Chapitre premier : Apprentissage automatique &
Apprentissage
profond.
1.1. Introduction.
Actuellement l'informatique est presque présente dans
tous les domaines : la santé, l'éducation, l'économie, et
la cosmologie. Cette présence se reflète dans la vie quotidienne
de l'individu et elle a permis des facilités d'utilisation et de
compréhension de plusieurs complexes domaines. Un des domaines les plus
importants qui a été touché par ce terrible
développement de l'informatique est le domaine de la santé. Le
développement de l'informatique et de la technologie continue à
prendre une place de plus en plus importante dans le domaine de santé,
ce qui a permis le développement du matériel médical, les
logiciels de surveillance médicale, et les logiciels d'analyse
médicales qui augmentent la précision des résultats. Ce
dernier a donné une grande attention par les scientifiques, en
particulier les spécialistes dans les domaines : de l'intelligence
artificielle, les systèmes experts, l'apprentissage automatique Machine
Learning, et l'apprentissage en profondeur Deep Learning.
Dans ce chapitre, nous allons d'abord présenter les
techniques d'apprentissage automatique Machine Learning. Ensuite, nous
décrierons comment l'apprentissage automatique a été
déplacé vers l'apprentissage profond pour avoir des architectures
plus prometteuses. Et enfin, nous finirons le chapitre par une conclusion.
1.2. L'apprentissage automatique Machine
Learning.
L'intérêt de l'apprentissage automatique a
augmenté au cours de la dernière décennie, pour tout le
discours sur l'apprentissage automatique, il y a beaucoup de conflits entre ce
que la machine peut faire et ce que nous souhaitons (Patterson et al., 2017).
L'apprentissage automatique est un sous-ensemble de l'intelligence artificielle
« IA », il est axé sur la création des systèmes
qui apprennent et améliorent les performances, en se basant sur des
données qu'ils traitent. Les algorithmes d'apprentissage automatique
entrent en jeu pour optimiser, fluidifier, et sécuriser cette
dernière (Clayton, 2019).
1.2.1. Définitions et types d'apprentissage
automatique. 1.2.1.1. Définitions.
La définition de l'apprentissage automatique a connu
une progression durant plusieurs années, cela est dû qu'à
chaque fois il y avait de nouvelles découvertes dans ce domaine :
2 Est un tableau qui rassemble les
individus qui ont un certain nombre de caractéristiques ou encore c'est
une structure qui contient nos données.
P a g e | 16
premier programme qui permet aux ordinateurs de jouer et
d'apprendre le jeu de dames sans être explicitement programmé
(Géron, 2017).
? En 1997, l'informaticien américain «
Tom Michael Mitchell » introduit une nouvelle
définition de l'apprentissage automatique. Il a considéré
qu'un programme apprend d'une expérience E, par rapport
à une classe de tâches T, et avec une mesure de
performance P (Géron, 2017).
? Avec le temps, la définition de
l'apprentissage automatique a commencé à prendre une dimension
mathématique et statistique. Selon les auteurs dans (Goodfellow et al,
2016), l'apprentissage automatique est essentiellement une forme de
statistiques appliquées, mettant davantage l'accent sur l'utilisation
d'ordinateurs pour estimer statistiquement les fonctions compliquées et
un accent moindre sur la démonstration des intervalles de confiance
autour de ces fonctions.
Ces définitions peuvent varier en fonction de l'angle
étudié, mais elles sont toutes orientées vers une seule
direction, qui est définie comme suit : l'apprentissage automatique est
la science ou l'art de la programmation des ordinateurs afin qu'ils puissent
apprendre à partir des données (Géron, 2017).
1.2.1.2. Types d'apprentissage automatique.
Il existe également de différents types
d'apprentissage automatique. Selon (Géron, 2017), la définition
du type d'apprentissage est basée sur la réponse à ces
deux questions suivantes :
? Est - ce que cet apprentissage compte sur la supervision
humaine dans son entrainement et apprentissage ?
? Est - ce que ce type d'apprentissage utilise une base de
données (dataset2) fournie par l'être humain ?
1-. Si la réponse est oui pour les deux questions,
nous avons un apprentissage supervisé.
2-. Si la réponse est non pour la première
question, et oui pour la deuxième question, nous parlons d'un
apprentissage non supervisé.
3-. Si la réponse est non pour les deux questions, le
type de l'apprentissage est l'apprentissage par renforcement.
Dans ce qui suit, nous définissons chacun de ces types
: apprentissage supervisé, apprentissage non supervisé, et
apprentissage par renforcement.
P a g e | 17
1.2.1.2.1. Apprentissage supervisé.
Dans l'apprentissage supervisé l'être humain aide
l'algorithme pour apprendre, un data scientiste sert de guide et il apprend
à l'algorithme les résultats qu'il doit trouver. Le même
cas lorsqu'on apprend à un enfant d'identifier les fruits, en les
mémorisant dans sa mémoire. Dans l'apprentissage
supervisé, l'algorithme apprend grâce à un jeu de
données déjà étiqueté et dont le
résultat est prédéfini (Goodfellow et al, 2016). (Voir
figure 1).
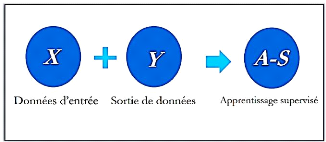
Figure 1. Apprentissage
supervisé.
Les algorithmes de l'apprentissage automatique
supervisé sont les plus couramment utilisés, il y deux types
d'apprentissage supervisé :
? La classification : la classification
consiste à trouver le lien entre une variable
d'entrée (X) et une variable de sortie
discrète (Y), en suivant une loi multinomiale
(Dupré, 2020).
? Régression : la régression
consiste à prédire une valeur continue
pour la variable de sortie (Dave,
2020).
Les algorithmes les plus célèbres
utilisés dans cette approche sont les suivants (GAËL, 2019) :
? SVM (Machines à vecteurs de support)
: est un apprentissage automatique très puissant et polyvalent
modèle, capable d'effectuer la classification linéaire ou non
linéaire, la régression, et même détection des
valeurs aberrantes. C'est l'un des modèles les plus populaires de
l'apprentissage automatique « Machine Learning », et
n'importe qui intéressés par cette approche devraient l'avoir
dans leur boîte à outils. Les SVM sont particulièrement
bien adapté à la classification d'ensembles de données
complexes mais de petite ou moyenne taille. L'algorithme SVM consiste à
chercher à la fois l'hyperplan optimal ainsi que de minimiser les
erreurs de classification.
P a g e | 18
A La méthode des k plus proches voisins
: cet algorithme consiste à essayer différentes valeurs
de K pour obtenir la séparation la plus satisfaisante.
A Naïve Bayes : est un classifieur assez
intuitif à comprendre. Il se base sur le théorème de Bayes
des probabilités conditionnelles, et il suppose que les variables sont
indépendantes entre elles. Cela permet de simplifier le calcul des
probabilités.
A Les arbres de décision : un arbre de
décision sert à classer les futures observations, sachant qu'un
corpus d'observations est déjà étiqueté.
A Les Forêts Aléatoires : cet
algorithme fonde sur les arbres de décision, est un modèle
construit par de multiples arbres de décisions.
A Régression Logistique : l'algorithme
de régression logistique consiste à trouver les meilleurs
coefficients pour minimiser l'erreur entre la prédiction faite pour des
destinations visitées et la vraie étiquette donnée (Ex.
bon, mauvais etc.).
A Les réseaux de neurones : Les
réseaux neuronaux sont un modèle informatique qui partage
certaines propriétés avec le cerveau humain, dans lequel de
nombreuses unités simples travaillent en parallèle sans
centralisation, ils permettent de trouver des patterns complexes dans les
données, il se compose de valeurs d'entrées, poids,
fonction de transfert et une valeur de sortie (Werfelli, 2015)
(Voir figure 2).

Figure 2. Neurone biologique et
neurone artificiel.
Il existe aussi d'autres algorithmes, tels que l'algorithme de
régression linéaire, les Algorithmes Génétiques
(GAËL, 2019). Certains algorithmes de régression peuvent
également être utilisés pour la classification, et la
régression, à titre d'exemple l'algorithme de la
régression logistique (Géron, 2017).
P a g e | 19
1.2.1.2.2. Apprentissage non
supervisé.
Avec l'apprentissage non supervisé la machine n'a pas
besoin de l'aide pour apprendre. L'apprentissage non supervisé est une
approche plus indépendante, dans laquelle un ordinateur apprend à
identifier des processus et des schémas complexes sans aucun guide, Il
implique une formation basée sur des données sans
étiquette, qui ne contiennent aucun résultat spécifique
(Goodfellow et al, 2016). (Voir figure 3).
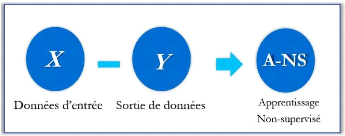
Figure 3. Apprentissage non
supervisé.
Selon (Géron, 2017), il y a deux types d'apprentissage
non supervisé :
A Regroupement (Clustering) : c'est une
méthode d'analyse statistique utilisée pour organiser des
données brutes en silos homogènes, à l'intérieur de
chaque grappe, les données sont regroupées selon une
caractéristique commune.
A Réduction de la dimension :
l'objectif est de simplifier les données sans perdre trop
d'informations, à titre d'exemple, fusionner plusieurs
caractéristiques en un seul caractère.
Les algorithmes les plus célèbres
utilisés dans cette approche sont (Issarane, 2019) :
A K-Moyenne : est un algorithme de
Regroupement (Clustering) il regroupe dans les même Cluster (Groupes) les
données similaires (qui se ressemblent). Il utilise un raffinement
itératif pour produire un résultat final.
A Analyse de classification hiérarchique (HCA)
: la mise dans un cluster hiérarchique est similaire à
la mise dans un cluster normal, sauf que dans ce cas nous souhaitons mettre en
place une hiérarchie des clusters. Cela peut s'avérer très
important surtout quand nous désirons une flexibilité par rapport
au nombre de clusters voulu.
A PCA (Analyse des composants principaux) :
l'algorithme PCA consiste à transformer des variables liées entre
elles, vers de nouvelles variables séparées les uns des autres.
Ces nouvelles variables sont
La figure ci - dessous exprime les différentes branches
et algorithmes de l'apprentissage automatique (Voir figure 5).
P a g e | 20
nommées les composantes principales, elles permettent
au praticien de réduire le nombre de variables et de rendre
l'information moins redondante.
? Apriori : l'algorithme Apriori s'utilise
dans une base de données transactionnelle pour extraire des ensembles
d'éléments fréquents, puis générer des
règles d'association.
1.2.1.2.3. L'apprentissage par renforcement.
Avec l'apprentissage par renforcement la machine n'a pas
besoin de l'aide de l'être humain, ni en termes de supervision, ni en
termes de fourniture de données. L'apprentissage par renforcement est
une branche très différente. Le système d'apprentissage,
appelé un agent dans ce contexte (Voir figure 4), peut observer
l'environnement, sélectionner et effectuer des actions, et enfin obtenir
des récompenses ou des pénalités (des récompenses
négatives). La machine peut apprendre toute seule la meilleure
stratégie à suivre, appelée une politique, pour obtenir
plusieurs récompenses au fil du temps. Une politique définit
l'action que l'agent devrait choisir lorsqu'il est dans une situation
donnée (Géron, 2017).
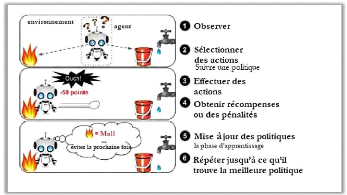
Figure 4. Apprentissage par
renforcement.
Parmi les premiers algorithmes d'apprentissage par
renforcement, c'est l'algorithme « Temporal différence
Learning », proposé par « Richard Sutton »
en 1988 (Sutton, 1988). Aussi l'algorithme « Q-Learning »
mis au point lors d'une thèse soutenue par « Chris Watkins
» en 1989 et publié réellement en 1992 (Watkins et al,
1992).
P a g e | 21
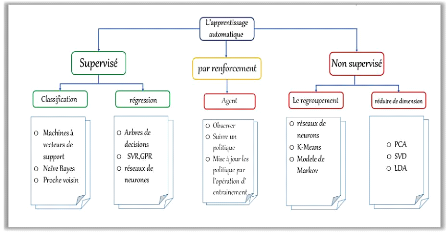
Figure 5. Les approches et les
algorithmes de l'apprentissage automatique. 1.3. Le choix d'un
type d'apprentissage automatique.
Avec la présence de différents types de
classifieurs pour l'apprentissage automatique, l'opération de choix d'un
type est une question typique « Quel algorithme dois-je
utiliser ? ». Selon (Li, 2017), la réponse à
cette question varie les facteurs suivants :
V' La taille, la qualité et la nature des
données. V' Le temps de calcul disponible.
V' L'urgence de la tâche.
V' Le but d'utilisation de ces données.
La figure suivante (Voir figure 6), fournir des indications
sur les algorithmes à essayer en premier selon les facteurs
mentionnés ci-dessus.
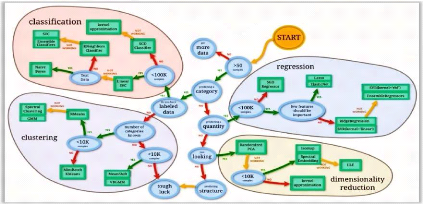
Figure 6. Le choix de
l'algorithme d'apprentissage selon certains facteurs.
P a g e | 22
1.4. Champs industriels d'apprentissage
automatique.
L'apprentissage automatique (l'apprentissage artificiel) a
fourni un grand nombre d'outils aux industriels et aux entrepreneurs. Nous les
regroupons selon deux grands axes: la reconnaissance des formes et la fouille
de données (l'extraction de connaissances des données
(Datamining)) (Chapman et al., 2000).
1.4.1. La reconnaissance de forme.
Elle est un ensemble de technique et méthodes
permettant d'identifier les motifs informatiques à partir des
données brutes pour la prise de décision en
dépendance de la catégorie que l'on attribue à ce motif.
C'est l'un de deux axes sur lesquels l'apprentissage automatique se
développe, elle utilise aussi les statistiques.
Au sens large si on veut bien comprendre la forme, c'est un
motif à nature variée et non pas une simple forme
géométrique.
Il peut s'agir par exemple d'un contenu visuel
(empreinte digitale, code barre, visage, ...) ou
sonore (la parole), d'images
médicales (rayon X, EEG, IRM...) ou
multi spectrales (images satellitaires) et
bien d'autres.
Les méthodes d'apprentissage automatique sont ici à
la base de :
? La reconnaissance des images (écriture manuscrite,
signatures, détection de ressources par satellite, pilotage automatique,
etc...) ; ? La reconnaissance de la parole ;
? Le traitement avancé des signaux biomédicaux ;
Etc.
1.4.2. La fouille de données ou
datamining.
Les problèmes pratiques que peut résoudre en ce
domaine le machine Learning se posent constamment dans la vie industrielle :
comment distinguer un bon client d'un mauvais, comment reconnaître un
mauvais procédé de fabrication et l'améliorer,
voilà deux exemples frappants parmi tant d'autres.
La fouille de données (Datamining, en anglais)
est le processus d'extraction de la connaissance : il consiste à
sélectionner les données à étudier à partir
de bases de données (BD) (hétérogènes ou
homogènes), à épurer ces données et enfin à
les utiliser en apprentissage pour construire un modèle (Gashler et al.,
2008).
Dans le souci de pouvoir corriger certains défauts
qu'avaient connus ses prédécesseurs entre autre (Statistique
descriptive, analyse de données, etc.), qui sont : exigence de
présentation des données sous une forme très rigide et
faiblesse d'intelligibilité constatée sur les
résultats. Dans ce souci est né le datamining.
Depuis, l'évolution de ces domaines, les critiques qui
leur ont été adressés ont changé, et ceci vers les
années 1990. Data ming est effectivement né quadruplet effort.
P a g e | 23
V' Permettre aux utilisateurs de fournir des données
dans l'état où elles sont
(ceci a donné naissance aux techniques de nettoyage
des données);
V' Utiliser les données enregistrées sous
forme de bases de données (en général relationnelles),
ceci a provoqué un large courant de recherche au sein de la
communauté des BD intéressée par la création de
modèles;
V' Fournir aux utilisateurs des outils capables de
travailler sur des données mixtes, numériques et symboliques
;
V' Construire des outils produisant une connaissance
intelligible aux utilisateurs.
C'est ainsi que datamining a pu trouver la large
reconnaissance industrielle dont elle jouit actuellement. Elle a
commencé à résoudre les deux problèmes industriels
principaux de l'analyse des données, ceux qui coûtent le plus cher
(le fait que le client est souvent imprécis dans la dentition du
problème qu'il se pose et le fait que les données dont il dispose
sont souvent de qualité discutable).
1.4.3. Caractéristique d'apprentissage
automatique.
Parmi les principales caractéristiques et
facultés adoptées par les modèles d'apprentissage
automatique, nous citons : l'entraînement, la reconnaissance, la
généralisation, l'adaptation, l'amélioration et
l'intelligibilité (Chapman et al., 2000).
1.4.3.1. Adaptation.
Elle peut être vue comme étant la disposition du
modèle (algorithme ou système) à corriger son
comportement ou à remanier sa réponse (ex.,
prédiction) par rapport à de nouvelles situations.
Pour les tâches de perception, en vision artificielle,
on accumule les bonnes et mauvaises expériences, et à partir
d'elles, on peut faire évoluer les règles pour mieux effectuer la
tâche, c'est le phénomène d'adaptation ou
d'amélioration.
1.4.3.2. Intelligibilité.
C'est améliorer la compréhension des
résultats d'apprentissage, afin que le modèle puisse fournir une
connaissance claire et compréhensible. Au sens interprétable (en
anglais, on parle de comprehensibility ou
understandability).
Exemple, quand un expert extrait de la
connaissance des bases de données (BDs), il apprend une manière
de les résumer ou de les formuler (expliquer, expliciter de
manière simple et précise).
P a g e | 24
D'un point de vue fouille de données, ça revient
purement et simplement à contrôler l'intelligibilité
(clarté) d'un modèle obtenu.
Actuellement, la mesure d'intelligibilité se
réduit à vérifier que la connaissance produite est
intelligible et que les résultats sont exprimés dans le langage
de l'utilisateur et la taille des modèles n'est pas excessive.
1.4.3.3. Généralisation.
D'une autre facette, l'apprentissage est typiquement
caractérisé par une généralisation rationnelle
des règles, c'est-à-dire si d'une expérience
accumulée sur un certain nombre d'exemples, on tire des règles de
comportement, il faudrait que celles-ci soient également applicables
à des situations encore non rencontrées.
1.4.3.4. Reconnaissance.
Avec la reconnaissance de la parole, par exemple, le
programme d'apprentissage n'aura pas besoin d'apprendre tous les sons de ladite
parole. Il va extraire une règle de classification qui lui permettra de
traiter au mieux les sons qu'il aura à décoder.
1.4.3.5. L'amélioration.
Les sciences cognitives définissent l'apprentissage
comme étant une capacité à améliorer les
performances au fur et à mesure de l'exercice d'une
activité. C'est le cas d'un joueur du scrabble au fil des parties,
où l'assimilation de l'expérience et la puissance du raisonnement
se combinent dans sa progression.
1.4.4. Tache d'apprentissage.
Il est possible de parler de l'objectif du processus
d'apprentissage suivant plusieurs points de vue :
? Par rapport à la
connaissance
L'apprentissage peut viser à modifier le contenu de la
connaissance (par l'acquisition de connaissances, soit par révision ou
par oubli), non seulement de modifier mais aussi le rendre plus efficace par
rapport à un certain but ; Par réorganisation, optimisation
ou compilation par exemple. Ce pourrait être le cas d'un joueur
d'échecs ou d'un calculateur mental qui apprend à aller de plus
en plus vite sans pour autant connaître de nouvelles règles de jeu
ou de calcul. On parle dans ce cas d'optimisation de
performance.
P a g e | 25
· Par rapport à
l'environnement
Dans cette optique la tache de l'apprentissage peut
être définie de ce que l'agent apprenant doit réaliser pour
survivre dans son environnement en :
V' Apprenant à reconnaître les
formes ; V' Apprendre à prédire ;
V' Apprendre à être plus
efficace.
· Par rapport à des classes abstraites
de problèmes.
Voyant des problèmes et processus de résolution
qui leur sont assignés, l'apprentissage peut viser à extraire
et à compresser l'information, à décoder ou même
à décrypter un message codé (cryptographie), à
approximer une fonction cachée dans les données
(problème d'analyse), à généraliser une
connaissance déjà apprise (problème d'induction),
à tenter la résolution des problèmes mal posés
(problème issu des mathématiques appliquées).
· Par rapport aux structures de données
ou types d'hypothèses visées.
Dans cette optique, la tâche agent apprenant est
définie sur la détermination de l'algorithme d'apprentissage
à utiliser ainsi que le type de données adéquat à
l'apprentissage. Il consiste parfois à modifier la structure de
données pour en trouver une équivalente mais plus efficace du
point de vue computationnel, c'est encore une fois, sous un autre angle, le
problème de l'optimisation de performance (Mitchell, 1997).
1.4.5. L'espace des données
d'apprentissage.
Le problème de la classification est l'apprentissage
d'une fonction dite de prédiction, de décision etc., au travers
des données. Pour espérer obtenir un classifieur
adapté à la tâche considérée,
quelques points sont à survoler (Wiener et al., 2002).
Ces points se résument autour de deux problèmes
essentiels :
V' Celui de la représentation
adéquate des données ;
V' Et celui de la représentation
des hypothèses faites par le programme d'apprentissage.
1.5. De l'apprentissage automatique à
l'apprentissage en profondeur.
Nous ne pouvons pas différer sur l'efficacité de
l'apprentissage automatique dans la résolution d'une
variété de problèmes, mais il y a beaucoup de
problèmes que ce type fait face, dont les plus importants sont le temps,
la vitesse et l'efficacité, si un algorithme d'apprentissage automatique
renvoie une prédiction inexacte, alors un
P a g e | 26
ingénieur doit intervenir et faire des ajustements,
dans ce cas, il y a un manque d'efficacité qui sera une perte de temps
avec une prévision lente (Grossfeld, 2020).
Les algorithmes simples d'apprentissage automatique
décrits dans ce chapitre fonctionnent très bien sur une grande
variété de problèmes importants. Cependant, ils n'ont pas
réussi à résoudre les problèmes centraux de
l'intelligence artificiel, tels que la reconnaissance de la parole ou la
reconnaissance d'objets. Le développement de l'apprentissage en
profondeur a été motivé en partie par l'échec de
algorithmes traditionnels, lorsque de travaille avec des données de
grande dimension, pour bien généraliser sur de telles
tâches l'intelligence artificiel (Goodfellow et al., 2016).
1.6. L'apprentissage en profondeur « Deep Learning
».
L'apprentissage en profondeur « Deep Learning » a
été un défi à définir pour beaucoup de
spécialiste dans le domaine, car il a changé de forme lentement
au cours de la dernière décennie. Une définition utile
précise que l'apprentissage en profondeur est un réseau neuronal
avec plus de deux couches (Patterson et al., 2017). Le problème avec
cette définition est qu'elle fait écho à l'existence de ce
domaine depuis les années 80 du siècle dernier, formant ainsi une
grande contradiction puisque beaucoup de gens pensent que ce domaine est
relativement nouveau, pour réfuter cette contradiction, il faut
distinguer le moment où le domaine est apparu et celui où il a
été cadré et exploité.
1.6.1. Définitions et les architectures
d'apprentissage en profondeur. 1.6.1.1. Définitions.
Le terme « apprentissage profond » a
été introduit dans le domaine du l'apprentissage automatique par
« Rina Dechter » en 1986, et dans les
réseaux de neurones artificiels par « Igor Aizenberg
» et ses collègues en 2000, dans le contexte des neurones
à seuil booléen (Schmidhuber, 2015), l'apprentissage profond
désigne une technique d'apprentissage d'une machine, c'est une
sous-branche de l'intelligence artificielle qui vise à construire
automatiquement des connaissances à partir de grandes quantités
d'information (Voir figure 7). Les caractéristiques essentielles du
traitement ne seront plus identifiées par un traitement humain dans
algorithme préalable, mais directement par l'algorithme d'apprentissage
profond (Nuageo, 2017).
P a g e | 27
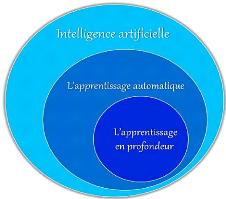
Figure 7. Les sous-bronches de
l'intelligence artificiel.
L'apprentissage en profondeur permet donc implicitement de
répondre à des questions du type « que peut-on
déduire de ces données ? » et décrire
des caractéristiques parfois cachées ou des relations entre des
données souvent impossibles à identifier pour l'homme.
D'après (Patterson & Gibson, 2017)
l'apprentissage profond est un réseau neuronal avec un grand nombre
de paramètres et de couches, l'exemple de base c'est le
perceptron multicouche MLP « multi layer
perceptron » (Voir figure 8).
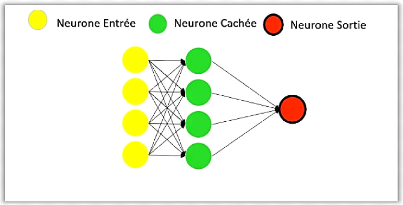
Figure 8. Un perceptron
multicouche.
Perceptrons a été inventé en 1958 au
« Cornell Aviation Laboratory » par « Frank
Rosenblat » financé par le bureau de recherche navale des
États-Unis, Le mot vient de verbe latin « Percipio
» qui signifie en Anglaise understand
; en Français comprendre, qui
montre que le robot ou l'appareil peut apprendre et comprendre le monde
extérieur (Rosenblatt, 1958).
P a g e | 28
Un perceptron multicouche avec plusieurs couches
cachées entre la couche d'entrée et la couche de sortie est un
réseau de neurones profonds (DNN), le DNN est une fonction
mathématique, qui mappe certains ensembles de valeurs d'entrée
aux valeurs de sortie. La fonction est formée par la composition de
nombreuses fonctions plus simples (Goodfellow et al., 2016).
Certaines de ses caractéristiques (Patterson et al., 2017)
:
V' Plus de neurones.
V' Des moyens plus complexes de connecter les couches neurones
dans
les réseaux neuronaux.
V' Puissance de calcul.
V' Extraction automatique des fonctionnalités.
L'apprentissage profond s'applique dans divers domaines
(Goodfellow et al., 2016), tel que :
V' L'intelligence artificielle en général.
V' La reconnaissance visuelle et la comparaison de forme.
V' La robotique.
V' La santé et la bio-informatique.
V' La sécurité.
1.6.1.2. Les architectures d'apprentissage en
profondeur.
Les trois grandes architectures de réseaux profonds
selon (Patterson et al., 2017) :
4. Réseaux de neurones pré-entraînés
non supervisés.
4. Réseaux neuronaux convolutionnels (CNN).
.
4. Réseaux neuronaux récurrents (RNN)
Habituellement, de nombreuses catégories
considèrent les réseaux de neurones supervisés comme
appartenant au domaine d'apprentissage automatique plutôt que
d'apprentissage en profondeur.
P a g e | 29
1.7. Comparaison entre l'apprentissage automatique et
l'apprentissage en profondeur.
|
L'apprentissage
automatique
|
L'apprentissage en
profondeur
|
|
Dépendances des données
|
Une performance excellence
avec des petites bases de
données.
|
Une performance
excellente avec les BIG-DATA3.
|
|
Dépendances du matériel
|
Travail sur une machine
faible.
|
Besoin d'une machine
fort avec un CPU4 fort aussi.
|
|
Les caractéristiques des
données
|
Besoin de comprendre les
caractéristiques des données.
|
Pas besoin de comprendre
les caractéristiques des
données.
|
|
Le temps d'exécution
|
Quelque minute à des heures.
|
Des semaines.
|
|
Interprétable
|
Certains algorithmes sont
faciles (Arber de disions) et
d'autres sont impossibles
(SVM, XGBoost5).
|
Difficile à impossible.
|
Tableau 1 : Comparaison entre
l'apprentissage automatique et l'apprentissage en
profondeur.
3 BIG-DATA : un ensemble
très volumineux de données qu'aucun outil classique de gestion de
base de données ou de gestion de l'information ne peut vraiment
travailler (Bremme, 2015).
4 CPU : Un processeur
« central processing unit »
5 XGBoost : est une
bibliothèque logicielle open source permettant de mettre en oeuvre des
méthodes de Gradient boosting, Le Boosting de Gradient est un algorithme
d'apprentissage supervisé dont le principe et de combiner les
résultats d'un ensemble de modèles plus simple et plus faibles
afin de fournir une meilleure prédiction (Cayla, 2018).
P a g e | 30
| 

