Environnements de grappes de calcul intensif sur réseaux d'entreprise: déploiement, exploitation et performances( Télécharger le fichier original )par Franklin TCHAKOUNTE Université de Ngaoundéré - Master en Systèmes et Logiciels en Environnements Distribués 2010 |

Chapitre ICALCUL PARALLELE ET ARCHITECTURE DES GRAPPES D Epuis les débuts de l'informatique s'est posée la question de résoudre rapidement des problèmes (le plus souvent numériques) coûteux en temps de calcul : simulations numériques, cryptographie, imagerie, S.G.B.D., etc. Pour résoudre plus rapidement un problème donné, une idée naturelle consiste à faire coopérer simultanément plusieurs agents à sa résolution, qui travailleront donc en parallèle. 1 Calcul parallèle 1.1 Motivations et principes La puissance des ordinateurs séquentiels augmentant de manière régulière (en gros, elle est multipliée par deux tous les dix-huit mois1), on pourrait croire qu'elles sera toujours suffisante, et que les machines parallèles (ordinateurs multiprocesseurs) sont inutiles. Plusieurs raisons contredisent cette tendance.
1Loi de Moore 21 Téra = 103Giga = 106Méga = 109Kilo = 1012. et le micro-processeur. Cette distance doit pouvoir être parcourue 1012 fois par seconde à la vitesse de la lumière, c 3.108m.s-1,d'où
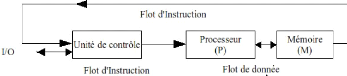
L'ordinateur devrait donc tenir dans une sphère de 0,3 mm de rayon. Avec cette contrainte de distance, si l'on considère la mémoire comme une grille carrée de 106 x 106 octets, alors chaque octet doit occuper une cellule de 3Å de côté, c'est à dire la surface occupée par un petit atome. On ne tient ici pas compte de l'espace nécessaire à l'acheminement de l'information et de l'énergie, ainsi qu'à l'extraction de la chaleur. Bien que la puissance et la capacité mémoire des ordinateurs ne cessent de croître, certains utilisateurs désirent toujours obtenir leurs résultats plus rapidement. D'autres souhaitent aussi faire tourner des simulations de plus grande précision en conservant un temps de calcul raisonnable. Le coût de fabrication d'un processeur toujours plus puissant croît exponentiellement avec la vitesse avec laquelle il peut faire les calculs. Par contre obtenir N processeurs ne représente qu'un coût N fois plus grand que celui d'un seul processeur. Le coût total de la machine parallèle (incluant le réseau d'interconnexion...) reste donc du même ordre. Le parallélisme consiste à utiliser plusieurs ressources disponibles (processeurs, mémoires, disques, etc.) pour qu'elles participent ensemble au calcul d'une application. En multipliant les ressources par N , un utilisateur peut espérer : - calculer N fois plus vite, - calculer des problèmes occupant N fois plus d'espace mémoire. Le calcul parallèle est donc un moyen pour fournir de la haute puissance de calcul à un prix raisonnable en utilisant des ordinateurs personnels. Pourtant, cela ne suffit pas; il faudrait trouver une bonne méthode pour soumettre l'application aux différentes ressources présentes en vue de son exécution. Pour cela, il faut appliquer une bonne programmation de l'application en vue de bien répartir les données pour résoudre un problème de grande taille qui satureraient la mémoire d'un seul ordinateur ou même d'un supercalculateur. Les applications parallèles sont une classe très importante d'applications concurrentes pour le calcul scientifique : elles visent à diminuer les temps d'exécution des calculs numériques intensifs, ou bien à répartir les données pour résoudre des problèmes de grande taille qui satureraient la mémoire d'un seul ordinateur ou même d'un seul supercalculateur. Cette section présente la classe des applications parallèles, puis elle se focalise sur deux technologies de programmation parallèle, à savoir les bibliothèques MPI et les systèmes de MVP. 1.2 Programmation parallèle 1.2.1 Objectifs de la programmation parallèle La programmation parallèle s'est imposée dans le domaine du calcul scientifique, car son objectif est essentiellement la haute performance. La programmation parallèle vise : - à répartir les tâches de calcul dans plusieurs processus sur plusieurs processeurs; - à répartir les données des problèmes de grande taille qui satureraient la mémoire d'un seul ordinateur ou même d'un superordinateur; - à recouvrir les calculs et les opérations d'entrées-sorties, afin de masquer leur latence. Dans tous les cas, l'objectif de la programmation parallèle est de diminuer les temps d'exécution des calculs numériques intensifs. Cette propriété permet alors d'augmenter la précision des calculs (et donc la taille des données) tout en conservant des temps de calcul acceptables. 1.2.2 Classes d'applications parallèles Programmation multi-threads ou multiprocessus. La programmation < multi-threads > est une méthode de programmation parallèle qui consiste à faire coopérer plusieurs threads au sein d'un même processus pour exécuter l'application : elle permet en particulier de recouvrir les calculs et les opérations d'entrées-sorties. Une autre approche est la programmation < multi-processus »3 : soit tous les processus de l'application sont issus du même code source (SPMD4), soit l'application est faite de plusieurs programmes (ou codes sources) différents (MPMD5). Dans le cas de la programmation multi-processus, les tâches de calcul sont le plus souvent réparties sur des ordinateurs qui ne partagent pas de mémoire commune. Or les processus doivent coopérer, donc s'échanger des données ou se synchroniser. Les communications entre les processus sont susceptibles de ralentir l'exécution d'une application parallèle multi-processus. Le ratio calcul/communications est le rapport entre le temps passé par les processus à faire des opérations de calcul et le temps qu'ils passent à communiquer. Plus ce ratio est faible et moins l'intérêt de la parallélisation est évident. C'est pourquoi on peut rarement augmenter indéfiniment le nombre de processus qui se répartissent les tâches de calcul car ils passent alors plus de temps à communiquer qu'à calculer et le temps global d'exécution de l'application augmente. Applications statiques et applications dynamiques. Parmi les applications parallèles, on peut distinguer les applications statiques et les applications dynamiques. Applications statiques. Dans une application statique, tous les processus sont lancés au moment du déploiement de l'application : l'utilisateur sait combien de processus composent l'application au début de son exécution et le nombre de processus reste le même tout au long de l'exécution. Applications dynamiques. Dans une application dynamique, il se peut qu'un ou plusieurs processus soient créés en cours d'exécution, ou bien soient terminés avant la fin de l'exécution de l'application. Cette création ou terminaison de processus en cours d'exécution se fait à l'initiative de l'application et les processus ajoutés doivent faire partie intégrante de l'application, au même titre que les processus lancés au moment du déploiement initial de l'application. Par exemple, un utilisateur qui lance par ailleurs un programme de visualisation ou d'analyse des traces de l'application en cours d'exécution ne permet pas de qualifier l'application de dynamique. Actuellement, la plupart des applications de calcul scientifique sont statiques, car elles sont plus simples à programmer, et il existe peu de support pour les applications parallèles dynamiques. 1.2.3 Modèle de la programmation parallèle Nous distinguons deux grandes classes de modèles de programmation parallèle : - avec le parallélisme explicite, le programmeur fait l'effort de parallélisation de l'application : décomposition en sous-tâches, placement des tâches sur les processeurs, répartition et redistribution des données, communications (échange de données et synchronisation) entre les tâches, etc.; - avec le parallélisme implicite, le travail de parallélisation de l'application est effectué par un compilateur (pour les langages parallèles), par un outil de parallélisation automatique, ou bien par une bibliothèque de fonctions déjà parallélisées. 3Les approches multi-threads et multi-processus ne sont pas incompatibles. 4Single Program, Multiple Data 5Multiple Program, Multiple Data. Comme le programmeur est souvent le plus à même de décider comment le parallélisme peut être exploité pour un problème particulier, le parallélisme explicite donne en général de meilleures performances que la parallélisme implicite. La programmation par passage de messages, celle par mémoire partagée et certains langages parallèles font partie de la classe du parallélisme explicite; les bibliothèques parallèles de haut niveau d'abstraction relèvent du parallélisme implicite, même si la frontière entre ces deux types de parallélisme n'est pas toujours très nette. Passage de messages. La programmation par passage de messages consiste à faire coopérer les différentes tâches qui constituent l'application par l'envoi et la réception explicites de données, typées ou non. Le plus souvent, les environnements de programmation par passage de messages ( MPI (Message-Passing Interface) et PVM (Parallel Virtual Machine) ) offrent également des opérations de synchronisation simples (la < barrière >, qu'un processus ne peut franchir que lorsque tous les autres processus de l'application l'ont aussi atteinte), ainsi que des opérations < collectives >, telles que : - envoyer une donnée à tout un groupe de processus en une seule opération (diffusion, ou Broad- cast); - effectuer une opération arithmétique simple (produit, somme, etc.) ou logique ( < et > , < ou > , etc.) sur des données détenues par tous les processus d'un groupe (opération de < réduction >, Reduce); - regrouper dans un seul processus des données qui sont dispersées dans chaque processus d'un groupe (Gather); - disperser des données situées dans un vecteur sur un processus vers les autres processus d'un groupe (Scatter). Deux grands standards sont disponibles pour le passage de messages: Message Passing Interface (MPI) et Parallel Virtual Machine (PVM). MPI est une API6 pour écrire des programmes parallèles portables. C'est une bibliothèque portable de programmation parallèle sur des ordinateurs distribués, hétérogènes (systèmes d'exploitation, architectures matérielles) et reliés en réseau. PVM est plus ancien, mais nous avons choisi de travailler avec MPI qui présente de nombreux avantages : - MPI est une norme définie par le ' MPI Forum [29], soutenu par les milieux académiques et industriels; - il existe un très grand nombre d'implémentations de MPI, tant académiques (gratuites ou non) qu'industrielles (IBM, Sun Microsystems, SGI, etc.), et qui sont portées sur de nombreuses plates-formes; - MPI est toujours un sujet de recherche actif et fait l'objet de nombreux développements; - MPI est très massivement utilisé dans les milieux scientifiques (physiciens, chimistes, etc.) pour le calcul numérique parallèle. Ainsi, la programmation par passage de messages est un modèle d'assez bas niveau : le travail de parallélisation revient intégralement au programmeur. Mémoire Partagée. Dans le modèle de programmation parallèle par mémoire partagée, les tâches qui constituent l'application coopèrent par l'écriture et la lecture dans une mémoire commune : ces opérations permettent d'échanger des données et de se synchroniser. Si les tâches sont les threads d'un même processus, alors ils peuvent lire et écrire dans l'espace d'adressage du processus. Si les tâches sont des processus au sein d'un même système d'exploitation, alors ils peuvent partager des segments 6Application Programming Interface. de mémoire c'est le cas par exemple avec les IPC7, ou bien encore avec les systèmes à image unique (SSI8). Enfin, le mécanisme de < mémoire virtuellement partagée > (MVP) permet de programmer des systèmes à mémoire distribuée en utilisant le modèle de programmation parallèle par mémoire partagée un environnement de MVP donne l'illusion à des processus localisés sur des machines distribuées (avec des systèmes d'exploitation distincts) de partager un espace mémoire commun. Dans ce modèle, la distribution des données est transparente et les communications entre les tâches de l'application parallèle sont implicites ce modèle est d'un peu plus haut niveau que celui de la programmation par passage de messages. Cependant, la programmation par mémoire partagée laisse encore le soin au programmeur de gérer lui-même la décomposition du problème en tâches de calcul, le placement de ces tâches, et la gestion de la localité des accès. 2 Taxonomie des machines parallèles Pour ordonnancer finement une application parallèle, il est également nécessaire de bien identifier les paramètres clés qui reflètent les architectures de la machine parallèle surlesquelles on envisage d'exécuter des applications. Historiquement, l'une des premières classifications est celle proposée par Flynn [12] en 1966. Le système de classification de Flynn [12] est basé sur la notion de flots d'information. Il existe deux types de flots d'informations dans un processeur les instructions et les données [14]. Le flot d'instructions est défini comme la séquence d'instructions exécutée par l'unité de calcul. Le flot de données est défini comme le trafic de données échangé entre la mémoire et l'unité de calcul. Selon la classification de Flynn, les flots d'instructions ou de données peuvent être uniques ou multiples. L'architecture de l'ordinateur peut être classifiée en quatre catégories distinctes [14]. - Single-instruction single-data streams (SISD); - Single-instruction multiple-data streams (SIMD); - Multiple-instruction single-data streams (MISD); - Multiple-instruction multiple-data streams (MIMD). 2.1 Architecture SISD Les machines Von Neumann monoprocesseur conventionnelles sont classifiés comme les systèmes SISD. Les algorithmes pour les calculateurs SISD ne contiennent aucun parallélisme. La figure I.1 représente cette machine.
Figure I.1 - Architecture SISD 7InterProcess communication 8Single System Image, où un système d'exploitation unique couvre un ensemble d'ordinateurs distribués, tel que Kerrighed : http :// www.kerrighed.org/. 2.2 Architecture MISD Dans la catégorie MISD, le même flot de données circule dans un vecteur linéaire de processeurs qui exécutent des flots d'instructions différentes. En pratique, il n'existe aucune machine construite sur ce modèle. Certains auteurs ont considérés les machines pipelines comme des exemples de machines MISD. Les ordinateurs parallèles sont soit SIMD ou MIMD. Lorsqu'il ya seulement une unité de contrôle et lorsque tous les processeurs exécutent la même instruction de manière synchrone, la machine parallèle est classifiée comme SIMD. Dans la machine MIMD, chaque processeur a sa propre unité de contrôle et peut exécuter des instructions différentes sur des données différentes. Les figures I.2 et I.3 représentent les machines SIMD et MIMD respectivement.
Figure I.2 - Architecture SIMD
Figure I.3 - Architecture MIMD 2.3 Architecture SIMD Le modèle SIMD du calcul parallèle comprend deux parties : l'ordinateur frontal de style Von Neumann et un ensemble de processeurs comme montre la figure I.4. Le vecteur de processeurs est un ensemble d'éléments de calcul identiques synchronisés capables d'exécuter simultanément la même opération sur des données différentes. Chaque processeur dans le vecteur a une petite mémoire locale où résident les données distribuées lors du calcul parallèle. Le vecteur de processeurs est connecté au bus mémoire du frontal ainsi donc le frontal peut accéder aléatoirement aux mémoires locales des processeurs comme si c'était une autre mémoire.
Figure I.4 - Modèle d'architecture SIMD Les processeurs opèrent de façon synchrone et une horloge globale est utilisée pour effectuer les opérations en mode <lockstep> c'est à dire qu'à chaque étape (top de l'horloge globale) tous les processeurs exécutent la même instruction, chacun sur une donnée différente. Dans ce système, soit les processeurs ne font rien, soit ils effectuent la même opération au même moment. Les processeurs <array> comme le ICL DAP (Distributed Array Processor) et les processeurs vectoriels pipelinés comme les CRAY 1, le CRAY 2 et le CYBER 205 font partie de la classe des calculateurs SIMD. Aussi, plus récemment, Maspar et CM (Connection Machine). Les machines SIMD sont particulièrement utiles pour traiter les problèmes à structure régulière où la même instruction s'applique à des sous-ensembles de données. Il y a deux schémas majeurs qui sont utilisés dans les machines SIMD (voir figure I.5). Dans la première configuration, chaque processeur a sa mémoire locale. Les processeurs peuvent communiquer entre eux via le réseau d'interconnexion. Si le réseau d'interconnexion ne fournit pas une connexion directe entre une paire de processeurs donnée, alors cette paire pourra échanger les données via un processeur intermédiaire. Dans la seconde configuration SIMD, les processeurs communiquent entre eux via un réseau d'interconnexion. Deux processeurs peuvent s'échanger les données par l'intermédiaire des modules de mémoire ou par un processeur intermédiaire. Exemple : Addition de deux matrices A + B = C Soient deux matrices A et B d'ordre 2, et 4 processeurs. A11 + B11 = C11 ... A12 + B12 = C12 A21 + B21 = 1 ... A22 + B22 = 2 La même instruction est envoyée aux 4 processeurs (ajouter les 2 nombres) et tous les processeurs exécutent cette instruction simultanément. Un pas de temps suffit contre quatre sur une machine séquentielle.
Figure I.5 - Les deux schémas SIMD Une instruction peut être simple (addition de 2 nombres) ou complexe (fusion de 2 listes). De la même façon les données peuvent être simples (un nombre) ou complexes (plusieurs nombres). Il peut parfois être nécessaire de limiter l'exécution de l'instruction a un sous ensemble des processeurs c'est à dire seulement certaines données ont besoin d'être traitées par cette instruction. Cette information peut être codée par un 11drapeau 11sur chaque processeur qui indique si :
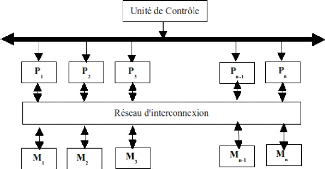
C'est la classe la plus générale et la plus puissante de toute cette classification. Les architectures parallèles MIMD sont faites de plusieurs processeurs et de plusieurs modules de mémoires connectées via un moyen de communication. Elles sont subdivisées en deux catégories : La mémoire partagée et le passage de messages. La figure I.6 illustre l'architecture générale de ces deux catégories.
Figure I.6 - Architecture à mémoire partagée et Architecture de passage de messages Dans les systèmes à mémoire partagée, les processeurs s'échangent les informations à travers leur mémoire centrale partagée tandis qu'ils s'échangent les informations à travers le réseau d'interconnexion dans le système d'échange de messages. Un système à mémoire partagée typique accomplit la coordination interprocesseur par une mémoire globale partagée par tous les processeurs. Ils représentent généralement les systèmes serveurs qui communiquent par un bus et le contrôleur de la mémoire cache. Les architectures à mémoire partagée multiprocesseurs SMP (symmetric multiprocessor) sont des architectures très courantes et très populaires. Parce que l'accès à la mémoire partagée est stable, ces systèmes sont nommés SMP (symmetric multiprocessor). Chaque processeur a la même opportunité de lire/écrire dans la mémoire, avec la même vitesse. Comme exemple de machines à mémoire partagée on a : les serveurs multiprocesseurs Sun Microsystems, les serveurs multiprocesseurs Silicon Graphics Inc. Le système par passage de messages (ou a mémoire distribuée) typiquement combine la mémoire locale et le processeur sur chaque noeud du réseau d'interconnexion. Il n y a pas de mémoire globale, ainsi il est nécessaire de déplacer les données d'une mémoire locale a une autre par le moyen d'envoi de messages. Ceci est réalisé typiquement en utilisant les commandes Send/Receive, qui doivent être écrits dans le logiciel d'application par le programmeur. Ainsi, les programmeurs doivent apprendre le paradigme du passage de messages qui implique des mouvements de données. Les exemples commerciaux de telles architectures sont nCUBE, iPSC/2 etc. Il était aussi apparent que la mémoire distribuée est le seul moyen efficace pour augmenter le nombre de processeurs administrés par un système parallèle et distribué. Les techniques a mémoires distribuées sont les plus appropriées pour le passage a l'échelle. Un conflit a donc existé entre ces deux architectures : programmer dans le modèle de mémoire partagée était facile et concevoir des systèmes dans le modèle de passage de messages fournissait le passage a l'échelle. Les calculateurs MIMD a mémoire commune sont appelés multiprocesseurs ou machines fortement couplées. Dans cette classe, l'accès a la mémoire est uniforme(UMA)9 ; c'est a dire tous les processeurs accèdent a toutes les zones de la mémoire commune avec la même vitesse. Le point fort de ces machines est la rapidité du partage de données entre des processeurs qui exécutent une même application parallèle. Cela est dû au fait que la mémoire commune est relativement proche des différents processeurs mis en jeu. Par exemple ENCORE, MULTIMAX, SEQUENT et BALANCE. Sur ce type d'architecture, tout le trafic entre les processeurs et la mémoire commune passe par un bus. Le trafic augmentant avec le nombre de processeurs, ce bus devient rapidement un goulot d'étranglement. C'est vraisemblablement pourquoi ce type de calculateur n'est pas massivement "scalable". Souvent, pour résoudre partiellement ce problème, une mémoire cache est associée a chaque processeur. L'objectif est de diminuer le trafic sur le bus et de rendre les données accessibles plus rapidement au processeur puisqu'il est plus rapide pour lui de les lire dans un cache rapide que dans une grande mémoire globale. Typiquement, le nombre de processeurs ne dépasse pas quelques dizaines. Les calculateurs MIMD avec un réseau d'interconnexion sont appelés multiordinateurs ou machines faiblement couplées. Par exemple INTEL iPSC, NCUBE/7, IBM SP1 et SP2 et réseaux de Transputers. Dans cette classe de calculateurs, les processeurs sont souvent appelés "noeuds" et ne partagent rien d'autre que le réseau. L'accès a la mémoire est non uniforme(NUMA)10 ;c'est a dire tous les processeurs n'accèdent pas a toutes les zones de la mémoire commune avec la même vitesse. Ce réseau peut avoir des performances très différentes : réseau local a crossbar ou switch Omega. Ce réseau est comparativement peu utilisé par rapport au trafic sur le bus d'une mémoire commune. Il sert uniquement a échanger des données entre les processeurs en utilisant un protocole de communication de type "passage de messages". Ce type d'architecture est fortement "scalable" et le nombre de noeuds peut atteindre plusieurs centaines. Les types de plates-formes multi-ordinateurs couramment cités dans la littérature sont :
9uniform memory access 10Non uniform memory access réseau local. Mais les différents noeuds et liens peuvent avoir des caractéristiques différentes. L'avantage qu'il y a à utiliser les grappes hétérogènes est de pouvoir disposer facilement de plusieurs ressources au sein d'un réseau local. Par contre, il est très difficile d'approcher les performances optimales pour les tâches parallèles du fait de la nécessité de synchronisation entre divers processus d'une même tâche.
2.4.1 Exemple d'application des quatre classes principales A, B, C et D sont les données. + et * sont les instructions ou les opérations.
Une des tendances claires dans le calcul est la substitution des machines parallèles coûteuses et spécialisées par les grappes de postes de travail plus rentables. 3 Grappes d'ordinateurs 3.1 Origine et évolution de grappes Cette section donne un tour d'horizon sur les origines et l'évolution des grappes de machines. Nous avons décomposé en quatre phases l'évolution des architectures parallèles qui n'est bien entendu pas achevée, mais il nous semble que les phases décrites ci-dessous reflètent correctement la situation. 3.1.1 Les supercalculateurs Les premières plate-formes possédant une architecture parallèle sont les machines désignées fréquemment par le terme de supercalculateurs. Il s'agit là d'un matériel très conséquent, aussi bien au niveau de la taille que des moyens nécessaires à leur exploitation. En effet, l'implantation et l'entretien d'une machine de ce type posent des problèmes logistiques concrets qui induisent un coût non négligeable en plus de la machine proprement dite, dispendieuse. Ces machines ont un succès cyclique et il est si courant de lire dans la presse les difficultés rencontrées par tel ou tel constructeur, que l'on peut se poser la question du maintien d'une niche de ce type tant le marché paraît moribond. Cependant, les sorties de plusieurs modèles de supercalculateurs semblent indiquer un regain d'intérêt pour ces architectures citons par exemple les Cray X-1 et RedStorm, l'Earth Simulator ou encore l'IBM BlueGene/L. Ce dernier est même premier du dernier classement du top 50011 montrant bien l'enracinement des supercalculateurs (au moins de type vectoriel) dans le paysage du calcul haute-performance. Du point de vue de l'utilisation, ces machines sont en général conçues pour des besoins applicatifs spécifiques et surtout gourmands en puissance de calcul. L'approche est de type High Performance Computing (HPC) on cherche à obtenir une importante puissance de calcul sur une durée de temps limitée. Ces architectures ne sont pas aisément extensibles et lorsque les performances deviennent insuffisantes, le changement de matériel s'impose. 3.1.2 les réseaux de station de travail Le coût et la logistique nécessaires pour l'implantation d'un supercalculateur étant prohibitifs pour une majorité de laboratoires et d'universités, des solutions de repli (ou de rechange) ont été adoptées afin de disposer d'un accès à une machine parallèle. Or, les laboratoires possèdent des moyens de calcul souvent inutilisés qui sont les stations de travail. L'idée de base est la suivante les temps de cycles inutilisés sont exploités en fédérant un ensemble de stations avec un réseau d'interconnexion (Figure I.7). Ce matériel étant plus standard, il est moins onéreux qu'un supercalculateur et surtout plus facilement implantable. L'approche est quelque peu différente du cas précédent, car il s'agit d'une vision de type High-Throughput Computing (HTC) où la puissance de calcul désirée doit être maintenue sur une longue période de temps (plusieurs mois, voire années). Nous avons moins affaire au parallélisme qu'aux systèmes répartis, et le projet Condor ( [8]) est typique de cette approche. C'est à partir de l'exploitation des configurations de cette nature que se sont posés les enjeux du support de la gestion dynamique des processus et des applications ainsi que de la tolérance aux pannes. Ces aspects étaient le plus souvent ignorés dans la programmation des supercalculateurs, entités fiables et offrant un modèle d'exécution statique. 11Novembre 2004
Figure I.7 - Un réseau de stations de travail 3.1.3 Les grappes de PC Les réseaux de stations de travail ont été massivement adoptés par les laboratoires, mais les réseaux d'interconnexion étaient souvent peu rapides et constituaient un goulot d'étranglement pour les performances. L'arrivée des réseaux rapides, avec une amélioration substantielle du débit (plusieurs ordres de grandeur) a bousculé cette situation et permis l'émergence d'un nouveau type d'architecture les grappes, dont le projet NOW est un représentant [32]. Architecturalement, il s'agit d'une interconnexion de PC standards (encore moins chers que les stations de travail) avec un réseau haut-débit. Cet ensemble de machines est localisé dans un même lieu physique (exemple la même pièce), à la différence des réseaux de stations qui pouvaient s'étendre sur une échelle plus grande, comme un bâtiment par exemple. La figure I.8 schématise une telle grappe de PC.
Figure I.8 - Une grappe de PC Cette approche est un mélange des deux précédentes les grappes sont dédiées au calcul haute-performance (HPC), mais avec des composants standards. L'extensibilité est très bonne, puisqu'il suffit de rajouter des noeuds pour augmenter la puissance de calcul. Cependant, la difficulté d'exploitation et de programmation est plus importante qu'avec les supercalculateurs car ces derniers sont équipés d'outils spécifiques. Dans le cas des grappes, les outils d'exploitation sont souvent calqués sur ceux des supercalculateurs et la gestion dynamique des processus ou la tolérance aux pannes sont souvent reléguées au second plan. Malgré ces quelques désagréments, l'excellent ratio performances/prix favorise les grappes qui tendent à s'imposer plus de la moitié des machines classées au top 500 sont des grappes. 3.1.4 Les architectures actuelles Ce sont ces architectures de type <grappes> qui connaissent des évolutions multiples. Nous trouvons donc les catégories décrites dans les paragraphes suivants. les grappes de grappes Cette évolution est naturelle et découle des excellentes capacités d'extensibilité des grappes. Le principe consiste en une interconnexion de plusieurs grappes potentiellement séparées par une forte distance géographique. En quelque sorte, il s'agit d'une méta-grappe avec une approche plutôt de type HTC, en remplaçant les stations de travail par des unités plus importantes (les grappes). Une telle évolution doit être replacée dans le contexte du [19] Grid computing et du metacomputing, dont le but est l'exploitation de ressources réparties. Cette agrégation pose de nouveaux problèmes car les composants sont hétérogènes processeurs, systèmes d'exploitation et réseaux d'interconnexion varient potentiellement d'une grappe à l'autre. La nature du réseau d'interconnexion est importante car cela permet de créer des sous-classes de grappes de grappes. L'une de ces classes de grappes de grappes est très présente les grappes faiblement couplées où les différentes grappes sont reliées par un nombre de liens tel que l'ensemble des noeuds ne forme pas un graphe complet (mais les grappes de départ continuent à l'être cependant). Les liens peuvent être à haut-débit et potentiellement distincts de ceux utilisés à l'intérieur de ces sous-grappes (Figure I.9).
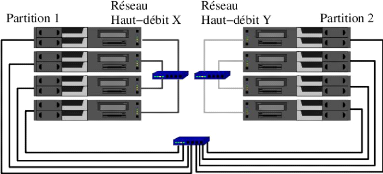
Figure I.9 - Une grappe de grappes faiblement couplées Les grappes multiplement câblées Une autre tendance consiste à équiper une grappe avec plusieurs réseaux haut-débit. La multiplicité des technologies disponibles favorise cette situation. La grappe sera soit totalement câblée avec les multiples réseaux, soit organisée en partitions, avec un réseau haut-débit dédié à une partition particulière (Figure 1.10). La difficulté réside alors dans la capacité du logiciel à prendre en compte ou non cette multiplicité des réseaux.
Figure I.10 - Une grappe multiplement câblée (avec des partitions) Les grappes de grande taille Comme les grappes sont facilement extensibles, il devient possible de construire des machines avec de nombreux noeuds. Si les premières générations de grappes étaient constituées par quelques dizaines de noeuds, les générations actuelles peuvent aller jusqu'à plusieurs centaines, voire milliers d'unités (par exemple, le projet Colombus de Fujitsu avec 16384 noeuds). Dans ce cas, le problème réside dans la capacité des logiciels à exploiter de telles configurations. Les mécanismes mis en place sont-ils aussi extensibles pour suivre l'évolution du matériel? Les grappes de type beowulf En 1994, Thomas Sterling et Don Becker du CESDIS (Center of Excellence in Space Data and Information Sciences) construisirent une grappe de 16 processeurs DX4 reliés par un réseau Ethernet 10BaseT. Ils appelèrent cette grappe Beowulf. Une grappe Beowulf est le type de grappe le plus simple que l'on puisse rencontrer. La seule différence majeure avec un réseau de stations de travail (NOW12) est que les noeuds sont complètement dédiés aux activités de la grappe. Le concept d'une grappe Beowulf repose sur l'utilisation de matériel issu de l'industrie du COTS (Commodity Off The Shelf) et des logiciels du domaine public. Les noeuds sont généralement des PC, ils ne sont pas forcément homogènes et sont interconnectés par un réseau classique de type Ethernet ou FastEthernet. Les logiciels sont généralement du domaine public; on retrouve donc principalement le système d'exploitation 12Network of workstations Linux13, les compilateurs GNU et des librairies de passage de messages comme MPI (Message Passing Interface) et PVM (Parallel Virtual Machine). Ce type d'architecture permet de faire tourner des applications qui ne nécessitent pas ou très peu de communications. Les applications parallèles à très gros grain14 ou à indépendance de données peuvent en bénéficier. Ce sont des architectures non génériques. Elles sont montées manuellement en utilisant des logiciels libres selon les besoins et les capacités de l'utilisateur. Ces logiciels y sont installés dépendamment de l'utilisateur et des traitements qu'il veut effectuer. Les ressources informatiques constituants ce type d'architecture peuvent être hétérogènes en termes d'unités de traitement, d'architecture, de logiciels, des réseaux d'interconnexion. Moyens de calcul. En termes de puissance de calcul, on peut aussi bien trouver des supercalculateurs que des ordinateurs de bureau (PC), des serveurs d'exécution, des stations de travail, etc. Ce point distingue le calcul sur grille du metacomputing, qui ne fait intervenir que des supercalculateurs. Architectures. En termes d'architecture matérielle, les ordinateurs peuvent être équipés de différents types de processeurs PowerPC, compatibles i386, des Alphas, des Mips, etc. Logiciels. En termes d'installation logicielle, les ordinateurs peuvent avoir différents systèmes d'- exploitation avec une version précise (AIX 5.3, IRIX 6.5, Solaris 9, Linux 2.6.10, Windows XP, Ubuntu, Debian, Windows Vista etc.). Les logiciels disponibles ainsi que leurs versions peuvent également être différents et installés à des endroits variés (compilateurs, bibliothèques de calcul, etc.). Réseaux. En termes de réseaux d'interconnexion entre les ordinateurs, les liens de communication peuvent avoir des débits, latences, gigues, taux de pertes différents. Les avantages clés pour les grappes de type Beowulf sont la haute performance pour un prix bas, le passage à l'échelle et l'ajustement rapide aux avancées technologiques. C'est ce genre d'architecture que nous avons adopté dans le cadre de notre travail. 3.2 Caractéristiques des grappes Cette section présente quelques caractéristiques importantes des grappes de calcul que nous devrons prendre en considération pour l'ordonnancement des tâches de notre application parallèle le partage des ressources, l'hétérogénéité des ressources et des politiques d'administration, la sécurité et la tolérance aux fautes. 3.2.1 Accès aux ressources Dans une grappe le partage et l'accès aux informations du système se font de manière transparente à l'utilisateur. Une information présente sur un noeud A peut être accessible sur un noeud B (Comme exemples, un utilisateur enregistré sur le noeud A peut se logger sur le noeud B sans toute fois être enregistré sur ce dernier. Egalement une donnée enregistrée sur le noeud A peut être utilisée par un utilisateur du noeud B. Toutes ces opérations se font de façon transparente aux utilisateurs de la grappe). '3il est parfaitement adapté aux calculs parallèles, stable, efficace et libre (gratuité et code source disponible). Les mises à jour ne posent aucun problème technique ou financier. '4Applications nécessitant de gros calculs mais peu de communications 3.2.2 Sécurité Une grappe est constituée d'utilisateurs qui se font une confiance limitée. De plus, la mise en place d'une grappe doit respecter (et non infléchir) les politiques d'accès aux ressources de chaque ressource. Ainsi, la sécurité et ses mécanismes de mise en oeuvre sont des problématiques cruciales des grappes. La sécurité concerne l'authentification mutuelle des utilisateurs et des ressources : ces mécanismes consistent à prouver qu'un utilisateur est bien qui il prétend être, et qu'une ressource est effectivement ce qu'elle prétend être (service d'information, serveur d'exécution, etc.). La sécurité concerne également les questions d'autorisation définies au paragraphe précédent, et le chiffrement des données. Le chiffrement sert non seulement pour les informations en transit sur les liens de communication, mais aussi pour celles qui sont stockées dans les mémoires et les disques. Il évite la lecture des données secrètes et protège leur intégrité en empêchant leur modification sans autorisation. Enfin, la sécurité peut impliquer la nécessité de comptabiliser les accès (en nombre et en durée) des utilisateurs aux ressources (accounting). 3.2.3 Tolérances aux fautes Les défaillances matérielles et logicielles font partie intégrante des grappes : lien réseau coupé, ordinateur qui tombe en panne, programme non conforme aux spécifications, etc. Pour pallier à cela, les méthodes comme le checkpointing, la migration des processus sont implémentées. Les politiques d'accès aux ressources. Chaque grappe décide de façon autonome et indépendante des politiques : - d'authentification, en sélectionnant une ou plusieurs méthodes de connexion (NIS, telnet, SSH, etc.) et éventuellement des algorithmes de chiffrement des communications; - d'autorisation d'accès aux ressources, afin de déterminer quels utilisateurs possèdent quels droits (lecture, écriture, effacement) sur chaque ensemble de données; - d'attribution des noms d'utilisateurs. 3.3 Infrastructures matérielles des grappes Dans la section précédente, nous avons défini les grappes de façon générale, et relativement abstraite. Cette section présente quelques infrastructures matérielles typiques des grappes. 3.3.1 Architectures matérielles des grappes De quoi une grappe est-elle constituée? Une grappe se compose d'un ensemble de noeuds reliés par des liens réseau comme l'illustrent les deux paragraphes suivants. Noeud de calcul et stockage Les noeuds d'une grille de calcul sont ses moyens de stockage de données informatiques, ses moyens de calcul, des dispositifs de visualisation (écrans de réalité virtuelle immersive). Les noeuds peuvent aussi désigner des instruments de mesure ou des capteurs, tels que des télescopes, des senseurs météorologiques, mais on rencontre plus rarement ce type de ressource dans les grappes de calcul génériques qui sont déployées de nos jours. Parmi les moyens de calcul, on trouve le plus souvent des ordinateurs de bureau (PCs), des stations de travail, des serveurs d'exécution, des supercalculateurs (calculateurs parallèles à mémoire partagée tels que des SGI Origin 3000 [1] ou des SMP, calculateurs vectoriels tels que des Cray XT3 [31]), ainsi que dans une moindre mesure, des PDA et des ordinateurs portables. Réseau de communication Les noeuds d'une grappe de calcul, quelle que soit leur nature, doivent être interconnectés par un réseau de communication pour coopérer en échangeant des données. Les liens réseau font partie à part entière des ressources informatiques d'une grappe de calcul. Les noeuds peuvent être reliés par des réseaux locaux (Local Area Network, LAN), de type FastEthernet (débit 100 Mb/s, latence de l'ordre de 90 s) ou Gigabit Ethernet (débit 1 Gb/s), ou bien encore par des réseaux sans fil (débit 54 Mb/s par exemple). Les noeuds d'un cluster peuvent être interconnectés par un réseau haute performance (System Area Network, SAN) tel que Myrinet [20, 21] (débit 2 Gb/s, latence de l'ordre de la microseconde), Quadrics [24](débit plus de 6 Gb/s, latence de l'ordre de la microseconde), ou InfiniBand [16]. 3.4 Infrastructures logicielles des grappes Comme nous venons de le voir dans la section précédente, les ressources d'une grappe sont hétérogènes (du point de vue du matériel, comme des politiques d'administration), très nombreuses, et elles nécessitent des garanties en matière de sécurité. Les grappes sont donc des environnements particulièrement complexes. L'intergiciel. Une des clés du succès des grappes est la suite logicielle qui facilite l'accès à leurs diverses ressources de manière sécurisée. Cette section définit les rôles d'une telle suite logicielle. Pour approcher l'objectif de transparence d'utilisation des grappes, on ne peut pas laisser un utilisateur qui voudrait lancer son application seul face aux ressources matérielles brutes de la grappe. Entre - l'application qui fait un calcul utile , - et les multiples systèmes d'exploitation et politiques d'accès des ressources des grappes, se trouve un < intergiciel d'accès aux ressources de la grappe >. Le rôle de cet intergiciel est de faciliter l'utilisation de la grappe, en donnant une vision plus uniforme et intégrée de ses ressources hétérogènes, et en assurant la sécurité des données et des communications. Les langages de programmation. Les langages de programmation nécessaire pour les traitements à faire devront être installés. Typiquement, on peut avoir des langages mathématiques pour le calcul scientifique etc.. Les serveurs. Les grappes sont dotées des services d'information sur les utilisateurs du système et de sécurité. Les serveurs de partage de fichiers est également présent pour distribuer des fichiers de manière transparente à l'utilisateur. Les grappes de PCs constituent une architecture en plein essor et qu'il faut considérer par conséquent. Elles sont dotées de caractéristiques qui rend son fonctionnement et son utilisation simple vis à vis de l'utilisateur. Pourtant le comportement hétérogène les rend très difficile à manipuler lorsqu'on y fait de la programmation parallèle tant sur le plan du choix du bon placement que de l'analyse de leur performances. Certains postulats révèlent que les performances d'une architecture parallèle sont indépendantes du nombre de processeurs existants tandis que d'autres révèlent le contraire. 4 Analyse des performances d'une architecture multiprocesseurs Dans les sections précédentes , nous avons introduit les concepts fondamentaux liés aux systèmes multiprocesseurs. Dans cette section, nous allons aborder les notions sur l'analyse des mesures des performances des architectures parallèles. Nous allons commencer par introduire le concept des modèles de calcul liés aux multiprocesseurs. Deux modèles seront étudiés : Le modèle de calcul parallèle avec des parties séquentielles et le modèle de processus à durée égale. En étudiant ces modèles, on discutera de deux mesures qui sont : l'accélération et l'efficacité. Par la suite, des lois seront présentées pour mesurer les performances d'une architecture multiprocesseur. 4.1 Modèles de Calcul On supposera qu'une application est divisée en tâches concurrentes15 pour l'exécution sur les différents processeurs. Partant de là, deux modèles de calcul seront décrits. 4.1.1 Modèle à durée égale Dans ce modèle [14], on suppose qu'une application peut être divisée en n tâches égales, chacune pouvant être exécutée par un processeur. Si ts est le temps d'exécution de l'application en utilisant un seul processeur, alors le temps pris par chaque processeur pour exécuter sa tâche est tm = ts n . comme dans ce modèle, tous les processeurs exécutent leurs tâches simultanément, alors le temps pris pour exécuter l'application est tm = ts n . Le facteur accélération du système parallèle peut être défini comme le rapport entre le temps pris par un seul processeur pour résoudre le problème et le temps pris par le système constitué de n processeurs pour résoudre le même problème. ts ts S(n) = facteur d'accélération = = = n ts tm n L'équation indique que, selon le modèle à durée égale, le facteur accélération résultant de l'utilisation de n processeurs est égal au nombre de processeurs utilisé, n. Un facteur important a été omis dans les relations ci-haut. Ce facteur est le surcoût des communications qui résulte du temps nécessaire aux processeurs pour communiquer et échanger les données en exécutant leurs tâches respectives. Considérons que le temps induit par le surcoût des communications est tc, alors le temps pris par chaque processeur pour exécuter sa tâche est donné par tm = ts n + tc.
L'équation ci-dessus indique que les valeurs relatives de ts et tc affectent l'accélération. Si on essaie d'étudier certains cas : (1) si tc << ts alors le facteur accélération est approximativement égal à n; (2) si tc >> ts alors le potentiel accélération est ts tc << 1; (3)sitc = ts alors le potentiel accélération est n n+1 1, pour n >> 1. Dans l'optique de faire varier le facteur accélération entre 0 et 1, on le divise par le nombre de processeurs, n. La mesure résultante est appelée efficacité, . L'efficacité est une mesure de l'accélération par processeur. Selon ce modèle, l'efficacité est égale à 1 si le surcoût dû aux communications est 15tâches qui se communiquent les données ignoré. Cependant si le surcoût dû aux communications est pris en compte, l'expression de l'efficacité est la suivante : î= 1 1+ tc ts Bien que simple, le modèle de durée égale n'est pas réaliste. Cela parcequ'il est basé sur le fait qu'une application peut être divisée en tâches égales qui peuvent être exécutées par des processeurs. Cependant, il est important ici d'indiquer que les algorithmes réels contiennent des parties séquentielles qui ne peuvent pas être divisées entre les processeurs. Ces parties séquentielles doivent être exécutées sur un seul processeur. Considérons, par exemple, les segments de programme donnés dans la figure I.11. Dans ces segments de programme, on suppose qu'on commence avec une valeur de l'un des deux vecteurs a et b stockés dans un des n processeurs disponibles. Le premier bloc de programme (encadré dans un carré) peut être résolu en parallèle; C'est à dire que chaque processeur peut calculer un élément du tableau c. Les éléments du tableau c sont distribués entre les processeurs et chaque processeur a un élément. Le prochain segment de programme ne peut pas être exécuté en parallèle. Ce bloc aura besoin que les éléments du tableau c soient envoyés à un processeur et additionnés sur ce processeur. Le dernier segment de programme peut être résolu en parallèle. Chaque processeur peut mettre à jour ses éléments de a et b. Cet exemple illustratif montre qu'un modèle de calcul réaliste devrait
Figure I.11 - Segments de programme assumer l'existence de parties séquentielles dans un programme qui ne peuvent être divisées. Cela est la base du modèle suivant. 4.1.2 Modèle de calcul parallèle avec des parties séquentielles Dans ce modèle de calcul[14], une fraction f d'un programme donné est séquentielle. La partie restante (1-f ) elle est parallélisable. Les dérivations similaires effectuées dans le modèle à durée égale vont résulter comme suit. Le temps nécessaire pour exécuter le programme sur n processeurs est tm = fts + (1 - f)(ts n ) . Le facteur accélération est par conséquent donné par:
Selon cette équation, l'accélération due à l'accélération des n processeurs est déterminée primairement par la fraction de code non parallélisable. Si le programme est complètement séquentiel, c'est à dire, f =1, alors aucune accélération ne sera atteinte peu importe le nombre de processeurs utilisés. Ce principe est la loi d'Amdahl.C'est intéressant de noter que selon cette loi le facteur accélération maximal est donné par: lim n-400 1 S(n) = f Par conséquent, selon la loi d'Amdahl l'amélioration de la performance(vitesse) de l'algorithme parallèle par rapport à l'algorithme séquentielle n'est pas limitée par le nombre de processeurs mais plutôt par la partie de l'algorithme qui ne peut pas être paralléliser. A première vue, la loi d'Amdahl indiques que peu importe le nombre de processeurs utilisé, il existe une limite intrinsèque sur l'utilité des architectures parallèles utilisées. Souvent et selon la loi d'Amdahl, les chercheurs étaient amenés à penser qu'une substantielle croissante du facteur d'accélération ne serait pas possible en utilisant les architectures parallèles. On discutera de la validité de cela et d'un postulat similaire dans la section suivante. Cependant, montrons l'effet du surcoût dû aux communications sur le facteur d'accélération sachant qu'une fraction f du programme n'est pas parallélisable. Comme on l'a mentionné depuis le début, le surcoût dû aux communications devrait être inclus dans le temps de traitement. Considérons le temps induit par le surcoût des communications, l'accélération est donnée par:
Le facteur d'accélération maximum dans ces conditions est donné par:
La formule ci-dessous indique que le facteur d'accélération n'est pas déterminé par le nombre de processeurs parallèles utilisés mais par la fraction du programme qui n'est pas parallélisable et par le surcoût des communications. Ayant considéré le facteur d'accélération, calculons maintenant la mesure d'efficacité. On sait que l'efficacité est le ratio entre le facteur d'accélération et le nombre de processeurs n. L'efficacité peut être calculée ainsi : î(sans surcoût de communications) = 1 1+(n-1)f 1 î(avec surcoût de communications) = 1+(n-1)f+n tc ts Comme dernière observation, il est a noté que dans une architecture parallèle, les processeurs maintiennent un certain niveau d'efficacité. Cependant, comme le nombre de processeurs augmente, il devient difficile de les utiliser efficacement. En vue de maintenir un certain niveau d'efficacité de processeur, il devrait exister une relation entre la fraction séquentielle du programme, f, et le nombre de processeurs employés. Après avoir introduit les deux modèles de calcul ci-haut, nous présenterons des lois de performance qui ont des hypothèses sur le gain potentiel des architectures parallèles. Parmi ces lois on a celle d'Amdahl, de Gustafson-Brasis. 4.2 Un argument pour les architectures parallèles Dans cette section, on introduit un nombre de lois nécessaires pour exprimer l'utilité des architectures parallèles. 4.2.1 Loi d'Amdahl Nous avons défini précédemment l'accélération d'un système parallèle comme le ratio entre le temps pris par un seul processeur pour résoudre le problème divisé par le temps pris par le système parallèle constitué de n processeurs pour résoudre le même problème. ts S(n) = fts + (1 - f)(ts n )
Une observation intéressante à faire ici est que selon la loi d'Amdahl[3], f est fixé et n'augmente pas avec la taille du problème, n. Cependant, il a été pratiquement observé que certains algorithmes parallèles réels ont une fraction f qui est une fonction de n. Supposons que f est une fonction de n telle que lim f(n)=0. Alors
Ceci est une contradiction à la loi d'Amdahl. Cette loi stipule donc qu'une application parallèle peut se décomposer en une partie parallélisable et une partie non parallélisable. Le temps d'exécution de la partie parallélisable est inversement proportionnel aux nombre de processeurs tandis que le temps d'exécution de la partie non parallélisable ne varie pas quelque soit le nombre de processeurs disponibles (elle ne s'exécute que sur un processeur). On peut remarquer que ce modèle ne tient pas explicitement compte d'éventuels coûts de communications entre les processeurs. Ce modèle est donc plutôt adapté aux tâches pour lesquelles les communications internes sont négligeables ou celles dont les calculs recouvrent totalement les communications. Ce modèle est illustré à la figure I-12. On voit effectivement qu'avec plusieurs noeuds pour le calcul, le temps parallèle peut tendre vers zéro mais le temps séquentiel ne change pas.
Figure I.12 - Modèle Amdahl 4.2.2 Loi de gustafson En 1988, Gustafson and Barsis dans les laboratoires Sandia ont étudié le paradoxe crée par la loi d'Amdahl et le fait que les architectures parallèles constituées de centaines de processeurs étaient construites avec amélioration de performances. En introduisant leur loi, Gustafson a reconnu que la fraction non parallélisable d'un algorithme peut ne pas être connue à priori. Ils affirment qu'en pratique, la taille du problème augmente avec le nombre de processeurs, n. Ceci contredit la base de la loi d'Amdahl qui stipule que le temps d'exécution de la partie parallélisable d'un programme, (1-f ), est indépendant du nombre de processeurs, n. Gustafson et Brasis ont postulé que lorsqu'on utilise un processeur plus puissant, le problème tend à utiliser plus de ressources. Ils ont trouvé que la partie parallèle du programme croît avec la taille du problème. Ils ont postulé que si s et p représentent respectivement le temps d'exécution de la partie séquentielle et de la partie parallèle, alors s + p * n représente le temps requis par un processeur séquentiel pour exécuter le programme. Ils ont ainsi introduit un nouvel facteur, appelé scaled sppedup factor, SS(n), qui peut être calculé ainsi : s + pn SS(n) = = s + p * n = s + (1 - s) * n = n + (1 -- n) * s s + p Cette équation montre qu'on peut atteindre une performance parallèle efficace contrairement à l'accélération d'Amdahl. L'accélération devrait être mesurée en augmentant le nombre de processeurs pas en fixant la taille du problème L'accélération et l'efficacité sont deux facteurs pour mesurer les performances sur une architecture parallèle. Mais ils ne tiennent pas compte de l'architecture du réseau d'interconnexion pourtant un facteur important à prendre en compte pour pouvoir effectuer un bon ordonnancement des tâches composantes d'une application parallèle. |
|