Géomarketing : localisation commerciale multiple( Télécharger le fichier original )par Jérôme Baray Université de Rennes I - Doctorat 2002 |

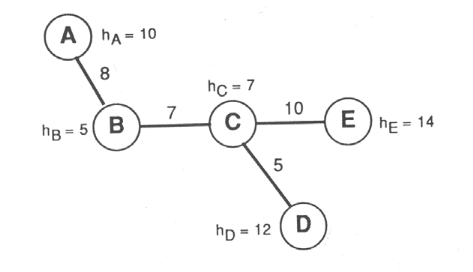
2.2 Les modèles de localisation multiplePouvoir gérer en parallèle plusieurs points de vente, outre l'intérêt économique qu'une telle organisation commerciale représente, permet de réaliser des économies d'échelle sur la promotion, la main d'oeuvre et la distribution. Ce mode de gestion synergique de plusieurs implantations offrant une meilleure représentation géographique conduit également à diminuer le risque lié à l'incertitude de l'environnement économique qui pèse tant sur un magasin individuel. Ces avantages ne sont effectifs que si les localisations des différents points de vente ont été examinées avec soin, l'impact réciproque d'ouverture d'un magasin sur l'activité de l'autre étant alors connu. La problématique de localisation multiple contraint le décideur à trouver la réponse à quatre questions472 473dont : - sur quels marchés faut-il s'implanter ? - combien de points de vente faut-il créer ? - comment évaluer les localisations possibles ? - quelles seront la taille et les caractéristiques des magasins et des sites retenus ? Parmi les instruments capables de répondre à ces questions, on trouve : - les modèles de localisation-allocation474, - le modèle Multiloc475, - la méthode d'analyse de portefeuille476. 472 KOTLER Philippe (1971) Marketing Decision Making : A Model Building Approach, Holt, Rinehart et Winston, NY. 473 CLIQUET G. (1992) Le Management Stratégique des Points de Vente, p.187, Ed. Sirey. 474 GHOSH A., RUSHTON G. (1987) Spatial Analysis and Location-Allocation Models, Van Nostrand, Rheinhold, 1987. 475 ACHABAL D.D., GORR W.L. et MAHAJAN V. (1982) Multiloc: A Multiple Store Location Decision Model, Journal of Retailing, 5-24. 476 MAHAJAN V., SHARMA S. et SRINIVAS D. (1985) An Application of Portfolio Analysis for Identifying Attractive Retail Locations, Journal of Retailing, vol.61, n°5, hiver 1985, 19-34. 2.2.1 les méthodes de localisation-allocation Pour faciliter la recherche d'implantation, différents modèles baptisés modèles de localisation-allocation ont été mis au point. La question fondamentale soulevée par ces modèles est de savoir comment approvisionner ou servir au mieux une aire géographique vaste à partir d'un nombre limité de points de vente. Etant donné que les entreprises ont toutes des moyens financiers limités (coûts d'ouverture et d'exploitation), le nombre maximal de commerces de détail à ouvrir est souvent fixé au préalable et constitue une donnée de base de ce type de modèle. Les modèles de localisation-allocation prennent d'une manière générale l'hypothèse que la probabilité d'un consommateur de fréquenter un point de vente ou de service donné est d'autant plus élevée qu'il en est plus proche, compte-tenu de son niveau d'attractivité. L'analyse tend ainsi à réduire la distance moyenne séparant l'ensemble des consommateurs au point de vente le plus proche de son domicile en maximisant l'accessibilité des localisations. Les modèles de localisation-allocation regroupent d'une manière générale cinq composants de base dont : - la fonction objectif : c'est une fonction qui intègre la notion de distance séparant les consommateurs aux emplacements potentiels des points d'offre ainsi éventuellement qu'une mesure de leur attractivité. Elle quantifie donc l'accessibilité globale des points d'offre vis-à-vis des clients ou bien encore une mesure de la viabilité économique des emplacements. - les points de demande : ils représentent le niveau de la demande concernant un ensemble de marchandises ou de services concernant un certain zonage géographique pouvant être une région, une ville ou un quartier. Les points de demande correspondent en général à des cellules densément peuplées où réside un pouvoir d'achat intéressant pour l'activité considérée. - les emplacements potentiels : ce sont les localisations possibles en termes de disponibilité foncière, coût, accessibilité. - la matrice d'éloignement ou de temps : cette matrice rend compte de la distance géographique ou temporelle séparant les emplacements potentiels des points de demande. Plus précisément, ces distances peuvent être mesurées en pâtés de maison, en distance kilométrique à vol d'oiseau, en terme de cheminement piétonnier, en temps de conduite selon la clientèle considérée et les moyens investis pour la déterminer. - la règle d'allocation : cette règle spécifie de quelle manière les emplacements potentiels seront alloués aux points de demande. On peut par exemple considérer dans le cas le plus simple que chaque client fréquentera le point de vente le plus proche de son domicile, la règle d'allocation étant alors la proximité géographique. Il est possible d'envisager des règles plus complexes à savoir par exemple que la fréquentation de tel ou tel point de vente dépendra de la saison et se reportera sur un autre emplacement à d'autres moments de l'année. Ainsi, compte tenu de ces cinq facteurs décrivant entièrement un modèle de localisation- allocation donné, l'espace commercial peut être apprécié sous la forme d'un réseau constitué de noeuds caractérisés par une certaine demande et/ou pouvant accueillir un point d'offre, les segments liant les noeuds de ce réseau représentant les éloignements. A ce réseau doit être néanmoins associé une fonction objectif qui, exprimé le plus souvent sous forme mathématique, spécifie la manière selon laquelle les clients opteront pour tel ou tel emplacement potentiel. Dans le cas où n'existerait qu'un seul point d'offre à localiser, le problème revient à le placer virtuellement tour à tour à l'un ou à l'autre des emplacements potentiels puis à choisir celui pour lequel la fonction objectif est la plus favorable. Tout se complique si l'on doit localiser plusieurs activités, car le nombre de noeuds étant souvent élevé, il devient pratiquement impossible physiquement, même avec des ordinateurs puissants, de calculer la fonction objectif exhaustivement pour chacune des combinaisons d'emplacements envisageables. Il a donc été développé pour cela des solutions approchées par la mise en oeuvre d'heuristiques qui conduisent, non pas à une série de localisations optimales mais tout au moins à un niveau satisfaisant de la fonction objectif. L'un des premiers modèles de localisation-allocation a été développé par Alfred Weber avec comme problématique la réduction du coût total de transport de matières premières à l'usine et de l'usine au marché. Le modèle p-médian La recherche opérationnelle en matière de localisations d'activités a été l'une des préoccupations majeures pour beaucoup de champs d'applications (logistique, transport, grande distribution, services bancaires, assurance). En particulier, en ce qui concerne la localisation de points de vente ou de services ou même d'entrepôts, une problématique importante est de trouver les localisations pour un nombre p d'activités devant fournir n clients de telle manière que la somme de l'ensemble des distances séparant chaque activité aux clients les plus proches soit minimale. Ce problème lié à un réseau discrétisé bien identifié est classiquement connu sous le nom de p-médian477 478 qui trouve son origine au début du 477 HAKIMI S.L. (1965) Optimum Distribution of Switching Centers in a Communication Network and Some Related Graph Theoretic Problems, Operations Research 13, 462-475. 478 REVELLE C. et SWAIN R. (1970) Central Facilities Location, Geographical Analysis, 2, 30-40. XXème siècle dans les réflexions d'Alfred Weber 479 sur la meilleure manière de placer un centre de production par rapport aux sources de matières premières. En pratique, le problème du p-médian (nommé en abrégé p-MP) est soulevé dans la plupart des réseaux qu'ils soient routiers, aériens ou téléphoniques 480 481. Handler et Mirchandani 482 ont dressé la liste très variée des applications potentielles du modèle p-médian comme les décisions de localisation pour les services d'urgence (police, pompiers, urgences médicales), les réseaux de communication et informatique (localisation des fichiers informatiques sur une série de serveurs identifiés), les applications militaires (centres militaires stratégiques), les activités de service public ou privé (les magasins, centres commerciaux, postes), les activités de transport (arrêts de transport en commun, entrepôts), l'intelligence artificielle et les modèles statistiques (partition de nuage de points). Mais, les applications vraiment centrées sur le domaine de la distribution ont été mises en oeuvre dans les années 1980 avec comme objectif principal d'optimiser le nombre de points de vente et leurs emplacements, connaissant la localisation précise de consommateurs, les coûts de déplacement et éventuellement la demande 483 484 485. Le présent exposé même s'il se concentre sur l'application à la localisation spatiale d'activités, pourrait très bien être directement transposé aux autres domaines précédemment cités. Il existe bien entendu de nombreux autres modèles dits de localisation-allocation que le p- médian, plus ou moins bien adaptés selon les cas. On peut citer parmi eux le modèle p- centré486 qui recherche les p localisations les plus proches de clients: créer p activités, en 479 WEBER A. (1909) Über den Standort der Industrien, Tübingen, Traduction Anglaise de Friedrich (1929) Theory of the Location of Industries, University of Chicago Press, Chicago. 480 DASKIN M.S. (1995) Network and Discrete Location - Models, Algorithms and Applications, John Wiley and Sons, Inc., New York.. 481 GALVAO R.D. (1993) Use of Lagrangean Relaxation in the Solution of Uncapacited Facility Location Problems, Location Science 1, 57-70. 482 HANDLER G.Y. et MIRCHANDANI P.B. (1979) Locations on Networks, MIT Press, Cambridge, MA. 483 GHOSH A. et CRAIG C.S. (1984) A Location Allocation Model for Facility Planning in a Competitive Environment, Geographical Analysis, Vol. 16, n°1, 39-51. 484 McLAFFERTY S.L. et GHOSH A. (1987) Optimal Location and Allocation with Multipurpose Shopping, Spatial. Analysis and Location-Allocation Models, ed. Ghosh Avijit, Rushton Gerard, Van Nostrand Reinhold. 485 CLIQUET G. (1992) Le Management Stratégique des Points de Vente, p.187-191, Ed. Sirey. 486 KARIV O. et HAKIMI S.L. (1979) An algorithmic Approach to Location Problems, Part 1: The p-Centers, SIAM J. Math. 37, 513-538. assignant chaque client à l'une d'entre elles, de telle manière que la distance maximale de n'importe quelle activité à l'ensemble de ses clients soit minimale. Cette problématique, dénommée également minimax, cadre bien avec la localisation d'ambulances ou de stations de pompiers qui doivent être les plus proches possibles des zones d'intervention. Il existe des modèles plus élaborés et plus spécifiques à la localisation d'enseignes commerciales tels que le MCI487 déjà évoqué et associé au modèle Multiloc488, qui intègrent la notion de concurrence, le coût d'ouverture des points de vente ou même les attributs des magasins. Mais, il est vrai que les caractéristiques des points de vente et des clients ne sont pas une information facile à obtenir, tâche d'autant plus ardue que le nombre de ces derniers est élevé. Rassembler des données sur les activités concurrentes s'avère également souvent particulièrement difficile pour le manager. C'est l'une des raisons pour laquelle notre thèse s'est concentrée sur le problème plus simple mais pas plus simpliste du p-médian. De plus, il est fondamental dans la plupart des projets d'ouverture de commerces (ou même d'entrepôts) d'être le plus proche possible de ses clients potentiels et de se mettre en quête d'un emplacement commercial en étant guidé par cette logique, au moins dans un premier temps. A quoi bon tenter en effet de chercher des informations sur une clientèle trop distante pour être conquise par le service offert au sens large du terme ! D'une manière générale, on peut distinguer deux catégories de clientèle489: l'une domiciliée dans une zone proche du point de vente nommée zone de chalandise, est attirée par un point de vente jouant le rôle d'un pôle (attraction polaire). L'autre, ayant un caractère plus aléatoire, est induite par le flux de clientèle passant à proximité du point de vente et interceptée par ce dernier (attraction passagère). Les points de vente eux-mêmes selon le produit ou le service proposés se rangent 487 NAKANISHI M. et COOPER L.G. (1974) Parameter Estimate for Multiplicative Competitive Interactive Model - Least Squares Approach, Journal of Marketing Research, 11, 303-311. 488 ACHABAL D.D., GORR W.L. et MAHAJAN V. (1982) Multiloc: A Multiple Store Location Decision Model, Journal of Retailing, 5-24. 489 CLIQUET G. (1997) Attraction Commerciale, Fondement de la Modélisation en Matière de Localisation Différentielle, Revue Belge de Géographie, 121ème année, p. 62-65. dans l'une ou l'autre des catégories selon leur capacité à capter le flux de clients circulant à proximité (ex.: bureau de poste, agence bancaire, distributeur automatique) ou à attirer "à distance" les consommateurs selon un principe similaire à celui de la gravitation étendue au commerce de détail par Reilly490 (ex.: agence d'intérim, supermarché, charcuterie, papeterie)491. Certaines activités possèdent un caractère mixte et comptent donc les deux types de clientèle évoqués avec éventuellement une certaine prépondérance pour l'un ou pour l'autre (ex.: bar-café-brasserie, épicerie, pâtisserie). Notre recherche visera à considérer la clientèle de points de vente ou de services jouant plutôt sur le principe de l'attraction polaire. Nous supposerons la localisation de cette clientèle au sein de zones de chalandise connue, par exemple identifiée par les adresses du domicile avec l'hypothèse que les clients seront d'autant plus fidèles (ou satisfaits) que le point de vente leur est proche. Les termes de "points de vente" et de "clients" peuvent être pris au sens large à savoir que le raisonnement qui suit s'appliquerait de la même manière à un service de livraison à partir d'entrepôts (les points de services) devant acheminer un produit vers des centres de distribution ou vers des détaillants (ex: services de tri postal et bureaux de poste; grossistes en boissons et cafés-bars-brasseries). Bien que le modèle p-médian ne s'appuie que sur la notion de distance (ou de coût de déplacement) entre clients et sites potentiels d'activité, compiler les données sur les localisations de ces différents acteurs pour trouver une localisation proche de l'optimal demande beaucoup d'efforts et de temps de calcul ainsi que nous le constaterons plus loin. 2.2.1.1 Formulation mathématique du p-MP La résolution du problème p-médian n'échappe pas à sa nécessaire rationalisation consistant à l'exprimer en langage mathématique: le p-MP sous-entend l'existence d'un réseau constitué 490 REILLY W. J. (1931) The Law of Retail Gravitation, W. Reilly ed, 285 Madison Ave, New York, NY. 491 CLIQUET G. (1997) Attraction Commerciale, Fondement de la Modélisation en Matière de Localisation Différentielle, Revue Belge de Géographie, 121ème année, p. 66. de noeuds ou points et de liens, ces derniers étant associés à un coût de déplacement représenté par la distance di,j (distance du point i au point j). L'objectif est ainsi de trouver un emplacement optimal pour p activités au sein des noeuds du réseau en cherchant à minimiser la distance totale entre les p activités et les clients qui leur sont associés (un client est associé à une activité s'il se trouve plus proche de cette dernière que de toutes les autres). Les modèles p-médian pondérés et non-pondérés se différencient par le fait que les premiers tiennent compte de la demande ai au point i avec l'objectif de minimiser la somme totale des distances pondérées par la demande. D'une manière générale, la formulation mathématique du p-MP s'écrit de la façon suivante492: Minimiser i j ai dij xij représente la fonction objectif, (1) avec i xij = 1, i, assure que tous les clients sont assignés à une activité et une seule, (2) xij yj, i, j empêche d'assigner un client à une activité si elle n'est pas ouverte, (3) yj = p, le nombre total d'activités est p, (4) j xij, yj {0,1}, i, j nature binaire des variables xij, yj (5) où ai : la demande au noeud i, di,j : la distance du noeud i au noeud j, p : le nombre d'activités à localiser, xi,j = 1, si le noeud i est assigné à l'activité j et 0 autrement, yj = 1, si l'activité j est ouverte et 0 autrement. 492 BEAUMONT J.R. (1987) Location-Allocation Models and Central Place Theory, Spatial Analysis and Location-Allocation Models, ed. Ghosh Avijit, Rushton Gerard, Van Nostrand Reinhold. Cette formulation suppose que tous les noeuds du réseau ont la qualité de localisation potentielle pour les activités et que les p activités seront localisées en des points distincts. Dans le cas non-pondéré, les demandes ai sont toutes égales à 1. Le problème p-MP est réputé appartenir à la classe des problèmes connus comme étant NP- complets493: ses solutions issues d'algorithmes linéaires deviennent insolubles au fur et à mesure que le nombre des variables (activités et clients) augmente avec une progression exponentielle de la taille du problème. En effet, selon une logique d'analyse combinatoire, le nombre de solutions à examiner est en fonction de n, le nombre de noeuds, et p, le nombre d'activités à placer: n! p! (n - p)! ce qui signifie par exemple que si l'on devait simplement chercher à placer 15 points de vente au milieu d'un réseau de 100 clients et que l'on dispose d'un ordinateur capable de réaliser un million d'opérations par seconde, le temps requis pour parvenir à la solution optimale serait de huit millénaires494 ! Dans le cas où l'on voudrait solutionner tous les problèmes p-médian (p variant de 1 à p activités à placer) si on ne connaît que le nombre maximum p d'activités à placer, le nombre de combinaisons à étudier serait alors de: n n! - =2n -1 j = 1 p! (n j)! Il existe donc un grand nombre d'heuristiques pour trouver une solution acceptable au problème p-Médian malgré le fait que toutes ces solutions ne convergent que vers des optima locaux et non vers une solution globale et qu'il ne soit pas possible a priori de connaître le niveau d'optimalité de cette solution. Dans les algorithmes de résolution fondamentaux, on trouve l'algorithme flou, l'algorithme de recherche de voisinage, une heuristique de 493 KARIV O et HAKIMI S.L. (1979) An Algorithmic Approach to Network Location Problems, Part 2: The p- median", SIAM Journal of Applied Mathematics 37, 539-560. 494 DASKIN M.S. (1995) Network and Discrete Location - Models, Algorithms and Applications, John Wiley and Sons, Inc., New York. substitution495 et ses variantes496, cette dernière catégorie étant l'une des plus robustes selon Densham et Rushton497. 2.2.1.2 Les algorithmes de résolution du p-MP Mais d'une façon générale, les heuristiques se rangent en deux classes498: les algorithmes de construction qui permettent de rechercher des localisations avec un degré d'optimalité faible et les algorithmes d'amélioration destinés comme leur nom l'indique, à améliorer les résultats fournis par les algorithmes de construction. Alors que l'algorithme flou est du type construction, l'heuristique de substitution et l'algorithme de recherche de voisinage ont une approche d'amélioration. Pour clarifier la signification de ces termes, nous passerons en revue le principe de mise en oeuvre de ces heuristiques. Localisation d'une activité unique dans la problématique du p-MP : le 1-médian Examinons tout d'abord la recherche de solutions dans le cas le plus simple, la localisation d'une activité unique ou problème 1-médian. Dans le cas où, plus de la moitié de la demande ai est localisée en un point, une des solutions optimales consiste à placer l'activité en ce i noeud. Et si ce noeud concentre plus de la moitié de la demande, cette localisation est alors la localisation optimale unique499. 495 TEITZ M.B. et BART P. (1968) Heuristic Methods for Estimating the Generalized Vertex Median of a Weighted Graph, Operations Research 16, 955-961. 496 GOODSCHILD M.F. et NORONHA V. (1983), Location-Allocation for Small Computers, University of Iowa, Monograph N°8. 497 DENSHAM P.J. et RUSHTON G. (1992) A More Efficient Heuristic for Solving Large p-median Problems, Papers in Regional Science: The Journal of the RSAI 71/3, 307-329. 498 GOLDEN B, BODIN L., DOYLE T. et STEWART Jr. (1980) Approximate Travelling Salesman Algorithms, Operations Research, 28, 694-711. 499 DASKIN M.S. (1995) Network and Discrete Location - Models, Algorithms and Applications, John Wiley and Sons, Inc., New York. La résolution du cas le plus général a été donnée par Goldman500. Elle consiste à choisir aléatoirement un noeud d'extrémité de branche sur le réseau et si au moins la moitié de la demande n'est pas fixée en ce noeud à le supprimer (ainsi que le lien) et à reporter sa demande sur le noeud suivant. Si l'un des noeuds du réseau concentre plus de la moitié de la demande, alors l'activité est à localiser en ce point et on peut calculer la distance totale pondérée par la demande. Un exemple concret plus explicite selon Daskin501 est donné par le réseau suivant qui compte une demande totale de 48 (la demande au point x est représenté par hx) :
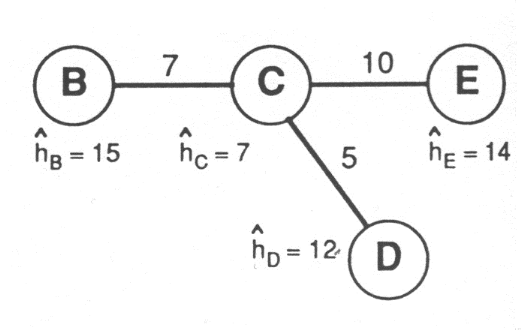
Fig. 2.7 - Méthode de résolution du 1-médian : étape 1 Aucun des noeuds ne compte plus de la moitié de la demande. Si l'on considère donc le point A dont la demande égale à 10 est inférieure à 48/2 = 24, on reporte cette demande sur le point B en supprimant le point A, demande qui atteint alors 5 + 10 = 15: 500 GOLDMAN 1J (1971) Optimal Center Location in Simple Networks; Transportation Science 5, 212-221. 501 DASKIN M.S. (1995) Network and Discrete Location - Models, Algorithms and Applications, John Wiley and Sons, Inc., New York.
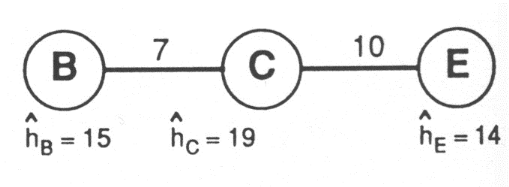
Fig. 2.8 - Méthode de résolution du 1-médian : étape 2 La demande en B égale à 15 est toujours inférieure à 24 (comme celle de tous les autres points). Supprimons alors le point D où la demande, 12, est la plus faible en la reportant sur le point adjacent C:
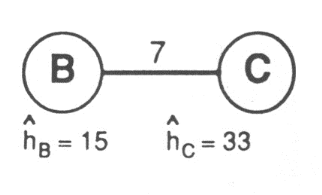
Fig. 2.9 - Méthode de résolution du 1-médian : étape 3 Comme les demandes de B, C et D sont toujours inférieures à 24, supprimons E et reportons sa demande sur C. On s'aperçoit alors que la demande de C égale à 33 est supérieure à la demande totale divisée par deux (24), ce qui signifie que C est le point optimal sur lequel doit être placée l'activité:
Fig. 2.10 - Méthode de résolution du 1-médian : étape 4 L'algorithme flou L'algorithme flou consiste tout simplement à localiser les activités sur le réseau une par une, puis à utiliser une procédure de voisinage ou de substitution pour optimiser les localisations. Dans un premier temps, on choisit donc le meilleur emplacement pour la première activité ce qui est facile si on calcule la fonction objectif pour chaque noeud envisagé en retenant le noeud pour lequel cette fonction objectif est la plus faible. Ensuite, on localise un deuxième point envisageant chaque noeud (sauf celui déjà occupé) et en assignant à la localisation précédente, les noeuds qui lui sont les plus proches comparés au noeud examiné. La fonction objectif est calculée de la même manière et on retient toujours comme second emplacement le noeud pour lequel cette fonction possède la valeur minimale. Ce processus est réitéré autant de fois qu'il y a d'activités à localiser. Ainsi, l'organigramme de cette procédure se résume à: Localiser la première activité en utilisant l'énumération totale Avons-nous p activités ? Non Localiser l'activité suivante en utilisant l'énumération totale et en fixant les autres localisations Oui Algorithme d'amélioration par substitution ou de voisinage Fin Fig. 2.11 - Organigramme de l'algorithme flou Résolution par les multiplicateurs de Lagrange502 Une méthode de résolution appartenant aux algorithmes de construction, plus classique mais moins performante, est représentée par les contraintes du p-médian relaxées à l'aide des multiplicateurs de Lagrange. Elle permet de transformer un problème contraint en un problème sans contraintes503. Nous la mentionnons pour mémoire. Appliquée à la relation (2) de la formulation générale du problème du p-médian, une relaxation par les multiplicateurs de Lagrange devient: 502 DE LAGRANGE Louis, mathématicien français né en 1736, mort en 1813. 503 DASKIN M.S. (1995) Network and Discrete Location - Models, Algorithms and Applications, John Wiley and Sons, Inc., New York. Minimiser i j ai dij xij + i i [1 - j xij ] (1) = i j ( ai dij + i ) xij + i i avec i xij = 1, i, (2) xij yj, i, j, (3) yj = p, (4) j xij, yj {0,1}, i, j (5) Les coefficients i considérés comme fixes sont appelés multiplicateurs de Lagrange et la nouvelle fonction objectif à minimiser devient (1). En appliquant une relation identique à la relation (3) de la formulation générale du p-médian, on démontre que les multiplicateurs de Lagrange peuvent être calculés à partir d'une formule récurrente, avec des multiplicateurs initialisés à une valeur quelconque: n in+1 = max { 0, in - tn (Xij - Yjn)} n avec t n = (UB - Ln) ( X j n ij i j - Y n )2 où tn : le pas de la procédure de Lagrange à la nième itération, n : une constante généralement prise égale à 2, UB : (upper bound) la plus petite limite supérieure de la fonction objectif, Ln : la fonction objectif de Lagrange (1) ci-dessus, Yjn : la valeur optimale de la variable de localisation Yj à la nième itération. La méthode de résolution du p-médian par les multiplicateurs de Lagrange a été récemment utilisée dans des travaux de recherche en informatique pour déterminer sur quels serveurs en réseau il était préférable d'implanter les informations pour obtenir des traitements de calcul plus rapides au niveau de l'ensemble504. Le même algorithme a été utilisé dans le même esprit pour améliorer la configuration des réseaux de communication505. Une méthode de résolution générale et (presque) exacte des problèmes de localisation développée par Homberg, Rönnqvist et Yuan fait appel à l'algorithme par les multiplicateurs de Lagrange en parallèle d'une procédure par séparation et évaluation (Branch and Bound en anglais) dans le cas où chaque noeud de demande est assigné à une activité et une seule506. La procédure par séparation et évaluation est une méthode d'énumération implicite qui repose sur le principe de diviser les solutions en paquets. Plus précisément, on divise l'ensemble des solutions possibles d'un problème de localisation-allocation (ou plus généralement d'optimisation combinatoire) en sous-ensembles de plus en plus petits afin d'isoler dans l'un de ces sous-ensembles une solution optimale. Le parcours est représentable par un arbre avec comme racine le problème de départ et toutes les combinaisons possibles, les branches représentant les sous-problèmes correspondant à des sous-ensembles de toutes les combinaisons admissibles. L'exploration de l'arbre se fait vers des niveaux d'optimalité des solutions obtenues croissantes et la partition des ensembles de solutions (destinée à créer des branches) est produite en allouant un ou plusieurs clients d'une activité à une autre si l'on considère la solution explorée en cours. Cette réallocation des clients se fait généralement par un processus aléatoire. La recherche de Homberg, Rönnqvist et Yuan montre que l'utilisation individuelle de la procédure par séparation et évaluation (grâce à l'algorithme commercial 504 CHURCH R.L. et SORENSEN P.A. (1995) A Comparison of Strategies for Data Storage Reduction in Location-Allocation Problems, National Center for Geographic Information and Analysis, Technical Report 95-4, University of Santa Barbara, California. 505 GUPTA R. (1996) Problems in Communication Network Design and Location Planning; New Solution Procedures, PhD, Graduate School of the Ohio State University. 506 HOLMBERG K., RÖNNQVIST M. et YUAN D. (1999) An Exact Algorithm for the Capacitated Facility Location Problems with Single Sourcing, European Journal of Operational research 113, 544-559. CPLEX) met jusqu'à 5 heures pour résoudre un problème de 30 activités à localiser en prenant en compte la position de 300 clients alors que la méthode associant cet algorithme avec les multiplicateurs de Lagrange ne met qu'une heure pour obtenir des solutions généralement meilleures. On le voit, les meilleurs algorithmes de résolution même s'ils tournent sur des ordinateurs puissants (un ordinateur Sun Sparc 20/HS151 pour cette recherche) n'arrivent à résoudre dans un temps raisonnable que des problèmes de localisation-allocation de quelques centaines de noeuds. Dans certains cas (1 cas sur 71 cas étudiés), l'algorithme de Homberg, Rönnqvist et Yuan ne réussit cependant pas à trouver une solution optimale et donc cet algorithme ne peut être qualifié de méthode de résolution exacte. Résolution par la méthode des algorithmes génétiques Les algorithmes génétiques se fondent sur la théorie générale de l'évolution de Darwin selon laquelle les espèces vivantes progressent en organisation et en complexité par la simple sélection naturelle de leurs caractères génétiques les plus performants lors des phases de reproduction. Ainsi, ce principe qui optimiserait la configuration génétique des systèmes vivants face à un environnement hostile serait tout aussi bien capable de traiter des problèmes d'optimisation beaucoup plus généraux tels que la résolution des problèmes d'optimisation ou des modèles de localisation-allocation. Les premières applications à ces cas datent des années 70 507 508. De manière analogue pour ces modèles, un individu ou une solution se caractérise par son empreinte génétique ou sa structure de données. Les opérations génétiques de croisement et de mutation modifient les données ou chromosomes de chaque individu ce qui permet en théorie de parcourir tout l'éventail des solutions possibles. L'algorithme génétique va donc à chaque nouvelle génération créer de nouvelles solutions mais aussi en détruire ainsi 507 HOLLAND J.H. (1975) Adaptation in natural and artificial systems, Ann Arbor: University of Michigan Press. 508 GOLDBERG D.E. et LINGLE R. Jr. (1985) Alleles, loci and the travelling salesman problem, Proceedings of an International Conference on Genetic Algorithms, J.J. Grefenstette (Ed.), LEA Pub, p 154-159. que le décrit la théorie de la sélection naturelle509. La performance de l'individu ou l'optimalité de la solution se mesure par le niveau de sa fonction objectif. Dans un premier temps, l'algorithme génétique va générer des solutions de manière aléatoire, puis il va les laisser évoluer jusqu'à obtenir les meilleures solutions possibles. Pour utiliser avec succès un algorithme génétique, il est nécessaire : - de réussir à coder les solutions en des ensembles de chromosomes, - de partir d'une population ou de solutions de base, - de disposer d'une fonction objectif qui va mesurer le niveau d'optimalité de chaque solution, - de décider comment sélectionner les chromosomes les plus performants, - de décrire les opérateurs génétiques ou le mode d'échange des données, - de spécifier les paramètres de l'algorithme tels que taille de la population initiale, probabilités de croisement et de mutation, - de donner un critère d'arrêt de l'algorithme. Le codage d'un modèle p-médian est une succession binaire de 0 et de 1 correspondant à l'absence ou à la présence d'un point de vente dans la liste des noeuds du réseau. Les caractéristiques des solutions de départ et leur nombre (population de départ) peuvent être tirées au hasard ou bien déterminées par une autre heuristique du modèle p-médian. Dans ce dernier cas, l'algorithme génétique constituera une procédure d'amélioration de la solution. La fonction objectif du p-médian nous conduisait à minimiser la quantité : ai dij xij i j L'évaluation la plus simple de la force de l'individu ou optimalité de la solution consiste à prendre l'inverse de la fonction objectif que l'on cherchera à maximiser : 509 HOLLAND J.H. (1992) Les algorithmes génétiques, revue Pour la Science, No 179, Sept. 1992, p. 44-51. 1 / ai dij xij i j La sélection ou reproduction va déterminer à partir de quels individus on va construire la génération suivante. On utilise assez souvent la roue de Goldberg510 qui consiste à tirer les solutions sur une roue de loterie sur laquelle les individus sont représentés sur une surface proportionnelle à leur force ou optimalité. De cette façon, les individus les plus forts auront à l'étape ultérieure de croisement et de mutation, une représentativité plus forte avec un nombre de copies plus importantes au sein de la population. Le croisement consiste alors à échanger des paquets de données (des suites de 0 et de 1 découpées dans la solution) entre des paires d'individus. La mutation consiste, elle, à basculer dans notre cas un 0 en 1 ou réciproquement un 1 en 0 en de très rares occasions selon une probabilité de mutation fixée à l'avance. Cette procédure permettrait d'explorer tous les recoins de l'espace des solutions en évitant d'emprisonner la recherche dans un maximum local (ou un minimum pour la fonction objectif). En pratique, les chromosomes sont tirés de façon aléatoire et sont remplacés par un chromosome d'une autre valeur toujours prise aléatoirement. Enfin, le nombre maximal de générations correspond au nombre d'itérations que l'on se fixe pour stopper la procédure. Tous les paramètres de l'algorithme génétique sont généralement fixés empiriquement. Une population de 20 à 1000 individus qui en général reste stable au fur et à mesure des générations, satisfait généralement la résolution de tous les problèmes. Une taille de population trop faible ne permettra pas d'explorer tous les champs de solutions possibles alors qu'une taille très élevée engendrera un nombre d'opérations importantes qui pourra nuire à la rapidité d'exécution. Les valeurs de moyennes des probabilités de croisement oscillent entre 0,65 et 0,9 : une probabilité élevée favorisera l'examen d'un grand nombre de solutions, mais une probabilité de croisement excessive risque d'emprisonner la recherche dans des maxima 510 GOLDBERG D.E. (1991) Genetic Algorithms, Addison-Wesley, New York. locaux. Une certaine probabilité de mutation511 est au contraire nécessaire pour réussir de temps en temps à générer des individus hors-normes qui sont susceptibles de constituer des super-solutions au problème. Ces solutions bien meilleures ne sauraient dans certains cas être générées par des simples transformations de croisement. Il reste que la probabilité de mutation doit rester faible, de 0,001 à 0,2 voire 0,1 à 10 pour ne pas entraver le processus normal de reproduction et d'empêcher l'algorithme de converger vers un optimum512. Outre ces paramètres fixés empiriquement, il n'existe pas à l'heure actuelle de critère de convergence efficace pour stopper le processus dès qu'une solution intéressante est atteinte. Il est donc indispensable de déterminer au départ le nombre de générations ou d'itérations au bout duquel on arrête l'algorithme513. Les algorithmes génétiques sont, d'une façon générale, particulièrement recommandés pour les problèmes pour lesquels n'existe aucune autre méthode de résolution ou bien pour lesquels les méthodes de résolution existantes n'offrent que des solutions approchées comme les modèles de localisation-allocation514. Les algorithmes d'amélioration Dans un second temps, on utilise l'algorithme d'amélioration de voisinage515 ou celui de substitution516. 511 GOLDBERG D.E. (1994) Algorithmes Génétique, Exploration, Optimisation et Apprentissage Automatique, Editions Addison-Wesley, 1994. 512 AURIFEILLE J.M. (2001) Les algorithmes génétiques, Conférence invitée à l'IREIMAR, Institut de Recherche Européen sur les Institutions et les Marchés, CNRS, Mars 2001. 513 AURIFEILLE J.M. (2001) Conjoint fuzzy vs non-fuzzy clustering : some empirical evidence using a genetic algorithm optimization, Actes du 7ème congrès international SIGEF, sept. 2001. 514 ROBERT-DEMONTROND P., THIEL D. (2002) Algorithmes génétiques et stratégies spatiales des firmes de distribution, in Stratégies de Localisation des Entreprises Commerciales et Industrielles : De Nouvelles Perspectives, G. Cliquet et J-M. Josselin éd., De Boeck Université, Bruxelles. 515 MARANZANA F.E (1964) On the Location of Supply Points to Minimize Transport Costs, Operational Research Quarterly, 15, 261-270. 516 TEITZ M.B. et BART P. (1968) Heuristic Methods for Estimating Generalized Vertex Median of a Weighted Graph, Operations Research, 16, 955-961. · L'algorithme de recherche de voisinage Dans l'algorithme de voisinage, on considère le voisinage de chaque localisation d'activité, c'est-à-dire l'ensemble des noeuds qui lui sont le plus proche et on calcule dans ce voisinage une localisation améliorée par l'algorithme du 1-médian vu précédemment. L'algorithme de voisinage peut être utilisé comme algorithme de construction si l'on démarre la recherche de localisation avec une configuration aléatoirement choisie. · L'heuristique de substitution On procède à l'heuristique de substitution en supprimant tout à tour chacune des p activités déterminées dans la procédure initiale de localisation, ensuite en recherchant le meilleur autre emplacement pour cette activité supprimée par une simple énumération et en calculant la fonction objectif correspondante. La recherche d'une valeur plus faible de la fonction objectif parmi celles calculées en recherchant une nouvelle localisation pour chaque activité déjà déterminée donnera éventuellement une configuration améliorée par rapport à celle obtenue à l'étape précédente. Les variantes des algorithmes d'amélioration La variante très proche de l'algorithme précédent, donnée par Goodschild et Noronha517, revient à identifier le noeud d'activité et le noeud libre dont la substitution offre la fonction objectif la plus basse. Si la fonction objectif a tendance à diminuer par rapport à la solution trouvée initialement, alors ce nouvel emplacement peut être considéré comme un optimum local. Une autre variante des algorithmes d'amélioration consiste à travailler au niveau global, puis régional518. Considérons l'ensemble des noeuds occupés par une activité S et celui des noeuds 517 GOODSCHILD M.F. et NORONHA V. (1983), Location-Allocation for Small Computers, University of Iowa, Monograph N°8. 518 DENSHAM P.J. et RUSHTON G. (1992) A More Efficient Heuristic for Solving Large p-median Problems, Papers in Regional Science: The Journal of the RSAI 71/3, 307-329. non occupés (V-S) avec V l'ensemble de tous les noeuds. Si un nouveau noeud est mis dans l'ensemble S, on appelle cette procédure ADD alors que si on retire un noeud de l'ensemble S, cette procédure est nommée DROP. Dans la première phase globale, on réalisera une séquence de DROP et d'ADD jusqu'à ce que l'on ne trouve plus d'amélioration à la fonction objectif. Dans la phase locale, on décomposera le réseau en p problèmes 1-médian que l'on résoudra par l'algorithme de voisinage explicité précédemment. Enfin, la procédure "Tabu" (mot anglais signifiant tabou) mise au point par Rolland, Schilling et Current519 utilise un temps dit tabou, mesuré en nombre d'itérations, durant lequel il est interdit de pratiquer une procédure DROP sur un noeud incorporé à l'ensemble S par une procédure ADD (le compteur d'itérations est initialisé dès que ce noeud est placé dans l'ensemble S). Cette durée "taboue" fixe, aléatoire ou dynamique durant le fonctionnement de l'algorithme doit être écoulée pour avoir le droit à nouveau de supprimer le noeud de l'ensemble S. Ce programme d'amélioration semble enregistrer de meilleurs résultats que les heuristiques déjà citées. Les auteurs ne s'attachent cependant à démontrer l'efficacité de l'algorithme par rapport aux autres méthodes qu'en se fondant sur un cas particulier. En tous les cas, l'algorithme flou correspond assez bien à la logique d'implantation des chaînes de magasins : celui-ci cherche en effet dans la procédure à localiser les points de vente les uns après les autres de la même manière qu'un manager voudra la plupart du temps en pratique les ouvrir graduellement avec une mise en puissance progressive et non d'une manière simultanée. De plus, dans un deuxième temps, l'algorithme d'amélioration s'identifie en quelque sorte à la phase de réorganisation des points de vente déjà créés qui est marquée par exemple soit par la suppression d'un point de vente non rentable (que se passe-t-il si je 519 ROLLAND E., SCHILLING D.A. et CURRENT J.R. (1996) An Efficient Tabu Procedure for the p-Median Problem, European Journal of Operational Research, 329-342. supprime un magasin ? algorithme de substitution), soit par la redistribution au niveau local des localisations ( algorithme de voisinage) . 2.2.2 Le modèle Multiloc Supposons que l'on veuille placer r points de vente parmi un éventail de n emplacements possibles. Le modèle Multiloc520 est en fait une extension du modèle MCI qui, d'une manière générale, considère q attributs d'attractivité de ces magasins Aijk, attributs susceptibles de prendre ík valeurs: par exemple, on a pour k=1 un attribut Aij1 qui peut être la distance (í1 =1); pour k=2, Aij2 peut signifier la taille du magasin qui peut être petite, moyenne ou grande (í2 =3 et valeurs discrètes),... Si l'on considère le nombre de combinaisons des attributs d'attractivité, le nombre de "designs" ou de configurations possibles que peuvent prendre les magasins est : L = í1 í2 ...íq La fonction objectif qui doit maximiser le profit est la suivante: m n n L Max Z = C j Ei Pij - Fjl X jl i =1 j =1 j =1 l =1 avec Z : le profit Ei: Le chiffre d'affaires total par groupe i sur le marché Fjl: les coûts fixes d'un magasin du plan l au site j Cj: un coefficient multiplicateur Xjl = 1 si un magasin avec le design l est implanté sur le noeud j et égale à 0 sinon j: la localisation considérée qui varie de 1 à n l: le design considéré qui varie de 1 à L on a aussi les conditions suivantes sur le nombre r de points de vente à localiser : 520 ACHABAL D.D., GORR W.L. et MAHAJAN V. (1982) Multiloc: A Multiple Store Location Decision Model, Journal of Retailing, 5-24. n L X jl = r j = 1l = 1 L et X jl 1 j=1,...,n l =1 La probabilité qu'un consommateur au point i fréquente un magasin particulier au point j est alors: Pij L q n ( Akl X jl) / L q ( Akl X jl) n + s q ( Akl ) = ijkl
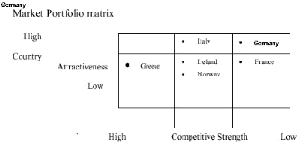
ijkl + ijkl l =1 k =1 j =1l =1 k =1 j = n + l k =1 Comme pour le modèle p-médian ou pour le modèle MCI, il n'est pas possible de résoudre le modèle Multiloc par la complète énumération des combinaisons d'emplacements possibles. En effet, si l'on doit placer r points de vente au niveau de n emplacements possibles avec L configurations de magasin possibles, le nombre de solutions à examiner est: W Lr n! = r! (n - r)! De la même manière que pour les modèles p-médian ou MCI précités ou n'importe quel problème d'analyse combinatoire de ce type, l'une des méthodes les plus réputées pour résoudre le modèle Multiloc est sans conteste encore l'algorithme de substitution de Teitz et Bart 521 mis en pratique dans la localisation d'agences bancaires 522. Une alternative consiste à employer l'échantillonnage aléatoire développé par McRoberts523. Le nombre de solutions h tirées d'une manière aléatoire à examiner pour qu'il y ait une 521 TEITZ M.B. et BART P. (1968) Heuristic Methods for Estimating the Generalized Vertex Median of a Weighted Graph, Operations Research 16, 955-961. 522 CORNUEJOLS G., MARSHALL L.F. et NEMHAUSER G.L. (1977) Location of Bank Accounts to Optimize Float: An Analytic Study of Exact and Approximate Algorithms, Management Science, 23 (1pril), 789-810. 523 Mc ROBERTS K.L. (1971) A Search Model for Evaluating Combinatorially Explosive Problems, Operations Research, 19, 1331-1349. probabilité y qu'au moins l'une des p meilleures configurations possibles soit dans cet échantillon est de: 1 h = W 1- (1- y) pW Ainsi, si l'on veut avoir 99 % de chance de trouver 1 % des meilleures configurations d'emplacements et de designs possibles dans un échantillon aléatoire, il faudra un ensemble de 460 combinaisons tirées au hasard. Si l'on a 7 magasins (r = 7) de 3 designs possibles (L = 3) à localiser sur 35 localisations potentielles (n = 35), il y a 14,7 milliards d'alternatives. La méthode de l'échantillonnage aléatoire revient donc si l'on se satisfait de la probabilité d'avoir 99 % de chance de tomber sur les 1 % des configurations les plus optimales, à tirer 460 combinaisons parmi les 105 configurations possibles d'emplacement et de design (7 emplacements x 3 designs possibles), puis à sélectionner le meilleur emplacement et le meilleur design possibles en calculant la fonction objectif qui doit être la plus importante possible524. 2.2.3 La méthode d'analyse de portefeuille La méthode d'analyse des portefeuilles issue du monde de la finance525 puis popularisée par les consultants de cabinets tels que le Boston Consulting Group (BCG), Mc Kinsey ou Arthur D. Little526 a été adaptée pour cibler les localisations les plus intéressantes ou comparer plusieurs localisations entre elles527. En variations verticales, on trouve l'attrait du secteur (atractiveness en anglais) alors qu'en horizontal, on a la force concurrentielle du réseau de points de vente (competitive strenght). 524 ACHABAL D.D., GORR W.L. et MAHAJAN V. (1982) Multiloc: A Multiple Store Location Decision Model, Journal of Retailing, 5-24. 525 MARKOWITZ H. (1952) Portfolio Selection, Journal of Finance, Vol. 7, mars, p.77-91. 526 KOENIG G. (1990) Management Stratégique : Visions, Manoeuvres et Tactiques, Nathan. 527 MAHAJAN V., SHARMA S. et SRINIVAS D. (1985) An Application of Portfolio Analysis for Identifying Attractive Retail Locations, Journal of Retailing, vol. 61, n°4, hiver 1985, 19-34. L'attrait du secteur, en l'occurrence le plus souvent de la zone de chalandise, est quantifiable en prenant une combinaison de paramètres comme 528 529: - la taille de la zone de chalandise ; - son taux de croissance ; - le taux de profit ; - l'intensité de la concurrrence au sein de la zone de chalandise. Et la force concurrentielle est, elle, une combinaison de : - la part de marché ; - la qualité des points de vente (équivalents aux produits) ; - la réputation des enseignes ; - l'efficacité promotionnelle. L'exemple ci-dessous montre l'utilisation de la matrice des portefeuilles par le groupe Lévi Strauss, fabricant de Jeans, pour renforcer sa présence dans les pays de distribution où il est le moins bien implanté.
Fig. 2.12 : La matrice de Portefeuille appliquée à l'Europe par le groupe Lévis Strauss530 Il n'y a eu cependant aucune étude qui est venue confirmer la validité et l'efficacité de la méthode d'analyse de portefeuille531. Certaines études sur les prises de décision ont montré au 528 THIETARD Raymond-Alain (1988) La Stratégie d'Entreprise, Mc Graw-Hill. 529 CLIQUET G. (1992) Le Management Stratégique des Points de Vente, Ed. Sirey., p.193 530 University of Newcastle upon Tyne, Agricultural Economics & Food Marketing Department (2001) Student Ressources, http://www.ncl.ac.uk/aefm/student_resources/aef334/LeviStrauss.pdf contraire que l'utilisation de cette méthode aboutissait dans 64 % des cas à la sélection d'un investissement non-rentable et dans 87 % des cas à l'un des investissements les moins rentables. 2.2.4 Les autres modèles de localisation-allocation Il existe de nombreux autres modèles dont la fonction objectif est dérivée de celle du p- médian. Citons les modèles p-centrés et le modèle de couverture maximale. Alors que le p- médian imposait de minimiser la somme des distances entre chaque client et son point de vente assigné, le modèle p-centré cherche la configuration pour laquelle la distance entre chaque point de vente et le plus éloigné de ses clients soit minimale. Ce modèle est particulièrement indiqué pour placer des services d'urgence, des hôpitaux ou des casernes de pompiers étant donné une population. Le modèle de couverture maximale532 vise à assurer que la majorité des clients sont à une distance maximale au moins d'un service donné : si cette condition est bien vérifiée, on dit alors que l'ensemble des clients est couvert : les modèles de couverture sont tout indiqués pour placer des services généraux du type poste, trésorerie, services de mairie et administrations d'une manière générale. Les algorithmes de résolutions de ces autres modèles de localisation-allocation se calquent sur ceux du p-médian. |
|