27
3.5.2 Les étapes du Machine Learning
supervisé
28
La résolution d'un problème par l'apprentissage
machine peut se résumer en trois étapes, voir quatre si on estime
que la compréhension de la problématique posée entre dans
le processus d'apprentissage (Chaouche, 2018) :
· La tâche spécifique :
comprendre le problème à résoudre
· Les données : préparer les
données
· L'algorithme d'apprentissage : choisir
et paramétrer un algorithme
· La mesure des performances du modèle :
évaluer le modèle pour ajuster au mieux ses paramètres.
Avant de démarrer un projet de Machine Learning il est
nécessaire de comprendre la problématique afin de
sélectionner les bonnes données, le bon algorithme et les bons
paramétrages.
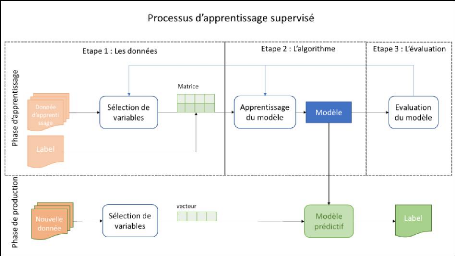
Figure 12 - Etapes de modélisation d'un
classifieur
Comme toute démarche empirique, le processus
d'apprentissage est itératif, il est peu probable d'arriver au meilleur
résultat possible du premier coup. Il sera donc nécessaire de
revenir sur certaines étapes pour améliorer le résultat.
L'évaluation permet de cibler les paramètres à optimiser
tant au niveau de l'algorithme que du pré-traitement des données
(figure 12).
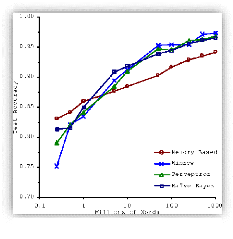
Figure 13 - Importance des données par rapport aux
algorithmes (Banko et Brill - 2001)
3.5.3 Les données
Le traitement des données est une étape
cruciale dans le processus de construction du modèle.
3.5.3.1 Quantité suffisante
Sans les données, il ne peut y avoir d'apprentissage,
c'est donc la première étape dans ce genre de projet :
vérifier que l'on dispose d'assez de données pour que le projet
soit viable.
29
D'ailleurs, il est prouvé que la performance de
l'apprentissage machine s'améliore avec la quantité de
données en entrée. Comme on peut le constater dans la figure
13,
l'augmentation des performances résultant de
l'utilisation de plus de données dépasse toute différence
de choix d'algorithmes. Un algorithme médiocre avec cent millions de
mots d'apprentissage dépasse le meilleur algorithme connu avec un
million de mots indépendamment de la technique choisie (Banko &
Brill, 2001).
Peter Norvig avance même que les données sont
plus importantes que les algorithmes notamment dans le cas de résolution
de problèmes complexes (Halevy, et al., 2009).
3.5.3.2 Donnée représentative
Les résultats seront bons si, et seulement si, les
données sont représentatives du corpus à traiter en
production. La sélection des données pour l'entrainement aura
donc un impact important sur la performance du modèle construit
(Géron, 2017).
| 

