|
1
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
0. INTRODUCTION GENERALE
0.1 CONTEXTE
La prise de décision est un problème essentiel
qui préoccupe les gestionnaires des entreprises, toutes les couches de
la société contemporaine, c'est alors que pour qu'une
décision soit rationnelle elle doit passer par la modélisation de
différents problèmes qu'ils rencontrent dans la gestion,
d'où la nécessité d'un modèle basé sur
l'arbre de décision.
L'entrepôt de données est une vision
centralisée et universelle de toutes les informations de l'entreprise.
C'est une structure qui a pour but, contrairement aux bases de données,
de regrouper les données de l'entreprise pour des fins analytiques et
pour aider le manager à la prise de décision
stratégique.
Une décision stratégique est une action
entreprise par les décideurs de l'entreprise qui vise à
améliorer, quantitativement ou qualitativement, la performance de
l'entreprise.
0.2 PROBLEMATIQUE
La Direction Générale de Recette du Kasaï
Occidental (DGR KOC) ne se base pas sur des critères objectifs pour le
recrutement de ses agents, mais elle se base sur des bases de
clientélisme et sentimentales. C'est pourquoi notre étude se base
sur la recherche à la solution de la question suivante :
Est-il possible de concevoir un système
décisionnel d'aide au recrutement à la DGRKOC?
0.3 HYPOTHESE
Un système décisionnel basé sur l'aide de
décision permettrait d'automatiser le recrutement du personnel à
la Direction Générale de Recette du Kasaï Occidental
(DGRKOC).
0.4 CHOIX ET INTERET DU SUJET
Notre choix est porté sur la mise en place d'un
système décisionnel basé sur le data mart et l'arbre de
décision pour le recrutement du personnel de la Direction
Générale de Recette du Kassaï Occidental (DGRKOC).
Le choix de ce sujet est motivé par deux raisons
essentielles :
? Aider la Direction Générale de Recette du
Kassaï Occidental à améliorer son système de
recrutement ;
? Lier les théories apprises dans notre formation à
la pratique.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
2
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
0.5 SUBDIVISION DU TRAVAIL
Outre l'introduction et la conclusion notre travail se subdivise
en quatre chapitres repartis dans deux parties : la partie théorique et
la partie pratique.
La première partie compte trois chapitres, alors que la
deuxième partie contient un chapitre.
Partie théorique :
Cette partie contient le premier chapitre qui s'intitule :
généralités sur les systèmes
décisionnels.
Le deuxième chapitre intitulé data warehouse et
data mart, qui présente les
différents concepts relatifs aux
entrepôts de données, au data mart et leur impotence dans une
entreprise.
Le troisième chapitre porte sur le datamining et l'arbre
de décision.
Partie pratique :
Cette partie contient le quatrième chapitre qui est la
modélisation et l'implémentation.
0.6 METHODOLOGIE ET TECHNIQUES
Nous avons utilisé les méthodes et techniques
ci-après :
? La méthode historique ou descriptive, qui est une
méthode de description nous a permis de décrire l'entreprise et
son fonctionnement.
? La technique d'interview qui nous a été d'une
importance capitale elle a
consisté en un questionnement verbal adressé
à toute personne de la DGRKOC Kananga, en vue d'éclairer notre
recherche.
? La technique d'enquête, qui nous a permis de mener
quelques enquêtes dans
l'entreprise pour savoir comment elle fonctionne.
? La technique d'observation, qui nous à aidée
à procéder à l'observation et à
palper du doigt l'aspect général de notre cible de
recherche.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
3
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|

Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
4
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
CHAP I : GENERALITES SUR LES SYSTEME DECISIONNELS [5,7,
8, 10,
11, 12]
I.0 INTRODUCTION
Toute entreprise qui veut atteindre des performances est
censée prendre des décisions rationnelles en se basant sur un
système décisionnel. La faillite de bon nombre d'entreprises est
due au manque d'un personnel qualifié, à une mauvaise gestion et
à une prise de décisions non adéquate.
I.1 HISTORIQUE DES SYSTEMES DECISIONNELS
La prise de décision est un problème essentiel
qui préoccupe les gestionnaires des entreprises. Cette prise de
décision passe par la modélisation de différents
problèmes qu'ils rencontrent dans la gestion d'où la
nécessité d'un modèle basé sur l'arbre de
décision.
De nos jours pour qu'une entreprise puisse bien marcher, elle
doit avoir besoin d'outils d'aide à la décision. Ces outils
permettront alors aux dirigeants de bien prendre des décisions. Ces
décisions concernent tous les services de cette entreprise. Le
système décisionnel englobe tous les services de l'entreprise
ainsi que leurs informations.
Les systèmes décisionnels travaillent comme des
systèmes opérationnels sur de gros volumes de données.
La décision concerne tous les départements de
l'entreprise : finances, ressources humaines, ventes, et la direction
générale. Les applications utiles dans le processus de prise de
décision sont nombreuses, et déjà présentes dans le
système d'information des entreprises.
I.2 L'INFORMATIQUE DECISIONNELLE [12,9]
L'informatique décisionnelle désigne les moyens,
les outils et les méthodes qui permettent de collecter, consolider,
modéliser et restituer les données, matérielles ou
immatérielles d'une entreprise, en vue d'offrir une aide à la
décision et de permettre aux dirigeants de prendre des stratégies
pour l'entreprise et d'avoir une vue d'ensemble de l'activité
traitée au sein de l'entreprise.
En général ce type d'applications utilise un
entrepôt de données pour stocker des données provenant de
plusieurs sources hétérogènes et fait appel à des
traitements par lots pour la collecte de ces informations.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
5
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
I.3 DEFINITION D'UN SYSTEME DECISIONNEL (BUSINESS
INTELLIGENCE) [8]
Un système est un ensemble de technologies
destinées à permettre aux collaborateurs d'avoir accès et
de comprendre les données de pilotage rapidement, de telle sorte qu'ils
prennent une décision meilleure a temps, résultant d'un processus
comportant le choix conscient entre plusieurs solutions en vue d'atteindre un
objectif précis.
Un système décisionnel permet de répondre
aux questions suivantes :
? Que s'est il passé ? (tableau de bord) ;
? Pourquoi cela s'est il passé ? (analyse) ;
? Que va-t-il se passé ? (prédiction) ;
? Que se passe-t- il en ce moment ? (aide opérationnelle)
;
? Que devrait- il se passer ou que faire ? (prise de
décision ou entrepôt actif).
I.3.1 ARCHITECTURE DE SYSTEMES DECISIONNELS [8]
L'architecture générale d'un système
décisionnel se décompose en trois processus : extraction et
intégration, organisation et interrogation.
Le processus d'extraction et intégration, situé
les sources de données et l'entrepôt est responsable de
l'identification des données dans les diverses sources internes et
externes ;
Dans l'extraction de l'information et de la préparation
et de la transformation (nettoyage, filtrage, etc..) des données
à l'intérieur de l'entrepôt, nous trouvons le processus
d'organisation. Il est responsable de la structuration des données par
rapport à leur niveau de granularité (agrégats).
Différents outils permettent de réaliser
l'analyse des données, pour les différents utilisateurs de
l'entreprise.
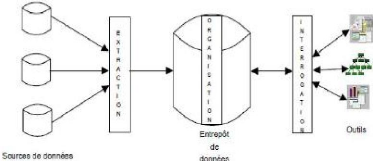
Fig. I. 1 Architecture Générale d'un
système décisionnel
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
6
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
I.4 LES DIFFERENTS ELEMENTS CONSTITUTIFS DU SYSTEME
DECISIONNEL [13]
I.4.1 Les sources de données :
Les sources de données sont souvent diverses et
variées et le but est de trouver des outils et en fin de les extraire,
de les nettoyer, de les transformer et de les mettre dans l'entrepôt de
données. Ces sources de données peuvent être de fichiers de
type Excel, des bases de données opérationnelles d'une entreprise
ou fichiers plats. I.4.2 L'entrepôt de données :
Il est le coeur du système décisionnel et
demande une analyse profonde de la part de maitre d'ouvrage.
La conception d'un datawarehouse diffère de la
conception d'une base de donnée relationnelles.
En effet, alors que les bases de données relationnelles
tendant le plus souvent à être normalisées, les bases des
données multidimensionnelles, elles sont normalisées en
respectant le modèle en étoile ou en flocon.
I.4.3 Le service OLAP ou serveur d'analyse
Le serveur OLAP est opposé a OLTP et à pour but
d'organisé les données à analysé par domaine ou par
thème et d'en ressortir des résultats pertinents pour le
décideur. Les résultats sont obtenus par différents
algorithmes de datamining (fouille de données) du serveur d'analyse. Ces
résultats peuvent amener l'organisation à prendre de très
bonnes décisions en vue d'améliorer le rendement de leurs
entreprises.
I.5 LES FONCTIONNALITES D'UN SYSTEME DECISIONNEL
Les besoins des utilisateurs peuvent être regroupés
en quatre catégories :
Simuler, analyser les données, réduire des
états de gestion, suivre et contrôler.
1°) Simuler :
? Gestion de modèles de calcul (calculs automatiques
d'ensemble de données
complexe en fonction de paramètre par l'utilisateur et de
règles de gestion)
Exemple d'utilisation : élaboration de business plan ;
? Elaboration collaborative ;
EX : l'élaboration budgétaire.
2°) Analyse de données
? Fonctionnalité OLAP (établissement d'analyse
dynamique multidimensionnelle avec possibilité de trié, filtrer,
zoomer a l'intérieure de données) ;
EX : chiffre d'affaire.
? Fonctionnalités avancées de datamining,
ensemble des techniques statistiques sophistiquées permettant de faire
apparaitre des corrélations, des tendances et des prévisions.
3°) Produire des Etat de gestion
Fonctionnalités de reporting raquetteurs permettant de
produire de façon simple et rapide, des tableaux de données
incorporant des calculs plus ou moins sophistiquées ; 4°) Suivre et
contrôler
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
7
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
·
· Elaboration de tableau de bord produit et
diffusion automatiquement à
fréquence régulière de tableaux de bord
regroupent des données hétérogènes. EX : production
de tableaux de bord graphique a destination de responsables
opérationnels
·
· Emission d'alerte
génération conditionnelle de message sur différents
supports (email, sms,...) plus ou moins complexes en fonction de la
configuration de données.
Nous avons constaté que l'ensemble de ces
fonctionnalités sont rarement mise en place dans une entreprise.
Les mises en oeuvre sont en outre souvent
réalisées par domaine fonctionnel(les ventes, achats,...). Par
ailleurs, il n'existe pas de produit couvrent l'ensemble de ces
fonctionnalités.
Chaque progiciel en fonction de son origine et du
positionnement que souhaite lui donner son éditeur est plus au moins
avancé sur l'un ou l'autre thème.
Il est donc crucial de déterminer
précisément ses besoins présent et future, ainsi que les
contraintes liées à son organisation ou a son activité
avant de choisir une solution.
I.6 LES APPORTS DES SYSTEMES DECISIONNELS
Dans beaucoup de nos entreprises ; il est difficile
d'expliquer aux dirigeants que l'on doit parfois dépenser beaucoup
d'argent pour analyser et manipuler des données existant dans le
système d'information de l'entreprise.
Les apports de systèmes décisionnel sont aussi
défais réels. Ils peuvent être classés en deux
catégories.
· L'amélioration de l'efficacité de la
communication et de la distribution des informations de pilotage ;
· L'amélioration du pilotage des entreprises
résultant de meilleures décisions à prendre plus
rapidement ;
Si le premier point est aisément compréhensible,
présente peu de risque de mise en oeuvre et pose peu de problème
d'évaluation ce n'est clairement pas en revanche une source de gains
significative. Il sera difficile le plus souvent de justifier les couts d'un
projet sur cette seule promesse.
La seconde catégorie a nettement plus de potentiel de
gains. Mais il faut bien reconnaitre que le risque de ne pas atteindre les
objectifs initiaux sont réels sans parler d'énormes
difficultés d'évaluation des bénéfices
escomptés.
Les bénéfices de ce type le plus souvent
cités sont les suivants :
> unicité des chiffres, une seule vérité
acceptée par tous ;
> meilleure planification ;
> amélioration de la prise de décision ;
> amélioration de l'efficacité des processus
;
> amélioration de la satisfaction des clients et des
fournisseurs ;
> amélioration de la satisfaction des
employés.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
8
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
I.7 LES ENJEUX DE L'INFORMATIQUE DECISIONNELLE [11]
De nos jours, les données applicatives métier
sont stockées dans une ou plusieurs bases de données
relationnelles ou non relationnelles. Ces données sont extraites,
transformées et chargées par un outil de type ETL.
Un entrepôt de données (datawarehouse) peut
prendre la forme d'un dataMart. En règle générale, le
datawarehouse globalise toutes les données applicatives de l'entreprise
tandis que les dataMarts, généralement alimentés à
partir des données du datawarehouse sont des sous ensembles
d'information concernant un métier particulier de l'entreprise.
I.8 LES FONCTIONS ESSENTIELLES DE L'INFORMATIQUE
DECISIONNELLE
Un système d'information décisionnel assure
quatre fonctions fondamentales, à savoir : la collecte,
l'intégration, la diffusion et la présentation des
données. A ces quatre fonctions s'ajoute une fonction de contrôle
du système d'information décisionnelle lui-même,
l'administration.
a) Collecte :
La collecte est l'ensemble des taches consistant à
détecter, sélectionner, extraire et à filtrer les
données brutes issues des environnements pertinents compte tenu du
périmètre du système d'information décisionnel
(SID).
Les sources de données internes ou externes
étant souvent hétérogène tant sur le plan technique
que sur le plant sémantique, cette fonction est la plus délicate
à mettre en place dans un système décisionnel complexe.
Elle s'appuie notamment sur les outils d'ETL.
Cette alimentation utilise les données sources issues
des systèmes transactionnels de production, le plus souvent sous forme
de compte rendu, d'inventaire ou compte rendu d'opération qui est le
constat au fil du temps des opérations (achats, ventes, écriture,
comptable), le film de l'activité de l'entreprise ; compte rendu
d'inventaire ou compte rendu de stock qui est l'image photo prise a un instant
donné (à une fin de période, mois, trimestre) de
l'ensemble du stock (les clients, les contrats, les commandes). La fonction de
collecte joue également au besoin un rôle de recodage. Une
donnée représentée différemment d'une source
à une autre impose le choix d'une représentation unique pour les
futures analyses.
b) Intégration :
L'intégration consiste à concentrer les
données collectées dans un espace unifié, dont le socle
informatique essentiel est l'entrepôt.
Élément central du dispositif, il permet aux
applications décisionnelles de bénéficier d'une source
d'information commune, homogène, normalisée et fiable,
susceptible de masquer la diversité de l'origine des données.
Au passage les données sont épurées ou
transformées par un filtrage et une validation des données en vue
du maintien de la cohérence d'ensemble (les valeurs acceptées par
les filtres de la fonction de collecte mais susceptibles d'introduire des
incohérences de référentiel par rapport aux autres
données doivent être soit rejetées, soit
intégrées avec un statut spécial).
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
9
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Une synchronisation (d'intégrer en même temps ou
à la même date de valeur des événements reçus
ou constatés de manière décalée ou
déphasée).
Une certification (pour rapprocher les données de
l'entrepôt des autres systèmes légaux de l'entreprise comme
la comptabilité ou les déclarations réglementaires).
C'est également dans cette fonction que sont
effectués éventuellement les calculs et les agrégations
(cumuls) communs à l'ensemble du projet. La fonction
d'intégration est généralement assurée par la
gestion de métadonnées, pour l'interopérabilité
entre toutes les ressources informatiques, des données
structurées (bases de données accédées par des
progiciels ou applications), ou des données non structurées.
c) La diffusion ou la distribution :
La diffusion met les données à la disposition
des utilisateurs, selon des schémas correspondant au profil ou au
métier de chacun, sachant que l'accès direct à
l'entrepôt ne correspondrait généralement pas aux besoins
d'un décideur ou d'un analyste. L'objectif prioritaire est de segmenter
les données en contextes informationnels fortement cohérents,
simples à utiliser et correspondant à une activité
décisionnelle particulière.
Alors qu'un entrepôt de données peut
héberger de centaines ou de milliers de variables ou indicateurs, un
contexte de diffusion raisonnable n'en présente que quelques dizaines au
maximum.
Chaque contexte peut correspondre à un DataMart, bien
qu'il n'y ait pas de règles générales concernant le
stockage physique.
Très souvent, un contexte de diffusion est
multidimensionnel, c'est-à-dire modélisable sous la forme d'un
hyper cube, il peut alors être mis à disposition à l'aide
d'un outil OLAP.
Les différents contextes d'un même
système décisionnel n'ont pas tous besoin du même niveau de
détail.
De nombreux agrégats ou cumuls, n'intéressant
que certaines applications et n'ayant donc pas lieu d'être gères
en tant qu'agrégats communs par la fonction d'intégration,
relèvent donc de la diffusion.
Ces agrégats peuvent être, au choix,
stockés de manière persistante ou calculés dynamiquement
à la demande.
On peut distinguer trois questions à élucider pour
concevoir un système de reporting : À qui s'adresse le rapport
spécialisé ? (choix des indicateurs a présenter, choix de
la mise en page)
Par quel trajet ? (circuit de diffusion type workflow pour
les personnes, circuits de transmission télécoms pour les
moyens)
Selon quel agenda ? (diffusion routinière ou sur
événement prédéfini)
d) Présentation : Cette quatrième fonction, la
plus visible pour l'utilisateur, régit les conditions d'accès de
l'utilisateur aux informations. Elle assure le fonctionnement du poste de
travail, le contrôle d'accès, la prise en charge des
requêtes, la visualisation des résultats sous une forme ou une
autre.
Elle utilise toutes les techniques de communication possibles
comme les outils bureautiques, raquetteurs et générateurs
d'états spécialises, infrastructure web,
télécommunications mobiles, etc.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
10
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
e) Administration :
C'est la fonction transversale qui supervise la bonne
exécution de toutes les autres; elle pilote le processus de mise
à jour des données, la documentation sur les données et
sur les métadonnées, la sécurité, les sauvegardes,
la gestion des incidents.
CONCLUSION PARTIELLE
Dans ce chapitre, nous avons traité les systèmes
décisionnels.
Nous avons défini l'informatique décisionnelle,
l'architecture de systèmes décisionnels et ses différents
enjeux avec leurs fonctions.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
11
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
CHAP II: DATA WAREHOUSE ET DATA MART [7, 8, 1,]
II.1 INTRODUCTION
Les entrepôts des données intègrent des
informations en provenance de différentes sources, souvent reparties et
hétérogènes ayant pour objectif de fournir une vue globale
de l'information aux analystes et aux décideurs.
La construction et la mise en oeuvre d'un entrepôt de
données représentent une tache complexe qui se compose de
plusieurs étapes.
La première est l'analyse des sources de données
et l'identification des besoins des utilisateurs, la deuxième correspond
à l'organisation des données à l'intérieur de
l'entrepôt. En fin, la troisième sert à établir
divers outils d'interrogation, d'analyse, et de fouille de données.
Chaque étape présente des problèmes
spécifiques. Ainsi, par exemple, lors de la première
étape, la difficulté principale consiste en l'intégration
des données, de manière a ce qu'elles soient de qualité
pour leur stockage. Pour l'organisation, il existe plusieurs problèmes
comme la sélection des vues à matérialiser, le
rafraichissement de l'entrepôt, la gestion de l'ensemble de
données courantes et historisées.
En ce qui concerne le processus d'interrogation, nous avons
besoin des outils performants et conviviaux pour l'accès et l'analyse de
l'information.
II.2 DEFINITION D'UN DATA WAREHOUSE (DW) [8]
Un entrepôt de données est une collection de
données orientées sujet, intégrées, non volatiles
et historisées, organisées pour le support d'un processus d'aide
à la décision. Nous détaillons ces
caractéristiques
Orientées sujet : les données
des entrepôts sont organises par sujet plutôt que par application,
par exemple, une chaine de magasins d'alimentation organise les données
de son entrepôt par rapport aux ventes qui ont été
réalisées par produit et par magasin, au cours d'un certain
temps.
Intégrées : les données
provenant de différentes sources doivent être
intégrées, avant leur stockage dans l'entrepôt de
données. L'intégration, c'est à dire la mise en
correspondance des formats, permet d'avoir une cohérence de
l'information.
Non volatiles : à la différence
des données opérationnelles, celles de l'entrepôt sont
permanentes et ne peuvent pas être modifiées .le rafraichissement
de l'entrepôt consiste à ajouter de nouvelles données, sans
modifier ou perdre celles qui existent. historisées :la
prise en compte de l'évolution des données est essentielle pour
la prise de décision qui, par exemple, utilise des techniques de
prédication en s'appuyant sur les évolutions passées pour
prévoir les évolutions futures.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
12
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
II.2.1 OBJECTIF DU DATA WAREHOUSE [8]
L'atout principal d'une entreprise réside dans les
informations qu'elle possède. Les informations se présentent
généralement sous deux formes : les systèmes
opérationnels qui enregistrent les données et le Data Warehouse.
En bref, les systèmes opérationnels représentent
l'emplacement de saisie des données, et l'entrepôt de
données l'emplacement de restitution.
Ainsi voici les objectifs fondamentaux du data warehouse :
Rendre accessibles les informations de
l'entreprise : le contenu de l'entrepôt doit être
compréhensible et l'utilisateur doit pouvoir y naviguer facilement et
avec rapidité. Ces exigences n'ont ni frontières, ni limites. Des
données compréhensibles sont
pertinentes et clairement définies. Par données navigables, on
n'entend que l'utilisateur identifie immédiatement à
l'écran le but de ses recherches et accède au résultat en
un clic.
Rendre cohérente les informations d'une
l'entreprise : les informations provenant d'une branche de
l'entreprise peuvent être mise en corrélation avec celles d'une
autre branche. Si deux unités de mesure portent le même nom, elles
doivent alors signifier la même chose. A l'inverse, deux unités ne
signifiant pas la même chose doivent être définie
différemment. Une information cohérente suppose une information
de grande qualité. Cela veut dire que l'information est prise en compte
et qu'elle est complète.
Constituer une source d'information souple et
adaptable : l'entrepôt de données est conçu
dans la perspective de notifications perpétuelle, l'arrivé de
question nouvelles ne doit bouleverser ni les données existantes ni les
technologies. La conception de Data Mart distincts composant un entrepôt
de données doit être répartie et incrémentielle.
Représenter un bastion
sécurisé qui protège la capitale information :
l'entrepôt de données ne contrôle pas
seulement l'accès aux données, mais il offre à ses
gestionnaires une bonne visibilité des utilisations.
Constituer la base décisionnelle de
l'entreprise : l'entrepôt de données recèle
en son sein les informations propres à faciliter la prise de
décisions.
II.2.2 LES COMPOSANTS DE BASE DU DATA WAREHOUSE
? Le système source : système
opération d'enregistrement, dont la fonction consiste à capturer
les transactions liées à l'activité.
? Zone de préparation des données :
ensemble des processus qui nettoient, transforment, combinent,
archivent, suppriment les doublons, c'est-à-dire prépare les
données sources en vue de leur intégration puis de leur
exploitation au sein du Data Warehouse. La zone de préparation
des données ne doit offrir ni service des
requêtes, ni service de présentation.
? Serveur de présentation : machine
cible sur laquelle l'entrepôt de données est stocké et
organisé pour répondre en accès direct aux requêtes
émises par des utilisateurs, les générateurs d'état
et les autres applications.
? Data Mart : sous-ensemble logique d'un Data
Warehouse, il est destiné à quelques utilisateurs d'un
département.
? Entrepôt de données : source
de données interrogeable de l'entreprise. C'est tout simplement l'union
des Data Marts qui le composent. L'entrepôt de
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
13
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
données est alimenté par la zone de
préparation des données. L'administrateur de l'entrepôt de
données est également responsable de la zone de
préparation des données.
> OLAP (On Line Analytic Processing ) :
Activité globale de requêtage et de présentation de
données textuelles et numériques contenues dans l'entrepôt
de données ; style d'interrogation et de présentation
spécifiquement dimensionnel.
> ROLAP (Relational OLAP) : ensemble
d'interface utilisateur et
d'applications donnant une vision dimensionnelle
des bases de données relationnelles.
> MOLAP (Multidimensional OLAP) : ensemble
d'interface utilisateur et d'applications dont l'aspect dimensionnel est
prépondérant.
> Application utilisateur : ensemble
d'outils qui interrogent, analysent et présente des informations
répondant à un besoin spécifique. L'ensemble des outils
minimal se compose d'outil d'accès aux données, d'un tableur,
d'un logiciel graphique et d'un service d'interface utilisateur, qui suscite
les requêtes et simplifie la présentation de l'écran aux
yeux de l'utilisateur.
> Outil d'accès aux données :
client de l'entrepôt de données.
> Outil de requête : types
spécifique d'outil d'accès aux données qui invite
l'utilisateur à formuler ses propres requêtes en manipulant
directement les tables et leurs jointures.
> Application de modélisation :
type de client de base de données sophistiqués
doté de fonctionnalités analytiques qui transforment ou mettent
en forme les résultats obtenus ; on peut avoir :
o les modèles prévisionnels, qui tentent
d'établir des prévisions d'avenir ;
o les modèles de calcul comportemental, qui
catégorisent et classent les comportements d'achat ou d'endettement des
clients ;
o la plupart des outils de Data mining.
> Métadonnées : toutes
informations de l'environnement du Data Warehouse qui ne constituent pas les
données proprement dites.
II.3 CARACTERISTIQUES D'UN DATA WAREHOUSE [8]
Un Data Warehouse est une base de données conçue
pour l'interrogation et l'analyse plutôt que le traitement de
transactions. Il contient généralement des données
historiques dérivées de données transactionnelles, mais il
peut comprendre des données d'autres origines.
Les Data Warehouse séparent la charge d'analyse de la
charge transactionnelle. Ils permettent aux entreprises de consolider des
données de différentes origines.
Au sein d'une même entité fonctionnelle, le Data
Warehouse joue le rôle d'outil analytique.
En complément d'une base de données, un Data
Warehouse inclut une solution d'extraction, de transformation et de chargement
(ETL), des fonctionnalités de traitement analytique en ligne (OLAP) et
de Data mining, des outils d'analyse client et d'autres applications qui
gèrent le processus de collecte et de mise à la disposition de
données.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
14
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
II.4 ENTREPOTS ET BASES DE DONNEES [7]
Dans l'environnement des entrepôts de données,
les opérations, l'organisation des données, les critères
de performance, la gestion des métadonnées, la gestion des
transactions et le processus de requêtes sont très
différents des systèmes de bases de données
opérationnels.
Par conséquent, les SGBD relationnels orientés
vers l'environnement opérationnel, ne peuvent pas être directement
transplantés dans un système d'entrepôt de
données.
Les SGBD ont été crées pour les
applications de gestion de systèmes transactionnels. Par contre, les
entrepôts de données ont été conçus pour
l'aide a la prise de décision. Ils intègrent les informations qui
ont pour objectif de fournir une vue globale de l'information aux analystes et
aux décideurs.
Le tableau suivant résume les différences entre
les systèmes de gestion de bases de données et les
entrepôts de données.
|
SGBD
|
entrepôts de données
|
|
Objectifs
|
gestion et production
|
consultation et analyse
|
|
Utilisateurs
|
Gestionnaires de production
|
décideurs, analystes
|
|
Taille de la base
|
plusieurs giga-octets
|
plusieurs téraoctets
|
|
Organisation des
données
|
par traitement
|
par métier
|
|
type de données
|
Donnée de gestion (courantes)
|
données d'analyse
(résumées, historisées )
|
|
Requêtes
|
simples,
prédéterminées,
données
détaillées
|
complexes, spécifiques, agrégations et group by
|
|
Transactions
|
Courte et nombreuse, temps réel
|
longues ,peu nombreuses
|
Tableau II.1.Différence entre SGBD et entrepôts de
données
II.4.1 ROLE D'UN ENTREPOT DE DONNE
Le rôle primordiale d'un data warehouse apparait ainsi
évident dans une stratégie décisionnelle. L'alimentation
du data warehouse en est la phase la plus critique.
En effet, importer des données inutiles en portera de
nombreux problèmes, cela consommera des ressources système et du
temps. De plus, cela rendra le service d'analyse plus lent. Autre point
à prendre en compte est la périodicité d'extraction des
données ; effectivement, le plus souvent, les opérations de
collecte de données sont couteuses en ressource pour la base
accédée.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
15
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
II.4.2 SYSTEMES TRANSACTIONNELS ET SYSTEMES
DECISIONNELS
Les Système de Gestion de Base de Donnée (SGBD) ont
été créés pour gérer de grands volumes
d'information contenus dans les différents systèmes
opérationnels qui appartiennent a l'entreprise.
Ces données sont manipulées en utilisant des
processus transactionnels en ligne, .parallèlement à
l'exploitation de l'information contenue dans ces systèmes
opérationnels, les dirigeants des entreprises ont besoin d'avoir une
vision globale concernant toute cette information pour faire des calculs
prévisionnels, des statistiques ou pour établir des
stratégies de développement et d'analyses des tendances.
|
système transactionnel
|
système décisionnel
|
|
Données
|
Exhaustives courantes dynamiques
|
Résumées historiques statiques
|
|
orientées applications
|
orientées sujets
|
|
|
(d'analyse)
|
|
Utilisateurs
|
Nombreux
|
peu nombreux
|
|
varies (employés, directeurs)
|
uniquement les décideurs
|
|
concurrentes
|
non concurrents
|
|
mises à jour et interrogations
|
interrogations
|
|
requêtes prédéfinies
|
requêtes imprévisibles et complexes
|
|
réponses immédiates
|
réponses moins rapides
|
|
accès a peu d'information
|
accès a de nombreuses informations
|
Tableau II. 2. compare les caractéristiques des
systèmes
II.4.3 DIFFERENCE ENTRE LE SYSTEME OLTP ET LE DATA
WAREHOUSE [8]
Les Data Warehouse et les Systèmes OLTP (On Line
Transaction Processing) répondent à besoins très
différents. Les Data Warehouse conçu pour prendre en charge des
interrogations ad hoc. La taille du Data Warehouse n'est pas connue
à l'avance. Par conséquent, celui-ci doit être
optimisé pour offrir de bonnes performances dans le cadre
d'opérations d'interrogation très diverses. Les systèmes
OLTP prennent généralement en charge des opérations
prédéfinies. Les applications peuvent être
réglées ou conçues spécifiquement pour ces
opérations.
Un Data Warehouse est mise à jour
régulièrement par les processus ETL (Extraction, Transformation
and Loading), un système de chargement de données en masse
soigneusement défini et contrôlé. Il n'est pas mise
à jour directement par les utilisateurs. Dans les systèmes OLTP,
les utilisateurs exécutent régulièrement des instructions
qui modifient les données de la base. La base de données OLTP est
à jour en permanence et elle reflète l'état actuel de
chaque transaction.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
16
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Les Data Warehouse utilisent souvent des schémas
dénormalisés ou partiellement dénormalisés (tels
que le schéma en étoile) pour optimiser les performances des
interrogations. A l'inverse, les systèmes OLTP ont souvent recours
à des schémas totalement normalisés pour optimiser les
performances des opérations de mise à jour, d'insertion et de
suppression, et pour garantir la cohérence des données. Il s'agit
là des différences générales, elles ne doivent pas
être considérées comme des distinctions strictes et
absolues.
De manière générale, une interrogation
portant sur un Data Warehouse balaye des milliers voire des millions de lignes.
En revanche, une opération OLTP standard accède à quelque
enregistrement seulement.
Le Data Warehouse contient généralement des
données correspondant à plusieurs mois ou années. Cela
permet d'effectuer des analyses historiques. Les systèmes OLTP
contiennent généralement des données quelque semaine ou
mois. Ils conservent uniquement des données historiques
nécessaires à la transaction en cours.
II.4.4 La problématique de l'entreprise [8]
L'entreprise construit un système décisionnel
pour améliorer sa performance, elle doit décider et anticiper en
fonction de l'information disponible et capitaliser sur ses
expériences.
Entreprise : est une organisation
dotée d'une mission et d'un objectif métier. Elle doit sa raison
d'être et /ou sa pérennité au travers de différent
objectifs (sécurité, développement, rentabilité
...). Par voie de conséquence, cette organisation humaine est
dotée d'un centre décision.
Rôle de décideur : il peut
être le responsable de l'entreprise, le responsable d'une fonction ou
d'un secteur. Il est donc celui qui engage la pérennité
ou la raison d'être de l'entreprise. Pour ces raisons, il
doit s'entourer de différents moyens lui permettant une prise de
décision la plus pertinente. Parmi ces moyens, les Data Warehouse ont
une place primordiale.
II.4.5 LA MODELISATION DIMENSIONNELLE ET LA MODELISATION
ENTITE/RELATION [5, 8]
a) Modélisation Entité/Relation :
est une discipline qui permet d'éclairer les relation
microscopique entre les données. Dans sa forme la plus artistique, elle
permet de supprimer toute redondance de données. Ceci apporte de
nombreux avantages au niveau du traitement des transactions, qui deviennent
alors très simples et déterministes.
b) Modélisation dimensionnelle :
est une méthode de conception logique qui vise à
présenter les données sous une forme standardisée
intuitive et qui permet des accès hautement performants. Elle
adhère totalement à la dimensionnalité ainsi qu'à
une discipline qui exploite le modèle relationnel en le limitant
sérieusement. Chaque modèle dimensionnel se compose d'une table
contenant une clé multiple, table des faits,
et d'un ensemble de tables plus petite nommées,
tables dimensionnelles.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
17
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Chacune de ces dernières possède une clé
primaire unique, qui correspond exactement à l'un des composants de la
clé multiple de la table des faits. Dans la mesure où elle
possède une clé primaire multiple reliée à au moins
deux clés externes, la table des faits exprime toujours une
relation n, n (plusieurs-à-plusieurs).
II.4. 6 RELATION ENTRE LA MODELISATION DIMENSIONNELLE ET LA
MODELISATION ENTITE/RELATION
Pour mieux appréhender la relation qui existe entre la
modélisation dimensionnelle et la modélisation
entité/relation, il faut comprendre qu'un seul schéma
entité/relation se décompose en plusieurs schémas de table
des faits.
La modélisation dimensionnelle ne se met pas à
son avantage en représentant sur un même schéma plusieurs
processus qui ne coexistent jamais au sein d'une série de données
et à un moment donné. Ce qui le rend indûment complexe.
Ainsi, la conversion d'un schéma entité/relation en une
série de schémas décisionnels consiste à scinder le
premier en autant de sous-schémas qu'il y a de processus métier
puis de les modéliser l'un après l'autre. La deuxième
étape consiste à sélectionner les relations n, n
(plusieurs-à-plusieurs) contenant des faits numériques et
additifs (autres que les clés) et d'en faire autant de table des
faits.
La troisième étape consiste à
dénormalisés toutes les autres tables en table non
séquentielle dotées de clés uniques qui les relient
directement aux tables des faits. Elles deviennent ainsi des tables
dimensionnelles. S'il arrive qu'une table dimensionnelle soit reliée
à plusieurs tables des faits, nous représentons cette table
dimensionnelle dans les deux schémas et dirons des tables
dimensionnelles qu'elles sont conformes d'un modèle à l'autre.
II.4.6.1 AVANTAGES DE LA MODELISATION DIMENSIONNELLE
[8]
Le modèle dimensionnel possède un grand nombre
d'avantages dont le modèle entité/relation est
dépourvu.
Premièrement, le modèle dimensionnel est une
structure prévisible et standardisée. Les
générateurs d'états, outils de requête et interfaces
utilisateurs peuvent reposer fortement sur le modèle dimensionnel pour
faire en sorte que les interfaces utilisateurs soient plus
compréhensibles et que le traitement soit optimisé.
La deuxième force du modèle dimensionnel est que
la structure prévisible du schéma en étoile réside
aux changements de comportement inattendus de l'utilisateur. Toutes les
dimensions sont équivalentes.
La troisième avantage du modèle dimensionnel
réside dans le fait qu'il est extensible à loisir pour accueillir
des données et des besoins d'analyse non prévus au départ.
Ainsi, il est possible d'accomplir :
Ajouter des faits nouveaux non prévus initialement ;
Ajouter des dimensions totalement nouvelles ;
Ajouter des attributs dimensionnels nouveaux non prévus
initialement ;
Décomposer les enregistrements d'une dimension
existante en un niveau de détail plus fin à partir d'une date
déterminée ;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
18
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
II.5 SCHEMAS D'UN DATA WAREHOUSE [8]
Un schéma est un ensemble d'objets de la base de
données tels que les tables, des vues, des vues
matérialisées, des index et des synonymes. La conception du
schéma d'un Data Warehouse est guidée par le modèle des
données source et par les besoins utilisateurs.
L'idée fondamentale de la modélisation
dimensionnelle est que presque tous les types de données peuvent
être représentés dans un cube de données, dont les
cellules contiennent des valeurs mesurées et les angles les dimensions
naturelles de données. Nos conceptions peuvent comporter plus de trois
dimensions. Techniquement, il faudrait parler d'hypercube, bien que le
terme cube de données ait été adopté par
le métier.
a) les objets d'un schéma de Data
Warehouse
Les deux types d'objet les plus courants dans les
schémas de Data Warehouse multidimensionnels sont les tables de faits et
les tables de dimension.
? Tables de faits : une table de faits
comprend généralement des colonnes de deux types : celles qui
contiennent des faits numériques (souvent appelés indicateurs) et
celles qui servent de clé étrangère vers les tables de
dimension. Une table de faits peut contenir des faits détaillés
ou agrégées. Les tables contenant des faits agrégés
sont souvent appelées tables agrégées. une table
de faits contient généralement de faits de même niveau
d'agrégation. La plupart des faits sont additifs, mais ils peuvent
être semi-additifs ou non additifs. Les faits additifs peuvent être
agrégés par simple addition arithmétique. C'est par
exemple le cas des ventes. Les faits non additifs ne peuvent pas être
additionnés du tout. C'est le cas des moyennes. Les faits semi-additifs
peuvent être agrégés selon certaines dimensions mais pas
selon d'autres. C'est le cas, pas exemple des niveaux de stock. Une table de
faits doit être définie pour chaque schéma. Du point de vue
de la modélisation, la clé primaire de la table de faits est
généralement une clé composée qui est formée
de toutes les clés étrangères associées.
? Tables de dimensions et hiérarchies :
une dimension est une structure comprenant une ou plusieurs
hiérarchies qui classe les données en catégories. Les
dimensions sont des étiquettes descriptives fournissant des informations
complémentaires sur les faits, qui sont stockées dans les tables
de dimension. Il s'agit normalement de valeurs textuelles descriptives.
Plusieurs dimensions distinctes combinées avec les faits permettant de
répondre aux questions relatives à l'activité de
l'entreprise. Les données de dimension son généralement
collectées au plus bas niveau de détail, puis
agrégées aux niveaux supérieurs en totaux plus
intéressants pour l'analyse, ces agrégations ou cumuls naturels
au sein d'une table de dimension sont appelés des
hiérarchies. Les hiérarchies
sont des structures logiques qui utilisent les niveaux ordonnées pour
organiser les données. Pour une dimension temps, par exemple, une
hiérarchie peut agréger les données selon le niveau
mensuel, le niveau trimestriel, le niveau annuel.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
19
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Au sein d'une hiérarchie, chaque niveau est
connecté logiquement aux niveaux supérieurs et inferieurs. Les
valeurs des niveaux inferieurs sont agrégées en valeurs de niveau
supérieur.
a) Le Schéma en Etoile
Le schéma en étoile peut être le type le
plus simple de schéma de Data Warehouse, il est dit en étoile
parce que son diagramme entité/relation ressemble à une
étoile, avec des branches partant d'une table centrale. Un schéma
en étoile est caractérisé par une ou plusieurs tables de
faits, très volumineuses, qui contiennent les informations essentielles
du Data Warehouse et par un certain nombre de tables de dimension, beaucoup
plus petites, qui contiennent chacune des informations sur les entrées
associées à un attribut particulier de la table de faits. Une
interrogation en étoile est une jointure entre une table de faits et un
certain nombre de table de dimensions. Chaque table de dimension est jointe
à la table de faits à l'aide d'une jointure de clé
primaire à clé étrangère, mais les tables de
dimension ne sont pas jointes entre elles.
Les schémas en étoile présentent les
avantages suivants : ils fournissent une correspondance directe et intuitive
entre les entités fonctionnelles analysées par les utilisateurs
et la conception du schéma. Ils sont pris en charge par un grand nombre
d'outils décisionnels. La manière la plus naturelle de
modéliser un Data Warehouse est la représenter par un
schéma en étoile dans lequel une jointure unique établit
la relation entre la table de faits et chaque table de dimension. Un
schéma en étoile optimise les performances en contribuant
à simplifier les interrogations et à raccourcir les temps de
réponse.
Les schémas en étoile présentent
néanmoins quelques limites. La table centrale peut devenir très
volumineuse, sa taille maximale étant déterminée par le
produit des nombres de lignes des tables de dimension. En outre, les tables de
dimension ne sont plus normalisées. Elles sont donc plus volumineuses et
plus difficiles à tenir à jour car elles contiennent beaucoup de
données dupliquées.
|
EX :
|
|
|
|
|
|
|
|
|
|
Dimensions 2 Id_dim2
|
|
Dimensions 1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Id_dim1
|
|
|
|
|
|
|
|
|
|
|
|
|
Table des Faits
|
|
|
|
|
|
|
|
|
Id_f (Pk) Id_dim1 (Fk) Id_dim2 (Fk)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Dimensions 3
|
|
Dimensions 4 Id_dim4
|
|
|
|
|
|
Id_dim3
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Fig.II .1 : schéma d'un modèle en étoile
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
20
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
b) Le Schéma en Flocon
Les schémas en flocons normalisent les dimensions pour
éliminer les redondances. Autrement dit, les données de dimension
sont stockées dans plusieurs tables et non dans une seule table de
grande taille. Cette structure de schéma consomme moins d'espace disque,
mais comme elle utilise davantage de tables de dimension, elle nécessite
un plus grand nombre de jointures de clé secondaire. Les interrogations
sont par conséquent plus complexes et moins performantes.
Dans un schéma en flocon, cette même table de
faits, référence les tables de dimensions de premier niveau, au
même titre que le schéma en étoile.
La différence réside dans le fait que les
dimensions sont décrites par une succession de tables (à l'aide
de clés étrangères) représentant la
granularité de l'information. Ce schéma évite les
redondances d'information mais nécessite des jointures lors des
agrégats de ces dimensions.
Dimensions 1
Id_dim1
Dimensions 4
Id_dim4
Dimensions 5
Dimensions 2
Id_dim5

Table des Faits
Id_dim2
Id_dim 5

Dimensions 3
Id_dim3
Id_dim 6
Id_f (Pk) Id_dim1 (Fk) Id_dim2 (Fk)
Dimensions 6
Id_dim 6
Le principal avantage du schéma en flocons est une
amélioration des performances des interrogations due à des
besoins réduits en espace de stockage sur disque et la petite taille des
tables de dimension à joindre. Le principal inconvénient de ce
schéma est le travail de maintenance supplémentaire imposé
par le nombre accru de tables de dimension. EX :
Fig II.2 : schéma d'un modèle en flocon
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
21
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
d) schéma multi dimensionnel
(CUBE)
Dans le modèle multidimensionnel, le concept central
est le cube, lequel est constitue des éléments appelés
cellules qui peuvent contenir une ou plusieurs mesures. La localisation de la
cellule est faite a travers les axes, qui correspondent chacun a une
dimension.
La dimension est composée de membres qui
représentent les différentes valeurs.
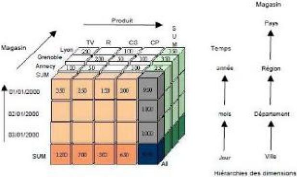
Fig. II. 3:Exemple de schéma multidimensionnel
La figure II. 3, présente un schéma
multidimensionnel pour les ventes qui ont été
réalisées dans les magasins pour les différents produits
au cours d'un temps donné (jour).
II.6 LE DATA MART [1, 8,]
II.6.1 INTRODUCTION
Un DataMart est un sous-ensemble d'un entrepôt de
données; il est généralement exploité dans les
entreprises pour restituer des informations ciblées sur un métier
spécifique, constituant pour ce dernier un ensemble d'indicateurs
à vocation de pilotage de l'activité et d'aide à la
décision. Un DataMart, selon les définitions, est issu ou fait
partie d'un Data Warehouse, et en reprend par conséquent la plupart des
caractéristiques.
II.6.2 LES DEFINITIONS [8]
Le DataMart est un ensemble de données ciblées,
organisées, regroupées et agrégées pour
répondre à un besoin spécifique à un métier
ou un domaine donné. Il est donc destiné à être
interrogé sur un panel de données restreint à son domaine
fonctionnel, selon des paramètres qui auront été
définis à l'avance lors de sa conception.
De façon plus technique, le DataMart peut être
considère de deux manières différentes, attribuées
aux deux principaux théoriciens de l'informatique décisionnelle,
bill inmon et Ralph Kimball :
Définition d'inmon : le DataMart est issu d'un flux de
données provenant du Data Warehouse. Contrairement a ce dernier qui
présente le détail des données pour toute
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
22
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
l'entreprise, il a vocation à présenter la
donnée de manière spécialisée,
agrégée et regroupée fonctionnellement.
Définition de Kimball : le DataMart est un
sous-ensemble du Data Warehouse, constitue de tables au niveau détail et
à des niveaux plus agrèges, permettant de restituer tout le
spectre d'une activité métier. L'ensemble des DataMarts de
l'entreprise constitue le Data Warehouse.
II.6.3 LA PLACE DU DATAMART DANS L'ENTREPRISE
Le DataMart se trouve en toute fin de la chaine de traitement
de l'information. En règle générale, il se situe en aval
d'un DataWarehouse plus global à partir duquel il est alimenté,
dont il constitue en quelque sorte un extrait.
Un DataMart forme la principale interaction entre les
utilisateurs et les systèmes informatiques qui gèrent la
production de l'entreprise (souvent des ERP).
Dans un DataMart, l'information est préparée
pour être exploitée brute par les personnes du métier
auquel il se rapporte. Pour ce faire, il est appelé a être utilise
via des logiciels d'interrogation de bases de données (notamment des
outils de reporting) afin de renseigner ses utilisateurs sur l'état de
l'entreprise à un moment donné (stock) ou sur son activité
(flux).
La préparation de la donnée pour une utilisation
directe, inhérente au DataMart, peut revêtir plusieurs formes. Il
faut noter que toutes représentent une simplification par rapport au
niveau de données inferieur ; on peut citer pour exemple :
L'agrégation de données : le DataMart ne
contient pas le détail de toutes les opérations qui ont eu lieu,
mais seulement des totaux, repartis par groupements.
Le retrait de données inutiles : le DataMart ne
contient que les données qui sont strictement utiles aux
utilisateurs.
L'historisation des données : le DataMart contient
seulement la période de temps qui intéresse les utilisateurs.
II.6.4 DATAWAREHOUSE ET DATAMART [1]
La première étape d'un projet busines
intelligent est de créer un entrepôt central pour avoir une vision
globale des données de chaque service. Cet entrepôt porte le nom
de DataWarehouse.
On peut également parler de DataMart, si seulement une
catégorie de services ou métiers est concernée.
Par définition, un DataMart peut être contenu
dans un DataWarehouse, ou il peut être seulement issu de celui-ci.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
23
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
II.6.4 ARCHITECTURE D'UN DATAMART
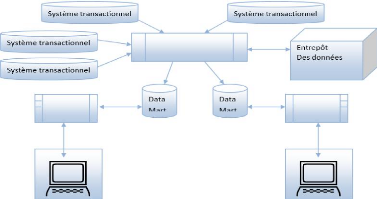
Système transactionnel
Fig. II.4: Architecture d'un Data Mart
II.6.5 Data Warehouse versus Data Mart
|
Data Warehouse
|
Data Mart
|
|
Utilisation globale de l'entreprise
|
Utilisé par un département ou une unité
fonctionnelle
|
|
Difficile et plus long à implémenter
|
Plus facile et rapide à implémenter
|
|
Volume de données plus important
|
Volume de données plus petit et
spécialisé
|
|
Développé sur la base de données
actuelle
|
Développé sur les bases des besoins
utilisateurs
|
Les Data Marts représentent de toute évidence
une réponse rapide aux besoins des différents départements
de l'entreprise. Leur coût moindre et leur facilité d'emploi
permettent une implémentation rapide et un retour à
l'investissement presque immédiat. Il faut toute fois être prudent
lorsque des Datamarts sont ainsi crées pour plusieurs divisions. Ces
dernières utilisent souvent des représentations
différentes de certains concepts de gestion. Par exemple, les
départements finances et marketing peuvent tous deux effectué un
suivi des ventes réalisées par l'entreprise, mais défini
différemment ce concept. Plus tard, si un employé du marketing a
besoin de recueillir certaines informations à partir du Data Marts des
finances, l'entreprise sera confrontée à un problème. Par
conséquent, une vision unifiée est nécessaire même
pour concevoir des Datamarts par département.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
24
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
II.7 LES SERVEURS OLAP (ON-LINE ANALYTICAL
PROCESSING)
Les données opérationnelles constituent la
source principale d'un système d'information décisionnel. Les
systèmes décisionnels complets reposent sur la technologie OLAP,
conçue pour répondre aux besoins d'analyse des applications de
gestion.
Nous exposons dans la suite les divers types de stockage des
informations dans les systèmes décisionnels.
II.7.1 LES SERVEUR ROLAP (RELATIONAL OLAP)

Fig. II. 5: Architecture ROLAP
Dans les systèmes relationnels OLAP, l'entrepôt
de données utilise une base de données relationnelle. Le stockage
et la gestion de données sont relationnels. Le moteur ROLAP traduit
dynamiquement le modèle logique de données multidimensionnel
m en modèle de stockage relationnel r, la plupart des
outils requièrent que la donnée soit structurée en
utilisant un schéma en étoile ou un schéma en flocon de
neige.
La technologie ROLAP a deux avantages principaux :
1) elle permet la définition de données
complexes et multidimensionnelles en utilisant un modèle relativement
simple.
2) elle réduit le nombre de jointures à
réaliser dans l'exécution d'une requête.
Le désavantage est que le langage de requêtes tel
qu'il existe, n'est pas assez puisant ou n'est pas assez flexible pour
supporter de vraies capacités d'OLAP.
II.7.2 LES SERVEUR MOLAP (MULTIDIMENSIONAL OLAP)
Les systèmes multidimensionnels OLAP utilisent une base
de données multidimensionnelle pour stocker les données de
l'entrepôt et les applications analytiques sont construites directement
sur elle. Dans cette architecture, le système de base de données
multidimensionnel sert tant au
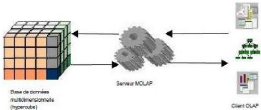
Niveau de stockage qu'au niveau de gestion des données.
Les données des sources sont conformes au modèle
multidimensionnel, et dans toutes les dimensions, les différentes
agrégations sont pour le calculées pour des raisons de
performance.
Fig.II.6:Architecture MOLAP
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
25
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Les systèmes MOLAP doivent gérer le
problème de données clairsemées, quand seulement un nombre
réduit de cellules d'un cube contiennent une valeur de mesure
associée.
Les avantages des systèmes MOLAP sont bases sur les
désavantages des systèmes ROLAP et elles représentent la
raison de leur création. D'un cote, les requêtes MOLAP sont
très puissantes et flexibles en termes du processus OLAP, tandis que,
d'un autre cote, le modèle physique correspond plus étroitement
au modèle multidimensionnel. Néanmoins, il existe des
désavantages au modèle physique MOLAP. Le plus important, a notre
avis, c'est qu'il n'existe pas de standard du modèle physique.
II.7.3 LES SERVEUR HOLAP (HYBRID OLAP)
Un système HOLAP est un système qui supporte et
intègre un stockage des données multidimensionnel et relationnel
d'une manière équivalente pour profiter des
caractéristiques de correspondance et des techniques d'optimisation donc
c'est l'ensemble des deux serveurs MOLAP et ROLAP.
Dans la figure 7, nous montrons une architecture en utilisant
les types de serveurs ROLAP et MOLAP pour le stockage de données.
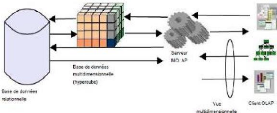
Fig. II.7:Architecture HOLAP
Nous traitons une liste des caractéristiques
principales qu'un système HOLAP doit fournir :
La transparence du système : Pour la localisation et
l'accès aux données, sans connaître si elles sont
stockées dans un SGBD relationnel ou dimensionnel. Pour la transparence
de la fragmentation.
Un modèle de données général et un
schéma multidimensionnel global :
Pour aboutir à la transparence du premier point, tant
le modèle de données général que le langage de
requête uniforme doivent être fournis. Etant donné qu'il
n'existe pas un modèle standard, cette condition est difficile à
réaliser.
Une allocation optimale dans le système de stockage : Le
système HOLAP Doit bénéficier des stratégies
d'allocation qui existent dans les systèmes distribués tels que :
le profil de requêtes, le temps d'accès, l'équilibrage de
chargement.
Une réallocation automatique : Toutes les
caractéristiques traitées ci-dessus
Changent dans le temps. Ces changements peuvent provoquer la
réorganisation de la distribution des données dans le
système de stockage multidimensionnel et relationnel, pour assurer des
performances optimales.
Actuellement, la plupart des systèmes commerciaux
utilisent une approche hybride. Cette approche permet de manipuler des
informations de l'entrepôt de données avec un
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
26
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
moteur ROLAP, tandis que pour la gestion des DataMarts,
ils utilisent l'approche multidimensionnelle.
CONCLUSION PARTIELLE
Dans ce chapitre, nous avons traité l'entrepôt de
données et le data mart. Nous avons donnés l'architecture d'un
entrepôt de données et celle du data mart. Nous avons
expliqué les différents composants qu'il intègre, les
types de données et les différents outils pour arriver à
la visualisation de l'information.
Nous avons décrit les différents modèles
multidimensionnels pour la construction d'un entrepôt de données,
ainsi que les différentes opérations pour la manipulation des
données multidimensionnelles et le parallélisme entre le deux,
nous avons présenté l'apport de DataMart dans les entreprises.
Nous avons décrit le serveur ROLAP qui utilise une base
de données relationnelle, tant au niveau du stockage qu'au niveau de la
gestion de données.
Le serveur MOLAP a été la deuxième
architecture que nous avons traitée.
Ces types de systèmes utilisent une base de
données multidimensionnelle pour le stockage des données. La
troisième architecture que nous avons décrite est le serveur
HOLAP et quelque caractéristique de ce types serveur.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
27
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
CHAP III DATA MINING ET ARBRE DE DECISION [2, 3, 4, 8,
13]
III.0 INTRODUCTION
Le terme datamining est souvent employé pour
désigner l'ensemble des outils permettant à l'utilisateur
d'accéder aux données de l'entreprise, de les analyser. Nous
retiendrons ici le terme de data mining aux outils ayant pour objet de
générer des informations riches à partir des
données de l'entreprise, notamment des données historiques, de
découvrir des modèles implicites dans les données.
Ces outils peuvent permettre par exemple à un magasin
de dégager des profils de client et des achats types et de
prévoir ainsi les ventes futures. Ils permettent d'augmenter la valeur
des données contenues dans le DataWarehouse.
Les outils d'aides à la décision, qu'ils soient
relationnels ou OLAP, laissent l'initiative à l'utilisateur, de choisir
les éléments qu'il veut observer ou analyser .Au contraire ,dans
le cas du datamining ,le système a l'initiative et découvre
lui-même les associations entre données ,sans que l'utilisateur
ait à lui dire de rechercher plutôt dans telle ou telle direction
ou à poser des hypothèses .
Il est alors possible de prédire l'aveni, par le
comportement d'un client, et de détecte, dans le passé, les
données inusuelles, exceptionnelles.
Ces outils ne sont plus destinés aux seuls experts
statisticiens mais doivent pouvoir être employés par des
utilisateurs connaissant leur métier et voulant l'analyser,
l'explorer.
Seul un utilisateur connaissant le métier peut
déterminer si les modèles, les règles, les tendances
trouvées par l'outil sont pertinentes, intéressantes et utiles
à l'entreprise. Nous pourrions définir le data mining comme une
démarche ayant pour objet de découvrir des relations et des
faits, à la fois nouveaux et significatifs, sur de grands ensembles de
données.
Le terme data mining signifie littéralement forage de
données dont le but est de pouvoir extraire un élément :
la connaissance.
Ces concepts s'appuient sur le constat qu'il existe au sein de
chaque entreprise des informations cachées dans le gisement de
données. Nous appellerons datamining l'ensemble des techniques qui
permettent de transformer les données en connaissances. L'exploration se
fait sur l'initiative du système, par un utilisateur métier, et
son but est de remplir l'une des tâches suivantes : Classification,
estimation, prédiction, regroupement par similitudes, segmentation
(cautérisation), description et, dans une moindre mesure,
l'optimisation.
III.1 OBJECTIFS DU DATA MINING [8]
Les objectifs du Data Mining peuvent être regroupés
dans trois axes importants:
1. Prédiction (What-if) : consiste à
prédire les conséquences d'un événement (ou d'une
décision), se basant sur le passé.
2. Découverte de règles cachées :
découvrir des règles associatives, entre différents
événements (Exemple : corrélation entre les ventes de deux
produits).
3. Confirmation d'hypothèses : confirmer des
hypothèses proposées par les analystes et décideurs, et
les doter d'un degré de confiance.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
28
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
En considérant le serveur de base données ou le
serveur d'entrepôt de données, le Data mining est
considéré comme un client riche de ces deux serveurs. Notons que
le client serveur est un mode de dialogue entre deux processus, l'un
appelé client qui sollicite des services auprès de l'autre
appelé serveur, par envoie des requêtes (send request en anglais).
Après avoir lancé une requête par rapport au fait à
analyser, le client data ming applique des méthodes ou procédures
sur les données obtenues, afin d'obtenir les informations
nécessaires pour la prise de décision. Ces procédures ou
méthodes, sont classées en deux catégories :
Apprentissage non supervisé et l'apprentissage
supervisé en dehors de ces deux s'ajoute l'autre qui est
l'apprentissage automatique.
a) Apprentissage non supervisé
:
Elle consiste à mettre en évidence les
informations cachées par le grand volume de données, en vue de
détecter dans ces données des tendances cachées. Les
techniques utilisées sont : La segmentation (Clustering en anglais),
L'analyse à composante principale, l'analyse factorielle de
correspondance.
b) Apprentissage supervisé :
L'apprentissage supervisé consiste à extrapoler
des nouvelles connaissances à partir de l'échantillon
représentatif issu de l'apprentissage non supervisé. Les
techniques utilisées sont : Les réseaux de neurones, le SVM,
l'arbre de décision, les réseaux de bayes, etc.
c) Apprentissage automatique :
L'apprentissage automatique (machine learning en
anglais), un des champs d'étude de l'intelligence artificielle, est la
discipline scientifique concernée par le développement, l'analyse
et l'implémentation de méthodes automatisables qui permettent
à une machine (au sens large) d'évoluer grâce à un
processus d'apprentissage, et ainsi de remplir des tâches qui sont
difficiles ou impossible d'être réalisées par des moyens
algorithmiques plus classiques.
Des systèmes complexes peuvent être
analysés, y compris pour des données associées à
des valeurs symboliques (ex: sur un attribut numérique, non pas
simplement une valeur numérique, juste un nombre, mais une valeur
probabilisée, c'est-à-dire un nombre assorti d'une
probabilité ou associé à un intervalle de confiance) ou un
ensemble de modalités possibles sur un attribut numérique ou
catégoriel.
L'analyse peut même concerner des données
présentées sous forme de graphes ou d'arbres, ou encore de
courbes (par exemple, la courbe d'évolution temporelle d'une mesure ; on
parle alors de données continues, par
opposition aux données discrètes
associées à des attributs-valeurs classiques).
Le premier stade de l'analyse est celui de la
classification, qui vise à « étiqueter »
chaque donnée en l'associant à une classe.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
29
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
III.1 .2 PROCESSUS DU DATAMINING
Le datamining est un processus méthodique : une suite
ordonnée d'opérations aboutissant à un résultat.
Le data ming est décrit comme un processus
itératif complet constitué de quartes divisées en six
phases qui sont représenté dans le tableau suivant :
|
PROCESSUS DU DATA MINING
|
|
Acteur
|
Etapes
|
Phases
|
|
Maitre d'oeuvre
|
Objectifs
|
1. Compréhension du métier :
|
|
2. Compréhension des données
|
|
|
|
Traitements
|
4 .Modélisation
|
|
5.Evaluation de la modélisation
|
|
Maître d'ouvrage
|
Déploiement
|
6. Déploiement des résultats de l'étude
|
Tableau .III .1: le processus du datamining.
a) Compréhension du Métier :
Cette phase consisté à :
Enoncer clairement les objectifs globaux du projet et les
contraintes de l'entreprise.
Traduire ses objectifs et ses contraintes en un problème
de data mining
Préparer une stratégie initiale pour atteindre ces
objectifs.
b) Compréhension des données
Cette phase consiste à :
Recueillir les données, utiliser l'analyse
exploratoire pour se familiariser avec les données, commencé
à les comprendre et imaginer ce qu'on pourrait en tirer comme
connaissance. Evaluer la qualité des données, Eventuellement,
sélectionner des sous ensembles intéressants.
c) Préparation des données
Cette phase aide à préparer, à partir
des données brutes, l'ensemble final des données qui va
être utilisé pour toutes les phases suivantes :
Sélectionner les cas et les variables à analyser,
réaliser si nécessaire les
transformations de certaines données, réaliser si
nécessaire la suppression de certaines données.
d) Modélisation
La phase de la modélisation consiste à :
Sélectionner les techniques de modélisation
appropriées (pouvant être utilisées pour le même
problème) calibrer les paramètres des techniques de
modélisation choisies pour optimiser les résultats ;
Eventuellement revoir la préparation des données
pour l'adapter aux techniques utilisées.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
30
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
e) Evaluation de la modélisation
? Pour chaque technique de modélisation
utilisée, évaluer la qualité (la pertinence) des
résultats obtenus ;
? Déterminer si les résultats obtenus
atteignent les objectifs globaux identifiés pendant la phase de
compréhension du métier ;
? Décider si on passe à la phase suivante (le
déploiement) ou si on souhaite reprendre l'étude en
complétant le jeu de données.
f) Déploiement des résultats obtenus
Cette phase est externe à l'analyse du datamining .Elle
concerne le maître d'ouvrage. Prendre les décisions en
conséquence des résultats de l'étude de data mining
Préparer la collecte des informations futures pour
permettre de vérifier la pertinence des décisions effectivement
mis en oeuvre.
III.1 .3 LES TACHES DU DATA MING
Contrairement aux idées reçues, le Data Mining
n'est pas le remède miracle capable de résoudre toutes les
difficultés ou besoins de l'entreprise cependant, une multitude de
problèmes d'ordre intellectuel, médical, économique
peuvent être regroupés, dans leurs formalisations, dans l'une des
tâches suivantes :
1. Classification
2. Estimation
3. Prédiction
4. Discrimination
5. Segmentation
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
31
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
III.I.3.1 LES TACHES ET TECHNIQUE DU DATAMINING
|
TACHES
|
TECHNIQUE
|
|
Classification
|
L'arbre de décision
|
|
Le raisonnement par cas
|
|
L'analyse de lien
|
|
Estimation
|
Le réseau de neurones
|
|
Prédiction
|
L'analyse du panier de la ménagère
|
|
Le raisonnement base sur le mémoire
|
|
L'arbre de décision
|
|
Les réseaux de neurones
|
|
Extraction de connaissance
|
L'arbre de décision
|
Tableau III 2:le taches et technique du datamining.
En outre, hormis ces quelques techniques et tâches du
datamining, nous signalons qu'il existe d'autres que nous n'avons pas
énumérez dans notre travail.
III .2 ARBRE DE DECISION [4, 9]
III .2.1 INTRODUCTION A L'ARBRE DE DECISION
Un arbre de décision est une structure qui permet de
déduire un résultat à partir de décisions
successives. Pour parcourir un arbre de décision et trouver une
solution, il faut partir de la racine. Chaque noeud est une décision
atomique.
Proche en proche, on descend dans l'arbre jusqu'à
tomber sur une feuille. La feuille représente la réponse
qu'apporte l'arbre au cas où l'on vient de tester.
Début à la racine de l'arbre
Descendre dans l'arbre en passant par les noeuds de test, la
feuille atteinte à la fin permet de classer l'instance testée.
Très souvent on considère qu'un noeud pose une question sur une
variable, la valeur de cette variable permet de savoir sur quels fils
descendre. Pour les variables énumérées, il est parfois
possible d'avoir un fils par valeurs, on peut aussi décider que
plusieurs variables différentes mènent au même sous
arbre.
Pour les variables continues, il n'est pas imaginable de
créer un noeud qui aurait potentiellement un nombre de fils infini, on
doit discrétiser le domaine continu (arrondis, approximation), donc
décider de segmenter le domaine en sous ensembles. Plus l'arbre est
simple, et plus il semble techniquement rapide à utiliser.
En fait, il est plus intéressant d'obtenir un arbre qui
est adapté aux probabilités des variables à tester. La
plupart du temps un arbre équilibré sera un bon
résultat.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
32
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Si un sous arbre ne peut mener qu'à une solution
unique, alors tout ce sous-arbre peut être réduit à sa
simple conclusion, cela simplifie le traitement et ne change rien au
résultat final.
III .2.2 DEFINITION
Un arbre de décision est un outil d'aide à la
décision et à l'exploration de données. Il permet de
modéliser simplement, graphiquement et rapidement un
phénomène mesuré plus ou moins complexe. Sa
lisibilité, sa rapidité d'exécution et le peu
d'hypothèses nécessaires a priori expliquent sa popularité
actuelle.
III .2.3 CARACTERISTIQUES ET AVANTAGES :
Le caractéristique principale est la lisibilité
du modèle de prédiction que l'arbre de décision fourni, et
de faire comprendre ses résultats afin d'emporter l'adhésion des
décideurs.
Cet arbre de décision à également la
capacité de sélectionner automatiquement les variables
discriminantes dans un fichier de données contenant un très grand
nombre de variables potentiellement intéressantes. En ce sens, constitue
aussi une technique exploratoire privilégiée pour
appréhender de gros fichiers de données.
III .2.4 ALGORITHME ID3 [4, 13]
L'algorithme ID3 à été
développé à l'origine par ROSS QUINLAN. C'est un
algorithme de classification supervisé. C'est-a-dire il se base sur des
exemples déjà classés dans un ensemble de classes pour
déterminer un modèle de classification. Le modèle que
produit ID3 est un arbre de décision. Cet arbre servira à classer
de nouveaux échantillons. Il permet aussi de générer des
arbres de décisions à partir de données. Imaginons que
nous ayons à notre disposition un ensemble d'enregistrements ayant la
même structure, à savoir un certain nombre de paires attribut ou
valeur. L'un de ses attributs représente la catégorie de
l'enregistrement. Le problème consiste à construire un arbre de
décision qui sur la base de réponses à des questions
posées sur des attributs non cible peut prédire correctement la
valeur de l'attribut cible. Souvent l'attribut cible pend seulement les valeurs
vrai, faux ou échec, succès.
III .2.5 PRINCIPES
Les principales idées sur lesquels repose ID3 sont les
suivantes :
Dans l'arbre de décision chaque noeud correspond à
un attribut non cible et chaque arc a une valeur possible de cet attribut. Une
feuille de l'arbre donne la valeur escomptée de l'attribut cible pour
l'enregistrement testé décrit par le chemin de la racine de
l'arbre de décision jusqu'à la feuille. (Définition d'un
arbre de décision). Dans l'arbre de décision, à chaque
noeud doit être associé l'attribut non cible qui apporte le plus
d'information par rapport aux autres attributs non encore utilisés dans
le chemin depuis la racine.(Critère d'un bon arbre de décision).
L'entropie est utilisée pour mesurer la quantité d'information
apportée par un noeud. (Cette notion a été introduite par
Claude Shannon lors de ses recherches concernant la théorie de
l'information qui sert de base à énormément de
méthodes du datamining).
Algorithme
Entrées : ensemble d'attributs A; échantillon E;
classe c
Début
Initialiser à l'arbre vide;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
33
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Si tous les exemples de E ont la même classe c
Alors étiqueter la racine par c;
Sinon si l'ensemble des attributs A est vide
Alors étiqueter la racine par la classe majoritaire dans
E;
Si non soit a le meilleur attribut choisi dans A;
Étiqueter la racine par a;
Pour toute valeur v de a
Construire une branche étiquetée par v;
Soit Eav l'ensemble des exemples tels que e(a) = v;
ajouter l'arbre construit par ID3 (A-{a}, Eav, c);
Fin pour Fin sinon
Fin sinon
Retourner racine;
Fin
III .2.2 EXEMPLE PRATIQUE
Pour introduire et exécuter "à la main"
l'algorithme ID3 nous allons tout d'abord considérer l'exemple
ci-dessous: Une entreprise possède les informations suivantes sur ses
clients et souhaite pouvoir prédire à l'avenir si un client
donné effectue des consultations de compte sur Internet.
EXEMPLE PRATIQUE D'UN ALGORITHME ID3
|
client
|
Moyenne des montants
|
Age
|
Lieu de Résidence
|
Etudes supérieures
|
Consultation par internet
|
|
1
|
Moyen
|
Moyen
|
Village
|
Oui
|
oui
|
|
2
|
Elevé
|
Moyen
|
Bourg
|
Non
|
non
|
|
3
|
Faible
|
Age
|
Bourg
|
Non
|
non
|
|
4
|
Faible
|
Moyen
|
Bourg
|
Oui
|
oui
|
|
5
|
Moyen
|
Jeune
|
Ville
|
Oui
|
Oui
|
|
6
|
Elevé
|
Agé
|
Ville
|
Oui
|
non
|
|
7
|
Moyen
|
Agé
|
Ville
|
Oui
|
non
|
|
8
|
Faible
|
Moyen
|
Village
|
Non
|
non
|
Tableau III 3:exemples pratiques
Ici, on voit bien que la procédure de classification
à trouver, qui à partir de la description d'un client, nous
indique si le client effectue la consultation de ses comptes par Internet,
c'est-à-dire la classe associée au client.
- le premier client est décrit par (M : moyen, Age :
moyen, Résidence : village, Etudes : oui) et a pour classe Oui.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
34
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
- le deuxième client est décrit par (M :
élevé, Age : moyen, Résidence : bourg, Etudes : non) et a
pour classe Non.
Pour cela, nous allons construire un arbre de décision
qui classifie les clients. Les arbres sont construits de façon
descendante. Lorsqu'un test est choisi, on divise l'ensemble d'apprentissage
pour chacune des branches et on
Réapplique récursivement l'algorithme.
H(C[Lieu) = -P (bourg). (P (C[bourg) log (P (C[bourg)) + P (C
[bourg)
Choix du meilleur attribut : Pour cet
algorithme deux mesures existent pour choisir le meilleur attribut : la mesure
d'entropie et la mesure de fréquence:
L'entropie : Le gain (avec pour fonction i
l'entropie) est également appelé l'entropie de Shannon et
peut se réécrire de la manière suivante :
Pour déterminer le premier attribut test (racine de
l'arbre), on recherche l'attribut d'entropie la plus faible. On doit donc
calculer H(C[Solde), H(C[Age), H(C[Lieu), H(C[Etudes), où la classe C
correspond aux personnes qui consultent leurs comptes sur Internet.
H(C[Solde) = -P (faible).(P (C[faible) log(P (C[faible)) + P
(C [faible) log(P (C[faible)))-P (moyen).(P (C[moyen) log(P (C[moyen)) + P
(C[moyen) log(P (C[moyen)))-P (eleve).(P (C[eleve) log(P (C[eleve)) + P
(C[eleve) log(P(C[eleve)))H(C[Solde)
H(C[Solde) = -3/8(1/3.log(1/3) + 2/3.log(2/3)-3/8(2/3.log(2/3) +
1/3.log(1/3)
-2/8(0.log (0) + 1.log(1)
H (C[Solde) = 0.20725
H(C[Age) = -P (jeune).(P (C[jeune) log(P (C[jeune)) + P (C
[jeune) log(P (C[jeune)))-P (moyen).(P (C[moyen) log(P (C[moyen)) + P (C
[moyen) log(P (C[moyen)))-P (age).(P (C[age) log(P (C[age)) + P (C[age) log(P
(C[age)))
H(C[Age) = 0.15051
Log (P (C[bourg)))-P (village).(P (C[village) log(P
(C[village)) + P (C [village) log(P (C[village)))-P (ville).(P (C[ville) log(P
(C[ville)) + P (C[ville)
Log (P (C[ville)))
H(C[Lieu) = 0.2825
H(C[Etudes) = -P (oui).(P (C[oui) log(P (C[oui)) + P (C [oui)
log(P (C[oui)))
-P (non).(P (C[non) log(P (C[non)) + P (C[non) log(P (C[non)))
H(C[Etudes) = 0.18275 Le premier attribut est donc l'âge (attribut dont
l'entropie est minimale). On obtient l'arbre suivant :
FIG III 1:Arbre de décision construit à partir de
l'attribut àge
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
35
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Pour la branche correspondant à un âge moyen, on
ne peut pas conclure, on doit donc
recalculer l'entropie sur la partition correspondante.
H(C|Solde) = -P (faible).(P (C|faible) log(P (C|faible)) + P
(C |faible) log(P
(C|faible)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P
(C|moyen)
Log (P (C|moyen)))-P (eleve). (P (C|eleve) log(P (C|eleve)) +
P (C|eleve) log(P
(C|eleve)))
H(C|Solde) = -2/4(1/2.log(1/2) + 1/2.log(1/2)-1/4(1.log(1) +
0.log(0)
-1/4(0.log (0) + 1.log (1)
H (C|Solde) = 0.15051
H(C|Lieu) = -P (bourg).(P (C|bourg) log(P (C|bourg)) + P (C
|bourg) log(P
(C|bourg)))-P (village).(P (C|village) log(P (C|village)) + P
(C |village) log(P
(C|village)))-P (ville).(P (C|ville) log(P (C|ville)) + P
(C|ville) log(P (C|ville)))
H (C|Lieu) = 0.30103
H (C|Etudes) = -P (oui).(P (C|oui) log(P (C|oui)) + P (C |oui)
log(P (C|oui)))
-P (non). (P (C|non) log(P (C|non)) + P (C|non) log(P
(C|non))) H(C|Etudes) = 0
L'attribut qui a l'entropie la plus faible est « Etudes
».
L'arbre devient alors :
FIG III 2:Arbre de décision finale
L'ensemble des exemples est classé et on constate que sur
cet ensemble d'apprentissage, seuls deux attributs sur les quatre sont
discriminants.
III.3 CONCEPTS THEORIQUES SUR LE GRAPHE [6, 8, 9]
Graphe :
Définition : Un graphe G est un
couple G=(X, U) ,X est un ensemble non vide et au plus dénombrable .
Nota :X est un ensemble fini ,les éléments de x?X
sont appelés les sommets ou noeuds ,u = une famille
d'éléments du produit cartésiens XxX .
Les éléments de U=(x,y) ,x,y?X, sont appelés
:
Soit des arcs lorsqu'on tient compte de l'orientation, soit les
arêtes lorsqu'on ne tient pas compte de l'orientation.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
36
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Graphe connexe :
Définition :
Un graphe est connexe si l'on peut atteindre n'importe quel
sommet à partir d'un sommet quelconque en parcourant les
différentes arêtes.
Exemple : soit G=(X, U) qui est un graphe connexe

U6 U5
U7
U8
EX :
U4
U3
U1 U2
Arbres et arborescence
1. Arbres :
Définition : Un arbre est un
graphe connexe sans cycle. C'est-à-dire dont on peut atteindre n'importe
quel sommet à partir d'un sommet quel- conque en parcourant
différents arêtes et ses arêtes ne coïncide pas.
EX :

2) Arborescence :
Définition : une structure qui
permet de déduire un résultat à partir de décision
successive.
Soit G=(X, U) on dit que le sommet rX est une racine de G si V
xX,(avec xr)? un chemin de r à x .c'est -à -dire un arbre ayant
une racine.
Exemple :

b
c
d
a
f
e
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
37
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
CONCLUSION PARTIELLE
Dans ce chapitre nous avons présenté le
datamining avec ses différentes méthodes, tâches,
techniques et nous avons fait un briefing sur la notion relative à la
théorie de graphe. Nous avons aussi construit un arbre de
décision ou nous nous somme basé sur l'attribut âge et
l'étude.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
38
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016


|
39
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
CHAP IV : MODELISATION ET APPLICATION [2,8]
IV.0 INTRODUCTION
Ce chapitre est consacré à la réalisation
de notre système décisionnel pour le recrutement du personnel
ainsi qu'à la réalisation de l'application opérationnelle
qui permettra au chef du personnel de la Direction Générale de
recette du Kasaï Occidental (DGR KOC) de prendre des décisions
concernant le recrutement des agents ou du personnel.
Cette application est réalisée pour le service
de ressource humaine de la Direction général de recette du
Kasaï occidentale qui constitue le champ d'application de notre
travail.
Ainsi, nous parlerons de l'aperçu historique, la
situation géographique, suivie de la structure organisationnelle pour
terminer par une conception de notre système décisionnel.
Par ailleurs, nous tenons à signaler que notre
étude porte sur la réalisation d'un système
décisionnel qui permettra de faire des analyses sur les recrutements
à la direction Générale de recette du Kassaï
Occidental.
IV.1 ANALYSE DE L'EXISTAN
APERÇU HISTORIQUE
La Direction Générale de Recette du Kasaï
Occidental (DGRKOC) est un service de l'Etat, décentralisé ayant
pour mission principale la mobilisation des recettes provincial.
Tous Sous la couverture de la loi du pays constitution du 18
février 2016 qui donne la libre administration ou un Etat
fédéral dont les dirigeants ou les décideurs sont plus
proches du gouvernement, l'édit n°2 de la nomenclature accorde la
chance à l'institution publique provinciale de l'Etat de créer
une institution financière en vue de la décentralisation et
l'autofinancement de la province ; c'est ainsi que le gouverneur Trésor
KAPUKU NGOY eu l'idée de créer le 28 février 2008, une
régie financière appelée Brigade de mobilisation
des recettes ( BMR) sous l'autorisation de l'assemblée
provinciale ; Cette régie financière présentait la
structure suivante :
? Directeur Provincial ;
? Directeur Provincial Adjoint ;
? 6 divisions ;
? 18 bureaux ;
? Et 12 centres de perception (centre de la catégorie A et
B)
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
40
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Tous les centres de la catégorie A étaient
chapotés par les chefs de division et ceux de la catégorie B, par
les chefs de bureaux.
Lorsque le gouverneur Alex KANDE arriva, après avoir
fait différents constats, il trouva que cette structure était
politisée, le recrutement était politique sans tenir compte des
capacités et compétences des certaines personnes ; cette
structure n'était pas aussi conforme à la loi et c'est ainsi
qu'il créa toujours sous l'autorisation de l'assemblée
provinciale, une régie financière appelée
Direction Générale des recettes du Kasaï occidental
(DGRKOC) par l'édit n°17 avec la structure ci -
après :
> Directeur Général
> Directeur Général Adjoint ;
> 4 directeurs ;
> 16 chefs de division ;
> 52 chefs de bureaux ;
> Et 208 agents d'exécution et aussi des centres de
perception au nombre de 12.
Malgré cette structure qui devait corriger la
précédente, nous remarquons que jusqu'à ce jour, cette
dernière n'a pas encore connue une modification.
La DGRKOC comme étant un service d'octroi
décentralisé qui a pour mission principale la mobilisation des
recettes provinciale comme toute centre de régie financière, la
DGRKOC s'inscrit aussi dans la chaine de réception des recettes ou
chaine de recette.
SITUATION GEOGRAPHIQUE
La Direction Générale de Recette du Kasaï
Occidentale se situe sur la ville de Kananga, commune du même nom, au
quartier malandji sur l'avenu Kikoler au N° 6 elle est bornée :
> AU Nord par la maison communale de Kananga ; > Au Sud par
les complexes scolaires amis de David > A l'Est par la fondation femme plus
et
> A l'Ouest par l'immo Kasaï.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
41
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
IV.1.1 STRUCTURE DE L'ENTREPRISE
La Direction Général de recette du Kasaï
occidental égorge des services ou division ci-après :
I. DIVISION BD'ASSIETTE
La division d'assiette est une division qui entre dans la ligne
de mobilisation des recettes elle s'occupe de :
· Recensement et identification des contribuables ainsi que
l'élaboration et le suivi des répertoires des contribuables ;
· Recherche et recoupement des données fiscales et
parafiscales ;
· Distribution des déclarations, le
dépouillement de déclaration rentrées et taxation des
redevables ;
· Documentation, gestion des dossiers des contribuables et
relance des contribuables insolvables ou défaillants ;
· Initiation des missions d'enquêtes fiscales et
parafiscales ;
· Enrôlement des impôts à charge des
contribuables et élaboration, coordination des procédures
d'assiette sur l'ensemble de la province.
II. DIVISION ADMINISTRATIVE Cette
division s'occupe de :
· S'assurer le secrétariat unique et coordonner les
activités du bureau du Directeur Provincial et celles du Directeur
Provincial Adjoint ;
· Préparer les dossiers soumis aux Directeur
provincial adjoint ou évoquer par eux ;
· Assurer la communication et la vulgarisation de la
législation ainsi que de la réglementation fiscale et parafiscale
;
· Etudier et mettre en oeuvre l'information de la Brigade
de mobilisation des recettes provinciales du Kasaï Occidental ;
· Faire le suivi des services attachés à la
Direction.
BUREAU ADMINISTRATION ET
SECRETARIAT
Ce bureau s'occupe de :
· Traite les dossiers lui confier par le Directeur
Provincial ou le Directeur Provincial Adjoint ;
· Emettre la demande de la Direction Provinciale, les
avis et considération sur les dossiers traités par les services
et devant être soumis à l'appréciation du Directeur
provincial ou à celle du Directeur provincial adjoint ;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
42
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
· Préparer et élaborer les comptes rendus
des réunions présidées par le Directeur provincial ou le
Directeur provincial Adjoint ;
· Rédiger les projets des allocations et discoure
du Directeur provincial ou directeur provincial adjoint ;
· Assister le directeur provincial ou le directeur
provincial adjoint dans le suivi du traitement ou de l'instruction des dossiers
revêtant un caractère urgent confiés aux différents
services de la DGRKOC ;
· Préparer et rédiger les projets des
rapports des missions effectuées par le Directeur provincial ou le
directeur provincial adjoint ;
· Faire le suivi des relations avec les autres
administrations ;
· Préparer des lettre-réponses des
contribuables sur les questions de fond ou de forme soulevée en
matière fiscale et parafiscale ;
2. Bureau étude et
Informatique
· Préparer le traitement informatique des
données fiscales et parafiscales ;
· Saisir des textes confiés à la Division
administrative ;
· Elaboration d'une stratégie du système
d'information fiscale et parafiscale ;
· Evaluation des offres et choix des matériels
informatique et des logiciels d'exploitation et d'application ;
· Analyse, développement, implantation et
maintenance des applications informatiques ;
· Elaboration des cahiers des charges des projets
informatiques ;
· Evaluation des besoins et organisation et des
utilisateurs ;
· Prospection et proposition des stages de
perfectionnement spécialisés ;
· Formulation des avis technique sur l'utilisation et
les affectations des matériels et des consommables informatiques ;
· Préparer des projets d'instruction de service.
III. DIVISION DE RESSOURCES HUMAINES
Cette division est compose des bureaux si après :
· La gestion du personnel de la DGRKOC ;
· La gestion financière et des infrastructures de la
DGRKOC ;
· L'organisation du recrutement des agents
nécessaires au fonctionnement et des services selon les modalités
en vigueur en la matière ;
· Formation en cour de carrière des agents ;
· Gestion de matérielle et mobilière de la
DGRKOC.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
43
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV. DIVISION DE CONTROLE FISCAL ET ORDONNACEMENT DES
RECETTES FISCALES PARAFISCALES
Cette division est chargée de :
· La tenu et la mise à jour d'une banque de
données de recoupement lui transmis par la division d'assiette, la
gestion des déclarations et relevés rentrés reçus
de la division d'assiette ;
· La programmation des missions de contrôle et
d'ordonnancement des taxes fiscales, administratives,
rémunératoires et autres droits ainsi que le suivi des recettes
exceptionnelles, de participation et des recettes des services émergeant
aux budgets annexes, relevant d la compétence de la province ;
· L'établissement après le control, des
avis d'imposition ou de redressement selon les cas pour les impôts ainsi
que l'ordonnancement des taxes parafiscales ;
V. DIVISION DE RECOUVREMENT
La division de recouvrement a pour attributions :
· La définition de la stratégie et des
objectifs tant quantitatifs que qualitatifs en matière de recouvrement
;
· La perception des sommes dues au trésor
provincial au titre des impôts, taxe, redevance et autres droits relevant
de la compétence de la province à base des avis de taxation
d'office, d'imposition d'office, de relance, des extraits de rôle lui
transmis par la division d'assiette ainsi que les avis d'imposition d'office,
de redressement des recettes fiscales et textes parafiscales
ordonnancées lui transmis par la division de contrôle fiscale et
d'ordonnancement des recettes fiscales et parafiscales ;
· L'évaluation des performances de
réalisation des recettes, l'amélioration du rendement des
services et la consolidation des résultats en matière de
recouvrement ;
· Transmission au service de contentieux et poursuite de
la liste des contribuables insolvables suivie des sanctions ;
· L'amorce des opérations des poursuites
créances de la province dues mais non recouvrées et
délivrer les acquis libératoires ;
· L'apurement des comptes courants des redevables des
impôts, taxes, redevances et autres droits recouvrés relevant de
la compétence de la province.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
44
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
? Etablissement de note de perception de sommes dues à
la province, établissement et expédition des avis de mise en
recouvrement des impôts taxes, redevances et autres droits dus à
la province établis par voie de rôle ;
? Recouvrement par voie des déclarations auto
liquidatives et recouvrement des pénalités revenant à la
DGR KOC.
VI. CENTRE DES RECETTES FISCALES ET
PARAFISCALES
Les centre des recettes fiscales et parafiscales sont
chargés de mener, dans leurs ressort respectifs, les opération
d'assiette, de contrôle et de recouvrement des impôts provinciaux
et locaux ainsi que celles d'ordonnancement des taxes redevances et autres.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
45
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.1.2 ORGANIGRAMME DE LA DIRECTION GENERAL RECETTE DU
KASSAI OCCIDENTAL
DIRECTEUR GENERAL
DIRECTEUR GENERAL ADJOINT
DIRECTEUR TECHNIQUE
3 Bureaux
14

4AUDITEUR
1
2
3
4 5
6
7
8
9 10
|
|
|
DIV
|
DIV
|
DIV
|
DIV
|
|
RHF SG
|
ADM
|
ASSIETT
|
C.FSC.O
|
|
AUDIT
|
|
DIV
REC
11 12 13
|
CENTRE
|
CENTRE
|
CENTRE
|
CENTRE
|
TPA
|
KAMONIA
|
ILEBO
|
LUEBO
|
|

3Bureaux
3 Bureaux
3 Bureaux
3 bureaux
2Antennes
5Antennes
7 Antennes
CENTRE
|
|
CENTRE
|
|
CENTRE
|
|
CENTRE
|
|
CENTRE
|
|
CENTRE
|
|
CENTRE
|
LUEBO
|
|
DEMBA
|
|
DIBAYA
|
|
MWEKA
|
|
KAZUMBA
|
|
DIMBELENGE
|
|
DEKESE
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2Antennes
|
|
Fig IV.1 Organigramme de l'entreprise
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
46
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.1.3 FONCTIONNEMENT DE LA DIVISION DES RESSOURCES
HUMAINES
Cette division s'occupe de la gestion du personnel, la gestion
financière et des infrastructures, de l'organisation du recrutement des
agents nécessaire au
fonctionnement des services selon les modalités en
vigueur en la matière, formation en
cours de carrière des agents et la gestion
matérielle et mobilière de la Direction Générale de
Recette du Kasaï Occidental.
IV.1.4 ORGANIGRAMME DU SERVICE CONCERNE

DIVISION DECRESOURCES HUMAINES

BUREAU GESTION
BUGJETAIRE
ET
MATERIEL

BUREAU DU
PERSONNEL PAIE
ET
FORMATION

BUREAU AFFAIRE
SOCIAL ET
RELATION
PUBLIC
Fig. IV.2 organigramme du service concerné.
IV.1.5 DESCRIPTION DES POSTES
La division des ressources humaine regroupe à son sein le
bureau ci-dessous :
1. Bureau Gestion du personnel, paie et formation
Ce bureau s'occupe de :
· suivre le respect de l'organigramme par les services
et pouvoir aux postes vacants ;
· examen des cas de recours d'avancement en grade ;
· étude et traitement des aspects juridique et du
contentieux à la carrière des agents ;
· rédaction des attestations de services,
feuilles de route, communiqués de service et autres documents
administratifs ;
· traitement des demandes de congé et gestion du
mouvement général congé du personnel ;
· tenue et exploitation des relevés de cotation
des agents et classement des dossiers administratifs des agents ;
· préparation des dossiers de retraités et
suivi des dossiers des décédés ;
· organisation et gestion de la paie des traitements et
primes, tenue des statistiques de la paie ;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
47
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
· Tenue des statistiques de la paie, collecte des besoins
en formation ;
· Organisation matérielle et pédagogique des
sessions de formation. 2. Bureau affaires sociales et relation
publiques
Ce bureau s'occupe de :
· Entreprendre toutes les démarches pour l'obtention
des cartes d'ayant droit en faveur des cadres et agents ;
· Initier des conventions médicales avec les
formations médicale de la place ;
· Réceptionner, enregistrer et contrôler les
ordonnances médicales et les facture introduite par les agents ;
· Initier les appels de fonds pour payer les
déclarations des créances en faveur des agents malades et autres
ayant-droits ;
· Payer les factures ou les produits pharmaceutiques en
faveur des agents malade et leur ayant-droit ;
· S'assurer de la prise en charge par la fonction publique
des retraités et payer les rentes aux bénéficiaires en
attendant prise en charge effective ;
· Distribuer des vivres à l'occasion des fêtes
de fin d'année et nouvel an ;
· Entreprendre les démarches ayant trait l'assurance
du personnel auprès de la SONAS et autres agences d'assurances
agrées ;
3) Bureau Gestion budgétaire et
matérielle
C'est bureau s'occupe de :
· Gestion des crédits alloués à la
DGRKOC ;
· Acquisition et gestion des biens, meubles et immeubles
nécessaires au bon fonctionnement de la DGRKOC ;
· Suivi des opérations de mise à la
disposition de la DGRKOC des fonds (rétrocession,
pénalités revenant à la DGRKOC, prime de mobilisation,
prime de plus-value, rémunération, remboursements spéciaux
et autres, etc.) ;
· Suivi des opérations bancaires ;
· Exécution du plan de trésorerie par la
préparation des chèques ou bons de caisse ;
· Suivi des opérations comptables et tenue des
livres auxiliaires en faisant le rapprochement entre les paiements et les
lignes de crédit ;
· Préparation des états de paie et
collecte des informations sur les actions de recouvrement des
pénalités revenant à la DGRKOC ;
· Centralisation des informations sur la prime du
contentieux et suivi des paiements pris en charge par la DGRKOC (loyer, soins
de santé, etc.) ;
· Tenue des fiches et comptes des fournisseurs des biens
et services ;
· Elaboration du plan de paiement ;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
48
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
PROBLEME RENCONTRER
Lors des nos recherche à la Direction
Générale de Recette du Kasaï Occidental, dans la division
des ressources humaine précisément dans le Bureau du personnel
nous avons constaté que le chef du personnel ne pas surtout disponible
dans son bureau, et aussi pour saisir ou bien vérifier quelques
informations sur un personnel il faut toujours recourir dans le bureau ou il y
a des matérielles informatique installer et aussi il y a insuffisance de
personnel qualifier dans certain services.
PROBLEMATIQUE ET MOTIVATION
La problématique de ce travail est de mettre en place
un data mart en vue de faire des analyses tout en évitant le recrutement
par connaissance ou par lien familiale.
Le sujet de ce data mart est le Recrutement, pour permettre
aux décideurs d'avoir une vue d'ensemble sur ce qui concerne le
Recrutement du personnel à la Direction Général de Recette
du Kasaï Occidental dont voici les motivations :
? D'aider le chef du personnel à arriver à faire
un bon recrutement ;
? Recruter des agents qui peuvent servir notre province sur
ce qui concerne les recettes ;
? D'aider le décideur à prendre une bonne
décision pour ce qui concerne le recrutement du personnel ;
? D'aidé le décideur à avoir des
critères basé sur le recrutement du personnel à la
Direction Général de Recette du Kassaï occidental ;
? Avoir tout les informations concernant les nouveaux
personnels engagés, sur son dossier, la date d'engagement et autre.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
49
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.2 MODELISATION
IV.2.1 OUTIL UTILISE
Nous présentons succinctement les outils ainsi que les
nouvelles méthodes de développement de processus
décisionnels qui en découlent.
1. Microsoft Visual Studio team système
SQL serveur 2008 (business intelligence)
Ici nous allons énumérer les modules et
composantes de SQL serveur 2008.
Composant
|
Module SQL Serveur 2008
|
Destination dans l'entreprise
|
Workflow+Flux de
données (ETL)
|
Intégration de services
(SSIS)
|
Administrateur de base des
données
|
Entrepôt de données relationnel
et multidimensionnel
|
Base de données
relationnelle SQL serveur
2005
|
Administrateur et développeurs
|
Base de donnés
multidimensionnelle analytique
|
Analysis service
|
Développeur et utilisateur
ayant des connaissances métier
|
exploration des données
|
Data mining intégré à
Analysis services designer
|
Staticien ou développeur
utilisateur
|
Création de rapport et
de modèle
sémantique et métier
|
Reporting services designer
|
Développeurs
|
Requêtes et analyses spécifiques
|
Report builder 1.0 Excel,
proclarity
|
Analystes métier
|
Développement d'application BI
|
SQL serveurBusiness
Intelligence Devellopment
Studio(BIDS)=Visual Studio
|
Développeur
|
Outil de gestion de base de données
|
SQL Server management
studio
|
Administraeur et developeur
|
Service de
notification
|
SQL Server notification
service
|
Alertes envoyées aux managers sur des
événements métier
|
|
Tableau IV .1: répartition de module de SQL serveur
2008 par composante.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
50
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.3 LE SYSTEME TRANSACTIONNEL SQL SERVEUR
IV.3.1 DEFNITION
T-SQL est un langage dédié à
l'accès aux données, il est une extension de SQL et
if/then/switch...) OU est un véritable serveur de base de données
SQL multi-utilisetur, SQL est le plus populaire langage de base de
données dans le monde.
AVANTAGE
Voici quelques avantage quel nous offres :
? Performât SQL server se classe parmi les SGBDR les
plus rapides ;
? Evolution et fiable : vous pouvez repartir la charge sur
Plusieurs serveurs,
bénéficier des avantages des systèmes
multiprocesseurs et profiter des
performances d'applications de Windows 2000
Datacenter server qui supporte 32 processeurs et 64 go de ram.
? Rapidité de mise en oeuvre avec SQL server, le
développement, le d'ploiement et l'administration d'application
destinés au web sont accélérés grâce aux
nombreux fonctionnements dédiées, ainsi qu'au support du web.
Bref est un langage qui rend facile le stockage, la mise à jour et
l'accès à l'information client sur site web.
IV.2.2 MODELISATION MULTIDIMENSIONNELLE DE DATAMART
Pour construire un entrepôt global d'une entreprise il ya
des méthodes : Top down : c'est la méthode la
plus lourde, la plus contraignante et la plus complète en même
temps elle consiste en la conception de tout l'entrepôt, puis la
réalisation de ce dernier.
Bottom-up : c'est l'approche inverse, elle
consiste à créer les étoiles, puis les regrouper par des
niveaux intermédiaires jusqu'à l'obtention d'un véritable
entrepôt pyramidal avec une vision d'entreprise.
Middle-Out : c'est
l'approche hybride, et conseillée par les professionnels du business
intelligence. Cette méthodes consiste en la conception totale de
l'entrepôt des données c-à-dire concevoir toutes
dimensions, tous les faits, toutes les relations, puis créer des
divisions plus petites et plus gérables et les mettre en oeuvre.
Pour notre étude nous avons construit un DataMart
représentant une étoile pour l'hôpital qui est un DataMart
sur les accouchements au service de la maternité.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
51
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.2.3 MODELISATION DE L'APPLICATION
Pour notre modélisation nous allons utiliser le
langage UML.
Au début des années 90, il existait une
Cinquantaine de méthodes objet liées par un certain consensus
autour d'idées communes:
Classes, sous -systèmes. Mais chacune possédait
sa propre notation, ses points forts, ses manques et son orientation
privilégiée vers le domaine d'application. L'idée d'une
certaine unification des méthodes objet est née de ce constant.
La communauté informatique, autour de l'OMG (Objet Management Group) qui
standardise les technologies de l'objet, s'est attachée à la
définition d'un langage commun unique, utilisable par toutes les
méthodes objets, dans toutes les phases du cycle de vie et compatible
avec les techniques de réalisation du moment.
Définition : UML (Unified Modeling
Language) en français Langage de Modélisation Unifié qui
est une notation basée principalement sur les méthodes OOD (de
Booch), OMT (de Rumbaugh) et OOSE (de Jacobson)
L'UML a été proposé afin de standardiser
les produits du développement (Modèle, notation, diagrammes) sans
standardiser le processus de
développement.il est en
effet très difficile de standardiser les processus de
développement qui dépend des personnes, des applications, des
cultures, etc.
UML se propose de créer un langage de
modélisation utilisable à la fois par les humains (forme
graphique) et les machines (syntaxe précise)
UML est une notation, non pas une méthode, c'est un
langage de modélisation objet et convient pour toute les méthodes
objets dans le domaine public. Elle a pour but de documenter les
méthodes objet.
Nous avons modélisé la base de données
opérationnelle avec la méthode
UML qui est la source de données alimentant notre
entrepôt des données.
NARATION :
La Direction Général de Recette du Kasaï
Occidental (DGR KOC) est une structure ou un service d'Etatique,
décentralisé, qui a pour mission principale la mobilisation de
recette provinciale.
Pour ce faire, la DGR KOC doit avoir un personnel reconnu au
sein de sa structure. Le recrutement d'un agent à la DGR KOC est
conditionnel, dans le cas ou elle n'éprouve un besoin en personnel et
soumet au ministère de finance, après étude de besoin
présenté par la régit, le ministère de finance
procédera au lancement officiel de l'offre pourvu que l'offre atteigne
toutes les couches de la société, tout en fixant la date limite
du dépôt, c'est le chef du personnel qui reçoit les
dossiers.
Les candidats intéressés procéderont
à la constitution des dossiers et au dépôt dans la date
fixée, ils les constitueront avec les éléments
ci-après :
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
52
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
> Une lettre de motivation ;
> Une lettre de demande d'engagement ;
> Un diplôme de graduat, licence au doctorat ;
> L'attestation de nationalité ;
> L'attestation de bonne vie et moeurs et ;
> L'attestation médicale.
Le dossier contenant ces éléments est
jugé complet au cas ou il ne manque pas un élément, au cas
ou la candidature est intéressante et qu'il manque un
élément, le service procédera à l'appel de candidat
pour compléter son dossier.
Le candidat se présente avec son dossiers à la
réception ou il le dépose à la fin de la période
prévue pour le dépôt des dossiers, la réception
codifiera le dossier et remettra la liste au candidat ou il inscrirera son nom
et celui-ci acheminera ces dernier au chargé de ressources humaines qui
procédera à la lecture et sélection des dossiers complets
pour le test, puis l'élimination des autres candidats pour l'interview
afin d'arriver à l'engagement effectif.
Les noms des candidats présélectionnés
seront affichés pour passé au concours, une fois le concours
effectués le service compétent procédera à la
correction afin de retenir les candidats effectifs avant de transférer
leurs dossiers au ministère de finance pour la validation afin
d'attribuer des numéros matricule à ces derniers pour enfin
être définitivement considéré comme agents
effectifs.
1. DIAGRAMME DE CLASSE DE L'APPLICATION EN
UML
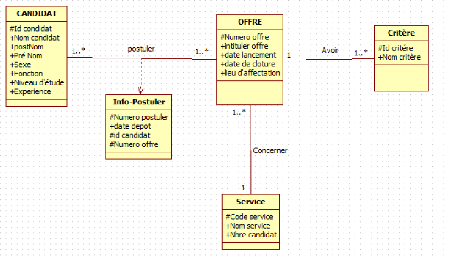
Fig. IV.3 Diagramme de classe en UMl
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
53
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
2. DIAGRAMME DE SEQUENCE EN UML
Est une suite d'échange de message entre des objets qui
compose le système pour réaliser les cas d'utilisation
1 : depot de dossier+letrre motivatio()
2 : selection dossier()
3 : enregistrement du dossier()

4 : faire passé le test()
5 : passé le test()
6 : passé à la correction du
test()
7 : envoi resultat test()
8 : confurmation et engagement()
Fig.IV.5 diagramme de
séquence
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
54
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
1. DIAGRAMME DE CAS D'UTILISATION EN UML
Les diagrammes de classes expriment la structure statique du
système, ils décrivent l'ensemble des classes et leurs
associations.
Une classe décrit un ensemble d'objet (instance de
classe) ; une association exprime une connexion sémantique
bidirectionnelle entre classe, elle décrit un ensemble de lien
(instances de l'association).
Les cardinalités(ou multiplicité) indiquent le
nombre d'instance d'une classe pour chaque instance de l'autres classe.
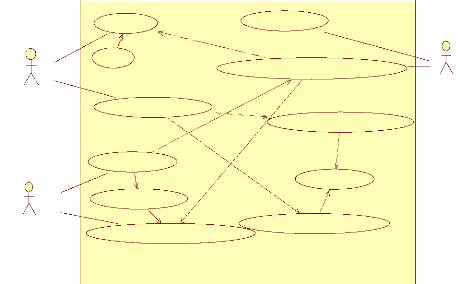
candidat
System
lancer offfre
test d'admissions
<<extend>>
critères
dossier+lettre de demande
d'engement
Decideur
<<extend>>
decision de recrutement
<<include>>
enregistrement profil candidat
<<include>>
lecture de dossier
<<include>>
authentification
selection de dossier
<<include>>
<<extend>>
chef du personnel
manupuler les outils decisionnel
transfer dedossier et resultat
test
Fig. IV. 4 Diagramme de cas d'utilisation.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
55
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.2.4 .CONCEPTION D'UN DATA MART
Etape 1 : Définir le processus
à analyser
La procédure ou fonction fait référence au
sujet de notre mini entrepôt des données
Nous déterminons le processus métier de la DGR
KOC par notre étude :
« Le Recrutement »Dont voici la modélisation de
la base de données de l'entrepôt de données.
Etape 2 : Déterminer le
niveau de granularité des données, choisir le grain qui signifie
décider exactement de ce que représente un enregistrement d'une
table de faits.par exemple l'entité candidat représente les faits
relatifs à chaque recrutement et devient la table de faits du
schéma en étoile des recrutements.
Par conséquent, le grain de la table de faits
recrutement est un recrutement réalisé à la DGR KOC.
A prés avoir choisi le grain de la table de faits nous
allons commencer à identifier les dimensions de la tables de faits.
A titre d'illustration, les entités candidat,
critère et offre serviront de références aux
données concernant le recrutement et deviendront les tables de
dimensions du schéma en étoile de recrutement.
Nous ajoutons aussi le Temps comme dimension principale, car
il est toujours présent dans le schéma en étoile.
Etape 3 : choisir les dimensions
Les dimensions déterminent le contexte dans lequel nous
pourrons poser des questions à propos des faits établis dans la
table de faits .Un ensemble de dimensions bien constitué rend le mini
entrepôt de données compréhensible et en simplifie
l'utilisation. Nous identifions les dimensions avec suffisance de
détails, pour décrire des choses telles que les clients et les
propriétés avec granularité correcte.
Par exemple, toute personne de la dimension candidat est
décrite par les attributs suivants : nom, post nom, sexe, fonction,
niveau d'étude, expérience.
La dimension offre est décrite par les attributs suivants
: numéro offre, intituler offre, date de lancement, date de
clôture, lier d'affectation code service
La dimension temps est décrite par les attributs
suivants : id temps, année, semestre, trimestre, mois et jours.
Etape 4 : identifier les
métriques (faits)
Pou notre cas le fait est recrutement. Les métriques
sont les données numériques NUM
OFFRE, NBRE CRITERE TOTAL, NBRE CRITERE PAR CANDIDAT.
Notons que les autres étapes qui suivent exclusivement
pour la construction d'un entrepôt des données. Mais pour notre
travail nous construisons un DataMart donc un sous ensemble d'un entrepôt
des données ainsi nous estimons que nous pouvons nous arrêter ace
points.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
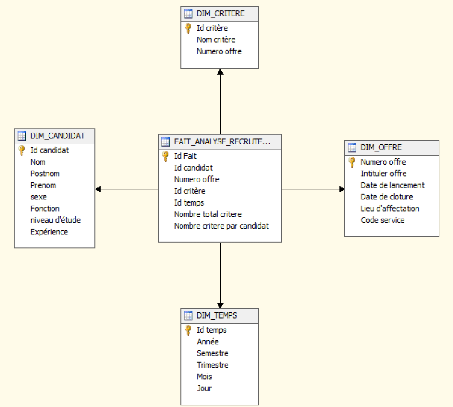
56
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
SHEMAT EN ETOILE
Fig. IV.5 schéma en étoile du recrutement
sous SQL
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
57
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.2.5 BUSINESS INTELLIGENCE
La fenêtre de test de connexion avant de
déployer le cube. Cette fenêtre nous donne la confirmation et
l'assurance que le cube est connecté aux différentes sources
hétérogènes extérieures et même l'état
prochain de notre exécution sur le cube.
Fig. IV.6.Schéma Du BI
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
58
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART
ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
|
IV.2.6 Création du cube
Il faut sélectionner la vue de source de données
et les tables, puis définir les propriétés du cube et
attribuer lui un nom.
Voici la procédure normale :
· Clic sur droit sur Cubes
· Clic sur nouveau cube
· Clic sur suivant
· Clic sur suivant
· Cocher la case de table de fait
· Clic sur suivant, suivant, suivant, suivant, Termier
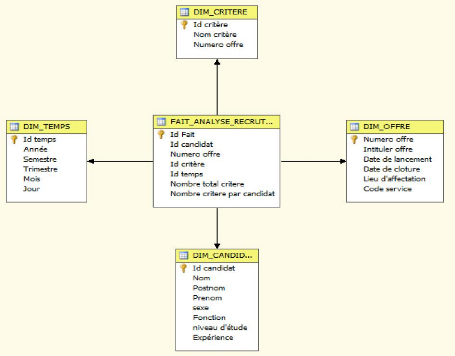
Fig. IV.7 Création de cube sous SQL
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
59
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE
DATA MART ET L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA
DGR KOC
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 -
2016
IV.3 IMPLEMENTATION
IV.3.1 INTERFACE
Formulaire du démarrage de
l'application
Fig. IV.8. Formulaire d'accueil
Formulaire d'identification
Ce formulaire nous permet de s'y identifiée et
accéder dans notre logiciel
Fig. IV.9 formulaire
d'authentification.
|
60
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Voici le code source pour ce formulaire
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
namespace Application_huguette
{
public partial class Authentification : Form {
public Authentification() {
InitializeComponent();
}
private void Authentification_Load(object sender, EventArgs e)
{
// TODO : cette ligne de code charge les données dans
la table 'hugaplayDataSet3.UTILISATEUR'. Vous pouvez la déplacer ou la
supprimer selon vos besoins.
this.uTILISATEURTableAdapter1.Fill(this.hugaplayDataSet3.UTILISATEUR);
}
private void button1_Click(object sender, EventArgs e)
{
Form form = null;
Form Form1 = new Principal();
form = Form1;
form.Show();
this.Hide();
}
private void button3_Click(object sender, EventArgs e)
{
Application.Exit();
}
private void button2_Click(object sender, EventArgs e)
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
61
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
{
comboBox1.Text = ""; textBox1 .Text = ""; comboBox1.Focus();
}
private void groupBox1_Enter(object sender, EventArgs e) {
}
}
}
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
Formulaire principal permettent de choisir
l'opération à effectuer
Fig. IV.10 formulaire principal
|
62
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Voici le code source pour ce formulaire
namespace Application_huguette
{
public partial class Principal : Form
{
public Principal()
{
InitializeComponent();
}
private void créationDoffreToolStripMenuItem_Click(object
sender, EventArgs
e)
{
Form form = null;
Form Form1 = new Gestion_application ();
form = Form1;
form.Show();
this.Hide();
}
private void
créationDunServiceToolStripMenuItem_Click(object sender,
EventArgs e)
{
Form form = null;
Form Form1 = new Gestion_application();
form = Form1;
form.Show();
this.Hide();
}
private void postulationToolStripMenuItem_Click(object sender,
EventArgs e)
{
Form form = null;
Form Form1 = new POSTULATION ();
form = Form1;
form.Show();
this.Hide();
}
private void lISTEDOFFRESToolStripMenuItem_Click(object
sender,
EventArgs e)
{
Form form = null;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
63
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Form Form1 = new LISTE_OFFRES ();
form = Form1;
form.Show();
this.Hide();
}
private void fERMERToolStripMenuItem_Click(object sender,
EventArgs e) {
Application.Exit();
}
}
}
Formulaire d'enregistrement du candidat et information
sur l'offre
Ce formulaire nous permet d'enregistrer le candidat postulant et
de voir aussi les informations concernant l'offre.
Fig. IV.11 formulaire de saisie.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
64
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
Voici le code source pour ce formulaire et connexion
directe à la base de données :
namespace Application_huguette
{
public partial class Gestion_application : Form
{
public Gestion_application()
{
InitializeComponent();
}
Service ser = new Service();
Offre of = new Offre();
Critere cr = new Critere();
string chaine = null;
SqlConnection connex = null ;
SqlCommand requete = null;
public void connexion()
{
try
{
Chaine="Data Source=HUGUETTE-PC;Initial
Catalog=hugaplay;Integrated
Security=True";
connex = new SqlConnection(chaine);
requete = new SqlCommand();
requete.Connection = connex;
}
catch (Exception)
{
MessageBox.Show("Echec de connexion à la base de
données!");
}
}
public void initialiser()
{
txt_codeservice.Text = "";
txt_nomservice.Text = "";
txt_codeservice.Focus();
}
public void initialiser2() {
txt_numoffre.Text = ""; txt_intitule.Text = "";
txt_lieuaffectation.Text = "";
txt_nomserv.Text = "";
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
65
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
cmb_codeservice.Text = ""; txt_numoffre.Focus();
}
private void groupBox3_Enter(object sender, EventArgs e) {
}
private void groupBox4_Enter(object sender, EventArgs e) {
}
private void button8_Click(object sender, EventArgs e) {
listBox1.Items.Add(txt_critere.Text);
cr.Numerocritere = maxcritere.ToString();
cr.Nomcritere = txt_critere.Text;
cr.Numoffre = txt_numoffre.Text;
connexion();
requete.CommandText = "insert into CRITERES values('" +
cr.Numerocritere
+ "', '" + cr.Nomcritere + "', '" + cr.Numoffre + "') ";
connex.Open();
requete.ExecuteNonQuery();
connex.Close();
MessageBox.Show("Enregistrement effectué avec
succès!");
maxcritere += 1;
}
private void button7_Click(object sender, EventArgs e) {
initialiser();
}
private void button6_Click(object sender, EventArgs e) {
initialiser();
}
private void button1_Click(object sender, EventArgs e)
{
ser.Codeservice = txt_codeservice.Text; ser.Nomservice =
txt_nomservice.Text;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
66
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
"',
connexion();
requete.CommandText = "insert into SERVICE values('" +
ser.Codeservice +
'" + ser.Nomservice + "') ";
connex.Open();
requete.ExecuteNonQuery();
connex.Close();
MessageBox.Show("Enregistrement effectué avec
succès!");
initialiser();
}
private void button4_Click(object sender, EventArgs e) {
DialogResult res = MessageBox.Show("Vous supprimerez toutes
les informations concernant ce service dans la base de données, vous le
voulez?", "QUESTION", MessageBoxButtons.YesNo, MessageBoxIcon.Question) ;
if (res == DialogResult.Yes)
{
connexion();
requete.CommandText = "delete from OFFRE where [Code
service]='"+txt_codeservice.Text +"' ";
connex.Open();
requete.ExecuteNonQuery();
connex.Close();
connexion();
requete.CommandText = "delete from SERVICE where [Code
service]='" +
txt_codeservice.Text + "' ";
connex.Open();
requete.ExecuteNonQuery();
connex.Close();
MessageBox.Show("Suppression effectuée avec
succès!");
}
else
{
initialiser();
}
}
int maxcritere = 0;
private void Gestion_application_Load(object sender, EventArgs
e)
{
// TODO : cette ligne de code charge les données dans
la table 'hugaplayDataSet.SERVICE'. Vous pouvez la déplacer ou la
supprimer selon vos besoins.
this.sERVICETableAdapter.Fill(this.hugaplayDataSet.SERVICE);
connexion();
SqlDataReader lecture;
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
67
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
requete.CommandText = "select * from CRITERES";
connex.Open();
lecture = requete.ExecuteReader();
while (lecture.Read())
{
maxcritere = int.Parse(lecture[0].ToString());
}
maxcritere += 1;
connex.Close();
}
private void button12_Click(object sender, EventArgs e)
{
Form form = null;
Form Form1 = new Principal();
form = Form1;
form.Show();
this.Hide();
}
private void button11_Click(object sender, EventArgs e)
{
initialiser2();
}
private void button3_Click(object sender, EventArgs e)
{
Form form = null;
Form Form1 = new Principal();
form = Form1;
form.Show();
this.Hide();
}
private void button10_Click(object sender, EventArgs e) {
of.Numoffre = txt_numoffre.Text;
of.Intituleoffre = txt_intitule.Text;
of.Datelancement = DateTime.Parse(dtp_datelancement.Text);
of.Datecloture = DateTime.Parse(dtp_datecloture.Text);
of.Lieuaffectation = txt_lieuaffectation.Text;
of.Codeservice = cmb_codeservice.Text;
connexion();
|
68
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
requete.CommandText = "insert into OFFRE values('" +
of.Numoffre + "', '" +
of.Intituleoffre + "','" + of.Datelancement + "', '" +
of.Datecloture + "', '" +
of.Lieuaffectation + "', '" + of.Codeservice+ "') ";
connex.Open();
requete.ExecuteNonQuery();
connex.Close();
MessageBox.Show("Enregistrement effectué avec
succès!");
}
private void button9_Click(object sender, EventArgs e)
{
initialiser2();
}
private void txt_numoffre_TextChanged(object sender, EventArgs e)
{
}
private void groupBox1_Enter(object sender, EventArgs e) {
}
private void button5_Click(object sender, EventArgs e)
{
connexion();
SqlDataReader lecture;
requete.Connection = connex;
requete.CommandText = "select * from SERVICE where [Code
service]='" +
txt_codeservice.Text + "'";
connex.Open();
lecture = requete.ExecuteReader();
while (lecture.Read())
{
txt_codeservice.Text = lecture[0].ToString();
txt_nomservice.Text = lecture[1].ToString();
}
connex.Close();
}
private void button2_Click(object sender, EventArgs e)
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
69
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
{
ser.Codeservice = txt_codeservice.Text; ser.Nomservice =
txt_nomservice.Text;
connexion();
requete.CommandText = "update SERVICE set [Code service]='"
+
ser.Codeservice + "', [Nom service]='" + ser.Nomservice + "'
";
connex.Open();
requete.ExecuteNonQuery();
connex.Close();
MessageBox.Show("Enregistrement effectué avec
succès!");
initialiser();
}
}
}
Conclusion partielle
Dans ce chapitre nous avons commencé par
présenter la Direction Générale de Recette du Kassaï
Occidental à Kananga qui est notre champs d'application, en suite nous
avons cité les outils utilises pour la réalisation de ce travail
et enfin nous avons présenté les interfaces graphiques de notre
DataMart.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
70
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
CONCLUSION GENERALE
Nous voici arrivés au terme de notre réflexion
scientifique, fruit de nos recherches rendue visible par ce travail de fin de
notre deuxième cycle, qui sanctionne la fin de nos études
universitaire à l'Université Notre-Dame du Kasayi (U.KA), dans la
faculté des sciences informatiques ; travail qui a porté sur la
mise en place d'un système décisionnel basé sur le
Datamart et l'arbre de décision pour le Recrutement du personnel
à la Direction Général de Recette du Kassaï
Occidental.
Dans notre travail, nous avons parlé d'abord du
système décisionnel qui présente l'ensemble des processus
qui permet de collecter, d'intégrer, de modéliser et de
présenter les données.
Nous avons également parlé des entrepôts
des données qui constituent le coeur du système
décisionnel jouant un rôle référentiel pour
l'entreprise puisqu'il permet de fédérer des données
souvent éparpillées dans le différentes base de
données et Nous avons réalisé le datamart avec SQL serveur
2008.
De ce qui précède, nous sommes persuadé
que l'ensemble des préoccupations répond à la
problématique de notre travail.
Le but de ce modeste travail est de mettre en place un
système décisionnel afin d'aider le gestionnaire des ressources
humaines en particulier chef du personnel de la direction général
de recette du Kassaï occidental d'avoir une vue d'ensemble sur les
informations concernant le recrutement de son personnel.
Notre contribution dans notre étude de cas était
de réaliser un Datamart pour la gestion de recrutement du personnel pour
que le chargé du personnel établisse au moment opportun son
Tableau statistique de tous les agents recruté, voir leur date
d'engagement, etc.
Enfin, nous disons à nos chers lecteurs que ce travail
étant une oeuvre scientifique et humaine peut avoir des imperfections,
ainsi, vos remarques, critiques et suggestions seront les bienvenues pour sa
perfection car il reste ouvert.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
71
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
BIBLIOGRAPHIE
OUVRAGES
1. ADIBA .M, Entrepôts de données et fouille
de données, Paris 2002.
2. BERTRAND BURQUIER, Business intelligence avec 2008,
Mise en oeuvre d'un projet décisionnel, Dunod, 2009.
3. DANIEL T. LAROSE, Des données à la
connaissance une introduction au Datamining, Vuibert, 2005.
4. VINCENT GUIJARRO, Les Arbres de Décisions
L'algorithme ID3, lile ,2006.
5. KIMBALL .R and m. ross, Entrepôts de
données, guide pratique de Modélisation dimensionnelle,
vuibert, paris, 2003.
6. RAKOTOMALALA. : Graphes d'induction apprentissage et
data mining, hermès, 2000.THESE
7. SERNA ENCINAS MARIA, Entrepôts de données
pour l'aide à la prise de décision médicale, conception et
expérimentation, UNIVERSITE JOSEPH FOURRIER, France 2005
NOTES DE COURS
8. KAFUNDA KATALAYI JP, Entrepôts des
données, L2 informatique option Gestion, cours inédit, U.K.A
2015-2016.
9. MANYA NDJADI, Recherche opérationnelle, G3
informatique option Gestion, cours inédit, U.K.A 2013-2014.
Mémoire et tfc
10. KANGIAMA LWANGI Richard : Extraction des
connaissances a partir d'un entrepôt des données à l'aide
de l'arbre de décision application aux données médicales,
UNIKIN 2010-2011.
WEBOGRAPHIE
11.
www.creatis.insa-lyon.fr,
le 16 janvier 2016.
12.
www.wilkipedia.org , le
18 jeanvier2016.
13.
www.devellopez.com , le
28 janvier 2016.
14.
www.wikipedia.org/algo
ID3, le 16 Mai 2016.
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
72
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
TABLE DE MATIERES
|
EPIGRAPHE
|
I
|
|
DEDICACE
|
.II
|
|
AVANT-PROPOS
|
III
|
|
LISTE DES FIGURES
|
IV
|
|
LISTE DES TABLEAUX
|
..V
|
|
LISTE DES SIGLES ET ABREVIATIONS
VI
|
|
|
0. INTRODUCTION GENERALE
|
1
|
|
0.1 CONTEXTE
|
1
|
|
0.2 PROBLEMATIQUE
|
1
|
|
0.3 HYPOTHESE
|
1
|
|
0.4 CHOIX ET INTERET DU SUJET
|
1
|
|
0.5 SUBDIVISION DU TRAVAIL
|
2
|
|
0.6 METHODOLOGIE ET TECHNIQUES
|
2
|
|
CHAP I : GENERALITES SUR LES SYSTEME DECISIONNELS [5,7, 8, 10,
11, 12]
|
4
|
|
I.0 INTRODUCTION
|
4
|
|
I.1 HISTORIQUE DES SYSTEMES DECISIONNELS
|
4
|
|
I.2 L'INFORMATIQUE DECISIONNELLE [12,9]
|
4
|
|
I.3 DEFINITION D'UN SYSTEME DECISIONNEL (BUSINESS INTELLIGENCE)
[8] ....
|
5
|
|
I.3.1 ARCHITECTURE DE SYSTEMES DECISIONNELS [8]
|
5
|
|
I.4 LES DIFFERENTS ELEMENTS CONSTITUTIFS DU SYSTEME DECISIONNEL
[13]
|
6
|
|
I.5 LES FONCTIONNALITES D'UN SYSTEME DECISIONNEL
|
6
|
|
I.6 LES APPORTS DES SYSTEMES DECISIONNELS
|
7
|
|
I.7 LES ENJEUX DE L'INFORMATIQUE DECISIONNELLE [11]
|
8
|
|
I.8 LES FONCTIONS ESSENTIELLES DE L'INFORMATIQUE DECISIONNELLE
|
8
|
|
CONCLUSION PARTIELLE
|
10
|
|
CHAP II: DATA WAREHOUSE ET DATA MART [7, 8, 1,]
|
11
|
|
II.1 INTRODUCTION
|
11
|
|
II.2 DEFINITION D'UN DATA WAREHOUSE (DW) [8]
|
11
|
|
II.2.1 OBJECTIF DU DATA WAREHOUSE [8]
|
12
|
|
II.2.2 LES COMPOSANTS DE BASE DU DATA WAREHOUSE
|
12
|
|
II.3 CARACTERISTIQUES D'UN DATA WAREHOUSE [8]
|
13
|
|
II.4 ENTREPOTS ET BASES DE DONNEES [7]
|
14
|
|
II.4.1 ROLE D'UN ENTREPOT DE DONNE
|
14
|
|
II.4.2 SYSTEMES TRANSACTIONNELS ET SYSTEMES DECISIONNELS :
|
15
|
|
II.4.3 DIFFERENCE ENTRE LE SYSTEME OLTP ET LE DATA WAREHOUSE [8]
|
15
|
|
II.4.4 LA PROBLEMATIQUE DE L'ENTREPRISE [8]
|
16
|
II.4.5 LA MODELISATION DIMENSIONNELLE ET LA MODELISATION
ENTITE/RELATION [5, 8] 16
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
73
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
II.4. 6 RELATION ENTRE LA MODELISATION DIMENSIONNELLE ET LA
MODELISATION ENTITE/RELATION 17
II.5 SCHEMAS D'UN DATA WAREHOUSE [8] 18
II.6 LE DATA MART [1, 8,] 21
II.6.1 INTRODUCTION 21
II.6.2 LES DEFINITIONS [8] 21
II.6.3 LA PLACE DU DATAMART DANS L'ENTREPRISE 22
II.6.4 DATAWAREHOUSE ET DATAMART [1] 22
II.6.4 ARCHITECTURE D'UN DATAMART 23
II.6.5 DATA WAREHOUSE VERSUS DATA MART 23
II.7 LES SERVEURS OLAP (ON-LINE ANALYTICAL PROCESSING) 24
II.7.1 LES SERVEUR ROLAP (RELATIONAL OLAP) 24
II.7.2 LES SERVEUR MOLAP (MULTIDIMENSIONAL OLAP)
24
II.7.3 LES SERVEUR HOLAP (HYBRID OLAP) 25
CONCLUSION PARTIELLE 26
CHAP III DATA MINING ET ARBRE DE DECISION [2, 3, 4, 8, 13]
27
III.0 INTRODUCTION 27
III.1 OBJECTIFS DU DATA MINING [8] 27
III.1 .2 PROCESSUS DU DATAMINING 29
III.1 .3 LES TACHES DU DATA MING 30
III .2 ARBRE DE DECISION [4, 9] 31
III .2.1 INTRODUCTION A L'ARBRE DE DECISION 31
III .2.2 DEFINITION 32
III .2.3 CARACTERISTIQUES ET AVANTAGES : 32
III .2.4 ALGORITHME ID3 [4, 13] 32
III .2.5 PRINCIPES 32
III .2.2 EXEMPLE PRATIQUE 33
III.3 CONCEPTS THEORIQUES SUR LE GRAPHE [6, 8, 9] 35
CONCLUSION PARTIELLE 37
CHAP IV : MODELISATION ET APPLICATION [2,8] 39
IV.0 INTRODUCTION 39
IV.1 ANALYSE DE L'EXISTAN 39
IV.1.2 ORGANIGRAMME DE LA DIRECTION GENERAL RECETTE DU
KASSAI
OCCIDENTAL 45
IV.1.3 FONCTIONNEMENT DE LA DIVISION DES RESSOURCES HUMAINES
46
IV.1.4 ORGANIGRAMME DU SERVICE CONCERNE 46
IV.1.5 DESCRIPTION DES POSTES 46
PROBLEME RENCONTRER 48
PROBLEMATIQUE ET MOTIVATION 48
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
|
74
|
MISE EN PLACE D'UN SYSTEME DECISIONNEL BASE SUR LE DATA MART ET
L'ARBRE DE DECISION POUR LE RECRUTEMENT DU PERSONNEL A LA DGR KOC
|
IV.2 MODELISATION 49
IV.2.1 OUTIL UTILISE 49
IV.3 LE SYSTEME TRANSACTIONNEL SQL SERVEUR 50
IV.3.1 DEFNITION 50
IV.2.2 MODELISATION MULTIDIMENSIONNELLE DE DATAMART 50
IV.2.3 MODELISATION DE L'APPLICATION 51
IV.2.4 .CONCEPTION D'UN DATA MART 55
IV.2.5 BUINESS INTELLIGENCE 57
IV.2.6 CREATION DU CUBE 58
IV.3 IMPLEMENTATION 59
IV.3.1 INTERFACE 59
CONCLUSION PARTIELLE 69
CONCLUSION GENERALE 70
BIBLIOGRAPHIE 71
TABLE DE MATIERES 72
Mémoire MANKAMBA YANKUMBA Jean Luc UKA 2015 - 2016
| 

