|
|
Mémoire de recherche de Master 2 Droit Des Affaires
2019-2020
Déposé le 2 juin 2020
|
|
Intelligence Artificielle
et mise en oeuvre des principes de
Privacy by design et Privacy by
default
Julie Richard Morin
Sous la direction de (PhD) Isabelle Bufflier
Remerciements
La réalisation de ce mémoire a été
possible grâce au concours de plusieurs personnes à qui je
voudrais témoigner ma gratitude.
Je souhaite d'abord remercier la directrice de ce
mémoire, Madame Isabelle Bufflier pour son accompagnement tout au long
de sa rédaction et pour m'avoir poussée à dépasser
mes limites.
Je tiens également à remercier Maître
Adrien Basdevant, qui m'a partagé la passion du métier lors de
mon stage effectué chez Basdevant Avocats.
Un grand merci aussi à Monsieur François Xavier
Cao pour m'avoir accompagnée dans ma démarche et pour m'avoir
confortée dans l'idée que le droit et la technologie sont
consubstantiels.
Je désire en outre saluer les professeurs de
l'Université du Littoral Côte d'Opale et de Skema Business School
ainsi que les intervenants qui ont su nourrir ma réflexion tout au long
de ce master, créant ainsi des ponts entre les connaissances et
participant à ma formation.
J'adresse enfin un remerciement tout particulier à ma
famille et mes amis, dont mes grands-parents héroïques, qui ont su
braver le confinement et le fossé technico-juridique et réussir
une relecture efficace de ce mémoire.
« La sécurité, c'est faire face aux
menaces de demain contre les plateformes d'aujourd'hui. C'est
déjàÌ assez difficile. Le respect de la vie
privée, c'est faire face aux menaces de demain contre les plateformes de
demain1 »
La Maison-Blanche
Bureau exécutif du Président B. Obama
Conseil d'experts en science et technologie du
Président
1 Texte original: « security deals with tomorrow's
threats against today's platforms. That is hard enough. But privacy deals with
tomorrow's threats against tomorrow's platforms, since those
«platforms» comprise not just hardware and software, but also new
kinds of data and new algorithms »
Executive office of the president, president's council of
advisors on science and technology «report to the president big data
and privacy: a technological perspective», mai 2014, p. 34
RGPD Règlement Général de
Protection des Données
Glossaire
CNIL Commission Nationale de l'Informatique et
des
Libertés. Autorité Administrative
Indépendante chargée de former, accompagner, contrôler et
sanctionner.
Donnée à caractère personnel
Toute information se rapportant à une personne
physique identifiée ou identifiable.
Personne concernée Personne pouvant
être identifiée directement ou
indirectement par une donnée à caractère
personnel.
Responsable du traitement Personne physique ou
morale, autorité publique,
service ou autre organisme qui, seul ou conjointement avec
d'autres, détermine les finalités et les moyens du traitement
Sigles
EDPB European Data Protection Board
Comité Européen de Protection des
Données
EDPS European Data Protection Supervisor
Contrôleur Européen de la Protection des
Données
G29 Groupe de travail de l'article 29
Le G29 devient l'EDPB le 25 mai 2018
IPEN Internet Privacy Engineering Network
Réseau d'ingénierie de la vie privée sur
Internet
IA Intelligence Artificielle
PET Privacy Enhancing Technologies
Technologies renforçant la protection de la vie
privée
Sommaire
IA et mise en oeuvre des principes de Privacy by design et
Privacy by default
INTRODUCTION 1
PREMIERE PARTIE : UNE NECESSAIRE ADAPTATION PRINCIPES DE
PROTECTION DES
DONNEES A CARACTERE PERSONNEL A L'INTELLIGENCE
ARTIFICIELLE 22
Titre 1 : L'application des principes de protection des
données à caractère personnel à l'intelligence
artificielle 23
Chapitre 1 : Les principes directeurs du RGPD, des
principes limités 23
Chapitre 2 : La nécessité de
créer des principes spécifiques à l'IA 29
Titre 2 : Les moyens d'autorégulation
adaptés à l'intelligence artificielle 34
Chapitre 1 : Vers une nouvelle notion du risque
34
Chapitre 2 : Des outils de conformités
adaptés au respect de la vie privée 41
SECONDE PARTIE : CONSTRUIRE UNE INTELLIGENCE
ARTIFICIELLE CONFORME AUX
PRINCIPES DE PRIVACY BY DESIGN ET DE
PRIVACY BY DEFAULT 47
Titre 1 : Le régime de lege lata
48
Chapitre 1 : Le régime de gouvernance
autorégulé de la donnée 48
Chapitre 2 : Les points d'attention selon le cycle
de vie de la donnée 57
Titre 2 : Le régime de lege
feranda 70
Chapitre 1 : De la gouvernance de la donnée
à la gouvernance de l'intelligence artificielle 70
Chapitre 2 : Replacer l'utilisateur au coeur de
l'intelligence artificielle 80
CONCLUSION 85
- 1 -
Introduction
Analyser la mise en oeuvre des principes de privacy by
design et du privacy by default dans le cadre d'un traitement d'un logiciel
d'intelligence artificielle requiert au préalable quelques propos
préliminaires. L'essor de l'IA est permis par l'augmentation massives
des données, dit big data (1). Par ailleurs, le terme d'intelligence
artificielle est galvaudé, si bien qu'il convient de s'accorder sur sa
définition (2) et sur le fonctionnement de cette technologie (3). Il
conviendra ensuite de mesurer les enjeux soulevés par son usage (4) afin
de comprendre les spécificités de la réglementation en
matière de données à caractère personnel et plus
particulièrement du privacy by design et du privacy by default (5) et
son application à l'intelligence artificielle (6).
1. L'avènement du big data
Les données font partie inhérente de la vie de
l'Homme. Utilisées avant même l'invention de l'écriture
pour compter, puis pendant l'antiquité pour effectuer des recensements,
l'usage des données évolua au fil des transformations de nos
sociétés. Elles devinrent ensuite un instrument de mesure de
risques par des indicateurs statistiques ; par une approche descriptive
d'abord, puis par une approche prescriptive ensuite, si bien que les
données prennent de plus en plus de place dans notre vie2. La
donnée est communément définie comme « une
description élémentaire d'une réalité. C'est par
exemple une observation ou une mesure. La donnée est dépourvue de
tout raisonnement, supposition, constatation, probabilité. État
indiscutable ou indiscutée, elle sert de base à une recherche,
à un examen quelconque3 ». Au fil des
siècles, la définition des données n'a pas changé,
mais son usage ainsi que son nombre modifient en profondeur notre mode de
vie.
Le volume de données augmente de 33,8 % par an, ce qui
représentera 163 Zigaoctets en 20254. Cette croissance
fulgurante de la quantité de données, appelée
également « données massives » ou «
big data » est définie comme « la conjonction
entre, d'une part, d'immenses volumes de données devenus difficilement
traitables à l'heure du numérique et, d'autre part,
2 A. Basdevant, JP Mignard, « l'empire des
données », Don Quichotte, 2018, p. 28 et s.
3 S. Abiteboul, « Sciences des données.
De la logique du premier ordre à la Toile », leçon
inaugurale à la chaire Informatique et sciences numériques du
Collège de France, 8 mars 2012
4 Cabinet IDC, « La gouvernance des
données, un enjeu majeur à l'ère de la transformation
numérique », novembre 2019
- 2 -
INTRODUCTION
les nouvelles techniques permettant de traiter ces
données, voire d'en tirer par le repérage de corrélations
des informations inattendues5. ». Le big data a
pu connaitre un essor fulgurant par la synergie de quatre facteurs
énumérés dans le rapport Villani6. Il s'agit de
la baisse colossale du coût de traitement de l'information, de
l'avènement du web 2.0 et des contenus générés par
les utilisateurs, de la croissance exponentielle des données
générées par les humains et les machines et des
progrès spectaculaires en algorithmie. Le big data fait par
ailleurs l'objet d'un investissement massif. Si le total estimé en
valeur des investissements mondiaux dans les domaines du big data et
de l'analytique s'élève à 189 milliards de dollars en
2019, le cabinet IDC estime que cet investissement total
s'élèvera à 274 milliards de dollars en 20227.
Ce phénomène participe à l'essor du marché
d'internet, basé sur la publicité en ligne. Désormais, les
« data brokers8 », courtiers en données
personnelles, revendent des données personnelles en temps réel
afin de proposer par exemple un contenu publicitaire
ciblé9.
Le big data permet ainsi la création de
nouveaux usages liés au développement de nouvelles technologies.
Le big data offre notamment la possibilité de traiter une plus
grande masse de données, souvent non structurées, afin de mener
une opération non plus déductive mais inductive10. Il
permet de faire émerger des modèles, appelés «
patterns ». L'intelligence artificielle ne peut fonctionner sans
ces données, qui permettent au logiciel de fonctionner et qu'elle permet
en retour de traiter. Cette technologie est ainsi intimement liée au
big data par un rapport d'interdépendance : «
L'algorithme sans données est aveugle. Les données sans
algorithme sont muettes11 ».
2. Un logiciel de traitement intelligent ?
L'idée d'un être artificiel est présente
dès l'antiquité à travers les mythes de Pygmalion et
d'Héphaïstos12. Néanmoins, la doctrine s'accorde
à dater l'apparition du terme d'intelligence artificielle en 1956 lors
de la conférence de Dartmouth. Les plus grands chercheurs du domaine
réunis sur le campus du Dartmouth College tels que K. McCarthy, M.
Minsky, C. Shannon, A. Newell, A. Samuel, H. Simon et N. Rochester s'accordent
à définir cette nouvelle technologie
5 CNIL, « Comment permettre à l'Homme
de garder la main ? Les enjeux éthiques des algorithmes et de
l'intelligence artificielle », 2017, p. 75
6 C. Villani, « Donner un sens à
l'intelligence artificielle », mars 2018, p.149
7 Propos rapportés dans le « Guide du
big data », 2019, p. 38
8 B. Poilvé, « Les enchères en
temps réel (RTB), un système complexe », LINC, CNIL, 14
janvier 2020
9 Rapport à l'Assemblée nationale
n°3119 « Numérique et libertés, un nouvel âge
démocratique », présenté par C. Paul et C.
Féral-Schuhl 2015, p. 108
10 A. Basdevant, J.P. Mignard, op. cit., p.
64
11 CNIL, sondage réalisé sur un
échantillon de 1001 personnes par l'IFOP, « Comment permettre
à l'homme de garder la main ? Les enjeux éthiques des algorithmes
et de l'intelligence artificielle », 2017 p.15
12 J. Diaz, «Petite histoire de l'intelligence
artificielle, Partie 1 », Actu IA, 12 avril 2017
- 3 -
INTRODUCTION
par le terme d'« intelligence artificielle
». Si cette date fait consensus, on notera néanmoins que
dès 1950, A. Turing s'intéresse13 à la
possibilité pour des machines de penser par elles-mêmes.
Plus récemment, des succès spectaculaires ont
mis en exergue les prouesses de l'intelligence artificielle. En 2016, Alpha Go,
intelligence artificielle créée par Google bat le champion du
monde du jeu de Go, Lee Sedol14. Cette victoire est notable car le
jeu de Go est basé davantage sur l'intuition des joueurs que sur un
raisonnement logique et ne repose donc pas sur une analyse statistique des
chances de succès.
Si l'intelligence artificielle fait l'objet de nombreuses
publications, sa définition peut rester vague pour les
non-initiés. Selon un sondage mené par l'IFOP pour la CNIL, 83%
des français ont déjà entendu parler des algorithmes mais
53% ne savent pas précisément de quoi il s'agit15.
L'intelligence artificielle est définie dans le Journal
Officiel de la République Française comme le « Champ
interdisciplinaire théorique et pratique qui a pour objet la
compréhension de mécanismes de la cognition et de la
réflexion, et leur imitation par un dispositif matériel et
logiciel, à des fins d'assistance ou de substitution à des
activités humaines » 16. La CNIL, dans son
rapport17 sur l'intelligence artificielle reprend la
définition de M. Minsky18, qui la définit comme des
théories et des techniques « consistant à faire faire
à des machines ce que l'homme ferait moyennant une certaine intelligence
». Ces deux définitions se fondent sur le
référentiel de l'intelligence humaine et ciblent une
catégorie spécifique d'algorithmes, capables d'effectuer des
instructions avec un certain degré d'autonomie par rapport à
l'homme.
On distingue traditionnellement deux types d'intelligence
artificielle. D'une part, l'IA qualifiée de « forte
», ou IA « généraliste », qui serait
capable de répondre globalement à n'importe quel problème,
et son fonctionnement serait donc comparable à celui de l'intelligence
humaine. D'autre part, l'IA « faible »,
spécialisée, qui pourrait imiter une tâche
déterminée19. Cette distinction provient de la
signification du terme « d'intelligence » qui selon C.
Castests-Renard20, renvoie à la capacité de la machine
à imiter les fonctions cognitives de l'esprit de l'humain ou de
l'animal. Dès lors, deux approches peuvent être
distinguées. D'une part, l'approche cognitive vise à imiter le
comportement humain dans la manière de penser ou dans
13 A. M. Turing, «Computing machinery and
intelligence», Mind, 59, 1950, p. 433-460
14 CNIL, les enjeux éthiques des
algorithmes et de l'intelligence artificielle, op. cit., p. 16
15 CNIL, sondage, op. cit., p.15
16 Vocabulaire de l'intelligence artificielle
(liste de termes, expressions et définitions adoptés), JORF
n°0285, 9 décembre 2018
17 CNIL, les enjeux éthiques des
algorithmes et de l'intelligence artificielle, op. cit., p. 16
18 1927-2016, père fondateur de l'intelligence
artificielle
19 Conseil de l'Europe, « Glossaire de
l'intelligence artificielle »
20 C. Castests-Renard, « Comment construire
une intelligence artificielle responsable et inclusive ? » Recueil
Dalloz 2020, p.225
- 4 -
INTRODUCTION
les actions. D'autre part, l'approche computationnelle, qui
consiste à imiter la logique rationnelle humaine.
Les enjeux juridiques de l'intelligence artificielle sont
directement liés à son état de développement. Un
important débat doctrinal oppose à ce sujet les partisans de
l'attribution d'une personnalité juridique aux robots. Maître F.
Chafiol considère que cette attribution est d'une part
non-pertinente21, car « si on commence à donner une
personnalité juridique à un robot, on l'associe à une
personne » ; et d'autre part non-nécessaire, car les
régimes existants de responsabilité civile, de protection des
données à caractère personnel et de
propriété intellectuelle permettent déjà d'encadrer
ces nouveaux usages issus de cette technologie. Ainsi, la conception d'une IA
forte est rejetée au profit de la conception d'une IA faible. Des
experts en informatique sont également opposés à cette
conception d'une IA forte, comme Y. Le Cun22 et J. G. Ganascia qui
dénoncent le fait que ce débat sur l'IA forte élude les
questions actuelles posées par l'IA faible23. Ce
mémoire sera donc axé sur les traitements effectués par
des intelligences artificielles faibles.
3. Comment fonctionne l'intelligence artificielle ?
Afin de saisir en quoi consiste le traitement des
données par l'intelligence artificielle, il convient de comprendre au
préalable les rouages de la programmation, qui nécessitent de
réunir des données, des algorithmes et une grande capacité
de calcul24. Pour développer un logiciel, le
développeur doit rédiger un code informatique sur son ordinateur.
L'ordinateur est composé de deux couches. La première est celle
de l'environnement matériel, constitué du clavier, de
l'écran, des câbles, et de l'ensemble des composants
électroniques, appelé communément « hardware
». La seconde comprend l'environnement numérique
immatériel, composé de logiciels appelés «
software ». L'ordinateur est ainsi la combinaison du support
matériel et du logiciel. Le développeur utilise donc son
ordinateur afin d'accéder à des logiciels permettant de
développer son code informatique dans le langage de programmation qu'il
souhaite, parmi les langages comme « Python », «
C++ » ou « SQL » en fonction de ses besoins
propres.
Le langage de programmation va interpréter l'algorithme
en langage informatique, afin qu'il soit compréhensible par le
système binaire de l'ordinateur. L'algorithme est communément
défini comme « une suite finie et non ambiguë
d'étapes (ou
21 F. Chafiol, « Débat Club des
juristes : Droit et IA : Quels impacts ? », octobre 2017
22 V. Béranger, « Le terme IA est
tellement sexy qu'il fait prendre des calculs pour de l'intelligence
», Le monde, 7 février 2020
23 CNIL, les enjeux éthiques des
algorithmes et de l'intelligence artificielle, op. cit., p. 19
24 Commission Européenne, « livre blanc
sur l'intelligence artificielle - une approche européenne de
l'excellence et de la confiance », 19 février 2020, p.2, 16
- 5 -
INTRODUCTION
d'instructions) permettant d'obtenir un résultat
à partir d'éléments fournis en
entrée25 ». Il s'agit donc de l'expression d'un
raisonnement mathématique d'algorithmie. Par ailleurs, le logiciel est
défini26 comme « l'ensemble des programmes,
procédés et règles, et éventuellement de la
documentation, relatifs au fonctionnement d'un ensemble de traitement de
données ».
Le logiciel permet donc d'exécuter les instructions
définies par l'algorithme et de traiter des données. Le logiciel
fonctionne en plusieurs étapes. Premièrement, l'initialisation
est composée de l'entrainement de l'algorithme et des retours
apportés afin de l'améliorer. Deuxièmement,
l'entrée constitue l'étape où l'algorithme intègre
les données externes dans son fonctionnement. Troisièmement,
l'étape de traitement cible l'exécution du logiciel. Enfin, la
sortie signifie le moment où le logiciel affiche le résultat
souhaité. Dès lors, pour fonctionner, n'importe quel logiciel
exécute les étapes suivantes :

Rédaction Initialisation Entrée Traitement
Sortie
Il a été expliqué
précédemment que la spécificité de l'intelligence
artificielle résulte du fait que le logiciel est doté d'un
certain niveau d'autonomie. Cela signifie donc que le développeur ne
rédige pas toutes les étapes de traitement dans son algorithme.
Néanmoins en pratique, les logiciels sont constitués par un
ensemble de briques algorithmiques dont seule une partie utilise la technologie
d'intelligence artificielle. C'est dans cette perspective que le groupe
d'experts indépendants de haut niveau sur l'intelligence artificielle
constitué par la Commission Européenne propose de définir
l'intelligence artificielle par l'approche des systèmes : «Les
systèmes d'intelligence artificielle (IA) sont des systèmes
logiciels (et éventuellement matériels) conçus par des
êtres humains et qui, ayant reçu un objectif complexe, agissent
dans le monde réel ou numérique en percevant leur environnement
par l'acquisition de données, en interprétant les données
structurées ou non structurées collectées, en appliquant
un raisonnement aux connaissances, ou en traitant les informations,
dérivées de ces données et en décidant de la/des
meilleure(s) action(s) à prendre pour atteindre l'objectif donné.
Les systèmes d'IA peuvent soit utiliser des règles symboliques,
soit apprendre un modèle numérique. Ils peuvent également
adapter leur comportement en analysant la manière dont l'environnement
est affecté par leurs actions antérieures. » 27
25 CNIL, les enjeux éthiques des
algorithmes et de l'intelligence artificielle, op. cit., p. 19
26 Journal Officiel, Vocabulaire de
l'informatique, 17 janvier 1982, p. 625
27 GEIDHNSIA, « Définition de l'IA :
principales capacités et disciplines », juin 2018
- 6 -
INTRODUCTION
Si l'on se base sur le critère de l'autonomie du
logiciel, il existe de nombreuses techniques d'intelligence artificielle,
réunies sous le terme d'intelligence artificielle. Il est donc
préférable de parler « d'intelligences artificielles
»28. Par ailleurs, L'Institut National de Recherche en
Informatique et en Automatique (INRIA), dans son livre blanc
sur l'intelligence artificielle29 considère qu'effectuer de
nombreuses typologies sur les technologies d'intelligence artificielle est
possible mais qu'aucune ne prévaut car « L'IA est un vaste
domaine; toute tentative de le structurer en sous-domaines peut donner lieu
à débat. ». Néanmoins, la technologie de
l'intelligence artificielle est dominée par les techniques
d'apprentissage automatique30. Seront ainsi
étudiées dans ce mémoire, les techniques d'apprentissage
automatique supervisé, non supervisé et par renforcement.
L'apprentissage automatique, ou « machine learning
», peut se définir comme une « branche de
l'intelligence artificielle, fondée sur des méthodes
d'apprentissage et d'acquisition automatique de nouvelles connaissances par les
ordinateurs, qui permet de les faire agir sans qu'ils aient à être
explicitement programmés.31 » Concrètement,
le développeur doit ici « alimenter la machine avec des
exemples de tâche que l'on se propose de lui faire accomplir. L'homme
entraine ainsi le système en lui fournissant des données à
partir desquelles celui-ci va apprendre et déterminer lui-même les
opérations à effectuer pour accomplir la tâche en question
»32. La CNIL caractérise ce type de
logiciel comme ayant la particularité d'être conçu de sorte
que son comportement évolue dans le temps, selon les données qui
lui sont fournies. En effet, ces types d'algorithmes ont la
particularité de ne pas être totalement programmés, ils se
différencient ainsi des algorithmes classiques de programmation par leur
logique d'apprentissage33.
L'algorithme de machine learning est une innovation
de rupture par rapport à l'algorithme classique. Selon J.P. Desbiolles,
on passe progressivement « d'un monde de programmation à un
monde d'apprentissage »34. On peut donc opposer les
algorithmes classiques, déterministes, qui fonctionnent selon des
instructions définies, aux algorithmes apprenants, probabilistes. La
machine découvre par elle-même les corrélations entre les
phénomènes traduits en données35. Si les types
de logiciels d'apprentissage automatique sont
28 T. Morisse, « intelligence artificielle,
un nouvel horizon : pourquoi la France a besoin d'une culture numérique
? », Les Cahier Lysias, 2017, p. 41
29 INRIA, « intelligence artificielle, livre
blanc n°1 », 2016, p. 20
30 Commission Européenne, « robustness
and Explainability of Artificial Intelligence », JRC technical report,
2020, p. 1
31 Vocabulaire de l'intelligence artificielle, JORF
n°0285, 9 décembre 2018
32 CNIL, les enjeux éthiques des
algorithmes et de l'intelligence artificielle, op. cit., p. 16
33 C. Villani, Rapport «Donner un sens à
l'intelligence artificielle», 2018, p. 26
34 CNIL, les enjeux éthiques des
algorithmes et de l'intelligence artificielle op. cit., p. 16
35 Y. Meneceur, « Pourquoi nous devrions (ne
pas) craindre l'IA », LinkedIn, 23 février 2020
- 7 -
INTRODUCTION
nombreux et complexes (cf. schéma - Typologie
des logiciels d'apprentissage automatique selon le Conseil de
l'Europe), l'étude ci-après vise à saisir les
étapes de traitement des données de manière
simplifiée36 et non technique37.
i. L'apprentissage automatique
supervisé
L'apprentissage automatique supervisé38
fonctionne en traitant des données d'entrée «
annotées », qualifiées par l'humain,
c'est-à-dire qu'à chaque donnée fournie, un label ou une
catégorie lui est attribué. Par exemple, à
côté de la photo de chien est associé le mot «
chien ». Le logiciel définit ensuite les règles
à partir d'exemples qui sont autant de cas validés39
lors de l'initialisation. Il sera donc capable de déterminer des
standards permettant de déterminer avec un niveau de probabilité
élevé un chien sur une photo. Il pourra ensuite traiter
l'information sur n'importe quelle photo entrée, et afficher en sortie
s'il s'agit bien d'un chien. On peut donc décrire les étapes du
fonctionnement d'un algorithme de machine learning de la
manière suivante :

Rédaction du logiciel
Initialisation
données
annotées
Traitement
Entrée probabilités
Sortie Résultat
Il s'agit par exemple du système de « Google
recaptcha », où les utilisateurs du moteur de recherche
définissent les zones d'une image où se situe un panneau de
signalisation. Ainsi, l'utilisateur annote la donnée et permet au
logiciel d'initialiser son fonctionnement à partir
d'elle40.
ii. L'apprentissage automatique non
supervisé
L'Apprentissage automatique non supervisé41,
est un type de machine learning. Dans ce système, «
l'algorithme apprend à partir de données brutes et
élabore sa propre classification qui est libre d'évoluer vers
n'importe quel état final lorsqu'un motif ou un élément
lui est présenté »42. Cette méthode
d'apprentissage ne permet pas de calculer le taux d'erreur en l'absence
d'informations en amont. Les données ne sont ici plus annotées
mais « brutes ». Par exemple, en initialisation, le logiciel
traitera un ensemble de photos sans savoir
36 M. Zimmer, «Apprentissage par
renforcement développemental », intelligence artificielle,
thèse, [cs.AI]. Université de Lorraine, NNT : 2018LORR0008, 2018,
p.10
37 O. Padilla, «Cheat sheets for AI»,
LinkedIn, février 2020, p.6
38 C. M. Bishop, «Pattern recognition and machine
learning», Springer, 2006
39 Vocabulaire de l'intelligence artificielle
(liste de termes, expressions et définitions adoptés), JORF
n°0285, 9 décembre 2018
40 CNIL, les enjeux éthiques des
algorithmes de l'intelligence artificielle, op. cit., p. 17
41 H. B. Barlow, «Unsupervised learning.
Neural computation», 1(3):295-311, 1989
42 Vocabulaire de l'intelligence artificielle, JORF
n°0285, op. cit.
- 8 -
INTRODUCTION
au préalable si ces photos sont des photos de chien. On
peut donc présenter les étapes du fonctionnement d'un algorithme
de deep learning de la manière suivante :

Rédaction du logiciel
Initialisation
données
brutes
Entrée Traitement
probabilités
Sortie Résultat
iii. L'apprentissage automatique par
renforcement
L'apprentissage automatique par renforcement43
fonctionne par un système de récompense. Le logiciel traite des
données brutes et détermine tout seul son raisonnement. Le
développeur effectue ensuite un retour sur le logiciel et l'informe du
succès ou de l'échec du résultat obtenu. Par
conséquent, plus le logiciel traite de données, plus son
système de traitement est fiable44.

Rédaction du logiciel
Initialisation
données
brutes
Traitement
Entrée probabilités
Sortie
récompense
Amélioration
4. Les questions soulevées par l'usage de
l'intelligence artificielle
L'usage des logiciels d'intelligence artificielle
combiné au big data bouleverse de nombreux systèmes
traditionnels. Sur le plan politique, B. Ancel45 considère
que nous sommes entrés dans l'ère de la « pax
Technica46 », période caractérisée
par le lien fort unissant États et nouvelles technologies, propice au
développement de la surveillance de citoyens tant dans les
régimes démocratiques que dans les régimes
autoritaires.
La justice se voit également transformée. Elle
utilise désormais cette technologie pour automatiser le traitement des
décisions de certains litiges47, et même prédire
les risques de récidive48. Par ailleurs, « La
gouvernance par les nombres49 » provoque un renversement
de paradigme. A. Supiot analyse que la normativité est désormais
pensée non plus par la législation
43 R.S. Sutton, A. G. Barto «Reinforcement
Learning: An Introduction (Adaptive Computation and Machine Learning», A
Bradford Book, ISBN 0262193981, 1998
44 J. Hurwitz, D Kirsh, «Machine Learning For
Dummies», IBM Limited Edition, 2018, p. 16
45 B. Ancel, « La vie privée dans un
monde digitalement connecté : la démocratie en danger ? »,
Revue Lamy Droit de l'Immatériel, N° 159, 2019
46 Notion attribuée à Phil Howard,
professeur à Yale dans la révue ci-après : C. Fried,
Privacy (1968) 77 3 Yale L. J. 475, 482
47 E. Niler, «Can AI Be a Fair Judge in Court?
Estonia Thinks So», Wired, 2019
48 Revue Lamy Droit de l'Immatériel, N° 159,
1er mai 2019
49 A. Supiot, « La gouvernance par les nombres
», cours au Collège de France, 2012-2014, Fayard, 2015
- 9 -
INTRODUCTION
mais par la programmation : « On n'attend plus des
hommes qu'ils agissent librement dans le cadre des bornes que la loi leur fixe,
mais qu'ils réagissent en temps réel aux multiples signaux qui
leur parviennent pour atteindre les objectifs qui leurs sont
assignés50 ».
Sur le plan économique, nous entrons dans une «
quatrième révolution industrielle ». K. Schwab,
fondateur du World Economic Forum de Davos, prévoit un
bouleversement de paradigme lié à cette nouvelle
révolution industrielle du fait de sa vitesse, de sa portée et de
son impact. Cette révolution marque un tournant du fait qu'elle est
davantage immatérielle qu'industrielle. Issue du bouleversement du
numérique engendré par la troisième révolution
industrielle - le développement des technologies de l'information et de
la communication - la quatrième révolution se caractérise
par « une fusion des technologies qui gomme les frontières
entre les sphères physique, numérique et
biologique51 ». Au coeur de cette révolution figure
la donnée. La première valeur lucrative dans le monde n'est plus
le pétrole, mais la donnée52 et les économies
évoluent en conséquence. Le marché est dominé
aujourd'hui par des acteurs non-européens et 80% des données sont
stockées sur des « clouds », c'est-à-dire des
serveurs situés sur un espace physique différent du lieu de
consultation de l'information53.
D'une manière plus globale, notre société
vit actuellement un « coup data », caractérisé
par le renversement du pouvoir des données choisissant en temps
réel la meilleure configuration pour déployer son programme :
« Les statistiques se sont progressivement substituées aux
expériences et aux vécus personnels pour percer les
mystères de la réalité54 ».
50 Ibid
51 K. Schwab, «La Quatrième
révolution industrielle : ce qu'elle implique et comment y faire
face» World Economic Forum, 2017
52 The Economist, «Regulating the internet
giants. The world's most valuable resource is no longer oil, but data»,
2017
53 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p. 4
54 A. Basdevant, JP Mignard, op. cit., p.
59
- 10 -
INTRODUCTION
5. La régulation de l'utilisation des données
i. Les étapes de la régulation
« La maîtrise de nos
vies dépendra de l'usage et de la protection des données
personnelles » affirmait déjà en 2015
la Commission de réflexion et de propositions sur le droit et les
libertés à l'âge du numérique en introduction de son
rapport55.
La règlementation en matière de données
à caractère personnel n'est pas nouvelle. En France, la loi
n° 78-17 du 6 janvier 1978 relative à l'informatique, aux fichiers
et aux libertés (ci-après « LIL ») a
posé le socle de ce cadre légal. Elle a par la suite
été modifiée par la transposition de la directive 95/46/CE
du 24 octobre 1995, élargissant le périmètre de protection
à l'ensemble des États membres de l'Union Européenne. La
troisième étape de régulation en matière de
données à caractère personnel est marquée par le
Règlement Européen de Protection des Données n°
2016/679 du 27 avril 2016 entré en vigueur le 25 mai 2018
(ci-après « RGPD », ou le «
Règlement »). Or, si un règlement
européen est en principe d'application immédiate, la France a
choisi de transposer ce règlement en modifiant la LIL. Ainsi, la LIL a
été modifiée par la loi n°2018-493 du 20 juin 2018 et
l'ordonnance 2018-1125 du 12 décembre 2018. Enfin, le décret
n° 2019-536 du 29 mai 2019 est venu préciser cette loi. Cette
dernière version de la Loi informatique et libertés,
entièrement réécrite et complétée par
décret, constitue le cadre législatif sur lequel sera basé
ce mémoire.
Au niveau européen, le droit à la protection des
données à caractère personnel apparait dès les
prémices de la construction européenne, dans l'article 16 du
Traité sur le Fonctionnement de l'Union Européenne56.
Si le premier paragraphe consacre ce droit, le second dispose des
compétences législatives des États-membres et du parlement
afin de protéger « la libre circulation de ces données
». On remarquera par ailleurs que le RGPD poursuit cette même
idée de libre circulation et de protection, étant donné
que le titre complet du Règlement s'intitule « règlement
(...) relatif à la protection des personnes physiques à
l'égard du traitement des données à caractère
personnel et à la libre circulation de ces données
».
De plus, le Considérant (1) du RGPD dispose que «
La protection des personnes physiques à l'égard du traitement
des données à caractère personnel est un droit
fondamental. » En effet, la Charte des droits fondamentaux de l'Union
Européenne57 dédie l'intégralité de son
article 8 à un droit à la protection des données à
caractère personnel. A l'échelle du Conseil de l'Europe, la
Convention Européenne de Sauvegarde des Droits de l'Homme et des
libertés fondamentales
55 Ass. nat, Commission de réflexion et de
propositions sur le droit et les libertés à l'âge du
numérique, C. Paul, C. Feral-Schuhl (prés.), rapp. no
3119, Numérique et libertés : un nouvel age
démocratique, 9 oct. 2015, Introduction.
56 TFUE, signé le 25 mars 1957 et entré
en vigueur le 1er janvier 1958.
57 Charte des droits fondamentaux de l'union
européenne, 2000/c 364/01, 2000
- 11 -
INTRODUCTION
consacre ce droit de manière indirecte par le biais de
son article 8 relatif au droit au respect de la vie privée et
familiale.
Il faut néanmoins distinguer le droit à la
protection des données à caractère personnel et le droit
à la vie privée58. Le droit à la protection des
données à caractère personnel est un « outil de
transparence59 ». Il vise à protéger
l'individu d'une atteinte par des acteurs puissants en garantissant une
information propice à son autodétermination et donc sa
liberté de choix. A l'inverse, le droit à la vie privée
est un « outil d'opacité60 », qui permet
à l'individu d'interdire les formes invasives d'interférence dans
sa vie privée, et donc de ses données personnelles. Ces deux
droits sont complémentaires dans l'exercice d'un traitement de
données à caractère personnel. Les jurisprudences de la
Cour Européenne des Droits de l'Homme (CEDH) et de la
Cour de Justice de l'Union Européenne, (CJUE)
illustrent le lien de ces deux notions. Dans L'affaire Atakunnan
Markkinapörssi oy et Satamedia oy c./ Finlande61, la Cour
Européenne des Droits de l'Homme, rappelle que la CJUE a de nombreuses
fois rappelé que la protection des données à
caractère personnel doit être interprétée à
la lumière de la Convention et de la Charte comme la vigilance du risque
d'un traitement puisqu'un traitement risque de porter atteinte aux
libertés fondamentales et notamment à la protection de la vie
privée. La CEDH se base sur la réglementation européenne
en matière de protection des données personnelles dans l'affaire
Big Brother Watch62. Dans l'arrêt Tele2
Sverige63, la Cour de Justice de l'Union Européenne juge
que le droit à la protection des données personnelles est un
droit fondamental qui doit être pris en compte avec autant
d'intérêt que le droit au respect de la vie privée. La
jurisprudence européenne a ainsi fortement participé au
renforcement du droit à la vie privée en consolidant les
garanties procédurales existantes64 .
Cette protection s'exerce au niveau collectif, à
l'instar de l'arrêt Digital Rights Ireland65 qui a
invalidé la directive 2006/24, qui autorisait les gouvernements à
traiter des données à des fins de prévention du
terrorisme.
Ce droit offre également une protection des individus
à titre individuel, à l'image du célèbre
arrêt Google Spain66 de 2014 qui consacre un droit au
déréférencement. La CJUE juge à cet
58 S. Watcher, «The GDPR and the Internet of
Things: A Three-Step Transparency Model», 2018
59 P.D. Hert, S. Gutwirth « Privacy, Data
Protection and Law Enforcement. Opacity of the Individual and Transparency of
power», 2006, p. 76
60 Ibid., p 71
61 CEDH, Arrêt Satakunnan Markkinapörssi oy
et Satamedia oy c. Finlande, Requête no 931/13, 27 juin 2017 §70
62 CEDH, Arrêt case of big brother watch and
others V. The United Kingdom, no 58170/13, 62322/14 and 24960/15,13 septembre
2018
63 CJUE, Arrêt Tele2 Sverige, C-203/15,
EU:C:2016:970, 21 décembre 2016, § 93
64 B. Ancel, « La vie privée dans un monde
digitalement connecté : la démocratie en danger ? », op.
cit
65 CJUE, Digital Rights Ireland, nos C-293/12,
C-594/12, 8 avril 2014
66 CJUE, Affaire Google Spain, C-131/12, 13 mai
2014
- 12 -
INTRODUCTION
effet que ce droit prévaut « en principe, non
seulement sur l'intérêt économique de l'exploitant du
moteur de recherche, mais également sur l'intérêt de ce
public à accéder à ladite information lors d'une recherche
portant sur le nom de cette personne. »
Le droit à la protection des données
personnelles est également consacré au niveau international par
l'article 12 de la Déclaration Universelle des Droits de l'Homme relatif
à la vie privée. Le Pacte international relatif aux droits civils
et politiques y fait référence en son article 17. L'OCDE a
également créé un cadre dédié à la
protection des données à caractère personnel67.
Enfin, la norme ISO / IEC 29100 propose également depuis 2011 un cadre
de protection des données personnelles et la norme ISO IEC 27 0000
encadre les solutions informatiques en matière de sécurité
et techniques.
Ainsi, ces différentes sources et définitions
illustrent bien que le « droit à la vie privée se
révèle [être] un concept polymorphe qui varie selon le
temps, l'espace et le contexte.68 »
ii. Les obligations du RGPD
Le RGPD s'applique en cas de traitement de données
à caractère personnel, c'est-à-dire dès lors qu'une
donnée permet de ré-identifier directement ou indirectement une
personne physique69, appelée « personne
concernée ». Ainsi, l'organisme, personne physique ou
morale, qui traite ces données, le « responsable du
traitement »70, doit respecter la
réglementation, à savoir : chaque donnée doit être
traitée en vue d'une finalité déterminée. De plus,
chaque traitement doit respecter les principes de licéité,
minimisation, conservation limitée, sécurité et
transparence71. Le traitement inclut tout le cycle de vie de la
donnée, de sa collecte à sa destruction. L'exercice du droit des
personnes concernées doit également être
garanti72. Le responsable du traitement doit être en mesure de
démontrer cette conformité en cas de contrôle de la
CNIL73, et peut le faire par le biais d'outils tels que le registre
de traitement, l'analyse d'impact à la protection des données,
les notifications de violation, les codes de conduite et les certifications,
...
67 OCDE, « The OECD privacy framework
», 2013
68 B. Ancel, « La vie privée dans un monde
digitalement connecté : la démocratie en danger ? », op.
cit.
69 Art. 2 RGPD
70 Art. 4, 7) RGPD
71 Art. 5.1 RGPD
72 Art. 12 et s. RGPD
73 Art. 5.2 RGPD
- 13 -
INTRODUCTION
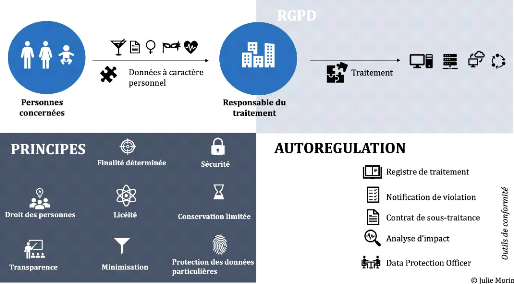
iii. L'apport du RGPD
Le réel apport du Règlement tient non pas par
son contenu, mais par le pouvoir normatif du texte74, imposant tant
aux acteurs publics que privés de respecter ce standard
élevé de protection des données, au risque de se voir
infliger des amendes importantes pouvant atteindre jusqu'à 4% du chiffre
d'affaires mondial75. En France, le non-respect de principes du RGPD
est sanctionné pénalement de cinq ans d'emprisonnement et de
300.000€ d'amende76. Si les sanctions ne sont pas
nouvelles77, elles font encore l'objet d'actualité. L'UFC Que
Choisir a interrogé la CNIL sur la conformité des pratiques de
Google et Facebook le 27 juin 2018. Cette saisine intervient à la suite
de la publication d'un rapport de l'autorité de contrôle
norvégienne qui interroge la licéité des astuces
graphiques et sémantiques de ces entreprises face aux principes de
privacy by design et de privacy by default. L. Costes analyse ces
comportements comme étant illicites et remettant en question la
validité du consentement des personnes
concernées78.
Le RGPD marque également un changement de
contrôle en matière de protection des données à
caractère personnel. Auparavant basé sur un régime de
déclaration préalable auprès de la CNIL et donc a
priori79, le contrôle s'effectue
désormais a posteriori, par un contrôle de
74 C. Villani, Rapport «Donner un sens à
l'intelligence artificielle», 2018, p. 28
75 Art. 83 RGPD
76 C. pèn. Art. 226-17
77 Conseil de l'Europe, « Protection des
données personnelles », février 2020
78 L. Costes, Introduction, Revue Lamy Droit de
l'Immatériel, N° 150, 1er juillet 2018
79 B. Ancel, « La vie privée dans un monde
digitalement connecté : la démocratie en danger ? », op.
cit.
- 14 -
INTRODUCTION
la CNIL. Cette nouvelle approche encourage ainsi
l'autorégulation, « accountability », soit la
responsabilisation des responsables du traitement, qui doivent eux-mêmes
créer des procédures de conformité pour garantir les
droits et libertés des personnes concernées. F. Mattatia
considère que ce glissement vers un système
d'autorégulation basé sur une approche par le risque juridique,
constitue une réponse pragmatique80. Toutefois, l'aspect
transdisciplinaire du risque et ses origines dérivées de la
gestion d'entreprise expliquent cette difficulté à définir
clairement la gestion du risque à adopter en matière de
protection des données personnelles. Dans son rapport annuel, la CNIL
interprète cette notion de responsabilisation des acteurs qui peuvent
être aussi bien des responsables du traitement ou des sous-traitants :
« Cette notion de responsabilisation (accountability) se traduit
notamment par la prise en compte de la protection des données dès
la conception du service ou du produit et par défaut (privacy by design
et by default). Le respect de la nouvelle législation européenne
implique, pour les administrations comme pour les entreprises, une adaptation
profonde de leurs outils, de leurs méthodes et, au-delà, de leur
culture en matière de protection des données » 81.
iv. Privacy by design et privacy by
default
Le terme de vie privée, traduction française de
« privacy » renvoie à la notion de
confidentialité, de contrôle et de pratique82. La
confidentialité est liée à la notion de confiance du fait
de ses origines latines, du terme « confidere », qui
signifie confier. En ce sens, la confidentialité des données est
une obligation incombant au responsable du traitement, qui se voit confier une
partie de la sphère privée de la personne
concernée83. Néanmoins, le terme de « respect
de la vie privée dès la conception » désigne de
manière large les mesures technologiques qui visent à garantir le
respect de la vie privée, tandis que les termes de «
confidentialité » ou de « protection »
des données dès la conception ou par défaut visent les
obligations légales de l'article 25 du RGPD84.
o Le privacy by design
Qu'est-ce que le privacy by design ? Le principe
du privacy by design peut se définir comme le fait de concevoir
le traitement, le produit, le service en prenant en compte la vie
privée85. P. Pucheral, A. Rallet, F. Rochelandet, et C.
Zolynski définissent le privacy by design
80 F. Mattatia, « La mise en oeuvre du RGPD au
prisme du risque juridique », Revue Lamy Droit de
l'Immatériel, N° 140, 1er août 2017
81 L. Costes, « CNIL. Rapport annuel 2017 de la
CNIL et principaux enjeux pour 2018 », 11 avril 2018
82 R. Sayaf, «Algebric Approach to Data
Protection by Design For Data Subjects», EDPS, p.6
83 G. Hass, A. Dubarry, « clause de
confidentialité, savoir-faire et secret des affaires », Dalloz
IP / IT, 2017, p. 322
84 EDPS, « Avis préliminaire sur le
respect de la vie privée dès la conception » avis 5/2018, 31
mai 2018, p. 1
85 M. Brogoli, N. Catelan, ..., Dalloz, Droit
européen des affaires, Protection des données personnelles, 2019,
§74
- 15 -
INTRODUCTION
par sa finalité, consistant en «
l'intégration de la protection de la vie privée dès la
conception du traitement des données à caractère personnel
à un nouvel outil, procédure ou service qui devra s'y conformer
tout au long de sa vie86 ». Ces auteurs reprennent la
définition de G. Loiseau87 qui considère qu'«
il s'agit de faire ab initio de la garantie de la vie privée une
cellule de veille placée au sein de la technologie en phase de
conception ». Concrètement, il peut s'agir notamment du
développement de nouveaux systèmes, services informatiques qui
impliquent le traitement de données à caractère personnel,
du développement de règles organisationnelles, du design
physique, de l'usage de données à caractère personnel pour
de nouvelles finalités88.
La protection des données dès la conception est
consacrée à l'article 25 du RGPD89 :
« Compte tenu de l'état des connaissances, des
coûts de mise en oeuvre et de la nature, de la portée, du contexte
et des finalités du traitement ainsi que des risques, dont le
degré de probabilité et de gravité varie, que
présente le traitement pour les droits et libertés des personnes
physiques, le responsable du traitement met en oeuvre, tant au moment de la
détermination des moyens du traitement qu'au moment du traitement
lui-même, des mesures techniques et organisationnelles
appropriées, telles que la pseudonymisation, qui sont destinées
à mettre en oeuvre les principes relatifs à la protection des
données, par exemple la minimisation des données, de façon
effective et à assortir le traitement des garanties nécessaires
afin de répondre aux exigences du présent règlement et de
protéger les droits de la personne concernée. »
La notion de privacy by design n'est ni
française, ni nouvelle. Ce concept est employé pour la
première fois en 1995, dans le rapport conjoint élaboré
par les autorités de protection de la vie privée canadienne et
hollandaise intitulé « Technologies renforçant la
protection de la vie privée : le chemin vers l'anonymat»
90. Les autorités, déjà conscientes de la
nécessité de protéger les données,
démontrée dans le volume 1, proposent des solutions techniques et
organisationnelles détaillées dans le volume 2 de ce rapport.
Le privacy by design a ainsi été développé
pour combler l'écart entre les tendances du marché et les
réglementations91. En effet, le privacy by design
est intimement lié aux technologies renforçant la protection
de la vie privée92, appelées Privacy Enhanced
Technologies (PETs). Développées
dès les années 1970
86 P. Pucheral, A. Rallet, F. Rochelandet,
Célia Zolynski, op. cit., p.89-99
87 G. Loiseau, « De la protection
intégrée de la vie privée (privacy by design) à
l'intégration d'une culture de la vie privée »,
Légipresse 2012/300, p. 712.
88 Information Commissioner's Office, «Data
protection by design and default», 2019
89 Règlement n? 2016/679
90 A. Cavoukian, J. Borking,
«Privacy-Enhancing Technologies: The Path to Anonymity», 1995
p.7
91 G. Rostana, A. Bekhardi, B. Yannou, «From
privacy by design to design for privacy», ICED, Canada, p. 2
92 R. Hes, J. J. Borking, Information and Privacy
Commissioner/Ontario of Canada , «Privacy-Enhancing Technologies: The
Path to Anonymity» 1995
- 16 -
INTRODUCTION
par D. Chaum, ces technologies visent à construire des
systèmes prenant en considération la vie privée tout au
long du cycle de vie du système93.
C'est une quinzaine d'années plus tard que la
Commissaire à l'information et à la vie privée de
l'Ontario, A. Cavoukian publie les sept principes fondateurs du privacy by
design94 qui sont les suivants :
· proactif et non réactif, préventif et non
curatif
· le respect de la vie privée comme paramètre
par défaut
· la vie privée intégrée à la
conception
· fonctionnalité complète - gagnant-gagnant
et non perdant-perdant
· protection intégrale tout au long du cycle
· visibilité et transparence - gardez l'esprit
ouvert
· respect de la vie privée de l'utilisateur -
recentrer autour de l'utilisateur
Ainsi, la conformité à ces principes suppose
d'adopter une politique tant technique qu'organisationnelle, de « data
responsable95 ». Cette vision vise un double objectif :
recentrer le traitement des données autour de l'utilisateur et imposer
une prise de conscience par des pratiques concrètes96. Il
faut toutefois interpréter ces principes davantage comme une
propriété plutôt que des instructions à respecter.
Dès 2014, l'ENISA recommandait97 de nuancer l'application de
ces principes : « l'approche holistique est prometteuse, mais elle
n'est pas assortie de mécanismes permettant d'intégrer la vie
privée dans le processus de développement d'un
système98 ».
Ce principe acquiert en 2010 une portée internationale
lors de la 32è conférence internationale des
Commissaires de la protection des données et de la vie
privée99. Les deux premiers points de la résolution
reconnaissent le privacy by design comme une composante essentielle de
la protection de la vie privée et encouragent l'adoption des 7 principes
du privacy by design. Le privacy by design a également
été consacré à l'échelle de l'Union
Européenne à l'article 25 du RGPD. En 2018, le Conseil de
l'Europe a modernisé la Convention n°108 de 1981 qui impose
désormais des obligations complémentaires aux responsables du
traitement et sous-traitants de prendre « des mesures techniques et
organisationnelles tenant compte des implications du droit
93 G. Danezis, J. Domingo-Ferrer, ENISA, «
Privacy and Data protection by design - form policy to engineering»,
décembre 2014, p. 5
94 A. Cavoukian, « Privacy by Design, the 7
foundational principles», 2009
95 P. Pucheral, A. Rallet, F. Rochelandet,
Célia Zolynski, « La Privacy by design : une fausse bonne solution
aux problèmes de protection des données personnelles
soulevés par l'open data et les objets connectés ? »,
Legicom, Victoires open data : une révolution en marche,
Editions, 2016, p.89-99
96 A. Cavoukian, «Operationalizing Privacy by
Design: A Guide to Implementing Strong Privacy Practices », 2012, p.15
97 G. Danezis, J. Domingo-Ferrer, ENISA, Privacy
and Data protection by design, op. cit., p. 2
98 Ibid., p. 6
99 Data Protection and Privacy Commissioners,
«Resolution on Privacy by Design», 2010
- 17 -
INTRODUCTION
à la protection des données à
caractère personnel à tous les stades du traitement des
données1°° ».
La protection des données dès la conception
consacrée à l'article 25 du RGPD se conçoit donc de pair
avec le nouveau principe de responsabilisation du responsable du traitement
introduit dans le RGPD, également appelé «
accountability ». Ce principe impose une proportionnalité
entre l'intérêt du traitement et la protection des données
personnelles. Il requiert aussi la mise en oeuvre d'une analyse de risque, qui
privilégie une approche pragmatique et rejette une approche englobante.
Le risque généré par le traitement des données
à caractère personnel sera donc vecteur du niveau de
conformité du responsable du traitement101. Ce principe
permet enfin d'intégrer tous les stades du traitement des données
à caractère personnel, de la création des outils de
collecte, au traitement ainsi qu'aux méthodes d'exploitations des
données. C'est notamment pour cette raison que les autorités de
régulation encouragent ce principe lors du développement de
nouveaux usages102. Néanmoins, les obligations du RGPD
restent imprécises quant aux obligations à
respecter103.
Ainsi, le privacy by design est un concept
polymorphe. Néanmoins il ne doit ni être interprété
comme un principe général, ni limité à l'usage des
technologies améliorant la protection de la vie privée, mais
comme un processus impliquant des composants techniques et
organisationnels variés, qui implémentent les principes de vie
privée et de protection des données104. Ce
concept impose notamment de prendre en compte la protection des données
personnelles tout au long du cycle de vie du projet, apprécier le
degré de rigueur d'application du principe selon les risques
générés par le traitement, mettre en oeuvre des mesures
appropriées et effectives, et intégrer les garanties
définies au traitement105.
o Le privacy by default
L'article 25 du RGPD dispose dans son deuxième
paragraphe de l'obligation du responsable du traitement de mettre en place une
protection des données par défaut :
« Le responsable du traitement met en oeuvre les
mesures techniques et organisationnelles appropriées pour garantir que,
par défaut, seules les données à caractère
personnel qui sont nécessaires au regard de chaque finalité
spécifique du traitement sont traitées. Cela s'applique à
la quantité de données à caractère
personnel
100 Conseil de l'Europe, Convention 108 +, «
Convention pour la protection des personnes à l'égard du
traitement des données à caractère personnel »,
mai 2018
101 Ibid
102 P. Pucheral, A. Rallet, F. Rochelandet, Célia
Zolynski, op. cit. p. 89-99
103 G. Rostana, A. Bekhardi, B. Yannou, op. cit., p.
2
104 G. D'acquisto, J. Domingo-ferrer, ENISA, « Privacy by
design in big data», décembre 2015, p.21
105 EDPS, «Avis préliminaire sur le respect de la
vie privée dès la conception», avis 5/2018, 31 mai 2018, p.
7
- 18 -
INTRODUCTION
collectées, à l'étendue de leur
traitement, à leur durée de conservation et à leur
accessibilité. En particulier, ces mesures garantissent que, par
défaut, les données à caractère personnel ne sont
pas rendues accessibles à un nombre indéterminé de
personnes physiques sans l'intervention de la personne physique
concernée. »
L'autorité de contrôle anglaise analyse la
protection des données par défaut comme un mécanisme qui
requiert seulement de traiter la donnée nécessaire et pour une
finalité déterminée. Il s'agit donc d'un concept
profondément lié aux principes de minimisation des données
et de limitation des finalités. Autrement dit106 : «
La protection des données par défaut signifie qu'il faut
spécifier la donnée avant de débuter le traitement,
informer de manière appropriée les personnes et ne traiter que
les données dont vous avez besoin pour atteindre votre objectif. Il
n'est pas nécessaire d'adopter une solution de type « par
défaut sans données à caractère personnel ».
Ce que vous devez faire dépend des circonstances de votre traitement et
des risques encourus par les personnes. » Le privacy by
default s'incarne par exemple par le recours à une case
pré-cochée en cas de collecte du consentement.
Conformément au considérant 32 du RGPD, une case
pré-cochée, et encore moins un silence, ne constituent un
consentement licite de la personne concernée pour accepter la politique
de confidentialité et accéder au site internet. Par
conséquent, le fait de prévoir systématiquement des cases
devant être cochées par l'utilisateur lui-même constitue une
mesure de protection des données par défaut. L'Agence
Européenne chargée de la Sécurité des
Réseaux et de l'Information (ENISA) recommande aux
autorités de clarifier leurs attentes sur l'application concrète
du principe de privacy by default107.
Dans le cas des systèmes d'information, l'application
de la protection des données par défaut vise le
paramétrage par défaut, soit le système
préconfiguré. Ce paramétrage est nécessaire afin de
permettre une navigation fluide sans imposer une multitude de choix à
l'utilisateur. Il s'agit donc d'un paramètre en «
opt-in108 », qui s'applique sans le consentement de
l'utilisateur. Néanmoins, le consommateur doit conserver la
possibilité de choisir un autre paramétrage, en «
opt-out109 »110. Le degré de
configuration s'apprécie au cas par cas111. L'ENISA
recommande112 pour garantir ce principe de minimiser la
quantité, l'étendue, la
106 Information Comissioner's Office, «Data protection
by design and default», 2019
107 M. Hansen, K. Limniotis, ENISA, « recommendations on
shaping technology according to GDPR provisions», décembre 2018,
p.6
108 L'avis de l'utilisateur est requis
109 L'avis de l'utilisateur n'est pas requis
110 M. Hansen, K. Limniotis, ENISA, recommendations on GDPR
provisions, op cit., p.11
111 Ibid., p.16
112 Ibid., p.17
- 19 -
INTRODUCTION
période et l'accessibilité de la donnée
personnelle. Le concept de « privacy by default » inclut le
principe de « Security by default113 ».
Le privacy by default cible donc
l'application des principes du RGPD en intégrant les choix et les
besoins des individus dès la conception des
données114.
Dès lors, le privacy by default et le
privacy by design sont profondément liés dans la mesure
où la nécessité d'un paramétrage par défaut
favorable au respect de la vie privée est aussi importante que la
capacité pour l'utilisateur à faire évoluer son
choix115. Un équilibre est d'autant plus nécessaire
à trouver que des études démontrent les effets sur les
personnes concernées. En effet, rendre le choix actif par défaut
impacte davantage le comportement de l'utilisateur qu'un choix
prédéterminé par les développeurs.116
6. Mise en oeuvre du privacy by design et by default dans
un traitement d'intelligence artificielle
Les principes de protection des données dès la
conception et par défaut disposent d'une obligation incombant au
responsable du traitement de veiller à respecter l'ensemble des
principes du RGPD tout au long du cycle de vie de la donnée, en mettant
en place des mesures techniques et organisationnelles. Or, le traitement
spécifique par un processus automatisé, ce qui est le cas de
l'intelligence artificielle, fait l'objet de dispositions
supplémentaires117, notamment en matière d'explication
du raisonnement algorithmique118 et de décisions
intégralement automatisées119. Il convient donc
d'analyser les spécificités de ce régime, même si
elles ne ciblent qu'une partie restrictive des traitements par un logiciel
d'intelligence artificielle120.
Par conséquent, la problématique de ce
mémoire sera :
Comment être conforme à ces principes
dans le cadre d'un traitement par un logiciel
d'intelligence artificielle ?
113 Ibid., p.20
114 Ibid., p.12
115 Ibid., p.13
116 P. A. Keller, ... «Enhanced active choice: A new
method to motivate behavior change», Journal of Consumer Psychology
21, p.376-383, 2011
117 C. Villani, Rapport «Donner un sens à
l'intelligence artificielle», 2018, p. 28
118 Art. 15.1 RGPD
119 Art. 22 RGPD
120 G. Malgieri, « Accountable AI: myth andrealities
», Legal Edhec,Webinar, 13 mai 2020
- 20 -
INTRODUCTION
Dans le rapport sur l'intelligence artificielle dirigé
par C. Villani,121 la difficulté d'encadrer le traitement des
logiciels d'intelligence artificielle est soulignée. Il s'agit d'un
« angle mort » de la législation actuelle, du fait
que l'IA ne traite pas que des données à caractère
personnel, et n'est donc pas intégralement soumise aux dispositions du
RGPD. L'intelligence artificielle ne fait pas non plus l'objet d'une
régulation à l'échelle européenne122, ni
d'exigences ou de lignes directrices spécifiques123.
L'efficacité de la mise en oeuvre des principes du RGPD est en
parallèle discutée, à l'heure où les conditions de
confidentialité de Facebook sont plus longues que la Constitution
américaine124.
Ce mémoire vise à dépasser
l'oxymore traditionnel big data / vie privée125,
afin d'aspirer à un objectif de « big data et vie
privée126 ». Cette réflexion s'aligne avec
les recommandations de la Commission Européenne qui
affirme127 et réaffirme128 de «
faire le lien entre les attentes légitimes (...) et le paysage actuel de
l'intelligence artificielle ».
Le big data bouleverse la vie privée dans la
mesure où il réduit le contrôle et la transparence,
augmente la réutilisation des données, et permet la
ré-identification des individus129. De nouvelles technologies
doivent être anticipées telle que la technologie quantique qui
pourrait augmenter la capacité de traitement de manière
exponentielle130. De nouvelles pratiques qui participent à
l'essor du big data131 tels que l'open
data132 et l'internet des objets133 posent
également de nouvelles questions.
Si le choix du paramètre par défaut n'est pas
nouveau dans la conception d'un logiciel, il n'en est pas de même du
principe de «priorité à la protection des
données» imposé par le RGPD134 qui constitue
une approche nouvelle pour les développeurs. Pourtant, la
conformité de ces principes impose une Protection Intégrée
de la Vie Privée. Il s'agit d'« intégrer des mesures
protectrices directement dans les systèmes informatiques, les pratiques
d'affaires et
121 C. Villani, Rapport «Donner un sens à
l'intelligence artificielle», 2018, p. 148
122 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit
123 EDPB, «Response to the MEP Sophie in't Veld's letter
on unfair algorithms», 29 janvier 2020, p. 5
124 N. Bilton «Price of Facebook Privacy? Start
Clicking», The New York Times, 12 mai 2010
125 G. D'acquisto, J. Domingo-ferrer, ENISA, « Privacy by
design in big data», décembre 2015, p.18
126 Ibid., p.49
127 Commission Européenne, robustness and
Explainability of Artificial Intelligence, op. cit., p. 5
128 Ibid., p. 5
129 G. D'acquisto, J. Domingo-ferrer, ENISA, « Privacy by
design in big data», décembre 2015, p.13
130 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p.4
131 36th Conference of Data protection and Privacy
commissioners, «resolution big data», 2014
132 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.29 et s.
133 36th Conference of Data protection and Privacy
commissioners, «Mauritius Declaration on the Internet of
Things», 14 octobre 2014
134 M. Hansen, K. Limniotis, ENISA, recommendations on GDPR
provisions, op cit., p.5
- 21 -
INTRODUCTION
l'infrastructure en réseau135
». Les PETs permettent une garantie technique de ces principes. Des
initiatives existent et portent leurs fruits136. La Commission
européenne rappelle qu'il est essentiel de trouver un équilibre
entre les attentes légitimes de protection de la vie privée et le
paysage scientifique de l'intelligence artificielle, d'autant plus que le RGPD
ne prévoit pas d'outils et de normes techniques137.
Par ailleurs, ces techniques ne portent pas atteinte à
l'innovation138. Pour le Contrôleur Européen de
Protection des Données139, ce cadre réglementaire de
protection des données n'est pas un frein à l'innovation, mais un
vecteur essentiel du développement d'une technologie d'intelligence
artificielle durable. Face à cette innovation perpétuelle de la
technologie, la réflexion éthique est nécessaire pour
trouver un équilibre entre la « liberté de droit
» et la « liberté de fait », avant
même d'élaborer une régulation140. Dès
lors, malgré l'effet de mode de ces concepts141 et pour
paraphraser le Contrôleur Européen de Protection des
Données, all we need is privacy by design and privacy by
default142.
Il convient donc, dans un premier temps d'analyser
l'application théorique du privacy by design et du privacy
by default dans le cadre d'un traitement effectué par un logiciel
d'intelligence artificielle et des questions sous-jacentes
(Première partie), pour dans un second temps, proposer
un cadre d'application pratique, respectueux des données à
caractère personnel (Seconde partie).
135A. Cavoukian, D stewart, B. Dewitt, «
Gagner sur tous les tableaux Protéger la vie privée à
l'ère de l'analytique » Deloitte Canada, 2014, p.1
136 F. Baudot, « Un service de localisation
décentralisé et privacy by design entre appareils »,
LINC, 24 octobre 2019
137 Commission Européenne, « Une stratégie
européenne pour la donnée », 19 février 2020, p.
12
138 A. Cavoukian, D stewart, B. Dewitt, Gagner sur tous les
tableaux, op. cit.
139 EDPS, «Press Statement - Data Protection and
Competitiveness in the Digital Age», 10 juillet 2019
140 LINC, «Éric Fourneret : « Le
numérique appelle la pensée », 3 avril 2020
141 A. E. Waldman, «Privacy's Law of Design», UC Irvine
Law Review, 8 octobre 2018, p.63
142 EDPS, «Speech on «All we need is L....Privacy
by design and by default», 29 mars 2017
- 22 -
PREMIERE PARTIE
Une nécessaire adaptation des principes de
protection des données
à caractère personnel à
l'intelligence artificielle
|
|
La mise en oeuvre du privacy by design et du
privacy by default dans le cadre d'un traitement réalisé par
un logiciel d'intelligence artificielle se heurte aux principes
intrinsèques de la protection des données personnelles
consacrés par le RGPD. Le Règlement étant
technologiquement neutre, il n'a pas pu prévoir des solutions à
des questions techniques. Il convient donc de dépasser cette
contradiction en adaptant ces principes à des objectifs
réalisables par l'intelligence artificielle par le biais de la norme
éthique. En étant réellement effective, la norme
éthique pourra guider le responsable du traitement dans la conception
et/ ou l'utilisation de l'intelligence artificielle (Titre 1).
La réflexion en amont du traitement se voit
également bouleversée et amène à une adaptation
spécifique aux problématiques de l'intelligence artificielle.
Conformément au principe d'autorégulation, le responsable du
traitement est tenu d'un devoir de responsabilisation à l'égard
du traitement qu'il effectue. Le privacy by design et le privacy
by default imposent à cet effet de mettre en oeuvre des mesures
techniques et organisationnelles adaptées. Ce dernier devra alors
mesurer le risque adéquat du traitement et mettre en oeuvre des outils
adaptés pour y pallier. Il s'avère ainsi nécessaire de
faire évoluer la notion de risque en prenant en compte les
spécificités techniques de l'intelligence artificielle (Titre
2).
- 23 -
Titre 1 : L'application des principes de protection des
données à caractère personnel à l'intelligence
artificielle
Le RGPD s'applique à tout traitement de données
à caractère personnel, y compris les traitements
automatisés (art. 2. 1 RGPD). Par conséquent, dès lors
qu'un logiciel d'intelligence artificielle utilise comme entrée des
données à caractère personnel, les dispositions du
Règlement s'appliquent. Néanmoins, les spécificités
techniques de cette technologie défient les principes constituant
l'essence même du texte (Chapitre 1). Respecter l'objectif de protection
des données personnelles amène aussi à envisager des
principes spécifiques à ce régime (Chapitre 2).
Chapitre 1 : Les principes directeurs du RGPD, des
principes limités
L'usage de l'intelligence artificielle lors du traitement de
données à caractère personnel révèle les
zones d'ombres du RGPD tant dans ses définitions (Section 1) que ses
principes directeurs (Section 2). Les principes de privacy by design
et de privacy by default peuvent alors servir de balance pour une
réglementation efficace (Section 3).
Section 1 : La remise en question des
définitions par l'intelligence artificielle
L'intelligence artificielle questionne tant la
définition de donnée à caractère personnel
(§1) que la possibilité de ré-identifier des personnes
concernées (§2).
§1. La distinction entre données à
caractère personnel, données pseudonymes, données anonymes
Le RGPD s'applique dès lors qu'un traitement cible des
données à caractère personnel (art. 2.1 RGPD). Une
donnée à caractère personnel est une donnée qui
permet d'identifier directement ou indirectement une personne (art. 4.1 RGPD).
Par conséquent, les données anonymes ne sont pas des
données à caractère personnel. Elles sont définies
au considérant (26) du Règlement comme les «
informations ne concernant pas une personne physique identifiée ou
identifiable ». En revanche, les données pseudonymes sont des
données à caractère
- 24 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
personnel143. Elles ne permettent pas de
ré-identifier des personnes concernées directement, mais
indirectement via des mécanismes tels que des clés de
ré-identification par une technique de hachage144, ou de
stockage sur des espaces distincts.
Données anonymes
|
Données à caractère personnel
|
|
Autres données
|
Identification impossible
|
Personnes identifiables
indirectement
|
Personnes identifiables directement
|
Non soumises au RGPD
|
Soumises aux dispositions du RGPD
|
|
Une donnée anonyme peut l'être soit par nature,
soit en faisant l'objet d'un processus d'anonymisation. L'anonymisation
empêche la ré-identification de la personne concernée de
manière définitive145. Dans un avis146 de
2014, le Groupe de travail « article 29 » sur la protection des
données (G29) considère qu'une donnée est
anonymisée si et seulement si aucun des trois critères suivants
n'est rempli. Si un de ces critères est rempli, les données ne
sont pas anonymes.
· L'individualisation : Est-il toujours
possible d'isoler un individu ?
Il s'agit de la «
possibilitéì d'isoler une partie ou la
totalitéì des enregistrements identifiant un individu
dans l'ensemble de données »147.
· La corrélation : est-il
toujours possible de relier entre eux les enregistrements relatifs à un
individu ?
Cela consiste en « la
capacitéì de relier entre elles, au moins, deux
enregistrements se rapportant àÌ la même
personne concernée ou à un groupe de personnes concernées
(soit dans la même base de données, soit dans deux bases de
données différentes) ».
· L'inférence : peut-on
déduire des informations concernant un individu ?
Il s'agit de « la
possibilitéì de déduire, avec un degré
de probabilité élevé, la valeur d'un attribut à
partir des valeurs d'un ensemble d'autres attributs. »
Par ailleurs, le G29 insiste sur le fait que les techniques du
numérique évoluent et qu'il faut donc s'adapter à
l'état de l'art, c'est-à-dire à l'évolution
technique de chaque innovation148 : « Les
éléments contextuels ont leur importance : il faut prendre en
considération «l'ensemble»
143 Art. 4.5 RGPD
144 La fonction de hachage permet de transformer une
donnée en une suite définie de chiffres et de lettres.
145 Conseil d'État, décision n° 393174, RJDA
5/17 n° 386, 8 février 2017
146 G 29, Avis 05/2014 sur les Techniques d'anonymisation,
0829/14/FR WP216, 2014 p.3
147 Ibid., p.13
148 Ibid., p.7
- 25 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
des moyens «susceptibles» d'être
«raisonnablement» utilisés à des fins d'identification
par le responsable du traitement ou par des tiers, en prêtant une
attention particulière aux moyens que l'état actuel de la
technologie a rendu récemment «susceptibles» d'être
«raisonnablement» mis en oeuvre (compte tenu de l'évolution de
la puissance de calcul et des outils disponibles). »
Le Conseil d'État149, dans sa
décision JCDecaux du 8 février 2017 statuant en
appel150 sur la notion d'anonymisation, s'inspire des
critères du G29, même si cet avis est dépourvu d'une valeur
normative. Il considère les données comme anonymisées
lorsque « l'identification de la personne concernée,
directement ou indirectement, devient impossible que ce soit par le responsable
du traitement ou par un tiers. Tel n'est pas le cas lorsqu'il demeure possible
d'individualiser une personne ou de relier entre elles des données
résultant de deux enregistrements qui la concernent. » En
l'espèce, le Conseil d'État considère que les
données traitées sont des données pseudonymes et non
anonymes. Le procédé utilisé est un processus de hachage,
irréversible, mais les données hachées peuvent encore
contenir des indices de singularisation pouvant être retrouvés par
les techniques d'inférence et de corrélation. Comme le
résument151 R. Perray et J. Uzan-Naulin, le Conseil
d'État s'inspire ici implicitement du droit souple du G29. Les
critères des procédés d'anonymisation prennent ainsi une
valeur normative de droit dur.
On pourra donc considérer des données comme
anonymes dès lors qu'aucun des trois critères du G29
(individualisation, corrélation, inférence) ne sont remplis et
que l'état de la technique ne permet pas de ré-identifier ces
données.
§2. Le risque de ré-identification à
l'heure du big data
Dès lors, quel est l'état de l'art à
l'heure du big data ? Le développement de nouveaux usages tels que
l'open data et l'internet des objets posent de nouvelles contraintes
aux processus de pseudonymisation et d'anonymisation. L'open data
offre la possibilité de regrouper des bases et ainsi de
ré-identifier directement ou indirectement des personnes. Ainsi, de
nombreuses études confirment scientifiquement152
l'impossibilité de rendre des données totalement anonymes. C'est
pour ces raisons qu'une grande majorité de la doctrine à l'instar
de A. Jomni153 et R. Perray et J. Uzan-naulin154
s'interroge sur la notion même de données à
caractère
149 Ibid., p.7
150 CNIL, Délib. n°2015-255,16 juillet 2015
151 R. Perray, J. Uzan-Naulin, « Existe-t-il encore des
données non personnelles ? Observations sous Conseil d'État, 8
février 2017, n° 393714, Société JCDecaux »,
Dalloz IP/IT, 2017, p. 286
152 A. Narayanan, V. Shmatikov, «Robust De-anonymization
of Large Sparse Datasets», IEEE Symposium on Security and
Privacy, 2008, p.111-125
153 A. Jomni, « RGPD : un atout ou un frein pour la
sécurité ? », Dalloz IP/IT, p.352, Juin 2019
154 R. Perray, J. Uzan-Naulin, Existe-t-il encore des
données non personnelles ? op. cit.
- 26 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
personnel. Cette idée est reprise dans le rapport
Villani155, qui démontre en s'appuyant sur les travaux d'H.
Nissenbaum que les données sont par essence contextuelles et peuvent
fournir des informations sur un ou plusieurs individus. Par conséquent,
dans le cadre de l'apprentissage automatique non supervisé, le
traitement à grande échelle peut permettre d'effectuer des
corrélations entre des individus. L'institut Montaigne
partage156 cette même approche, en considérant que les
métadonnées telles que le nombre de clics peuvent se transformer
en données à caractère personnel à partir du moment
où il révèle des informations sur nos humeurs ou notre
état de santé. Dans cette perspective, la distinction classique
entre données personnelles et données anonymes n'est plus
pertinente.
De plus, l'usage du big data et de l'intelligence
artificielle permet de transformer des données brutes en données
identifiantes par regroupement a posteriori. Or, le Règlement
s'applique dès que la donnée collectée est une
donnée à caractère personnel, donc a priori.
Cependant, avec le big data, la donnée devient une
donnée à caractère personnel lors du traitement alors
qu'elle ne l'était pas lors de la collecte. C'est pourquoi ce
prérequis de donnée à caractère personnel n'est
plus pertinent157.
Malgré les limites techniques du processus
d'anonymisation et sous réserve d'une documentation
détaillée, les critères du G29 permettent néanmoins
de justifier d'un processus d'anonymisation juridiquement conforme. Le RGPD
impose en effet une obligation de moyens et non de résultat à cet
égard158. Le procédé d'anonymisation demeure
donc légal en l'état de la réglementation et permet ainsi
de ne plus être soumis au RGPD.
Section 2 : La confrontation des principes directeurs
du RGPD à la technologie de l'IA
Les algorithmes du big data permettent de traiter une
immense quantité de données qui échappe à
l'expertise humaine. Ce fonctionnement est aux antipodes de la
réglementation du RGPD159 fondée sur des principes
directeurs (§1, §2). Ces algorithmes remettent également en
question la validité du consentement des personnes concernées,
qui ne sont pas capables de mesurer l'ensemble des risques induits liés
à leur utilisation (§3).
155 C. Villani, « Donner un sens à
l'intélligence artificielle », mars 2018, p.148
156 F. Godement «Données personnelles, comment
gagner la bataille ?» Institut Montaigne, décembre 2019, P.
41
157 A. Bensamoun, G. Loiseau « L'intégration de
l'intelligence artificielle dans certains droits spéciaux »,
Dalloz IP/IT, 2017, p. 295
158 B. Nguyen, « Survey sur les techniques
d'anonymisation : Théorie et Pratique », Journée CERNA
sur l'Anonymisation, p.50
159 P. Pucheral, A. Rallet, F. Rochelandet, Célia
Zolynski, op. cit., p. 89-99
- 27 -
L'application des principes de protection des données
à caractère personnel à l'intelligence artificielle
§1. Le Big data face au principe de minimisation
Les principes du RGPD se placent en contradiction avec
l'essence même de l'intelligence artificielle. Pour fonctionner, cette
technologie nécessite de traiter des données massives,
caractérisées par les « 5 V : volume,
variété, vélocité, véracité, valeur
»160. L'intelligence artificielle nécessite une
grande consommation de données, conservées pour une longue
durée. Ce besoin va donc à l'encontre des principes de
minimisation et de durée de conservation du RGPD.
Par ailleurs, le principe de minimisation est par nature
antagoniste à l'objectif du big data qui nécessite une
grande quantité de données pour fonctionner. Ainsi,
l'efficacité du big data est inversement proportionnelle au
minimum requis nécessaire pour garantir le principe de
minimisation161.
§2. L'Intelligence artificielle face au principe de
finalité
A. Bensamoun et G. Loiseau soulignent162 l'aspect
irréalisable de cet objectif de garantir par défaut un traitement
strictement nécessaire à une finalité. C'est justement
l'accumulation, l'étendue et la durée qui rendent cette
technologie efficiente. Le logiciel d'intelligence artificielle traite des
masses unitaires et dynamiques et non des unités statistiques comme
c'est le cas traditionnellement. La quantité de données est alors
préférée à leur qualité. La finalité
est alors définie non pas au stade de la collecte mais au stade de
l'exploitation.
§3. Le paradoxe de la vie privée face au principe
de consentement
La notion de « privacy Paradoxe » est
née en 2001 dans une étude de B. Brown, qui met en
évidence163 un paradoxe entre les utilisateurs qui utilisent
des cartes de fidélité dans les supermarchés tout en se
plaignant de l'atteinte à leur vie privée. Le paradoxe de la vie
privée, qui peut se définir comme l'incohérence entre les
préoccupations relatives à la vie privée et notre
comportement en ligne, est d'autant plus d'actualité à l'heure
d'internet. K. Burkhardt préfère employer le terme de «
dilemme de la vie privée »164. L'usage
d'internet a modifié en profondeur la notion de vie privée qui
s'incarne désormais à la fois en ligne et hors ligne. Il est donc
préférable de parler de « privacy dilemma »,
dans la mesure où les utilisateurs doivent désormais choisir
entre utiliser un service ou partager leurs données. K. Burkhardt
souligne
160 A. Bensamoun, G. Loiseau, l'intégration de
l'intelligence artificielle dans certains droits spéciaux, op.
cit.
161 P. Pucheral, A. Rallet, F. Rochelandet, Célia
Zolynski, op. cit., p. 10
162 A. Bensamoun, G. Loiseau, l'intégration de
l'intelligence artificielle dans certains droits spéciaux, op.
cit.
163 B. Brown, «Studying the Internet
Experience», Publishing Systems and Solutions Laboratory HP
Laboratories Bristol, HPL-2001-49, 26 mars 2001, p.1
164 K. Burkhardt «The privacy paradox is a privacy
dilemma», Internet citizen, 24 août 2018
- 28 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
également la difficulté à chiffrer la
valeur de la donnée, ce qui complexifie la prise de décision dans
ce dilemme. Aux États-Unis, certains utilisateurs croient
néanmoins naïvement que les données de leur historique
valent l'équivalent d'un Big Mac165. La question de la
patrimonialisation des données est fallacieuse en Europe. La protection
des personnes concernées et de leurs droits y est
préférée et consacrée quel que soit la valeur de
leur donnée à caractère personnel.
Section 3 : Le privacy by design et by default, entre
innovation et protection des données
Le RGPD étant un texte de régulation
générique, il n'a pas pris en compte les
spécificités de l'intelligence artificielle166. Si les
dispositions du Règlement sont souples, la CNIL167
s'interroge sur la possible remise en cause de ces principes. Il est
envisageable de faire évoluer le droit afin de trouver un nouvel
équilibre entre protection des libertés, en l'espèce
protection des données personnelles, et progrès. C'est face
à ces nouveaux défis que P. Pucheral, A. Rallet, F. Rochelandet,
Célia Zolynski voient168 le « dilemme de la
régulation de la vie privée », qui doit combiner
innovation et protection de la vie privée. Dans cette perspective, il
est préférable de se concentrer sur l'objectif du privacy by
design plutôt que sur les moyens mis en oeuvre pour y
parvenir169, bien que le RGPD règlemente les moyens et non le
résultat170.
Pour ces auteurs, le principe de privacy by design
est difficile à mettre en oeuvre tant il fait écho aux
mécanismes techniques de protection de données tels que la
minimisation, l'anonymisation, la suppression et l'audibilité. De plus,
ces techniques sont difficiles à mettre en oeuvre dans les contextes
ouverts que sont l'open data, les objets connectés et le
Cloud. Néanmoins, la mise en oeuvre de ces principes met un
terme au « privacy paradox » en permettant à la
personne concernée de protéger ses données à la
fois de l'opérateur mais aussi de lui-même en agissant comme un
« filtre ».
Ainsi, le privacy by design, et il en va de
même pour le privacy by default, serait malgré tout
« l'instrument idoine pour opérer la balance des
intérêts entre protection et innovation171
».
165 L. F. Motiwalla, X.-B. Li, « Unveiling consumer's
privacy paradox behaviour in an economic exchange » PMCID: PMC5046831,
NIHMSID: NIHMS746547, PMID: 27708687, 3 octobre 2016
166 F. Godement «Données personnelles, comment
gagner la bataille ?» Institut Montaigne, décembre 2019, P. 165
167 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p. 39
168 P. Pucheral, A. Rallet, F. Rochelandet, Célia
Zolynski, op. cit., p.89-99
169 A. E. Waldman, «Privacy's Law of Design», UC
Irvine Law Review, 31 octobre 2018, p. 63
170 F. Godement «Données personnelles, comment
gagner la bataille ?» Institut Montaigne, décembre 2019, P.
40
171 P. Pucheral, A. Rallet, F. Rochelandet, Célia
Zolynski, op. cit., p.89-99
- 29 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
Chapitre 2 : La nécessité de créer
des principes spécifiques à l'IA
Comment implémenter le privacy by design et
le privacy by default ? Si le RGPD pose de nombreux principes auxquels
chaque responsable du traitement doit se soustraire, le traitement par un
logiciel d'intelligence artificielle pose de nouvelles questions non
prévues par le texte. L'éthique peut alors être une
solution pour réfléchir en amont du traitement et mettre en
oeuvre de mesures techniques et organisationnelles afin de guider une mise en
oeuvre effective du privacy by design et du privacy by
default.
A titre liminaire, il convient de distinguer les trois volets
du terme « éthique »172. Dans son sens
premier, l'éthique renvoie à la morale, dans laquelle Aristote
voyait173 la réponse à la question «
qu'est-ce qu'une vie bonne ? ». L'éthique fait
également référence à un ensemble de normes de
soft law élaborées et mises en oeuvre par les acteurs
privés, telles que la Responsabilité Sociétale des
Entreprises. Enfin, l'éthique est employée dans le vocable des
institutions publiques comme un élément qui préfigure au
droit, depuis la création du Comité Consultatif National
d'Éthique pour les sciences de la vie de la santé en 1983.
L'éthique de l'intelligence artificielle impose au préalable de
déplacer le curseur éthique en fonction de chaque usage et
évolution de la technique. Comme le rappelle la CNIL, «
L'évolution technologique déplace la limite entre le possible
et l'impossible et nécessite de redéfinir la limite entre le
souhaitable et le non souhaitable174 ». L'éthique
peut guider le responsable du traitement tant lors de la collecte (section 1)
que pour le traitement (section 2), lorsqu'elle est effectuée à
bon escient (section 3).
Section 1 : Des principes inhérents à la
collecte et au traitement des données
Les principes éthiques doivent guider le traitement
tout au long du cycle de vie de la donnée soit dès la collecte
(§1) et tout au long du traitement (§2).
§1. Les principes liés à la collecte des
données
1.1. Des données de qualité, quantité
et pertinence adéquates
L'impératif éthique de l'usage de l'IA commence
par la surveillance des données collectées en veillant à
leur qualité, leur quantité et à ce que leur pertinence
soient adéquates175.
La « qualité » des données
impose de fournir des données vérifiées pour obtenir un
résultat fiable.
172 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.24
173 Aristote, « Éthique à Nicomaque »
174 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.25
175 Ibid., p.39
- 30 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
La « quantité » de données
doit être adaptée au besoin du traitement, car elle risque de
nuire à la qualité des données. Cathy O'Neil illustre ce
propos par le cas du licenciement d'enseignants à la suite du
résultat d'un logiciel d'évaluation alors qu'ils jouissaient
d'une forte notoriété176. En l'espèce, les
critères du logiciel se basaient sur les résultats scolaires des
élèves, qui peuvent s'expliquer par de nombreux facteurs autres
que la qualité de l'enseignement. Ainsi, la quantité des
données ne doit pas résulter d'une agrégation
irréfléchie de données.
Enfin, la « pertinence » des données
doit être analysée. Cette notion signifie qu'il faut
réfléchir aux biais qui peuvent exister au moment de la
collecte.
Ainsi, les algorithmes peuvent être utilisés
à bon escient lorsque les données utilisées pour le
traitement sont sélectionnées avec la rigueur de ces trois
principes. Il est important de noter que sans cette rigueur, les algorithmes ne
sont donc pas fiables et qu'un esprit critique reste indispensable.
1.2. Les principes FAIR
La Commission Européenne encourage par ailleurs la
promotion de données fiables et réutilisables par la mise en
place des principes FAIR177. Ces Principes visent à Trouver
la donnée, la rendre Accessible, Interopérable et
Réutilisable178.
§2. Les principes inhérents au traitement des
données pour un traitement d'IA 2.1. Les principes nationaux
La CNIL, dans son rapport sur les enjeux éthiques de
l'intelligence artificielle rédigé à la suite d'un
débat public179, émet deux principes
nécessaires à un usage éthique de ces logiciels, qui sont
le principe de loyauté et le principe de vigilence.
Le principe de loyauté est basé sur la
formulation émise par le Conseil d'État vis-à-vis des
plateformes180. Il s'agit ici d'élargir cette notion et
d'intégrer une vision collective à la vision individuelle de la
loyauté.
Le principe de vigilance ou de réflexivité vise
à « répondre dans le temps au défi
constitué par le caractère instable et imprévisible des
algorithmes d'apprentissage ». Concrètement, il s'agit
176 CNIL, les enjeux éthiques des
algorithmes et de l'intelligence artificielle, op. cit., p.39
177 Commission Européenne, «turning fair into
reality», final report and action plan from the European Commission
Expert Group on FAIR data, 2018, p.19
178 M. Wilkinson, M. Dumontier, I. Aalbersberg, « The
FAIR Guiding Principles for scientific data management and
stewardship». Sci Data 3, 160018, 2018
179 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p. 6
180 J. Richard, T. Areau, A. Delorme, Conseil d'État,
« Le numérique et les droits fondamentaux », rapp.
Annuel. 2014, P.337
- 31 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
de mettre en oeuvre des procédures concrètes
posant des questionnements réguliers à tous les acteurs de la
chaîne algorithmique.
Ces deux principes s'articulent en parallèle des
principes instaurés par le RGPD qui sont l'obligation d'intervention
humaine dans la prise de décision algorithmique181,
l'intelligibilité et la responsabilité des systèmes
algorithmiques182.
2.2. Les principes internationaux et européens
L'OCDE encourage183 l'adoption des principes de
croissance inclusive, développement durable et bien-être ; valeurs
centrées sur l'homme et équité ; transparence et
explicabilité ; robustesse, sécurité et
sûreté ; responsabilisation. Le G20 a par ailleurs adopté
les mêmes recommandations184. Le rassemblement mondial des
autorités de régulation a également émis une
déclaration sur l'éthique et la protection des données
dans l'intelligence artificielle185.
La Commission européenne a aussi mis en place un cadre
pour une IA digne de confiance, qui se traduit par les principes de respect de
l'autonomie humaine, de prévention du préjudice,
d'équité, et d'explicabilité186.
Intégrer les principes éthiques de
l'intelligence artificielle est essentiel pour garantir une
confidentialité dès la conception et par défaut. Les
principes doivent néanmoins être effectifs.
Section 2 : Des principes éthiques effectifs
Mettre en oeuvre une IA éthique suppose de ne pas
tomber dans les travers des principes éthiques. C. Castets-Renard liste
les écueils à éviter187.
Tout d'abord l'« Ethical shopping »
résulte d'une confusion et d'une saturation de l'utilisateur face
à la grande quantité de chartes éthiques. Cette
diversité est d'autant plus complexe qu'elle implique une multitude
d'acteurs (privés, institutionnels) et différents degrés
d'application des principes éthiques. Plus de 260 documents non
contraignants ont été produits ces quatre dernières
années188. Une synthèse de ces principes a
été effectuée par J. Fjeld, N.
181 Art. 10 LIL, et art. 22 RGPD
182 Art. 14.2.g) RGPD
183 OCDE, « Recommendation of the Council on Artificial
Intelligence », OECD/LEGAL/0449, 22 mai 2019
184 G20, « G20 Ministerial Statement on Trade and Digital
Economy », juin 2019, p.11
185 ICDPPC, « Declaration on ethics and data protection
in artifical intelligence», 23 octobre 2018
186 Commission Européenne, « Lignes directrices
pour une IA digne de confiance », 8 avril 2019
187 C. Castests-renard, « comment construire une
intelligence artificielle responsable et inclusive ? » recueil dalloz
2020, p.225
188 EUFRA, «AI policy initiatives (2016-2019)»,
4 novembre 2019
- 32 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
Achten, H. Hilligoss, A. Nagy, and M. Srikumar 189.
(cf. Annexe vi - Synthèse des principes éthiques pour
l'intelligence artificielle).
Cette complexité impose une analyse sémantique
des différences entre chaque norme et risque de créer des
confusions.
Un autre risque tend à ce que les acteurs n'aient pas
à se justifier a posteriori et n'améliorent pas leurs
chartes éthiques. La création du Comité ad hoc sur l'IA
(CAHAI) du Conseil de l'Europe peut constituer un cadre normatif adéquat
à l'adoption de normes éthiques190.
Le principe d'« Ethical Washing » se
traduit par le risque de fournir une information erronée ou
dépourvue d'application du fait du caractère non contraignant de
la norme éthique. Une grande partie des travaux de recherche vise
à définir des principes éthiques et non à
réfléchir aux manières de les mettre en oeuvre alors qu'il
est essentiel d'implémenter une « éthique dès la
conception »191. De nombreux articles de recherche
insistent sur le besoin de préférer des bonnes pratiques à
des concepts abstraits. Cette vision est notamment partagée par J.-P.
Besse, C. Castets-Renard et A. Garivier 192, et B. Wagner et S.
Delacroix193. L'informaticien, philosophe et président du
comité d'éthique du CNRS, J.-G. Ganascia partage cette
conception194, considérant qu'il est temps de s'entendre sur
des compromis concrets et non sur des grands principes.
Par ailleurs, l'« Ethical Lobbying »
illustre le risque de croire que les normes éthiques se suffisent en
elles-mêmes à réguler les comportements et ainsi
empêcher toute sorte de législation de droit dur applicable aux
acteurs privés.
Enfin, la norme éthique peut porter atteinte aux droits
fondamentaux dans la mesure où le fait d'intégrer ces droits
à des objectifs éthiques risque d'induire en erreur et de les
vider de leurs caractères non négociables et non optionnels.
C'est pour cela que C. Castets-Renard critique le fait que les «
droits fondamentaux » soient intégrés au concept
d'« objectif éthique » dans le rapport sur les lignes
directrices pour une IA digne de confiance rédigé par le groupe
d'experts désignés par la Commission européenne.
189 J. Fjeld, N. Achten, H. Hilligoss, A. Nagy, and M.
Srikumar, «Principled Artificial Intelligence: Mapping Consensus in
Ethical and Rights-Based Approaches to Principles for AI», Berkman
Klein Center Research Publication No. 2020-1, 15 janvier 2020
· Carte accessible ici
· Chronologie accessible ici
190 Y. Meneceur, « Pourquoi nous devrions (ne pas)
craindre l'IA », LinkedIn, 23 février 2020
191 N. Kinch, « How to design a Data Ethics
Framework », 9 décembre 2019
192 J.-P. Besse, C. Castets-Renard et A. Garivier, «
Loyauté des décisions algorithmiques », HAL-01544701.
Rapp. pour l'étude de la CNIL : Comment permettre à l'homme de
garder la main : les enjeux éthiques des algorithmes et de l'
intelligence artificielle, 2017
193 B. Wagner et S. Delacroix,» Constructing a
Mutually Supportive Interface between Ethics and Regulation,», 14 juin
2019
194 B. Leclercq, « Vie numérique : Place à
l'éthique », libération, 17 novembre 2019
- 33 -
L'application des principes de protection des données
à caractère personnel à l'intelligence
artificielle
Ainsi, face aux limites du RGPD, l'éthique
s'avère être un instrument essentiel pour guider l'utilisation des
données par des logiciels d'intelligence artificielle et ainsi respecter
la confidentialité dès la conception et par défaut.
Toutefois, des nombreux écueils relatifs à l'utilisation de la
norme éthique sont relevés et rendent difficile son
application.
- 34 -
Titre 2 : Les moyens d'autorégulation
adaptés à l'intelligence artificielle
Le traitement par un logiciel d'intelligence artificielle
impose, afin de respecter la protection des données dès la
conception et par défaut, de prendre en compte les
spécificités du risque engendré par l'IA (Chapitre 1), et
de développer des outils de conformité adaptés afin de
garantir l'autorégulation (Chapitre 2).
Chapitre 1 : Vers une nouvelle notion du risque
Les risques liés à l'intelligence artificielle
requièrent une réflexion spécifique en ce qui concerne
leur moment d'appréciation (Section 1), et leur nature (Section 2).
Section 1 : Le moment d'appréciation du risque
Les pratiques du big data, de l'internet des objets
et de l'open data, qui utilisent les logiciels d'intelligence
artificielle suscitent de nouveaux risques et incitent à une prise en
compte de ces derniers (§1).
§1. L'existence d'un risque en aval
L'analyse d'impact relative à la protection des
données nécessite d'évaluer les risques en amont du
traitement (art. 35 RGPD). Néanmoins, cette analyse préalable au
traitement est insuffisante195. P. Pucheral, A. Rallet, F.
Rochelandet, Célia Zolynski, soulignent le « paradoxe du
privacy by design », du fait que ce principe impose une
réflexion en amont alors que les problèmes ne pourront être
détectés et traités qu'en aval du traitement. Par exemple,
les procédés d'anonymisation offrent des garanties mais ne
peuvent empêcher le risque résiduel de ré-identification.
De plus, il est difficile d'anticiper toutes les utilisations
ultérieures de ces données et d'ainsi mesurer leur risque. Avant
le développement des réseaux sociaux et que le cas
d'espèce ne survienne, il était difficile d'envisager le fait que
les employeurs puissent utiliser les informations des comptes Facebook de leurs
employés pour contester un arrêt maladie.
Dans cette perspective, le risque doit s'analyser à la
fois en amont et en aval, en mettant en place une veille
régulière pendant tout le cycle de vie de la donnée
réutilisée. Les ajustements
195 P. Pucheral, A. Rallet, F. Rochelandet, C. Zolynski, op.
cit., p.89-99
- 35 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
en aval sont nécessaires pour préserver
l'équilibre entre protection et innovation. Pour préserver
à la fois la protection des données personnelles et leur
exploitation à des fins économiques, un ajustement ex-post
est requis. Ce compromis ne peut pas être effectué
ex-ante dans la mesure ou cet équilibre dépend de
l'utilisation, du type de données et du type d'usage des données,
qui sont des facteurs qui s'apprécient lors du traitement et non lors de
la collecte. P. Pucheral, A. Rallet, F. Rochelandet, Célia Zolynski
proposent une analyse196 intéressante pour encadrer les
pratiques d'open data et la collecte par les objets
connectés.
L'open data, en traitant des données
publiques, permet potentiellement d'obtenir des informations sur un individu
à partir de données publiques et permet ainsi la descente
d'informations. A l'inverse, les objets connectés favorisent une
remontée d'informations, obtenues à la source : l'individu.
Dès lors, on pourrait envisager le Principe de privacy by design
comme principe de prévention et le principe de privacy by
default comme principe de protection.
1.1. Le privacy by design comme principe de
prévention
Le principe de prévention est très utile dans
le cas de l'open data. On peut définir l'open data
comme une pratique visant à « ouvrir les bases de
données publiques à des fins de transparence démocratique
et d'innovation économique ou sociale, ces données étant
la source potentielle de nouveaux services. » Une donnée
publique est « une donnée communicable contenue dans un
document administratif ou, plus largement dans tout document détenu
(produit ou reçu) par une personne morale ou une personne privée
dans le cadre de l'exercice d'une mission de service public197
». La loi pour une république numérique198 et la
Directive du 20 juin 2019 relative à l'open data199
posent une obligation de rendre accessible certaines données publiques.
Il s'agit par exemple des données du nombre d'habitants de la
région PACA. Or, une donnée publique peut être une
donnée à caractère personnelle et donc être soumise
au RGPD. De plus, l'individu n'a pas de rôle actif dans le cadre d'un
traitement issu de l'open data. Le privacy by design agit
alors en tant que mécanisme de précaution pour empêcher
deux risques issus de la réutilisation des données.
Tout d'abord le « risque ex-ante »
consiste à éviter une exploitation préjudiciable des
données. Dans le cas d'un traitement d'open data, les
administrations ne sont pas toujours
196 Ibid., p.89-99
197 CNIL, CADA, « Guide pratique de la publication en
ligne et de la réutilisation des données publiques (« open
data ») », p.27
198 Loi n° 2016-1321 pour une République
numérique, 7 octobre 2016
199 Directive n° 2019/1024 du parlement européen
et du conseil concernant les données ouvertes et la réutilisation
des informations du secteur public, 20 juin 2019
- 36 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
préparées à l'ouverture des
données et ne prévoient pas les mesures techniques et
opérationnelles adaptées. Par exemple, les données du
nombre d'habitants de la région PACA ont été
anonymisées pour un usage statistique mais ces mesures n'ont pas
anticipé une réutilisation de ces informations à des fins
de profilage. Les données anonymes peuvent être exposées
à ce risque. En effet, les auteurs considèrent qu'une technique
d'anonymisation n'est efficace que lorsqu'elle a pour but d'atteindre un
objectif défini, par conséquent une approche globale est donc
impossible. Dans cet exemple, les données de genre des habitants de la
région PACA, croisées avec les données des lecteurs du
journal La Provence, permettent d'avoir un indice géographique sur le
nombre de femmes par ville et d'effectuer un ciblage des lectrices.
Par ailleurs, un « risque ex-post »
existe. Il consiste en la possibilité de ré-identifier des
données soit par un croisement de bases soit par l'évolution des
méthodes de traitement. Face à l'open data, il est
difficile pour les responsables du traitement de mesurer l'ampleur du risque de
ré-identification et la nécessité ou non d'adopter un
comportement de prévention optimal.
1.2. Le privacy by default comme principe de protection
Ce principe de protection est tout à fait pertinent
dans le cadre de l'utilisation d'objets connectés. Dans ce cas de
figure, le privacy by default agit comme un filtre entre l'individu et
le responsable du traitement. Il s'agit par exemple de l'enceinte Alexia
d'Amazon, qui nécessite de stocker les informations relatives à
la voix et au contenu de la requête pour fonctionner. L'enceinte stocke
alors les données à caractère personnel nécessaires
à son fonctionnement, qui pourront ensuite faire l'objet d'un traitement
ultérieur. L'idée ici est de protéger en amont l'individu
qui n'est plus capable de le faire lui-même, par le biais du privacy
by default.
Concernant les objets connectés, la pratique du
privacy by default vise à convertir une donnée brute en une
donnée agrégée ou brouillée afin de la rendre moins
identifiante.
Ce principe est également utile en matière
d'open data, où il vise à complexifier l'identification
ou la ré-identification des personnes concernées. La technologie
impose donc par défaut une confidentialité.
Pour pallier les risques de l'intelligence artificielle,
le privacy by design s'exerce comme principe de prévention et
le privacy by default comme principe de protection. Ces deux principes
doivent être mis en place simultanément.
- 37 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
Section 2 : Un risque inhérent au logiciel
d'intelligence artificielle
Une mise en oeuvre effective du privacy by design et
du privacy by default requiert des mesures techniques et
organisationnelles pour pallier les risques d'atteinte aux droits et
libertés des personnes concernées selon l'intensité du
risque (§1). Ce risque doit prendre en compte la spécificité
de la technologie d'IA (§2).
§1. L'appréciation du critère de risque
élevé
L'article 35.1 du RGPD dispose que l'analyse d'impact
relative à la protection des données est obligatoire et est
susceptible d'engendrer un « risque élevé pour les
droits et libertés des personnes physiques ». Le management du
risque ne peut se résumer à une analyse binaire de traitements
risqués ou non risqués. Cette pratique vise à
réduire les risques à un niveau acceptable au regard du
bénéfice potentiel et du contexte200. La CNIL propose
une méthode de mise en oeuvre d'une analyse d'impact à la
protection des données pas à pas201. Le risque peut
traditionnellement provenir de sources humaines internes, de sources humaines
externes et de sources non humaines202. Afin de mesurer le risque
lié au traitement, il convient d'envisager la conjugaison de la
gravité et de la vraisemblance du fait
générateur203. Les facteurs de gravité prennent
en compte le recours à de nouvelles technologies dans le traitement,
ainsi que la nature, le contexte, la portée et la finalité du
traitement. L'analyse de risque comprend le risque ainsi que les mesures
coercitives prévues pour y remédier204.
Certains types de traitement sont par nature susceptibles
d'engendrer un risque élevé. Tout d'abord, le paragraphe 3 de
l'article 35 du RGPD dresse une liste non exhaustive205 qui inclut
notamment les décisions automatisées produisant des effets
significatifs ou équivalant sur les personnes ; le traitement à
grande échelle de données sensibles ou relatives à des
infractions pénales ; ainsi que la surveillance systématique
à grande échelle d'une zone interdite au public. De plus,
conformément aux paragraphes 4 et 5 de cet article, la CNIL a
publié une liste d'opérations de traitements pour lesquelles
cette analyse d'impact est requise206 ou non
200 OCDE, «Enhancing Access to and Sharing of Data :
Reconciling Risks and Benefits for Data Re-use across Societies», 6
novembre 2019, 4.
201 CNIL, « Outil PIA : téléchargez et
installez le logiciel de la CNIL », 8 avril 2020
202 CNIL, « Analyse d'impact à la protection des
données : les bases de connaissances », février 2018,
p.2
203 CNIL, « Analyse d'impact relative à la
protection des données, la méthode », février
2018, p.6
204 CNIL, « Analyse d'impact relative à la
protection des données, application aux objets connectés
», février 2018, p. 33
205 G29, « Lignes directrices concernant l'analyse
d'impact relative à la protection des données (AIPD) et la
manière de déterminer si le traitement est «susceptible
d'engendrer un risque élevé» aux fins du règlement
(UE) 2016/679 », WP 248, 4 avril 2017, p. 9
206 CNIL, Délib. n° 2018-327, 11 octobre 2018
- 38 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
requise207. Sur cette liste figurent notamment les
traitements de profilage faisant appel àÌ des données
provenant de sources externes, les traitements qui présentent un risque
élevé du fait du croisement des bases de données et les
traitements dont l'usage est innovant.
Par ailleurs, le G29 a adopté des lignes
directrices208 listant les cas de figure susceptibles d'engendrer un
risque élevé. En compilant les paragraphes de l'article 35 et les
Considérants (91), (71), (75) et (91) du RGPD, le G29 liste les neuf
critères susceptibles de rendre le risque du traitement
élevé :
· évaluation ou notation
· prise de décisions automatisées avec effet
juridique ou effet similaire significatif
· surveillance systématique
· données sensibles ou données à
caractère hautement personnel
· données traitées à grande
échelle
· croisement ou combinaison d'ensembles de
données
· données concernant des personnes
vulnérables
· utilisation innovante ou application de nouvelles
solutions technologiques ou organisationnelles
· traitements en eux-mêmes qui « empêchent
[les personnes concernées] d'exercer un droit ou de
bénéficier d'un service ou d'un contrat »
Dès que deux critères sont réunis, il est
fort probable que le traitement présente un risque
élevé209.
En l'absence de lignes directrices, la Commission
européenne recommande de déterminer ce qui constitue un risque
élevé d'une application de l'IA en prenant en compte le secteur
d'activité et le traitement210. Or, afin de réaliser
un traitement par un logiciel d'intelligence artificielle, il est
nécessaire de disposer d'une grande quantité de données.
C'est justement ce qui constitue la « plus-value de l'intelligence
artificielle211 ». Dès lors, tout traitement peut
potentiellement être considéré comme présentant un
risque élevé du fait qu'il est effectué par une nouvelle
technologie, qu'il est permis par un croisement ou une combinaison de
données, et/ou que les données sont traitées à
grande échelle.
Il est alors recommandé de systématiquement
effectuer une analyse d'impact lors d'un traitement effectué par IA.
207 CNIL, Délib. n° 2019-118, 12 septembre 2019
208 G29, WP 248, op. cit., p. 10
209 G29, ibid., p. 13
210 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p.17
211 A. Bensamoun, G. Loiseau, l'intégration de
l'intelligence artificielle dans certains droits spéciaux, op.
cit.
- 39 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
§2. Un risque spécifique au logiciel de
l'intelligence artificielle
Le traitement effectué par des logiciels d'intelligence
artificielle crée de nouveaux risques spécifiques et augmente les
risques existants. La prise en compte des évolutions techniques de l'IA
est nécessaire pour effectuer une analyse d'impact efficace, qui permet
de mesurer les risques et de proposer des solutions scientifiques
réalisables212. La Commission européenne recommande
que l'Europe mette en oeuvre des outils de guide pour aider l'évaluation
de ces risques spécifiques213.
2.1. Risque d'opacité des systèmes d'IA
La nécessité de transparence dans le cadre de
traitements automatisés à des fins de profilage a
été souligné par le G29214. Il ne s'agit pas de
divulguer des secrets d'affaires mais de proposer une « intelligence
artificielle explicable » afin d'obtenir la confiance des
consommateurs215.
Néanmoins, dans le cadre de l'apprentissage automatique
supervisé, le phénomène de « black box
» empêche l'homme de connaitre le fonctionnement du logiciel.
Ce phénomène est lié à cette technologie qui
empêche de comprendre comment raisonne le logiciel lors du traitement. La
transparence du processus est donc illusoire.
Par ailleurs, l'opacité de certains systèmes
d'intelligence artificielle rend impossible l'audit des
systèmes216 et également le contrôle a
posteriori.
2.2. Risque de biais algorithmique
Le biais d'un algorithme est l'écart entre ce que dit
l'algorithme et la réalité217. Il existe deux types de
biais algorithmique218 : les « biais directs »,
généré par le codage de l'algorithme, et les «
biais indirects », créés par le design de
l'algorithme. Ces derniers ne sont pas créés directement par les
humains, mais indirectement lors de l'initialisation des algorithmes.
Le biais est susceptible de provoquer des discriminations et
de créer des atteintes tant collectives qu'individuelles et provoquer
des baisses d'opportunité, des pertes économiques,
212 Commission Européenne « Robustesse et
explicabilité de l'intelligence artificielle », 2020, p. 2 et s.
213 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p.14, p.17
214 G29, «Guidelines on Automated individual
decision-making and Profiling for the purposes of Regulation
2016/679», 3 octobre 2017
215 J. Toscano, «Privacy By Design: What Needs to be
Done, How to do It, and How to Sell It to your Boss», Medium,
30 octobre 2018
216 E. Caprioli, «intelligence artificielle et RGPD
peuvent-ils cohabiter ?», L'usine Digitale, 30 janvier
2020
217 Institut Montaigne, «Algorithmes : contrôle des
biais S.V.P», mars 2020
218 A. Jean « Interview : The history and future of
algorithms», France 24 English, 18 février 2020
- 40 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
des préjudices sociaux et des pertes de
liberté219. Or, lutter contre les biais algorithmiques
revient à se heurter au principe même de l'algorithme.
L'algorithme est par nature discriminant étant donné qu'il vise
à effectuer une distinction entre les individus en se basant sur
certaines caractéristiques220. Tout d'abord, il est
impossible de garantir simultanément une équité
individuelle et une équité de groupe221. Par ailleurs,
la mesure du biais n'est pas toujours possible, car il faudrait avoir
accès à des données sensibles, telles que l'orientation
sexuelle ou la religion. Par exemple, l'auditeur ne pourra pas vérifier
que son logiciel favorise les hommes de couleur blanche s'il ne peut pas
mesurer dans sa base de données le nombre d'hommes et le nombre de
personnes de couleur blanche.
L'intelligence artificielle soulève de nouveaux
risques, presque systématiquement susceptibles de porter des atteintes
élevées pour les droits et libertés des personnes
concernées. Le responsable de traitement doit donc accorder une
attention particulière aux risques d'opacité des systèmes
d'intelligence artificielle et de biais algorithmique, en amont et en aval du
traitement.
219 Future of Privacy Forum, «unfairness by algorithm:
distilling the harms of automated decision-making», 2017, p.4
220 A. Basdevant, «the rise of the blackbox
society», Coup Data
221 Institut Montaigne, « Algorithmes : contrôle
des biais S.V.P », mars 2020 p. 34
- 41 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
Chapitre 2 : Des outils de conformités
adaptés au respect de la vie privée
Le principe de l'autorégulation impose une approche
basée sur l'analyse de risque et une capacité à
démontrer que les responsables du traitement sont en conformité
avec les dispositions du Règlement. Or, cette analyse de risque est
basée sur une approche de protection des données dès la
conception et par défaut, ce qui promeut ces deux principes au coeur de
la réglementation222. Pour être efficace le management
du risque et la protection des données doivent être
appréhendés dans un processus global de prise de décision
qui allie à la fois les contraintes physiques et
techniques223. En l'absence de lignes directrices224, il
est nécessaire de définir des mesures organisationnelles (section
1) et techniques (section 2) envisageables.
Section 1 : Les mesures organisationnelles
Il peut s'avérer judicieux d'avoir recours à une
analyse d'impact algorithmique (§1), sur les discriminations (§2), et
sur la ré-identification (§3).
§1. L'analyse d'impact algorithmique
Cette analyse vise à mesurer les conséquences
sociales et le niveau d'exigence adéquat de protection des
données à caractère personnel. La récente directive
sur la prise de décision automatisée canadienne225 est
plus complète que la réglementation française. Son
approche est davantage technico-pragmatique, avec des obligations telles que la
nécessité d'une explication de l'administration canadienne aux
personnes concernées, l'obligation de publier le code source, ou encore
l'évaluation des risques nécessairement en amont, ...
En ce qui concerne l'apprentissage automatique non
supervisé, si l'analyse de la manière dont le logiciel propose
les résultats s'avère impossible, l'analyse du comportement du
logiciel est en revanche faisable et permet ainsi de réduire
l'opacité226.
222 ICO, «Guide to data protection», mai 2018
223 OCDE, «Enhancing Access to and Sharing of Data :
Reconciling Risks and Benefits for Data Re-use across Societies», 6
novembre 2019, p.4
224 E. Caprioli, «intelligence artificielle et RGPD
peuvent-ils cohabiter ?», L'usine Digitale, 30 janvier 2020
225 Canada, Directive sur la prise de décision
automatisée, entrée en vigueur le 1er avril
2019
226 Parlement Européen, « A governance
framework for algorithmic accountability and transparency », avril
2019, p. 35
- 42 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
§2. L'analyse d'impact sur les discriminations
Le rapport Villani propose227 de mettre en oeuvre
une étude d'impact sur les discriminations, appelée «
Discrimination Impact Assesment ».
En cas d'apprentissage automatique supervisé où
l'audit se révèle impossible, la Commission européenne
recommande de prendre des mesures adéquates, telles que la supervision
humaine pour la prise de décision finale228.
§3. L'analyse d'impact sur la ré-identification
des données anonymes
Il est impératif d'évaluer les risques de
ré-identification et d'être capable d'évaluer la
fiabilité des processus d'anonymisation229. Concernant les
mécanismes d'anonymisation, pour B. Nguyen, il s'agit davantage de voir
ces mécanismes comme un compromis plutôt qu'une technique
infaillible230.
Section 2 : Les mesures techniques
La mise en oeuvre de mesures techniques et organisationnelles
pour garantir le privacy by design et le privacy by default
est conditionnée à « l'état des
connaissances231 ». Il convient donc de définir
l'état de l'art des technologies garantissant la vie privée avant
de définir un régime spécifique de traitement par un
logiciel d'intelligence artificielle. D'après l'EDPS seule l'ENISA est
compétente pour définir l'état de l'art des
PETs232.
Il existe deux grandes catégories de PETs
adaptées au traitement du big data. Il s'agit du chiffrement
(§1) et de la pseudonymisation (§2)233. Ces
procédés se distinguent par leur finalité. Le premier vise
à garantir la sécurité d'un canal de communication par un
codage à clé, dont l'information ne peut être
décodée qu'avec une clé secrète. Le second vise
à éviter l'identification d'un individu en évitant qu'un
attribut soit mis en relation avec une donnée en permettant ainsi de
ré-identifier une personne concernée234. Ces
techniques permettent de protéger les données, les bases de
données et leurs infrastructures. Trois dimensions sont à prendre
en compte : le contrôle de la divulgation statistique, l'exploration des
données dans le respect de la vie privée et la
récupération de données privées235.
227 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.147
228 Commission Européenne « Robustesse et
explicabilité de l'intelligence artificielle », 2020, p. 23
229 G. D'acquisto, J. Domingo-ferrer, ENISA, « Privacy by
design in big data», décembre 2015, p. 60
230 B. Nguyen, « Survey sur les techniques
d'anonymisation : Théorie et Pratique », Journée CERNA
sur l'Anonymisation, P.50
231 Art. 25 1. RGPD
232 EDPS, « avis préliminaire sur le respect de la
vie privée dès la conception », avis 5/2018, 31 mai 2018,
p.20
233 G. D'acquisto, J. Domingo-ferrer, ENISA, « Privacy by
design in big data», décembre 2015, p27,38 et s.
234 G 29, Avis 05/2014 sur les Techniques d'anonymisation,
0829/14/FR WP216, 2014 p.32
235 G. Danezis, J. Domingo-Ferrer, ENISA, Privacy and Data
protection by design, op. cit., p. 32
- 43 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
§1. Les techniques de chiffrement
1.1. Les procédés de chiffrement
Le mécanisme de cryptographie est défini
à l'article 29 de la Loi pour la confiance dans l'économie
numérique comme « tout matériel ou logiciel conçu
ou modifié pour transformer des données, qu'il s'agisse
d'informations ou de signaux, à l'aide de conventions secrètes ou
pour réaliser l'opération inverse avec ou sans convention
secrète.236 ». Il existe deux types de chiffrement
: asymétrique et symétrique. Le chiffrement est un
procédé réversible consistant à remplacer la valeur
d'une donnée par une donnée pseudonyme appelée «
clé d'identification » ou « token »237. Le
processus de chiffrement fonctionne avec une table de correspondance. Il faut
donc sécuriser les serveurs qui hébergent ces tokens, voire
chiffrer la table de correspondance. Il est par ailleurs recommandé
d'effectuer une séparation physique entre le lieu de stockage des
données pseudonymisées et les tokens. La CNIL recommande l'usage
d'algorithmes de hachage à clé secrète tel que le HMAC.
L'ANSSI a publié des référentiels relatifs aux
mécanismes cryptographiques238, aux clés
cryptographiques239, et à l'identification240.
Le chiffrement permet de protéger le matériel,
les bases de données, et les fichiers241. Il
représente un intérêt tout particulier en matière de
souveraineté numérique puisqu'il permet d'empêcher un
intermédiaire de décrypter une donnée et ainsi
empêcher les autorités étrangères de demander la
divulgation de ces informations242. Ce procédé permet
ainsi d'empêcher l'identification directe de la personne concernée
en cryptant la donnée.
1.2. Les opportunités offertes par la technologie
Blockchain
La technologie Blockchain peut contribuer à la mise en
oeuvre des principes de privacy by default et de privacy by
design. En effet, elle permet tout d'abord de «
décentraliser la protection des données243
». Le rapport parlementaire « numérique et libertés
»244 juge que cette
236 Loi pour la confiance dans l'économie numérique
n° 2004-575, 21 juin 2004
237 A. Jomni, « RGPD : un atout ou un frein pour la
sécurité ? », Dalloz IP/IT, P.352, Juin 2019
238 ANSSI, « Mécanismes
cryptographiques», 26 janvier 2010
239 ANSSI, « Gestion des clés
cryptographiques», 24 octobre 2008
240 ANSSI, « authentification »,13 janvier
2010
241 CNIL, «Analyse d'impact à la protection des
données, les bases de connaissances », p. 13
242 F. Montaugé, G. Longuet, Rapport Commission
d'enquête sur la souveraineté au numérique, « le
devoir de souveraineté numérique : ni résignation, ni
naïveté » version provisoire, n° 7 tome I
(2019-2020) , 1 octobre 2019, P. 74
243 G. Zyskind, O. Nathan and A. S. Pentland,
"Decentralizing Privacy: Using Blockchain to Protect Personal Data," 2015
IEEE Security and Privacy Workshops, San Jose, CA, 2015, P. 180-184
244 Rapport à l'Assemblée nationale n°3119
« Numérique et libertés, un nouvel âge
démocratique », présenté par C. Paul et C.
Féral-Schuhl 2015, P. 118
- 44 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
technologie présente un intérêt au regard
de la sécurité des données du fait de son système
de registre décentralisé sécurisé.
Cette technologique pourrait également proposer une
forme d'anonymat car la Blockchain permet de conserver un réel anonymat
par le mécanisme du Zero Knowledge Proof,
(ZKP). Cette technologie permet par un mécanisme
d'isomorphisme d'effectuer une vérification sur la validité de la
donnée, sans avoir accès à cette
dernière245. Néanmoins, à l'heure actuelle, le
procédé de chiffrement ne peut constituer un processus
d'anonymisation tant que la clé ou les données originales sont
accessibles, mêmes lorsqu'elles sont mises en séquestre par un
tiers246.
Il faudra par ailleurs réévaluer la
fiabilité de ces techniques selon les évolutions de la
technologie quantique247.
§2. Les techniques de pseudonymisation
Aussi appelées « techniques d'anonymisation
», le terme de pseudonymisation sera ici
préféré, l'anonymisation faisant référence
à un standard technico-juridique controversé.
2.1. Les techniques de randomisation
La randomisation vise à modifier les valeurs
réelles des données afin d'empêcher de retrouver les
valeurs originales248. Cette méthode est rendue possible par
deux techniques : le bruit et la permutation.
La permutation vise à intervertir plusieurs données
les unes par rapport aux autres.
Le bruit, ou protection différentielle, vise à
intégrer de façon aléatoire des « bruits
», c'est-à-dire des données
synthétiques249, dans un ensemble de données afin de
fournir une garantie mathématique que la présence de toute
personne dans cet ensemble sera masquée250. Cette technique a
été démontrée par C. Dwork251.
Aujourd'hui, des logiciels sont capables de mesurer le risque d'atteinte
à la vie privée et de déterminer le degré de bruit
adéquat252. Apple, utilise notamment la technique du
Differential privacy. Il s'agit d'ajouter un bruit aléatoire
à la
245 R. Sayaf, «Algebraic Approach to Data Protection
by Design for Data Subjects», IPEN Workshop Conférence
«State of the art' in data protection by design», 12 juin 2019, P. 11
et s.
246 G 29, Avis 05/2014 sur les Techniques d'anonymisation,
0829/14/FR WP216, 2014 p.33
247 The Cybersecurity hub, « types of
cryptography», Linkedin, février 2020
248 G 29, Avis 05/2014 sur les Techniques d'anonymisation,
0829/14/FR WP216, 2014 p.30
249 Deloitte Canada, « gagner sur tous les tableaux :
protéger la vie privée à l'heure de l'analytique
», p. 7
250 A. Cavoukian, D stewart, B. Dewitt, Gagner sur tous les
tableaux, op. cit.
251 C. Dwork, «Differential Privacy». In:
Bugliesi M., Preneel B., Sassone V., Wegener I. (eds) Automata, Languages and
Programming. ICALP 2006. Lecture Notes in Computer Science, vol 4052. Springer,
Berlin, Heidelberg, 2006
252 A. Cavoukian, D stewart, B. Dewitt, Gagner sur tous les
tableaux, op. cit.
- 45 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
donnée253, et d'avoir un paramètre de
perte de niveau faible afin de garantir à la fois la valeur de la
donnée mais aussi de la protéger d'une éventuelle
attaque.
Dès 2014, le G29 rappelle que ces
procédés de randomisation ne permettent que de pseudonymiser des
données à caractère personnel : « Si la
pseudonymisation se fonde sur le remplacement d'une identité par un
autre code unique, il serait naïf de supposer qu'un tel
procédéì constitue une solution d'anonymisation
fiable, sans tenir compte de la complexité des méthodes
d'identification et des multiples contextes dans lesquels elles pourraient
être appliquées254 ». De plus, ces deux
techniques ne sont efficaces qu'en fonction de requêtes définies,
ce qui pose des difficultés à l'heure de l'open
data255.
2.2. Les techniques de généralisation
La généralisation, vise à remplacer
l'attribut d'une donnée par une catégorie plus grande. Par
exemple, si une base de données présente le nombre de personnes
par ville, on peut remplacer le critère de ville, par le critère
de pays. Cette technologie a vu le jour lorsque L. Sweeney a mis en
évidence les limites de la pseudonymisation du fait que 87% de la
population américaine pouvait être retrouvée à
partir de trois attributs, étant le code postal, le genre et la date de
naissance256. Néanmoins, « cette
généralisation supplémentaire s'opère au prix d'une
perte évidente et radicale d'information257 ».
Cette pratique permet toutefois de prévenir les attaques par
corrélation en évitant la granularité, c'est-à-dire
la possibilité d'isoler un individu à partir d'un attribut. Ce
processus peut être mis en place par les techniques de k-anonymat,
l-diversité, et de t-proximité.
Le k-anonymat est définit par le G29 comme «
une technique fondée sur la généralisation des
attributs qui vise à prévenir les attaques par corrélation
». Il s'agit en pratique de supprimer les attributs qui permettent de
ré identifier les personnes, appelés les attributs «
quasi-identifiants ». Pour anonymiser des données, il est
néanmoins nécessaire de supprimer des attributs
supplémentaires selon le G29. Cette technique permet de confondre un
individu au sein d'un groupe où tous les membres partagent les
mêmes caractéristiques et le rendre indistinguable.
253 C. duchesne-Jeanneney, G. Lallement, J. Serris, «
Accès aux données, consentement, l'impact du projet de
règlement e-privacy », CGE, 2018, P. 22, 23
254 G 29, Avis 05/2014 sur les Techniques d'anonymisation,
0829/14/FR WP216, 2014 p.35
255 Ibid., p.31
256 L. Sweeney, «k-anonymity: a model for protecting
privacy», International Journal on Uncertainty, Fuzziness and
Knowledge-based Systems, 10 (5), 2002; P. 557-570, P.2
257 G 29, Avis 05/2014 sur les Techniques d'anonymisation,
0829/14/FR WP216, 2014 p.37 et s.
- 46 -
Les moyens d'autorégulation adaptés à
l'intelligence artificielle
La l-diversité consiste à ajouter « une
contrainte supplémentaire (...), à savoir que chaque attribut
d'une classe d'équivalence apparaît à au moins à
« l » reprises, de telle sorte qu'un attaquant reste toujours
confronté à un degré d'incertitude considérable
concernant les attributs, malgré les connaissances tirées du
contexte dont il pourrait disposer à propos d'une personne
concernée. Cela revient à dire qu'un ensemble de données
(ou un segment) doit posséder un nombre minimal d'occurrences d'une
propriété sélectionnée: ce procédé
permet d'atténuer le risque de ré-identification258
».
Enfin la t-proximité ajoute un rempart
supplémentaire et fonctionne de la manière suivante : «
L'approche désignée par le terme
«t-proximité» prend en considération le cas particulier
des attributs qui sont distribués de manière inégale au
sein d'un segment ou qui ne présentent qu'un faible écart de
valeurs ou de contenus sémantiques. C'est une amélioration
supplémentaire de l'anonymisation par généralisation
consistant à organiser les données de façon à
créer des classes d'équivalence qui reflètent autant que
possible la distribution initiale des attributs dans l'ensemble de
données original259 ».
Néanmoins, le souci majeur des techniques de
généralisation réside dans le fait que la robustesse du
dispositif dépend du niveau d'information de
l'attaquant260.
Ainsi, le respect de la vie privée n'est envisageable
qu'au prix d'une autorégulation efficace et évolutive. La mise en
conformité nécessite d'adapter le risque aux
spécificités de l'intelligence artificielle et de se doter
d'outils permettant une protection réaliste des données à
caractère personnel.
Face aux limites d'application du RGPD
soulevées par l'utilisation de l'intelligence artificielle,
l'utilisation des principes éthiques s'avère indispensable pour
guider la collecte et le traitement des données à
caractère personnel. Le responsable du traitement doit donc les prendre
en compte dans le cadre de sa mise en conformité et élaborer des
outils adaptés à la spécificité de l'intelligence
artificielle, en restant vigilent à l'état de l'art.
258 G 29, Avis 05/2014 sur les Techniques d'anonymisation,
0829/14/FR WP216, 2014 p.39
259 Ibid., p.40
260 B. Nguyen, « Survey sur les techniques
d'anonymisation : Théorie et Pratique », Journée CERNA
sur l'Anonymisation, p.43
SECONDE PARTIE
|
Construire une intelligence artificielle conforme aux
principes de
privacy by design et de privacy by
default
|
L'élaboration d'un régime de traitement par un
logiciel d'intelligence artificielle conforme à la protection des
données à caractère personnel requiert de définir
les règles de gouvernance des données et d'étudier les
précautions à prendre tout au long du cycle de vie de la
donnée (Titre 1).
Mais si un code algorithmique régule le traitement, il
doit être au service des citoyens et préserver de manière
efficace et effective les droits et les libertés
fondamentales261. Or, le code est le reflet de l'homme qui le
rédige. Il faut donc envisager un régime de demain où l'IA
pourra être développée conformément aux standards
européens et garantir effectivement les droits et libertés des
personnes. Cela n'est possible que par l'appropriation d'une
souveraineté numérique européenne et individuelle (Titre
2).
- 47 -
261 L. Godefroy, « Le code au service du droit »,
Recueil Dalloz, 2018, p.734
- 48 -
Titre 1 : Le régime de lege lata262
En l'état actuel de la réglementation, il
n'existe pas de lignes directrices spécifiques au traitement par l'IA
conformément au RGPD. Cette partie vise donc à définir
l'obligation du responsable du traitement (Chapitre 1) et le régime
spécifique à l'IA (Chapitre 2).
Chapitre 1 : Le régime de gouvernance
autorégulé de la donnée
La gouvernance des données englobe l'ensemble des
pratiques procédures, normes et règles qui garantissent que le
traitement des données est conforme au RGPD263. Il est donc
impératif de définir les régimes de gouvernance de la
donnée spécifique à l'IA tant en matière de
responsabilité (Section 1), que d'instruments de conformité
(Section 2).
Section 1 : La responsabilité incertaine des
acteurs
La gouvernance de la donnée suppose de définir
au préalable le contenu de l'obligation du responsable du traitement
(§1), ainsi que son étendue (§2), ses tempéraments
(§3) et la répartition de cette responsabilité (§4).
§1. Le contenu de l'obligation
Le privacy by design (cf. Annexe i -
Schéma - la protection des données dès la
conception) et le privacy by default (cf. Annexe ii -
Schéma - la protection des données par défaut)
imposent de mettre en oeuvre des mesures appropriées et effectives pour
respecter les principes relatifs à la protection des données.
L'obligation de privacy by design consiste en la mise
en oeuvre de méthodes visant à diminuer les risques d'atteinte
aux droits et libertés des personnes concernées. Les aspects
techniques et organisationnels englobent toute méthode allant d'une
simple sensibilisation du personnel à une technique avancée.
Toutes les mesures peuvent être employées à condition
qu'elles soient « appropriées ». Le responsable du
traitement est par ailleurs tenu de démontrer qu'il a effectivement
choisi et mis en oeuvre les bonnes mesures. Il doit pour cela déterminer
les indicateurs clés de performance avec des instruments de mesure
qualitatifs et quantitatifs264.
262 De lege lata signifie « en
application du droit actuellement en vigueur »
263 Commission Européenne « Robustesse et
explicabilité de l'intelligence artificielle », 2020, p. 7
264 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit., p. 7
- 49 -
Le régime de lege lata
L'obligation de privacy by default vise à
déterminer comme paramètre par défaut une solution
respectueuse de la vie privée, et pouvant être
paramétrée tant par le responsable du traitement que par la
personne concernée265.
La mise en oeuvre opérationnelle de ces principes dans
le cadre de l'intelligence artificielle passe par l'ingénierie de la vie
privée, et donc par l'utilisation des PETs266.
§2. L'étendue de l'obligation du responsable du
traitement
Les principes énoncés à l'article 5 du
RGPD constituent les objectifs à atteindre par ces
mesures267. En imposant des principes larges, le RGPD insiste
davantage sur les résultats que sur les processus techniques, si bien
qu'on pourrait interpréter le Règlement comme une obligation de
résultat et non de processus268. Or, pour les praticiens, le
responsable du traitement est en réalité tenu à une
obligation de moyens en matière de privacy by
design269. Il en va de même pour le privacy by
default qui impose au responsable du traitement de mettre en oeuvre «
des mesures techniques et organisationnelles appropriées
».
Ces mesures doivent être mises en oeuvre tout au long du
cycle de vie de la donnée, soit « tant au moment de la
détermination des moyens du traitement qu'au moment du traitement
lui-même270 ». Néanmoins, le RGPD fixe
seulement le cadre de conformité et non les moyens de mise en oeuvre de
ces principes271. De plus, la mesure de cette obligation reste
imprécise en ce qui concerne la balance entre l'intérêt des
personnes concernées et les « intérêts
légitimes » des responsables du traitement272,
n'étant pas précisée dans le
Règlement273. Le fondement même du régime de
l'action en responsabilité est incertain274.
Il s'agit néanmoins d'une nouvelle
responsabilité à la charge du responsable du traitement, qui sera
prise en compte par les autorités administratives en cas d'oubli, de
défaillance ou de fragilité du respect de ce
concept275. Le responsable du traitement n'est pas seul tenu
à cette
265 Ibid., p. 4
266 EDPS, « avis préliminaire sur le respect de la
vie privée dès la conception », avis 5/2018, 31 mai 2018,
p.15
267 Ibid., p.8
268 F. Godement «Données personnelles, comment
gagner la bataille ?» Institut Montaigne, décembre 2019, P.
42
269 C. Castets-Renard, « La protection des
données personnelles dans les relations internes à l'Union
européenne » 2018, §181
270 Art. 25 RGPD
271 M. Griguer, J. Shwartz, «Privacy by Design - Privacy
by Design/Privacy by Default Une obligation de conformité et un avantage
concurrentiel», Lexis Nexis, Cahiers de droit de l'entreprise n° 3,
prat. 15, Mai 2017
272 S. Watcher, «The GDPR and the Internet of Things : A
Three-Step Transparency Model», 2018, p.8
273 F. Godement «Données personnelles, comment
gagner la bataille ?» Institut Montaigne, décembre 2019, P.
70
274 L. Marignol, « Principe de responsabilité et
action en responsabilité dans le Règlement général
sur la protection des données », Lamy droit de
l'immateriel, n°166, janvier 2020, p. 44
275 M Rees,
nextinpact.com, « Le RGPD
expliqué ligne par ligne (articles 24 à 50) », 201
- 50 -
Le régime de lege lata
obligation de moyens. Cette responsabilité incombe
aussi le cas échéant aux co-responsables du traitement et aux
sous-traitants276.
§3. Les tempéraments à cette obligation
3.1. Pour le principe de privacy by design
L'étendue de cette obligation dépend des
compétences, des capacités et du type de données
traitées par le responsable du traitement. Le premier paragraphe dispose
en effet qu'il est nécessaire de prendre en compte «
l'état des connaissances, des coûts de mise en oeuvre et de la
nature, de la portée, du contexte et des finalités du traitement
ainsi que des risques, dont le degré de probabilité et de
gravité varie, que présente le traitement pour les droits et
libertés des personnes physiques277 ».
En ce qui concerne l'« état de la connaissance
», il est difficile de mesurer le respect effectif du privacy by
design dans le choix des solutions techniques. Si le recours aux PETs est
indispensable à leur application, il ne faut toutefois pas attendre
davantage de la technologie que ce dont elle est capable278. La
notion d'« état de l'art » fait l'objet d'une
réflexion quant à sa transposition dans le domaine du
droit279. L'EDPB propose d'interpréter ce critère
comme la prise en compte du progrès actuel de la
technologie280.
Les facteurs à prendre en compte pour mesurer le
degré de protection de la vie privée incluent la nature, le
champ, le contexte et la finalité du traitement. Ces critères
font référence aux caractéristiques inhérentes, de
la taille et de la portée, des circonstances et du but du
traitement281.
Enfin, le risque d'atteinte aux droits et libertés des
personnes physiques s'apprécie selon sa « probabilité
» et sa « gravité »282. Il
conviendra de prendre en compte les risques spécifiques au traitement
par un logiciel d'intelligence artificielle non prévus par le RGPD et
listés dans une partie précédente283.
276N. Lenoir, « Informatique et
libertés publiques - Protection des données personnelles et
responsabilités plurielles », Lexis Nexis, La Semaine Juridique
Edition Générale n° 41, La Semaine Juridique Edition
Générale n° 41, 8 Octobre 2018, doctr. 1059, 8 Octobre
2018
277 Art. 25 RGPD
278 A. Jomni, « RGPD : un atout ou un frein pour la
sécurité ? », Dalloz IP/IT, p.352, Juin 2019
279 EDPS, « Internet Privacy Engineering Network
discusses state of the art technology for privacy and data protection
», 12 juin 2019
280 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit., p. 8
281 Ibid., p. 9
282 Ibid., p. 9
283 Titre 2, chapitre 1, section 2, p.37
- 51 -
Le régime de lege lata
3.2. Pour le principe de privacy by default
Les mesures techniques et organisationnelles relatives au
privacy by default doivent prendre en compte « la quantité
de données à caractère personnel collectées, (...)
l'étendue de leur traitement, (la) durée de conservation et (l')
accessibilité284 ».
La « quantité de données »
collectées fait référence285 au principe de
minimisation en imposant que seules les données nécessaires
soient collectées. Il s'agit d'un critère tant qualitatif que
quantitatif qui impose de respecter les principes de sécurité et
de durée de conservation.
L'« étendue » du traitement impose
de prendre en compte les attentes raisonnables des personnes concernées
relatives au traitement de leurs données et de ne pas extrapoler la
notion de réutilisation ultérieure en cas de finalités
compatibles.
La référence à « la durée
de conservation » suggère de prévoir des
procédures de mise en conformité justifiables et
démontrables garantissant ce principe. Les données doivent
être supprimées ou anonymisées lorsqu'elles ne sont plus
nécessaires afin de clore le cycle de vie de la donnée. Il s'agit
alors de créer des procédures systématiques de suppression
ou d'effectuer une analyse de risque de ré identification en cas
d'anonymisation.
Enfin l'objectif d'« accessibilité »
crée une obligation du responsable du traitement de limiter
l'accès aux données au strict nécessaire. Des
contrôles d'accès doivent être mis en place.
L'article 25.2 du RGPD insiste sur la nécessité
de ne pas rendre les données accessibles à un nombre
indéterminé de personnes physiques sans l'intervention de la
personne concernée. Le cas échéant, il conviendra de
limiter par défaut l'accessibilité et de consulter la personne
concernée avant la publication pour obtenir son consentement avant de
rendre la donnée publique. Si une information est rendue publique sur
internet, il faudra veiller à limiter le référencement
internet, c'est-à-dire à faire en sorte que la page ne soit pas
accessible sur les moteurs de recherche.
§4. La répartition de la responsabilité
Une approche transversale est nécessaire pour
déterminer l'ensemble des responsabilités des acteurs de
l'intelligence artificielle, qu'il convient de préciser au titre de
l'obligation de moyens du responsable du traitement286. En
matière d'algorithme d'intelligence artificielle, la
284 Art. 25.2 RGPD
285 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit, p. 11 et s.
286 P. Pucheral, A. Rallet, F. Rochelandet, C. Zolynski,
« a Privacy by design : une fausse bonne solution aux problèmes de
protection des données personnelles soulevés par l'open data et
les objets connectés ? Legicom, Victoires Editions, open data : une
révolution en marche, pp.89-99, 2016
- 52 -
Le régime de lege lata
responsabilité n'est pas diluée entre tous les
acteurs de la chaîne, mais est en réalité
déplacée au stade du paramétrage de
l'algorithme287. Comme le remarque le magistrat A.
Garapon288, ce déplacement risque de regrouper le pouvoir
autour d'un petit groupe d'experts du code informatique, et créer ainsi
une « petite caste de scribes ».
Néanmoins, cette responsabilité peut être
diluée lorsque la traçabilité des instructions est
paramétrée dès la conception de l'algorithme. C'est
notamment le cas du logiciel d'Application Post-Bac, où les
développeurs avaient organisé une procédure de
traçabilité de la responsabilité et où toutes les
modifications du paramétrage de l'algorithme étaient
répertoriées.
La CNIL encourage vivement l'attribution explicite des
responsabilités289, qui peuvent s'envisager tant en
amont290 qu'en aval291 du traitement.
Section 2 : Les instruments à la disposition du
responsable du traitement
Conformément à l'article 5.2 du RGPD, la charge
de la preuve du respect de l'obligation de moyens incombe au responsable du
traitement. Dans sa démarche de conformité, le responsable du
traitement doit documenter les modalités de traitement qu'il effectue.
Le considérant (78) précise en effet qu'« afin
d'être en mesure de démontrer qu'il respecte le présent
règlement, le responsable du traitement devrait adopter des
règles internes et mettre en oeuvre des mesures qui respectent, en
particulier, les principes de protection des données dès la
conception et de protection des données par défaut ».
Le responsable du traitement demeure obligé d'utiliser certains outils
de conformité (§1) mais est libre d'en utiliser davantage
(§2).
§1. Les outils classiques
Pour démontrer la mise en oeuvre de ces obligations, la
CNIL recommande de prioriser les actions à mener en amont du traitement,
de créer des procédures internes qui garantissent la prise en
compte de la protection des données, et de documenter les
développements dès le début
287 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit.,, p.29
288 Ibid
289 CNIL, sondage, op. cit. p.51
290 H. Nissenbaum, «Accountability in a Computerized
Society, Science and Engineering Ethics 2», 25-42, 1996 ; J. A. Kroll, J.
Huey, S. Barocas, E. W. Felten, J. R. Reidenberg, D. G. Robinson et H. Yu,
Accountable Algorithms, University of Pennsylvania Law Review, vol. 165,
2017
291 J. Millar, B. Barron ,K. Hori, R. Finlay, K. Kotsuki et I.
Kerr, «Accountability in ai, Promoting Greater Social Trust»,
6 décembre 2018
- 53 -
Le régime de lege lata
de la réflexion292. Le rôle du
délégué à la protection des données est
crucial dans cette démarche293.
1.1. Registre et analyse d'impact à la protection
des données
Conformément au RGPD, le responsable du traitement doit
toujours tenir un registre de traitement294.
De plus, une analyse d'impact relative à la protection
des données peut être requise lorsque le traitement
effectué est susceptible de créer « un risque
élevé pour les droits et libertés des personnes
physiques295 ». Dans certains cas de risques très
élevés, un avis préalable de la CNIL est
requis296. (cf. annexe iv - Guide de la CNIL pour effectuer
une AIPD).
L'autorité de contrôle anglaise analyse cet outil
comme « partie intégrante de la protection des données
dès la conception et par défaut » 297. Il
permet en effet de déterminer les mesures techniques et
organisationnelles qui garantissent la conformité. C'est pour cette
raison que la CNIL recommande de mettre en place une analyse d'impact à
la protection des données (ci-après « AIPD
»), même lorsqu'elle n'est pas obligatoire.
L'université Ku Leuven a développé la méthode
LINDDUN qui fixe un cadre d'analyse de risques en matière
d'ingénierie de la vie privée298. La CNIL a
également proposé un cadre relatif à la mise en oeuvre de
l'AIPD.
1.2. Le contrat
Le RGPD insiste sur l'obligation incombant aux responsables du
traitement de vérifier que ces derniers et leurs sous-traitants sont en
mesure de respecter les obligations en matière de protection des
données, en particulier pour les fabricants de produits, prestataires de
services et producteurs d'application299. Dès lors, les
responsables du traitement sont tenus de formaliser par contrat le partage des
responsabilités en cas de co-responsabilité300. Ils
doivent par ailleurs définir les modalités et les
finalités de traitement en matière de
sous-traitance301. La mise en
292 CNIL, « Développer en conformité avec
le RGPD », 27 janvier 2020
293 EDPS, « avis préliminaire sur le respect de la
vie privée dès la conception », avis 5/2018, 31 mai 2018,
p.18
294 Art. 30 RGPD, détail des modalités du registre
accessible ici
295 Art. 35 RGPD
296 CNIL, soumettre une analyse d'impact relative à la
protection des données (AIPD) à la CNIL, 22 octobre 2019
297 ICO, «Data protection by design and default»
mai 2019
298 EDPS, « avis préliminaire sur le respect de la
vie privée dès la conception », avis 5/2018, 31 mai 2018,
p.16
299 Consid. (78) RGPD
300 Art. 26 RGPD
301 Art. 28 RGPD
- 54 -
Le régime de lege lata
oeuvre de la protection des données doit aussi
être précisée en cas d'élaboration de règles
d'entreprises contraignantes et en cas de transferts transfrontaliers hors
UE302.
En matière d'encadrement contractuel de l'intelligence
artificielle, N. Quoy et A. Boullet recommandent de prévoir des clauses
spécifiques303. Il s'agit notamment d'insérer des
clauses relatives à la confidentialité et à la
sécurité, à l'obligation de transparence, et au niveau de
service. L'insertion d'une clause de « soft law »,
c'est-à-dire une clause faisant référence à un code
de conduite ou une charte éthique, crée une valeur contraignante
de la norme éthique à l'égard des parties. Cette clause
de soft law peut donc rendre contraignant les principes
éthiques de l'IA listés
précédemment304.
De plus, s'il n'existe pas réellement d'obligation
d'assurer la traçabilité des données tout au long du
déroulement du projet, cette pratique est néanmoins fortement
recommandée. En définissant dans un contrat les
responsabilités respectives des parties prenantes, le responsable du
traitement sera davantage en mesure de démontrer sa
conformité305.
§2. Les démarches facultatives 2.1. Le
code de conduite
Des initiatives privées peuvent également
être mises en place, telles que les codes de conduite dans des branches
sectorielles. Conformément aux articles 40 et suivants du RGPD, ces
codes sont soumis à l'avis de l'EDPB après un accompagnement de
la CNIL306. Une fois que l'EDPB approuve ces codes non obligatoires,
ils s'imposent à tout le secteur d'activité et sont davantage
contraignants que le Règlement.
Néanmoins, à l'heure de la parution de ce
mémoire, aucun code de conduite n'a été
validé307.
2.2. La certification
Une autre manière d'attester de sa démarche de
conformité avec le RGPD est de recourir à la certification. Les
articles 42 et 43 du RGPD disposent des conditions d'obtention d'une
certification par les organismes dédiés. Les certifications
peuvent être un référentiel
302 Art. 47, considérant (108) RGPD
303 N. Quoy, A. Boullet, « L'encadrement contractuel de
l'intelligence artificielle », Lexis Nexis, Communication Commerce
éléctronique n°2, Février 2020
304 Titre 1, chapitre 2, p. 29
305 F.X. Cao, « Intelligence artificielle et valorisation de
la donnée », Lexis Nexis, à paraitre
306 CNIL, « Comment faire approuver un code de conduite
? », 7 février 2020
307 EDPB, « Register for Codes of Conduct, amendments and
extensions »
- 55 -
Le régime de lege lata
d'agrément, pour les organismes certificateurs, ou un
référentiel de certification pour des services ou des
personnes308.
Le référentiel d'agrément a permis de
certifier cinq organismes309, qui ont eux-mêmes
certifié des délégués à la protection des
données conformément au référentiel de
certification310. Néanmoins, aujourd'hui, seuls des
référentiels ont été délivrés pour la
certification de délégué à la protection des
données. La CNIL a pour projet de mettre en place un dispositif de
certification des organismes de formation RGPD311.
Par ailleurs, la délivrance de Labels par la CNIL n'est
plus possible depuis l'entrée en vigueur du RGPD, mais les labels
délivrés avant le 25 mai 2018 restent valables pendant trois
ans312. La certification est donc encore à un stade
embryonnaire malgré l'encouragement313 de l'EDPB en la
matière et la publication de nouvelles lignes directrices314.
Dans l'attente, on pourrait toutefois envisager une certification partielle par
le bais de la certification en matière de cybersécurité
conformément aux pouvoirs de l'ENISA315.
Ainsi, il n'existe à l'heure actuelle pas de
certification en matière de respect des principes de privacy by
design et de privacy by default et encore moins dans le cadre
d'un traitement d'intelligence artificielle. Cette nécessité de
certifier des responsables du traitement était pourtant
encouragée dès 2015 par l'Assemblée Nationale, qui
considérait qu'il était nécessaire d'encourager la
conception et l'utilisation de technologies permettant de garantir les
principes de privacy by design et de privacy by default par
des dispositifs contraignants ou réellement incitatifs, tels que des
certifications.316 Le troisième paragraphe de l'article 25 du
RGPD mentionne d'ailleurs le recours à la certification pour
démontrer le respect des exigences de ce principe. Néanmoins, si
cet acte volontaire « joue le rôle de
rambarde317 » pour les responsables du traitement, il ne
diminue en rien leur obligation de moyens.
308 CNIL, « La certification », 19
décembre 2018
309 Liste des organismes agréés accessible au lien
suivant :
https://www.cnil.fr/fr/organisme-agrees
310 CNIL, « Certification des compétences du DPO :
la CNIL délivre son premier agrément », 12 juillet
2019
311 CNIL « La CNIL lance une consultation publique sur
son projet de certification « Formation à la protection des
données », 5 mars 2020
312 CNIL « Transition vers le RGPD : des labels à
la certification », 28 février 2018
313 CEPD, « rapport annuel », 2018, p.11
314 CEPD, « Guidelines 1/2018 on certification and
identifying certification criteria in accordance with Articles 42 and 43 of the
Regulation», 4 juin 2019
315 Art. 56 Règlement (UE) 2019/881 relatif à
l'ENISA (Agence de l'Union européenne pour la
cybersécurité) et à la certification de
cybersécurité des technologies de l'information et des
communications, et abrogeant le règlement (UE) no 526/2013
(règlement sur la cybersécurité), 17 avril 2019
316 C. Paul, C. Feral-Schuhl, rapp. no 3119, op.
cit., recomm. no 50
317 M. Rees, « Le RGPD expliqué ligne par ligne
Certification (article 42)», Nextinpact, 2018
- 56 -
Le régime de lege lata
2.3. Les initiatives de responsabilisation par les
organismes privés
La volonté de fixer des codes de conduites n'est pas
nouvelle318. Dès 2011, il était recommandé
d'adopter des pratiques claires, de simplifier les paramètres, de
respecter le privacy by design et d'expliquer ce que le traitement des
données permet comme service. Des acteurs privés avaient
déjà pris des initiatives à l'instar de Microsoft qui
dès 2006 publie ses lignes directrices relatives à la vie
privée, mises à jour depuis319.
Des standards voient également le jour. Si la
méthode PRIPARE posa les bases de ces mécanismes320,
les standards Oasis définissent les bonnes pratiques en termes de
privacy by design pour les ingénieurs en
programmation321. Une norme ISO relative au privacy by design
et aux biens de consommation et aux services est en cours de
développement322. L'ensemble des initiatives est
recensé sur le Wiki323 de l'IPEN324.
Depuis 2018 a été mis en place le consortium qui
vise à créer une plateforme nommée DEFenD325.
Composé d'acteurs publics et privés européens mais non
français, ce projet vise à améliorer les outils de
conformité et à développer une intégration
logicielle par le biais d'une plateforme organisationnelle unique de
gouvernance de la confidentialité des données, respectueuse
du privacy by design326.
Ainsi, il n'existe pas aujourd'hui de lignes directrices
relatives au traitement par un logiciel d'intelligence artificielle conforme
aux principes de privacy by design et de privacy by default,
malgré les nombreuses recommandations en la
matière327.
318 J F. Rayport, « What big data Needs : A code of Ethical
Practices», Technology review, 26 mai 2011
319 «Building Global Trust Online, 4th Edition, Microsoft
Perspectives for Policymakers» 2014
320 «Privacy- and Security-by-Design Methodology
Handbook», 31 décembre 2015
321 OASIS, « standards », 2012
322 ISO/AWI 31700, «Consumer protection -- Privacy by
design for consumer goods and services»
323 IPEN, «Wiki for Privacy Standards and Privacy
Projects»
324 L'initiative IPEN, Internet Privacy Engineering Network,
vise à regrouper des développeurs et des spécialistes de
la protection des données ayant une expérience technique dans
différents domaines afin d'initier et de soutenir des projets qui
intègrent la protection de la vie privée
325 DEFeND: the data governance framework for supporting
GDPR
326 H. Mouratidis, L. Piras, ..., «DEFeND
Architecture: a Privacy by Design Platform for GDPR Compliance» Aout
2019
327 M. Hansen, K. Limniotis, ENISA, recommendations on GDPR
provisions, op cit., p.36
- 57 -
Le régime de lege lata
Chapitre 2 : Les points d'attention selon le cycle de
vie de la donnée
L'EDPB, dans son projet de lignes directrices328
sur l'article 25 du RGPD analyse le respect de la confidentialité
dès la conception et par défaut dès lors que les
responsables du traitement effectuent une mise en oeuvre effective des
principes de protection des données ainsi que des droits et
libertés des personnes concernées. Ainsi, ces dispositions
s'appliquent à l'ensemble des principes329 du RGPD, qui sont
les principes de licéité, loyauté et transparence,
limitation des finalités, minimisation des données, exactitude,
limitation de la conservation, responsabilité, intégrité
et confidentialité. Par conséquent, le responsable du traitement,
et le cas échéant le sous-traitant, doivent garantir
l'effectivité de ces principes tout au long du traitement de ces
données. Néanmoins, le RGPD est technologiquement neutre et
contient des principes larges et adaptables. Il convient donc de
réfléchir à leur adaptation aux systèmes
d'IA330, suivant le cycle de vie de l'intelligence artificielle
(Section 1) et point par point (Section 2).
Section 1 : Définition du cycle de vie de la
donnée lors d'un traitement d'intelligence artificielle
S'il existe de profondes différences techniques entre
les algorithmes d'intelligence artificielle, une analyse globale reste
pertinente selon la CNIL331 pour appréhender les
conséquences sociales éthiques et politiques puisque la
finalité reste la même : automatiser des tâches autrement
accomplies par des humains. Les acteurs publics européens332,
internationaux333 et privés334 s'accordent
à définir un cycle de vie commun aux systèmes
d'apprentissage automatique. Ce cycle de vie suit les étapes suivantes
:
· identification de la donnée
· préparation de la donnée
· modélisation
o sélection du modèle de logiciel
o test du design du logiciel
o construction du modèle : entrainement
o évaluation du modèle
· évaluation
· déploiement
o prédiction
o bilan de la prédiction
328 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit., p.4
329 Art. 5 RGPD
330 W. Wiewiórowski, «AI and Facial Recognition:
Challenges and Opportunities», EDPS, 21 février 2020
331 CNIL, les enjeux éthiques des algorithmes de
l'intelligence artificielle, op. cit., p. 18
332 Parlement Européen, a governance framework for
algorithmic accountability and transparency, op. cit., p. 29
333 OCDE, « State of the art in the use of emerging
technologies in the public sector », 2019, p. 10
334 IBM, « Machine Learning for dummies », p.
37
- 58 -
Le régime de lege lata
En se basant sur les recommandations de la CNIL pour les
développeurs335 et les étapes de développement
d'un logiciel d'intelligence artificielle, on peut élaborer les points
d'attention pour chaque étape du traitement afin d'être en
conformité avec les principes de privacy by design et de
privacy by default. Une attention particulière sera accordée
à l'entrainement de la donnée, le stockage de la donnée,
l'information fournie, la robustesse et la sécurité, la
supervision humaine et les spécificités de certains traitements
d'IA336. Il faudra veiller à ces points dès la
conception du traitement puis tout au long du cycle vie de la donnée,
étant constitué par les étapes de collecte, traitement et
suppression. On peut envisager la typologie suivante :
Préparation de la donnée
Identification de la donnée
|
Évaluation
|
Déploiement
|
|

Définition du Modélisation Initialisation
Entrée Traitement Sortie
traitement
Section 2 : Les étapes à respecter tout
au long du cycle de vie de la donnée
Dans un avis consultatif, l'EDPB liste les principes à
respecter pour garantir le privacy by Design et le privacy by
default337. Cet avis, n'étant que provisoire, il ne sera
pas détaillé dans ce mémoire. En revanche, les
étapes à respecter qui suivent les étapes
d'élaboration d'un logiciel d'intelligence artificielle sont accessibles
en annexe (Annexe v - Privacy by design et by privacy by default
d'après l'avis du CEPD).
§1. Étape 1 : Définition du
traitement

Définition du Modélisation Initialisation
Entrée Traitement Sortie
traitement
Avant d'effectuer un traitement, il est nécessaire de
définir chacun des principes suivants et de justifier ce choix dans le
registre ou dans l'analyse d'impact à la protection des
données.
335 CNIL, « La CNIL publie un guide RGPD pour les
développeurs », 28 janvier 2020
336 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p.18
337 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit.
- 59 -
Le régime de lege lata
1.1. Principe de limitation des finalités
Le principe de finalité impose que chaque traitement
doit être effectué en vue d'une ou plusieurs finalités
« déterminées, explicites et
légitimes338 ». En cas de traitement
effectué à des fins ultérieures, le responsable du
traitement doit s'assurer que cette finalité est compatible avec la
finalité initiale qui a justifié la collecte (art. 6.4. RGPD).
1.2. Principe de licéité
Le traitement n'est licite que lorsqu'il est fondé sur
une des bases légales de l'article 6.1 du RGPD, qui sont
l'exécution d'un contrat339, le respect d'une obligation
légale, la sauvegarde des intérêts vitaux de la personne
concernée ou d'une autre personne physique, la mission
d'intérêt public, les intérêts légitimes
poursuivis par le responsable du traitement ou par un tiers, et le consentement
de la personne concernée340. Le traitement des données
sensibles est en principe interdit par l'article 9.1 du RGPD, mais peut en
revanche être permis si le traitement est fondé sur des bases
légales spécifiques.
Dans la décision341 de la CNIL qui a
sanctionné Google à hauteur de 50 millions d'euros, sanction la
plus importante jamais donnée, les manquements reprochés
étaient relatifs à l'information des utilisateurs et au
consentement. Le bouton d'acceptation de l'utilisation des données
à des fins publicitaires était pré-coché, ce qui a
privé le consentement de son caractère spécifique et
univoque. W. Maxwell et C. Zolynski analysent cette décision comme une
prise en compte du design des interfaces homme-machine342. Le
responsable du traitement devra s'assurer de la conformité de ce visuel
afin d'obtenir le consentement des personnes concernées. Il s'agit ainsi
de la sanction du non-respect du privacy by design.
Par la suite, la décision343 de la CJUE a
poursuivi cette dynamique et a considéré que le
pré-cochage d'une case permettant l'utilisation de cookies invalidait le
consentement. En l'espèce344, afin de pouvoir accéder
à un jeu promotionnel, l'utilisateur se voyait présenter au
préalable une interface présentant deux cases. La
première, non cochée, était nécessaire pour
participer au jeu et indiquait que l'utilisateur donnait son accord pour
être démarché par les partenaires de la
société. La seconde, pré-cochée, indiquait que
l'utilisateur acceptait
338 Art. 5.1.b) RGPD
339 Détaillé dans les guideslines de l'EDPB :
«Guidelines 2/2019 on the processing of personal data under Article
6(1)(b) GDPR in the context of the provision of online services to data
subjects», 8 octobre 2019
340 Détaillé dans les Lignes directrices du G29
sur « le consentement au sens du règlement 2016/679 »,
10 avril 2018
341 CNIL, Délib. formation restreinte, n°
SAN-2019-001, 21 janv. 2019
342 W. Maxwell, C. Zolynski, «Protection des données
personnelles», recueil Dalloz 2019, P. 1673 §6
343 CJUE, aff. C-673/17, Planet49 GmbH c/ Bundesverband), 21
mars 2019
344 W. Maxwell, C. Zolynski, «Protection des données
personnelles», receuil Dalloz 2019, P. 1673
- 60 -
Le régime de lege lata
l'utilisation des cookies. La Cour a jugé que le
consentement ne pouvait résulter d'un acte positif de l'internaute du
fait que la case était pré-cochée. Le consentement ne peut
pas non plus être considéré comme distinct, du fait que la
manifestation du consentement à l'utilisation des cookies et la
volonté de jouer au jeu ne peuvent résulter d'un même acte.
La CNIL s'est par la suite alignée345 sur cette
décision. Ainsi, le design des interfaces homme-machine est donc
déterminant dans les modalités d'obtention du
consentement346.
Concernant le profilage, l'affaire Vectuary a mis en
lumière la nécessité d'informer les utilisateurs pour
avoir un consentement valide347. En l'espèce, la
finalité de traitement de la géolocalisation n'était pas
assez explicite, et consistait à établir des habitudes de
déplacement afin de leur proposer de la publicité
ciblée.
La base légale conditionne les modalités
d'information ainsi que le droit des personnes concernées. La CNIL dans
le tableau ci-après présente348 les droits que le
responsable du traitement est tenu de consacrer suivant les bases
légales du traitement.
|
DROIT DES PERSONNES A GARANTIR
|
BASE LEGALE
|
|
ACCÈS
|
RECTIFICATI
ON
|
EFFACEMENT
|
LIMITATION
DU
TRAITEMENT
|
PORTABILITÉ
|
OPPOSITION
|
|
Oui
|
Oui
|
Oui
|
Oui
|
Oui
|
Retrait du
consentement
|
|
Oui
|
Oui
|
Oui
|
Oui
|
Oui
|
Non
|
|
Oui
|
Oui
|
Oui
|
Oui
|
Non
|
Oui
|
|
Oui
|
Oui
|
Non
|
Oui
|
Non
|
Non
|
|
Oui
|
Oui
|
Non
|
Oui
|
Non
|
Oui
|
|
Oui
|
Oui
|
Oui
|
Oui
|
Non
|
Non
|
|
1.3. Principes d'intégrité et de
confidentialité
Par ailleurs, il est essentiel de réfléchir
à une architecture sécurisée en suivant le parcours des
données349. Le recours à un prestataire pour
l'hébergement doit faire l'objet de précautions
particulières.
345 CNIL, Délib., n° 2019-093, 4 juill. 2019
346 W. Maxwell, C. Zolynski, «Protection des données
personnelles», receuil Dalloz 2019, P. 1673 §6
347 CNIL, Délib. n°2018-343, 8 novembre 2018
348 CNIL, «Prendre en compte les bases légales
dans l'implémentation technique», 27 janvier 2020
349 CNIL, «faire un choix éclairé de son
architecture», 27 janvier 2020
- 61 -
Le régime de lege lata
§2. Étape 2 : Modélisation

Définition du Modélisation Initialisation
Entrée Traitement Sortie
traitement
2.1. Principe de transparence
Le principe de transparence s'interprète
d'après l'EDPB comme le devoir d'informer les personnes
concernées des modalités de traitement et des droits qu'elles
peuvent exercer350. L'information concerne donc l'exercice effectif
de ce droit (art. 12 RGPD), l'information de la personne concernée en
cas de collecte directe (art. 13 RGPD) ou indirecte (art. 14 RGPD), le droit
d'accès (art. 15 RGPD), le droit de rectification (art. 16 RGPD), le
droit à l'effacement (art. 17 RGPD), le droit à la limitation du
traitement (art. 18 RGPD), le droit à l'effacement ou à la
rectification (art. 19 RGPD), le droit à la portabilité (art. 20
RGPD), le droit d'opposition à la prise de décision
entièrement automatisée (art. 21 RGPD), le droit d'opposition au
profilage (art. 22 RGPD) et la communication d'une violation de données
(art. 34 RGPD). Si le principe de transparence n'est pas défini par le
RGPD, le G29, dans ses lignes directrices relatives à la
transparence351, indique que ce principe doit être garanti
tout au long du cycle de vie du traitement des données tant lors de la
collecte que lors du traitement.
Il convient donc de veiller à garantir l'exercice de
ces droits dans la rédaction de l'algorithme. La CNIL
recommande352 d'intégrer l'exercice des droits des personnes
dès la conception du logiciel, même si cette pratique n'est pas
obligatoire. Par exemple, implémenter une fonctionnalité qui
affiche l'ensemble des données relatives à une personne pour
garantir le droit d'accès. Il est aussi recommandé de
prévoir un traçage de l'ensemble des opérations ayant un
impact sur les données à caractère personnelle de la
personne concernée.
2.2. Principe de loyauté
Sur ce point l'EDPB considère353 que le
principe de loyauté est un principe global, qui permet d'éviter
que le traitement soit effectué de manière préjudiciable,
discriminante, inattendue ou trompeuse. Ce principe permet de garantir les
droits et libertés des personnes concernées. La mise en oeuvre de
ce principe passe par une attention particulière lors de la
350 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit., p.14
351 G29, «Guidelines on transparency under Regulation
2016/679», 11 avril 2018, p.6
352 CNIL, « Préparer l'exercice des droits des
personnes », 27 janvier 2020
353 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit., p.16
- 62 -
Le régime de lege lata
rédaction du code et la mise en place d'une
documentation et d'un système de contrôle de qualité du
code354.
De plus, la prise de décision entièrement
automatisée ayant des conséquences cruciales pour les personnes
est interdite par le RGPD355. Il convient donc de prévoir
systématiquement une intervention humaine356.
2.3. Principe de minimisation
Le principe de minimisation impose de limiter le nombre de
données traitées au strict nécessaire mais
également de restreindre leur accès aux seules personnes qui en
ont besoin pour l'accomplissement de la finalité du traitement. L'ENISA
recommande en application du principe de privacy by default de limiter
la quantité de données, l'ampleur du traitement, la durée
de stockage ainsi que l'accessibilité des données au
nécessaire357.
Il convient donc avant la collecte de réfléchir
aux données nécessaires au traitement et de justifier ce choix.
Si l'information n'est pas nécessaire au fonctionnement de l'application
mais permet seulement d'améliorer ses possibilités, l'utilisateur
doit pouvoir choisir d'utiliser ou non cette
fonctionnalité358. Le principe de minimisation impose
également de veiller à ce que la durée de conservation
soit adéquate. Sur ce point, l'EDPB rappelle que les traitements doivent
par défaut ne pas traiter de données à caractère
personnel, ces paramètres pouvant être modifiés tant par
les responsables du traitement que par les personnes
concernées359.
Limiter les accès aux données implique
d'anticiper les accès des utilisateurs en amont du traitement. La CNIL
recommande360 à cet effet d'attribuer des identifiants
propres à chaque utilisateur, de leur imposer une identification, de
prévoir une politique de gestion d'accès aux données
différenciées, de suivre les activités par un
système de journalisation et de prévoir des audits d'intrusion et
des tests de code. La conformité du principe de minimisation impose par
ailleurs de mener une politique de gestion des profils d'habilitation efficace.
Pour cela, il est préconisé de documenter ou d'automatiser les
procédures d'inscription et de désinscription, d'effectuer un
suivi régulier des droits accordés, de restreindre au maximum
l'utilisation des comptes administrateurs pour des opérations simples
ainsi que d'encourager l'usage d'un gestionnaire de mots de passe.
354 CNIL, « Veiller à la qualité de votre
code et sa documentation », 27 janvier 2020
355 Art. 22 RGPD
356 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.45
357 M. Hansen, K. Limniotis, ENISA, recommendations on GDPR
provisions, op cit., p. 22
358 CNIL, «Minimiser les données
collectées», 27 janvier 2020
359 EDPB, Guidelines 4/2019 on Article 25 Data Protection by
Design and by Default, op. cit., p.4
360 CNIL, «Gérer les utilisateurs», 27
janvier 2020
- 63 -
Le régime de lege lata
Lors de l'élaboration du logiciel, la CNIL
préconise361 de réfléchir en amont aux choix
technologiques employés. Il faut tout d'abord évaluer les impacts
de l'architecture et des fonctionnalités proposées. Ce choix doit
intégrer la protection de la vie privée, afin d'être
conforme aux principes de privacy by design et de privacy by
default. Il peut s'agir par exemple, du choix d'une architecture
décentralisée, de sécuriser l'architecture par
défaut, ou de garder la maitrise du système.
2.4. Principe de sécurité
Lors de la conception de l'architecture informatique, en
l'espèce, du logiciel d'intelligence artificielle, il est
impératif de se pencher sur les mécanismes de
sécurité.
L'ensemble de cette réflexion doit être
documentée. Cette documentation inclut l'écriture du code ainsi
que l'architecture et doit être régulièrement mise à
jour362. Ces mécanismes ne doivent pas reposer sur une seule
ligne de défense, mais intégrer des modules de défense
périphériques. Il peut s'agir par exemple, d'avoir une politique
de mot de passe sécurisé en accord avec la
délibération363 de la CNIL. Les risques incluent
également la sécurité des serveurs informatiques, dont il
est conseillé d'effectuer une veille sur l'état des attaques
informatiques364, et d'utiliser des outils de détection des
vulnérabilités365. Une analyse périodique de
ces risques doit être effectuée et une personne doit être
désignée pour les corriger366.
La sécurisation des données passe
également par le choix des outils et des pratiques. Les normes de
programmation doivent intégrer ces normes de sécurité,
tels que les standards C++367. La rédaction même du
code doit faire l'objet d'une attention particulière. Il est possible de
se référer à des standards existants368. Des
outils de contrôle de la qualité du code sont
recommandés369. Par ailleurs, il est impératif
d'utiliser systématiquement les dernières versions des briques
technologiques. Une attention particulière doit avoir lieu en cas
d'utilisation de logiciels SaaS et d'outils collaboratifs dans le
cloud370. Lorsque le développeur utilise des kits de
développement écrits par des tiers appelés aussi «
Software Developpent Kits » (SDK), il
convient de prendre garde à évaluer l'intérêt de
l'ajout de chaque dépendance et de choisir une
361 CNIL, «Préparer son
développement», 27 janvier 2020
362 CNIL « Veiller à la qualité de votre
code et sa documentation», 27 janvier 2020
363 CNIL, Délib. n° 2017-012 « portant
adoption d'une recommandation relative aux mots de passe », janvier
2017
364 Veille accessible sur les bulletins d'actualité du
CERT-FR
365 CNIL, «Sécuriser vos sites web vos
applications et vos serveurs », 27 janvier 2020
366 CNIL, « Sécuriser son environnement de
développement », 27 janvier 2020
367 CERT Secure Coding, «The SEI CERT C++ Coding
Standard», 2016
368 GitHub, « Awesome Guidelines », 4 janvier
2020 dernière modification
369 CNIL « Veiller à la qualité de votre
code et sa documentation», 27 janvier 2020
370 CNIL, « Sécuriser son environnement de
développement », 27 janvier 2020
- 64 -
Le régime de lege lata
bibliothèque qui prend en compte la question de la vie
privée, et auditer les bibliothèques et SDK371.
La sécurité inclut aussi l'environnement de
développement du code. Pour cela, la CNIL conseille de mettre en oeuvre
une procédure homogène sur tous les postes de travail, et de
centraliser cette procédure sur un document commun explicatif. Par
ailleurs, il est important de superviser la gestion des accès et la
traçabilité des opérations. Par exemple, en documentant la
gestion des clés SSH conformément aux
recommandations372 de l'ANSSI373.
La sécurité passe également par la
protection de l'environnement physique. La mise en place d'alarmes
anti-intrusions, d'un contrôle d'accès pour les zones à
risques et des contrôles d'accès sont
recommandés374. La sécurisation des postes de travail
doit aussi faire l'objet de précautions375.
Une fois que les environnements physiques et
numériques sont définis, le programmeur doit définir le
parcours des données tout au long de leur cycle de vie et le choix du
support correspondant au besoin du traitement376. Il faut en
parallèle permettre de supprimer les données à tout moment
et de sécuriser tous ces environnements. Si le traitement
nécessite le recours à un hébergeur, des
précautions supplémentaires doivent être adoptées
étant donné que les données sont transférées
à un sous-traitant : clause de confidentialité, connaitre la
localisation géographique des serveurs. Les bases de données
accessibles sur internet peuvent être protégées par une
restriction des adresses IP377 et une procédure de changement
des mots de passe utilisateurs378.
2.5. Principes de robustesse et d'exactitude
Pour que le système d'intelligence artificielle soit
digne de confiance, la Commission européenne recommande de
prévoir des prérequis pour garantir ces principes, de permettre
la reproductibilité des résultats. Il est également
conseillé de faire en sorte que les systèmes d'IA puissent
gérer les anomalies tout au long du cycle de vie du
traitement379.
371 CNIL, « Maitriser vos bibliothèques et vos
SDK », 27 janvier 2020
372 ANSSI, «Recommandations pour un usage
sécuriséì d'(Open)SSH», 17 août
2015
373 Agence nationale de la sécurité des
systèmes d'information
374 CNIL, « la sécurité des données
personnelles », les guides de la CNIL, 2018, p. 26
375 CNIL, « la sécurité des données
personnelles », les guides de la CNIL, 2018, p. 13
376 CNIL, «faire un choix éclairé de son
architecture», 27 janvier 2020
377 Une adresse IP (Internet Protocol) est un numéro
d'identification qui est attribué à chaque
périphérique relié à un réseau informatique
qui utilise l'Internet Protocol.
378 CNIL, «Sécuriser vos sites web vos
applications et vos serveurs », 27 janvier 2020
379 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p. 20
Le régime de lege lata
Il est aussi recommandé de permettre une supervision
humaine lors du design du logiciel, soit a priori avant la prise de
décision, soit a posteriori, selon le risque du traitement et
ce, même lorsqu'il ne crée pas de conséquences importantes
sur les droits et libertés des personnes.
§3. Étape 3 : initialisation

Définition du Modélisation Initialisation
Entrée Traitement Sortie
traitement
3.1. Principes de sécurité, loyauté,
licéité
L'évaluation est une étape clé du
développement d'un logiciel respectueux de la vie
privée380. L'ENISA recommande pour implémenter le
privacy by design de mettre en oeuvre une stratégie de
contrôle381. Il faut notamment anticiper dès la
collecte la possibilité de retirer son consentement et d'exprimer ses
préférences de vie privée.
Afin d'être certain que le logiciel effectue le
traitement attendu, la CNIL recommande de le tester au
préalable382. Cette phase inclut des tests de
développement et des tests de sécurité. Il convient de
veiller à tester le logiciel sur un jeu de données fictives,
c'est à dire des données qui ne sont pas liées à
des personnes existantes, pour ne pas détourner les données de
leur finalité initiale.
L'entrainement de la donnée par un logiciel
d'intelligence artificielle doit faire l'objet d'une attention
particulière d'après la Commission
européenne383. Il faut veiller à ce que les
règles édictées ne provoquent pas de discrimination et que
les données fassent l'objet d'une sécurité
adéquate. Par ailleurs, la Commission recommande de conserver les jeux
de données afin de pouvoir effectuer un audit ex-post. Une
documentation sur la programmation et les techniques utilisées ainsi que
les suivis des mises à jour sont également recommandés.
- 65 -
380 L. Gabudeanu, «Embedding privacy in software
development: Implementation aspects», EDPS, juin 2019
381 G. D'acquisto, J. Domingo-ferrer, ENISA, «Privacy by
design in big data», décembre 2015, p.26
382 CNIL, « Tester vos applications », 27
janvier 2020
383 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p. 19
- 66 -
Le régime de lege lata
§4. Étape 4 : Entrée

Définition du Modélisation Initialisation
Entrée Traitement Sortie
traitement
L'étape « entrée » correspond
au moment où les données sont traitées par le logiciel.
Cela signifie donc que la collecte a été effectuée
auparavant et que le RGPD s'applique.
4.1. Principe de minimisation des données
Le principe de minimisation signifie que seules les
données « adéquates, pertinentes et limitées
à ce qui est nécessaire au regard des finalités
» doivent être collectées. C'est donc le critère
de nécessité qui va déterminer si chaque donnée est
pertinente pour la collecte et le traitement. L'EDPB
suggère384 d'analyser le degré de
confidentialité pertinent en privilégiant par exemple les
données pseudonymes aux données à caractère
personnel. Par ailleurs, il faut analyser périodiquement l'état
des process, des procédures et de la technologie afin d'être
certain que le besoin de traitement de ces données existe toujours.
Pour mettre en oeuvre ce principe, la CNIL
recommande385 de mettre en place un système de purge
automatique des données après expiration de la durée de
conservation, de réduire la sensibilité des données en les
pseudonymisant dès que possible, et de mettre en place une
procédure de suivi des effacements. L'état des techniques de
minimisation actuelles sont accessibles dans le guide de la CNIL relatif
à l'AIPD des objets connectés386.
4.2. Principe d'exactitude
L'article 5.1. d) dispose que les données
traitées doivent être « exactes et, si nécessaire,
tenues à jour ; toutes les mesures raisonnables doivent être
prises pour que les données à caractère personnel qui sont
inexactes, eu égard aux finalités pour lesquelles elles sont
traitées, soient effacées ou rectifiées sans tarder
».
4.3. Principe de transparence
Dès la collecte des données, il est
nécessaire d'informer les personnes concernées,
conformément au privacy by design387. Le contenu de
l'information varie suivant le fait que la collecte est effectuée
directement ou indirectement auprès de la personne concernée.
384 EDPB, «Guidelines 4/2019 on Article 25 Data
Protection by Design and by Default», 20 novembre 2019, p.19
385 CNIL, « Minimiser les données
collectées », 27 janvier 2020
386 CNIL, « Analyse d'impact relative à la
protection des données », février 2018, p. 39
387 G. D'acquisto, J. Domingo-ferrer, ENISA, «Privacy by
design in big data», décembre 2015, p.26
- 67 -
Le régime de lege lata
L'information doit être facile d'accès,
délivrée de manière claire et compréhensible,
concise, et distinguée des autres types d'information388. Par
ailleurs, le G29 précise389 que pour garantir les principes
de protection des données par design et par défaut, des
mécanismes de traçage de l'identification du responsable du
traitement devraient être mis en place tout au long du cycle de vie de la
donnée afin de garantir le principe de transparence.
En cas de faille de sécurité présentant
un risque pour les personnes, le responsable du traitement doit informer la
CNIL dans les 72 heures qui suivent la connaissance de cette faille, ainsi que
les personnes concernées si le risque est
élevé390.
Les traitements par des logiciels d'intelligence artificielle
doivent faire l'objet d'informations supplémentaires. Les articles
13.2.f) et 14.2.g) du RGPD disposent du droit d'être informé d'une
prise de décision automatisée et de l'obligation d'informer les
personnes du fait qu'ils interagissent avec un robot et non avec un humain.
L'article 22 du RGPD ajoute un droit d'obtenir des
informations sur la logique de fonctionnement algorithmique et des
conséquences potentielles du traitement. La CNIL recommande de
préférer le principe d'intelligibilité au principe de
transparence391. Le principe de transparence peut être trop
réducteur et se traduire par la publication du code source, peu
compréhensible par le grand public. A l'inverse, le principe
d'intelligibilité vise à expliquer la logique
générale de fonctionnement de l'algorithme. Dans une logique
similaire, la Commission européenne recommande de préciser les
capacités et les limites des systèmes d'intelligence artificielle
au regard de la finalité pour laquelle ils
s'exécutent392.
Toutefois, le devoir d'information n'inclut pas toujours
l'obligation d'explicabilité des algorithmes. Le RGPD impose le droit
à l'explicabilité seulement pour des décisions
fondées exclusivement sur un traitement automatisé et ayant des
effets sur la personne concernée. Néanmoins, comme l'a
rappelé le Conseil d'État dans sa décision
Parcoursup393, certains régimes spéciaux posent un
cadre plus contraignant telle que la Loi sur la République
Numérique. La prise de décision automatisée entrainant des
décisions à l'égard des personnes concernées en
matière de traitement effectué par l'administration publique fait
l'objet d'un décret394. En l'espèce, lors d'un
traitement régissant les relations entre les administrations et le
public, le droit d'information existe dès lors qu'une décision
est prise, même de manière
388 CNIL, « Informer les personnes », 27
janvier 2020
389 G29, «Guidelines on transparency under Regulation
2016/679», 29 novembre 2017, p.29
390 Art. 33 RGPD
391 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.51
392 Commission Européenne, livre blanc sur
l'intelligence artificielle, op. cit., p. 20
393 Conseil d'Etat, décision n° 427916, 12 juin
2019
394 Décret n° 2017-330, relatif aux droits des
personnes faisant l'objet de décisions individuelles prises sur le
fondement d'un traitement algorithmique, 14 mars 2017
- 68 -
Le régime de lege lata
partielle, par un algorithme395. Dans ce cas de
figure, les administrations françaises ne pourront donc pas effectuer un
traitement par un logiciel d'apprentissage non supervisé, le devoir
d'information ne pouvant être respecté396. Plus
largement, la Convention 108+ du Conseil de l'Europe institue un droit «
d'obtenir, à sa demande, connaissance du raisonnement qui sous-tend
le traitement de données, lorsque les résultats de ce traitement
lui sont appliqués397 ». Ce droit englobe donc
l'ensemble des traitements comme le remarquent W. Maxwell, C.
Zolynski398. La France a signé le Protocole d'amendement
à la Convention pour la protection des personnes à l'égard
du traitement automatisé des données à caractère
personnel399. Or, le nombre de ratifications n'ayant pas
été atteint pour le moment, cette version n'est pas susceptible
d'entrer en vigueur rapidement.
L'article 22 et le considérant (71) du RGPD disposent
également d'un droit d'opposition à un traitement
entièrement automatisé et du droit d'obtenir une intervention
humaine.
4.4. Principe de sécurité
Sur le plan technique, il est recommandé d'appliquer
les PETs pour dissimuler les données à caractère personnel
par des procédés de pseudonymisation ou de
chiffrement400.
§5. Étape 5 : Traitement des
données

Définition du Modélisation Initialisation
Entrée Traitement Sortie
traitement
5.1. Principe de limitation de la conservation
Les données doivent être conservées
seulement pour une durée nécessaire aux objectifs poursuivis par
le traitement. Le cycle de conservation des données est divisé en
trois phases401 :
o la base active
o l'archivage intermédiaire
o l'archivage définitif ou la suppression
La CNIL recommande de restreindre les accès à
l'archivage intermédiaire aux services spécifiques chargés
de les sortir des archives, de prévoir des modalités
d'accès spécifiques aux données archivées et de
mettre en oeuvre un mécanisme de purge ou d'anonymisation.
395 Art. R. 311-3-1-2 Code des relations entre le public et
l'administration
396 W. Maxwell, C. Zolynski, Protection des données
personnelles, Recueil Dalloz - D. 2019. 1673 §1
397 Art.9,1.C, Conseil de l'Europe, Convention 108+,
modifiée en 2018, p.9
398 W. Maxwell, C. Zolynski, Protection des données
personnelles, Recueil Dalloz - D. 2019. 1673 §1
399 Conseil de l'Europe, Etat des signatures et ratifications
du traité 223, 19 mars 2020
400 G. D'acquisto, J. Domingo-ferrer, ENISA, «Privacy by
design in big data», décembre 2015, p.26
401 CNIL, « Gérer la durée de conservation
des données », 27 janvier 2020
Le régime de lege lata
5.2. Principe de sécurité
Tout au long du stockage des données, les techniques de
chiffrement sont conseillées. Par ailleurs, l'ENISA recommande de mettre
en place des mesures organisationnelles telles que l'authentification et le
contrôle d'accès. La décentralisation du stockage des
données est encouragée402. Il faut également
veiller à encadrer la maintenance et la destruction des
données403.
§6. Étape 6 : Sortie

Définition du Modélisation Initialisation
Entrée Traitement Sortie
traitement
6.1. Principe de sécurité
Lors de l'analyse des données, la mise en oeuvre de
mécanismes de chiffrement et de pseudonymisation est recommandée
lorsque cela est possible404.
Ainsi, le traitement actuel par un logiciel d'intelligence
artificielle peut être conforme à la protection des données
à caractère personnel. Il faut pour cela définir
clairement la gouvernance des données et utiliser les outils des
conformité adaptés. Des précautions sont néanmoins
requises tout au long du développement et de l'utilisation du
logiciel.
- 69 -
402 G. D'acquisto, J. Domingo-ferrer, ENISA, «Privacy by
design in big data», décembre 2015, p.26
403 CNIL, « la sécurité des données
personnelles », 2018, p. 22
404 G. D'acquisto, J. Domingo-ferrer, ENISA, «Privacy by
design in big data», décembre 2015, p.26
- 70 -
Titre 2 : Le régime de lege feranda405
Le traitement des données par des logiciels
d'intelligence artificielle respectueux de la protection des données
personnelles est dès à présent mis à mal face
à l'évolution du numérique. Les logiciels
développés dans d'autres régions du monde ne prennent pas
toujours en compte la protection de la vie privée par défaut
et/ou dès la conception. L'Europe s'est fixé comme objectif
d'incarner une alternative éthique en proposant des solutions
d'intelligence artificielle garantes de la vie privée (Chapitre 1). En
parallèle, la place croissante des algorithmes dans notre
société impose de doter les individus d'instruments leur
permettant de faire des choix éclairés (Chapitre 2). Il convient
donc d'acquérir une souveraineté tant individuelle que collective
en matière d'IA.
Chapitre 1 : De la gouvernance de la donnée
à la gouvernance de l'intelligence artificielle
La gouvernance de l'intelligence artificielle ne peut
être envisageable que par un positionnement de l'Europe en tant que
leader (Section 1) en proposant un modèle éthique pérenne
(Section 2).
Section 1 : l'IA éthique, stratégie
géopolitique de souveraineté européenne
Selon N. Miailhe, il serait naïf de penser que l'IA est
une technologie neutre, alors qu'il s'agit en réalité d'un
système socio-économique complexe, gouverné par les
humains406. L'intelligence artificielle est un instrument de
puissance incontestable conduit aujourd'hui par quelques pays et entreprises
(§1). Cette gouvernance du numérique pose des questions
éthiques (§2) sur laquelle l'Europe doit se positionner
(§3).
§1. Le contexte géopolitique de l'intelligence
artificielle
Le marché de l'intelligence artificielle est
aujourd'hui dominé par un duopole sino-américain407.
Il se caractérise par la taille du marché des deux puissances et
leurs politiques laxistes en matière de protection des données
à caractère personnel.
405 De lege feranda signifie « quant à
la loi que l'on doit appliquer »
406 N. Miailhe, « Géopolitique de l'intelligence
artificielle : le retour des empires ? », politique
étrangère, 2018, p. 117
407 Ibid., p. 112
- 71 -
Le régime de lege feranda
Aux États-Unis, la conservation du titre de leader de
l'IA fait partie d'un des quatre objectifs de la Maison-Blanche. Le pays
dispose de nombreux talents, et notamment deux fois plus de chercheurs qu'en
Chine, soit plus de 78 000 scientifiques408. La Chine ambitionne de
devenir le premier centre global de l'IA d'ici 2030 et inclut sa
stratégie numérique de l'IA dans sa stratégie
géopolitique à l'image du programme des « routes
digitales de la soie ». Elle dispose d'une législation
permissive et d'un rôle fort de l'État, qui encourage
l'innovation409. Néanmoins, la Chine reste dépendante
de l'exportation américaine des processeurs et de puces, qui sont
nécessaires au développement du machine learning.
Face à ces deux géants, l'Europe dispose
aujourd'hui d'un retard technique et industriel, si bien qu'elle risque de
devenir une « colonie du numérique ». Si l'Union
Européenne dispose d'un marché signifiant et d'experts notoires,
les investissements privés en IA sont faibles et les rares
licornes410 se heurtent au manque de dynamisme capitalistique et
industriel du marché européen411.
A l'échelle nationale, certains pays européens
tels que l'Espagne la France et le Royaume-Uni sont favorables au
développement de l'IA à l'image des entreprises telles que
Artlenics, Shift Technology et Darktrace et de l'initiative gouvernementale
« France IA »412. Néanmoins, seule une
coopération entre puissances européennes permettra
d'acquérir une taille critique, capable de concurrencer les autres
acteurs413.
§2. L'Europe, alternative pour garantir la vie
privée
L'Union Européenne s'est construite autour de valeurs
économiques, politiques et philosophiques communes. Le sénateur
A. Gattolin souligne que les libertés individuelles et le droit des
peuples étant un pilier de la construction européenne, une
proposition éthique sur l'intelligence artificielle est
nécessaire pour les garantir414. C. Castets-Renard
insiste415 par ailleurs sur la valeur du mot éthique et les
spécificités culturelles, politiques et technologiques qui
encadrent l'usage de l'intelligence artificielle. C'est dans ce cadre
éthique que l'Europe et la France pourront proposer une alternative et
être « championnes d'une IA éthique et
408 N. Miailhe« Géopolitique de l'intelligence
artificielle : le retour des empires ? » , politique
étrangère, 2018, p. 113
409 C. Thibout, « L'intelligence artificielle, un rêve
de puissance », Chronik, 10 septembre 2018
410 Start-up dont la valorisation dépasse 1 milliards de
dollars
411 N. Miailhe, Géopolitique de l'intelligence
artificielle : le retour des empires ?, op. cit., p. 114
412 F. Amat, « Geopolitique de l'intelligence
artificielle : une course mondiale à l'innovation »,
Diploweb : la revue géopolitique, 28 mars 2018
413 L. Bloch, « Internet : que faire pour défendre
nos chances ? » Diploweb, 20 mai 2015
414 Conférence parlementaire, «
cybersécurité, protection desonnées, intélligence
artificielle : quels enjeux pour l'Europe ? » Organisée par le
Sénat français, le Bundesrat allemand et le Sénat
polonais, 20 juin 2019, p. 19
415 C. Castets-Renard, « L'intelligence artificielle, les
droits fondamentaux et la protection des données personnelles dans
l'Union européenne et les États-Unisé », Revue de
Droit International d'Assas, RDIA n° 2019 | 163 P.1.72. et s.
- 72 -
Le régime de lege feranda
soutenable416 ». Ce
positionnement correspond par ailleurs à une demande forte étant
donné que 86% des utilisateurs préfèrent choisir un objet
connecté qui protège by default la vie
privée417. Dans cette perspective, une proposition
européenne éthique adaptée aux développements de
l'intelligence artificielle donnerait un réel avantage
concurrentiel418.
§3. Les moyens à mettre en place pour y parvenir
Une souveraineté des données doit être
mise en place à l'échelle européenne, des États,
des entreprises, mais aussi des individus419. La Commission de
réflexion sur l'Éthique de la Recherche en science et
technologies du Numérique d'Allistene recommande420 notamment
d'intégrer les notions éthiques aux enjeux politiques et
économiques de souveraineté numérique. Pour l'ancienne
Secrétaire d'État chargée du Numérique et de
l'Innovation A. Lemaire421, l'Europe dispose des ressources
nécessaires pour être leader et proposer un environnement
numérique à la fois fiable et sûr. La société
civile considère également que l'Europe peut être leader
d'une intelligence artificielle éthique422. Pour atteindre
cet objectif, il convient de réunir plusieurs facteurs qui sont la
création d'un marché unique de données
réglementées, des infrastructures maitrisées, des projets
européens capables de concurrencer les plateformes
étrangères.
Dans cette perspective, l'Union Européenne a
présenté sa stratégie pour l'intelligence artificielle
avec trois axes majeurs : « renforcer la capacité technologique
et industrielle de l'UE et l'adoption de l'IA dans l'ensemble de
l'économie ; préparer les changements socio-économiques ;
garantir un cadre éthique et juridique
approprié423 ». La politique européenne en
faveur de l'IA424 lancée par la Commission européenne
dans son livre blanc sur l'intelligence artificielle détaille cet
objectif425. La mise en oeuvre d'une souveraineté
numérique impose une réglementation uniforme, ainsi que des
investissements humains et financiers suffisants.
416 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.25
417 G. Rostana, A. Bekhardi, B. Yannou, op. cit., p.4
418 Commission Européenne, « L'intelligence
artificielle pour l'Europe », 25 mai 2018, p.3
419 J.-G. Ganascia, E. Germain, C.Kirchner, « La
souveraineté à l'ère du numérique. Rester
maîtres de nos choix et de nos valeurs », CERNA, Octobre 2018,
p.28
420 Ibid., p.34
421 Coup Data, «3 Questions To... Axelle
Lemaire», 3 décembre 2019
422 Editorial, Le monde « L'intelligence artificielle, enjeu
majeur pour l'UE », 18 février 2020
423 Conseil de l'Union Européenne, « Governance of
the Artificial Intelligence Strategy for Europe», juillet 2018
424 Commission Européenne « Robustesse et
explicabilité de l'intelligence artificielle », 2020, p. 6
425 Commission Européenne, « Whitepaper, A European
approach to excellence and trust », 19 février 2020
- 73 -
Le régime de lege feranda
3.1. Proposer un socle normatif fiable
cy428.
Le cadre normatif s'opère à deux niveaux : d'une
part, par un cadre réglementaire conforme aux droits fondamentaux et
d'autre part par l'autorégulation des acteurs426. La
réglementation du numérique s'articule au niveau européen
autour du RGPD et de la Directive ePrivacy427,
prochainement remplacée par le Règlement ePriva
Le RGPD a été construit sur une volonté
de pallier la domination numérique américaine. Il s'agit avant
tout d'un instrument de diplomatie européen de soft
law429. Le Secrétaire général de
l'Institut de la Souveraineté Numérique, B. Benhamou
considère que le RGPD a eu un effet significatif mais qu'il ne s'agit
que d'une première étape430. Depuis sa conception,
l'effet de réseau s'est accéléré et de nouvelles
technologies telles que l'Internet des objets pointent les angles morts de la
régulation. Il recommande de mettre à jour le RGPD et le futur
Règlement ePrivacy, pour favoriser davantage une «
préoccupation by design » de l'architecture technologique.
L'EDPS appelle à prendre en compte le privacy by design dans la
rédaction de ce règlement et de créer un observatoire de
« l'état des connaissances » des PETs431.
Néanmoins, une régulation spécifique des algorithmes
s'avère inadaptée à l'heure actuelle432 car
elle deviendrait rapidement obsolète et serait susceptible de freiner
l'innovation.
3.2. Doter la CNIL de moyens adaptés à ses
missions
Le financement doit également cibler les
autorités de régulation. La CNIL dispose de moyens humains et
financiers inférieurs à d'autres autorités de l'Union, ce
qui décrédibilise l'influence de la France en matière de
protection des données personnelles433. La CNIL se retrouve
ainsi submergée par le nombre de plaintes, et « craque, comme
dans un habit trop étroit »434. Les
autorités ont besoin de capacités techniques pour pouvoir
effectuer des contrôles sur une quantité colossale de
données. Par exemple, La Direction Générale de la
Concurrence a traité 5,2 téraoctets de données, cela
équivaut à plus de 20 millions de documents PDF, et a
426 Commission Européenne, « L'intelligence
artificielle pour l'Europe », 25 mai 2018, p.18
427 Directive 2002/58/CE, règlement «vie
privée et communications électroniques»
428 Règlement concernant le respect de la vie
privée et la protection des données à caractère
personnel dans les communications électroniques et abrogeant la
directive 2002/58/CE, dont la dernière version est accessible ici
429 A. Banck, D. Rahmouni, « Le RGPD, nouvel outil de
soft law de l'Europe dans le numérique », Revue Lamy droit de
l'immatériel n°151, 2018, p. 54
430 Annales des Mines,«Concurrence et numérique
: entretien avec Bernard Benhamou», enjeux numériques,
N°8, décembre 2019, p. 118
431 EDPS, « Avis préliminaire sur le respect de la
vie privée dès la conception » avis 5/2018, 31 mai 2018, p.
26
432 CNIL, sondage, op. cit., p.44
433 F. Montaugé, G. Longuet, Rapport Commission
d'enquête sur la souveraineté au numérique, « le
devoir de souveraineté numérique : ni résignation, ni
naïveté » version provisoire, n° 7 tome I
(2019-2020) , 1 octobre 2019, p. 64
434 Propos de l'ancienne directrice de la CNIl,
rapportés dans l'art. de B. Leclercq, « Vie numérique :
Place à l'éthique », Libération, 17 novembre
2019
- 74 -
Le régime de lege feranda
effectué 1,7 milliard de recherche dans le cadre du
dossier Google Shopping435. Le rapport provisoire du Sénat
sur la souveraineté du numérique propose pour cela d'investir
dans un personnel qualifié capable d'effectuer des contrôles et
des audits d'algorithmes, qui pourrait être mutualisé entre les
Autorités Administratives Indépendantes
françaises436.
3.3. Investir dans la recherche
Par ailleurs, l'investissement dans la recherche est
nécessaire. La France regorge de talents à l'image des 8 prix
Nobel scientifiques et des 16 médailles Fields obtenus437.
L'Enseignement Supérieur de la Recherche (ESR) en IA jouit par ailleurs
d'une forte notoriété438. Néanmoins, le budget
R&D français n'est aujourd'hui qu'au 6e rang
mondial439 et la fuite des cerveaux est un grand frein au
développement de la recherche européenne. Cette fuite s'accentue
d'autant plus que la frontière entre la recherche privée et
publique devient poreuse et que les GAFA créent des centres de recherche
où ils recrutent ces mêmes chercheurs. Le rapport Villani
émet des recommandations à cet égard : doubler les
salaires de début de carrière des chercheurs, créer un
supercalculateur pour pouvoir initialiser les IA ainsi qu'un cloud
privé capable de stocker ces données440.
Sur le plan européen, l'investissement dans le domaine
de l'intelligence artificielle s'élève à 3,2 milliards
d'euros en 2016, contre 12,1 milliards aux États-Unis et 6,4 milliards
en Chine441.
3.4. Encourager l'innovation
Enfin, l'investissement dans des secteurs clés doit
être conséquent pour stimuler l'innovation. C'est le cas du
domaine des Deeptech, synergie d'acteurs publics et privés dans
des technologies complexes, dont l'intelligence artificielle fait partie. Les
Deeptechs d'aujourd'hui sont les GAFA de demain442, ce qui
explique cet investissement important dans ces technologies de rupture alors
que leur risque d'échec est plus important443. En cinq ans,
les investissements mondiaux dans ce secteur ont augmenté de 5,5%. Or,
si la France est aujourd'hui le deuxième pays Européen en termes
de capitaux investis444, ces investissements
435 F. Montaugé, G. Longuet, op. cit., p. 64
436 Ibid., P. 64
437 D. Boujo, BPIfrance, « Génération
Deeptech », janvier 2019, p. 15
438 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.73
439 D. Boujo, BPIfrance, « Génération
Deeptech », janvier 2019, p. 15
440 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.89
441 Commission Européenne, « Whitepaper, A European
approach to excellence and trust », 19 février 2020, p.4
442 D. Loye, Les échos entrepreneurs, « Les deep
techs d'aujourd'hui sont les prochains Gafa », 12 mars 2020
443 Ou disruptives
444 D. Boujo, BPIfrance, « Génération
Deeptech », janvier 2019, p. 23
- 75 -
Le régime de lege feranda
représentent 4% des investissements américains
en 2017445. Pour pallier ce retard, la BPI France a
créé un plan DeepTech et investit 775 Millions
d'euros446 dans ce secteur clé pour accompagner et financer
les projets innovants. Le programme s'élève à 1,35
milliards d'euros sur cinq ans447.
En parallèle, le gouvernement a mis en place un plan
sur l'intelligence artificielle qui vise à investir 1 milliard d'euros
supplémentaires448.
L'Union européenne a également investi
massivement. Toutefois, les 20 milliards d'euros d'investissement prévus
ne font pas l'objet d'un contrôle précis449.
Si ces conditions sont réunies, l'Europe pourra se
placer en leader de l'intelligence artificielle éthique. Cela passe par
exemple, par le design des plateformes, atout de différenciation. Selon
la CNIL, « ces outils [de design] sont donc à-même de se
muer en leviers de soft power particulièrement efficaces, puisqu'ils
façonnent l'univers numérique à l'image des grandes
plateformes450 ». Dès lors, le design doit
être conforme aux principes de privacy by design et de
privacy by default et peut en ce sens être un atout de
différenciation éthique.
Section 2 : L'éthique de l'IA, fruit d'une
réflexion pluridisciplinaire de tous les acteurs
Une approche interdisciplinaire est nécessaire pour
réfléchir aux enjeux éthiques de l'intelligence
artificielle451 (§2). Elle doit réunir les disciplines
économiques, juridiques, sociales et techniques, car elles se confondent
dans ces questions452 (§1).
§1. Inclure tous les acteurs dans la réflexion
éthique de l'IA
Une Europe pionnière d'une intelligence artificielle
éthique n'est possible que si chaque maillon de la chaîne de
création d'un logiciel d'IA est sensibilisé à ces enjeux,
comme le recommande la CNIL453.
Cette sensibilisation débute tout d'abord par le
responsable du traitement. L'EDPS a rappelé à plusieurs reprises
la nécessité pour les entreprises d'adopter une culture
éthique454.
445 Ibid., p. 25
446 Ibid., p. 4
447 Corp, « Guide du big data : 365 jours au coeur de la
data économie », 2019-2020, p.43
448 Ibid., p. 43
449 C. Thibout, « La stratégie européenne
en intelligence artificielle : un acte manqué ? », Iris France, 19
février 2020
450 CNIL, LINC, « Cahier IP - La forme des choix -
Données personnelles, design et frictions désirables »,
P.23
451 A. Basdevant, « Promoting data culture in Europe
with interdisciplinary research institutes », Coup Data, 8
octobre 2019
452 R., Alain, F.Rochelandet, et C/Zolynski. « De la
Privacy by Design à la Privacy by Using. Regards
croisés droit/économie », Réseaux, vol. 189,
no. 1, 2015, pp. 15-46.
453 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.54
454 Practical law, «Expert Q&A: European Data
Protection Supervisor on Digital Ethics», 2019, p.2
- 76 -
Le régime de lege feranda
C'est pour cela que le RGPD place au coeur de sa
règlementation le principe d'acccountability455, qui
va de pair avec le privacy by design et le privacy by
default. Cette sensibilisation porte déjà ses fruits, mais
témoigne aussi de la puissance des grandes entreprises du
numérique, à l'heure où Microsoft propose une Convention
de Genève digitale456.
Les développeurs doivent également faire partie
de la concertation sur l'éthique du numérique. La
nécessité de former des programmeurs capables de
développer des logiciels d'intelligence artificielle est croissante. Si
la pénurie d'experts dans ce domaine était déjà
annoncée en 2011 dans un rapport de McKinsey Global Institute et dans le
rapport ministériel de T. Rhamani en 2014457, une
étude plus récente prévoit une augmentation de la demande
de Data scientist et Data analysts de 28 % dans les cinq
prochaines années458.
Le rapport Villani insiste sur la nécessité de
sensibiliser à l'éthique les ingénieurs et les chercheurs
en IA dès leur formation459. Ils auront un rôle «
décisif dans la société numérique de demain
». Cet enseignement devrait viser à doter ces programmeurs
d'outils conceptuels afin d'agir de manière responsable en cas de
confrontation à des questions morales et éthiques. Cette
formation est d'autant plus nécessaire que ces futures questions ne
pourront pas être tranchées directement par le droit. Par exemple,
la responsabilité incombera aux développeurs en matière de
systèmes de traçabilités dans leurs algorithmes. En cas
d'apprentissage supervisé, L.Godefroy recommande460 aux
programmeurs de porter une attention particulière aux données
annotées qui constituent le traitement pour l'initialisation de
l'algorithme.
L'interface homme-machine étant le « premier
objet de médiation entre la loi, les droits et les individus
», il est impératif de sensibiliser les architectes
informatiques à un « design de la privacy461
» et de les intégrer à la chaîne de
gouvernance462.
Il est essentiel que les autorités de régulation
s'adaptent à cette évolution technologique. Dans un rapport
conjoint, ces autorités, dont la CNIL, appellent à une
régulation par la donnée463. Cette nouvelle approche,
qui complète les outils traditionnels de régulation, vise
à sensibiliser tous les acteurs du marché pour les inciter
à un comportement responsable. Cette vision appelle à un
changement de culture. Ces Autorités recommandent également la
pratique
455 G. Buttarelli , «Artificial Intelligence and the
future Digital Single Market «, EDPS, Keynote speech on privacy, 24
avril 2018
456 B. Smith, «The need for a Digital Geneva
Convention», Microsoft, 14 février 2017
457 T. Rhamani , « Les développeurs, un atout pour
la France », 2014
458 Burning Glass Technologies, BHEF, IBM, «The quant
crunch how the demand for data science skills is disrupting the job
market», 2017, p. 6
459 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.146
460 L. Godefroy, « Le code algorithmique au service du droit
» recueil Dalloz, 2018, p. 734
461 CNIL, LINC, « Cahier IP - La forme des choix -
Données personnelles, design et frictions désirables »,
p.10
462 Ibid., P.39
463 AMF, Arafer, Arcep, Arjel, CNIL, CRE, CSA, ADLC, «
Nouvelles modalités de régulation : la régulation par la
donnée », 8 juillet 2019, p.3
- 77 -
Le régime de lege feranda
du « crowdsourcing », qui consiste à
s'appuyer sur des acteurs tiers pour optimiser leurs actions et leurs
régulations464. Enfin, pour mener à bien leur
rôle de régulateur, ces Autorités ont besoin elles aussi
d'une formation afin de se doter de compétences techniques, et de mettre
à disposition des outils communs permettant de traiter les
données. Dans cette perspective, l'usage de l'IA permettrait d'aider la
vérification de la conformité du privacy by design et du
privacy by default.
De nombreux acteurs du numériques appellent par
ailleurs à la création d'une entité
spécialisée sur les questions du numériques.
Déjà en 2015, la commission parlementaire465 proposait
de former les juges au numérique et de créer un «
pôle de compétences numériques » au sein du
ministère de la Justice. Parmi les praticiens, A. Basdevant et J. P
Mignard appellent à la création d'un parquet
spécialisé dans le numérique466. Le rapport
Villani élargit les pouvoirs de cette entité et
recommande467 de créer un service d'audit des algorithmes.
Ces experts agiraient soit dans le cadre d'enquêtes judicaires ou sous la
demande d'autorités administratives indépendantes. Leur champ
d'action s'exercerait à plusieurs niveaux : accès à
certaines preuves, consultation du code source, test des biais algorithmiques
avec des bases de données fictives. Certains auteurs, comme L.
Godefroy468 prônent la création d'une autorité
de contrôle des algorithmes capable d'effectuer des audits des
algorithmes. La CNIL partage également cette opinion469.
Les praticiens doivent également se saisir des
questions éthiques de l'IA, et cela impose une compréhension de
la technologie. C. Castets-Renard propose470 deux méthodes
complémentaires. Il s'agit dans un premier temps d'évaluer les
enjeux juridiques d'une technologique pour chaque branche du droit. Dans un
second temps, il conviendra de mesurer les questions juridiques
soulevées par les nouvelles technologies pour comprendre les risques
économiques et sociaux sous-jacents. Dans la même perspective, les
praticiens du droit devront être sensibilisés aux techniques de
l'informatique. Le rapport Villani suggère471 ainsi de
permettre des enseignements pluridisciplinaires avec par exemple une majeure en
droit et une mineure en informatique.
Dernier point, mais non des moindres, l'ensemble de la
population civile doit mesurer les enjeux éthiques de ces technologies
afin d'exercer leurs droits et de permettre un débat
464 Ibid., p.9 et s.
465 Commission de réflexion et de propositions sur le
droit et les libertés à l'âge numérique, op.
cit., prop. n°36, 37
466 A. Basdevant, J. Mignard, op. cit. , p. 177
467 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.143
468 L. Godefroy, « Le code algorithmique au service du droit
» recueil Dalloz, 2018, p. 734
469 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.57
470 C. Castests-Renard, « Comment construire une
intelligence artificielle responsable et inclusive ? » Recueil Dalloz
2020, p.225
471 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.147
- 78 -
Le régime de lege feranda
démocratique472. Cela passe d'abord par
l'éducation. Le Conseil de l'Europe473, et le rassemblement
des Autorités de protection des données
internationales474 se sont saisis de ces questions. En France, des
dynamiques sont mises en place mais sont insuffisantes, et il est
impératif que les individus « ne (soient) pas seulement
consommateur de l'ère numérique mais aussi entrepreneur,
innovateur et créateur475 ». C'est en étant
formé dès l'école et en étant sensibilisé
régulièrement à ces enjeux que les individus pourront
« rester maîtres476 » de leurs choix, et
ainsi s'approprier leur souveraineté numérique.
§2. La mise en oeuvre de cette collaboration
Cette réflexion pluridisciplinaire commence dès
la recherche. Le Rapport Villani recommande477 de travailler entre
spécialistes de l'IA et spécialistes d'autres disciplines afin de
créer une synergie. Il propose pour cela de créer des Instituts
Interdisciplinaires d'intelligence artificielle (3IA),
caractérisés par une autonomie et une pluridisciplinarité
entre les sciences sociales et les sciences dures, mais également par le
profil des personnes : étudiants, ingénieurs, chercheurs. Cette
recommandation a porté ses fruits, puisque quatre instituts ont vu le
jour à Grenoble, Nice, Paris et Toulouse478.
La nécessité de créer un comité
national d'éthique du numérique, distinct de la CNIL est
affirmée479 et réaffirmée480 par les
présidents d'instituts scientifiques dont le CERNA, le CNRS, et l'INRIA.
Fin 2019, la création d'un comité éthique du
numérique481 a finalement vu le jour dans un contexte de
programme national de recherche en IA en plein essor482.
Sur le plan international, l'OCDE a lancé son propre
observatoire pluridisciplinaire et consultatif de l'IA483. Le
Conseil de l'Europe a créé en septembre 2019 le Comité Ad
Hoc sur l'intelligence artificielle (CAHAI484). Des initiatives
multipartites émergent à l'instar de la
472 B. Leclercq, « Vie numérique : Place à
l'éthique », 17 novembre 2019
473 Conseil de l'Europe, « Décoder
l'intelligence artificielle : 10 mesures pour protéger les droits de
l'homme », objectif n° 4, mai 2019, p. 10
474 ICDPPC « Report of the International Working Group on
Digital Education » Août 2019, action 1, p.2
475 Institut Montaigne, « enseignement supérieur :
connectez vous ! », juin 2017, p. 104
476 J-G. Ganascia, E. Germain, C. Kirchner, « La
souveraineté à l'ère du numérique. Rester
maîtres de nos choix et de nos valeurs », CERNA, Octobre 2018, S-5
et S-6
477 C. Villani, « Donner un sens à l'intelligence
artificielle », mars 2018, p.75, 16
478 Ministère de l'enseignement supérieur,
« Lancement de 4 Instituts Interdisciplinaires d'intelligence
artificielle (3IA) et ouverture de deux appels à projets
complémentaires », 24 avril 2019
479 Dirigeants d'instituts scientifiques, « Il faut
créer un comité national d'éthique du numérique
», Le monde, 14 décembre 2017
480 J.-G. Ganascia, E. Germain, C. Kirchner, « La
souveraineté à l'ère du numérique. Rester
maîtres de nos choix et de nos valeurs », CERNA, Octobre 2018
481 CCNE, « Création du comité pilote
d'éthique du numérique » 2 décembre 2019
482 AI for Humanity, « Lettre d'information »,
numéro 2, décembre 2019
483 OCDE, « Lancement de l'observatoire ocde des
politiques relatives à l'intelligence artificielle », 27
février 2020
484 Les missions du CAHAI sont accessibles ici
- 79 -
Le régime de lege feranda
déclaration de Montréal pour une IA
responsable485, et des recommandations d'un cadre éthique du
groupe d'experts AI4People486. Les institutions ont pris conscience
de la nécessité d'adopter des guides pratiques à l'image
des Commissaires à la Protection des données mondiales, qui
prévoient dans le troisième pilier de leur réunion
annuelle de « traduire la Déclaration de 2018 sur
l'éthique et la protection des données en matière d'IA
dans les pratiques de travail quotidiennes des
autorités487 ». Un groupe de travail sur
l'Éthique et la protection des données personnelles dans la vie
privée a notamment été créé par ce
même organisme488.
Pour conclure, la stratégie géopolitique de
l'Europe réside dans le développement d'une IA éthique.
Toutefois, la mise en place de cette alternative ne peut voir le jour qu'avec
un investissement pécunier et humain notoire à l'échelle
européenne. De plus, cette vision éthique doit être
partagée par toutes les disciplines et les acteurs de l'IA, dans le but
commun de (re)placer au coeur de cette technologie l'individu.
485 Déclaration de Montréal pour un
développement responsable de l'intelligence artificielle, 2018
486 L. Floridi, J. Cowls, M. Beltrametti, R. Chatila, P.
Chazerand, V. Dignum, C. Luetge, R. Madelin, U. Pagallo, F.Rossi, B. Schafer,
P. Valcke, E. Vayena, 2018, 'AI4People--An ethical framework for a good AI
society: Opportunities, risks, principles, and recommendations', Minds ad
machines, vol. 28, no. 4, p. 689-707
487 41e Conférence internationale des commissaires
à la protection des données et de la vie privée Tirana, 22
octobre 2019, « Résolution sur l'orientation stratégique
de la conférence (2019-21) », P. 8
488 ICDPPC Working Group, Groupe de travail sur
l'éthique et la protection des données dans le domaine de
l'intelligence artificielle, Plan stratégique (2019-21)
- 80 -
Le régime de lege feranda
Chapitre 2 : Replacer l'utilisateur au coeur de
l'intelligence artificielle
Le marché d'internet est dominé aujourd'hui par
de grandes plateformes dont le business model réside en la
monétisation des données à caractère personnel des
individus489. Capter l'attention devient l'enjeu majeur, ce qui
encourage le développement de méthodes persuasives et addictives,
au prix d'influencer nos perceptions de la réalité, nos choix et
nos comportements dans l'objectif d'accroître le profit490. Ce
comportement est cependant contraire à l'article 1 de la Loi
informatique et libertés qui dispose que « L'informatique doit
être au service de chaque citoyen ». Il devient alors
impératif de protéger l'autodétermination des personnes
concernées, en les formant (Section 1) et en leur fournissant des outils
adaptés (Section 2).
Section 1 : Responsabiliser l'utilisateur
Le consentement des personnes concernées ne peut
être obtenu qu'en étant « libre, spécifique,
éclairé et univoque491 ». Or, le
développement des algorithmes entraine une diminution des vigilances
individuelles, qu'il convient de pallier492. Le caractère
éclairé du consentement peut être affaibli face à
deux mécanismes que sont la bulle filtrante (§1) et le design
trompeur (§2).
§1. Ne pas réduire la personne concernée
à son alter égo numérique par le mécanisme de bulle
filtrante
Un des risques de l'usage des algorithmes d'intelligence
artificielle sur internet est la pratique d'enfermement et de perte de
pluralisme culturel. Dans son ouvrage493, E. Parisier emploie le
terme de « bulle filtrante », qui signifie que
l'activité intrinsèque de filtrage et de classement
opérée par les algorithmes a pour effet de nuire au pluralisme et
de renforcer le déterminisme de l'individu. Cet effet, appelé
aussi l'« effet performatif », utilisé sur internet
est lié à la personnalisation des recherches et limite ainsi les
contenus auxquels les individus sont exposés, et réduit par voie
de conséquence la créativité et la capacité de
penser494.
L'enfermement s'opère à deux niveaux. A
l'échelle de l'individu, « les algorithmes augmenteraient la
propension des individus à ne fréquenter que des objets, des
personnes, des
489 CEPD, avis n° 3/2018 sur la manipulation en ligne et
les données à caractère personnel, mars 2018, p. 12
490 N. Miailhe, « Géopolitique de l'intelligence
artificielle : le retour des empires ? », politique
étrangère, 2018, p. 109
491 Art. 4 11) RGPD
492 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.50
493 E. Pariser, «The filter Bubble: What the Internet is
hiding from you», Penguin Press, 2011
494 Parlement européen, « Understanding
algorithmic decision-making: Opportunities and challenges», mars 2019,
p.13
- 81 -
Le régime de lege feranda
opinions, des cultures conformes à leurs propres
goûts et à rejeter l'inconnu495 ». L'individu
serait ainsi assimilé à son « alter-égo
numérique », enfermé dans sa prison de recommandations.
A l'échelle de la société, cet usage risque de nuire
à la démocratie du fait que les privations d'exposition des
individus à la différence réduiraient la qualité et
la vitalité du débat publique.
§2. Être conscient des pratiques de design
trompeur
La « théorie du nudge496
» repose sur l'idée que « l'homo
economicus497 » n'existe pas. L'homme n'est en
réalité pas totalement rationnel. Ses décisions sont
influencées par des structures mentales, appelées «
biais cognitifs » qui orientent nos perceptions et nos
comportements à partir de notre environnement physique, social et
cognitif498. Ce sont d'ailleurs ces biais cognitifs qui expliquent
le paradoxe de la vie privée.
La technique du « nudge » ou «
coup de pouce » consiste donc à agir sur l'architecture
des choix des individus pour les inciter à effectuer certaines actions
plutôt que d'autres499. Dans son sens péjoratif, le
Nudge est appelé « dark pattern ». Il existe en
effet des design abusifs, trompeurs, et dangereux500 dont l'usage
contrevient au respect de la protection de la vie privée. Il existe
quatre types de designs trompeurs : ceux qui influencent le consentement, ceux
qui déroutent la personne, ceux qui créent des frictions et ceux
qui incitent au partage des données501.
Le « dark pattern » peut nuire au
consentement de la personne concernée. Tout d'abord le «
paradoxe du choix » provoque une fausse impression de
contrôle de l'individu. De plus, le consentement est toujours
accordé dans un espace contraint, l'usage de stratégies de
détournement de l'attention invalidera alors le
consentement502. Ce comportement porte également atteinte aux
principes de transparence et de loyauté503.
Le design trompeur peut également induire en erreur la
personne concernée. L'autorité de contrôle
norvégienne a récemment démontré comment les
Darks Patterns employés par Facebook et Google empêchent les
personnes concernées d'exercer leurs droits504. Ces
procédés ont d'ailleurs fait l'objet d'une question à la
CNIL sur la conformité des pratiques de
495 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.35
496 R. Thaler, « Nudge : améliorer les
décisions concernant la santé, la richesse et le bohneur »,
2008
497 E. Benays, « propaganda », 1928
498 CNIL, LINC, « Cahier IP - La forme des choix -
Données personnelles, design et frictions désirables »,
p.15
499 Ibid., p.19
500 Ibid., p.27
501 E. Hary; «Dark patterns : quelle grille de lecture
pour les réguler ? » 2 septembre 2019
502 CNIL, « Cahier IP - La forme des choix - Données
personnelles, design et frictions désirables », p.30, 40
503 Ibid., p.30, 43
504 Forbrukerradet, «Deceived by design, How tech
companies use dark patterns to discourage us from exercising our rights to
privacy», 27 juin 2018
- 82 -
Le régime de lege feranda
Facebook et de Google par rapport aux principes de privacy
by default et des modalités de collecte du
consentement505.
Section 2 : Doter l'utilisateur d'outils
adaptés
La vie privée s'interprète pour certains
universitaires comme le droit d'exercer un certain contrôle sur les
informations relatives aux individus506. Garantir ce droit
fondamental implique alors de rétablir ce contrôle par la
conception d'une économie digitale centrée sur
l'humain507. Cela passe par une consécration du privacy
by using (§1) effective (§2).
§1. Consacrer le principe de privacy by using
Le concept de privacy by using508 vise
à responsabiliser les personnes concernées par des
mécanismes d'usages dynamiques. Le privacy by using peut se
définir comme « l'ensemble des moyens juridiques, techniques et
informationnels, ex ante ou ex post, qui permettent de réduire
l'asymétrie informationnelle et les conséquences
inintentionnelles, ouvrant ainsi la voie à des comportements
informés de privacy et, ultimement, à de nouvelles normes de
privacy partagées»509. Les utilisateurs se voient
dotés d'instruments technologiques, juridiques et informationnels afin
de mieux être informés de l'usage de leurs données. Il
s'agirait par exemple d'un tableau de bord recensant l'ensemble de
l'utilisation des données par un objet connecté.
Ce concept s'inscrit dans le mouvement du « Self Data
» qui vise à responsabiliser les personnes concernées
afin qu'elles deviennent des sujets actifs de leur
données510. Adopter une démarche conforme à un
modèle « User centrics » peut
s'incarner511 par exemple par la prise de conscience du lieu de
stockage en préférant son ordinateur à un cloud.
Sous réserve d'un meilleur contrôle, elles seraient ainsi capables
de décider de leurs usages et de quels filtres elles choisissent
d'utiliser. Ce principe favorise donc leur
émancipation512.
La responsabilisation des individus passe ainsi par le
privacy by using513. La régulation doit se penser de
manière architecturale et non composante par composante. Le privacy
by using
505 C. Gruhier, « Données personnelles Les
petits arrangements de Google et Facebook », Que Choisir, 26 juin
2018
506 G. Rostana, A. Bekhardi, B. Yannou, «From privacy by
design to design for privacy», op. cit. p.1
507 N. Krunch, Greater than Experience, « Designing A
Humanity Centric Digital Economy », 2019
508 P. Pucheral, A. Rallet, F. Rochelandet, C. Zolynski, op.
cit., p.13
509 Ibid., p. 15, p.46
510 Ibid., p. 15
511 Ibid., p.11
512 T. Livenais, « Le règlement
général sur la protection des données, outil
d'émancipation des consommateurs face aux objets connectés
», Dalloz, Revue de l'Union européenne, 2020, p.48
513 R. Alain, F. Rochelandet, C. Zolynski. « De la
Privacy by Design à la Privacy by Using. Regards croisés
droit/économie », Réseaux, vol. 189, no. 1, 2015, pp.
15-46.
- 83 -
Le régime de lege feranda
agit donc en complément du principe de privacy by
design514. Le privacy by using permet de
compléter et de pallier les paradoxes de ce dernier. Néanmoins,
le privacy by using requiert un coût cognitif
élevé et est aux antipodes du principe de privacy by
default. Il convient donc de réfléchir à une approche
globale de confidentialité pour intégrer les principes de
privacy by design, by default et by using selon les
besoins afin de conserver ces objectifs commun de protéger les
données à caractère personnel et de rendre le choix
à l'utilisateur.
§2. Promouvoir un design pour la privacy
L'usage du design est nécessaire afin de garantir les
principes de privacy by design et de privacy by
default515. Ces principes impliquent en effet la mise en oeuvre
de garanties relatives à l'information, l'exercice des droits des
personnes concernées et l'obtention de leur consentement. La CNIL a pour
cela créé un site internet dédié au design afin de
garantir des « parcours utilisateurs respectueux du RGPD et de la vie
privée ».
En ce qui concerne le droit des personnes, les individus ont
tendance à choisir la proposition par défaut516. La
mise en oeuvre d'un design respectueux du privacy by default implique
que les utilisateurs soient capables de consulter et de comprendre les
configurations et les options pour être capable de changer eux même
les paramètres par défaut517.
Concernant le droit d'information, il arrive que la surcharge
informationnelle noie les individus sous le flux d'informations, la mise en
oeuvre effective de ce droit correspond alors à un « droit de
ne pas choisir518 ». Consacrer une réelle
information des utilisateurs passe aussi par une communication honnête
des risques, ce qui peut s'avérer être une solution à
l'impossible promesse de garantir une confidentialité sans
failles519.
Le modèle user-centric permet ainsi
d'augmenter le contrôle des personnes concernées sur leurs
données520. Néanmoins, le big data rend les
mécanismes de collecte du consentement dépassés. Il
devient donc nécessaire d'adapter ces procédés à
l'intelligence artificielle, par le biais par exemple des
préférences pour la protection de la vie privée, ou
d'entrepôts de données personnelles : « Les nouvelles
technologies requièrent de nouveaux modèles de consentement et
l'industrie doit être ouverte et créative en proposant des
solutions pratiques d'opt-in complétées par des solutions
d'opt-out et de mécanismes d'accès qui placent les
utilisateurs
514 P. Pucheral, A. Rallet, F. Rochelandet, C. Zolynski, op.
cit., p.13
515 CNIL, LINC, « Cahier IP - La forme des choix -
Données personnelles, design et frictions désirables »,
p.43
516 Ibid ., p. 19
517 M. Hansen, K. Limniotis, ENISA, recommendations on GDPR
provisions, op cit., p.35
518 CNIL, « Cahier IP - La forme des choix - Données
personnelles, design et frictions désirables », p.30, 19
519 S. Watcher, «The GDPR and the Internet of Things : A
Three-Step Transparency Model», 2018, p.12
520 G. D'acquisto, J. Domingo-ferrer, ENISA, « Privacy by
design in big data», décembre 2015, p. 46
- 84 -
Le régime de lege feranda
dans une démarche de contrôle de la
chaîne de traitement des données521 ». La
CNIL recommande de réfléchir à l'interface entre la
machine et son utilisateur, pour garantir la liberté
humaine522. L'institut Montaigne encourage l'investissement dans la
recherche relative à l'aide aux utilisateurs en matière de
protection de la vie privée523.
Néanmoins, ces dispositifs restent des prémices.
Les grandes plateformes interrogées lors de l'enquête de la
Commission sur la souveraineté du numérique ont reconnu que ces
outils étaient « récents et
perfectibles524 ». Si la Commission félicite
quelques pratiques à l'instar du tableau de bord de Google recensant
l'historique de la collecte des données personnelles et de leurs
utilisations, ces initiatives doivent être davantage encouragées
et contrôlées.
Ainsi, recentrer l'utilisateur au coeur de l'IA éthique
requiert de l'éduquer à la technologie et aux pratiques de bulle
filtrante et de design trompeur. Pour cela, l'intégration du principe
de privacy by using en complément du privacy by design
et du privacy by default est impératif, ainsi que la mise
à disposition d'outils adaptés.
La réglementation en vigueur ne donnant pas de
lignes directrices, l'importance de l'autorégulation se voit accrue. Le
responsable du traitement doit donc veiller à déterminer une
politique de gouvernance de la donnée efficace et prendre des
précautions particulières tout au long du cycle de vie de la
donnée lors du traitement effectué par un logiciel d'intelligence
artificielle.
Le régime de demain, respectueux de l'usage des
données à caractère personnel doit proposer une
intelligence artificielle éthique, avec au coeur de cette
réflexion l'utilisateur. Ce dernier doit être formé et
doté d'outils permettant une prise de décision
éclairée.
521 Ibid., p. 50
522 CNIL, les enjeux éthiques des algorithmes et de
l'intelligence artificielle, op. cit., p.56
523 F. Godement «Données personnelles, comment
gagner la bataille ?» Institut Montaigne, décembre 2019, P.
184
524 F. Montaugé, G. LONGUET, Rapport Commission
d'enquête sur la souveraineté au numérique, « le
devoir de souveraineté numérique : ni résignation, ni
naïveté » version provisoire, n° 7 tome I
(2019-2020) , 1 octobre 2019, p. 76
- 85 -
Conclusion
Ainsi, le privacy by design et le privacy by
default se traduisent par une application technique et organisationnelle
des principes du RGPD. Or, les logiciels d'intelligence artificielle sont par
nature contraires à ces principes. L'objectif de ce mémoire est
de dépasser cette impossibilité conceptuelle pour proposer un
régime, sous la forme de guide pratique, proposant un équilibre
entre innovation et protection des données à caractère
personnel.
La mise en place d'un régime effectif de l'intelligence
artificielle conforme à la protection des données personnelles
doit s'effectuer en deux étapes : tout d'abord, adapter les principes
traditionnels de protection des données pour ensuite construire un
régime adapté. La mise en place de ce régime
nécessite au préalable une évolution de la
réglementation existante en adaptant les principes directeurs du
Règlement à la spécificité du logiciel d'IA. Les
outils de conformité doivent eux aussi prendre en compte les nouveaux
risques engendrés par l'IA. C'est dans ce nouveau cadre qu'un
régime de l'intelligence artificielle pourra être envisagé,
en définissant clairement les obligations des acteurs de la chaîne
algorithmique, ainsi que les points d'attentions à respecter tout au
long de la vie de la donnée. Néanmoins, l'effectivité de
ces obligations ne peut être assurée que si une dynamique
européenne encourage le développement de l'IA éthique. En
proposant un modèle alternatif aux initiatives actuelles, les standards
européens pourront être établis puis respectés, et
les choix des personnes réellement préservés.
Concernant la première partie de ce mémoire, les
points suivants ont été mis en évidence :
i. Le privacy by design et le privacy by
default peuvent constituer la balance entre innovation et protection des
données à caractère personnel.
ii. Le régime spécifique du traitement par un
logiciel d'intelligence artificielle amène
à créer de
nouveaux standards éthiques, sans toutefois tomber dans les travers de
la norme éthique.
iii. Le traitement par un logiciel d'intelligence
artificielle nécessite de prendre en
compte de nouveaux risques
liés à cette technologie. Le risque doit se concevoir en amont et
en aval du traitement. Dans cette perspective, le privacy by design
s'incarne comme principe de prévention, et le privacy by
default comme principe de protection.
- 86 -
CONCLUSION
iv. Les mesures techniques et organisationnelles
nécessitent de prendre en compte l'état de l'art et des outils
adaptés à l'intelligence artificielle.
La deuxième partie de ce mémoire a mis en exergue
les éléments ci-après :
v. Le régime de gouvernance des données est
aujourd'hui incomplet, du fait de son imprécision en matière de
responsabilité des acteurs de la chaîne algorithmique. L'absence
de standards spécifiques au traitement de l'IA favorise une
autorégulation dont la conformité est difficile à
mesurer.
vi. A défaut de standards en la matière, on
peut tout de même envisager un régime respectueux du RGPD en
prenant en compte la protection des données tout au long du cycle de vie
de la donnée lors du traitement par un logiciel d'intelligence
artificielle.
vii. La mise en place de ce régime requiert une
gouvernance de l'intelligence artificielle
éthique. L'Europe doit
acquérir une souveraineté du numérique pour proposer une
alternative éthique de l'intelligence artificielle, fruit d'une
réflexion pluridisciplinaire.
viii. Les nouveaux usages de l'intelligence artificielle
constituent un risque au choix
éclairé de la personne
concernée. Replacer l'utilisateur au coeur de l'IA est essentiel. Le
passage vers un modèle centré sur l'humain nécessite de
responsabiliser les utilisateurs et de les doter d'outils propices à
leur émancipation. Ainsi, le principe de privacy by using
s'incarne en parallèle des principes de privacy by design et de
privacy by default.
Si la mise en oeuvre des principes de privacy by default
et de privacy by design dans le cadre d'un traitement d'intelligence
artificielle se heurte à un cadre législatif incomplet, un
régime en conformité avec le RGPD est toutefois envisageable.
Privilégier des recommandations à une
régulation propre à l'intelligence artificielle. Le
cadre législatif du RGPD se voit incomplet face au traitement d'un
logiciel d'intelligence artificielle. Le Règlement vise à
englober tout type de traitement en étant technologiquement neutre.
C'est pour cela qu'il propose un cadre normatif de principe, couplé
à une boîte à outil composée d'analyse d'impact, de
code de conduite et de standards de vie privée. Les bonnes
- 87 -
CONCLUSION
pratiques des responsables du traitement ne sont plus des
initiatives encouragées mais de réels standards de
conformité, conformément aux principes de privacy by design
et de privacy by default525.
La mesure de ces indicateurs ne peut donc pas être
incluse dans le Règlement pour ne pas discriminer des technologies ou
devenir obsolète. Cependant, le RGPD, malgré son caractère
technologiquement neutre, impose des obligations techniques. C'est pour cela
que la Commission européenne a publié en 2015 une demande de
standardisation526 auprès de l'Organisation de
standardisation européenne relative à l'implémentation
du privacy by design et du privacy by default. Cette demande
a été acceptée et fait l'objet d'un travail encore en
cours par le Groupe de travail conjoint n°8. Il s'agit du premier effort
de co-régulation en termes de protection des données, mais qui
n'est encore qu'à un stade embryonnaire527.
La nécessité de pouvoir concevoir des
logiciels d'intelligence artificielle. On oublie trop souvent
qu'internet n'a rien de gratuit. Les géants du numérique,
c'est-à-dire les GAFA528 et les BHATX529,
présentent tous un élément commun : leur modèle
économique repose davantage sur le client que sur le
produit530. Leur business model repose donc sur l'attention
de l'utilisateur ; et la collecte de ses données devient la principale
source de revenus. Face à la domination sino-américaine, l'Europe
est aujourd'hui spectatrice et risque de devenir une « colonie du
numérique ».
La nécessité de proposer une alternative
éthique s'avère nécessaire pour permettre une protection
des données à caractère personnel efficace, et
responsabiliser les individus.
Cet impératif est un enjeu essentiel de
société puisque « les outils nous façonnent
autant que nous les façonnons531 ». Cette nouvelle
économie bouleverse à nouveau notre rapport à la
donnée, puisque la mesure n'est plus un moyen mais une
fin532, au risque de réduire l'humain
525 I., Kamara, "Co-regulation in EU personal data protection:
the case of technical standards and the privacy by design standardisation
'mandate'", in European Journal of Law and Technology, Vol 8, No 1, 2017
526 Commission Européenne, commission implementing
decision, n° M/530, 20 janvier 2015
527 I., Kamara, "Co-regulation in EU personal data protection:
the case of technical standards and the privacy by design standardisation
'mandate'", in European Journal of Law and Technology, Vol 8, No 1, 2017
528 Google, Apple, Facebook, Amazon
529 Baidu, Huawei, Alibaba, Tencent, Xiaomi
530 N. Miailhe, « Géopolitique de l'intelligence
artificielle : le retour des empires ? », politique
étrangère, 2018, p. 108
531 CNIL, LINC, « Cahier IP - La forme des choix -
Données personnelles, design et frictions désirables »,
p.6
532 Ibid., p.13
- 88 -
CONCLUSION
à des nombres533. La technologie
étend le champ des possibles en agrandissant notre «
liberté de fait » 534, mais nous rend-elle plus
libre pour autant ? Les nouvelles technologies peuvent entraver notre
libre-arbitre en influençant notre liberté cognitive. Il est donc
essentiel de réfléchir au curseur éthique, qui pose la
frontière de la « liberté de droit ».
Cette réflexion est d'autant plus d'actualité
face à la situation exceptionnelle à laquelle nous faisons face
du fait de la pandémie du STRAS-Covid-2, où les applications
de tracing peuvent s'avérer très intrusives dans la vie
privée dans individus535. « Aux grands maux, les
grands moyens », comme dit le proverbe. Mais dans quelle mesure ? Le
développement des nouvelles technologies offre de nombreuses
opportunités, favorables à notre société, tant que
nous continuons à nous rappeler que la « science sans
conscience n'est que ruine de l'âme536 ».
533 Parlement européen, « Understanding
algorithmic decision-making: Opportunities and challenges», mars 2019,
p. 13
534 Éric Fourneret, « Le numérique appelle
la pensée », LINC, CNIL, 3 avril 2020
535 A. Courmont, « Coronoptiques (1/4) : dispositifs
de surveillance et gestion de l'épidémie », LINC, CNIL,
10 avril 2020
536 F. Rabelais, « Pentagruel », p. 131
Annexes
i. Schéma - la protection des données
dès la conception
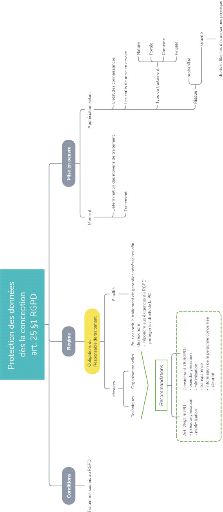
ii. Schéma - la protection des données par
défaut

iii. Typologie des logiciels d'apprentissage automatique selon
le Conseil de l'Europe537
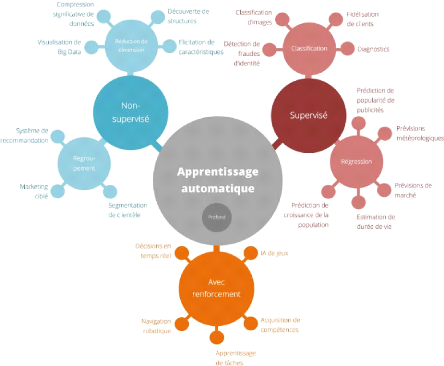
537 Source :
https://www.coe.int/fr/web/artificial-intelligence/glossary
iv. Guide de la CNIL pour effectuer une AIPD
v. Privacy by design et by privacy by
default d'après l'avis du CEPD dans le cadre d'un traitement d'IA
|
Principes à respecter / étapes
de
traitement
|
Définition du
traitement
|
Rédaction de
l'algorithme
|
Design du
logiciel
|
Collecte
|
Traitement
|
Résultat
|
|
Licéité
|
|
Pertinence
|
x
|
|
|
|
|
|
|
Différenciation
|
x
|
|
|
|
x
|
|
|
Finalité déterminée
|
x
|
|
|
|
|
|
|
Nécessaire
|
x
|
|
|
|
|
|
|
Autonomie
|
|
x
|
x
|
x
|
x
|
x
|
|
Retrait du consentement
|
|
x
|
x
|
x
|
x
|
x
|
|
Mise en balance des intérêts
|
x
|
|
|
|
|
|
|
Prédétermination
|
x
|
|
|
|
|
|
|
Cessation
|
|
|
|
|
x
|
x
|
|
Ajustement
|
x
|
x
|
|
|
x
|
x
|
|
Configurations par défaut
|
|
x
|
|
|
|
|
|
Répartition des responsabilités
|
x
|
|
|
|
|
|
|
Loyauté
|
|
Autonomie
|
x
|
x
|
x
|
x
|
x
|
x
|
|
Interaction
|
x
|
x
|
x
|
x
|
x
|
x
|
|
Attente
|
x
|
x
|
x
|
|
x
|
|
|
Non-discrimination
|
x
|
x
|
x
|
|
x
|
x
|
|
Non-exploitation
|
x
|
x
|
x
|
|
x
|
x
|
|
Choix des consommateurs
|
x
|
x
|
x
|
|
x
|
x
|
|
Équilibre des pouvoirs
|
x
|
x
|
x
|
|
|
|
|
Respect des droits et libertés
|
x
|
x
|
x
|
|
x
|
x
|
|
Respect de l'éthique
|
x
|
|
|
|
x
|
x
|
|
Vérité
|
x
|
|
|
|
x
|
x
|
|
Intervention humaine
|
x
|
x
|
x
|
|
x
|
|
|
Algorithmes équitables
|
x
|
x
|
x
|
|
x
|
|
|
Transparence
|
|
Clarté
|
x
|
x
|
x
|
|
|
|
|
Sémantique
|
x
|
x
|
x
|
|
|
|
|
Accessibilité
|
x
|
x
|
x
|
|
|
|
|
Contexte
|
x
|
|
|
|
|
|
|
Pertinence
|
x
|
|
|
|
|
|
|
Conception universelle
|
x
|
|
|
|
|
|
|
Compréhensibilité
|
x
|
|
|
|
|
|
|
Multicanal
|
x
|
x
|
x
|
|
|
|
|
Finalité
|
|
Prédétermination
|
x
|
|
|
|
|
|
|
Spécificité
|
x
|
|
|
|
|
|
|
Orientation des finalité
|
x
|
|
|
|
|
|
|
Nécessité
|
x
|
|
|
x
|
|
|
|
Compatibilité
|
|
|
|
|
x
|
|
|
Limiter le traitement ultérieur
|
|
|
|
|
x
|
x
|
|
Contrôle
|
|
x
|
x
|
x
|
x
|
|
|
Limites techniques de la réutilisation
|
|
|
|
|
|
x
|
|
Minimisation
|
|
Minimiser les données
|
x
|
|
|
|
|
|
|
Pertinence
|
x
|
|
|
|
|
|
|
Nécessité
|
x
|
|
|
|
|
|
|
Limitation
|
x
|
|
|
|
x
|
|
|
Agrégation
|
x
|
|
|
x
|
|
|
|
Pseudonymisation
|
x
|
|
|
|
x
|
x
|
|
Anonymisation et suppression
|
x
|
|
|
|
x
|
x
|
|
Flux de données
|
x
|
x
|
x
|
x
|
x
|
x
|
|
État de la technique
|
x
|
|
|
|
|
|
|
Exactitude
|
|
Source de données
|
x
|
|
|
x
|
|
|
|
Degré d'exactitude
|
x
|
|
|
x
|
|
|
|
Exactitude mesurable
|
x
|
|
|
x
|
|
|
|
Vérification
|
x
|
|
|
x
|
|
|
|
Effacement / rectification
|
x
|
x
|
x
|
x
|
|
|
|
Erreurs cumulées
|
x
|
x
|
x
|
x
|
|
|
|
Accès
|
x
|
x
|
x
|
x
|
x
|
|
|
Exactitude continue
|
x
|
x
|
x
|
x
|
x
|
x
|
|
Mise à jour
|
x
|
x
|
x
|
x
|
x
|
|
|
Conception des données
|
x
|
x
|
x
|
|
|
|
|
Limitation de la conservation
|
|
Suppression
|
x
|
x
|
x
|
|
x
|
|
|
Automatisation
|
x
|
x
|
x
|
|
x
|
|
|
Critères de stockage
|
x
|
|
|
|
|
|
|
Application des politiques de conservation
|
x
|
|
|
|
x
|
|
|
Efficacité de l'anonymisation / suppression
|
x
|
|
|
|
x
|
x
|
|
Divulguer la justification
|
x
|
|
|
|
|
|
|
Flux de données
|
x
|
|
|
x
|
x
|
x
|
|
Sauvegardes/ logs
|
x
|
|
|
|
|
|
|
Intégrité et
confidentialité
|
|
Systèmes de gestion de la sécurité de
l'information
|
x
|
x
|
x
|
|
x
|
|
|
Analyse de risques
|
x
|
|
|
|
|
|
|
Résilience
|
x
|
x
|
x
|
|
x
|
|
|
Gestion des accès
|
x
|
x
|
x
|
|
x
|
|
|
Transferts sécurisés
|
x
|
x
|
x
|
|
x
|
|
|
Stockage sécurisé
|
x
|
x
|
x
|
|
x
|
|
|
Sauvegardes/logs
|
x
|
x
|
x
|
|
x
|
|
|
Protection spéciale
|
x
|
x
|
x
|
|
x
|
|
|
Pseudonymisation
|
x
|
x
|
x
|
x
|
x
|
|
|
Gestion des réponses aux incidents de
sécurité
|
x
|
x
|
x
|
|
x
|
|
|
Traitement des violations de données à
caractère personnel
|
x
|
|
|
|
x
|
|
|
Maintenance et développement
|
x
|
|
x
|
|
x
|
|
|
Responsabilité
|
vi. Synthèse des principes éthiques pour
l'intelligence artificielle

Bibliographie
Ouvrages généraux
Aristote, Éthique à Nicomaque,
lgf, 2001
Castet-Renard (C.), Brogli (M.), Younes (V.), Beaugrand
(T.), Protection des données personnelles,
éditions legislatives, 2e édition, mai 2019
Costes (L.), Lamy droit du numérique,
avril 2020
Perray (R.), Fasc. 930 : données
à caractère personnel - Introduction générale et
champ d'application de la règlementation relative à la protection
des données personnelles, Lexis Nexis, 8 avril 2019
Simon (D.), répertoire de droit
européen, dalloz, mai 2020 Rabelais (F.),
Pentagruel, points, 1996
Ouvrages spéciaux
Abiteboul, (S.), « Sciences des
données. De la logique du premier ordre à la Toile »,
leçon inaugurale à la chaire Informatique et sciences
numériques, Collège de France, 8 mars 2012
Basdevant (A.), Mignard (J.P.), L'empire des
données, Essai sur la société, les algorithmes et la
loi, Don Quichotte, 2018
Supiot (A.), La gouvernance par les
nombres, cours au Collège de France, 2012-2014, Fayard, 2015
Revue Lamy Droit de l'Immatériel, N°
159, 1er mai 2019
Articles de doctrine
· Articles juridiques
Ancel (B.), « La vie privée dans un
monde digitalement connecté : la démocratie en danger ? »,
Revue Lamy Droit de l'Immatériel, N° 159, 2019
Boullet (A.), Quoy (N.), « L'encadrement
contractuel de l'intelligence artificielle », Lexis Nexis,
Communication Commerce éléctronique n°2, Février
2020
Cao (F.X.), « Intelligence artificielle et
valorisation de la donnée », Lexis Nexis, à
paraitre
Castets-Renard (C.), « L'intelligence
artificielle, les droits fondamentaux et la protection des données
personnelles dans l'Union européenne et les États-Unisé
», Revue de Droit International d'Assas, RDIA n° 2019
Castests-Renard (C.), « Comment
construire une intelligence artificielle responsable et inclusive ? »
Recueil Dalloz, 2020
Castets-Renard (C.), Besse (J.P.) et Garivier (A.),
« Loyauté des décisions algorithmiques »,
HAL-01544701. Rapp. pour l'étude de la CNIL : Comment permettre à
l'homme de garder la main : les enjeux éthiques des algorithmes et de
l'intelligence artificielle, 2017
Costes (L.), « Introduction »,
Revue Lamy Droit de l'Immatériel, N° 150, 1er juillet 2018
Godefroy (L.), « Le code au service du droit »
Recueil Dalloz, 2018
Hass (G.), Dubarry (A.), « clause de
confidentialité, savoir-faire et secret des affaires », Dalloz
IP / IT, p. 322
Hert (P.D.), Gutwirth (S.), « Privacy,
Data Protection and Law Enforcement. Opacity of the Individual and Transparency
of power», privacy and the criminal law (pp. 61-104),
Intersentia, 2006
Griguer (M), Shwartz (J), «Privacy by
Design - Privacy by Design/Privacy by Default Une obligation de
conformité et un avantage concurrentiel», Lexis Nexis, Cahiers de
droit de l'entreprise n° 3, , prat. 15, Mai 2017
Jomni (A.), « RGPD : un atout ou un
frein pour la sécurité ? », Dalloz IP/IT, Juin
2019
Kamara (I.), "Co-regulation in EU personal
data protection: the case of technical standards and the privacy by design
standardisation 'mandate'", European Journal of Law and Technology,
Vol 8, No 1, 2017
Loiseau (G.), « De la protection
intégrée de la vie privée (privacy by design) à
l'intégration d'une culture de la vie privée »,
Légipresse, 2012
Loiseau (G.), Bensamoun (A.), «
L'intégration de l'intelligence artificielle dans certains droits
spéciaux », Dalloz IP/IT, 2017
Lenoir (N), « Informatique et
libertés publiques - Protection des données personnelles et
responsabilités plurielles », Lexis Nexis, La Semaine Juridique
Edition Générale n° 41, La Semaine Juridique Edition
Générale n° 41, 8 Octobre 2018, doctr. 1059, 8 Octobre
2018
Livenais (T.), « Le règlement
général sur la protection des données, outil
d'émancipation des consommateurs face aux objets connectés
», Dalloz, Revue de l'Union européenne, 2020, p.48
Marignol (L.), « Principe de
responsabilité et action en responsabilité dans le
Règlement général sur la protection des données
», Lamy droit de l'immatériel, n°166, janvier 2020
Mattatia (F.), « La mise en oeuvre du
RGPD au prisme du risque juridique », Revue Lamy Droit de
l'Immatériel, N° 140, 1er août 2017
Morisse (T.), « intelligence
artificielle, un nouvel horizon : pourquoi la France a besoin d'une culture
numérique ? », Les Cahier Lysias, 2017
Perray (R.), Uzan-Naulin (J.) «
Existe-t-il encore des données non personnelles ? Observations sous
Conseil d'État, 8 février 2017, n° 393714,
Société JCDecaux », Dalloz IP/IT, 2017
Rostana (G.), Bekhardi (A.), Yannou (B.),
«From privacy by design to design for privacy», ICED,
Canada, hal-01673578, 2017
Rahmouni (D.), Banck (A.), « Le RGPD,
nouvel outil de soft law de l'Europe dans le numérique », Revue
Lamy droit de l'immatériel n°151, 2018
Waldman (A.E.), «Privacy's Law of
Design», UC Irvine Law Review, 8 octobre 2018
Watcher (S.), «The GDPR and the
Internet of Things: A Three-Step Transparency Model», Journal Law
Innovation and Technology, Volume 10, 2018
Zolynski (C.), Pucheral (P.), Rallet, (A),
Rochelandet (F.), « La Privacy by design : une fausse bonne
solution aux problèmes de protection des données personnelles
soulevés par l'open data et les objets connectés ? »,
Legicom, Victoires open data : une révolution en marche,
pp.89-99, 10.3917/legi.056.0089, hal-0142798, 2016
Zolynski (C.), Maxwell (W.), «Protection
des données personnelles», recueil Dalloz, 2019
Zolynski (C.), Alain (R.), Rochelandet (F.),
« De la Privacy by Design à la Privacy by
Using. Regards croisés droit/économie »,
Réseaux, vol. 189, no. 1, 2015
· Articles non juridiques
Barlow (H. B.), «Unsupervised learning.
Neural computation», 1(3):295-311, 1989 Bishop (C. M.),
«Pattern recognition and machine learning»,
Springer, 2006
Brown (B.), «Studying the Internet
Experience», Publishing Systems and Solutions Laboratory HP
Laboratories Bristol, HPL-2001-49, 26 mars 2001
Dwork (C.), «Differential Privacy».
In: Bugliesi M., Preneel B., Sassone V., Wegener I. (eds) Automata,
Languages and Programming. ICALP 2006. Lecture Notes in Computer Science, vol
4052. Springer, Berlin, Heidelberg, 2006
Fjeld (J.), Achten (N.), Hilligoss (H.), Nagy (A.),
and Srikumar (M.), «Principled Artificial Intelligence: Mapping
Consensus in Ethical and Rights-Based Approaches to Principles for AI»,
Berkman Klein Center Research Publication No. 2020-1, 15 janvier
2020
Keller (A.), «Enhanced active choice: A
new method to motivate behavior change», Journal of Consumer
Psychology 21, p.376-383, 2011
Motiwalla (L.F.), Li (X.B.), « Unveiling
consumer's privacy paradox behaviour in an economic exchange » PMCID:
PMC5046831, NIHMSID: NIHMS746547, PMID: 27708687, 3 octobre 2016
Mouratidis (M.), Piras (L.), «DEFeND
Architecture: a Privacy by Design Platform for GDPR Compliance» Aout
2019
Narayanan (A.), Shmatikov (V.), Robust
De-anonymization of Large Sparse Datasets, IEEE Symposium on Security and
Privacy, 2008
Nissenbaum (H.), «Accountability in a
Computerized Society, Science and Engineering Ethics 2», 25-42, 1996 ; J.
A. Kroll, J. Huey, S. Barocas, E. W. Felten, J. R. Reidenberg, D. G. Robinson
et H. Yu, Accountable Algorithms, University of Pennsylvania Law Review, vol.
165, 2017
Pariser (E.), «The filter Bubble : What the
Internet is hiding from you», Penguin Press, 2011
Sutton (R.S.), Barto (A. G.),
«Reinforcement Learning: An Introduction (Adaptive Computation
and Machine Learning», A Bradford Book, ISBN 0262193981, 1998
Sweeney (L.), «k-anonymity: a model for
protecting privacy», International Journal on Uncertainty, Fuzziness and
Knowledge-based Systems, 10 (5), 2002; P. 557-570
Turing, (A.M.), `Computing machinery and
intelligence», Mind, n°59, p. 433-460, 1950
Thaler (R.), « Nudge : améliorer
les décisions concernant la santé, la richesse et le bohneur
», New haven, Yale University Press, 2008
Wagner (B.), Delacroix (S.),»
Constructing a Mutually Supportive Interface between Ethics and
Regulation,», 14 juin 2019
Wilkinson (M.), Dumontier (M.), Aalbersberg (I.),
« The FAIR Guiding Principles for scientific data management and
stewardship». Sci Data 3, 160018, 2018
Zimmer (M.), «Apprentissage par
renforcement développemental », intelligence artificielle,
thèse, [cs.AI]. Université de Lorraine, NNT :
2018LORR0008, 2018
Décisions de justice
CEDH, Arrêt Satakunnan Markkinapörssi oy et
Satamedia oy c. Finlande, Requête no 931/13,
27 juin 2017
CEDH, Arrêt case of big brother watch and others V. The
United Kingdom, no 58170/13,
62322/14 and 24960/15,13 septembre 2018
Commission Européenne, commission implementing
decision, n° M/530, 20 janvier 2015
CJUE, aff. C-673/17, Planet49 GmbH c/ Bundesverband), 21 mars
2019
CJUE, Arrêt Tele2 Sverige, C-203/15, EU:C:2016:970, 21
décembre 2016
CJUE, Affaire Google Spain, C-131/12, 13 mai 2014
CJUE, Digital Rights Ireland, nos C-293/12, C-594/12, 8 avril
2014
CNIL, Délib. n° 2019-118, 12 septembre 2019
CNIL, Délib., n° 2019-093, 4 juill. 2019
CNIL, Délib. formation restreinte, n°
SAN-2019-001, 21 janv. 2019
CNIL, Délib. n°2018-343, 8 novembre 2018
CNIL, Délib. n° 2018-327, 11 octobre 2018
CNIL, Délib. n° 2017-012, janvier 2017
CNIL, Délib. n°2015-255,16 juillet 2015
Conseil d'Etat, décision n° 427916, 12 juin
2019
Conseil d'État, décision n° 393174, RJDA
5/17 n° 386, 8 février 2017
Webographie538
Amat (F.), « Géopolitique de
l'intelligence artificielle : une course mondiale à l'innovation »,
Diploweb : la revue géopolitique, 28 mars 2018
AI for Humanity, « Lettre d'information
», numéro 2, décembre 2019
ANSSI, «Recommandations pour un usage
sécuriséì d'(Open)SSH», 17 août 2015
538 Cliquez sur le titre pour accéder au
contenu
Basdevant (A.), «the rise of the blackbox
society», Coup Data
Basdevant (A.), « Promoting data culture in
Europe with interdisciplinary research institutes », Coup Data, 8
octobre 2019
Baudot (F.), « Un service de localisation
décentralisé et privacy by design entre appareils »,
LINC, 24 octobre 2019
Béranger, (V.), « Le terme IA est
tellement sexy qu'il fait prendre des calculs pour de l'intelligence »,
Le monde, 7 février 2020
Benhamou (B.), «Concurrence et
numérique : entretien avec Bernard Benhamou», Annales des
Mines, enjeux numériques, N°8, décembre 2019
Bilton (N), «Price of Facebook Privacy?
Start Clicking», The New York Times, 12 mai 2010 Bloch
(L.), « Internet : que faire pour défendre nos chances ?
» Diploweb, 20 mai 2015 Blaede (C.J.), «How
Will AI Nudging Affect Our Privacy?», Médium, 2019
Boujo (D.), « Génération
Deeptech », BPIfrance, janvier 2019,
Burning Glass Technologies, , «The quant
crunch how the demand for data science skills is disrupting the job
market», BHEF, IBM, 2017
Burkhardt (K.), «The privacy paradox is a
privacy dilemma», Internet citizen, 24 août 2018
Buttarelli (G.) , «Artificial Intelligence
and the future Digital Single Market «, EDPS, Keynote speech on
privacy, 24 avril 2018
Cabinet IDC, « La gouvernance des
données, un enjeu majeur à l'ère de la transformation
numérique », novembre 2019.
Caprioli (E.), «intelligence artificielle
et RGPD peuvent-ils cohabiter ?», L'usine Digitale, 30 janvier
2020
Cavoukian (A.) , Borking (J.),
«Privacy-Enhancing Technologies: The Path to Anonymity», 1995
Cavoukian (A.), « Privacy by Design, the 7
foundational principles», 2009
Cavoukian (A.), stewart (D.), Dewitt (B.),
« Gagner sur tous les tableaux Protéger la vie privée
à l'ère de l'analytique » Deloitte Canada, 2014
CCNE, « Création du comité
pilote d'éthique du numérique » 2 décembre 2019
CERT Secure Coding, «The SEI CERT C++ Coding
Standard», 2016
Chafiol, (F.), « Débat Club des
juristes : Droit et IA : Quels impacts ? », octobre 2017 Conseil
de l'Europe, « Glossaire de l'intelligence artificielle »
Costes (L.), CNIL. Rapport annuel 2017 de la
CNIL et principaux enjeux pour 2018, 11 avril 2018
CNIL, « Outil PIA :
téléchargez et installez le logiciel de la CNIL », 8 avril
2020
CNIL « La CNIL lance une consultation
publique sur son projet de certification « Formation à la
protection des données », 5 mars 2020
CNIL, « Comment faire approuver un code de
conduite ? », 7 février 2020
CNIL, « Prendre en compte les bases
légales dans l'implémentation technique », 27 janvier
2020
CNIL, «faire un choix éclairé
de son architecture», 27 janvier 2020
CNIL, «Minimiser les données
collectées», 27 janvier 2020
CNIL, «Gérer les utilisateurs»,
27 janvier 2020
CNIL, «Préparer son
développement», 27 janvier 2020
CNIL « Veiller à la qualité
de votre code et sa documentation», 27 janvier 2020
CNIL, «Sécuriser vos sites web vos
applications et vos serveurs », 27 janvier 2020
CNIL, « Sécuriser son environnement
de développement », 27 janvier 2020
CNIL « Veiller à la qualité
de votre code et sa documentation», 27 janvier 2020
CNIL, « Sécuriser son environnement
de développement », 27 janvier 2020
CNIL, « Maitriser vos bibliothèques
et vos SDK », 27 janvier 2020
CNIL, « Tester vos applications », 27
janvier 2020
CNIL, « Minimiser les données
collectées », 27 janvier 2020
CNIL, « Informer les personnes », 27
janvier 2020
CNIL, « Gérer la durée de
conservation des données », 27 janvier 2020
CNIL, « Certification des
compétences du DPO : la CNIL délivre son premier agrément
», 12 juillet 2019
CNIL, « La certification », 19
décembre 2018
CNIL « Transition vers le RGPD : des labels
à la certification », 28 février 2018
CNIL, « Analyse d'impact à la
protection des données : les bases de connaissances »,
février 2018
CNIL, « Analyse d'impact relative à
la protection des données, la méthode », février
2018
CNIL, « Analyse d'impact relative
à la protection des données, application aux objets
connectés », février 2018
CNIL, « la sécurité des
données personnelles », les guides de la CNIL, 2018
CNIL, « soumettre une analyse d'impact
relative à la protection des données (AIPD) à la CNIL
», 22 octobre 2019
Dardayrol (J.P.), Mantienne (D.), «
Concurrence et numérique : entretien avec Bernard Benhamou :
Secrétaire général de l'Institut de la Souveraineté
Numérique », Enjeux numériques N°8, Annales des
Mines, décembre 2019
Data Protection and Privacy Commissioners,
«Resolution on Privacy by Design», 2010
Déclaration de Montréal pour un
développement responsable de l'intelligence artificielle,
2018
DEFeND the data governance framework for
supporting GDPR
Diaz (J.), «Petite histoire de
l'intelligence artificielle, Partie 1 », Actu IA, 12 avril
2017
Duchesne-Jeanneney (C.), Lallement (G.), Serris (J.),
« Accès aux données, consentement, l'impact du
projet de règlement e-privacy », CGE, 2018
European Data Protection Board, «
Register for Codes of Conduct, amendments and extensions »,
consulté le 01/05/2020
European Data Protection Supervisor,
«Press Statement - Data Protection and Competitiveness in the Digital
Age», 10 juillet 2019
European Data Protection Supervisor,
«Speech on «All we need is L....Privacy by design and by
default», 29 mars 2017
Fournier (E.), «Éric Fourneret :
« Le numérique appelle la pensée », LINC, 3
avril 2020 GitHub, « Awesome Guidelines », 4 janvier
2020 dernière modification
Courmont (A.), « Coronoptiques (1/4) :
dispositifs de surveillance et gestion de l'épidémie »,
LINC, CNIL, 10 avril 2020
Hary (E.), «Dark patterns : quelle
grille de lecture pour les réguler ? » 2 septembre 2019
Hurwitz (J.), Kirsh (D.), «Machine Learning For
Dummies», IBM Limited Edition, 2018,
Hes (R.), Borking (J.), Information and
Privacy Commissioner/Ontario of Canada , «Privacy-Enhancing Technologies:
The Path to Anonymity» 1995
Jean (A.), « Interview : The history and
future of algorithms», France 24 English, 18 février
2020
Krunch (N.), Greater than Experience, «
Designing A Humanity Centric Digital Economy », 2019
Kinch (N.), « How to design a Data
Ethics Framework », Médium, 9 décembre 2019
Information Commissioner's Office, «Data protection by
design and default», 2019 Information Commissioner's
Office, «Guide to data protection», mai 2018
Leclercq (B.), « Vie numérique :
Place à l'éthique », libération, 17 novembre
2019
Loye (D.), « Les deep techs
d'aujourd'hui sont les prochains Gafa », Les échos
entrepreneurs, 12 mars 2020
Meneceur (Y.), « Pourquoi nous devrions
(ne pas) craindre l'IA », LinkedIn, 23 février 2020
Millar (J.), Barron (B.), ... ,
«Accountability in ai, Promoting Greater Social Trust», 6
décembre 2018
Ministère de l'enseignement
supérieur, « Lancement de 4 Instituts Interdisciplinaires
d'intelligence artificielle (3IA) et ouverture de deux appels à projets
complémentaires », 24 avril 2019
Niler (E.), «Can AI Be a Fair Judge in
Court? Estonia Thinks So», Wired, 2019
OCDE, «Enhancing Access to and Sharing
of Data : Reconciling Risks and Benefits for Data Re-use across
Societies», 6 novembre 2019
OASIS, « standards », 2012
IPEN, «Wiki for Privacy Standards and
Privacy Projects»
Poilvé, (B.), « Les
enchères en temps réel (RTB), un système complexe »,
LINC, CNIL, 14 janvier 2020
Padilla (O.), «Cheat sheets for
AI», LinkedIn, février 2020
Practical law, «Expert Q&A: European
Data Protection Supervisor on Digital Ethics», 2019, Rees (M.),
« Le RGPD expliqué ligne par ligne (articles 24 à
50) »,
nextinpact.com
Rees (M.), « Le RGPD expliqué
ligne par ligne Certification (article 42)», Nextinpact, 2018
Schwab (K.), «La Quatrième
révolution industrielle : ce qu'elle implique et comment y faire
face», World Economic Forum, 2017
Smith (B.), «The need for a Digital
Geneva Convention», Microsoft, 14 février 2017 The
Cybersecurity hub, « types of cryptography»,
Linkedin, février 2020
The Economist, «Regulating the internet
giants. The world's most valuable resource is no longer oil, but data»,
2017
Toscano (J.), «Privacy By Design: What
Needs to be Done, How to do It, and How to Sell It to your Boss»,
Medium, 30 octobre 2018
Conférences
Big data Paris, « Guide du big data »,
2019
Conférence parlementaire, «
cybersécurité, protection desonnées, intélligence
artificielle : quels enjeux pour l'Europe ? » Organisée par le
Sénat français, le Bundesrat allemand et le Sénat
polonais, 20 juin 2019
Future of Privacy Forum, «unfairness by
algorithm: distilling the harms of automated decision-making», 2017
Malgieri (G.), « Accountable AI: myth
andrealities », Legal Edhec, Webinar, 13 mai 2020
Nguyen (B.), « Survey sur les techniques
d'anonymisation : Théorie et Pratique », Journée CERNA sur
l'Anonymisation
Sayaf (R.), «Algebraic Approach to Data
Protection by Design for Data Subjects», IPEN Workshop Conférence
«State of the art' in data protection by design», 12 juin 2019,
Zyskind (G.), Nathan (O.), Pentland (A.S.),
"Decentralizing Privacy: Using Blockchain to Protect Personal Data," 2015
IEEE Security and Privacy Workshops, San Jose, CA, 2015
Autres : rapports, avis, résolutions, lignes directrices,
...
Agence nationale de la sécurité des
systèmes d'information (ANSSI), « Mécanismes
cryptographiques», 26 janvier 2010
Agence nationale de la sécurité des
systèmes d'information (ANSSI), « Gestion des clés
cryptographiques», 24 octobre 2008
Agence nationale de la sécurité des
systèmes d'information (ANSSI), « authentification
»,13 janvier 2010
AMF, Arafer, Arcep, Arjel, CNIL, CRE, CSA, ADLC,
« Nouvelles modalités de régulation : la régulation
par la donnée », 8 juillet 2019
Cavoukian (A.), «Operationalizing Privacy
by Design: A Guide to Implementing Strong Privacy Practices », 2012
Cavoukian (A.), Stewart (D.), Dewitt (B.),
« Gagner sur tous les tableaux Protéger la vie
privée à l'ère de l'analytique » Deloitte Canada,
2014
Commission Européenne, «Lignes
directrices pour une IA digne de confiance », 8 avril 2019
Commission Européenne, « Livre
blanc sur l'intelligence artificielle - une approche européenne de
l'excellence et de la confiance », 19 février 2020
Commission Européenne, « Une
stratégie européenne pour la donnée », COM(2020) 66
final, 19 février 2020
Commission Européenne, «
Robustness and Explainability of Artificial Intelligence », JRC technical
report, 2020
Commission Européenne, «Turning
fair into reality», final report and action plan from the European
Commission Expert Group on FAIR data, 2018
Commission Nationale Informatique et
Libertés, sondage réalisé sur un
échantillon de 1001 personnes par l'IFOP, « Comment permettre
à l'homme de garder la main ? Les enjeux éthiques des algorithmes
et de l'intelligence artificielle », 2017
Commission Nationale Informatique et
Libertés, rapport,« Comment permettre à l'Homme de
garder la main ? Les enjeux éthiques des algorithmes et de
l'intelligence artificielle », 2017
Commission Nationale Informatique et
Libertés, LINC, « Cahier IP - La forme des choix -
Données personnelles, design et frictions désirables »
Commission Nationale Informatique et Libertés,
CADA, « Guide pratique de la publication en ligne et de la
réutilisation des données publiques (« open data »)
Commission de réflexion et de propositions sur
le droit et les libertés à l'âge numérique,
« numérique et libertés, un nouvel âge
démocratique », rapport n°3119, 9 octobre 2015
Conseil de l'Europe, Etat des signatures et
ratifications du traité 223, 19 mars 2020
Conseil de l'Europe, « Décoder
l'intelligence artificielle : 10 mesures pour protéger les droits de
l'homme », objectif n° 4, mai 2019
Conseil de l'Union Européenne, «
Governance of the Artificial Intelligence Strategy for Europe», juillet
2018
CNIL, «Analyse d'impact à la
protection des données, les bases de connaissances »
Conseil de l'Europe, « Protection des données
personnelles », février 2020
Conseil d'Etat, « Le numérique et
les droits fondamentaux », Richard, T. Areau, A. Delorme, rapp. Annuel,
2014
Coup Data, «3 Questions To... Axelle
Lemaire», 3 décembre 2019
Deloitte Canada, « gagner sur tous les
tableaux : protéger la vie privée à l'heure de
l'analytique », 2014
Editorial, Le Monde « L'intelligence
artificielle, enjeu majeur pour l'UE », 18 février 2020
EUFRA, «AI policy initiatives (2016-2019)», 4
novembre 2019
Agence européenne chargée de la
sécurité des réseaux et de l'information (ENISA),
« Privacy and Data protection by design - form policy to
engineering», décembre 2014
Agence européenne chargée de la
sécurité des réseaux et de l'information (ENISA),
« Privacy by design in big data», décembre 2015
Agence européenne chargée de la
sécurité des réseaux et de l'information (ENISA)
« recommendations on shaping technology according to GDPR
provisions», décembre 2018
Forbrukerradet, «Deceived by design, How
tech companies use dark patterns to discourage us from exercising our rights to
privacy», 27 juin 2018
G20, « G20 Ministerial Statement on
Trade and Digital Economy », juin 2019
G 29, Avis 05/2014 sur les Techniques
d'anonymisation, 0829/14/FR WP216, 2014 G29, «Guidelines
on transparency under Regulation 2016/679», 11 avril 2018
G29, « Lignes directrices concernant
l'analyse d'impact relative à la protection des données (AIPD) et
la manière de déterminer si le traitement est «susceptible
d'engendrer un risque élevé» aux fins du règlement
(UE) 2016/679 », WP 248, 4 avril 2017
G29, «Guidelines on Automated individual
decision-making and Profiling for the purposes of Regulation 2016/679», 3
octobre 2017
ICDPPC, « Declaration on ethics and data
protection in artifical intelligence», 23 octobre 2018
ICDPPC, « Report of the International Working Group on
Digital Education » Août 2019
ICDPPC Working Group, Groupe de travail sur
l'éthique et la protection des données dans le domaine de
l'intelligence artificielle, Plan stratégique (2019-21)
European Data Protection Board,
«Guidelines 4/2019 on Article 25 Data Protection by Design and by
Default», 20 novembre 2019
CEPD, « rapport annuel », 2018
CEPD, « Guidelines 1/2018 on
certification and identifying certification criteria in accordance with
Articles 42 and 43 of the Regulation», 4 juin 2019
CEPD, avis n° 3/2018 sur la manipulation
en ligne et les données à caractère personnel, mars
2018
European Data Protection Board,
«Response to the MEP Sophie in't Veld's letter on unfair algorithms»,
29 janvier 2020
European Data Protection Supervisor, «
Avis préliminaire sur le respect de la vie privée dès la
conception » avis 5/2018, 31 mai 2018
European Data Protection Supervisor, «
Internet Privacy Engineering Network discusses state of the art technology for
privacy and data protection », 12 juin 2019
Gabudeanu (L.), «Embedding privacy in
software development: Implementation aspects», EDPS, juin 2019
Groupe d'experts indépendants de haut niveau
sur l'intelligence artificielle constitué par la Commission
Européenne, « Définition de l'IA : principales
capacités et disciplines », juin 2018
Ganascia (J.G.), Germain (E.), Kirchner, (C.)
« La souveraineté à l'ère du
numérique. Rester maîtres de nos choix et de nos valeurs »,
CERNA, Octobre 2018
Institut National de Recherche en Informatique et en
Automatique, « intelligence artificielle, livre blanc n°1
», 2016
Institut Montaigne, «Données
personnelles, comment gagner la bataille ?», Godement (F.),
décembre 2019
Institut Montaigne, «Algorithmes :
contrôle des biais S.V.P», mars 2020 Institut
Montaigne, « enseignement supérieur : connectez vous !
», juin 2017
Longuet (G.), Montaugé (F.), Rapport
Commission d'enquête sur la souveraineté au numérique,
« le devoir de souveraineté numérique : ni
résignation, ni naïveté », Sénat, version
provisoire, n° 7 tome I (2019-2020) , 1 octobre 2019
Miailhe (N.), « Géopolitique de
l'intelligence artificielle : le retour des empires ? », politique
étrangère, 2018,
Organisation de coopération et de
développement économiques (OCDE), « The OECD
privacy framework », 2013
Organisation de coopération et de
développement économiques (OCDE), « Recommendation
of the Council on Artificial Intelligence », OECD/LEGAL/0449, 22 mai
2019
Organisation de coopération et de
développement économiques (OCDE), «Enhancing Access
to and Sharing of Data : Reconciling Risks and Benefits for Data Re-use across
Societies», 6 novembre 2019
Organisation de coopération et de
développement économiques (OCDE), « State of the
art in the use of emerging technologies in the public sector », 2019
Paul (C.), Féral-Schuhl (C.), Rapport
à l'Assemblée nationale n°3119 « Numérique et
libertés, un nouvel âge démocratique », 2015
Parlement Européen, « A
governance framework for algorithmic accountability and transparency »,
avril 2019
Thibout (C.), « L'intelligence
artificielle, un rêve de puissance », 10 septembre 2018
Thibout (C.), « La stratégie
européenne en intelligence artificielle : un acte manqué ?
», Iris France, 19 février 2020
Villani (C.), « Donner un sens à
l'intelligence artificielle, Pour une stratégie nationale et
européenne », AIforhumanity, mars 2018
Wiewiórowski (W.), «AI and Facial
Recognition: Challenges and Opportunities», EDPS, 21 février
2020
WhiteHouse, Executive office of the
president, president's council of advisors on science and technology
«report to the president big data and privacy: a technological perspective
», mai 2014
36th Conference of Data protection and
Privacy commissioners, «resolution big data», 2014
36th Conference of Data protection and
Privacy commissioners, «Mauritius Declaration on the Internet of
Things», 14 octobre 2014
Table des matières
INTRODUCTION
1. L'avènement du big data
2. Un logiciel de traitement intelligent ?
3. Comment fonctionne l'intelligence artificielle ?
4. Les questions soulevées par l'usage de
l'intelligence artificielle
5. La régulation de l'utilisation des
données
6. Mise en oeuvre du privacy by design et by default dans un
traitement d'intelligence artificielle

PREMIERE PARTIE : UNE NECESSAIRE ADAPTATION PRINCIPES
DE PROTECTION DES DONNEES A CARACTERE PERSONNEL A L'INTELLIGENCE
ARTIFICIELLE
Titre 1 : L'application des principes de protection des
données à caractère personnel à l'intelligence
artificielle
Chapitre 1 : Les principes directeurs du RGPD, des
principes limités
Section 1 : La remise en question des
définitions par l'intelligence artificielle
Section 2 : La confrontation des principes directeurs du RGPD
à la technologie de l'IA Section 3 : Le privacy by design
et by default, entre innovation et protection des
données
Chapitre 2 : La nécessité de
créer des principes spécifiques à l'IA
Section 1 : Des principes inhérents à la collecte
et au traitement des données Section 2 : Des principes éthiques
effectifs
Titre 2 : Les moyens d'autorégulation
adaptés à l'intelligence artificielle
Chapitre 1 : Vers une nouvelle notion du risque
Section 1 : Le moment d'appréciation du
risque
Section 2 : Un risque approprié au logiciel d'intelligence
artificielle
Chapitre 2 : Des outils de conformités
adaptés au respect de la vie privée Section 1 : Les
mesures organisationnelles
Section 2 : Les mesures techniques
SECONDE PARTIE : CONSTRUIRE UNE INTELLIGENCE ARTIFICIELLE
CONFORME AUX PRINCIPES DE PRIVACY BY DESIGN ET DE PRIVACY BY
DEFAULT
Titre 1 : Le régime envisageable de lege
lata
Chapitre 1 : Le régime de gouvernance
autorégulé de la donnée
Section 1 : La responsabilité incertaine des
acteurs
Section 2 : Les instruments à la disposition du
responsable du traitement
Chapitre 2 : Les points d'attention selon le cycle de
vie de la donnée
Section 1 : Définition du cycle de vie de la donnée
lors d'un traitement d'intelligence artificielle Section 2 : Les étapes
à respecter tout au long du cycle de vie de la donnée
Titre 2 : Le régime envisageable de lege
feranda
Chapitre 1 : De la gouvernance de la donnée
à la gouvernance de l'intelligence artificielle Section 1
: L'IA éthique, stratégie géopolitique de
souveraineté européenne
Section 2 : L'éthique de l'IA, fruit d'une
réflexion pluridisciplinaire de tous les acteurs
Chapitre 2 : Replacer l'utilisateur au coeur de
l'intelligence artificielle Section 1 : Responsabiliser
l'utilisateur
Section 2 : Doter l'utilisateur d'outils adaptés
CONCLUSION
| 

