3.3. TEST LEXICO-STATISTIQUE AVEC LES LANGUES
VOISINES
Ne faisant aucunement partie des critères
susmentionnés permettant de voir si une langue est en mesure
d'être standardisée ou pas, nous avons jugé
nécessaire (constatant le niveau de familiarité que les locuteurs
kw ? ont de manière particulière avec leurs voisins nd
?ndà? de Bazou et m d mb de bangangté, peut être d à
l'exode), de faire une comparaison lexicostatistique de ces différents
parlers afin de ressortir leur niveau de similarité et de dissemblance.
Nous nous sommes limités à la comparaison du kw ? avec ces deux
langues uniquement (le nd ?ndà? et le m d mb ) d au fait du
rapprochement des locuteurs desdites langues, et aussi à cause de la
classification linguistique de celles-ci. Les autres langues avoisinantes comme
le ?àsà , le bàk koÌ, le ndeml et le tunen
principalement ne font pas partie de la même famille linguistique que le
kw ?
117
et les locuteurs desdites langues ne sont pas aussi
socialement proches de ceux du kw ?. Ceci nous permettra également de
démontrer que le kw ? est une unité-langue à part
entière vu que celle-ci est quasi-monodialectale comme nous l'avons
mentionné plus haut.
Pour y parvenir, nous sommes partis sur la base d'un
questionnaire de 200 mots dont nous avons trouvé des correspondances en
nd ?ndà?, en kw ? et en m d mb auprès de nos informateurs
(confère Annexe 3). Ces données ont été transcrites
en A.P.I car le logiciel utilisé pour l'analyse ne reconnait que les
symboles de cet alphabet.
Pour plus d'objectivité au niveau des résultats,
nous avons opté pour le logiciel COG version 1.3.2.10014 mis au point en
2018 par SIL International. Il s'agit d'un logiciel qui permet de comparer les
langues en utilisant la lexicostatistique ainsi que les techniques de la
linguistique comparative. Ce logiciel va de l'introduction des données
(input) jusqu'à l'analyse en passant par la comparaison des mots qui y
sont introduits. Pour analyser nos données utilisant ce logiciel, nous
avons la possibilité d'entrer directement nos mots dans le logiciel, de
l'importer à partir d'un fichier du logiciel wordsurv (beaucoup plus
spécialisé dans la phonostatistique afin de ressortir la distance
entre les variantes potentielles d'une même langue) ou à partir
d'un fichier Excel enregistré au format texte (.txt). Nous sommes parti
d'un fichier excel pour entrer nos données dans le logiciel. L'image
suivante présente la disposition des mots dans le logiciel Cog.
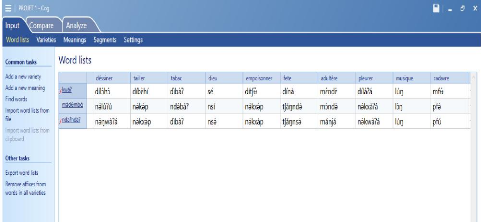
Image 1: la liste de mots à analyser dans le
logiciel Cog
À travers cette image, nous pouvons apercevoir un
tableau avec un grand titre « Word lists » qui a 4 lignes et
plusieurs colonnes. La première ligne du tableau contient les gloses des
mots transcrits, la deuxième ligne présente les mots transcrits
en langue kw ?, la troisième ligne, les
118
mots en langue m d mb et la quatrième ligne
présente les mots en langue nd ?ndà?. Nous avons un onglet sur
l'image qui nous précise que nous sommes dans le « input » du
sous-onglet « Word lists » c'est-à-dire l'introduction des
éléments à analyser. Dans cet onglet, nous avons
également divers autres éléments. L'image suivante permet
d'illustrer un autre sous-onglet.
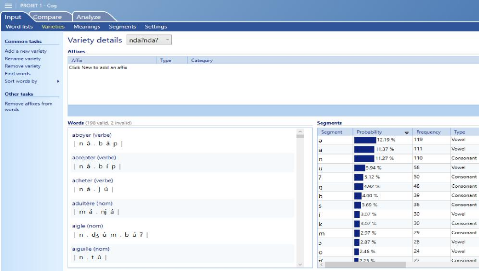
Image 2: les détails des mots nd
?ndà?
Cette image présente le sous-onglet
dénommé « varieties ». Ici, le logiciel présente
une des langues ou variétés de langues introduites pour analyse.
Nous avons choisi au hasard ici la langue nd ?ndà? et à travers
l'image ci-dessus, on peut apprécier la segmentation avec des
statistiques faites par le logiciel. Donc, pour chaque mot, le logiciel fait
automatiquement une segmentation syllabique d'une part et d'autre part, le
logiciel présente un inventaire de tous les sons avec des
probabilités en pourcentage et des fréquences que l'on peut
observer à droite sur l'image. Nous avons également la
possibilité de ressortir les sons avec à chaque fois les
occurrences dans chacune des langues ou variétés de langue.
119
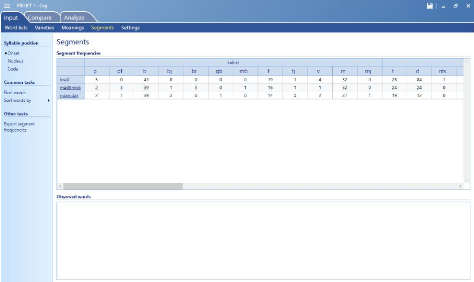
Image 3: les fréquences des segments
En observant l'image ci-dessus, nous constatons que le
logiciel fait une présentation de tous les sons
répertoriés dans les mots des 3 langues, introduits comme «
input ». Ici, nous constatons que les sons sont regroupés en
fonction de leurs caractéristiques (point d'articulation principalement)
et pour chaque son identifié, le logiciel présente le nombre de
ses occurrences dans chacune des langues concernées par l'analyse. Il
s'agit là des fréquences des segments d'après le logiciel.
Nous allons dès à présent nous intéresser au
deuxième onglet du logiciel qui concerne la comparaison
elle-même.
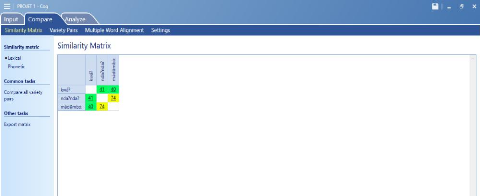
Image 4: la matrice de similarité sur le plan
lexicale
120
Après avoir importé la liste de mots dans le
logiciel, nous pouvons de manière automatique aligner et calculer la
similarité (lexicale ou phonétique) pour chaque paire de mots et
identifier les correspondances sonores régulières. L'image
ci-dessus nous présente la matrice de similarité lexicale entre
nos 3 langues. À travers cette image capturée du logiciel, nous
constatons que la similarité lexicale entre le kw ? et le nd
?ndà? est de 41%, et de 40% entre le kw ? et le m d mb . Nous pouvons
également visualiser par paire de langues et de manière plus
détaillée cette matrice de similarité ci-dessous.
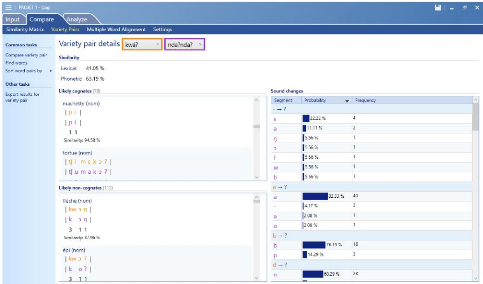
Image 5: comp r ison entre le kwaì? et le nd
?ndà?
L'image ci-dessus présente une comparaison plus
détaillée entre deux parlers, le kw ? et le nd ?ndà?. Nous
pouvons observer entre ces deux langues une similarité lexicale de
41,05% et une similarité phonétique de 63,19%. Ces
similarités sont ressorties sur la base des comparaisons des mots que le
logiciel, en fonction des rapprochements, attribuent un pourcentage quelconque
pour chaque paire tel qu'on peut observer au bas de l'image.
121
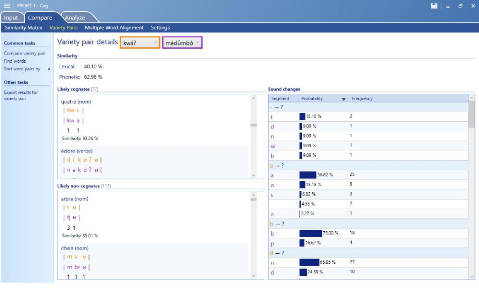
Image 6 : comp r ison entre le kwaì? et le
màd mb
La même comparaison faite avec le m d mb , nous
constatons à travers l'image ci-dessus un éloignement entre le kw
? et le nd ?ndà?. Nous observons une similarité lexicale entre
ces deux langues qui est de 40,10% et une similarité phonétique
qui se situe à 62,98%. Nous avons également de manière
délibérée recherché la similarité entre le
nd ?ndà? et le m d mb .
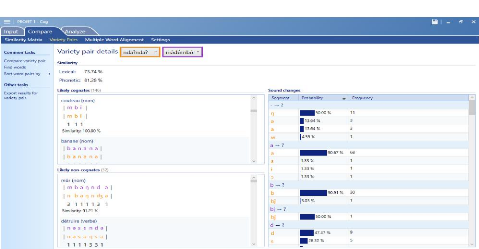
Image 7: comparaison entre le nd ?ndà? et le m? d
mb
122
travers les résultats observés dans l'image
ci-dessus, nous constatons que le nd ?ndà? et le m d mb sont plus
proches par rapport au kw ?. En effet, nous observons une similarité
lexicale située à 73,74% et une similarité
phonétique qui se situe à 81,28%.
Après analyse de nos données, nous constatons
que suivant la matrice de similarité, il existe un rapprochement lexical
de 40.10% et un rapprochement phonétique de 62.98% entre le kw ? et le m
d mb . En ce qui concerne le rapprochement entre le kw ? et le nd ?ndà?,
la similarité lexicale est de 41.05% et la similarité
phonétique est de 63.19%. Cependant, force est de constater que sur la
base des données collectées, la similarité lexicale et
phonétique entre le m d mb et le ndà?ndà? est très
considérable, donc respectivement 73.74% et 81.28%.
L'analyse de ces résultats par le logiciel est
décrite suivant un graphe tels que présentés par les
images ci-dessous.
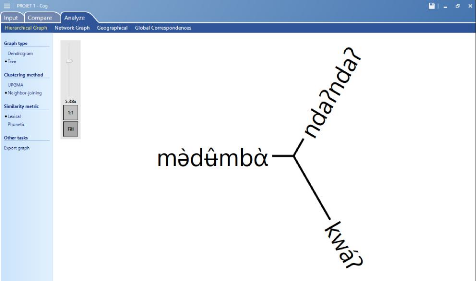
Image 8: présent tion de l' n lyse sous forme
arborescente
travers cette image, nous observons une distance entre le kw ?
et les deux autres langues. Or, ces deux autres langues semblent être
plus proches l'une de l'autre. Donc, nous pouvons à travers cette
analyse via le logiciel Cog, tirer la conclusion selon laquelle le kw ? est une
unité-langue à part entière tout comme le nd ?ndà?
et le m d mb .
123
| 

