2.2. Présentation de la solution OpenStack
OpenStack est une plate-forme de cloud computing
développée par le fournisseur de services d'hébergement
Rackspace et la NASA pour aider les fournisseurs de services cloud et les
entreprises à créer des services d'infrastructure cloud [25]. Le
projet OpenStack pourrait être considéré comme un
système d'exploitation cloud. Toute organisation ou tout particulier
peut créer son propre environnement de cloud computing (IaaS)
basé sur OpenStack. Openstack permet la gestion du calcul, du stockage
et du réseau à travers une interface web et visant à
créer une plateforme de Cloud qui soit open source flexible et
élastique. L'architecture d'OpenStack propose de nombreux services dont
les plus importants sont : le service de calcul (Nova), service
d'identité (Keystone), service d'Image (Glance), service de
réseau (Neutron), service de stockage en objet (Swift), service de
stockage en bloc (Cinder), le tableau de bord (Horizon)[26]
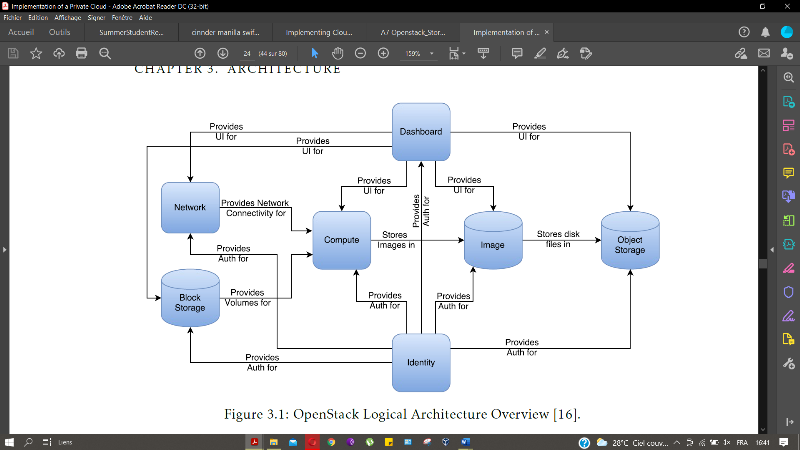
Figure 27 : Architecture des services
d'OpenStack[25]
2.3. Étude et analysede l'existant
Les plateformes de stockage dans le Cloud en existe beaucoup,
certains mieux que les autres et d'autres complémentaire qui peuvent
donc être implémentés et cohabités dans le
même système. Après plusieurs lectures approfondie une
sélection d'article semblait potentiellement intéressante
à aborder dans ce travail qui touchait nécessairement à
ces plateformes de stockage open source dans le Cloud : Swift, Manilla,
Cinder, Ceph, GlusterFS et Sheepdog. Dans ce qui suit nous présenterons
les recherches effectuées et la conclusion tiré des supports de
recherches [27][28][29][30][31][32]pour chacune des plateformes de stockage.
Nous discuterons la combinaison de celles que leur implémentation dans
notre plateforme Cloud est intéressantes.
Les recherches qui ont été menéesau sein
du département IT de l'université des sciences appliqué
sur les établissements d'enseignement supérieur montrent le
développement exponentiel de l'utilisation des données
informatiques au sein de ces établissements provocant ainsi deux
problématiques majeures lié principalement à la
fourniture des ressources informatiques via le matériel physique. En
constatant le changement du monde informatique par le biais de la technologie
du Cloud qui transforme la façon dont fonctionne les datacenter (centres
de traitement de données), de nombreux établissements
d'enseignement supérieur y réfléchissent pour tirer parti
de son potentiel, l'utilité de son implémentation dans
l'infrastructure réside dans sa capacité à fournir des
ressources matérielles virtuelles à savoir des serveurs, des
routeurs et des réseaux avec un mécanisme standard pour leurs
gestion et leurs distributions. Le travail présenté dans la
source [27] qui fait d'ailleurs parti du projet fondé par The
Research Council (TRC) présente une conception et une mise en
oeuvre d'un prototype de Cloud privé pour les établissement
d'enseignement supérieures en utilisant la solution OpenStack qui
fournit une IaaS, permettant ainsi aux étudiants et aux chercheurs de
travailler avec des machines virtuelles en créant leurs propres
ressources virtuelles comme les serveurs, les routeurs et les topologie des
réseaux, cette solution offre la possibilité de faire des
expériences dans un environnement sandbox(environnement de test
pour logiciels ou sites web). Lorsque nous prêtons attention à
l'architecture du déploiement qui finalement est censé
répondre à la problématique de stockage nous remarquons
qu'en plus des services primaires d'OpenStack : Identité, Image,
Réseau, Calcul, Tableau de bord, existe deux autres services de stockage
Cinder pour le stockage en bloc et Swift pour le stockage en objet, nous nous
intéressons plus particulièrement à cette partie du
Cloud : le stockage. Ce que nous pourrons conclure de ce travail est que
les deux services de stockage Cinder et Swift ont chacun leurs propres
fonctionnalités qui peuvent être complémentaire pour
assurer une bonne gestion de stockage dans le Cloud.
La source [28]partage les idées du travail
élaboré dans le projet du TRC et se focalise principalement sur
le service Swift qui propose un stockage en objet. Ce travail exploite
complètement les solutions open source existantes pour
accélérer l'effort de développement et construit un
prototype local de Cloud basé sur base d'une architecture de service de
stockage cloud en Objet (COS3) que des entreprises et des organisations peuvent
se l'approprier. L'architecture COS3 est flexible, simple et modulaire avec une
conception hiérarchique composée de trois couches : stockage
de données, transformation et routage de données, accès
aux données. L'article souligne grandement l'utilité du service
de stockage choisi en expliquant que Swift fournit un stockage rentable,
évolutif et redondant grâce à l'utilisation des clusters,
permet la prise en charge des application web et mobiles ainsi que la
sauvegarde et l'archivage actif des données qui peuvent être
récupérées via une API REST. Swift adopte une architecture
de cohérence à terme (eventual consistency en anglais)
qui le rends idéal pour la construction d'infrastructure massives et
hautement distribuées avec de nombreuses données non
structurées, avec Openstack Swift fournit en plus trois types de
authentification : TemAuth, Swauth et keystone, TempAuth étant le
service d'authentification par défaut de Swift, il stokce les noms des
utilisateurs et leurs mots de passes en texte clair, il n'est donc pas
fortement recommandé de l'utiliser, Swauth en revanche utilise des droit
d'accès configurés pour sécuriser les mots de passe, il
est utilisé principalement dans les environnements d'expériences
et de test contrairement à keystone qui est utilisé dans
n'importe quel environnement que ce soit en test ou en production, c'est le
service qui gère l'accès dans Openstack utilisant les tokens il
propose une meilleure sécurité des mots de passes. L'organisation
des données comme expliquée dans l'article [28] est construite
selon une hiérarchie de : Compte, Conteneur et objet, le compte
étant au niveau supérieur de la hiérarchie, le conteneur
comme les buckets (seaux) et les objets comme magasin de stockage de
donnée : documents, images, vidéos ...etc. Les objets
stockés dans Swift ont une URL que les applications utilisent pour
stocker et récupérer des données, ils peuvent aussi avoir
des métadonnées étendues qui sont indexées et
recherchées, ces objets sont stockés avec plusieurs copies
(généralement trois) pour éviter de les perdre. Cet
article estime que le benchmarking (techniques de test des performances) de
l'implémentation d'un Cluster Swift est essentiel avant le
déploiement de ce dernier pour une utilisation en production. Pour se
faire ils se sont basés sur une configuration d'un cluster de stockage
répartie sur six serveurs (noeuds) : l'un de ces noeuds est un
serveur proxy qui expose les requêtes aux entités de stockage, et
les autres sont es noeuds de stockage à savoir Compte, Conteneurs et
Objet. Ils ont ensuite utilisé« Swift-bench » qui
est un outil de benchmarking en lignes de commande fournit avec la distribution
Swift utilisé comme générateur de charge de travail pour
comparer Swift en termes d'opération #PUT par seconde,
d'opération #GET par seconde et d'opération DELETE par seconde.
Ils ont constaté à la fin que les opération #PUT et
#DELETE sont dominantes dans le cluster Swift.
La conférence ayant eu lieu en mars 2016 à
l'université de Manitoba à Winnipeg au Canada s'intéresse
au problème de mise en oeuvre et d'évaluation des performances
des données critiques dans le marché du Cloud, et plus
précisément à la gestion des incidents [29], cette
conférence présente les travaux qui ont été faits
afin de sélectionner la meilleure stratégie de stockage
permettant la reprise des services en cas de défaillance du
système due à une catastrophe naturelle ou humaine pour une
organisation utilisant un Cloud privé. L'idée était de
créer un nouveau système de proposé une nouvelle
stratégie de réplication pour la duplication des données
dans un Cloud privé basé sur openstack. Pour cela ils ont
construit un Cloud privé à l'aide d'une solution logicielle open
source basée sur OpenStack suivie d'un déploiement d'une
application financières sur des machine virtuelles. Le but était
de provoquer un déclenchement d'un sinistre pour repérer lequel
des deux services de stockage d'Openstack Cinder ou Swift est le meilleur en
cas de défaillance du système (i.e. lequel possède la
meilleure technique de réplication des données). Parmi les
multiples plans de reprise de travail qui existent dans le domaine du
Cloud : sauvegarde du système uniquement, transfert de
données hors site, sauvegarde à la fois du système et des
donnée...etc. la dernière a été choisie, pour se
faire, une technologie de snapshots (une sauvegarde de l'état d'un
système à un instant donné)a été
adopté.Pour récapituler leur expérience, ils ont
créé des scripts qui planifient les captures des snapshots,
ensuite ils ont déclenché une machine virtuelle avec des erreurs
de configuration suivis de la mise hors tension de cette dernière,
à cet instant-là, les snapshots sont
récupérés et le bloc de données passif est
activé ce qui produit un système de réplication de la
machine virtuelle. L'analyse expérimentale des deux
stratégies de stockage s'est basée sur d'autres scripts
créés pour déterminer premièrement laquelle des
deux est rapide en termes de création et déploiement de snapshot
et en quantité de données associé à chaque
itération et deuxièmement laquelle des méthodologies
garantit le plus la cohérence des données en mesurant le nombre
d'octet de données perdus à chaque itération.
D'après les résultats de cet analyse Cinder est 53fois plus
rapide que Swift en termes de création, déploiement et sauvegarde
des données (i.e. Cinder 53 fois mieux que Swift en termes de
récupération du système après un sinistre) un
deuxième constat est tiré de cette analyse, il s'agit de la
cohérence des données, en effet les deux stratégies de
stockage : Cinder et Swift fournissent des données
cohérentes. En conclusion s'il y a un choix à faire entre le
stockage en bloc Cinder et le stockage en objet Swift pour assurer la
fiabilité des données critiques et la reprise des services en cas
de sinistre mieux vaut opter pour Cinder.
Le projet Openstack contient plusieurs composants comme Cinder
qui est dédié au stockage en bloc et qui comme déjà
montré précédemment améliore les performances des
machines virtuelles, ou même Swift qui propose un stockage en objet
offrant ainsi plusieurs fonctionnalités complémentaire avec
Cinder, cependant la création des volumes ne se fait pas uniquement en
local sur OpenStack, il existe en vrai d'autres système de stockage dits
à distance, qui offrent plus ou moins des fonctionnalités pareils
voire absents dans les système de stockage en local : Cinder,
Swift...etc. ces systèmes peuvent être open source comme LVM, NFS,
Ceph ou GlusterFS ou propriétairescomme EMC et IBM.Les chercheurs dans
l'article [30] affirment que le stockage local d'OpenStack n'est pas assez
puissant ni facile à étendre et que son
hétérogénéité rend la gestion et la
maintenance du système complexe, ils constatent qu'il présente un
taux de fiabilité bas. Leur stratégie est composée de deux
partie la première était d'intégrer une solution libre de
stockage distribuée délivrant des services de stockage à
la fois en Bloc, en Objet mais aussi en fichier : Ceph RBD (Rados
Block Device en anglais, dispositif de stockage en bloc en
français) avec les services de calcul (nova), d'image (Glance) et de
stockage en bloc (Cinder) dans Openstack. La deuxième consistait
à construire trois plateformes de stockage : RBD_OpenStack,
Local_OpenStack et GSR_OpenStack avec des backend de stockage différent
(LVM, GlusterFS, LocalFS, RBD)afin de les analyser et les comparer visant
à trouver la meilleure plateforme open source parmi eux. Les analyses
et les calculs de performances de la première partie de
l'expérience ont montré que le système de stockage RBD
réduit le temps de déploiement des machine virtuelles et de leurs
migrations, de plus ils ont trouvé qu'il améliore
l'efficacité de la lecture et de l'écriture sur les volumes de
stockage. L'évaluation des stockages dans la deuxième partie
s'est basée sur trois critères : concernant le temps de
déploiement de la machine virtuelle, le mode de stockage RBD est le plus
rapide suivi du GSR et ensuite du mode Local car le
téléchargement des images disques dans le local se fait à
chaque création d'une machine virtuelle, une seule fois dans le mode GSR
contrairement au mode RBD dans lequel le service de Calcul et d'Image partage
le même backend de stockage unifié ; le deuxième
critère sur lequel ce sont basé les analyses est le temps de
la migration à chaud de la machine virtuelle le temps de la migration
à chaud des machines virtuelles, les modes de stockage partagé
RBD et GSR prennent une seule seconde pour faire cette action contrairement au
mode Local qui nécessite une copie des fichier d'image disque entre les
noeuds de calcul en prenant plus de temps à savoir 121.4 secondes.
Concernant le troisième critère, les performances en lecture et
en écriture de la machine virtuelle dans un volume de stockage sont
élevées dans le RBD car il ne dépend que du transfert de
données dans le cluster Ceph, contrairement au mode Local et GSR qui eux
dépendent des performances I/O (Input/Output, entrée/sortie) du
disque physique ainsi que du trafic du réseau. La conclusion à
relever de ces expériences présentées dans l'article [30]
est que RBD Ceph est la meilleure solution de stockage à mettre en place
en termes de vitesse de déploiement et de migration des machines
virtuelles ainsi qu'en lecture et écriture sur les disques de
stockage.
L'immense quantité de données structurés,
non structurés et semi structuré présente dans le Cloud
est stockée dans un serveur ou un cluster de stockage, ce dernier est
configuré avec un système de stockage Cloud comme GlusterFS,
Ceph, LVM, ZFS etc. l'article [31] discute en premier temps la vue d'ensemble
de ces plateformes et compare par la suite entre les deux plateformes les plus
utilisé : Ceph et Swift, en profondeur et en respectant certains
critères tels que la cohérence, la méthode de placement
des données, opération de lecture, opération
d'écriture, sécurité et autres. GlusterFS est un
système NAS (Network Attached Storage), cette plate-forme fonctionne
avec du matériel à faible coût et convient aux
données non structurées, par exemple : documents, courriers
électroniques, massages, images, fichiers multimédias et fichiers
journaux, etc.[31]Le système ZFS est un système de fichiers avec
gestionnaire de volume logique, il est basé sur l'idée des pools
de stockage pour gérer le stockage physique. ZFS offre des performances
efficaces et une intégrité des informations, ainsi qu'une
administration simple[31].LVM permet au système de fichiers d'être
redimensionné efficacement, il prend des snapshots pour la sauvegarde.
Il peut créer un volume virtuel unique à partir de
différents volumes réels ou d'un disque dur entier et permet le
redimensionnement du volume[31]. Ceph est une plateforme de stockage cloud
distribuée et open source qui prend en charge le stockage en objets, en
blocs et en fichiers, elle est nécessairement conçue pour
atteindre la fiabilité, l'évolutivité avec de meilleures
performances tout en s'exécutant sur du matériel de base sans
point de défaillance unique. [31] Swift fournit une plateforme de
stockage distribuée afin que les clients puissent stocker et
accéder à des informations ou à des objets à l'aide
d'API REST, elle est développée pour assurer
l'évolutivité, la durabilité, la disponibilité et
la simultanéité sur l'ensemble des données.[31]
après avoir comparé entre ces cinq plateformes de stockage ils
ont été classé selon leurs types de stockages, en effet,
Swift assure uniquement le stockage en objet, LVM et ZFS uniquement le stockage
en Bloc, Gluster assure quant à lui le stockage en fichier et en objet
et enfin la plateforme Ceph qui assure les trois type de stockage : en
bloc, en objet et en fichier.
Après cette vue d'ensemble et comparaison
générale présenté dans l'article de journal [31],
les chercheurs ont étudié en profondeur les deux systèmes
Ceph et Swift, en terme de type de stockage Swift fournit un stockage en objet,
accessible via une API RESTful http, il utilise des rings (anneaux) pour
surveiller et fournir des information sur l'emplacement des informations
stockées dans un conteneur, pour se connecter les clients se connectent
via des serveurs proxy aux noeuds de stockage (ce qui crée un goulot
d'étranglement : un point d'un système limitant les
performances globales, et pouvant avoir un effet sur les temps de traitement et
de réponse), pour répartir le travail entre les noeuds de
stockage, Swift utilise la technique de Load Balancer qui consiste à
répartir uniformément les charges de travail sur plusieurs
servers afin d'optimiser le rendement, la fiabilité et la
capacité du réseau. La cohérence étant la
capacité du système à refléter sur la copie d'une
donnée les modifications intervenues sur d'autres copies de cette
donnée, le système Swift est fondé sur un type de
cohérence dit « à terme », ce type de
cohérence consiste à répondre immédiatement aux
demandes de lecture (i.e. faible latence) avec un risque d'envoi de
données obsolètes. Concernant Ceph en fournissant trois type de
stockage : en bloc, en objet et en fichier, il est accessible via l'API
Amazon S3 et l'API de Swift, utilisant pour calculer l'emplacement des objets
stocké dans le cluster un algorithme appelé CRUSH (The Controlled
Replication Under Scalable Hashingen anglais, La réplication
contrôlée sous hachage évolutifenfrançais),
son architecture permet au client de se connecter directement aux noeuds de
stockages (i.e. meilleures performances entrée/sortie), il
possède des serveurs dits Ceph Monitor qui surveillent le cluster en
sauvegardant les données liées à ce dernier, et enfin, par
rapport à Swift il utilise une autre forme de
cohérence appelée « la cohérence
forte » qui certainement réponds aux demandes de lecture
tardivement (latence élevé) mais qui assure que l'information
envoyé soit mise à jours. Pour conclure le travail des chercheurs
présenté dans cet article, nous retiendrons que Ceph et Swift ne
sont pas des concurrents, chacun possède des fonctionnalité
complémentaire à l'autre et peuvent cohabiter dans un seul
système pour profiter des deux offres, cependant à retenir que
Ceph est moins sécure que Swift car les clients communiques directement
avec le cluster de stockage et sur le même réseau Ceph utilise un
trafic de réplication non chiffré (i.e. un pirate pourrait
facilement observer le trafic sur le réseau de stockage).
Les futurs travaux décrits dans l'article [30] dans
lequel des chercheurs ont intégrer le système de stockage Ceph
avec le service du stockage en bloc d'Openstack : Cinder, consistent
à intégrer ce même système avec les services de
stockage en objet : Swift et avec celui du stockage en fichier :
Manila. Un projet au sein du département IT de CERN (nommé
maintenant : l'Organisation Européenne pour le Recherche
Nucléaire) a été réaliser en 2019 pour
l'infrastructure Cloud Openstack du CERN[32], une partie de ce projet
consistait à décrire les fonctionnalités et les avantages
d'une implémentation d'un service de stockage autre que celui du mode
« bloc » : Cinder et du mode
« objet » : Swift, il est nommé Manila et offre
à l'infrastructure Cloud de CERN un service de fichier partagé,
il permet aux utilisateurs de créer et gérer des partages de
fichiers, son utilité principale est son autorisation aux machines
virtuelles d'accéder simultanément à ces fichiers
partagés ( fonctionnalités qui n'est pas prise en charge par
Cinder). À l'heure actuelle, ce service est utilisé pour le
cluster de calcul haute performance qui utilise ces partages de fichiers comme
stockage partagé pour ses charges de travail de calcul. Le service est
également utilisé pour remplacer les fichiers NFS car il
simplifie la gestion de ces machines dédiées. Une fois les
partages de fichiers créés, l'utilisateur peut utiliser le
protocole CephFS pour accéder aux données. CephFS étant le
système de fichier de Ceph.
|
|


