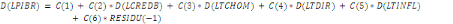Crédits bancaires et croissance économique en république démocratique du congo, de 1990 à 2019par Guillaume gigi Mbode Universite de kindu - Licence 2021 |

1.3. Méthode d'estimationL'identification des facteurs fondamentaux susceptibles d'influencer la croissance économique en RD Congo procède de l'estimation économétrique du modèle à correction d'erreur, l'algorithme d'Engel et Granger. La méthode d'estimation est celle des moindres carrés ordinaires (MCO). Par la suite, une batterie de tests statistiques (27(*)) permet de valider le modèle aux fins de son utilisation. Ces tests portent, tour à tour, sur la significativité des paramètres estimés et sur celle du modèle global. Ils portent également sur la vérification des hypothèses stochastiques (normalité, non corrélation et homoscédasticité des erreurs) ainsi que sur la stabilité du modèle. 1.4. Estimation du modèle spécifiéL'analyse de la stationnarité est un préalable indispensable à toute économétrie des séries temporelles. La stationnarisation (en moyenne) d'une série chronologique précède donc toute estimation. Mais avant d'y arriver, il nous est important de présenter le modèle de cointégration ou de long terme. Les résultats consignés dans les annexes B, en page D, tableau n°12 renseignent sur l'estimation du modèle mesurant la relation de long terme entre les variables exogènes et celle endogène. Stationnarisation des variables Tableau n°2 : Stationnarité des variables (Test ADF)
Source : auteur (sur base des éléments des tableaux 1 à 11, en page A à D, de l'annexe A).
Source : auteur (sur base des éléments des tableaux 1 à 11, en page A à D, de l'annexe A). Le tableau 2 reprend des résultats des tests ADF qui s'y rapportent. Les modèles 1, 2 et 3 représentent respectivement le modèle avec tendance et dérive, le modèle avec dérive et sans trend ainsi que le modèle sans tendance ni dérive. Aussi, il apparaît à travers le tableau 1 à 11, en page A à C, de l'annexe A que toutes les variables suivent des lois normales ou lognormales sur la période allant de 1990 à 2019. Les séries LCREDB, LPIBR, LCHOM, LTDIR et LTINFL ont été passées au filtre logarithme. (28(*)). Seule la variable EXPORTNET n'y a pas été car contenant des valeurs négatives. A l'issue de ces résultats susmentionnés, toutes les variables sont stationnaires. A l'exception de la dernière non filtrée en logarithme, d'autres variables sont des processus DS et ont été différenciée d'ordre 1 pour être stationnaires. La variable exportations nettes a suivi le processus TS au cours de sa stationnaisation. Tableau n°3 : Test de stationnarité des résidus
L'algorithme de représentation d'Engel et Granger conditionne pour être d'application que les résidus issus de la relation de long terme soit stationnaire à niveau. Ainsi, ce tableau indique que les résidus issus de la relation de long terme étant stationnaires à niveau et les variables intégrées de même ordre. Donc, l'utilisation de l'algorithme d'Engel et Granger est possible. L'estimation du modèle de court terme préconisé est alors envisageable. De la sorte, tout risque d'une hypothèse de régression fallacieuse est écarté. Les résultats de l'estimation sont contenus au tableau 12, en page D, de l'annexe B. Les données couvrent la période 1990-2019. L'estimation procède du logiciel EViews (version 10). Le modèle à estimer prend la forme générale définitive suivante ci-après (29(*)) :
Le tableau 4 synthétise les résultats des estimations du modèle de court terme spécifié. Voir tableau 12, annexe B, page D. Tableau 4 : Résultats du modèle spécifié retenu
Après substitution des valeurs des coefficients estimés, le modèle peut alors s'écrire :
Il convient de préciser que les coefficients associés aux variables filtrées en logarithme mesurent une élasticité. Le coefficient du terme résiduel retardé est significativement négatif. Il existe de ce fait un mécanisme de retour à l'équilibre de long terme, tout décalage entre la valeur de court terme et la cible de long terme se résorbe endéans 4mois et 7 jours environ.
Le terme indépendant est statistiquement non significatif. Les variables qui entrent dans le modèle suffisent donc pour expliquer le phénomène sous-étude. La significativité statistique des variables D(LCREDB), D(LTDIR) et D(LTCHOM) est nulle. Donc, Les paramètres de ces variables sont significativement statistiquement nuls. Elles n'exercent pas une influence statistiquement et significativement sur la croissance économique. Cependant, leurs signes respectifs ne sont pas conformes à ceux qui résultent des littératures empirique et théorique revues, à l'exception de la variable D(LCREDB) dont le coefficient est précédé d'un signe moins. La significativité statistique de la variable taux d'inflation est non nulle, donc le coefficient est statistiquement et significativement différent de zéro.
Le modèle estimé est globalement statistiquement significatif. Il explique 81,99 % des variations de la croissance économique en RD Congo. Le modèle étant prévisionnel, le taux de 81,99 %, étant supérieur 2/3, soit 67% requis pour le coefficient de détermination corrigé n'est pas contraignant. * 27 5 % est le seuil de significativité retenu pour les tests statistiques. Pratiquement, hormis les tests t de Student, ADF de Duckey-Fuller et F de Fischer, la règle de décision de tous les autres tests usités dans cette monographie veut qu'on accepte (rejette) l'hypothèse nulle dès que la probabilité critique est supérieure (inférieure) à 0,05. * 28 Les séries brutes sont transformées par passage au filtre logarithme. La variable Exportations nettes ne s'y prête pas. Elle contient un nombre négatif. * 29Initialement, le modèle a compté toutes les variables et leurs transformées préalablement rendues stationnaires, mais il s'est fait observer que la variable Exportations nettes n'a pas été différenciée pour être stationnaire, raison pour laquelle elle n'apparait pas dans le modèle de court terme validé. Le choix du meilleur modèle (dont les variables sont les plus corrélées avec la variable à expliquer et les moins corrélées entre elles) a procédé de la régression par étage. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||