2.2. Identification du type d'objet
Pour le second modèle proposé à
entraîner, les résultats sur les 27 premiers appareils
entraînés semblent concluants, vous pouvez les retrouver en
annexe. La précision dépassait les 97% au moins pour chaque
appareil, ce qui était de bons résultats. Toutefois nous ne
disposions pas des fichiers pcap correspondant à ces appareils, nous
n'avions que des fichiers Excel déjà prétraités. Il
nous fallait générer nos propres fichiers Excel
prétraités pour entraîner et tester notre modèle.
Nous nous sommes servis des fichiers pcap dont nous disposions
sur le trafic bénin concernant la détection du trafic
malveillant. D'abord il s'agissait de trafic généré par
des appareils que le modèle nous supposions ne connaissait pas. Il
fallait le ré-entraîner et donc extraire les attributs dont le
modèle avait besoin.
Nous avons donc écrits un programme en python
d'extraction des paramètres dont nous avions besoin en se basant sur les
travaux déjà faits c'est-à-dire qu'on a
décidé de prendre les mêmes attributs, de leur donner des
valeurs 0 ou 1 et nous les avons extraits des fichiers pcap dont nous
disposions. Nous avons donc obtenu 03 fichiers csv différents (Edimax,
l'ampoule hue bridge et la serrure Somfy).
Nous avons créé trois fichiers Excel
différents correspondants aux trois types d'objets qui avaient
généré du trafic bénin.
Ensuite nous avons entrainé nos modèles et
réalisé les tests. Les trois figures ci-dessous vous montrent les
rapports de classifications des objets que nous avons testés !
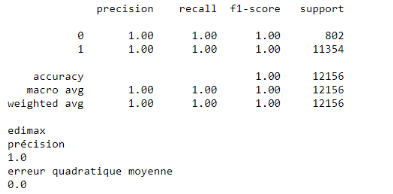
Figure 33 : Rapport de
classification de l'objet connecté Amazon echo

Figure
34 : Rapport de classification de l'ampoule hue bridge

Figure
35 : Rapport de classification de la serrure somfy
L'une des choses que nous pouvons
observer dans les trois figures ci-dessus est que le jeu de données est
déséquilibré. Ensuite ses performances pour la
précision, le score-f1 et le rappel sont déjà très
bons.

Figure 36 : Matrice de
confusion entre x_test et les prédictions
La figure 29 présente la matrice
de confusion entre les prédictions du modèle et les
véritables valeurs. Nous voyons que les modèles ont des
résultats excellents et permettent d'identifier les objets
entraînés et testés.
Les résultats obtenus avec le classifieur MLP sont bons
et nous n'avons pas eu à faire beaucoup de changement sur l'algorithme
lors de l'entraînement.
Toutefois ceci est peut être dû au fait que
c'était déjà un modèle entrainé que nous
avons pris et qu'il avait déjà testé au préalable
certains objets comme par exemple un nommé
« Edimax » (voir Annexe). Il se pourrait donc qu'on ait
fait que ré entraîné des modèles qui avaient
déjà été testé ! Donc je précise
que nous ne disposions pas de beaucoup d'informations sur les
caractéristiques des objets déjà
entraînés.
| 

