2.2.1.1 AutoEncoders
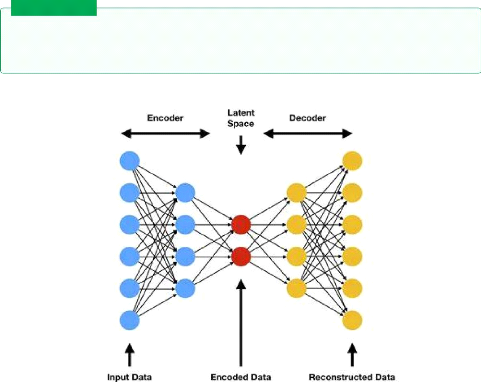
AutoEncoders are a deep learning model usedfor learning a
valid representations of unlabeled data ,it is adjusted by trying to regenerate
the input data from the encoding [12]. AutoEncoders are composed of two sub
models.
Definition 2.3
?
Figure 2.2: AutoEncoder architecture /
Source[21]
Encoder takes the data and try to learn a valid simpler
representation, in vision tasks it takes an image x fed as a vector of size y
and outputs a latent vector with the size z ,from a theory
17
2.3 Generative Adversarial Networks
of information perspective we are trying to find a smaller
representation without any loss in the information.
Latent vector(z): it is a smaller representation of the data.
Decoder: takes the latent vector with the size z and output
the image x* ,we thrive to make the image x* identical to x.
ïNote The training process
ofAutoEncoders is done through one general loss function,in contrast this would
no be the case in other architectures we are gonna bring up in the next
section.
2.2.1.2 Variational AutoEncoders
The difference between a regular AutoEncoder and a
variational AutoEncoder has to do with the latent representation.
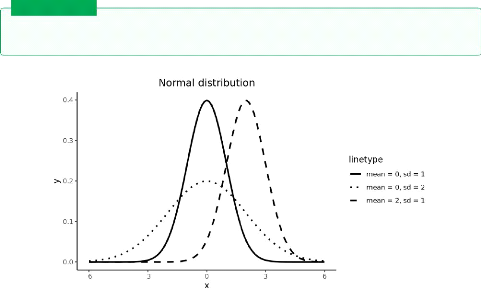
A variational AutoEncoder is a type ofAutoEncoder where
the latent vector is represented as a distribution 2.3 with a learned mean and
a standard deviation [12]
Definition 2.4
?
Figure 2.3: variational distribution /
Source[22]
In the training process of a regular AutoEncoder we learn the
values of that vector where as in variational AutoEncoder we need to further
learn the parameters of that distribution, this implies that in the decoding
process we need to sample from that distribution which means the result will
look like the data we fed into the encoder. [12].
· Note The difference for the
generating process comesfrom the nature ofthe latent space representation ,in
the variational AutoEncoder we get an output that looks something like an
example from the dataset,in contrast a regular AutoEncoder the output will be
similar to the example we fed.
18
2.3 Generative Adversarial Networks
2.3 Generative Adversarial Networks
Generative adversarial network is a new architecture ,first
introduced in 2014 by Ian Goodfellow et al at the International Conference on
Neural Information Processing Systems (NIPS 2014). Like any new technology
there is no good theories on how to implement the model, yet it achieves
remarkable results,in 2019 Nvidia released a realistic fake face images 2.4
,indistinguishable from real faces using an advanced GAN architecture called
Cycle GANs.

Figure 2.4: fake faces generated using cycle
GAN / Source [25]
2.3.1 What are Generative Adversarial
Networks
Generative adversarial networks or GANs for short is an
approach of generative modeling using deep learning ,it's a way offraming an
unsupervised problem of generating data into a supervised problem using two
models working together,a generator with the target of generating plausible
fake data and the discriminator with the target of classifying fake and real
data ,this two sub networks are trained together in an adversarial frame ,in a
zero sum game ,where the win of one sub-model is a loss to the other 2.5.
[1]
Definition 2.5
?
2.3.2 Generative Adversarial Network model
In a basic GAN architecture the generator takes a random
noise vector which is just a vector of random numbers in order to introduce
some randomness into the generation process ,the generated is next fed to the
discriminator along with a real image from the data set. the training process
happens on two cycles ,one for the discriminator and one for the generator
| 

