1.5 Le processus de découverte de connaissance2
Nous présentons dans cette section un nouveau concept
qui est la découverte de connaissance dans les bases de
données en montrant ses étapes et sa relation avec le data
mining. Ce que nous intéresse -bien sur- dans ce mémoire est le
data mining spatial et la découverte de connaissances spatiales.
Cependant les points discutés dans cette section ne se limitent pas aux
données spatiales, mais concernent plutôt le data mining et la
découverte de connaissances dans leurs sens génériques
indépendamment des type de données sur lesquelles ils
s'appliquent (relationnelles, spatiales, textuelles, multimédia...).
C'est pour cette raison que nous avons choisi dans cette section d'utiliser les
termes data mining et découverte de connaissance sans
la spécification « spatial ».
1.5.1 Définition et étapes
La découverte de connaissances dans les bases de
données, plus connu avec son acronyme anglais KDD
(Knwoledge discovery in databases) est le processus non trivial
d'identification de modèles valides, nouveaux, potentiellement utiles,
et compréhensibles dans les données3 (Fayyad,
Piatetsky-Shapiro and Smyth 1996).
Le terme processus signifie que le KDD se compose de plusieurs
étapes. Ces étapes
peuvent être résumées
en trois phases globales, à savoir : la préparation des
2 Des parties de cette section ont été
publiées dans (Bensalem et Kholladi 2008)

données, le data mining, et l'évaluation des
modèles. Ces phases sont définies brièvement ci-dessous.
Toutefois, les détails ne sont pas l'objet de ce mémoire. Voir
(Han et Kamber 2006) pour une ample explication.
La préparation des données : elle
comprend la collecte, l'intégration, la transformation, le nettoyage, la
réduction, et la description des données.
Le data mining : consiste à appliquer
des méthodes issues de la statistique, et de l'apprentissage automatique
pour découvrir des modèles importants et utiles sur les
données. Parmi les méthodes du DM, la classification, clustering,
les règles associatives, etc. (voir la section 1.4).
L'évaluation des modèles :
consiste à estimer l'erreur et la précision sur les
modèles extraits, et mesurer leur utilité, leur
originalité et leur intelligibilité. Un modèle est
considéré comme une connaissance s'il est utile, inconnu
auparavant, et dépasse un certain pourcentage de précision.
1.5.2 Le sens large et le sens étroit du data
mining(Bensalem et Kholladi 2008)
La préparation des données, et aussi
l'évaluation des modèles (les phases respectivement avant et
après l'application des tâches du DM) sont des phases d'une
importance primordiales. La phase de préparation de données seule
contribue de 75 à 90% à la réussite du projet de fouille
(Pyle 2003). C'est pourquoi il n'est pas question de négliger ces
étapes dans la réalité. Ignorer les phases de
préparation des données ou d'évaluation des modèles
rendrait inutile le DM et nous met en danger d'obtenir des modèles
étrangers à la réalité.
Ce lien étroit entre le data mining et les phases
antérieures et postérieures est la
raison derrière
l'émergence d'un autre point de vue sur sa définition.
Certains
chercheurs comme (Han et Kamber 2006) définissent le data
mining comme
3 Par analogie au KDD, la Découverte de
Connaissance Géographique DCG (en anglais Geographique knowledge
discovery (GKD)) est le processus d'extraction d'informations et de
connaissances à partir

l'ensemble des phases de découverte de connaissances et
non pas seulement la phase d'extraction de patterns4. Par
conséquent, il existe deux sens du terme data mining (voir
Figure 1-3), dont l'un est un sens large : tout le processus de
découverte de connaissances, tandis que l'autre est un sens
étroit : l'étape d'extraction de patterns dans le processus de
découverte de connaissances (Bensalem et Kholladi 2008).
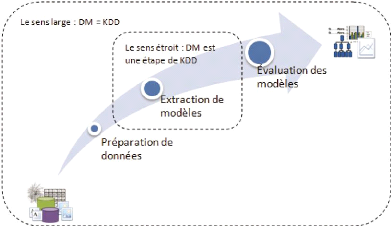
Figure 1-3. La relation entre le data mining et le
KDD
Dans le reste de ce chapitre nous utilisons le terme data
mining dans son sens large car c'est l'étape de collecte de
données5 qui vas nous permettre de montrer la relation du DMS
avec la désambiguïsation des toponymes.
Comme nous avons déjà mentionné, le data
mining spatial est une extension du
data mining classique (c.-à-d.
celui appliqué sur les données
alphanumériques,
relationnelles ou transactionnelles) avec une
adaptation aux données spatiales. Les
des grandes bases de données
géo-référencées (Miller, 2007).
4 Par analogie, Shekhar & Chawla (2003) voient que
le data mining spatial est un processus qui contient toutes les phases de
découverte de connaissances géographiques.
5 La collecte de données est une étape
dans la phase du prétraitement de données.

données spatiales sont donc un concept clé pour le
data mining spatial, et elles le sont également pour la
désambiguïsation des toponymes.
La section suivante donne une vue globale sur ce type de
données et plus particulièrement sur les données
géographiques. Toutefois, on se limite aux aspects que nous
considérons indispensables pour la compréhension du reste du
mémoire. Quelques aspects des donnée géographiques ont
été complètements omis, comme, la représentation
raster et vectorielle, et les relations topologiques; les autres sont
présentées d'une façon plus ou moins
détaillées. Pour des détails plus amples sur les
informations géographiques et des domaines en relation voir (Longley, et
al. 2005).
| 

