PARTIE II :
PRESENTATION DE LA HAUTE DISPONIBILITE, ANALYSE COMPARATIVE ET PROPOSITION
D'UNE SOLUTION SATISFAISANTE ET COMPATIBLE AUX SERVICES DE CREOLINK.
Chapitre I: HAUTE DISPONIBILITE : CONCEPT ET
PRINCIPE
Chapitre II: SYNTHESE ET FUTUR
Chapitre III: CAS PRATIQUE : DEPLOIEMENT DES SERVICES ET
MISE EN HAUTE DISPONIBILITE
CHAPITRE I: HAUTE
DISPONIBILITE : CONCEPT ET PRINCIPE
Introduction
Toutes les techniques permettant de venir à bout des
désagréments causés par une indisponibilité
temporaire ou permanente sont regroupées sous différentes
appellations suivant le degré de la réponse qu'elles apportent au
problème posé :
Ø Disponibilité des services
Dans le contexte d'un service critique rendu dans le cadre
d'une entreprise (serveur) ou vis-à-vis d'une clientèle (site
marchand), une panne occasionnant un arrêt du service peut causer un tort
considérable entraînant une perte de productivité, voire de
confiance du client. Dans tous les cas, cela peut coûter à court
ou moyen terme beaucoup d'argent. On base la démarche sur la
disponibilité des données pour ensuite fiabiliser par
différentes techniques la continuité du service ;
Ø Disponibilité des
données
Même si votre système n'est
pas critique et peut supporter un arrêt de service à durée
variable, il est généralement inhabituel de se satisfaire de la
perte de données. Dans ce cas précis, toutes les techniques
utilisées convergent pour garantir l'intégrité des
données ;
Ce document va s'attacher à décrire les
principes fondamentaux qui régissent l'étude et le
développement de systèmes critiques Hautement Disponibles
(résumé sous l'acronyme HA pour High Availability)
Nous verrons d'abord de façon succincte comment nous
pouvons aborder le problème d'un point de vue théorique pour
ensuite élaborer une architecture hautement disponible à partir
de différents composants logiciels choisis dans une liste non
exhaustive. Dans cette partie précise, les briques logicielles que nous
utiliserons sont pour la plupart basées sur les logiciels libres :
la tentation est donc forte de vouloir mettre en oeuvre soi même, et
à peu de frais, des solutions de ce type au sein d'une entreprise.
I.1 FIABILITE
VERSUS DISPONIBILITE
Pour appréhender la notion de Haute
Disponibilité, il nous faut d'abord aborder les différences qui
existent entre la fiabilité d'un système et sa
disponibilité.
La fiabilité est un attribut permettant de mesurer la
continuité d'un service en l'absence de panne. Les constructeurs
fournissent généralement une estimation statistique de cette
valeur pour leurs équipements : On parle alors de MTBF (pour Mean Time
Between Failure). Un MTBF fort donne une indication précieuse sur la
capacité d'un composant à ne pas tomber en panne trop souvent.
Dans le cas d'un système complexe (que l'on peut décomposer en un
certain nombre de composants matériels ou logiciels), on va alors parler
de MTTF pour Mean Time To Failure, soit le temps moyen passé
jusqu'à l'arrêt de service consécutif à la panne
d'un composant ou d'un logiciel.
La disponibilité en ce qui la concerne, est plus
difficile à calculer car englobant la capacité du système
complexe à réagir correctement en cas de panne pour
redémarrer le service le plus rapidement possible. Il est alors
nécessaire de quantifier l'intervalle moyen de temps ou le service est
indisponible avant son rétablissement : On utilise l'acronyme MTTR (Mean
Time To Repair) pour représenter cette valeur. La formule qui permet de
calculer le taux de disponibilité relative à un système
est la suivante :
Disponibilité =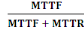

Ainsi, un système qui aspire à une forte
disponibilité se doit d'avoir soit un MTTF fort, soit un MTTR faible.
Une autre approche, plus pratique, consiste à mesurer
la période de temps ou le service n'est plus rendu pour évaluer
le niveau de disponibilité. C'est la méthode la plus souvent
utilisée même si elle ne tient pas compte de la fréquence
des pannes mais plutôt de leur durée. Le calcul se fait le plus
souvent sur une année calendaire. Plus le pourcentage de
disponibilité du service est fort, plus nous pouvons .parler de Haute
Disponibilité. Il est assez facile de qualifier le niveau de Haute
Disponibilité d'un service à partir de la durée
d'arrêt cumulée en utilisant le principe normalisé des "9"
(en dessous de 3 neuf, il n'est plus possible de parle de Haute
Disponibilité mais simplement de disponibilité) :
|
Nombre de 9
|
Arrêt du service sur un an
|
|
3 neufs (99,9%)
|
Environ 9heures
|
|
4 neufs (99,99%)
|
Environ 1heure
|
|
5 neufs (99,999%)
|
Environ 5minutes
|
|
6 neufs (99,9999%)
|
Environ 30secondes
|
I.1.1 CONDITION DE MISE EN PLACE
Une bonne démarche, permettant de mettre une oeuvre
assez rapidement une infrastructure solide capable de garantir la Haute
Disponibilité d'un service critique, consiste à évaluer
les différents objectifs suivants :
Ø Définition des critères
d'indisponibilité du service : Niveau de disponibilité, temps de
rétablissement ou encore temps d'engagement du service ;
Ø Analyse de la volumétrie des données et
des performances nécessaires au bon fonctionnement du service ;
Ø Prise en compte des différents critères
de coûts ;
Ø solution des configurations matérielles et
logicielles (si applicable) ;
Ø Surveillance du service et planification de la
maintenance corrective et préventive (qui, quand, comment).
A ce stade de l'étude, on a une idée bien
précise du type d'architecture qu'il est nécessaire de mettre en
oeuvre pour répondre au besoin posé. L'étape suivante
consiste à évaluer les différentes architectures possibles
et à sélectionnez celle qui semble répondre le mieux aux
différentes contraintes. En effet, identifier les faiblesses d'un
système informatique est la première étape permettant de
fiabiliser son fonctionnement et d'initier une réflexion sur les moyens
qu'il sera possible de mettre en oeuvre pour garantir la continuité du
service, et donc la Haute Disponibilité.
| 

