Conception et mise en oeuvre d'un SIG pour le suivi des investissements publics au Cameroun( Télécharger le fichier original )par Bakary ABDOULAYE Ecole Nationale Supérieure Polytechnique de Yaoundé - Ingénieur de conception en informatique 2009 |

CHAPITRE II. CONCEPTSTHÉORIQUES Ce chapitre présente l'état de l'art dans le domaine des sy st4mes d'information géographiques. Nous évoquerons dans un premier temps les généralités sur les SIG d'une part et d'autre part les techniques de diffusion des cartes via un réseau informatique. Par la suite nous présenterons les concepts de Data Mining et de Text Mining utilisés pour aider à la décision. II.1. Les systèmes d'information géographiques Un système d'information géographique (SIG) est un système informatique qui permet à partir de diverses sources, de rassembler, d'organiser, de gérer, d'analyser, de combiner et de représenter des informations localisées géographiquement, contribuant notamment à la gestion de l'espace. II.1.1 Généralités Un système d'information géographique peut être considéré comme :
Un outil informatique permettant d'effectuer des tk~ches diverses, sur des données à référence spatiale. Un ensemble informatique constitué de logiciels, de matériels et de méthodes destinés à assurer la saisie, l'exploitation, l'analyse, et la représentation de données géo référencées pour résoudre un problème de planification et de management. Un « ensemble de données repérées dans l'espace, structurées de façon à fournir et extraire commodément des synthèses utiles à la décision » Un « ensemble organisé globalement comprenant des éléments (données, équipements, procédures, ressources humaines) qui se coordonnent, à partir d'une référence spatiale commune, pour concourir à un résultat. » Un système de gestion de bases de données pour la saisie, le stockage, l'extraction, l'interrogation, l'analyse, et l'affichage des données localisées. Un SIG traite d'informations localisées et ainsi apporte une dimension géométrique aux systèmes d'information classiques (géométrie + sémantique). C'est donc un outil de gestion pour l'utilisateur et un outil d'aide à la décision pour le décideur. II.1.2 Les fonctionnalités des SIG Un Système d'informations géographique comporte les cinq groupes de fonctionnalités suivantes dénommées « les cinq A » :
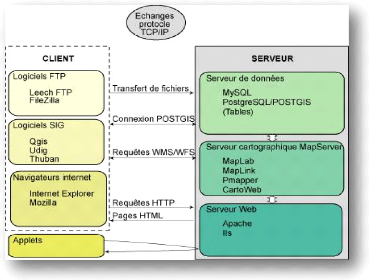
Affichage Analyse Acquisition Abstraction Archivage Figure 1 : Les fonctionnalités d'un SIG II.2. La cartographie sur internet : le Webmapping II.2.1 Généralités Le Webmapping, ou diffusion de cartes via le réseau internet, est un domaine en pleine expansion grâce au développement des solutions Open Sources. La cartographie en ligne répond à de réels besoins de diffusion rapide de l'information et de mise à jour à distance des données. Bien que le résultat cartographique permette de faciliter la compréhension de l'espace environnant, la mise en oeuvre de telles plateformes demande des compétences transversales à la fois en informatique et en géographie. La cartographie désigne la technique de réalisation des cartes et l'étude de celles-ci. Elle constitue l'un des moyens privilégiés pour l'analyse et la communication en géographie. Elle sert à mieux comprendre l'espace, les territoires et les paysages. Le terme Webmapping défini à la fois le processus de distribution de cartes via un réseau tel que l'Internet, l'Intranet ou l'extranet et leur visualisation dans un navigateur. On l'appelle aussi SIG web. II.2.2 Principe du Webmapping Le Webmapping utilise comme support de communication un réseau. Celui-ci utilise le protocole de communication TCP/IP qui permet à des ordinateurs connectés d'échanger de l'information. L'architecture dans le cadre du Webmapping est de type client-serveur. L'utilisateur sur sa machine locale effectue des requêtes pour demander une carte spécifique; le serveur cartographique interprète cette requête et renvoie la carte sous la forme d'une image matricielle (gif, jpg, jpeg, png,...) ou vectorielle (svg, flash). La solution la plus répandue actuellement dans le domaine de la mise en ligne de données cartographiques, consiste à créer une image correspondant à la demande de l'utilisateur. Ce qui nécessite un serveur cartographique. Le serveur cartographique est géré par des langages de script qui lui permettent de charger dynamiquement une carte en réponse à la requête. L'ordinateur serveur peut chercher cette information soit dans ses propres ressources, soit sur des serveurs de données distants.
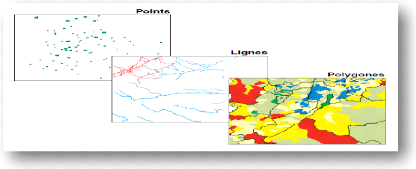
Figure 2: Principe des échanges entre un ordinateur client et un serveur Source : http://mappemonde.mgm.fr/num8/internet/int05401.html La consultation de l'information requiert l'existence d'un serveur web qui permettent aux serveurs de cartes d'accéder à l'intranet et/ou à l'internet. Il faut aussi rajouter des interpréteurs de scripts et éventuellement une visionneuse pour afficher la carte sur le navigateur du client. La visionneuse peut être un applet ou un servlet. II.3. Unités cartographiques II.3.1 Point Le point est un élément sans dimension. Sa localisation est donnée par ses coordonnées. Ce concept est référencé à des étiquettes (constituant la légende) qui permettent sa compréhension. II.3.2 Ligne ou segment La ligne ou segment est un élément à une dimension. Sa localisation est déterminée par les coordonnées des deux extrémités du segment. L'épaisseur du trait ou la forme du trait apporte une information supplémentaire sur sa signification thématique. II.3.3 Le polygone ou surface ou zone La surface ou zone est l'espace limité par une ligne fermée. Du point de vue cartographique, c'est un élément à deux dimensions. La localisation d'une surface s'exprime par les coordonnées de son centre de gravité, d'une référence interne ou des sommets du polygone qui forme ses limites. II.3.4 Modes de représentation Il s'agit ici du mode de représentation des données ci-dessus. Deux modes de représentations sont possibles : il s'agit des modes vectoriel et matriciel. II.3.4.1 Vectoriel Les objets sont représentés par des objets mathématiques élémentaires. Ce sont les points, les lignes et les polygones. Les SIG travaillent de façon privilégiée en mode vecteur. Ce mode ne repose pas sur la décomposition de l'image en cellules élémentaires, mais sur la décomposition de son contenu en traits caractéristiques et éléments principaux. [SANG2006]
Figure 3 : Exemple de données vectorielles II.3.4.2 Matriciel Il s'agit d'une image, d'un plan ou d'une photo numérisés et affichés dans le SIG en tant qu'image. Le mode matriciel est appelé ainsi parce que l'on découpe l'image à l'aide de grilles régulières ou encore matrice. Construite sur une partition régulière, souvent en carrés dits pixels, l'image est rendue par la vision globale des surfaces élémentaires juxtaposées, comme un écran d'ordinateur ou de télévision. Le mode raster est par exemple celui des informations reçues des satellites ou des cameras numériques. C'est aussi celui des informations obtenues par numérisation.
Figure 4 : Exemple de données raster Un système de coordonnées terrestres (sphérique ou projectif) permet de référencer les objets dans l'espace et de positionner l'ensemble des objets les uns par rapport aux autres. Les objets sont généralement organisés en couches, chaque couche rassemblant l'ensemble des objets homogènes (bâti, rivières, voirie, parcelles, etc.). II.4. Le Datamining II.4.1 Définition Le datamining ou fouille des données est l'ensemble des algorithmes et méthodes destinés à l'exploration de grandes bases de données des connaissances sous la forme de modèles de description afin de décrire le comportement actuel et /ou de prédire le comportement futur des données. Le datamining est la convergence de plusieurs disciplines : Base De Données, Statistique descriptive, Intelligence Artificielle et Analyse des données. [TUF2006] II.4.2 Méthodologie
Figure 5: Le datamining Les données dur lesquelles travaillent le datamining sont des données très importantes et sont le plus souvent stockées dans des entrepôts de données (Data Warehouse). Le principe du datamining est basé sur les modèles de description. Ce sont la classification des entités, l'attribution des scores de qualités, des règles et des analyses. La «fouille des données » met au point des typologies descriptives et des modèles afin de faciliter la prise de décision. Les choix sont alors faits en fonction des résultats du score et de la composition de certaines « niches » typologiques, critères statistiques (donc objectifs) et non plus, comme ce fut longtemps le cas, sur le « flair » et l'habitude d'un vieux routier du marketing. Le Datamining est un outil incontournable au sein des processus décisionnels d'une structure. [TUF2006] Les étapes sont : - La connaissance du contexte : intérioriser la problématique posée ; cerner les objectifs, connaître la signification de tel ou tel comportement - La connaissance des données : Que signifie telle ou telle grandeur ? Quelle est l'ordre de grandeur ? - La mise en forme des données : Créer des indicateurs synthétiques ; préparation des données ; coder ; normaliser ; enrichir - Modélisation : Choisir un type de modèle et une technique pour construire un modèle - Évaluation : Choix de la meilleure des solutions - La mise en production qui consiste à mettre en application les résultats proposés. Ces résultats positifs et négatifs permettront d'améliorer les futurs modèles.
Figure 6: Principes du Data Mining Source : Le DataMining , qu'est-ce que c'est et comment l'appréhender ? Olivier Decourt 10p II.5. Le Text Mining Le Text Mining représente l'ensemble des techniques permettant d'automatiser le traitement d'une masse importante de données textuelles non structurées, l'objectif étant d'extraire les principales tendances. De là, peuvent rtre répertoriés de manière statistique les différents sujets évoqués, afin d'adopter des stratégies plus pertinentes, résoudre des problèmes et saisir des opportunités commerciales. II.5.2 Principe Les règles de base que les outils de Text-mining se doivent de respecter dans leur traitement sont plus ou moins chronologiquement les suivantes : + D'abord le logiciel doit reconnaître les unités de la langue que sont les mots (tokenisation) + Ensuite il doit savoir interpréter et prendre en compte la ponctuation et la mise page (retour à la ligne, paragraphe, etc.) + Puis les formes lexicales et grammaticales, qui peuvent énormément varier selon que la langue est l'anglais, l'arabe ou le chinois. + Ensuite, il y a une phase de lemmatisation : elle consiste à identifier les différentes flexions d'un terme, ou déclinaisons d'un verbe. L'objectif de ce chapitre était la description sommaire des principaux concepts employés dans le cadre de ce projet. Le chapitre suivant fera une ébauche de solution sur l'architecture de l'application finale construite en présentant les outils. CHAPITRE III. PROPOSITION DE SOLUTION Les systèmes d'information de nos jours ont beaucoup gagné en complexité, les temps de développement cependant ne sont pas extensibles. Il faut dès lors privilégier l'approche métier, associer utilisateurs et informaticiens, optimiser les ressources et la technologie pour garantir les délais et le budget. Les méthodes répondent à ces exigences et permettent la construction d'applications fonctionnellement et techniquement conformes aux attentes des divers intervenants du projet. L'impératif est clair : plus vite, moins cher et de meilleure qualité. Le succès d'un projet dépend désormais de deux facteurs essentiels : l'implication des utilisateurs et une méthode garantissant la réussite du projet tout autant que la qualité de l'application. Les progrès du génie logiciel ont permis à plusieurs méthodes d'éP erJer. Dans les paragraphes suivants, nous allons décrire quelques-unes, les classifier et enfin choisir. III.1. Classification des méthodes d'analyse et de conceptionLes méthodes d'analyse et de conception peuvent être divisées en quatre grandes familles : III.1.1 Les méthodes cartésiennes ou fonctionnelles Le système étudié est abordé par les fonctions qu'il doit assurer plutôt que par les données qu'il doit gérer. Le processus de conception est vu comme un développement linéaire. Il y a décomposition systématique du domaine étudié en sous domaines, eux-mêmes décomposés en sous domaines jusqu'à un niveau considéré élémentaire. III.1.2 Les méthodes systémiques Le système est abordé à travers l'organisation des systèmes constituant l'entreprise. Elles aident donc à construire un système en donnant une représentation de tous les faits pertinents qui surviennent dans l'organisation en s'appuyant sur plusieurs modèles à des niveaux d'abstraction différents (conceptuel, organisationnel, logique, physique, etc.) III.1.3 Les méthodes objets L'approche objet permet d'appréhender un système en centrant l'analyse sur les données et les traitements à la fois. Les stratégies orientées objet considèrent que le système étudié est un ensemble d'objets coopérant pour réaliser les objectifs des utilisateurs. Les avantages qu'offre une méthode de modélisation objet par rapport aux autres méthodes sont la réduction de la « distance » entre le langage de l'utilisateur et le langage conceptuel, le regroupement de l'analyse des données et des traitements, la réutilisation des composants mis en place, maintenance aisée, gain en productivité, code plus lisible. III.1.4 Approche orientée aspect Bien qu'en étant encore à ses débuts, la Programmation Orientée Aspect commence à se faire connaître et séduit. C'est un principe novateur qui permet de résoudre les problèmes de séparation des préoccupations d'une application. Le code résultant devient plus lisible, réutilisable et le remplacement de composants se fait rapidement et à moindre coût du fait de la séparation des préoccupations. Cette séparation se fait par la création d'aspects contenant le code à greffer à l'application. Un programme appelé « tisseur » greffe ensuite les aspects de façon statique après la compilation, ou de façon dynamique au moment de l'exécution. III.2. Les méthodes de conduites de projet Elles sont diverses et variées. Nous allons dans la suite, présenter deux méthodes en rapport avec ce projet. III.2.1 RAD III.2.1.1 Définition La méthode RAD (Rapid Application Development) définie par James Martin au début des années 80 est une méthode de conduite des projets qui implique :
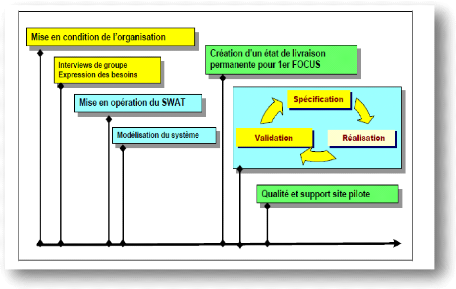
III.2.1.2 Description globale des phases La méthode RAD structure le cycle de vie du projet en 5 phases :
Figure 7 : Jalons décisifs du cycle RAD III.2.2 Le processus unifié : UP III.2.2.1 Définition Le processus unifié est un processus de développement logiciel itératif, centré sur l'architecture, piloté par des cas d'utilisation et orienté vers la diminution des risques. C'est un patron de processus pouvant être adaptée à une large classe de systèmes logiciels, à différents domaines d'application, à différents types d'entreprises et à différents niveaux de compétences. III.2.2.2 Les avantages d'UP
processus de développement sera donc axé sur l'utilisateur. Les cas d'utilisation permettent d'illustrer ces besoins. Ils détectent puis décrivent les besoins fonctionnels (du point de vue de l'utilisateur), et leur ensemble constitue le modèle de cas d'utilisation qui dicte les fonctionnalités complètes du système. III.3. UML [BOO00] UML est un langage de modélisation de données orienté objet basé sur l'utJlJsatJRn de neuf types de diagrammes regroupés en 02 familles de diagrammes :ce sont les diagrammes comportementaux et les diagrammes statiques. III.3.1 Les diagrammes statiques Ces diagrammes permettent de visualiser, spécifier, construire et documenter l'aspect statique ou structurel du système d'information. Il s'agit entre autre des diagrammes de cas d'utilisation, de classes, d'objets, mais aussi de déploiement et de composants. III.3.1 Diagrammes comportementaux (les vues dynamiques) Ils modélisent les aspects dynamiques du système, c'est-à-dire les différents éléments qui sont susceptibles de subir des modifications. Parmi eux on distingue, les diagrammes de séquence, de collaboration, d'états - transitions et d'activités.
Les diagrammes Les diagrammes Les diagrammes Aspects physiques Les diagrammes Aspects Le diagramme des Le diagramme des le diagramme Le diagramme de Le diagramme de Le diagramme de Le diagramme de Le diagramme Le diagramme Figure 9 : Les diagrammes UML III.4. Les systèmes de gestion de bases de données spatiales III.4.1 Définition Ce sont des systèmes de gestion de bases de données qui intègrent des composantes spatiales et qui offrent la capacité de stocker et de gérel.RI.Rl'IQRIPLIIRQ.RUplUILSKEqDe. Les plus connus sur le marché sont : - MySQL avec la cartouche MyGIS - Oracle avec cartouches spatiales Locator et Spatial - PostgreSQL et sa cartouche spatiale PostGIS III.4.2 Présentation des différences entre les cartouches spatiales Les trois systèmes de gestion de bases de données se basent sur la norme OGC (Open Geospatial Consortium) pour les types géographiques et les fonctions agissant sur ces types. III.4.2.1 Le modèle objet : La norme OGC définit des types
géométriques pour représenter les objets. Ce sont :
Point, MySQL PostgreSQL Oracle Point Point Point Linestring Linestring Linestring Polygone Polygone Polygone GeometryCollection GeometryCollection GeometryCollection Multipoint Multipoint Multipoint MultiLine String MultiLine String MultiLine String MultiPolygon Multi Polygon Multi Polygon CircularString Rectangle
CurvePolygon ArcPolygon
CompoundPolygon
2D(X-Y) 2D(X-Y) 2D(X-Y)
3D(X-Y-M) 3D(X-Y-M)
Tableau 1 : Comparaison entre BD spatiales : Le modèle Objet Oracle permet le stockage d'arc de cercles comme parties d'une géométrie, PostGIS et MySQL ne le permettent pas. MySQL implémente en partie la norme OGC. Les principales fonctions définies par la norme sont absentes de MySQL. Quant à PostGIS, le modèle objet est entièrement implémenté et toutes les fonctions et opérateurs décrit par la norme sont disponibles. Oracle enfin est conforme à la norme OGC, mais Oracle ne respecte pas les règles de nommage concernant les fonctions. III.4.2.2 Système de Référence Spatiale Il permet la gestion des systèmes de coordonnées, le changement de systèmes et la prise en compte de coordonnées géocentriques. MySQL PostgreSQL Oracle Stockage SRID Moteur de projection : Package SRS :sdo_cs (cs = bibliothèque C/C++ PROJ4 coordinate system) Pas de système de projection Définition issues d'EPS G (plus Définition issues d'EPS G de 2670 systèmes de projection) (2670+codes Oracle) Faible support des coordonnées Gestion géocentrique géocentriques Pas de transformation implicite (mêmes SRID pour les objets) Transformations complexes et implicites (filtres uniquement) Tableau 2 : Comparaison entre les BD spatiales: SRS Oracle supporte la gestion des SRS basés sur EPSG et sur le système Oracle, le changement de SRS pour les objets spatiaux et gère les systèmes de coordonnées géocentriques. MySQL ne permet pas le changement de SRS. Il ne connaît pas la notion de système de projection. Les calculs ici sont faits dans un espace euclidien. PostGIS permet le changement de SRS. Les données relatives aux SRS sont stockées dans une table de métadonnées définie par la norme OGC. III.4.2.3 Prédicats spatiaux Ce sont des fonctions et/ou des opérateurs permettant de tester les relations spatiales entre les objets. Uniquement sur les bounding Tous implémentés Tous implémentés ou prédicats box (bbox) équivalents MySQL PostgreSQL Oracle Respect du nommage de la norme OGC Non respect du nommage de la norme OGC Tableau 3 : Comparaison entre les BD spatiales: prédicats spatiaux MySQL supporte les prédicats définis par la norme OGC avec la restriction importante que ces fonctions n'agissent que sur les rectangles englobant des objets (bbox) et non sur les objets eux-mêmes. PostGIS supporte tous les prédicats définis par la norme, en respectant le nommage. Oracle Spatial et Locator supportent en partie les prédicats définis par la norme OGC. Tous les prédicats de la norme ne sont pas présents et les noms des prédicats Oracle ne correspondent pas à ceux de la norme. III.4.2.4 Prédicats spatiaux Sous ce terme de prédicats sont répertoriés des fonctions et/ou opérateurs permettant de tester les relations spatiales entre les objets. La norme OGC définit un certain nombre de ces prédicats, qui doivent renvoyer une valeur booléenne ou une valeur évaluable dans une condition booléenne. Voici une liste non exhaustive des opérateurs répondant à la norme OGC. Il s'agit de Union (mot réservé SQL...), Intersects, Difference, Symmetric Difference (SymDifference), Buffer, ConvexHull. MySQL PostgreSQL Oracle
Respect du nommage OGC Noms spécifiques Tableau 4 : Comparaison des bases de données
spatiales : Opérateurs III.4.2.5 Métadonnées La norme OGC définie deux tables pour la gestion des métadonnées: - Spatial_ref_sys : qui contient la définition des systèmes de projection - Geometry_Columns : qui référence toutes les tables comportant de la géométrie ainsi que leurs caractéristiques. MySQL PostgreSQL Oracle Pas de gestion des métadonnées Gestion des métadonnées Gestion des métadonnées Respect des règles de nommage Noms spécifiques : vue METADATA
Tableau 5 : Comparaison BD spatiales : Gestion des métadonnées MySQL ne dispose pas d'optimisation de la partie spatiale alors que les deux autres en disposent. Au terme de ces comparaisons, il ressort clairement que le premier SGBD dans le monde spatial est incontestablement Oracle avec sa composante Oracle Spatial. Mais PostgreSQL et sa composante spatiale PostGIS n'a rien à envier à Oracle. MySQL est encore un projet jeune et manque de fonctionnalités pour pouvoir couvrir les besoins actuels et futurs des projets mettant en oeuvre des données spatiales. Notre développement étant orienté vers les logiciels libres, nous choisirons donc PostgreSQL et sa composante spatiale PostGIS. III.5. Les logiciels SIG III.5.1 Les logiciels propriétaires Ce sont des logiciels qui appartiennent à l'éditeur. On retrouve sur le marché une importante gamme dont les plus connus sont : la famille ArcGis, Geoconcept, MapInfo et ArcView. Pour des raisons de besoins fonctionnels, ces solutions commerciales ont été écartées. III.5.2 Les logiciels libres On distingue deux catégories : Les logiciels SIG généralistes et les logiciels clients légers. III.5.2.1 Les logiciels SIG généralistes Ces systèmes fonctionnent également en mode client-serveur. Mais le client dans ce cas est un client lourd. 3. 5. 2. 1. 1 GRASS1 C'est le plus connu et le plus complet d'entre eux. Il supporte un grand nombre de format. Il prend en charge les analyses raster te vecteur. Ses inconvénients sont sa lourdeur, son installation fastidieuse, son utilisation assez difficile et son manque de portabilité. 3. 5. 2. 1. 2 OpenJump2 Développé en Java, ce logiciel est compatible avec tous les systèmes d'exploitation. Il permet de faire des traitements complexes sur données géographiques. Il prend en compte des 1 KOUT05 2 KOUT05 connexions WMS, ou PostGIS. Son inconvénient majeur est son manque de fonctionnalités. Il a besoin d'ajout de plugins supplémentaires pour l'ajout de certaines fonctionnalités basiques telles que la prise en charge raster et la mise en page. 3. 5. 2. 1. 3 QuantumGIS : 3 Ce logiciel, développé en C++, est assez simple d'utilisation. Il se connecte facilement à PostGIS. Par contre, on ne peut pas reprendre la géométrie d'une couche. On ne peut également pas effectuer de requêtes SQL (ni attributaires, ni spatiales). III.5.2.2 Les solutions client-serveur Ce sont des solutions adaptées au principe de Webmapping 3. 5. 2. 2. 1 MapLab4 MapLab est une suite logicielle intégrée destinée à faciliter le déploiement de solutions de Webmapping. Avec MapLab on peut construire graphiquement son mapfile, visualiser l'ensemble des données et y rajouter, par exemple, des couches d'information provenant d'une requr~te WMS sur un serveur cartographique distant. Enfin, on peut configurer l'interface proposée à l'utilisateur. La mise au point de cette dernière reste néanmoins basique. 3. 5. 2. 2. 2 MapServer : 5 C'est un serveur cartographique SIG permettant de générer des cartes dans un environnement web. Il est assez simple à installer. Les cartes sont composées de différentes couches que l'utilisateur crée à partir de ses données. MapServer est livré avec plusieurs bibliothèques qui permettent à l'utilisateur de créer, éditer, voir ses cartes sur le web. Son avantage majeur est qu'il est facile à utiliser et qu'il possède une très grande famille de développeurs. Au coeur de MapServer se trouve une application CGI pour la présentation sur le World Wide Web de contenus dynamiques SIG ou résultant du traitement d'images. MapServer intègre également un certain nombre d'applications autonomes pour la construction hors ligne de cartes, d'échelles et de légendes. Le module MapScript permet de l'interfacer à des pages html grâce au langage PHP. MapServer est télécommandé par du PHP et produit des cartes grâces aux mapfiles. Le mapfile est la pièce maîtresse d'une application de Webmapping avec MapServer. 3KOUT05 4 KOUT05 5 [KROP09] Un mapfile est un fichier texte ASCII structuré en plusieurs paragraphes qui définissent les paramètres de la carte (cadre, échelle, légende et couches). En pratique, il est appelé par un script et renvoie les différentes couches sous la forme d'images. 3. 5. 2. 2. 3 Deegree C'est un serveur cartographique qui implémente strictement toutes les normes OGC et ISO. Il permet la création des infrastructures complexes. Il est assez difficile à manipuler et est orienté développement. 3. 5. 2. 2. 4 CartoWeb6 : CartoWeb, n'est pas un serveur cartographique mais est plutôt un client léger qui est installé sur le serveur de données ou sur un serveur différent et interagit avec les données. Il est basé sur le moteur cartographique libre UMN MapServer et est publié sous licence GNU GPL. CartoWeb est une surcouche de MapServer. Il permet la présentation, mais aussi l'acquisition de données géographiques au travers de l'Internet. En pratique, il est doté d'une interface dotée de nombreux outils: consultation, interrogation, annotations, gestion de données, mesures... Il est aussi compatible avec de nombreux GPS. On distingue également d'autres clients légers notamment Ka-Map, Intermap, Chameleon qui respectent toutes les normes OGC. III.6. L'architecture Celle-ci doit être faite en tenant compte des besoins du ministère. En effet, les critères suivants seront pris en compte : - L'application doit pouvoir rtre consultée n'importe où : Mode client-serveur : protocole SOAP - Pas besoin de plugins supplémentaires pour afficher le rendu des cartes : format d'images standard. Donc pas de format SVG, et pas d'interactions sur les cartes. Au regard de toutes les contraintes ci-dessus énumérées, l'architecture finale choisie est la suivante : Au niveau de la couche de données, on utilise le SGBD PostgreSQL version 8.2.5 et sa composante spatiale PostGIS version 1.3.5. Au niveau de la couche application, on utilise le serveur cartographique MapServer version 5.2.1 qui s'installe facilement à partir du package MS4W version 2.3.1 et qui comporte 6 Extrait de Camptocamp_presentation cartoweb également les applications suivantes : - Apache 2.2.10 (muni d'OpenSSL0.9.8i) - L'interpréteur PHP version 5.2.9 - MapScript version 5.2.1 - Les bibliothèques GSAL/OGR, PROJ4, Shapelib, OGR/PHP Extension, OWTChart Pour la couche présentation on utilisera Cartoweb3 version 3.5. Dans cette architecture on retrouve les différentes couches. On distingue : y' La couche de données : Elle est gérée par le SGBD relationnel PostgreSQL et les fichiers shapefiles. y' La couche métier : Elle est constituée de mapfiles dans lesquels le développeur spécifie tous les traitements de son application. y' La couche présentation : Elle est essentiellement constituée de fichier de configuration cartoweb et des templates (.php, .tpl, .html). La solution entière repose sur une architecture 3-tiers dont le schéma est illustré ci- après :
Couche de données Couche présentation Couche métier Moteur cartographique : MAPSERVER (mapfiles) Navigateur web : HTTP Fichiers Shapefiles Serveur cartoweb3 : Données raster Logiciels de Datamining ou de Text Mining Serveur web Apache Données SIG Données vectorielles PostgreSQL/ Figure 10 : Architecture finale de l'application Le présent chapitre a présenté les différentes techniques de projet en rapport avec ce projet, puis il a présenté et comparé quelques outils notamment les serveurs de bases de données cartographiques et les logiciels SIG qui permettent d'aboutir sur une architecture de l'application finale qui sera mise en oeuvre dans le chapitre suivant. |
|