2. Tests des modèles et
évaluation
2.1. Détection de trafic IoT malveillant
Nous avons entraîné et testé deux algorithmes
différents pour pouvoir choisir le plus efficace.
En ce qui concerne le modèle LSTM, ses performances
étaient faibles au début mais ont donné de bons
résultats par la suite en ajustant le réseau. Le modèle
avait du mal à se généraliser mais après avoir
réduit le nombre de neurones et le nombre de couches, il a fini par
donner de meilleurs résultats. La perte était
élevée lors des premiers tests de l'entraînement toutefois
elles ont aussi diminué. Une autre difficulté est le
modèle qui prenait aussi trop de temps à s'entraîner, au
moins 40 minutes pour un epoch et autour des 400 ms/étape et ça
pouvait largement dépasser ces chiffres. Les résultats du jeu de
validation nous ont permis de nous rendre compte que l'entraînement au
début n'était pas concluant et qu'il fallait changer les
paramètres du réseau de neurone.

Figure 27 : Evolution de la
précision de l'algorithme LSTM lors de l'entraînement avec le jeu
de validation et d'entraînement lors du premier entrainement avec 04
couches de 128 neurones chacun
Cette courbe présente
l'évolution de la précision du modèle après chaque
epoch pendant l'un des premiers entraînements. Nous obtenions presque
toujours les mêmes schémas. Elle était très
élevée au début autour de 90% ou 80% et descendait
drastiquement jusqu'à 40% ou moins avant de remonter et se maintenir
autour de 55% quelque soit le nombre d'epoch et le temps
d'entraînement.
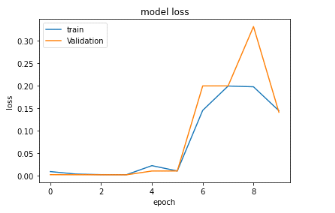
Figure 28 : Evolution de
la perte de l'algorithme LSTM lors de l'entraînement
avec le jeu de validation et celui d'entraînement lors du premier
entraînement avec 04 couches de 128 neurones chacun
Cette figure nous permet de visualiser
l'évolution des pertes après chaque epoch lors des premiers
entraînements. Celle-ci était faible durant les premiers epoch,
environ 0.1% mais ensuite augmentait tout aussi vite que descendait la
précisions et se maintenait autour des 14% ou 15% quelque soit le nombre
d'epoch.
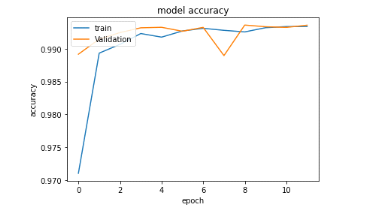
Figure 29 : Evolution de la
précision de l'algorithme LSTM lors de l'entraînement avec le jeu
de validation et d'entraînement lors du dernier entraînement avec
02 couches de 100 neurones chacun
Ensuite nous avons changé les
paramètres du réseau, réduit le nombre de couches et le
nombre de neurones. Nous avons aussi changé le nombre de classes
à prédire pour mélanger certaines classes que nous avons
jugé non pertinentes de séparer. La figure ci-dessus nous
démontre que cela a eu des effets positifs sur le modèle. Elle a
rapidement atteint les 99% de précision et le temps d'entraînement
de chaque epoch a diminué de quelques minutes.
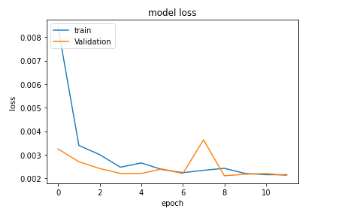
Figure 30 : Evolution de la
perte de l'algorithme LSTM lors de l'entraînement avec le jeu de
validation et d'entraînement lors du dernier entraînement avec 02
couches de 10101 neurones chacun
La perte quant à elle a énormément
diminué et même si celle du jeu de validation nous a prouvé
qu'on pouvait encore plus entraîner le modèle, le temps
d'entraînement global du modèle qui pouvait prendre un jour ou
deux nous a amenés à nous arrêter à ces
résultats.
A contrario, le modèle MLP était beaucoup plus
performant et donnait des résultats encourageants dès les
premiers entraînements. La précision dépassait souvent les
98% et la perte très faible était inférieure à 1%
pendant tous les entraînements même lorsqu'on changeait les
paramètres du réseau ou les fonctions de pertes et
d'optimisation. Le sur-ajustement n'est pas énorme. Le temps
d'entraînement ici était 10 fois plus rapide. Tout au plus 15
minutes par epoch.
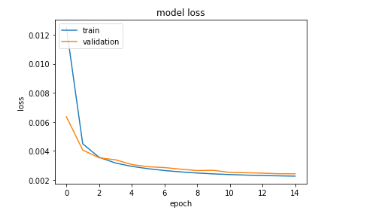
Figure 31 : Evolution de la
perte de l'algorithme lors de l'entraînement avec le jeu d'entrainement
et celui de validation
On observe sur la figure 31 que la
courbe de la perte du jeu de validation est légèrement au-dessus
à celle du jeu d'entraînement. La perte du jeu
d'entraînement diminuait à chaque epoch pour essayer de rattraper
la perte du jeu de validation qui était toujours plus faible.

Figure 32 : Evolution de la
précision de l'algorithme lors de l'entraînement avec le jeu
d'entraînement et le jeu de validation
Les modèles ont
été entraînés plusieurs fois avec des
paramètres différents (nombre de couches, nombres de neurones
dans chaque couche, fonction de perte, optimiseur, etc.) pour pouvoir obtenir
des résultats satisfaisants. Nous ne déduisons que le choix de
l'algorithme impacte énormément sur les résultats mais
aussi le choix des attributs en entrées, leur nombre et celui des
classes à prédire en sortie. Lors de l'entraînement, le
LSTM a été celui qui nous a donné le plus de
difficulté surtout qu'un entraînement de seulement 05 epoch
pouvait prendre une journée et parallèlement il était plus
facile d'essayer plusieurs changements sur le MLP au niveau des
paramètres car plus rapide.
Il faut savoir que nous avons entraîné le LSTM
avec moins de 9000 échantillons par epoch alors que pour le MLP,
c'était environ 25800 échantillons par epoch. Cela
démontre bien à quel point le LSTM était lent même
avec un nombre d'échantillons inférieur.
Une fois que les résultats de l'entraînement
nous satisfaisaient, nous enregistrions le modèle, faisions des
prédictions et évaluions les résultats afin de comparer ce
que le modèle prédit et les valeurs réelles.
Tableau
7 : Comparaison entre les résultats des modèles sur le jeu
de test
|
Précision
|
Perte
|
Temps
|
|
MLP
|
98.75%
|
0.37 %
|
9s
|
|
LSTM
|
99.40%
|
0.19%
|
743s
|
Avec les chiffres obtenus pour chacun le même nombre
d'échantillons, il apparaissait donc clairement que le LSTM était
le meilleur choix pour la prédiction par rapport aux performances de la
machine sur laquelle on travaillait. Cependant nous avons aussi pris en compte
le temps de prédiction de chaque modèle et même si le LSTM
donne de bons résultats, nous avons opté pour le MLP pour
prédire car plus rapide.
Toutefois, si on décide d'effectuer le travail de
prédiction dans le cloud avec des serveurs beaucoup plus performants
avant de renvoyer les résultats à la passerelle, on pourrait
utiliser le LSTM.
| 

