CHAPITRE 1 : Modélisation QSPR/QSAR
1. Les méthodes QSAR/QSPR
Les méthodes QSAR (Quantitative Structure-Activity
Relationships) et QSPR (Quantitative Structure Property Relationships) reposent
sur la recherche d'une relation entre un ensemble de nombres réels,
appelés descripteurs moléculaires et la propriété
ou l'activité que l'on souhaite prédire, afin de justifier les
données expérimentales disponibles et prédire les
propriétés et les activités pour des nouveaux
composés, pour lesquels les données expérimentales ne sont
pas disponibles (Denis, 2007). Le principe de ces dernières est
fondé sur l'outil statistique. En effet, il existe plusieurs types
différents d'outils statistiques :
> Régressions linéaires simples et multiples.
> Régressions aux moindres carrées partielles. > Arbres de
décision.
> Réseaux de neurones.
> Algorithmes génétiques.
> Vecteurs Machines.
Ces méthodes peuvent être utilisées pour
développer des modèles RQSA dans différent domaines
d'application comme la pharmacodynamique, pharmacocinétique et
toxicologie (Yap, 2005). Dernièrement, d'autres méthodes ont
été apparues comme les nouvelles méthodes basées
sur l'apprentissage automatique appelé « Machine learning »
qui permettent une modélisation plus complexe. Ces méthodes
surpassent fréquemment ceux développés à l'aide de
méthodes statistiques traditionnelles. Le modèle optimal est
obtenu en recherchant simultanément les paramètres de
modélisation optimaux et le sous-ensemble de caractéristiques. Ce
modèle sélectionné est vérifié avec les
paramètres optimaux en faisant une validation avec un ensemble de tests
pour s'assurer que le modèle est approprié et utile
(Figure 1).
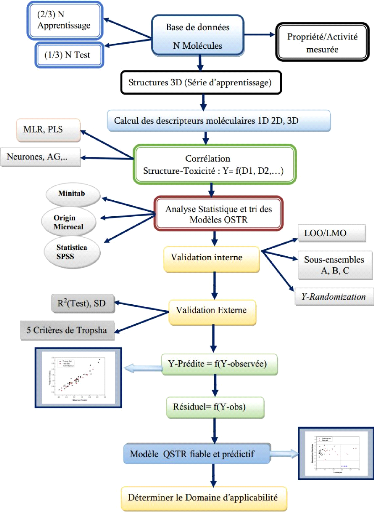
3
Figure 1. Schéma d'élaboration et
validation d'un modèle QSTR (Khadidja, 2015)
4
2. Méthodologie générale d'une
étude QSAR/QSPR
La qualité des résultats obtenus en suivant le
modèle QSAR dépendent des données expérimentales de
référence. Le choix de la base de données est une
étape très importante pour établir un lien avec les
données expérimentales de référence afin
d'éviter toutes erreurs probables. En se basant sur les données
expérimentales issues de la littérature, les théoriciens
peuvent donc choisir des données présentant des incertitudes
faibles et acceptables, ainsi ils auront des paramètres bien
ajustés aux données expérimentales. Les données
rassemblées doivent être obtenues en suivant un protocole
expérimental unique (Samir 2017).
2.1 Les descripteurs moléculaires
| 

