Chapitre II : Conception et mise en place de notre
entrepôt de données
2.1. Le cycle de développement
La conduite d'un projet informatique, tel que le
développement d'un système d'information, fait appel à des
méthodes formalisées dont les principales sont : Les
méthodes séquentielles dites en cascade et les méthodes
itératives (évolutive, objet).
Depuis des décennies, les projets sont
gérés avec une approche classique, le plus fréquemment
« en cascade » ou son adaptation « en V », basée sur
des activités séquentielles : on recueille les besoins, on
définit le produit, puis on le développe, ensuite on le test
avant de le livrer au client.
Vu que les besoins évoluent en permanence pour
répondre aux changements du marché, ces approches
prédictives se sont révélées trop « rigides
»parfois, sont alors apparues, dans les années 1990, des
méthodes moins prédictives ; ce sont les méthodes dites
« agiles».
Après une étude exploratoire des méthodes
de conduite de projet et pour répondre aux objectifs fixés en
début, le cycle de développement en « V » s'est
révélé le plus approprié pour ce travail.
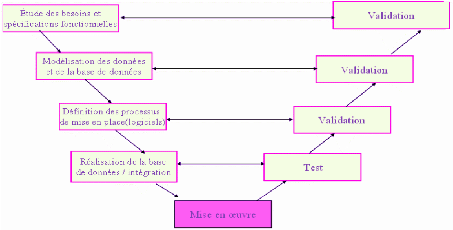
Le model en « V » a été imaginé
suite au problème de réactivité du model en cascade. Il
permet en cas d'anomalie de limiter le retour aux étapes
précédentes.
Les phases de la partie montantes doivent renvoyer de
l'information sur les phases en vis -à-vis lorsque des défauts
afin d'améliorer le logiciel.
Ndioba Syll et Abdrahmane Aw Page27
Figure 10 : Processus de développement du projet
tiré du modèle en « V »
2.2. Choix du modèle multidimensionnel
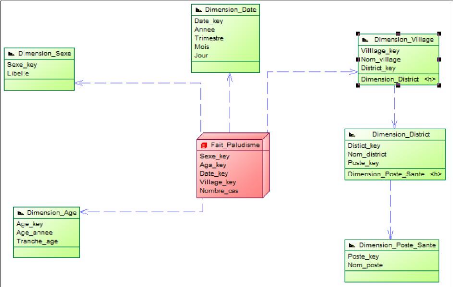
Notre choix c'est porté sur le modèle en flacon
de neige car simple à alimenter, celui-ci permet une bonne
lisibilité et une bonne performance des requêtes. Il sera
constitué de tables de dimensions, et d'une table de fait. La table de
fait contiendra des données normalement numériques, puisque
d'ordre quantitatif.
Il s'agira des clés primaires de chaque table de
dimension et des mesures (nombre de personne infecté qui sera
analysé en fonction de chaque dimension). En effet les dimensions
citées précédemment nous serviront d'axes d'analyses pour
les faits enregistrés.
Ndioba Syll et Abdrahmane Aw Page28
Figure 11 : Représentation du modèle en
flacon de neige « pour l'indicateur Paludisme »
2.3. Processus ETL
L'intégration des données est une étape
clé dans la mise en oeuvre de ce projet. En effet, l'objectif de cette
partie est de mener une réflexion sur des solutions et outils afin
alimenter les tables de la base de données. Parmi ces outils, on notera
les ETL (Extract, Transform, Load).
2.3.1. Définition d'un outil ETL
Un ETL est une boite à outil (pro-logiciel) qui permet
ainsi l'Extraction, la Transformation et le chargement (Load) de données
depuis des sources diverses(bases de données, fichiers ,...) vers des
cibles préalablement définies. Les ETL sont communément
utilisés dans l'informatique décisionnelle afin de permettre
l'alimentation des datawarehouses (entrepôts de données).
De nombreux systèmes de gestion de bases de
données sont supportés nativement en lecture/écriture
(Oracle, MSQL Server, DB2, MYSQL,...).De nombreux types de fichiers peuvent
également être lus ou écrits: Csv, Excel, Txt, XML, ...
Ndioba Syll et Abdrahmane Aw Page29
Notons que la plupart des ETL disposent d'une interface graphique
permettant l'élaboration des différents scénarios
d'intégration.
Le travail des développeurs en est ainsi grandement
facilité, tant au niveau de la conception que de la maintenance des
traitements de données.
| 

