Conclusion
Dans ce chapitre on a vu comment représenter des
applications parallèles en utilisant des graphes de
précédence et de flots de données. Un autre plus
général que nous adopterons par la suite a été
présenté : le graphe de tâches. Il contient les
caractéristiques des deux graphes précédemment
cités mais de manière plus fine. Après avoir
présenté de manière succinte les modèles
d'ordonnancement avec délai et sans délai de communications sur
des graphes, nous avons décrit les modèles d'exécution les
plus souvent employés qui donnent une prédiction sur le temps
d'exécution parallèle. Les modèles sans délais de
communication sont très loin de la réalité concernant les
machines à mémoire distribuée alors que les modèles
avec délai sont raisonnablement plus proches de la réalité
bien qu'ils ne tiennent pas compte des paramètres comme le débit
du processeur, la latence de communication entre des processeurs distants. Les
modèles LogP et BSP par contre tiennent compte de ces paramètres
en plus du nombre d'unités de calcul. Le second utilise également
un synchroniseur général après les super-étapes de
calcul.
Il ressort des modèles d'exécution qu'on obtient
un temps optimal lorsque l'on néglige les temps de communication, mais
on s'éloigne du temps optimal lorsque l'on tient compte des
délais de communication. Le principe de la duplication de tâches
est souvent employée pour réduire les temps d'inactivité
des processeurs. Jusqu'ici, les modèles utilisés négligent
des éléments importants comme la congestion du réseau
pourtant présents dans une architecture MIMD à mémoire
distribuée telle que les grappes
3Les communications sont cachées
hétérogènes dans la cadre de
l'ordonnancement. Dans le chapitre suivant, nous proposons un modèle
d'ordonnancement sous ces architectures.
Chapitre III
GRAPPES HETEROGENES et
ORDONNANCEMENT
N
otre travail a pour objectif de proposer un ordonnancement des
tâches issues d'une application parallèle sur une grappe
hétérogène en tenant compte de toutes les ressources
informatiques présentes. En d'autres termes, étant donnés,
l'application parallèle traduite en graphe de tâches et la
grappe
hétérogène, il s'agira pour nous de trouver
un bon placement des tâches.
Il convient donc de bien maîtriser d'une part notre
architecture MIMD donc de cerner ses caractéristiques en termes de
ressources logicielles( les bibliothèques de communication ) et
matérielles ( le réseau d'interconnexion, les noeuds, les
équipements réseaux etc.) et d'autre part le graphe de
tâches (les précédences, les volumes de données
etc..) pour répartir efficacement les tâches de notre application
entre les différentes unités de traitement et de traiter chacune
en parallèle.
1 Eléments de coût
Les grappes hétérogènes impliquent de
prendre en compte plusieurs facteurs de coût pour une bonne exploitation.
Parmi ces facteurs, on peut citer les stations de travail, les
éléments d'interconnexion entre eux, la technologie du
réseau utilisé et le système d'exploitation et la pile
réseau.
1.1 Les stations de travail
Les machines constituants la grappe peuvent être des
machines constituées de plusieurs processeurs ou des monoprocesseurs.
Ces machines peuvent avoir des mémoires de capacités de stockage
différentes(256 Mo, 128 Mo etc..).
1.2 Les équipements réseau
Les équipements permettant de faire transiter les
données entre les stations de travail peuvent être :
- Les commutateurs
- Les routeurs
- Les concentrateurs
1.2.1 Les commutateurs
Ce sont des équipements de couche 2 du modèle OSI
qui filtrent, acheminent et font circuler les trames ( figure III-1 ) en
fonction de l'adresse de destination de chaque trame.
Les commutateurs utilisent des adresses MAC pour orienter les
communications réseau via leur matrice de commutation vers le port
approprié et en direction du noeudde destination. La matrice de
commutation désigne les circuits intégrés et les
éléments de programmation associés qui permettent de
contrôler les chemins de données par le biais du commutateur. Pour
qu'un commutateur puisse connaître les ports à utiliser en vue de
la transmission d'une trame de monodiffusion, il doit avant tout savoir quels
noeuds existent sur chacun de ses ports.
Un commutateur détermine le mode de gestion des trames
de données entrantes à l'aide d'une table d'adresses MAC. Il
crée sa table d'adresses MAC en enregistrant les adresses MAC des noeuds
connectés à chacun de ses ports.
Dès que l'adresse MAC d'un noeudspécifique sur
un port spécifique est enregistrée dans la table d'adresses, le
commutateur peut alors envoyer le trafic destiné au noeudvers le port
mappé à ce dernier pour les transmissions suivantes.
Lorsqu'un commutateur reçoit une trame de
données entrantes et que l'adresse MAC de destination ne se trouve pas
dans la table, il transmet la trame à l'ensemble des ports, à
l'exception du port sur lequel elle a été reçue.
Dès que le noeudde destination répond, le commutateur enregistre
l'adresse MAC de ce dernier dans la table d'adresses à partir du champ
d'adresse source de la trame. Dans le cadre de réseaux dotés de
plusieurs commutateurs interconnectés, les tables d'adresses MAC
enregistrent plusieurs adresses MAC pour les ports chargés de relier les
commutateurs qui permettent de voir au-delà du noeud. En règle
générale, les ports de commutateur utilisés pour connecter
entre eux deux commutateurs disposent de plusieurs adresses MAC
enregistrées dans la table d'adresses MAC.

Figure III.1 - Trame ethernet
Ils transmettent des trames Ethernet sur un réseau selon
différents modes : commutation Store and Forward (stockage et
retransmission) ou cut-through (direct).
Commutation store and forward. Lorsque le
commutateur reçoit la trame, il stocke les données dans des
mémoires tampons jusqu'à ce qu'il reçu
l'intégralité de la trame. Au cours de ce processus de stockage,
le commutateur recherche dans la trame des informations concernant sa
destination. Dans le cadre de ce même processus, le commutateur
procède à un contrôle d'erreur à l'aide du
contrôle par redondance cyclique (CRC) de l'en-queue de la trame
Ethernet. Le contrôle par redondance cyclique (CRC) a recours à
une formule mathématique fondée sur le nombre de bits (de uns)
dans la trame afin de déterminer si la trame reçue possède
une erreur. Une fois l'intégrité de la trame confirmée,
celle-ci est transférée via le port approprié vers la
destination. En cas d'erreur détectée au sein de la trame, le
commutateur ignore la trame. L'abandon des trames avec erreurs réduit le
volume de bande passante
consommé par les données altérées.
Commutation cut-through. Dans le cas de la
commutation cut-through, le commutateur agit sur les données à
mesure qu'il les reçoit, même si la transmission n'est pas
terminée. Le commutateur met une quantité juste suffisante de la
trame en tampon afin de lire l'adresse MAC de destination et déterminer
ainsi le port auquel les données sont à transmettre. L'adresse
MAC de destination est située dans les six premiers octets de la trame
à la suite du préambule. Le commutateur recherche l'adresse MAC
de destination dans sa table de commutation, détermine le port
d'interface de sortie et transmet la trame vers sa destination via le port de
commutateur désigné. Le commutateur ne procède à
aucun contrôle d'erreur dans la trame.
Il existe deux variantes de la commutation cut-through:
- Commutation fast-forward : ce mode de commutation offre le
niveau de latence le plus faible. La commutation fast-forward transmet un
paquet immédiatement après la lecture de l'adresse de
destination. Du fait que le mode de commutation fast-forward entame la
transmission avant la réception du paquet tout entier, il peut arriver
que des paquets relayés comportent des erreurs. Cette situation est
occasionnelle et la carte réseau de destination ignore le paquet
défectueux lors de sa réception. En mode fast-forward, la latence
est mesurée à partir du premier bit reçu jusqu'au premier
bit transmis. La commutation fast-forward est la méthode de commutation
cut-through classique.
- Commutation fragment-free : en mode de commutation
fragment-free, le commutateur stocke les 64 premiers octets de la trame avant
la transmission. La commutation fragment-free peut être
considérée comme un compromis entre la commutation store
andforward et la commutation cut-through. La raison pour laquelle la
commutation fragment-free stocke uniquement les 64 premiers octets de la trame
est que la plupart des erreurs et des collisions sur le réseau
surviennent pendant ces 64 premiers octets. La commutation fragment-free tente
d'améliorer la commutation cut-through en procédant à un
petit contrôle d'erreur sur les 64 premiers octets de la trame afin de
s'assurer qu'aucune collision ne s'est produite lors de la transmission de la
trame. La commutation fragment-free offre un compromis entre la latence
élevée et la forte intégrité de la commutation
store and forward; et la latence faible et l'intégrité
réduite de la commutation cut-through.
La commutation cut-through est bien plus rapide que la
commutation store and forward, puisque le commutateur n'a ni à attendre
que la trame soit entièrement mise en mémoire tampon, ni besoin
de réaliser un contrôle d'erreur. En revanche, du fait de
l'absence d'un contrôle d'erreur, elle transmet les trames
endommagées sur le réseau. Les trames qui ont été
altérées consomment de la bande passante au cours de leur
transmission. La carte de réseau de destination ignore ces trames au
bout du compte.
De plus, les commutateurs peuvent être
symétriques ou asymétriques. La commutation
symétrique offre des connexions commutées entre les ports
dotés de la même bande passante, notamment tous les ports
100Mbits/s ou 1000Mbits/s. Un commutateur de réseau local
asymétrique assure des connexions commutées entre des ports
associés à des bandes passantes différentes, par exemple
entre une combinaison de ports de 10Mbits/s, 100Mbits/s et 1000Mbits/s.
Un commutateur asymétrique dispose donc de débit
différents sur chacun de ses ports.
1.2.2 Les concentrateurs
Ce sont des équipements réseau d'interconnexion
de couche 1 du protocole OSI qui contrairement aux switchs sont moins
intelligents. Ils n'ont aucune fonction de commutation, de traitement
de données. Lorsqu'ils reçoivent un signal (0 ou 1), ils ne
savent à qui transmettre l'information; ils propagent l'information sur
tous les ports y compris le port de réception.
1.2.3 Les routeurs
Cet équipement de couche 3 du protocole OSI
maintient une table de routage contenant des routes de sortie vers
d'autres réseaux. Lorsqu'il recoit message, son rôle est choisir
le meilleur chemin pour parvenir au destinataire. Ce choix s'éffectue
à l'aide des algorithmes de routage très complexes : la route la
plus courte n'est pas forcément la meilleure. Ce qui importe en
réalité, c'est la somme des temps de transit pour une destination
donnée qui, elle même, est proportionnelle à l'importance
du traffic et au nombre de messages qui attendent d'être transmis sur les
différentes lignes.
1.3 Technologie réseau
Les communications dans un réseau local commuté
surviennent sous trois formes : monodiffusion, diffusion et multidiffusion :
- Monodiffusion : communication dans laquelle une trame est
transmise depuis un hôte vers une destination spécifique. Ce mode
de transmission nécessite simplement un expéditeur et un
récepteur. La transmission monodiffusion est la forme de transmission
prédominante adoptée sur les réseaux locaux et sur
Internet. HTTP, SMTP, FTP et Telnet sont des exemples de transmission
monodiffusion.
- Diffusion : communication dans laquelle une trame est
transmise d'une adresse vers toutes les autres adresses existantes. Un seul
expéditeur intervient dans ce cas, mais les informations sont transmises
à tous les récepteurs connectés. La transmission par
diffusion est un incontournable si vous envoyez le même message à
tous les périphériques sur le réseau local. Un exemple de
diffusion est la requête de résolution d'adresse que le protocole
ARP (Address Resolution Protocol) transmet à tous les ordinateurs sur un
réseau local.
- Multidiffusion : communication dans laquelle une trame est
transmise à un groupe spécifique de périphériques
ou de clients. Les clients de transmission multidiffusion doivent être
membres d'un groupe de multidiffusion logique pour recevoir les informations.
Les transmissions vidéo et vocales employées lors de
réunions professionnelles collaboratives en réseau sont des
exemples de transmission multidiffusion.
Selon chacune des formes, les liens peuvent être de
latence et débit différents. Typiquement, si on a trois machines
M1 , M2 , M3 reliées via un commutateur
S1, le temps de transmission de M1 à M2 peut
être différent du temps de M1 à M3 par
exemple. Cela peut être dû aux congestions intervenues sur chaque
liaison ou même aux performances des machines.
1.4 Système d'exploitation et pile
réseau
Les ordinateurs constituants la grappe peuvent avoir des
systèmes d'exploitation différents avec une version
précise.Comme exemple, Ubuntu 9.04, Windows Vista, Solaris 9 etc.. Ces
systèmes sont constitués de module de gestion des communications.
Dans la suite nous donnons une description générale de la pile
réseau utilisée pour les communications entre deux
hôtes.
Dans un système monoprocesseur, la plupart des
communications inter-processus supposent l'existence d'une mémoire
partagée. Dans le cas d'une grappe, le mémoire est
distribuée et les communications se font par échange de messages.
Quand le processus A veut communiquer avec le processus B, il commence
par élaborer un message dans son propre espace d'adressage. Il
exécute ensuite un appel système qui va prendre le message et
l'envoyer à B via le réseau. L'émetteur et le
récepteur doivent être en accord sur de nombreuses choses; depuis
les détails de bas niveau de la transmission des bits jusqu'à
ceux de plus haut niveau de la représentation des données. Pour
résoudre plus facilement ces problèmes, l'ISO (organisation
internationale de Normalisation) a défini un modèle de
référence qui identifie clairement les différents niveaux
d'une communication. Ce modèle est le modèle OSI (Open
Systems Interconnection) qui comporte sept couches:
1. la couche physique : c'est la couche la plus basse. Elle est
concernée par la normalisation des interfaces électriques et
mécaniques et des signaux.
2. la couche liaison : Son rôle primordial est de
détecter et traiter les erreurs dans les réseaux de
communication.
3. la couche réseau : Son rôle est de choisir le
meilleur chemin pour faire transiter un message.
4. la couche transport : Son rôle est de gérer le
service de connexion fiable entre l'expéditeur et le destinataire.
5. la couche session: C'est une version enrichie de la couche
transport. Elle fournit des dialogues de contrôle pour mémoriser
les connexions en cours ainsi que des mécanismes de synchronisation.
6. la couche présentation : Elle s'occupe de la
signification des bits.
7. la couche application: c'est la couche la plus haute. Elle
comporte un ensemble de protocoles divers pour gérer des applications
utilisateurs comme le transfert de fichiers.
Dans ce modèle, la communication est partagée en
ces sept couches. L'ensemble des protocoles utilisés est appelé
suite de protocoles ou pile de protocoles. Quand le processus
A de la machine 1 veut communiquer avec le processus B de la
machine 2, il élabore un message et passe ce message à la couche
application de la machine 1. Le logiciel de la couche application ajoute une
en-tête au début du message et passe le message qui en
résulte à la couche présentation au travers de l'interface
des couches 6/7. La couche présentation rajoute son en-tête et
passe le résultat à la couche session et ainsi de suite.
Certaines couches ne se contentent pas d'ajouter des informations en
début du message, elles en ajoutent également à la fin.
Quand le message arrive en bas de la pile, la couche physique transmet le
message qui ressemble alors à ce qui est décrit à la
figure III.2.
Quand le message arrive sur la machine 2, il remonte les
couches et chacune de celles-ci prend et examine l'en-tête qui lui
correspond. Le message finit par arriver au récepteur, c'est à
dire que la machine 2 peut alors répondre en suivant le chemin
inverse.
Si on examine encore notre cas de tout à l'heure entre
la machine 1 et la machine 2, l'existence des en-têtes implique une perte
d'éfficacité considérable. Chaque fois qu'un message est
envoyé, il doit être traité par une demi douzaines de
couches. Chacune d'entre elles génère et ajoute un en-tête
dans le chemin descendant ou bien retire et traite dans le chemin ascendant.
Tout ce travail prend du temps. La perte d'éfficacité due
à la gestion de la pile de protocoles n'est pas négligeable pour
un système qui utilise un réseau local. On perd réellement
de temps UC1 pour cette gestion que le débit effectif est
souvent une fraction de la capacité nominale du réseau.
Cette description est variable selon des systèmes
d'exploitation.
'Unité centrale
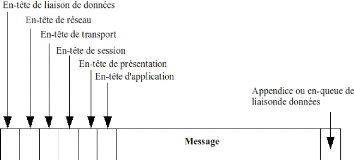

Figure III.2 - Un message classique tel qu'il
transite sur le réseau
Nous voyons donc que chacun des éléments de
coût ci-haut sont non uniformes et complexes dans leur fonctionnement.
Chacun d'eux induit des surcoûts considérables.
Les modèles d'ordonnancement traditionnels
présentés au chapitre précédent ne sont pas
réellement adaptés aux grappes hétérogènes
puisqu'ils ne tiennent pas compte d'un grand nombre de paramètres
cités ci-haut. Notamment, le coût de gestion de la pile de
protocoles est toujours considéré comme négligeable, la
congestion du réseau est négligée (ces modèles
supposent généralement que le réseau est parfait). Ils
nécessitent par conséquent d'être plus affinés. Nous
développons dans la suite un modèle plus fin de placement des
tâches sur les ressources de calcul sur notre architecture. Nous donnons
également une modélisation de cette dernière.
2 Proposition d'un modèle d'ordonnancement sur
les grappes hétérogènes
Notre système d'ordonnancement comprend : le graphe de
tâches, la grappe hétérogène et l'ordonnancement
proprement dit dans lequel des critères de performance et de
validité seront détaillés. Ces composantes sont
présentées plus formellement.
2.1 Modélisation de l'architecture
hétérogène
Notre environnement hétérogène peut donc
être modélisé par un graphe Gr =
(Vr, Er) que nous appellons graphe de la
grappe. Vr = {P1, P2, ...,
Pm} est l'ensemble des unités de calcul.
Er est l'ensemble des liens de communication entre les
noeuds.
1. m noeuds Pi, 1 < i < m
caractérisés par: - Leur puissance Si,
- Leur capacité mémoire Mi,
- L'impact du protocole réseau Ri.
2. Chaque arc (i, j) de Er
connectant deux noeuds Pi et Pj de Vr est
caractérisé par: - Sa latence lij,
- Son débit dij.
2.2 Graphe de tâches.
Les caractéristiques de notre application parallèle
sont définis comme les 4-uplets (T,<,D,A) ainsi qu'il suit :
- T=t1,...,tn qui est
l'ensemble des tâches à exécuter.
- < est l'ordre partiel défini sur T qui
spécifie les contraintes sur l'ordre de précédence entre
les tâches. C'est à dire ti < tj veut dire que ti
doit être complètement exécutée avant que
tj ne débute son exécution.
- D est une matrice n x n de
données communiquées entre les tâches, où dataij
~ 0 est le volume des données réquis à transmettre de
la tâche ti à la tâche tj, 1 < ti,
tj < n.
- A un vecteur de taille n qui représente
l'ensemble des coûts des chaque tâche. C'est à dire, cij
> 0 est le coût en calcul de la tâche ti sur le
processeur Pj, 1 ti, tj n.
Le graphe de tâche (T,E) est acyclique
où E est l'ensemble des arcs.
Un arc (ti,tj) entre deux tâches
ti et tj spécifie la relation de
précédence entre ti et tj. A chaque sommet
ti est associé son temps de calcul qui représente le
nombre d'instructions ou d'opérations présentes dans la dite
tâche. A Chaque arc (ti,tj) connectant les tâches
ti et tj est associé la taille des données
dataij, c'est à dire la taille du message de ti
à tj.
Ordonnancer les tâches revient donc à
répartir les tâches sur la grappe en respectant les contraintes de
précédence entre elles.
2.3 L'ordonnancement.
Un ordonnancement f prend en entrée: - Le graphe
de grappe Gr =
(Vr,Er),
- Le graphe de tâches G = (V, E) Plus
formellement,
- f : V -? Vr X
[0,00) Ti -? (Pj,s)
f(Ti) = (Pj, t) signifie que la
tâche Ti sera traitée par le processeur Pj au
temps t.
- F inTim est le temps de fin
d'exécution de la tâche Ti sur le processeur
Pm.F inTim = sim + cim où
sim est son temps de début d'exécution sur le
processeur Pm.
2.4 Modéle des communications
Une tâche est considérée comme
prête si tous ses prédécesseurs ont terminé
leur éxécution et que toutes les données utiles
calculées par ses prédécesseurs ont été
acheminées dans la mémoire locale du processeur où vont
avoir lieu les calculs.
Deux tâches d'un arc du graphe peuvent être
allouées au même processeur ou non. Lorsque nous sommes dans le
premier cas, cela veut dire que le coût de communication de
données est identique à celui d'un accès à la
mémoire locale puisque les données nécéssaires
à l'exécution des tâches sont présentes. Ce
coût est négligeable et est considéré égal
à zéro. Lorsque nous sommes dans le deuxième cas, le
coût de communication de données est le temps de transfert des
données nécessaires à la tâche seconde pour
débuter son exécution.
Plus formellement, Si une tâche Ti (
ordonnançée sur Pm ) doit communiquer les
données à l'un de ses successeurs Tj (
ordonnançée sur Pn ), le coût est
modéliser par :
1
0 si Pm = Pn
C(Tim, Tjn) = lmn +
dataij × 1
dmn sinon.
La date de début d'exécution de Tj est
donc sjn = F inTim +
C(Tim, Tjn).
Les problèmes NP-complet sont des problèmes qui
sont très difficilement solubles en temps polynomial. Il ya un bon
nombre de problèmes qui sont équivalents en complexité et
forment la classe des problèmes NP-complets. Cette classe inclut
plusieurs problèmes classiques de combinatoire, de théorie de
graphe, et d'informatique comme le problème du voyageur de commerce, le
problème du circuit hamiltonien, le problème d'affectation etc.
Les meilleurs algorithmes connus pour ces problèmes peuvent avoir une
complexité exponentielle avec certaines entrées. La
complexité exacte de ces problèmes NP-complets reste un
problème ouvert en informatique théorique. Soit tous ces
problèmes ont des solutions en temps polynomial ou aucun d'entre eux n'a
une telle solution.
Il a été prouvé que le problème
d'ordonnancement[6] d'un ensemble de m tâches sur n
processeurs identiques est NP-Complet en tenant compte des communications
entre les processeurs. Nous avons choisi d'aller vers une solution heuristique
permettant d'avoir un bon ordonnancement.
2.5 Idée Générale
Les points suivants constituent l'idée
générale à appliquer lorsque l'on doit effectuer une
instance d'ordonnancement f comme décrit
précédemment.
1. Exécuter les tâches les plus longues sur les
processeurs les plus rapides.
2. Exécuter les tâches qui communiquent beaucoup
sur les processeurs disponibles les plus proches.2
3. Exécuter les tâches qui communiquent un gros
volume de données sur des processeurs connectés sur des gros
réseaux.
4. On exécute Ti sur Pj si :
- le temps de transfert des données de Ti sur
Pj est minimal
- Pj est libre à cet instant
- cij est «acceptable »
La décision d'exécuter une tâche ti
sur un processeur Pj à un instant donné est donc
motivée par: - L'ensemble des tâches prêtes
- Le coût des tâches cij
- Le surcoût des communications
- L'état des processeurs
Le chapitre suivant illustrera sur un exemple cette
heuristique.
2Les processeurs interconnectés par des liens
de latence faible
| 

