3.3 La classification de documents
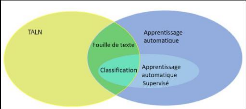
Figure 10 - La classification, à la croisée
des chemins de l'IA
Parmi la multitude d'applications de l'intelligence
artificielle, la classification de documents consiste à regrouper les
documents en catégories en fonction de leur contenu. La classification
des documents joue un rôle essentiel dans diverses
applications d'intelligence artificielle
traitant de
l'organisation, de la classification et de la recherche de quantités
importantes de données textuelles. La classification de documents est
une discipline étudiée de longue date dans les disciplines de la
recherche d'information (Power, et al., 2010) (Patra & Singh, 2013). C'est
aussi une des tâches de la fouille de texte qui utilise les techniques et
méthodes du TALN et le Machine Learning (figure 10).
3.4 Le traitement automatique du langage naturel
Le TALN (NLP en anglais) ou TAL est le domaine de
l'intelligence artificielle qui s'intéresse à l'analyse et
à la compréhension des langues naturelles. Bien que cette
discipline ait plus de soixante ans, ce n'est qu'à partir des
années 90 qu'elle se développe, grâce aux progrès de
l'informatique qui a permis le traitement du texte au format numérique.
Les techniques utilisées aujourd'hui sont issues de l'informatique, de
la linguistique et du Machine Learning (Tellier, 2010).
Il existe deux approches distinctes, l'approche linguistique
et l'approche syntaxique (aussi appelée stochastique), cette
dernière s'appuie sur les méthodes numériques,
principalement statistiques et probabilistes, elle ne cherche pas à
comprendre le texte mais à étudier les corrélations
présentes dans celui-ci. Depuis que les chercheurs se sont
tournés vers ces nouvelles méthodes de l'intelligence
12 Traitement automatique de la langue naturelle
13 Natural language Processing
26
artificielle, le TALN a connu une avancée remarquable,
parmi les applications que le grand public utilise, il y a la correction
orthographique des logiciels de traitement de textes, la reconnaissance de
caractère, et plus récemment la traduction automatique et la
reconnaissance vocale.
Nous ferons un focus sur ces méthodes
appliquées à la classification textuelle qui sont principalement
issues du Machine Learning.
3.5 Le Machine Learning
Comme toutes les branches de l'intelligence artificielle, les
domaines du Machine Learning et du TALN partagent l'objectif de douer les
machines de certaines capacités humaines (Tellier, 2010), comme nous
l'avons vu plus haut le TALN utilise les méthodes du Machine Learning en
particulier dans les tâches de fouille de textes et de recherche
d'informations. Le Machine Learning est un domaine vaste et complexe, nous nous
limiterons aux aspects qui s'appliquent à notre sujet.
Le Machine Learning est la voie qui donne aujourd'hui les
meilleurs résultats dans les applications d'intelligence artificielle.
Cette discipline étudie, développe des techniques et
méthodes qui permettent à un algorithme d'apprendre à
partir d'exemples. C'est une démarche empirique qui tient plus de
l'observation que de la logique mathématique.
Parmi les nombreuses définitions du Machine Learning
celle-ci résume assez bien le but du Machine Learning : « une
machine14 est censée apprendre, si à partir d'une
expérience E en respectant les classes de la tâche T et en
mesurant la performance P sa performance à exécuter la
tâche T mesuré par P s'améliore avec l'expérience E
» (Mitchell & al., 1997), en d'autres termes il s'agit
d'améliorer la performance d'un algorithme à réaliser la
tâche en utilisant un ensemble d'exercices d'apprentissage.
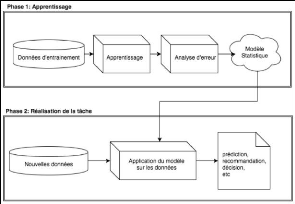
Figure 11 - Les deux phases de l'apprentissage automatique
(Chaouche, 2018)
Rappelons que la plupart des applications de Machine Learning
ont pour objectif d'automatiser, tout ou partie, des tâches complexes
accessibles seulement à l'être humain. Le ML15
répond ainsi aux problématiques non résolues par les
systèmes basés sur l'approche symbolique traditionnelle de
l'intelligence artificielle. Ceux-ci ne peuvent être
modélisés et configurés que par des spécialistes,
cette approche devient problématique lorsque la complexité
augmente et limite le
champ d'application de
l'intelligence artificielle. Au
contraire, le ML qui se
base principalement sur une approche
analogiste va limiter
14 « Machine » est pris au sens informatique,
autrement dit c'est un programme
15 Machine Learning
l'intervention d'experts, ce système utilise des
exemples déjà vus pour prendre des décisions. Dans une
première phase, il va rechercher des corrélations à partir
d'un jeu de données en entrée pour créer une règle,
puis le but est de généraliser cette règle apprise
à de nouvelles données dans une deuxième phase (figure
11).
3.5.1 Les modes d'apprentissage et les types de
problèmes à résoudre
Il existe plusieurs techniques de Machine Learning (Russell
& Norvig, 2010) :
· L'apprentissage supervisé : Un
expert labelise une partie des données qui va servir à
l'apprentissage. L'algorithme va alors apprendre la tâche de
classification en se basant sur les données labelisées.
· L'apprentissage non supervisé
: L'algorithme doit découvrir de lui-même les
ressemblances et différences dans les données fournies pour
apprendre la tâche.
· L'apprentissage semi-supervisé :
Les algorithmes fonctionnent comme pour l'apprentissage
supervisé mais acceptent en plus des données non
labelisées pendant la phase d'apprentissage.
· L'apprentissage par renforcement :
L'algorithme doit apprendre les actions à partir d'expériences,
de façon à gagner une récompense et à éviter
un gage.
Il existe deux types de problèmes bien distincts pour
lesquels le ML propose une solution, la classification et la
régression.
· Classification : Un problème
d'apprentissage supervisé où la réponse à apprendre
est celle d'un nombre infini de valeurs possibles. C'est un type de tâche
qui va chercher à catégoriser des éléments à
partir d'autres. Quand il n'y a que deux valeurs possibles, on dit que c'est un
problème de classification binaire, s'il y en a plus on parle de
classification multi-classes.
· Régression : Un
problème d'apprentissage supervisé où la réponse
à apprendre est une valeur continue. L'algorithme va chercher à
prédire un chiffre.
La tâche à traiter dans notre contexte
relève de la classification supervisée, nous ne nous
intéresserons pas aux autres cas dans la suite de ce chapitre. Le
modèle de classification supervisée à construire est
communément appelé « classifieur » (Boucheron, et al.,
2005).
| 

