Chapitre 3
Cadre méthodologique
3.1 Introduction
En Apprentissage automatique et dans toute science
expériementale, une connaissance de certaines données anciennes
permettant de prendre des décisions sur des données nouvelles est
necéssaire. Ainsi, dans ce chapitre, nous allons nous
intérésser à la présentation de la base de
données récueillies dans plusieurs hopitaux de la, aussi, par le
trichement de ces données, nous allons montrer comment nous
procédérons à l'analyse de ces dernières d'abord
par le traitement des données.
Nous avons recolté des données dans certains
hopitaux de la Province du Sud-Kivu notamment à l'Hopital
Général de Référence de Kaziba à Kaziba, aux
Centres Hospitaliers BIOPHARM à Bukavu, KAKWENDE à Burhinyi, et
ORANGE à Twangiza dans l'unité médicale de
Gynécologie (image 3.1 ). Ces données sont à
caractère confidentiel et pour y avoir accès, nous avons
été d'abord formé et informé de la
confidentialité des données médicales. Le cas
écheant entraine des peines.
3.2 Type d'informations récuillies
Les enregistrements de cette base de données concerne
des informations des patientes admises dans le service de Gynécologie
dans des hopitaux que nous avons visité. Les données incluent les
variables suivantes :
- Adresse
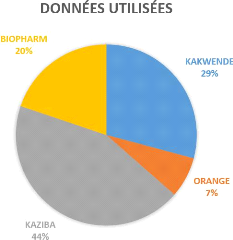
44
FIGURE 3.1 - Diagramme circulaire des données
utilisées
-- Age
- Diagnostic
- Traitement
-- DDS
Le tableau 3.1 montre un exemple d'un extrait de la base des
données. Par exemple, la premiere ligne présente une patiente
habitant à Kakwende âgée de 24 ans où les
premières informations diagnostiquées lors de son admission sont
: Anémie, Paludisme grave. Les traitements qu'elle a suivi sont
une transfusion 450m de sang; ampi3; arthemeter, Gentamiciline 160mg, pendant
19 jours. Sa durée de séjour hospitalier est de 5 jours.
Comme nous pouvons observer dans ce tableau, il ya certaines
informations manquantes. Ce qui est normal car le plus souvent la base de
données souffre de ceci. Nous allons présenter dans la partie
à suivre comment nous nous sommes mis pour faire face à ceci.
3.3 Récolte et Pré-traitement des données
Il a été observé dans plusieurs
structures sanitaires que les informations sont parfois stockuées d'une
manière traditionnelle (c'est-à-dire dans un cahier qui peut soit
se perdre
45
Tableau 3.1 - Exemple de la base de données
|
N°
|
Adresse
|
Age
|
Diagnostic
|
Traitement
|
DDS
|
|
1
|
KAKWENDE
|
24
|
- Anémie
- Paludisme grave
|
Transfusion
450ml de
sang Ampi
3, Arthemeter,
Genta 160mg/l 9 jours
|
5
|
|
2
|
MULI
|
35
|
Avortement incomplet
|
10u d'ocytocine
dans SG 5%
500ml, ampi
3Xsg
|
5
|
|
3
|
CIDAHO
|
-
|
- Paludisme grave - IU
- MAV
|
vinine 1000mg,
puis 500mg,
Aceftriaxène
sg/5jrs Genta
160mg/5jrs
|
7
|
|
4
|
BUDAHA
|
-
|
Paludisme grave
|
Arthemeter 160mg , Ampi genta mebenda,
letro, vit A
100.000U DU IU
|
4
|
|
5
|
CIBINDYE
|
21
|
- Paludisme grave insufisament trété
- UI
-- MAV
|
Quinine 100mg,
puis 800mg,
ceftriaxène sg/
sjs Genta 160mg / 5js
|
6
|
avec toutes les données de l'hopital). C'est ce qui va
faire l'objet de cette section.
3.3.1 Récolte de données
Nous sommes partie des structures sanitaires. De ces registres
manuscrites nous on été données et de ces registres, nous
y avons tirés des informations que nous avons jugées bonnes pour
ce travail.
3.3.2 Pré-traitement des
données
Comme indiqué dans le tableau 3.1, certaines informations
ne sont pas disponibles. Ceci nous a permis de passer à leur
préparation (appelé en anglais data pre-processing).
46
Certaines variables sont quantitatives et d'autres
qualitatives. Nous avons d'abord transformer la variable adresse
par la distance entre le domicile et la structure sanitaire que nous
avons calculé en utilisant le logiciel Google Earth Pro
et ceci en utilisant un milieu connu dans la contrée comme
l'église, l'école, etc., les identifiants tels que les noms sont
remplacés par les numéros pour nous permettre de garder les
données discrètes.
D'après l'hystogramme 3.1, nous constatons que les
données proviennent de 4 hopitaux, c'est ainsi que, l'étiquette
Hopital de Kaziba a été modifiée par 1,
Hopital de Kaziba remplacé par 2, CH Biopharm
par 3 et CH Orange par 4. Ceci pour nous permettre
d'avoir des données numériques pour cette variable aussi
catégorielle Hopital.
Quant à la catégorie Diagnostic
qui est catégorielle, pour avoir des données plus
manipulables, nous sommes passés à la subdivision des diagnostics
en fonction des maladies fréquemment trouvées dans notre base de
données (Grossesse, Infection Urinaire, malformation
artério-veineuse ou mesure de l'acuité visuelle,
Hémoragie, Paludisme Avortement, Infections, Autres
1). Ce qu'il faudra rétenir ici est que, les
avortements qu'ils soient provoqués, volontaires ou des ménaces
d'avortement, nous les avons ainsi classés dans cette variable.
Quant à la catégorie Traitement
réçu qui est aussi catégorielle, nous avons fait
la même chose comme pour le cas précédent, subdiviser les
médicaments par classes thérapeutiques. Nous les avons donc
regroupé de la sorte. On a donc scindé cette colonne en 12
colonnes [17], [21] : Anti-Bactériens,
Anti-palidéens, Ocytociques, Anthelmintiques Intestinaux,
Antispasmodique musculotrope, Analgesiques Non Opioides et Ains,
Antiallergiques / Antianaphylactiques, Vitamines, Cephalosporines, Antiamibiens
et Antigiardiens, Transfusion, Autres.
Malgré cette fusion, nous avons toujours des variables
qui n'ont pas assez d'importance dans la prédiction. Nous avons
utilisé la la fonction python display_feat_imp_rforest (figure 3.2 ).
Quant à la Durée de Séjour Hospitalier,
nous avons pris la Durée de séjour moyenne par hopital. On a
l'histogramme (figure 3.3) suivant pour la variable DDS.
En subdivisant nos différentes catégories, nous
sommes passé de 6 colonnes à 25 colonnes. Et plusieurs variables
sont catégorielles Nous sommes passés pour ce faire de 6
1. Cette colonne conserne uniquement des diagnostiques qui ne
sont pas pris en silo
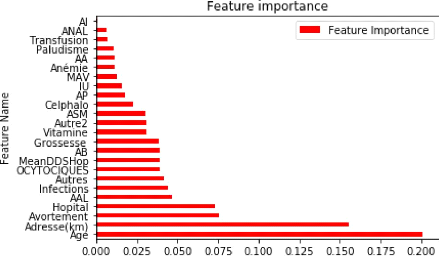
47
FIGURE 3.2 - Importance de chaque variable colonnes à 25
colonnes.
Quant à la gestion des données
manquantes, nous avons utilisé la médiane pour les
données quantitatives (adresse, âge, ) et la
durée de séjour hospitalier nous avons supprimé toutes les
lignes qui n'ont pas de DDS. Ceci pour nous permettre de faire une
préduction plus ou moins bonne où notre basse de données
est passée de 538 lignes à 344 lignes.
Nous avons en suite utilisé la fonction .dropna() de
Python pour supprimer des lignes comptenant des données manquantes
où notre base de données est passée à 333 lignes.
Une base de données parfois contient des enregistrements qui semblent
être les mêmes. Nous avons dans ce sens utilisé la fonction
.drop_duplicates pour nous permettre de supprimer les lignes qui peuvent
être dupliquées.
Nous passons dans ce cas, d'une base de données de 333
à 332 observations.
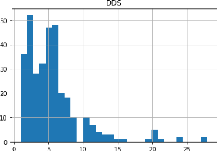
48
FIGURE 3.3 - Histogramme de la Durée de
Séjour Hospitalier
3.3.3 Normalisation et Standardisation des
données
La standardisation des données, également
appelée normalisation, fait référence au processus de
transformation des données brutes en une forme standardisée. La
plupart du temps, cela implique de procéder à la modification des
données afin que ces dernières obtiennent une moyenne de
zéro et un écart-type de un. En d'autres termes, la
standardisation consiste à trier, organiser et
homogénéiser des données suivant certains standards
préalablement définis. [5]
Dans ce travail, nous avons utilisé la fonction
StandardScaler(). Mathématiquement, la normalisation StandardScaler est
:
avec :
- x la valeur qu'on veut standardiser (input
variable)
- u la moyenne (mean) des observations pour cette
feature
- ó est l'ecart-type (Standard Deviation) des
observations pour cette variable (feature)
Cette transformation a été faite juste dans le
cadre de vouloir expirmer nos unités dans la même unité.
Comme c'est le cas par exemple de l'âge en année et de la distance
en kilomètre.
49
3.3.4 Descripition des données
Dans cette partie nous allons présenter dans le tableau
3.2 les différentes corrélations entre les données en
étudiant la moyenne de chaque variable, le maximum, le minimun,
l'écart-type (tableau 3.2), ...
Tableau 3.2 - Description des variables quantitatives non
continues
|
Variable
|
Nombre
|
moyenne
|
std
|
min
|
25%
|
50%
|
75%
|
max
|
|
Adresse(km)
|
332.0
|
3.563193
|
3.995763
|
0.34
|
1.41
|
2.43
|
4.925
|
54.0
|
|
Age
|
332.0
|
26.313253
|
6.725840
|
14.00
|
21.00
|
25.00
|
30.000
|
50.0
|
|
Durée de
Séjour
|
332.0
|
5.539157
|
4.351786
|
1.00
|
2.00
|
5.00
|
7.000
|
28.0
|
|
Mean DDSHop
|
332.0
|
5.54
|
0.49
|
5.0
|
5.0
|
6.0
|
6.0
|
6.0
|
3.3.5 Corrélation entre les données
quantitatives
Pour éviter d'autres problèmes de
surapprentissage, nous avons catégorisé certaines colones en
variables catégorielles comme le diagnostique, l'hopital où les
données ont été tirées ainsi que le traitement
réçu. La corrération de SPEARMAN trouvée pour nos
variables est (figure 3.4) :
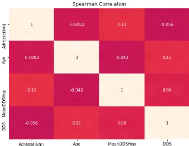
FIGURE 3.4 - Corrélation de spearman entre variables
quantitatives
Selon la figure 3.4, nous constatons que la distance du
ménage et la Durée de Séjour Hospitalier ne
corrélent pas. Par contre, la Durée de Séjour
corrèle avec les autres variables.
50
Ce chapitre étant consacré à la
présentation de la méthode utilisée pour parvenir à
avoir les données utilisables dans l'apprentissage de notre base de
données. Nous avons fait des descentes au sein des hôpitaux
ci-haut énumérés. Les différentes transformations
ont été faites dans le cadre d'avoir une base de données
plus ou moins manipulable. Le chapitre qui suivra sera consacré à
l'apprentissage de la nouvelle base de données avec 332
entrées.
51
| 

