1.4.1 Les règles associatives spatiales
Une règle associative est une implication de la forme
« si A alors B » (Gardarin 1999) ou plus formellement notée :
AB, [s%; c%] où A et B sont des ensembles de prédicats spatiaux
et non spatiaux, s% est le support de la règle, et c% est sa confiance
(Han et Kamber 2006). Les règles associatives servent à trouver
des associations entre des propriétés des objets et celles de
leur voisinage (Aufaure, Yeh et Zeitouni 2000).
Exemple
La règle suivante est une règle associative
spatiale :
Est-un(X, «école») ? proche-de(X, «station
de bus») proche-de (X, «marché») [20%; 80%].
Cette règle stipule que 80% des écoles qui sont
proches des stations de bus sont également à proximité des
marchés, et que 20% des données appartenant à un tel
cas.

1.4.2 Les collocations spatiales
Ce sont un type spécifique des règles
d'association. Elles représentent des sous-ensembles d'objets
géographiques qui apparaissent fréquemment proches les uns des
autres dans une carte géo-spatiale (Han et Kamber 2006, Miller 2007).
Ces objets géographiques sont représentés par des
attributs booléens qui indiquent leur présence ou leur absence
dans un endroit dans la surface de la Terre. Des exemples des objets
géographiques booléens incluent les espèces
végétales, les espèces animales, les types de routes, les
cancers, la criminalité, et les types d'activités
économiques (Shekhar, Zhang, et al. 2004).
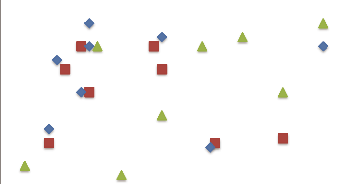
La Figure 1-1 (voir Page 13) montre un ensemble de
données qui consistent à des instances des objets spatiaux
booléens, chacun d'eux est représenté par une forme
distincte. Un examen attentif révèle le pattern de collocation {,
}.
Exemple
Un exemple en écologie : la tâche des
collocations spatiale peut découvrir que le crocodile du Nil et le
pluvier égyptiens vivent dans les mêmes endroits
géographiques.
1.4.3 Le clustering spatial
Le clustering est une méthode de classification
automatique non supervisée qui regroupe des objets dans des classes. Son
but est de maximiser la similarité intraclasses et de minimiser la
similarité interclasses.
La transposition au domaine spatial des méthodes de
clustering s'appuie sur une mesure de similarité d'objets
localisés suivant leur distance métrique. Néanmoins, la
finalité du clustering en spatial n'est pas tant de former des classes
que de détecter des concentrations anormales (par exemple,
détecter un point chaud dans l'étude de criminalité, ou
des zones à risque en accidentologie) (Aufaure, Yeh et Zeitouni 2000).
Voir (Ng et Han 1994) pour plus de détails sur le clustering spatial.

|
Position Y
|
4 3,5 3 2,5 2 1,5 1 0,5 0
|
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5
Position X
Figure 1-1. Exemple de collocations spatiales. Le
pattern {, } est une collocation spatiale
Exemple
Le clustering est utilisé pour déterminer les
"points chauds" dans l'analyse de criminalité et le suivi de maladies.
L'analyse des points chauds "Hot spot analysis" est le processus de chercher
des clusters d'évènements denses et inhabituels à travers
le temps et l'espace. De nombreux organismes de justice pénale dans le
monde profitent des avantages fournis par les technologies informatiques pour
identifier les points chauds de la criminalité afin de prendre des
stratégies préventives, comme le déploiement de
patrouilles dans les zones de points chauds (Shekhar, Zhang, et al. 2004).
| 

