyser ces résultats. Exemples: Recensement des agents de KAMOTO COPPER COMPANY notes obtenues par les salaires de tous les employés de cette entreprise, etc... Mais la population peut être trop vaste pour être étudiée dans sa totalité, par manque de moyens, ou de temps. (C'est le cas si on s'intéresse à la situation présente des agents KCC). Elle peut même être considérée comme infinie. C'est le cas si l'on note la qualité (défectueuse ou non) des pièces produites par un certain procédé : le nombre de ces pièces est a priori illimité, et on ne peut toutes les tester. De même, si l'on s'intéresse aux fréquences d'obtentions de "pile" et "face" avec une pièce de monnaie, le nombre de lancers de pièce à étudier est à priori infini : on a ici une population latente infinie. Il arrive aussi que la mesure d'une variable soit destructrice pour l'individu : si on étudie la durée de vie de certains appareils, il serait absurde de les faire tous fonctionner jusqu'à la panne, les rendant inutilisables. Dans tous ces cas, on est amené à n'étudier qu'une partie de la population, un échantillon, obtenu par sondage, dans le but d'extrapoler à la population entière des observations faites sur l'échantillon. III.1. CARACTÉRISTIQUE DE L'ÉCHANTILLON.En statistique, un échantillon est un ensemble d' individus représentatifs d'une population. L'objectif est d'obtenir une meilleure connaissance de la population par l'étude du seul échantillon. Le recours à un échantillon répond en général à une contrainte pratique (manque de temps, de place, évaluation destructive d'une production, coût financier...) interdisant l'étude exhaustive de la population. L'acte de sélection s'appelle l'échantillonnage. Pour garantir une bonne représentation, il s'agit en général d'un échantillon aléatoire, totalement ou partiellement. La statistique s'est donc intéressée aux principes d'échantillonnage, dans le but de garantir ou au moins d'estimer la fiabilité de conclusions tirées de l'étude d'échantillons, mais étendues aux populations entières. Quelques-unes des préoccupations de la théorie de l'échantillonnage sont : · la capacité à capter la diversité du phénomène étudié ; · l'absence de biais ou erreur systématique ; · le lien entre la taille de l'échantillon et la confiance que l'on peut accorder à la généralisation des résultats. La stratégie d' échantillonnage constitue une étape essentielle de la conception des expériences scientifiques, avec ou sans traitement expérimental particulier, c'est-à-dire incluant les mesures sur un objet ( metrologie) ainsi que, par exemple, les suivis environnementaux et la biométrie. Les statisticiens supposent la population d'une taille donnée et lui associent une loi de probabilité, c'est le rôle de l' inférence statistique ou statistique mathématique. Dans ces conditions, l'échantillon est interprété comme un ensemble de variables aléatoires dont on possède une réalisation supposée issue de tirages indépendants. L'analyse des propriétés de l'échantillon permet d'estimer certaines caractéristiques de la population, de déterminer la validité de ces estimations ou de certaines hypothèses. Dans les sondages d'opinion la théorie statistique obligerait à tenir à jour la liste des membres de la population, tirer au sort les heureux élus et interroger ceux-ci à l'exclusion de tous les autres. C'est évidemment impossible et les instituts tentent de bâtir ce qu'ils nomment un échantillon représentatif. Celui-ci doit obéir à un certain nombre de règles afin de s'assurer de sa représentativité qui exige l'indépendance des réponses. Le problème concerne la validité d'un tel choix. Il semblerait que, mieux elle est assurée, plus on se rapproche d'un sondage aléatoire avec ses limites parfaitement déterminées par la théorie (une enquête effectuée sur 1,000 personnes a 95 chances sur 100 de donner le résultat correct à #177;3 % près, d'après le calcul de l' intervalle de fluctuation). Selon la plupart des instituts leurs résultats seraient meilleurs, ce qui demanderait quelques justifications. La taille d'échantillon se calcule avec la formule suivante: n = t² * p * (1-p) / m² · n: Taille d'échantillon minimale pour l'obtention de résultats significatifs pour un événement et un niveau de risque fixé · t: Niveau de confiance (la valeur type du niveau de confiance de 95 % sera 1,96) · p: Probabilité de réalisation de l'événement · m: Marge d'erreur (généralement fixée à 5 %) Ainsi, pour un événement ayant une probabilité de réalisation de 40 %, en prenant un niveau de confiance de 95 % et une marge d'erreur de 5 %, la taille d'échantillon devra être de : n = 1,96² * 0,4 * 0,6 / 0,05² = 368,79Soit 369 individus. Pour se faire, nous avons conçu un questionnaire d'enquête de 18 items, subdivisé en 2 grandes parties: les variables et les non variables constitués des questions fermées, ouvertes et semi- fermées. Notre échantillon est constitué de 300 agents comme repartis dans le tableau n°1. Le dépouillement des questions fermées s'effectuera par pointage pour ressortir les fréquences de distribution, à la fin nous dégagerons les effectifs à partir des quelles nous allons calculer les pourcentages selon la formule suivante :
· P : pourcentage · F : la fréquence d'apparition de la réponse · N : nombre total des fréquences ou de la distribution. a. Données en rapport avec les variables
Source: GRHKamotocoppercompany |
|