
Mémoire :
Mise en OEuvre de l'auto reconfiguration
partielle
et dynamique sur un FPGA Xilinx Virtex-II
Pro
Présenté par :
Guy WASSI
LEUPI
En vue de l'obtention du :

Spécialité :
Informatique Industrielle et
Systèmes
Automatisés (IISA)
Laboratoire d'accueil
ETIS
ENSEA - Université de Cergy
Soutenu le 07 Mars 2006
Jury :
Michel Drouin, Président
Véronique Perdereau, Responsable de la
formation
Amine Benkhelifa, Encadrant de stage

RESUME
Pour faire face à la complexité algorithmique et
aux exigences de flexibilité des applications futures (systèmes
de radio Communication 3G et 4G par exemple), de nouvelles approches doivent
être envisagées dans la conception des architectures
numériques. Dans ce contexte, les architectures reconfigurables
dynamiquement présentent des atouts considérables car elles
offrent le meilleur compromis Flexibilité/Performance. Les FPGAs (Field
Programmable Gate Array) sont les composants reconfigurables les plus denses et
flexibles, permettant des manipulations au niveau bit. Aujourd'hui, il existe
des plateformes mixtes (FPGA et Processeur intégré dans un SOC
unique une seule puce) permettant d'envisager l'auto-reconfiguration partielle
du FPGA sous le contrôle de son processeur embarqué. Dans une
telle configuration, la partie FPGA serait un accélérateur
matériel dont les fonctionnalités évolueraient et
s'adapteraient aux contextes, et ce sans interruption de service.
Mais les environnements de développement fournis par
les constructeurs de telles plateformes n'intègrent pas encore le flot
de conception des applications auto-reconfigurables. Certes les outils tels que
JBits API (Application Programming Interface) permettent de manipuler
sélectivement les ressources configurables des FPGAs Xilinx à
partir d'un PC. Mais JBits nécessite que JVM (Java Virtuel Machine)
tourne sur le processeur hôte, ce qui peut ne pas être souhaitable
dans le cas d'un système embarqué.
Ce rapport présente la mise en oeuvre d'une approche
modulaire (Modular Design Flow) de l'auto-reconfiguration dynamique et
partielle sur un FPGA Virtex-II Pro de Xilinx, le processeur PPC405
intégré reconfigurant dynamiquement et partiellement le FPGA via
un port interne. Pour cela nous avons développé une application
basée sur une API1 ICAP de Xilinx écrite en C et
permettant de lire/écrire/modifier la mémoire de configuration du
FPGA via l'interface interne ICAP (Internal Configuration Access Port). Bien
entendu cette API est assez légère pour tourner sur le processeur
PPC405 embarqué.
1 Application Programming
Interface

SOMMAIRE
|
Sommaire
Abréviations
Liste des figures
Liste des tableaux
Remerciements
|
2
5
5
6
5
|
|
1
|
INTRODUCTION
|
8
|
|
1.1
|
Le Contexte
|
8
|
|
1.2
|
But du stage
|
9
|
|
1.3
|
Travaux similaires
|
10
|
|
1.4
|
Environnement de travail
|
10
|
|
1.5
|
Plan du rapport
|
11
|
|
2
|
FPGA, RECONFIGURATION DYNAMIQUE ET CONCEPTION DE SYSTEMES
|
12
|
|
EMBARQUES
|
|
|
2.0
|
Introduction
|
12
|
|
2.1
|
Implémentation logicielle vs implémentation
matérielle d'une application
|
14
|
|
2.1.1
|
Implémentation logicielle
|
14
|
|
2.1.2
|
Implémentation matérielle
|
14
|
|
2.1.3
|
Partitionnement Matériel / Logiciel
|
15
|
|
2.2
|
Architecture des FPGAs (Field Programmable Gate Array)
|
16
|
|
2.2.1
|
Introduction
|
16
|
|
2.2.2
|
Principe de fonctionnement et Architecture Interne des FPGAs
|
16
|
|
2.2.3
|
Exemple d'architecture de FPGA : la série Virtex-II Pro de
Xilinx
|
18
|
|
2.2.4
|
Détails de quelques unes des ressources du Virtex-II Pro
|
19
|
a)
|
Les CLBs (Configurable Logic Blocks - Blocs de logiques
configurables)
|
19
|
b)
|
Les SLICES
|
19
|
c)
|
|
Les blocs multiplieurs 18 x 18 bits
|
20
|
|
|
d)
|
Le processeur PowerPC 405
|
21
|
|
2.3
|
Les divers scenarii de reconfiguration des FPGAs
|
22
|
|
2.3.1
|
Les modèles de reconfiguration
|
22
|
a)
|
La reconfiguration à contexte unique (Single Context)
|
22
|
b)
|
La reconfiguration multi-contextes (Multi-Context)
|
22
|
c)
|
|
La reconfiguration partielle ( Partially Reconfigurable)
|
23
|
|
|
2.3.2
|
Configuration du Virtex-II Pro de Xilinx
|
24
|
|
a)
|
Vue en couche d'un FPGA
|
24
|

b)
|
Organisation de la mémoire de configuration et son
influence sur la délimitation des modules reconfigurables
|
25
|
|
c)
|
Les modes de reconfiguration
|
27
|
|
d)
|
Le port de configuration interne ICAP
|
28
|
|
e)
|
Analyse des trames de configuration
|
30
|
|
3
|
METHODOLOGIES DE MISE EN OEUVRE DE L'AUTO-RECONFIGURATION
|
32
|
|
PARTIELLE ET DYNAMIQUE SUR LE VIRTEX-II PRO
|
|
|
3.1
|
Méthodologie de conception
|
33
|
|
3.1.1
|
Flot de conception standard (Ordinary Design Flow)
|
34
|
|
3.1.2
|
Le Flot de conception incrémentale (Incremental Design
Flow)
|
35
|
|
a)
|
La synthèse incrémentale
|
36
|
|
b)
|
Le Placement et Routage (P&R) Incrémental
|
36
|
|
3.1.3
|
Le Modular Design Flow pour la reconfiguration partielle
|
36
|
a)
|
Présentation
|
36
|
b)
|
|
Modular Design pour la reconfiguration partielle
|
37
|
|
|
3.2
|
Principe de l'Auto-Reconfiguration partielle et dynamique
|
38
|
|
3.2.1
|
De la reconfiguration partielle
|
38
|
|
3.2.2
|
De l'auto-reconfiguration dynamique
|
39
|
|
3.3
|
Exemple de mise en oeuvre d'une application auto-reconfigurable
sous ISE et EDK...
|
39
|
|
3.3.0
|
Introduction
|
39
|
|
3.3.1
|
La plateforme matérielle de développement, la carte
Virtex-II Pro de Memec Design
|
40
|
|
3.3.2
|
Conception sous EDK du module << Système a
processeur »
|
42
|
|
a)
|
Architecture du système
|
42
|
|
b)
|
Création de la plateforme matérielle du
système sous Xilinx EDK
|
43
|
|
c)
|
Création de la plateforme logicielle
|
45
|
|
d)
|
Gestion de la mémoire et génération du
linker script
|
45
|
|
e)
|
Implémentation du système à processeur
|
46
|
|
3.3.3
|
Conception sous ISE du design global <<Top » suivant
le Modular Design Flow
|
47
|
a)
|
Création des codes sources
|
47
|
b)
|
|
Etape de synthèse des fichiers sources
|
48
|
|
|
c)
|
Etape d'Initial Budgetting
|
50
|
|
d)
|
Etape d'Active Module Implémentation
|
51
|
|
e)
|
Etape de Final Assembly
|
52
|
|
f)
|
Etape de génération du bistream final
|
52
|
|
3.4
|
Récapitulatifs
|
53
|
|
4
|
DIFFICULTES RENCONTREES, CONCLUSION ET PERSPECTIVES
|
55
|
|
4.1
|
Difficultés rencontrées
|
55
|

4.1.1
|
Les restrictions physiques à la reconfiguration partielle
des FPGAs Xilinx
|
55
|
|
4.1.2
|
Les outils
|
56
|
|
4.2
|
Conclusion
|
57
|
|
4.3
|
Perspectives
|
58
|
|
4.3.1
|
Implémenter les bus macros pour les connexions
inter-modules
|
58
|
|
4.3.2
|
Utiliser XMS , le fichier de système de Xilinx
|
58
|
|
4.3.3
|
Implanter l'interface de Ethernet
|
58
|
|
4.3.4
|
OS temps réels pour la gestion de la ressource FPGA
|
59
|
|
A.
|
ANNEXES
|
60
|
|
A-1
|
ANNEXE 1: Les Outils
|
60
|
|
A-1.1
|
L'outil Floorplanner (Editeur de contraintes de placement, cas de
2 modules)
|
60
|
|
A-1.2
|
FPGA Editor (Routage avec bitstream complet)
|
60
|
|
A-2
|
ANNEXE 2: Procédure de création du fichier
SYSTEM.BMM
|
61
|
|
A-2.1
|
Fichier system_stub.bmm
|
61
|
|
A-2.2
|
Le fichier system.bmm
|
62
|
|
A-3.
|
ANNEXE 3: Utilisation de la Plate-forme de démonstration
|
62
|
|
A-3.1
|
Génération des bitstreams à partir des du
répertoire Modular
|
62
|
|
A-3.2
|
Paramètres de configuration de l'HyperTerminal
|
63
|
|
A-3.3
|
Message d'accueil de la demo
|
64
|
|
A-3.4
|
Exemple de début et fin de fichier RBT (module
compteur_rapide)
|
65
|
|
A-4.
|
ANNEXE 4 : Listing des programmes
|
66
|
|
A-4.1
|
Le code VHDL du Top (top.vhd)
|
66
|
|
A-4.2
|
Code VHDL d'un design du module reconfigurable
(compteur_lent.vhd)
|
69
|
|
A-4.3
|
Fichier de contraintes (top.ucf)
|
71
|
|
A-4.4
|
Les codes sources des programmes développés en C
pour le processeur PPC405.
|
73
|
|
A-4.5
|
Les fichiers de commande .batch pour le Modular
Design Flow
|
82
|
|
RÉFÉRENCES BIBLIOGRAPHIQUES
|
85
|
ABREVIATIONS
ASIC : Application-Specific Integrated Circuit BRAM : BlockRAM
CLB : Configurable Logic Blocks
CPU : Central Processing Unit
EDK : Embedded Development Kit FPGA : Field Programmable Gate
Array GPP : General Purpose Processors ICAP : Internal Configuration Access
Port LUT : Look Up Table
OPB : On-chip Peripheral Bus
RISC : Reduced Instruction Set Computer rSOC : reconfigurable
System-On-a-Chip SOC : System-On-a-Chip
SOPC : System-On-a-Programmable-Chip
UART : Universal Asynchronous Receiver-Transmitter
UCF : User Constraints File
XPS : Xilinx Platform Studio
VHDL : Very High Speed Integrated Circuit Hardware
Description Language
Liste des figures
Figure 1 : Exemple de Systèmes Embarqués 13
Figure 2 : Evolution des systèmes électroniques
13
Figure 3 : Implémentation temporelle vs
implémentation spatiale 14
Figure 4 : Structure globale des FPGAs 17
Figure 5 : Un LUT (Look-Up-Table) 17
Figure 6 : Implémentation d'une fonction Y = ab + (non)C
17
Figure 7 : Structure interne d'un CLB 20
Figure 8 : Structure interne d'un Slice 20
Figure 9 : Bloc multiplieur et SelectRam 20
Figure 10 : Vue générale du Virtex-II Pro XVP7
20
Figure 11 : Structure générale du processeur
PowerPC 405 21
Figure 12 : Les différents types de reconfiguration
23
Figure 13 : Reconfiguration partielle et dynamique du FPGA 24
Figure 14 : Vue en couche d'un FPGA 24
Figure 15 : Format d'adresse d'une Frame 27
Figure 16 : Adressage de la mémoire de configuration
27
Figure 17 : Port ICAP 28
Figure 18 : Architecture matérielle pour la
reconfiguration via le port ICAP 28
Figure 19 : L' Interface de configuration du Virtex-II Pro et ses
registres 30
Figure 20 : Flot de conception Standard pour les FPGAs 35
Figure 21 : Vue au niveau TOP d'un design modulaire 36
Figure 22 : Le flot Modular Design pour la reconfiguration
partielle 37
Figure 23 : Passage d'un Top à un autre par
reconfiguration partielle 38
Figure 24 : Etude de cas de l'auto-reconfiguration 40
Figure 25 : Vue schématique de la carte de developement
Virtex-II ProTM de Memec 41
Design
Figure 26 : Architecture du systeme a processeur 44
Figure 27 : Structure des répertoires du Projet 44
Figure 28 : Flot de conception de l'ensemble de la plateforme
54
Figure 29 : Vue physique de la carte Virtex-II Por de Memec
Design 56
Figure 30 : SOC hétérogène 58
Liste des tables
Table 1 : Comparatif des caractéristiques de
différentes implémentations 15
Table 2 : FPGAs de la famille Virtex-II Pro et leurs principales
ressources 19
Table 3 : Répartition des ressources en frames dans les
FPGAs Virtex-II Pro 28
Table 4 : Taille des données de configuration dans la
série Virtex-II pro 28
Table 5 : Fonctions permettant lire et écrire en
mémoire de configuration via le port 28
ICAP
Table 6 : Principaux fichiers générés au
déroulement du Modular Design Flow 29
REMERCIEMENTS
Je remercie tout particulièrement Monsieur Amine
Benkhelifa de m'avoir permis d'effectuer ce stage sous sa supervision, mais
surtout pour son aide précieuse, sa disponibilité, et toute son
expérience dont il a su me faire profiter tout au long de mon stage.
Je tiens à remercier également Monsieur Francois
Verdier pour ses constants éclaircissements et sa disponibilité
dont j'espère vivement n'avoir pas abusée.
Ma gratitude s'adresse également à Arthur Segard
qui m'a soutenu au quotidien et qui a certainement subi plus que toute autre
personne mes incessantes questions.
Je remercie également tous les autres membres du
Laboratoire ETIS pour l'esprit de convivialité qui règne en son
sein et qui a facilité mon intégration.
Je remercie enfin les membres du jury qui ont bien voulu assister
à mon exposé.
1. INTRODUCTION
1.1 Le contexte
Les besoins sans cesse croissants des systèmes
embarqués en puissances de calcul incitent à l'exploration de
nouvelles architectures. En effet, pour palier aux limites des processeurs
génériques ou spécifiques une solution est l'utilisation
d'architectures dédiées comme accélérateurs
matériels pour certaines tâches. Aujourd'hui, l'une des solutions
semblent être la mise en oeuvre d'architectures alliant dans une moindre
mesure la flexibilité des processeurs et la performance des circuits
spécialisés ASICs1 : Ce sont des architectures
reconfigurables. Cette approche est possible grâce aux avancées
technologiques qui permettent d'une part la mise en oeuvre des SOCs
(System-On-a-Chip, intégration sur une puce unique toutes les
fonctionnalités de traitement numérique des informations telles
que processeurs, DSP, mémoires, bus, blocs dédiés, etc...)
et d'autre part de fabriquer des circuits programmables FPGAs de plus en plus
denses et sophistiqués.
En effet, jusqu'alors essentiellement destinés au
prototypage rapide des ASICs (à cause des limites dues à leur
vitesse lente, leur coût et leur consommation élevés),
l'utilisation des FPGAs comme ressource matérielle de calcul
reconfigurable dynamiquement est aujourd'hui sérieusement
envisagée. Dans cette optique, le projet ARDOISE2 par exemple
a prouvé l'efficacité de la reconfiguration successive sur une
même architecture de type FPGA des opérateurs d'une chaîne
de traitement de flux vidéo.
Aujourd'hui, la densité croissante des FPGAs
(jusqu'à 10 millions de portes...) et leur possibilité de
reconfiguration rapide et dynamique ouvrent de nouvelles perspectives.
Des plateformes hétérogènes SOPC
(System-On-a-Programmable-Chip) comme les produits Xilinx Virtex-II Pro ou
Altera Excalibur-Arm intégrant des zones reconfigurables et des
processeurs de traitement généralistes (PowerPC405 ou ARM920)
permettent d'envisager la construction de systèmes auto-reconfigurables
dynamiquement : le processeur de la puce provoquant lui-même la
reconfiguration (partielle dans certains cas) du FPGA. Il devient ainsi tout
à fait envisageable de mettre en oeuvre des architectures SOC hybrides
dans lesquelles certaines tâches seraient implémentées
matériellement et gérées suivant le modèle des
tâches logicielles dans un OS (ordonnancement, commutation de
tâches, préemption de tâches, etc...).
1 Application-Specific Integrated Circuit; circuit
intégré optimisé pour une application
spécifique.
2 ARDOISE Architecture Reconfigurable Dynamiquement
Orientée Image et Signal,
Ce type d'architectures hybrides où les tâches
s'exécuteraint sous forme matérielle et/ou logicielle offrirait
d'une part une flexibilité supplémentaire et d'autre part
permettrait l'utilisation de toutes les unités de calcul (Processeur,
DSP, FPGA, etc.).
1.2 But du stage
La problématique globale de ce stage est la mise en
oeuvre de l'auto-reconfiguration partielle et dynamique sur une plateforme SOPC
intégrant sur une même puce processeur(s) et FPGA. En effet, la
technologie n'étant pas encore mature surtout au niveau de la mise au
point d'outils permettant d'automatiser cette mise en oeuvre, notre but est de
montrer la faisabilité de l'«Auto-reconfiguration partielle et
dynamique » à l'aide d'outils de développement
disponibles.
Nous entendons ici par Auto-reconfguration partielle et
dynamique le fait pour le processeur intégré1 au
FPGA de reconfigurer partiellement ce dernier sans perturber le fonctionnement
continu de la zone non reconfigurée.
Ci-dessous2 (figure) se resument les choix faits
à priori :
- Configurer totalement le FPGA avec un design modulaire
(developpé suivant le Modular Design Flow approprié
à la reconfiguration partielle) depuis un PC par les moyens classiques
et éprouves.
- Générer sur PC les bitstreams partiels pour le(s)
module(s) reconfigurable(s).
- Dévélopper une application (srp.c) pour
le processeur PPC405 intégré permettant à ce dernier de
communiquer avec le PC via le port serie et l'application
Hyperterminal afin de
Embarquée AC! soutenue par le MESR en 1998 et
1999.
www-etis.ensea.fr/Equipes/Archi
1 Chez la famille Virtex-!! Pro de Xilinx, ce processeur peut
être un coeur hard (AS!C, cas du PPC405) immergé en dur dans le
FPGA ou un coeur soft (cas du Microblaze) instancié dans le
FPGA.
2 Vue imagée de la plateforme
auto-reconfigurable
charger en mémoire embarquée la version ASCII
(format RBT) des bitstreams générés, et de reconfigurer
dynamiquement et à la demande le(s) module(s) reconfigurable(s) du FPGA
via le port ICAP. Il est à préciser qu'après chargement en
mémoire embarquée, la plateforme devient autonome ; le temps de
reconfiguration d'un module n'inclut pas le temps de transfert de son bitstream
de l'ordinateur PC vers la mémoire embarquée.
A l'issue de ce stage, si le flot de mise en oeuvre de
l'auto-reconfiguration dynamique du Virtex-II Pro est parfaitement
maîtrisé, il peut servir au développement d'un OS temps
réels permettant de gérer la ressource FPGA, et ainsi
d'évaluer l'intérêt de la reconfiguration partielle et
dynamique.
Nous avons choisi le FPGA Xilinx Virtex II-Pro pour cette mise
en oeuvre car d'une part il est partiellement reconfigurable, et d'autre part
il intègre en dur un ou plusieurs coeurs de processeur PowerPC405.
1.3 Travaux similaires
La mise en oeuvre de la reconfiguration partielle et dynamique
sur FPGA Xilinx suivant un flot de conception modulaire (Modular Design
Flow) fait l'objet de beaucoup d'intérêt dans plusieurs
laboratoires de recherche universitaire actuellement. Pour la reconfiguration
partielle et dynamique, [12] et [20] présentent chacun des exemples
simples et très utiles. [6] montre un exemple appliqué à
la radio-logicielle (software radio). [8] et [15] détaillent la
méthodologie de mise en oeuvre. Mais dans les cas cités
precedemment, la reconfiguration est contrôlée depuis l'exterieur
; il ne s'agit donc pas d'auto-reconfiguration. [3] et [5] présentent
effectivement un cas d'auto-reconfiguration où le processeur PPC405
intégré reconfigure partiellement le FPGA. Mais dans le premier,
le contrôle de l'ICAP1 est totalement effectué par le
processeur , et non par un contrôleur instancié dans le FPGA. Dans
le second, on utilise l'outil JBits pour manipuler les bitstreams de
reconfiguration.
1.4 Environnement de travail
Ce stage s'est déroulé au sein du laboratoire
ETIS (Equipe Traitement des Images et du Signal) et plus
précisément dans l'équipe « Architecture ».
L'ETIS est abritée au sein de l'ENSEA (Ecole Nationale Supérieure
de l'Electronique et de ses Applications), et ses membres assurent outre la
recherche, des activités d'enseignement dans les deux
établissements d'attache du laboratoire que sont l'Université
Cergy-Pontoise et l'ENSEA. Les outils support mis à disposition par le
laboratoire pour ce stage sont essentiellement la carte de
développement Virtex-II Pro conçue par Memec Design
et les outils de développement ISE 7.1i et EDK 7.1.i de Xilinx.
1.5 Plan du rapport
Dans une première partie nous présenterons
sommairement le composant FPGA, et ensuite la notion d'architecture
reconfigurable de type FPGA et de leur intérêt. Ensuite nous
étudierons la méthodologie de mise en oeuvre de la
reconfiguration dynamique du Virtex-II Pro en nous focalisant sur le «
Modular Design Flow ». Enfin nous présenterons la plateforme
auto reconfigurable que nous avons mise en oeuvre, et qui permet au processeur
PPC05 intégré de reconfigurer dynamiquement et à la
demande une partie du FPGA. Quelques annexes en fin de document
présentent les differents codes en C et en vhdl développés
dans le cadre de ce projet ainsi que les détails sur l'utilisation de la
plateforme de démonstration que nous avons mis en oeuvre.
1 ICAP : Internal Configuration Access Port, port de
configuration interne des FPGA Xiinx
2. FPGA, RECONFIGURATION DYNAMIQUE ET CONCEPTION DES
SYSTEMES EMBARQUES
2.0 Introduction
Une architecture reconfigurable est une architecture dont les
ressources (calcul, interconnexions, ...) peuvent être modifiées
pour s'adapter à un traitement. Les FPGAs sont la parfaite illustration
de la reconfigurabilite matérielle au niveau bit d'une architecture. Ces
dernières années sont apparus des FPGAs reconfigurables
dynamiquement et/ou autoreconfigurables. Aujourd'hui, la plupart des
architectures ont un certain degré de reconfigurabilité.
La reconfiguration dynamique implique que le FPGA peut
être partiellement reconfiguré sans perturber le fonctionnement
continu du reste du composant qui n'a pas été reconfiguré.
L'autoreconfiguration est une forme de reconfiguration dynamique. En effet,
elle suppose l'implémentation du contrôle de la reconfiguration
partielle du FPGA sur une partie de ses propres ressources. Ceci n'est possible
que si l'intégrité de la logique de contrôle
implémentée dans le FPGA est assurée durant la
reconfiguration.
Par ailleurs, la croissance continue de la densité
d'intégration des puces électroniques permet de concevoir
aujourd'hui des systèmes électroniques entiers sur une seule
puce. Cette avancée technologique profite au premier chef aux FPGAs qui
en outre ont des fréquences de fonctionnement de plus en plus
élévées, des consommations et des temps de reconfiguration
en baisse constante. Tous ces atouts font aujourd'hui des FPGAs de serieux
concurrents aux solutions « tout ASIC », avec la flexibilté en
plus.
On parle de plus en plus de conception à base de FPGAs,
d'où les acronymes SOPC (SystemOn-a-Programmable-Chip) et rSOC
(reconfigurable-SOC) ; ceci implique clairement que l'utilisation des FPGAs ne
se limite plus comme à ses débuts, au prototypage rapide des
circuits ASICs.
La Figure 1 montre les deux approches qui
prédomineront dans la conceptions des systèmes numériques
sur une seule puce. L'approche SOC (System-On-a-Chip) qui consiste
à intégrer sur une seule puce ASIC des composants
hétérogènes, et l'approche SOPC
(System-On-aProgrammable-Chip) qui consiste à implémenter
presque tout le système entier sur une seule puce programmable de type
FPGA. La première approche permet une plus grande diffusion, alors que
la seconde apporte beaucoup plus de souplesse. La tendance aujourd'hui est
davantage à la conception des circuits FPGAs intégrant des coeurs
de processeurs (hard ou
soft) et autres blocs ASICs dediés au traitement
numérique du signal (additionneurs, multiplieurs, Ram, etc...) et aux
communications (I/Os).
Il est a noter également que le flot de conception des
FPGAs s'est essentiellement appuyé sur celui largement eprouvé
des ASICs.

Figure 1 : Exemple de Systèmes Embarqués
[9]
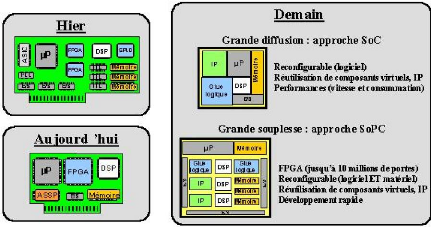
Figure 2 : Evolution des systèmes électroniques
[17]
Dans ce chapitre, nous présenterons la notion
d'implémentation matérielle et/ou logicielle d'une application,
puis le composant FPGA en nous focalisant sur le Virtex-II Pro, ensuite
l'intérêt des architectures reconfigurables et les differents
scénarii de reconfiguration.
2.1 Implémentation logicielle vs
implémentation matérielle d'une application
2.1.1 Implémentation logicielle (Figure 3.a)
Dans un modèle d'exécution logicielle, le
traitement est séquentiel et exécuté par un processeur. En
effet, un CPU (Central Processing Unit) exécute une tâche (ou une
operation) à la fois. Toute application est découpée en
tâches unitaires exécutées les unes à la suite de
autres (Figure 3.a). Le passage d'une tâche à l'autre
nécessite une sauvegarde de contexte (context switch) qui permet de
conserver la cohérence globale de l'application, et donner une apparence
d'exécution parallèle des tâches. Mais ce modèle
nécessite des processeurs de plus en plus rapides pour répondre
à la complexité algorithmique des applications. Or les
fréquences de fonctionnement des processeurs ne sauraient être
augmentées indéfiniment a cause d'une part des limites
technologiques, et d'autre part d'une augmentation de la consommation qui n'est
pas souhaitable dans les systèmes embarqués.
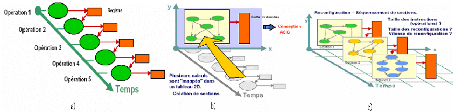
Figure 3 : Implémentation temporelle vs
implémentation spatiale [13]
2.1.2 Implémentation matérielle (Figure
3.b)
Par contre dans un ASIC ou un FPGA, les applications
(algorithmes, fonctions, etc...) décrites dans un langage de description
de circuits (VHDL, Verilog, etc...) sont implémentées
matériellement; ceci apporte un gain de performance supérieur
à celui des processeurs grâce à l'implémentation
spatiale (parallèlisme) des tâches [13]. En effet dans ce type
d'implémentation matérielle, seul le temps de propagation des
signaux de l'entrée à la sortie d'un système fixe sa
limite supérieure en fréquence.
En outre, la reconfigurabilité dynamique de
certains FPGAs permet de faire évoluer l'architecture pour s'adapter au
traitement (Figure 3.c), contrairement aux ASICs. Il est aujourd'hui
envisagéable d'implémenter et d'exécuter
séquentiellement sur ce type de composants reconfigurables plusieurs
algorithmes, et de profiter à la fois de leur reconfigurabilité
(flexibilité) et de leur performance. Pour cela une architecture
reconfigurable inclut généralement deux principales parties, une
partie matérielle et une partie logicielle. La partie logicielle
comprend généralement un processeur (à usage
générique - GPP ou orienté traitement du signal -
DSP) chargé du contrôle et de la gestion de la
reconfiguration de la partie
matérielle, ainsi que de l'exécution des
tâches encore dévolues au logiciel. Elle utilise la partie
matérielle (un ou plusieurs FPGAs) comme accélérateur
matériel, en y implémentant les parties les plus critiques des
traitements.
Le tableau comparatif ci-dessous (Table 1) permet de
situer les FPGAs parmi les principaux types d'architectures et leurs
caractéristiques [6].
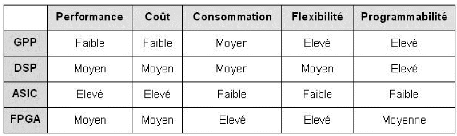
Table 1 : Comparatif des caractéristiques de
différentes implémentations [6]
2.1.3 Partitionnement Matériel / Logiciel
Les problèmes de partitionnement
matériel/logiciel des tâches apparaissent dès que les
ressources permettent une implémentation matérielle et/ou
logicielle des tâches. En effet, pour les systèmes incluant une
architecture matérielle reconfigurable et un ou plusieurs processeurs(
GPP, DSP), le programme doit être prémièrement
partitionné en sections devant s'exécuter soit logiciellement,
soit matériellement. En général, les opérations
récursives et de contrôle sont plus efficaces sur processeur. Mais
les outils disponibles à ce jour fournissent en général
soit le modèle matériel, soit le modèle logiciel
d'implémentation d'une application. Des travaux sur des compilateurs
permettant d'automatiser ce processus de partitionnement existent1
[10]. Mais avec le developpement d'architectures reconfigurables, il est de
plus en plus envisagé d'avoir des tâches ayant les deux
modèles d'exécution, l'un où l'autre étant
utilisé à un instant donné suivant des critères
d'efficacité et de priorité par exemple.
Notre étude étant essentiellement circonscrite
à la mise en oeuvre d'une plate-forme auto-reconfigurable dynamiquement
sur FPGA Virtex-II Pro de Xilinx, nous présentons suscintement
ci-dessous l'architecture des FPGAs ainsi que les différents
scénarii de reconfiguration, puis nous relèvons ceux qui sont
envisagéables sur cette famille de FPGAs.
1 C'est le cas du projet POLIS qui a mis au point un outil
du meme nom, permettant la conception conjointe matériel/Logiciel
(CoDesign) et supportant des outils de spécification niveau system comme
Esterel. Universite de California Bekerley,
http://embedded.eecs.berkeley.edu/Respep/Research.
2.2 Architecture des FPGAs
2.2.1 Introduction
C'est une famille de puces électroniques introduite par
la société Xilinx. Les FPGAs sont les premières
architectures reconfigurables à avoir été
proposées. Ils ont l'avantage d'être recongurables à
souhait. Ils comprennent des blocs configurables qui permettent de
générer des fonctions logiques combinatoires ou
séquentielles sur 1 bit. Ainsi, en associant plusieurs
éléments configurables de 1 bit par le biais d'interconnexions
tout aussi programmables (Figure 4), l'utilisateur est capable de
générer n'importe quelle fonction logique.
Si le nombre d'unités configurables est suffisamment
important, il est possible, en associant ces blocs, de recréer un
système entier. C'est pour cette raison que ces composants sont
utilisés pour faire des prototypes de circuits, avant de les envoyer
chez le fondeur de silicium. Son développement s'est
accéléré sous la double pression du
«Time-To-Market»1 et de
«FirstTime-Right»2 (minimiser d'une part le temps
de développement et de mise sur le marche des circuits digitaux et
d'autre part éviter toute défaillance dans leur conception).
2.2.2 Principe de fonctionnement et Architecture Interne
des FPGAs
La structure interne ainsi que la technologie utilisées
dans les FPGAs varient suivant les fabricants. Mais la structure globale de la
Figure 4 (si on y rajoute les entrées/sorties programmables)
est valable indépendamment des fabricants. En général le
bloc configurable est bati autour d'un LUT (Look-Up-Table, voir Figure
5). Un LUT permet d'implémenter toute fonction combinatoire (ou
séquentielle, d'où le flip-flop de sortie) à quatre
entrées.
La Figure 6 présente l'implémentation
d'une fonction combinatoire a l'aide d'une LUT. La table de vérite de la
fonction est stockée dans une RAM connectée à un
multiplexeur. Configurer une LUT revient donc à stocker la table de
vérite de la fonction dans sa RAM et à router les signaux a, b et
c vers les entrées de sélection du multiplexeur.
1 Le Time-To-Market qui traduit donne «temps de mise
sur le marché» est vrai challenge pour reduire le temps de
developpement d'un nouveau produit électronique afin de s'adapter a la
reduction croissante du cycle de vie de produits électroniques grands
publics.
2 Le First-Time-Right par contre traduit la
nécessité d'éviter toute erreur dans la conception d'un
circuit avant l'envoi chez le fondeur d'ASIC; en effet un ASIC
défectueux coute en NRE (Non Recurring Engineering), cette somme que les
fournisseurs d'ASIC facturent au concepteur des le démarrage de
processus de fabrication. Dans tous les cas, le cout de la technologie ASIC
contribue largement a l'émergence des FPGAs.
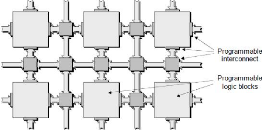
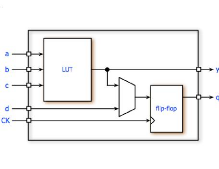
Figure 4 : Structure globale des FPGAs [14]
Figure 5 :
Un LUT (Look-Up-Table) [14]
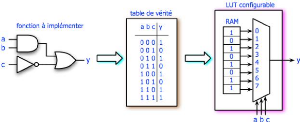
Figure 6: Implémentation d'une fonction Y = ab +
(non)C [14]
Grâce à sa granularité fine, on est
capable avec un circuit FPGA d'exploiter le parallélisme autant qu'avec
un circuit spécifique ASIC dans la mesure où l'on est capable de
le recréer entièrement par association des éléments
configurables. Mais cette fine granularité qui offre toute la
flexibilité logique voulue est au prix d'une performance moindre
comparée aux ASICs. En effet, elle apporte deux problèmes :
- La baisse de la fréquence de fonctionnement due au temps
de propagation des signaux.
- L'augmentation des temps de reconfiguration requis, ce qui
peut empêcher par exemple d'enchaîner sur le même circuit
deux configurations pour des applications à contraintes temps
réel [2].
Grâce aux avancées technologiques, les FPGAs sont
envisagés aujourd'hui (sur les plans du coût et des performances)
comme une alternative entre les solutions dédiées très
performantes (ASIC) et les solutions programmables très flexibles
(processeurs et DSP). Les principaux fabricants proposent aujourd'hui des FPGAs
intégrant jusqu'à 10 millions de portes logiques, et sur lesquels
on peut même synthétiser un coeur de microprocesseur (Microblaze
sur FPGAs Xilinx [21], Nios sur ceux d'Altera). De même, les FPGAs
à mémoire de configuration de type SRAM1 permettent la
reconfiguration dynamique. C'est le cas du Virtex-II Pro.
2.2.3 Exemple d'architecture de FPGA : la série
Virtex-II Pro de Xilinx (figure10)
Introduite en 2002 et fabriquées en technologie CMOS
1.5V/130nm, la série Virtex-II Pro vise les fortes densités
(jusqu'à 10 millions de portes). Elle intègre en dur de un
à quatre coeurs de processeur RISC IBM PowerPC 405 (jusqu'à
400Mhz) ainsi que des blocs optimisés pour les applications
orientées traitement du signal (blocs de RAMs de 18 Ko et de
multiplieurs 18x18, etc...). Outre la logique programmable, elle comprend ainsi
(Error! Reference source not found.):
- Des entrées/sorties configurables en
entrée, sortie ou bidirectionnel, supportant de nombreux standards
(LDVS, PCI-X, differentiel,...) et interfaçant les pins externes du
circuit et la logique reconfigurable interne.
- Des blocs multiplieurs 18x18 bits cablées et
donc rapides et de faible consommation.
- Des CLBs (Configurables Logics Blocs - Figure
7) qui sont des blocs de ressources programmables permettant
d'implémenter des fonctions combinatoires et séquentielles.
- Des émetteurs/récepteurs série haut
débit (RocketIO) supportant des débits atteignant 3,125 Gb/s
par canal (6,25 Gb/s pour les RocketIO X).
- Des blocs de mémoire selectRAM qui sont des
RAM dual port de 18 kb, chacune programmable en mémoire de 16K X 1 bit
à 512 x 36 bits, et cascadables pour former des blocs mémoires de
taille plus grande.
- Des blocs DCMs (Digital Clock Manager) permettant
la synthèse de fréquences (multiplication et divivion d'horloge),
l'auto-calibration, la compensation des retards pour une parfaite distribution
d'horloge, etc...
1 On peut distinguer les FPGAs par leur type de
mémoire de configuration (fuse, anti-fuse, EEPROM, E2PROM/Flash, SRAM).
Le type détermine la reconfigurabilité du FPGA. Par exemple les
FPGAs à SRAM peuvent facilement être reconfigurés
partiellement et dynamiquement.
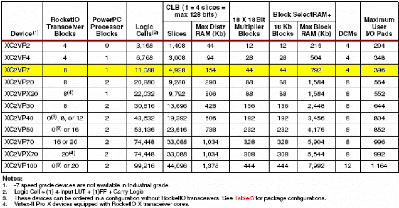
Table 2 : FPGAs de la famille Virtex-II Pro et leurs
principales ressources
(la colonne grisée montre les éléments
du FPGA XVP7 que nous avons utilisée)
2.2.4 Détails de quelques unes des ressources du
Virtex-II Pro
Nous détaillons ci-dessous les caractéristiques qui
permettent de mieux comprendre les règles de reconfiguration du
Virtex-II Pro.
a) Les CLBs (Configurable Logic Blocks - Blocs de
logiques configurables)
Un FPGA Xilinx comprend un certain nombre de colonnes de
CLBs. Chaque CLB comprend 4 Slices identiques et 2 buffers tri-states (TBUF,
Figure 7) . Chaque colonne de CLB comprend 2 colonnes de Slices.
Chaque CLB est relié à une matrice d'interconnexion (switch
matrix) pour accéder à la matrice générale de
routage. Les Slices d'un même CLB sont reliés entre eux et aux
CLBs voisins par des interconnexions directes et rapides (fast connects to
neighbors, Figure 7).
b) Les SLICES (Figure
78) Chaque Slice contient :
- Deux générateurs de fonction (F & G); ce
sont des LUTs (Look-Up-Table) pouvant implémenter soit une fonction
logique à 4 entrées, soit une mémoire SelectRAM 16 bits
(dans ce cas on parle de distributed selectRam) , ou encore un
registre à décalage 16 bits.
- Deux éléments de stockage (Register/Latch) qui
servent de registres D flip-flop de sortie.
- Deux multiplexeurs MUXFX qui combinés aux
générateurs de fonction permettent de générer des
fonctions logiques de plus de 4 entrées.
- Des portes logiques qui facilitent l'implémentation de
la logique arithmétique ( des XORs pour additionneurs, des ORs pour les
sommes de produit et des ANDs pour les multiplieurs).
- Des chaînes de propagation rapide de retenue (CY).
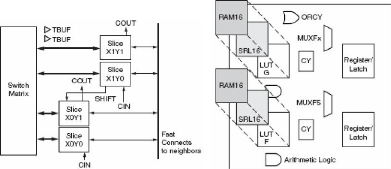
Figure 7 : Structure interne d'un CLB Figure 8 : Structure
interne d'un Slice
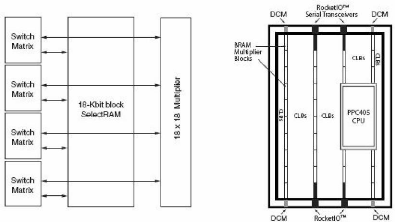
Figure 9 : Bloc multiplieur et SelectRam Figure 10 : Vue
générale du
Virtex-II Pro XVP7
c) Les blocs multiplieurs 18 x 18 bits
(Figure 910)
Ils réalisent des multiplications en complement
à 2 (signes), et peuvent être associés à de blocs
memoires SelectRam 18 Kb pour former des modules MAC (Multiplier-Accumulator)
très utiles en traitement numérique du signal (filtres FIR et
IIF). Cables en dur, ils sont optimisés en vitesse et en consommation.
Un virtex-II pro peut contenir jusqu'a 444 blocs multiplieurs de ce type, et
autant de blocs SelectRam (Error! Reference source not
found.).
Toutes ces ressources permettent également au Slice de
combiner avec des Slices voisins pour implémenter des fonctions plus
complexes.
d) Le processeur PowerPC 405
Le PowerPC 405 est un processeur RISC1 de 32 bits
d'architecure Harvard1. Il est optimise pour de hautes performances
(jusqu'à 400Mhz pour certains) et des basses consommations (0.9mW/MHz).
Il est intégré dans le FPGA Virtex-II Pro comme le montre la
Figure 9 10.
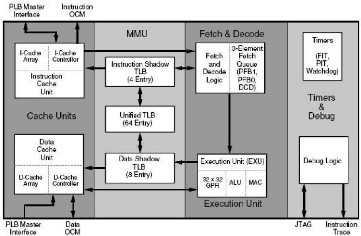
Figure 11 : Architecture générale du processeur
PowerPC 405 Il possède essentiellement:
- Une MMU (memory management unit) qui peut faciliter la misen
en oeuvre d'un systeme de fichier, solution envisageable dans notre cas pour
stocker les configurations en mémoire embarquée sous forme de
fichier.
- Deux interfaces mémoires (Figure 11) ;
l'interface OCM (On-Chip-Memory) subdivisée en deux blocs ; l'un pour
les données et l'autre pour les instructions et l'interface PLB.
- Une interface JTAG permettant le debugage (en plus de trois
autres modes de debogage supportés).
- Un pipeline de 5 étages
- Des caches de données et d'instruction
séparées et de 16 Ko chaque. - 3 Timers programmables.
1 Reduced Instruction Set Computer ; concept consistant
à réduire le jeu d'instruction des processeur, et parti du
constat suivant lequel dans 80% des cas un processeur n'utilisait que 20% de
son jeu d'instruction (essentiellement des Load/Sore)
- Une unité de division/multiplication.
En outre ce processeur implémenté en dur occupe
2% de la surface totale d'un FPGA Virtex-II Pro XVP50 par exemple
(Error! Reference source not found.). Mais il n'a pas
d'unité arithmétique flottante.
Le processeur est connecté au bus PLB (Processor Local
Bus) directement, et a un second bus (OPB pour On-chip Peripheral Bus)
via un pont entre les deux bus.
2.3 Les divers scénarii de reconfiguration des
FPGAs
2.3.1 Les modèles de reconfiguration [4]
Un facteur de différenciation des FPGAs est leurs modes
(ou possibilités) de
configurations qui varient d'une famille à l'autre. Ces
modes sont souvent liés à la technologie de fabrication et
peuvent être des critères déterminants lors du choix du
FPGA cible pour implémenter une application. Par exemple pour une
application nécessitant plusieurs configurations (contextes), il peut
être profitable d'utiliser un FPGA reconfigurable dynamiquement
(RTR-Runtime Reconfigurable). Comme décrit dans [4], on peut
classifier les architectures reconfigurables en trois catégories suivant
leurs modèles de reconfiguration (Figure 12). Ces
modèles qui s'appliquent également aux FPGAs sont:
a) La reconfiguration à contexte unique
(Single Context)
Elle est encore appelée Reconfiguration totale car la
reconfiguration se fait entièrement sur toute la surface de la matrice
de configuration (sur tout le FPGA par exemple). Tous les bits de la matrice de
configuration sont donc réécrits, même s'ils n'ont pas
changé entre deux configurations (Figure 12.a). Ce qui est
évidemment une perte de temps. La reconfiguration à contexte
unique est utilisée pour des applications statiquement
reconfigurables (SRD - Statically Reconfigurable Design). Plusieurs
applications sont programmées une à la fois (par chargement du
fichier binaire correspondant) sur le FPGA; un Reset du FPGA est
effectué entre deux programmations.
b) La reconfiguration multi-contextes
(Multi-Context)
Elle se fait sur des FPGAs ayant plusieurs mémoires de
configuration se trouvant sur des plans différents (Figure
12.b). On peut ainsi "charger" plusieurs plans de configurations dans le
FPGA, et le passage d'une configuration à l'autre (commutation de
contexte) se fait par commutation d'un plan mémoire à un autre.
Par rapport à la reconfiguration à contexte unique,
1 Memoires de données et des programmes
separées et accessibles par des bus séparés
également, ce quipermet l'accès simultanée des
données et des programmes, contrairement a l'architecture de Von
Neumann. Ceci
le temps de reconfiguration en est fortement
accéléré. En outre, une mémoire inactive peut
être reprogrammé pendant que l'autre est active sur le FPGA. Une
sorte de mémoire cache de contexte existe alors dans le FPGA.
Ce type de reconfiguration s'apparente au Page Mode
[1] dans les séries Stratix et APEX 20K d'Altera où on peut
charger jusqu'à 8 configurations en mémoire Flash et passer
dynamiquement d'une à l'autre. Dans ce cas la mémoire Flash est
divisée en pages, chaque page contenant un bitstream1 total
pouvant configurer tout le FPGA ; il ne s'agit pas de plan de configuration, et
donc pas d'accélération de temps de reconfiguration.
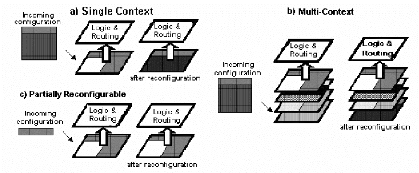
Figure 12 : Les différents types de reconfiguration
[4]
c) La reconfiguration partielle ( Partially
Reconfigurable)
Contrairement à la reconfiguration à contexte
unique ou multi-contextes, on peut configurer partiellement le FPGA afin de
n'utiliser que les ressources nécessaires à
l'implémentation de l'application (Figure 12.c) ; on reduit
ainsi la consommation en énergie et en ressources logiques du FPGA,
ainsi que le temps de reconfiguration.
En outre, une portion du FPGA peut être
reconfigurée dynamiquement (c'est-à-dire reconfigurer une partie
du FPGA pendant que l'autre active), ce qui cache la latence due à la
reconfiguration qui peut s'observer dans la reconfiguration à contexte
unique ou multiple. Reconfigurer dynamiquement permet l'implémentation
matérielle de beaucoup plus de sections de l'application et
d'accélerer ainsi l'exécution. Par exemple sur la Figure
13, le module «Control » est remplacé par le
module « Video out » par reconfiguration partielle du
FPGA.
accelère l'execution et est tres utilisé dans
les processeur de type DSP
1 Fichier de flot de données contenant une
configuration prête à être chargée dans le FPGA. Dans
le cas du Virtex, il peut être en .bit pour le binaire ou en .rbt pour
son equivalent ASCII. L'Outil de programmation de FPGA (Impact par exemple)
supporte indifféremment l'un ou l'autre type de fichier pour la
reconfiguration.
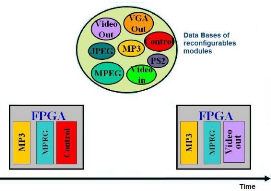
Figure 13 Reconfiguration partielle et dynamique du
FPGA
2.3.2 Configuration du Virtex-II Pro de Xilinx
a) Vue en couche d'un FPGA
Le FPGA peut être vu comme une structure à deux
couches (Figure 14):
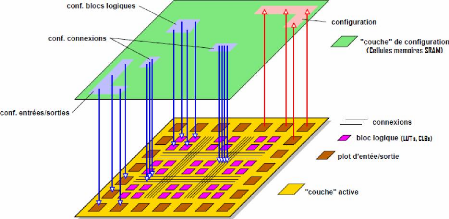
Figure 14 : Vue en couche d'un FPGA [16]
- Une couche active ou couche logique qui comprend des ressources
logiques, des
entrées/sorties, des ressources de routage, et
éventuellement des blocs dediés.
- Une couche de configuration encore appelée
mémoire de configuration et permettant de
programmer électriquement les caractéristiques
des ressources de la couche active. En effet,
toutes les ressources logiques
du FPGA sont contrôlées par le contenu de la
«mémoire de
configuration» (chez Xilinx cette mémoire
est à base de cellules SRAM1 volatiles, le FPGA doit donc
être reconfiguré à chaque mise sous tension). Leur contenu
fixe l'équation des LUTs, le routage des signaux, les
entrées/sorties et leur tension ainsi que les paramètres de
toutes les autres ressources du FPGA.
Pour programmer un FPGA, les instructions de contrôle de
configuration ainsi que les données à écrire en
mémoire de configuration sont fournies sous forme d'un bitstream qui est
envoyé dans la puce via une interface de configuration (JTAG, SelectMap,
Série,...).
b) Organisation de la mémoire de configuration
et son influence sur la délimitation des modules
reconfigurables
La mémoire de configuration du Virtex-II Pro
est constituée d'un certain nombre de colonnes
élémentaires de mémoires appelées Frames.
Une Frame est la plus petite unité de mémoire
reconfigurable individuellement dans un Virtex-II Pro ; elle est donc
adressable individuellement sur 32 bits et permet ainsi aux FPGAs Xilinx
d'être partiellement reconfigurables2. Une Frame occupe toute
la hauteur du FPGA et chaque ressource programmable (CLBs, IOBs, IOIs, GCLKs,
BRAMs) est constituée d'un certain nombre de frames (Error!
Reference source not found.). Le nombre de Frames par ressource ainsi
que la taille de la Frame dépendent
du type de FPGA et fixent la taille du fichier de
configuration totale (Error! Reference source not found.). Par
exemple dans un Virtex-II Pro XVP7 constitué de 1320 frames, on trouve
34 colonnes de CLBs, chacune comprenant 22 frames. A l'aide de la table 3, on
peut refaire le calcul de ce nombre total de frames dans un Virtex-II Pro XVP7
comme suit :
Nbre_Frames_XVP7 = 2x4 IOB_frames + 2x22 IOI_frames + 34x22
CLB_frame
+ 6x64 BRAM_frames + 6x22 BRAMi_frames + 1x4 GCLK_frames =
1320 frames.
Reconfigurer partiellement un FPGA comme le Virtex-II Pro de
Xilinx [24] consiste en la reconfiguration d'une ou plusieurs colonnes (plus
précisement des Frames) de la mémoire de configuration.
L'alignement en colonne des frames (et donc des ressources) sur la surface
physique du FPGA explique le fait que, dans la reconfiguration partielle, on
attribue exclusivement à un module les I/Os en contact avec la zone du
FPGA attribuée au module. En effet, un module situé à
l'extrémité gauche du FPGA engloberait forcément la
première colonne d'entrées/sorties IOBs (figure 16) et serait
ainsi le seul pouvant utiliser les entrées/sorties du côté
gauche du FPGA.
1 Il est à noter qu'il existe plusieurs technologies
de fabrication des FPGAs, et elles se distinguent généralement
par le type de mémoire de configuration utilisé (SRAM, fuse et
anti-fuse, etc...).
2 La société Atmel propose aussi des FPGAs
à reconfiguration partielle, les AT40K, utilisant un système de
mémoire cache de contextes de configuration très
intéressant pour des applications de notre type.
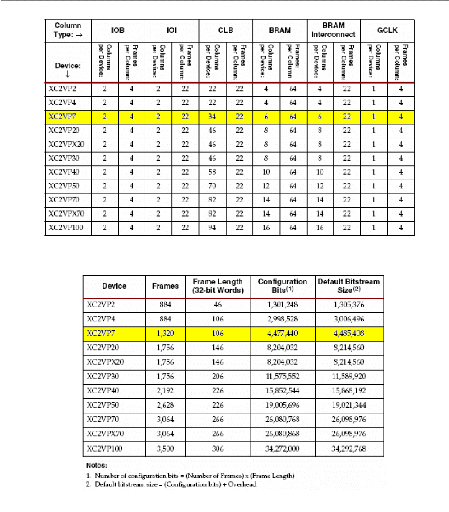
Table 3 :Répartition des ressources en frames dans les
FPGAs Virtex-II Pro
Table 4 : Taille des données de configuration dans la
série Virtex-II pro
La Figure 15 montre le format d'une adresse de Frame
et la Figure 16 montre le principe d'adressage des Frames. Par
exemple, toutes les adresses ou le mot binaire BA1 = 00 adressent
les colonnes de Frames configurant les GCLK, les IOB, les IOI et toutes les
colonnes
1 Chaque frame de configuration a une adresse unique sur 32
bits composee des champs BA (Block Address), MJA (Major Address) et MNA (Minor
Address) et un octet. Comme indique a la figure 16. BA indexe le bloc de
ressources a configurer (par exemple les blocs BRAM), MJA identifie la colonne
dans le bloc, MNA identifie la frame et l'octet sert de compteur de mots par
frame. Un mot dans une frame ne pourrait etre adresse, voir [Xilinx 06] page
339 pour details.
de CLB alors que pour BA = 01 (resp. 10 ou 2 en decimal) on
adresse les colonnes frames configurant les colonnes BRAM (resp. colonnes de
BRAM INTerconnection). La valeur des bits MJA et MNA permet d'adresser une
frame précise.
Dans un design modulaire, la largeur minimale admissible d'un
module est de 4 Slices (plus précisément 4 colonnes de Slices
correspondant à 2 colonnes de CLBs, car la hauteur d'un module est
toujours égale à celle du FPGA). Reconfigurer partiellement un
module revient à reconfigurer toutes les frames de ses ressources.

Figure 15 : Format d'adresse d'une Frame
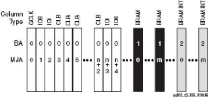
Figure 16 : Adressage de la mémoire de
configuration
c) Les modes de reconfiguration
La configuration des FPGAs Xilinx peut être
effectuée de l'extérieur (à partir d'un PC par exemple, ou
d'un microcontroleur) selon les modes suivants :
- Serial (Programmation série).
- JTAG / Boundary-Scan (Programmation via la sonde JTAG). -
SelectMap1 (Programmation parallèle).
Et de l'intérieur par:
- Le port ICAP qui est une interface permettant
d'accéder à la mémoire de configuration du FPGA. Cette
interface est celle que nous avons utilisée pour la reconfiguration
partielle du FPGA par le processeur PPC 405 intégré, mais avant,
le FPGA doit avoir été configuré totalement par l'un des
modes de reconfiguration extérieur cité ci-dessus.
1 SelectMap est une interface de configuration du FPGA depuis
l'exterieur. Il permet d'accéder en lecture/écriture à la
mémoire de configuration du FPGA suivant plusieurs modes. Pour les
détails, voir [Xilinx 06] en page 306.
d) Le port de configuration interne
ICAP
Le port ICAP (Figure 17) est un sous-ensemble de l'interface
SelectMap. Il est physiquement présent sur le FPGA en bas a
l'extrême droite de la puce. Il utilise le même protocole que
SelectMap en mode esclave. Il est capital dans la mise en oeuvre de
l'autoreconfiguration. En effet, il sert d'interface d'accès interne
à toute la mémoire de configuration du FPGA et permet ainsi au
processeur intégré de le reconfigurer partiellement. Dans [24] en
page 317 sont précisées les précautions à prendre
vis-a-vis des autres modes de configuration lors de l'utilisation du port
ICAP.
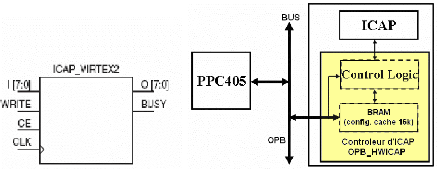
Figure 17 : Port ICAP Figure 18: Architecture materielle
pour
la reconfiguration via le port ICAP
Pour faciliter l'utilisation de l'ICAP, Xilinx fournit sous
forme d' IP1 un Controleur d'ICAP2 (Figure
178) dont les détails peuvent être trouvés dans [25].
Le contrôleur est instancié comme périphérique du
processeur PPC405 et implemente sous EDK à l'aide des ressources du
FPGA. Il est connecté au bus OPB (On chip Peripheral Bus). Il utilise
une BRAM de 16 Ko (suffisant pour contenir les données de configuration
d'une Frame) qui sert de mémoire de cache aux données de
configuration en provenance du bus pour le port ICAP (reconfiguration) ou vice
versa (Readback) . La BRAM double port est connecté d'un coté au
contrôleur d'ICAP et de l'autre au bus OPB.
Xilinx fournit également pour le contrôleur une
couche logicielle (pilotes) sous forme de fonctions légères
écrites en C (Error! Reference source not found.) et
évitant d'avoir à gérer la communication entre le bus et
l' ICAP. Par exemple l'écriture en mémoire de configuration du
FPGA se fait en 2 temps (voir table 5):
1 Intellectual Property
2 Sur la figure 17, opb_hwicap est le nom d'instance
choisi pour le contrôleur d'ICAP lors de son implémentation sous
EDK comme périphérique du processeur. De même on le
connecte à un bus (OPB) et on lui attribue une adresse d'implantation
dans l'espace d'adressage du bus.
- La fonction storageBufferWrite( ) permet au
processeur d'écrire un certain nombre de trames binaires (512 mots de 32
bits au maximum pour les 16Ko de BRAM) en BRAM de cache.
- La fonction deviceWriteFrame( ) permet ensuite au
contrôleur de transférer ces trames précédemment
écrites en BRAM vers le port ICAP qui les interprètent pour
configurer le FPGA frame par frame. Ces trames proviennent des bitstreams de
configuration partielle du FPGA et contiennent toutes les informations
nécessaires à l'adressage et à la configuration d'une ou
plusieurs frames.
Les fonctions storageBufferRead( ) et
deviceReadFrame( ) jouent respectivement le même rôle que
les deux précédentes mais plûtot dans le sens ICAP -
Processeur PPC405 et servent donc à lire le contenu des frames du FPGA
(Readback).
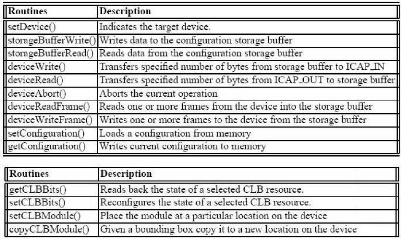
Table 5 : Fonctions permettant de lire et écrire en
mémoire de configuration via le port ICAP
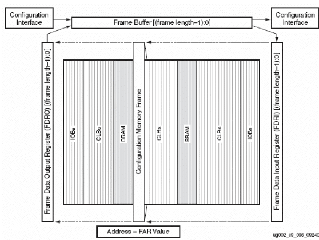
Figure 19 :L' Interface de configuration du Virtex-II Pro et
ses registres
e) Analyse des trames de
configuration1
1 Premieres et les dernieres lignes d'un fichier bitstream au
format ASCII (.rbt)

Comme expliqué plus haut, configurer le FPGA revient
à y envoyer à l'interface de configuration (Figure 19)
un fichier bitstream de configuration sous forme de trames qui comprennent les
données de contrôle de configuration et les données
à écrire dans les frames de configuration pour programmer les
ressources. On distingue globalement:
- Les trames d'écriture
- Les trames de lecture
- Les trames de synchronisation
- Etc...
[23] étudie en détails au chapitre 4 toutes ces
trames et les registres cités dans l'exemple cidessous.
Les premières et les dernières lignes (il peut
en avoir plusieurs milliers de lignes suivant la taille du module) d'un exemple
de fichier bitsteam au format RBT apparaît plus haut. Il permet de
reconfigurer un module du FPGA. Ce sont donc des trames d'écriture. Nous
l'avons généré dans le cadre de ce projet. La trame de
reconfiguration commence en ligne 8. On peut décrypter ces quelques
lignes de trames comme suit [23] :
- Les 7 premières lignes représentent
l'entête du fichier RBT ; elles renferment quelques renseignements.
- 0xff, 0xff, 0xff, 0xff : Mot inutile (ligne 8).
- 0xaa, 0x99, 0x55, 0x66 : Mot de synchronisation. Demande au
FPGA de commencer à analyser les mots suivants.
- 0x30, 0x00, 0x80, 0x01 : Mot d'entête ; annonce une
écriture de 1 mot dans le registre de commandes.
- 0x00, 0x00, 0x00, 0x07 : Remise à zéro du
registre du CRC.
- 0x30, 0x01, 0xc0, 0x01 : Mot d'entête. Annonce
l'écriture du code d'identification du FPGA (registre IDCODE).
- 0x01, 0x24, 0xa0, 0x93 : Code d'identification du FPGA
- 0x30, 0x00, 0x80, 0x01 : Mot d'entête. Annonce une
écriture de 1 mot dans le registre de commande (registre CMD).
|
- 0x00,
|
0x00,
|
0x00,
|
0x01 : Initialise l'écriture des données de
configuration
|
|
- 0x30,
|
0x00,
|
0x20,
|
0x01 : Mot d'entête. Annonce l'écriture de
l'adresse de la colonne
|
élémentaire.
- 0x00, 0x48, 0x0c, 0x00 : Adresse de l'unité
élémentaire à reconfigurer (voir figure 15 et figure
16).
- 0x30, 0x00, 0x40, 0xd4 : Mot d'entête. Annonce
l'écriture de 212 mots de 16 bits de configuration. Nous indiquons ici
la taille de l'unité élémentaire spécifique
à chaque FPGA.
- En fin de fichier on a toujours la même séquence
de trames, et le mot de fin est 0x00, 0x00, 0x00, 0x0D.
3. METHODOLOGIE DE MISE EN OEUVRE DE L'AUTO
RECONFIGURATION PARTIELLE ET DYNAMIQUE SUR LE VIRTEX-II PRO
Ce chapitre se focalise sur la mise en oeuvre sur FPGAs Xilinx
Virtex-II Pro d'un système auto-reconfigurable partiellement et
dynamiquement à l'aide d'outils de conception électronique.
L'auto-reconfiguration vient de ce que le processeur immergé dans la
puce FPGA reconfigure partiellement celle-ci.
Pour la reconfiguration partielle, Xilinx propose dans [20] deux
méthodes:
· Le Small Bit Manipulation à l'aide l'outil
JBits1
· Le Modular Design Flow
Le Small Bit Manipulation permet de modifier
rapidement un ou plusieurs détails dans un design, comme par exemple la
modification d'un CLBs, IOBs, LUT ou Block RAM. Il est à noter que les
outils comme JBITs fournissent une interface et des classes Java permettant de
manipuler (lire et modifier) individuellement les données de
configuration de chaque ressource du FPGA.
Le Modular Design Flow est une approche
modulaire qui permettrait dans le cadre de la reconfiguration partielle, de
reconfigurer un module entier, et non pas un détail dans le module. Dans
le cadre de ce stage, nous avons utilisé cette approche qui est par
ailleurs suggérée par Xilinx pour la reconfiguration
partielle.
3.1 Méthodologie de Conception
Pour la conception des designs pour FPGAs Xilinx, il existe
deux démarches principales, une démarche dite standard
(Ordinary Design Flow) et une démarche dite incrémentale
(Incremental Design Flow). Après une brève description
de la première démarche, nous nous focaliserons sur la seconde et
plus particulièrement sur le Modular Design Flow, une
méthode incrémentale suggérée par Xilinx pour la
mise en oeuvre d'applications partiellement
1 JBits est une API (Application Programmable Interface) java
fournie par Xilinx et contenant un jeu de classes permettant de manipuler
(lire/modifier/ecrire) individuellement toutes les ressources reconfigurables
du Virtex. JBits permet de modifier dynamiquement le bitstream du Virtex. Par
exemple, il peut permettre d'extraire un bitstream partiel du bitstream total
d'un design fait suivant le modular design flow. Nous n'avons pas utilise JBits
dans le cadre de ce travail (auto-reconfiguration) car il n'est pas souhaitable
que le processeur PPC405 embarque puisse supporter JVM(Java Virtual
Machine).
reconfigurables et supportée par ses familles de FPGAs les
plus récentes (Spartan et Virtex). Ces méthodologies de
conception
permettent de dérouler tout le processus de la
description du design à la génération des fichiers de
configuration ; elles sont mises en oeuvre dans des environnements
(ISE1 et EDK2) intégrant plusieurs outils Xilinx
que nous décrirons plus loin.
3.1.1 Flot de conception standard (Ordinary Design
Flow)
Dans le flot de conception standard, tout le design est
décrit dans un langage de description de circuit (Vhdl, Verilog) comme
un tout unique, puis synthétisé, simulé, placé et
routé. Les étapes minimales du flot de conception d'un design
sont figure 20 ci-dessous :
1. La description du design soit dans un langage de description
(Vhdl, verilog, SystemC), soit grâce à un outil de saisie
graphique qui génère le code Vhdl correspondant.
2. La simulation en vue de vérifier le bon
comportement.
3. La synthèse
4. Le placement et routage pour un FPGA précis.
5. La génération du fichier binaire de
configuration (bitstream) qui sera chargé sur le FPGA cible.
En cas de modification d'une partie du design, les
étapes ci-dessus sont entièrement refaites pour tout le design,
ce qui rend le processus très long. De même, cette méthode
ne facilite pas le découpage modulaire du design en vue d'une
répartition des tâches entre les membres d'une équipe,
contrairement au Modular Design Flow.
Le flot standard est supporté par l'outil
intégré ISE qui déroule automatiquement tout le processus;
il en résulte un fichier binaire unique (.bit) contenant les
données de configuration totale du FPGA.
Dans le cas de la conception d'un SOC, l'outil
intégré EDK permet de développer l'application
destinée au processeur intégré (de l'écriture du
code à la génération de l'exécutable), de
générer tous ses supports de communication (bus, uart, jtag,
Ethernet...), et de produire un
1 ISE : Integrated Software Evironment, environnement de
developpement integré de Xilinx, permettant de dérouler
automatiquement le flot de conception pour les FPGAs Xilinx de la saisie du
schema (ou l'ecriture en vhdl) a la génération du bistream de
programmation du FPGA.
2 Embedded Development Kit, environnement de developpement du
sous-système à processeur et périphériques
associés pour FPGAs Xilinx.
fichier binaire unique comprenant les données de
configuration totale du FPGA et l'exécutable pour le processeur du
SOC.
Mais ce flot standard ne permet que la configuration totale du
FPGA, et ne peut donc être utilisé dans le cadre de la
reconfiguration partielle des FPGAs Xilinx.
|
Figure 20 : Flot de conception Standard pour les
FPGAs
|
|
3.1.2 Le Flot de conception incrémental
(Incremental Design Flow)
Contrairement à un flot de conception standard, un Flot
incrémental permet de découper le design en modules
séparément synthétisables. L'intérêt de cette
méthode est la possibilité de valider des modules du design bloc
par bloc. De même les modules conçus pour des designs
antérieurs peuvent facilement être réutilisés dans
de nouveaux designs sans plus être revalidés.
Les phases de Synthèse-Placement-Routage ne sont
ré-exécutées que sur les modules ayant été
modifiés, ce qui sollicite moins de puissance et de temps à
l'ordinateur hôte.
a) La synthèse
incrémentale (Figure 21)
Au lieu de synthétiser le design complet (Top, Figure
21), chaque module (Module 1,2,3 Figure 21) est
synthétisé séparément et son fichier netlist
généré (nom_entite.ngc).
Les modules sont déclarés comme des composants
dans le Top, puis instanciés et interconnectés (top.vhd,
annexe 4.1). Le niveau Top du design contient toute la logique globale, les
Entrées/Sorties (IOBs), les signaux, et les interconnexions
inter-modules. Tous ces éléments y sont déclarés et
instanciés. Les fichiers netlists résultant de la synthèse
séparée des modules sont alors prêts à être
insérés au niveau Top du design lors de la
synthèse de Top. En effet, lors
de la synthèse du Top, un module ne sera
resynthétisé que s'il a été modifié.
L'intérêt de la conception incrémentale est justement cette
validation modulaire qui apporte un gain de temps.
Sous ISE par exemple avec l'outil de synthèse XST, les
modules du design Top doivent être déclarés dans son
fichier vhdl du top comme des composants ayant l'attribut « Black box
». Cet attribut indique à l'outil de synthèse de ne pas
faire la synthèse du module lors de la synthèse du Top.
b) Le Placement et Routage (P&R)
Incrémental
Le principe est identique à celui de la synthèse
incrémentale. Ainsi, après modification d'un bloc un nouveau
P&R n'affecterait pas le P&R de la partie inchangée du
design.
3.1.3 Le Modular Design Flow pour la reconfiguration
partielle
a) Présentation [22]
Il s'agit d'une méthode de conception
incrémentale. A l'origine il permet à une équipe
d'ingénieurs de travailler indépendamment sur des modules d'un
design en vue d'une fusion postérieure et une implémentation sur
un FPGA unique. Comme décrit au paragraphe précédent, un
grand design est découpé en plusieurs modules en vue d'un travail
en équipe. Chaque concepteur de l`équipe implémente et
teste le(s) module(s) à sa charge séparément, et le chef
d'équipe définit la structure globale du design et intègre
les modules implémentés au niveau Top-Level du design
qui comprend (Figure 21) :
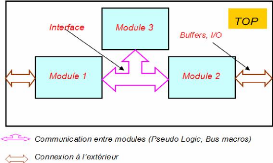
Figure 21 : Vue au niveau TOP d'un design modulaire
- Un ensemble de modules indépendants (mais synchrones et
pouvant communiquer par des interfaces appelés Bus macros).
- L'interface entre les modules (Bus macros).
- L'interface avec les pins (les E/S du design sont
déclarées au niveau Top).
Un fichier de contrainte (.ucf chez Xilinx) permet de
fixer les contraintes d'espace (pour les pins du FPGA à utiliser et la
position de chaque module sur le FPGA) et de temps (fréquence maximale
de fonctionnement). Chez Xilinx, ce fichier peut être soit écrit
soi-même, soit généré automatiquement par l'outil
Floorplaner, l'éditeur graphique de contraintes d'espace pour
les FPGAs Xilinx.
b) Modular Design Flow pour la reconfiguration
partielle
Le Modular Design flow par son approche modulaire est
particulièrement adapté à la conception d'applications
partiellement reconfigurables comme la nôtre ou un module entier
doit être reconfiguré. Mais le modular design flow pour la
reconfiguration partielle suggère pour des raisons pratiques que
toute conception doit avoir au niveau top deux parties homogènes
(à ne pas confondre avec les modules dont le nombre maximal est en
théorie égale au quart du nombre de colonnes de Slices) : une
partie fixe et une partie reconfigurable.
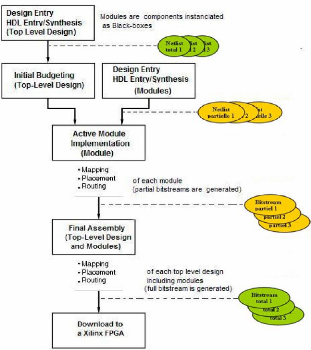
Figure 22 : Le flot Modular Design pour la reconfiguration
partielle Il se déroule en 4 étapes (Figure 22)
:
1. La Synthèse des modules et du design au niveau
top (Top-level Design).
2. L'Initial Budgeting qui détermine
approximativement la taille de chaque module à implémenter puis
lui attribue une zone sur le FPGA conformément aux contraintes de
placement et de temps.
3. L'Active Module Implémentation ; les
modules sont implémentés individuellement et dans des
répertoires séparés, et les bitstreams partiels sont
générés dans le cas de la reconfiguration partielle.
4. Le Final Assembly qui implémente le design
entier en assemblant tous les modules, puis génère son bitstream
complet qui permet de configurer le FPGA.
Nous décrirons en détail les étapes du
Modular Design dans un cas d'étude effectué plus loin.
3.2 Principe de l'Auto-Reconfiguration partielle et
dynamique
3.2.1 De la reconfiguration partielle
Sur la Figure 23 , le design Top1 est
constitué de 3 modules (Module 1, Module 2 et Module 3). Reconfigurer
partiellement ce design revient à le faire passer de Top1
à un nouveau design Top2 (resp. Top3) par remplacement du
Module 3 par le Module 3' (resp. Module 3'') conçu à
dessein pour occuper le même espace physique sur le FPGA et utiliser les
mêmes entrées/sorties. L'exemple de la figure 13 , ou le module
« Control » est remplacé par le module «
Video out » par reconfiguration partielle du FPGA l'illustre bien.
|
Figure 23 : Passage d'un Top à un autre par
reconfiguration partielle (remplacement du module 3).
|
|
Ainsi, soit un FPGA pouvant contenir i modules sur
des emplacements Ei de sa surface. Soit j le nombre de
designs pouvant occuper le même emplacement Ei. En supposant que
tous les modules soient reconfigurables (ce qui n'est pas possible dans le cas
de l'autoreconfiguration car le module chargé de reconfigurer
partiellement doit être fixe pour assurer l'intégrité du
circuit entre deux configurations), on peut facilement déduire qu'on a
i x j scénarii possibles de fonctionnement. Dans le cas de la
figure 23, les modules 1 et 2 sont fixes et le
module 3 reconfigurable : il ya donc 3 scenarii possibles
(Top1, Top2, Top3) pour 3 designs différents du module 3
(Module 3, Modules 3' et Module 3»).
3.2.2 De l'auto-reconfiguration dynamique
Nous entendons ici par Auto-reconfiguration le fait
que le processeur PPC405 integré au FPGA puisse partiellement
reconfigurer celui-ci. En effet, on peut également dire que le FPGA
s'auto-reconfigure partiellement. C'est effectivement le cas si on utilise un
FPGA avec un processeur soft core (Microblaze par exemple). Ayant
adopté une conception modulaire, il est également clair que le
module contenant le processeur et ses périphériques et
chargé de la reconfiguration partielle est fixe (non-reconfigurable).
La reconfiguration dynamique suppose que la
reconfiguration d'un bloc ou d'un module n'altère pas le fonctionnement
du reste de la puce. L'auto-reconfiguration est donc
intrinsèquement une reconfiguration dynamique.
3.3 Exemple de mise en oeuvre d'une application
auto-reconfigurable à l'aide
de ISE et EDK
3.3.0 Introduction
Nous allons détailler les étapes de la mise en
oeuvre de l'auto-reconfiguration à travers une étude de cas. La
Figure 24 présente le schéma de principe de ce
système à deux modules, l'un fixe et l'autre reconfigurable. Les
bitstreams de reconfiguration du module reconfigurable peuvent être
chargés dans une mémoire de type SRAM ou Flash. Le FPGA
utilisé est le VirtexII Pro XVP7 que nous avons présenté
plus haut.
Une fois le FPGA configuré, une application
développée par nous (srp.c) permet au processeur PPC
intégré :
- De charger (via une connexion UART-HyperTerminal a un PC) des
bitstreams partiels
du module reconfigurable et de les stocker en mémoire SRAM
(externe à la puce).
- De reconfigurer dynamiquement et à la demande le module
reconfigurable.
- L'environnement EDK (Embedded Development Kit) de
Xilinx a permis de bâtir
séparément le module fixe (système
à microprocesseur), de développer l'application pour le
processeur et de générer l'exécutable (environnement de
cross-compilation et de debuggage). Xilinx EDK est un ensemble d'outils
softwares pour la conception des systèmes à processeur
embarqué sur des circuits FPGAs Xilinx. A travers son environnement
graphique XPS (Xilinx Platform Studio), EDK facilite la création de
l'architecture matérielle du système a microprocesseur
(processeur et périphériques de communication, Figure
25) et fournit le
support logiciel (generation des pilotes, cross-compilation,
debuggage) permettant le developpement des applications pour le processeur
integre.
- L'environnement ISE (Integrated System Environment) a
permis d'integrer les deux
modules de la Figure 24 dans un design unique
(top.vhd) et de faire la synthèse. En effet, une fois que le
système à processeur est teste et valide sous EDK, il est
exporte vers ISE comme un sous-module reconfigurable afin de construire le
design global de la Figure 24. Après la synthèse du
design global sous ISE, le reste du flot de conception modulaire pour la
reconfiguration partielle (Figure 22) sera deroule par ecriture de
scripts appropries, ce flot n'etant pas automatise sous ISE.
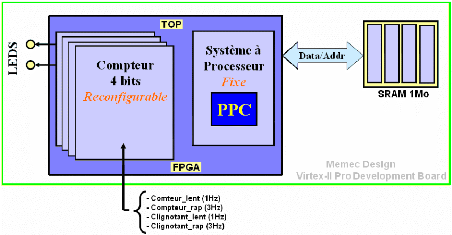
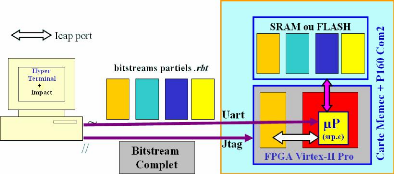
Figure 24 : Etude de cas de l'auto-reconfiguration
3.3.1 La plateforme matérielle de
développement, la carte Virtex-II Pro de Memec Design
Cette carte developpee par Memec Design comprend essentiellement
(Figure 25): - Un FPGA Virtex II Pro XVP7 ou XVP4
- Une SDRAM 32 Mo que nous n'avons pu utiliser comme memoire de
stockage des
configurations parce qu'elle n'est pas situee du côte du
FPGA où se trouve le module « Système à Processeur
».
- Deux horloges (100MHz et 125 MHz)
- Un ecran d'affichage LCD
- 4 LEDs
- 4 Boutons poussoirs
- 8 DIP switches
- Un port Série RS232 (physiquement connecté au
FPGA par ses pins du côté gauche,
et donc inutilisable par le module « Système à
Processeur » implémenté sur le côté droit de la
puce).
- Un port Jtag
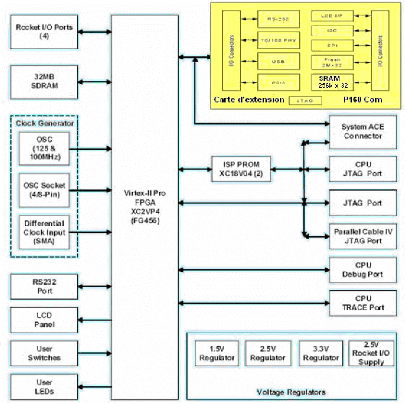
Figure 25 : Vue schématique de la carte de
développement Virtex-II ProTM de Memec Design - Une
carte d'extension P160 Com (Figure 25, en gris).
Cette carte d'extension P160 Com comprend des ressources
additionnelles connectées physiquement aux pins du côté
droit du FPGA sur la carte et donc utilisables par le module «
Système à Processeur » ; ces ressources sont:
- Une mémoire Flash de 8 Mo
- Une mémoire SRAM de 1 Mo (que nous avons
utilisée comme mémoire de stockage
des configurations).
- Un port Ethernet 10/100
- Un port Usb
- Un port série RS232 supplémentaire
- Un port PS/2
- Un écran d'affichage LCD supplémentaire.
[29] est le document de référence de cette
carte.
Mais la limite essentielle de la carte vient de ce qu'elle ne
soit pas adaptée à la reconfiguration partielle. La distribution
des périphériques autour du FPGA ne facilite pas le respect des
contraintes de conception d'applications partiellement reconfigurables. En
effet, comme nous l'avons souligné plus haut, dans ce type
d'application, un module implementé sur le FPGA ne peut utiliser que les
entrées/sorties se trouvant sur la surface qui lui a été
attribuée sur la puce.
3.3.2 Conception sous EDK du module « Système
à processeur »
[26] est un tutorial de référence pour cette
conception. Il s'appuie sur un exemple simple permettant de tester
l'Uart. Quelques autres exemples existent sur le site de Xilinx.
a) Architecture du système
Les différents blocs de cette figure sont disponibles
soit sous forme d'IPs prêts à être implementés
à l'aide des ressources logiques du FPGA, soit directement
présents en blocs ASICs sur la puce FPGA (PPC405, ICAP, JTAG). Les
composantes essentielles de ce système sont :
- Le Processeur PPC405
- Le bus PLB (Processor Local Bus) auquel est directement
relié le processeur ; il est plus
rapide.
- Le contrôleur de BRAM (PLB_Bram_if_ctrl) qui permet
d'associer une BRAM au bus
PLB ; cette BRAM servira de mémoire de données
et/ou de programme au processeur.
- Le bus OPB (On-chip Peripheral Bus) permettant de connecter
les autres périphériques
plus éloignés du processeur.
- Le pont PLB-OPB (Plb2Opb_Bridge) reliant les deux bus.
- Le bloc OPB_GPIO permettant de gérer les
entrées/sorties utilisateurs (LEDs, Switch,
ecran LCD) suivant la plateforme de développement
choisie.
- Le bloc OPB_UARTLite implémentant une interface
série UART allégée qui nous
permettra de faire communiquer le système à
processeur embarqué avec un ordinateur PC via l'application
Hyperterminal sous Windows. Côté PC,
l'HyperTerminal nous permettra d'interagir avec le système
embarqué (à travers le clavier et le terminal
émulés) et d'envoyer les fichiers de configuration au
système à processeur via le port série du PC. Pour cela
nous écrirons côté Processeur PPC405 le programme
permettant ce genre d'échanges de données avec
l'HyperTerminal1.
- Le bloc OPB_HWICAP qui est le contrôleur permettant
d'utiliser le port ICAP.
- Le bloc OPB_EMC qui est le contrôleur de mémoire
extérieur (Flash ou SRAM) ; dans
notre cas, nous avons utilisé une SRAM de 1 Mo externe
à la puce et se trouvant sur la carte de développement
utilisée.
- Le bloc PLB_ETHERNET qui implémente une interface
réseau ; nous n'avons pas
implémenté ce bloc dans le design final car nous
n'en avions pas besoin dans l'immédiat.
b) Création de la plateforme matérielle
du système sous Xilinx EDK
A travers son interface graphique XPS, EDK permet de rajouter
de façon interactive au processeur les blocs présentés
figure 26, et d'unifier tout cet ensemble dans un design unique au niveau top
(qu'il appelle par défaut system.vhd).
Les étapes essentielles sont les suivantes [26] :
- Démarrer XPS (Start ? Programs ? Xilinx Platform
Studio 7.1i ? Xilinx Platform Studio).
- Créer un projet a l'aide "Base System Builder"
XPS (File ? Project ? Base System Builder).
- Choisir un répertoire de travail (par exemple
SELF_RECONF_PLATFORM de la Figure 27, sans espace sur le chemin).
- Choisir la carte de développement ciblée
(dans notre cas c'est la carte Virtex-II Pro P4 FG456 Development
Board de Memec Design).
- Configurer le processeur PPC (on peut laisser les
fréquences par défaut proposées par BSB et choisir 100 Mhz
comme fréquence du bus).
- Choisir les périphériques à utiliser sur
la carte (LEDs, Switches, RS232 Uart, Boutons poussoirs).
1 HyperTerminal est un programme qui permet de se
connecter à d'autres ordinateurs, à des sites Telnet, aux forums
électroniques (BBS), aux services en ligne et aux ordinateurs
hôtes, à l'aide d'un modem, d'un câble null-modem ou d'une
connexion TCP/IP (Winsock).
- Rajouter les périphériques du processeur sur
les bus appropriés suivant le schéma de la Figure 27 (ne
pas oublier de rajouter de la mémoire interne BRAM de 16 ou 32 Ko et de
la mémoire externe SRAM ou Flash de 1 Mo, pour l'instant le bloc
PLB_Ethernet peut ne pas être ajouté).
- Générer la plateforme matérielle.
A l'issue de cette génération interactive de la
plateforme matérielle, XPS aurait ainsi créé dans le
répertoire SELF_RECONF_PLATFORM le fichier projet
system.xmp , les fichiers (.mhs et .mss) décrivant
l'architecture du système et quelques autres répertoires de la
Figure 27(a).
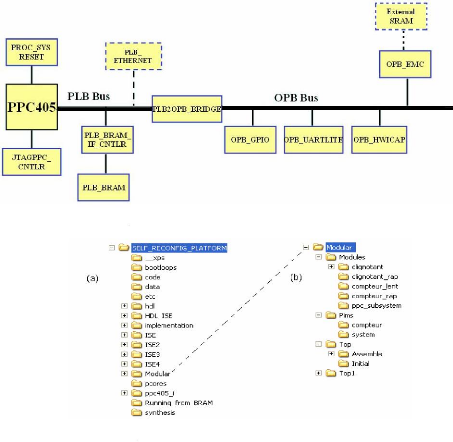
Figure 26 : Architecture du système a
processeur.
Figure 27 : Structure des répertoires du
Projet
Les adresses d'implantations sont attribuées
automatiquement aux différents périphériques dans l'espace
d'adressage du bus auquel ils sont connectés. Mais la plateforme
matérielle (les adresses, les paramètres des blocs IP,
l'Ajout/Suppression de blocs IP, etc...) peut être modifiée
ultérieurement de façon interactive (Project - Add/Edit
Cores....).
c) Création de la plateforme logicielle
Ceci se déroule en deux étapes :
- Génération des pilotes pour les blocs de la
plateforme matérielle ainsi que des librairies
avec la commande Project - Software Platform Setting.
Les fenêtres apparaissant permettent de choisir les versions des
drivers du processeur et des périphériques (laisser les valeurs
par défaut) , les librairies Xilinx à utiliser ( par exemple
cocher Xilnet si on utilise le bloc Ethernet...), le
compilateur à utiliser ( powerpc-eabi-gcc est le compilateur
par défaut), les entrées/sorties standard du processeur
(Stdin/Stdout, ici ce sera l'Uart). Ensuite les librairies
peuvent être générées ( Tools - Generate
Libraries and BSPs).
- Développement des applications pour le processeur
embarqué. Sur la fenêtre System en
haut à gauche sous XPS permettant de voir
l'architecture de la plateforme générée, on peut cliquer
sur Applications pour voir les applications destinées au
processeur. Cette fenêtre permet de créer de nouveaux projets pour
le processeur, d'ajouter les programmes à éxecuter, et d'indiquer
au processeur la mémoire de boot (Bram ou Sram), etc... A ce stade,
Xilinx fournit des programmes simples (hello word, xil_printf,...)
permettant de tester la plateforme en utilisant le clavier et l'ecran d'un PC
comme des entrées/sorties standards du processeur via l'Uart et
l'HyperTerminal.
d) Gestion de la mémoire et
génération du linker script
Notre architecture comprend une mémoire (BRAM) interne
au FPGA et connectée au bus PLB et une mémoire externe SRAM (SRAM
de 1 Mo se trouvant sur la carte d'extension P160 Comm) connectée au bus
OPB. A cause de leur petite taille et de leur distribution sur la puce (il
serait très coûteux en ressources FPGAs de les associer et de les
connecter au bus PLB), les BRAM ne sont pas appropriées comme
mémoire de stockage des bitstreams de configuration. Ces
dernières peuvent etre stockés en SRAM externe.
Le processeur démarre toujours par un programme initial
de boot en BRAM et peut ensuite être dérouté vers
un programme se trouvant en mémoire SRAM externe à l'aide de
XMD1.
Le Linker script est un fichier de script indiquant
les sections du code et les zones mémoires qui les contiendront. Il sert
lors de la compilation du code sous EDK. Lors de la génération
automatique du fichier Linker script, toutes les sections du code sont
automatiquement mises en mémoire BRAM par défaut. Dans notre
application, il est nécessaire de modifier ce fichier pour
1 Xilinx Microprocessor Debugger se
lance sous EDK par Tools - XMD ; il permet de charger en SRAM externe
l'executable .elf et de brancher le processeur sur ce code. En effet, lorsqu'on
fait Tools - Update Bitstream, un programme est chargé par défaut
dans la BRAM interne (Bootloop.c). C'est une boucle infinite 'exécut
é par le processeur. Pour que le processeur BOOT sur un programme il
faut aller a la fenetre «Application», cliquer droit sur le projet
Software concerne et choisir «Initialize BRAM». Le
envoyer certaines sections en mémoire SRAM
externe1 (comme la section .data par exemple car c'est
celle dans laquelle les bitstreams de configurations seront chargées) ;
en effet la BRAM n'est pas assez capacitive pour contenir les fichiers
bitstreams des modules.
e) Implémentation du systeme à
processeur
On peut à présent générer le
fichier bitstreams correspondant à la plateforme matérielle
générée plus haut, afin de configurer le FPGA. Pour cela
il faut choisir ajouter au projet un fichier de contraintes (.ucf)
spécifiant les connexions des les options de projet. A ce stade,
deux cas se présentent :
(i) Déroulement de tout le flot sous EDK afin
de tester et valider le module.
Project - Options - Hierarchy and flow (This is the toplevel
of my design) - Synthesis Tool (ISE XST ) - Implementation tool flow
(XPS_Xflow) - Ok
Tools - Clean , Tools - Generate libraries
Tools - Built user application : génère
l'exécutable destiné au processeur.
Tools - Generate netlist : fait la synthèse de la
plateforne matérielle (fichiers .ngc).
Tools - Generate bitstream : génère le
fichier system.bit permettant de configurer le FPGA et d'y
implémenter la plateforme matérielle de la Figure 26.
Tools - Update bitstream : associe
l'exécutable (.elf) destiné au processeur au fichier
system.bit de configuration du FPGA et génère en fichier
unique download.bit téléchargeable dans le FPGA. Cette
commande lancée toute seule déroule automatiquement les
étapes précédentes de la génération des
librairies à la génération du fichier
download.bit.
A ce niveau, l'outil Impact permet de configurer le
FPGA avec le fichier download.bit. A la fin de la configuration du
FPGA, le processeur exécute le programme chargé en
mémoire. On peut alors vérifier et valider les plateformes
matérielles et logicielles du système.
Remarque: Il peut arriver que le lancement du programmateur de
FPGA depuis XPS échoue ; dans ce cas démarrer l'outil
Impact...
Démarrer-9 Programmes - Xilinx ISE 7.1i -9Accessoires
Æ Impact
...ensuite choisir le mode de programmation (Boundary
Scan par exemple), puis joindre le fichier download.bit et
programmer le FPGA.
programme choisi pour initialiser la BRAM est celui dont
l'exécutable ( .elf) servira a générer le fichier
download.bit.
1 Pour envoyer certaines sections du
code en mémoire SRAM, on peut le faire graphiquement (voir [Xilinx 08])
ou manuellement en éditant le fichier Linker_script et en redirigeant
les sections du type data (.data, .sdata), .sbss, et .text vers la SRAM. Bien
entendu les sections de boot voire la pile (stack) peuvent rester en BRAM pour
accélerer l'exécution.
Le déroulement entier du flot sous EDK
génère les répertoires suivants (Figure
27.a) :
- Le répertoire hdl qui contient les fichiers
vhdl du module system et de ses composantes (IPs). Ces
fichiers sont générés automatiquement à la
génération de la plateforme matérielle sous EDK.
- Le répertoire « Synthesis » qui
contient tous les fichiers de synthèse générés lors
de la génération de la Netlist sous EDK (Tools - Generate
Netlist).
- Le répertoire « Implémentation »
crée par EDK pour stocker tous les fichiers de netlist
nécessaire à implémenter le module fixe
(system).
(ii) Exportation du système à
processeur vers ISE comme module fixe d'un design
global.
Apres avoir testé et validé le module dans un
flot totalement intégré sous EDK, on doit changer les options du
projet afin d'exporter ce module vers ISE comme module fixe du design
Top de la Figure 24 de la façon qui suit:
Project - Options - Hierarchy and flow (This is a submodule
of my design)
- Synthesis Tool (ISE XST ) - Implementation Tool flow
(XPS_Xflow) - Ok
Le processus est ensuite identique au cas (i) ci-dessus
jusqu'à la génération de la netlist (Tools - generate
netlist), suivi par l'exportation du module vers ISE par la commande :
Tools - Export to ProjNav. En effet, dans ce cas de figure, les
bitstreams ne sont pas générés sous EDK.
Remarque : L'exportation du module vers ISE crée
automatiquement un projet ISE s'il n'existe pas encore.
3.3.3 Conception sous ISE du design global «Top »
suivant le Modular Design Flow
A ce stade nous supposons que le module système
à processeur a été testé et validé sous EDK.
Nous rappelons que l'environnement intégré ISE ne permet que la
synthèse des designs dans tout le Modular Design Flow.
Après la création des fichiers sources vhdl et la synthèse
avec XST sous ISE, nous déroulerons les étapes suivantes du
Modular Design Flow par des scripts.
a) Création des codes sources
Les designs (compteurs et clignotants)
destinés au module reconfigurable de gauche peuvent être
écrits, synthétises, placés, routés, testés
et validés individuellement sur le FPGA dans un flot
intégré sous ISE suivant le flow standard Figure, et ce
dans des projets séparés. Ensuite leurs codes sources vhdl
(compteur_lent.vhd, compteur_rap.vhd, clignotant_lent.vhd,
cignotant_rap.vhd, voir annexe 4) sont
rajoutés, chacun a un projet de niveau Top. Chaque projet Top contient
donc le même module fixe (system) et un des designs du module
reconfigurable. Dans ces fichiers sources du module reconfigurable, les
entités doivent porter un nom unique (compteur) et les
mêmes interfaces (entrées/sorties).
Pour les codes vhdl du module fixe (system) et de ses
composantes (IPs), ils ont été
générés par EDK et se trouvent dans le répertoire
hdl du projet EDK. En outre, les fichiers netlists des sous-modules se
trouvent dans le répertoire Implementation du projet EDK et
sont automatiquement ajoutés au projet ISE vers lequel le module fixe
est exporté (sous ISE 6.1.i il faut les ajouter manuellement au projet
ISE).
Pour la création du code source top.vhd, les
étapes préliminaires sont :
- Créer un projet avec Project Navigator [27] de
ISE (ou ouvrir le projet exporté).
- Choisir comme répertoire de travail le même
où le module systeme à processeur (system) validé
a été exporté (répertoire ISE de la Figure
27(a) par exemple).
- Copier le fichier
hdl/system_sub.vhd vers le répertoire ISE de
travail, le renommer top.vhd et y changer le nom de l'entite
system_stub en top. En effet lors de l'exportation du module
system de EDK vers ISE, un fichier system_stub.vhd est
automatiquement généré dans le répertoire
hdl. Ce fichier est un modèle d'instantiation du module
system comme composant d'une entité nommée
system_stub.
- Ajouter au projet le fichier top.vhd.
- A ce niveau, il faut compléter le fichier
top.vhd en y ajoutant le module reconfigurable
(composant compteur) ainsi que ses interfaces (Buffers
I/Os, clk et signaux) de connexion en s'inspirant de l'insertion du module
system.
NB. Les buffers d'entrées/sorties doivent être
ajoutés manuellement dans le fichier top.vhd (voir Etapes de
synthèse ci-dessous).
Dans cette application, les deux modules sont synchrones et
fonctionnent à la même fréquence (voir la distribution
d'horloge aux modules dans le fichier top.vhd, annexe 4. 1).
b) Etape de synthèse des fichiers
sources
Nous avons réalisé la synthèse
incrémentale (voir modular design flow plus haut) des modules
et du Top sous ISE 7.2.i avec l'outil de synthèse XST.
Cette synthèse génère des fichiers de netlist du type
nom_entite.ngc, un pour chaque design du module reconfigurable et un
pour le top (les netlists du module system ayant été
déjà générés sous EDK et ajoutés au
projet ISE). Elle se déroule dans cet ordre :
(i) Synthèse de chaque module ; pour
éviter que XST les instancie dans les modules lors de la
synthèse, les buffers I/O sont désactivés (Synthesize
- Properties - I/O Disabled). En
effet, lors de l'ajout du module reconfigurable dans le
fichier top.vhd, les buffers d'Entrées/Sorties et de clock
doivent être inserrés manuellement comme des composants
(component IBUF/OBUF/IOBUF/BUFGP is...) au niveau top du design, sur
le modèle du fichier system_stub.vhd. La synthèse
génère dans chacun des répertoires les fichiers de netlist
system.ngc et compteur.ngc.
(ii) Synthèse du Top ; l'outil XST fait la
synthèse de la logique globale (connexions inter-modules par bus macros,
connexions entre les modules et les pins externes, etc...), charge
automatiquement les fichiers de netlist (.ngc) de tous les composants
déclarés et instanciés dans le top (modules et Buffers
I/Os et de clock), puis génère le fichier de synthèse du
design complet (top.ngc). Tous les composants déclarés
au niveau Top ont l'attribut « Black_Box » (voir top.vhd
annexe 4.1). Cet attribut indique à XST de ne pas refaire la
synthèse des modules concernés lors de la synthèse du Top,
et de charger directement leur netlist (.ngc).
Pour le Modular Design Flow, Xilinx suggère
une arborescence de répertoires facilitant la lisibilité du
projet [22], les fichiers générés étant très
nombreux et variés. Nous nous en sommes inspirés pour adopter
celle de la Figure 27. Ainsi on a les répertoires et les
projets suivants:
- Le répertoire « ISE » est le
principal répertoire contenant le projet ISE (top.ise) vers lequel
le module system a été exporté
depuis EDK. Il implémente le design Top constitué des modules
system (fixe) et compteur_lent (reconfigurable, avec pour nom
d'entité compteur) et contient les fichiers
générés à la synthèse sous ISE.
- Les répertoires ISE2, ISE3 et ISE4 qui
contiennent chacun une réplique du projet ISE
précédent (top.ise), mais plutôt avec
comme module reconfigurable un design différent (compteur_rap,
cignotant_lent, cignotant_rap) mais de noms d'entité
(compteur) et d'entrées/sorties identiques.
- Le répertoire « HDL_ISE » qui
contient tous les fichiers sources vhdl du top et des designs
(compteur_lent, compteur_rap, cignotant_lent, cignotant_rap)
du module reconfigurable.
- Le répertoire « Modular » dont chaque
sous-répertoire Figure 27.b renvoie à une étape
du
Modular Design Flow et permet de mieux comprendre les
phases d'implémentation des modules et de génération des
bitstreams partiels et total.
Remarque : On peut aussi procéder
autrement en créant un projet ISE unique, en y synthétisant tour
à tour le module fixe et chacun des designs du module reconfigurable, et
en sauvegardant chaque netlist compteur.ngc dans des
répertoires différents en vue d'une utilisation lors de la
phase active d'implémentation. En effet, le modular
design suggère la création de plusieurs projets pour
permettre simplement de générer séparément la
netlist de chaque design (sans Buffer I/Os) en vue de leur
implémentation individuelle, ce que le flot standard ne permet pas.
c) Etape d'Initial budgetting
Apres l'étape de synthèse, l'Initial budgetting
se réalise dans le répertoire
Top/Initial (Figure 27.b) et a pour but de
:
- Déterminer approximativement la taille de chaque
module.
- Attribuer une zone sur la cible pour chaque module à
implémenter.
- Contraindre les I/O du Top communicant avec l'extérieur,
et positionner les BUFG et
BUFGP.
- Positionner toute la logique du niveau Top, spécialement
les Bus macros (bus
d'interconnexion entre modules) qui sont positionnés sur
des TBUFs du FPGA.
En premier on exécute la commande «ngdbuild
-modular initial top.ngc » (voir initial.batch en annexe
4.5) qui prend en entrée la netlist du Top (top.ngc) et la
convertit en un format Xilinx top.ngd.
Ensuite on édite le fichier de contrainte (.ucf)
du projet (voir top.ucf annexe 4.3) . Les outils Constraints
Editor (pour les contraintes de temps) et Floorplanner (pour les
contraintes de placement et de dimensionnement des modules et composants)
permettent d'éditer automatiquement ce fichier. Mais pour la
reconfiguration partielle quelques contraintes spécifiques dont celles
ci-dessous doivent être insérrées manuellement dans le
fichier ucf :
(i) Déclaration du caractère reconfigurable
d'un module
AREA_GROUP "AG_nom_instance_module" MODE = RECONFIG;
Tous les modules sont en mode RECONFIG qu'ils soient
reconfigurables ou fixes.
(ii) Contrainte de placement des bus macros
INST "nom_instance_bus_macro" LOC = "TBUF_X56Y24" ;
[28] est le document de référence pour
l'édition des fichiers de contrainte.
Il est à noter que des broches du FPGA sont
physiquement connectés à des périphériques (SRAM,
LEDs, SDRAM 32Mo, Ethernet, RS-232, etc...Figure 25) présents
sur la carte de développement. La position et la dimension d'un module
sur le FPGA sont donc fortement dépendant du périphérique
auquel on souhaite le connecter. C'est ainsi que nous n'avons pas pu utiliser
la SDRAM 32 Mo présente sur la carte comme mémoire de stockage
des bitsreams, car elle est connectée au FPGA par les broches du
côté gauche, opposé au côté du système
à processeur. Dans tous les cas, éditer un fichier de contrainte
dans une application comme celle-ci se fait en grande partie manuellement, et
demande une bonne connaissance de la carte de développement
utilisée. Pour la carte Memec Design Virtex-II ProTM, nous
avons conjointement utilisé [24] et [29]. Il en a resulté le
fichier top.ucf en annexe 4.3.
d) Etape d'Active Module
Implémentation
Chaque design est implémenté
séparément dans un sous-répertoire d'implémentation
se trouvant chacun dans le répertoire Modules
(par exemple Modules/compteur_rap, Figure 27.b). Pour
implémenter chaque design, on utilise en entrée son fichier
<nom_entité_module.ngc> généré lors
de la synthèse ainsi que les fichiers .ucf et .ngc du
Top. Ces fichiers doivent donc être dans le
sous-répertoire d'implémentation courant du design. Pour le
module system, tous les fichiers .ngc de ses composantes
(fichiers xxx_wrapper.ngc, etc) doivent également être
recopiés dans son répertoire d'implémentation.
La phase active nécessite plusieurs commandes (voir
fichiers active.batch annexe 4.5):
- NGDBUILD lancée en mode actif pour chaque design dans
son sous-répertoire
d'implémentation et qui génère le fichier
.ngd du module.
ngdbuild -modular module -active <nom_entite_module>
-uc top.ucf top.ngc
- MAP et PAR qui font le Placement et Routage du module à
partir du fichier .ngd généré
plus haut.
map < nom_entite_module.ngd> par -w <
nom_entite_module.ncd>
- PIMCREATE qui crée un sous-répertoire par module
dans le répertoire PIMS
(Physically Implemented Modules, Figure 27.b) et y
publie tous les fichiers décrivant l'implémentation physique du
module ;
pimcreate -ncd « nom_entite_module.ncd »
..\..\Pims
Ces informations servent lors de l'assemblage final du Top
(Final Assembly). Tous les designs du module reconfigurable ayant des
I/Os identiques, il n'est pas nécessaire de lancer cette commande pour
chacun de ces designs, car elle publierait les mêmes informations.
- BITGEN permet de générer le bitstream partiel
(fichier .bit). L'option -g ActiveReconfig
permet la reconfiuration dynamique. L'option -d est
utilisée pour ne pas lancer DRC (Design Rule Check) lors du bitgen, et
l'option -b permet de générer la version ASCII du
fichier bitstream. Cette version est plus facile à manipuler et à
stocker dans la mémoire SRAM de la carte en vue de la reconfiguration
dynamique.
Remarque : Avant la phase active d'un module, son
fichier .ngc et celui de ses composantes (cas du module system
avec ses composantes xxx_wrapper.ngc, etc..) doivent être
recopié dans son sous-répertoire d'implémentation, ainsi
que les fichiers .ucf et . ngc du top.
e) Etape de Final Assembly (annexe
4.5)
Cette phase finale sert à assembler tous les modules
indépendamment implémentés dans un design Top
unique (voir fichiers assemble.batch annexe 4.5). Tous les modules
sont ainsi placés et routés dans un design Top unique,
puis le bitstream complet est généré. Les commandes
d'assemblage sont exécutées dans le répertoire
Top/Assemble (figure 27b) et utilisent les fichiers
publiés en phase précédente dans les
sous-répertoires du répertoire PIMS. Les commandes sont
identiques à celles utilisées en phase active pour
implémenter les modules (voir fichier assemble.batch en annexe
4.5), la commande Pimcreate en moins. La difference majeure vient des
options utilisées.
Lors du BITGEN on doit avoir l'option -g
startupclk:jtagclk pour s'assurer que le FPGA démarrera sur le
clock du Jtag après configuration. L'option -d n'est pas utilisée
en phase d'assemblage. L'option -b également (on n'a pas besoin de la
version ASCII du fichier bitstream). Le fichier bistream
généré permet de configurer le FPGA.
On peut souhaiter faire plusieurs assemblages afin de
générer plusieurs bitstreams complets (par exemple on peut
associer compteur_lent et system dans Assemble/Top, et
associer cignotant_lent et system dans Assemble/Top1).
Remarque :Pour reconfigurer partiellement le FPGA, il faut au
préalable l'avoir programmé avec un bitstream total.
f) Etape de
génération du bitstream final
Apres la phase d'assemblage (voir repertoire Top/Assemble), le
fichier bitstream (assemble.bit et/ou assemble.rbt) permettant de reconfigurer
les ressources logiques (CLBs, BRAMs, etc...) du FPGA est
généré. Mais pour notre application qui comporte en outre
une partie logicielle a exécuter sur le processeur embarqué, il
convient:
- de configurer les ressources logiques du FPGA (avec le fichier
bitstream de la phase
d'assemblage).
- de charger l'exécutable destiné au processeur
PPC405 en mémoire de programme
du processeur et d'initialiser ce dernier.
Ce dernier point nécessite :
- le fichier executable.elf produit suivant les phases
de développement décrites plus
haut (création de la plate-forme logicielle), et
- un fichier.bmm (system.bmm pour
l'entité system) indiquant les coordonnées
exactes des BRAMs (ressources FPGA) qui ont été
associées au processeur via le
bus PLB lors de la phase
d'implémentation active du module fixe (système
à
processeur) ; en effet c'est dans cette mémoire
que seront chargés le code de démarrage du processeur ainsi que
l'exécutable de notre application.
Le fichier .bmm est édité manuellement,
les outils ne permettant pas encore sa génération automatique.
Les coordonnées des BRAMs associés au processeur sont obtenus en
éditant avec l'outil FPGA Editor le design placé et
routé (phase d'implémentation active) du module «
système à processeur » et en répérant
lesdites coordonnées dans une des fenêtres indiquant le placement
des composants instanciés dans le FPGA. On peut aller plus vite en
complétant simplement le fichier system_stub.bmm se trouvant
dans le répertoire Implementation. L'annexe 2 détaille
avec un exemple visuel les étapes de création du fichier
.bmm.
En annexe 4.5 se trouve la ligne de commande permettant
d'associer un fichier .bmm nomme
system, un fichier
bitsream_complet.bit et un fichier
executable.elf pour générer un fichier
unique (chargement.bit) permettant de configurer totalement le FPGA et
démarrer le processeur.
3.4 Récapitulatifs
Nous avons implémenté et testé
l'auto-reconfiguration sur le virtex-II Pro. Le processus étant assez
touffu, la Figure 28 ci-dessus donne un rapide aperçu de la
démarche.
1. Sous EDK_XPS une plate-forme matérielle
(intégrant le processeur) est générée suivant un
flot standard intégré.
2. Sous EDK_XPS la plateforme logicielle est
développée et testée sur la plateforme matérielle
générée ; l'exécutable (.elf) est
produit.
3. La plate-forme matérielle ci-dessus est
exportée vers ISE Proj_Nav comme un module d'un design à
plusieurs modules. Ce design est synthétisée suivant les
étapes et les règles (.ucf, .ngc) du Modular Design pour la
reconfiguration partielle.
4. Les bitstreams partiels et complets sont
générés. On peut alors éditer le design
routé du module importé de EDK vers ISE à l'aide de
FPGA Editor afin de localiser les coordonnées des BRAMs et
éditer le fichier system.bmm en s'inspirant du fichier
system_stub.bmm comme indiqué en annexe 2.
5. On associe les fichiers .bit, .elf et .bmm
pour générer le bitstream final.
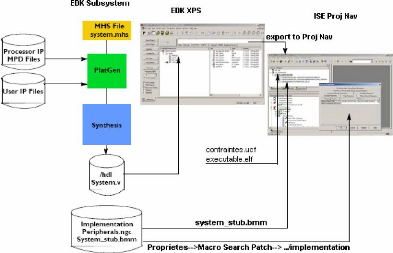
Figure 28 : Flot de conception de l'ensemble de la
plateforme.
4. DIFFICULTES RENCONTREES , CONCLUSION ET
PERSPECTIVES
4.1 Difficultés rencontrées
4.1.1 Les restrictions physiques à la
reconfiguration partielle des FPGAs Xilinx
- La mémoire de configuration du Virtex-II Pro est
certes accessible de façon aléatoire, mais la plus petite
unité adressable est non pas un mot, mais est une frame entière.
Une frame occupe toute la hauteur du FPGA. Un CLB est constitué de
plusieurs colonnes de frames. Les CLBs sont ainsi configurables en colonnes, et
un module occupe toujours toute la hauteur du FPGA. Sa largeur minimale doit
être de 4 CLBs.
- Un module ne peut utiliser que les ressources (CLB, BRAMs,
multiplieurs) se trouvant dans sa zone. Ces ressources même si elles ne
sont pas effectivement utilisées sont perdues pour les autres
modules.
- Un module ne peut utiliser que les pins du FPGA se trouvant
dans sa zone. En conséquence, il empêche à priori à
un autre module l'utilisation des ressources connectées au FPGA par des
pins situés dans sa zone. Les connexions entre les broches du FPGA et
les composants (périphériques, port série, port Ethernet,
LEDs, Switches, écran LCD, mémoires, etc....) situés dans
le voisinage du FPGA sont figées. En effet les cartes de
développement actuellement disponibles n'offrent pas de
flexibilité de connexion. Par exemple avec la carte Memec Design
ci-dessous figure 29, le module ppc_subsystem intégrant le processeur ne
pouvait être connecté ni au port RS-232, ni à la
mémoire SDRAM 32 Mo disponibles sur la carte. Nous avons eu recours
à une carte d'extension P160 Com enfichable sur les slots d'extension de
la carte et possédant un port RS-232 et une mémoire SRAM 1 Mo
supplémentaires.
La flexibilité gagnée dans la reconfiguration
partielle et dynamique des modules est sérieusement entamée d'une
part par la consommation élevée en ressources logiques d'un
design partiellement reconfigurable, et d'autre part par l'absence sur le
marché des cartes de développement adaptées à ce
genre de conception.

Figure 29 : Vue physique de la carte Virtex-II Pro de Memec
Design
4.1.2 Les outils
L'une des difficultés à mettre en oeuvre la
reconfiguration partielle et surtout l'auto reconfiguration est que les outils
ne soient pas au point pour automatiser ce processus.
Ces outils ne sont simplement pas adaptés aux exigences
de la méthode. C'est pourquoi de nombreux bugs survenant lors du
développement sont généralement autant dus aux erreurs de
conception qu'à l'outil de conception lui-même. Fort heureusement
les outils Xilinx éliminent des nombreux bugs logiciels au fur et
à mesure des versions. De même, quelques forums d'échanges
d'expériences sur la mise en oeuvre de la reconfiguration partielle
existent sur le net , le plus fournis étant le forum
partial-reconfig1 hébergé par un serveur de
l' ITEE2.
1
http://www.itee.uq.edu.au/~listarch/partial-reconfig/
2 School of ITEE Information Technology & Electrical
Engineering, University of Queensland, Brisbane - Australia.
4.2 Conclusion
Ce rapport a montré la faisabilité de l'auto
reconfiguration partielle et dynamique sur un FPGA Virtex-II Pro. Ce travail
s'inscrit dans le cadre de la recherche sur les architectures reconfigurables
dynamiquement. Il est une contribution à la définition d'une
méthodologie permettant de tirer le meilleur profit de la
reconfiguration partielle des FPGAs.
Nous avons souligné dans les chapitres 1 et 2 de ce
rapport les avantages et les limites de l'implémentation d'une
application sur un processeur (grande flexibilité au prix de
performances moindres) ou sur un ASIC (grandes performances au prix d'une
faible flexibilité). Nous avons évoqué le meilleur
compromis flexibilité/performance qu'offraient les architectures
reconfigurables dynamiquement en général et les FPGAs en
particulier.
Ce type d'architecture est une des solutions qui permettront
de répondre aux exigences des systèmes embarqués du futur.
La reconfiguration dynamique est en train de combler l'écart entre et le
logiciel et le matériel. Et le FPGA singulièrement profite
beaucoup plus des avancées technologiques. Leur densité
(jusqu'à 10 millions de portes) et leurs performances (200Mhz)
continuent de croître très vite, et on parle de plus en plus de
conception à base de FPGA (FPGA Based Design).
La figure ci-dessous (figure 30) représente un exemple
de SOCs hétérogènes du futur. Une plate-forme comme la
notre est nécessaire à la mise en oeuvre d'un OS
dédié à la gestion de la ressource FPGA. L'architecture
globale du SOC évoluerait pour s'adapter aux traitements à
effectuer. Les applications sont nombreuses dans le domaine de la
téléphonie mobile de 3ème et 4ème géneration
par exemple, meme s'il y a encore des blocages lies a la consommation en
puissance des FPGAs.
D'autre part, l'essor des architectures reconfigurables passe
par le développement des nouveaux outils et méthodes conception
qui pour l'instant semblent en retard sur la technologie.
La figure ci-dessous (figure 30) représente les SOCs
hétérogènes du futur. Une plate-forme comme la notre est
nécessaire à la mise en oeuvre d'un OS dédié
à la gestion de la ressource FPGA.
Enfin, l'essor des architectures reconfigurables passe par le
développement des nouveaux outils et méthodes conception qui pour
l'instant semblent en retard sur la technologie.
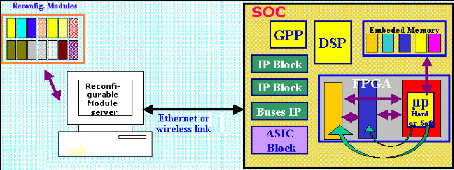
Figure 30 : SOC hétérogéne
4.3 Perspectives
4.3.1 Implémenter les bus macros pour les connexions
inter-modules.
Les bus-macros sont les seuls moyens de connexion entre de
deux modules d'un design partiellement reconfigurable. Nous n'avons pas eu le
temps d'en implémenter dans cette application, notre but premier
étant de valider le concept d'auto reconfiguration. De nombreux exemples
d'implémentation de bus macros existent, et peuvent être
expérimentée sur notre plate-forme de démonstration.
4.3.2 Utiliser XMS (Xilinx Memory File System), le
système de fichier de Xilinx
Dans notre application, nous stockons les bitstreams partiels
par écriture direct des mots en mémoire SRAM a des adresses
précises. Ceci nous impose un contrôle stricte des adresses de
début et de fin des bitstreams en mémoire. Utiliser le
système de fichiers fournis par Xilinx (XilMFS) nous apporterait une
souplesse dans le traitement des bitstreams. Ce système permettrait de
créer/supprimer des fichiers de stockage de bitstreamns en SRAM et de
les lire/écrire avec des instructions faciles.
4.3.3 Implémenter l'interface Ethernet
Utiliser un port Ethernet plutôt qu'une liaison UART
pour transférer les bitstreams de reconfiguration des modules en
mémoire SRAM embarquée accélérerait
considérablement la vitesse de transfert.
Ainsi nous avons implémenté et testé
l'interface de connexion Ethernet. Cet IP est fourni par
Xilinx avec comme
exemple d'application un serveur Web tournant sur le processeur
intégré
PPC405. Cette application rend tout a fait envisageable de
charger via le réseau Ethernet des fichiers bitstreams pour la
reconfiguration de modules.
4.3.4 OS Temps réels pour la gestion de la ressource
FPGA
Ce travail peut être un pas vers la mise en oeuvre d'un
OS temps réel dédié a la gestion de ressources
reconfigurables de type FPGA. Ce type d'OS, à la manière d'un
ordonnanceur dans un OS classique, gérerait l'attribution de la
ressource FPGA à plusieurs taches, dans un contexte temps reel. En effet
aujourd'hui on parle de plus en plus de nouvelles méthodologies pour la
conception des SOCs intégrant des coeurs de processeurs, des IPs de
communications et de la ressource reconfigurable (figure 29). La gestion
efficiente de la partie reconfigurable dynamiquement reste une
problématique entière. La résoudre passe par la mise en
oeuvre des plate-formes comme la notre qui contribuerait la mise en oeuvre de
cet OS.
ANNEXES
ANNEXE 1 : LES OUTILS
1.1 L'outil Floorplanner (Editeur de contraintes
de placement, cas de 2 modules)
|
Figure Annexe 1 :
On remarque que le module a processeur (a droite) occupe
la majeure partie du FPGA. Ceci est surtout du au fait que ce module utilises
des périphériques connectes au FPGA par des pins situes trop a
gauche de la puce. Ceci oblige le module à englober les zones adjacentes
à ces pins.
|
|
1.2 FPGA Editor (Routage avec bitstream
complet)
|
Figure Annexe 2 : Vue sous FPGA Editor) du
Routage complet des deux modules.
|
|
ANNEXE 2 : Procédure de création du
fichier SYSTEM.BMM
Ce fichier indique au programmateur du FPGA Virtex-II Pro la
localisation de la mémoire BRAM associée au processeur PPC405
lors du routage, et dans laquelle sera chargée l'exécutable. En
effet pour configurer le FPGA avec un design utilisant le processeur
intégré, on a besoin du fichier de configuration des ressources
programmables du FPGA (fichier.bit), de l'exécutable
destiné au processeur PPC (fichier.elf) et des
cordonnées de la BRAM (fichier.bmm) associée au
processeur et a partir de laquelle le code sera exécuté.
|
Figure Annexe 3 :
Edition du module ppc_subsystem (généré
lors de la phase active d'implementation) a l'aide de
FPGA Editor.
A gauche : Fenêtre de filtrage en
vue d'afficher les adresses d'implémentation des BRAMs
connectes au processeur. Ces adresses seront manuellement
écrites dans le fichier
system.bmm.
|
|
2.1 Fichier system_stub.bmm
Il est généré par EDK lors de la
génération (X_Flow) du système a processeur.
\SELF_RECONFIG_PLATFORM_DEMO\implementation\system_stub.bmm
|
ADDRESS_BLOCK bram1 RAMB16 [0xffff8000:0xffffffff] BUS_BLOCK
|
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_0
|
[63:60]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_1
|
[59:56]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_2
|
[55:52]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_3
|
[51:48]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_4
|
[47:44]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_5
|
[43:40]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_6
|
[39:36]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_7
|
[35:32]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_8
|
[31:28]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_9
|
[27:24]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_10
|
[23:20]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_11
|
[19:16]
|
;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_12
|
[15:12]
|
;
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_13 [11:8] ;
ppc_subsystem/bram1/bram1/ramb16_s4_s4_14 [7:4] ;
ppc_subsystem/bram1/bram1/ramb16_s4_s4_15 [3:0] ; END_BUS_BLOCK;
END_ADDRESS_BLOCK;
2.2 Le fichier system.bmm.
Il est obtenu en rajoutant quelques informations au fichier
system_stub.bmm ci-dessus. En effet, après la
phase d'implémentation active du module
ppc_subsystem, on édite son fichier .ngd
à l'aide de FPGA Editor, puis on utilise le filtre des
composants de la fenêtre de droite (voir Figure Annexe 4) pour
afficher les informations sur les composants BRAMs utilisés par ce
module. On peut alors relever les adresses d'implantation des BRAMs du fichier
system_stub.bmm. On complète le fichier system.bmm
comme indiqué ci-dessous en gras:
\SELF_RECONFI_PLATFORM_DEMO\Modular\Top\Assemble\system.bmm
|
ADDRESS_BLOCK bram1 RAMB16 [0xffff8000:0xffffffff] BUS_BLOCK
|
|
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_0
|
[63:60]
|
PLACED
|
= X2Y2;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_1
|
[59:56]
|
PLACED
|
= X5Y2;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_2
|
[55:52]
|
PLACED
|
= X4Y2;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_3
|
[51:48]
|
PLACED
|
= X5Y5;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_4
|
[47:44]
|
PLACED
|
=X5Y4;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_5
|
[43:40]
|
PLACED
|
= X5Y3;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_6
|
[39:36]
|
PLACED
|
= X3Y2;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_7
|
[35:32]
|
PLACED
|
= X1Y5;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_8
|
[31:28]
|
PLACED
|
= X1Y4;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_9
|
[27:24]
|
PLACED
|
= X2Y5 ;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_10
|
[23:20]
|
PLACED
|
= X1Y6;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_11
|
[19:16]
|
PLACED
|
= X2Y4;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_12
|
[15:12]
|
PLACED
|
= X1Y3;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_13
|
[11:8]
|
PLACED
|
= X1Y1;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_14
|
[7:4] PLACED = X1Y2;
|
|
ppc_subsystem/bram1/bram1/ramb16_s4_s4_15
|
[3:0] PLACED = X2Y3;
|
|
END_BUS_BLOCK;
|
|
|
|
|
END_ADDRESS_BLOCK;
|
|
|
|
ANNEXE 3: UTILISATION DE LA PLATE-FORME DE
DEMONSTRATION
3.1 Génération des bitstreams a partir des
du répertoire Modular
La fenêtre ci-dessous montre le contenu du
répertoire Modular qui contient tous les sous
répertoires et les fichiers permettant de dérouler les
étapes du Modular Design Flow. Nous supposons que :
- Le module « system a processeur » a été
teste et validé sous EDK puis exporte vers ISE.
- La synthèse des designs du module reconfigurable a
été réalisée et validée dans des projets
ISE, et associés aux divers projets du top.
- La synthèse d'au moins un Top a été
réalisée et le fichier top.ngc se trouvant dans le
répertoire
ISE correspondant.
- Le fichier de contrainte top.ucf a été
édité et se trouve dans le répertoire ISE.
- L'exécutable (fichier.elf) a été
correctement testé et validé dans un flot intégré
(Xflox) sous EDK
(avant exportation).
- L'HyperTerminal a été parametré suivant la
Figure Annexe 5.
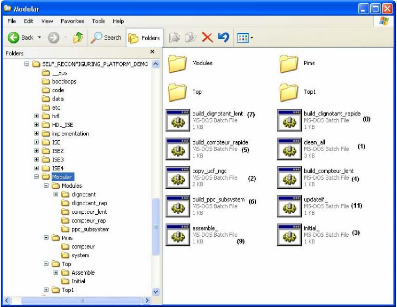
Figure Annexe 4 : Le repertoire Modular avec les fichiers de
commande pour le Modular Design
Les fichiers Batch du répertoire permettent de
dérouler le Modular Design Flot de l'Initial Budgetting à la
Phase finale d'assemblage (voir phases 1 a 11 Figure Annexe 4).
Suivre simplement les étapes de (1) a (9) pour
générer les bitstreams partiels de tous les designs. Les
étapes (4), (5), (7) et (8) ne seront réalisées que si les
designs y afférents ont été effectivement
synthétises).
Apres la phase d'assemblage (9), la phase (10)
consistera a éditer le fichier system.bmm
comme montre en annexe 2. Ce fichier doit être ensuite recopie dans le
répertoire Top/Assemble.
La phase (11) consiste a produire a partir de
trois fichiers (.bit, .elf et .bmm) un fichier unique prêt a configurer
totalement le FPGA.
Apres cette configuration totale, le processeur lance
l'application que nous avons écrite, et affiche via l'HyperTerminal
l'invite de la figure Annexe 6.
Dans cet exemple, le module fixe (ppc_subsystem) est
assemblé dans Top/Assemble avec le dernier design de module
reconfigurable a avoir écrit dans le répertoire Pims (avec la
commande Pimcreate lors de la phase active d'implémentation).
Les fichiers .batch sont en Annexe 4.
3.2 Paramètres de configuration de
l'HyperTerminal
La Vitesse de transmission (19600 bits/sec) est celle qui a
été choisie lors de l'implémentation de l'UART. Pour
accélérer le transfert des fichiers de configuration
Figure Annexe 5 : Paramètres de configuration de
l'HyperTerminal.
3.3 Message d'accueil de la demo
Pour envoyer un bitstream partiel en format .rbt, cliquer sur
transfert et choisir le format texte, et pointer sur le fichier dans le
répertoire ou il a été produit
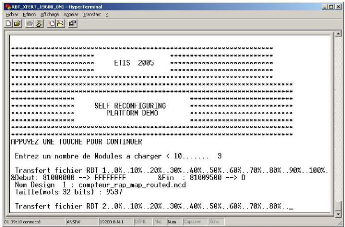
Figure Annexe 6 : Transfert interactif des fichiers des
configurations en mémoire SRAM sur la carte ;
appuyer sur « Transfert ».
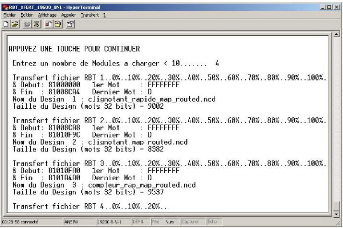
Figure Annexe 7 : Transfert fichier bitstream format .rbt en
cours
3.4 Exemple de début et fin de fichier RBT (module
compteur_rapide)
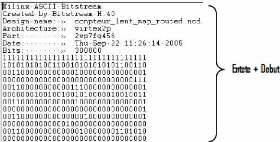

Figure Annexe 8 : Exemple de début et fin d'un fichier
.RBT
ANNEXE 4 : LISTING DES PROGRAMMES
4.1 Le fichier Top
######################## top.vhd
##############################
library IEEE;
use IEEE.STD_LOGIC_1164.ALL; library UNISIM;
use UNISIM.VCOMPONENTS.ALL;
entity top is
port (
clk : IN STD_LOGIC; CLK commun aux 2 modules
I/O module reconfigurable
cen : IN STD_LOGIC;
clr : IN STD_LOGIC;
s_cpt : OUT STD_LOGIC_VECTOR (7 DOWNTO 0);
I/O module system à ppc405
sys_clk : in std_logic;
HALTNEG : in std_logic;
System_reset : in std_logic;
Leds : inout std_logic_vector(0 to 7);
rx : in std_logic;
tx : out std_logic;
sram_addr : out std_logic_vector(0 to 31);
sram_data : inout std_logic_vector(0 to 31);
sram_cen : out std_logic_vector(0 to 0);
sram_oen : out std_logic_vector(0 to 0);
sram_wen : out std_logic;
sram_ben : out std_logic_vector(0 to 3);
sram_rst : out std_logic;
sram_cefn : out std_logic
);
end top;
architecture STRUCTURE of top is
Internal signal du CLK commun
SIGNAL clk_in : STD_LOGIC;
|
Internal signals du module reconfigurable
SIGNAL cpt_clk_sig : STD_LOGIC; --clk
SIGNAL clr_sig : STD_LOGIC;
SIGNAL cen_sig : STD_LOGIC;
SIGNAL s_cpt_sig : STD_LOGIC_VECTOR (7 DOWNTO 0);
Internal signals du module ppc
signal HALTNEG_IBUF : std_logic;
signal sys_clk_sig : std_logic;
|
|
signal
|
leds_I
|
: std_logic_vector(0 to
|
7);
|
|
signal
|
leds_O
|
: std_logic_vector(0 to
|
7);
|
|
signal
|
leds_T
|
: std_logic_vector(0 to
|
7);
|
|
signal
|
rx_IBUF
|
: std_logic;
|
|
|
signal
|
sram_addr_OBUF
|
: std_logic_vector(0 to
|
31);
|
|
signal
|
sram_ben_OBUF
|
: std_logic_vector(0 to
|
3);
|
|
signal
|
sram_cefn_OBUF
|
: std_logic;
|
|
|
signal
|
sram_cen_OBUF
|
: std_logic_vector(0 to
|
0);
|
|
signal
|
sram_data_I
|
: std_logic_vector(0 to
|
31);
|
|
signal
|
sram_data_O
|
: std_logic_vector(0 to
|
31);
|
|
signal
|
sram_data_T
|
: std_logic_vector(0 to
|
31);
|
|
signal
|
sram_oen_OBUF
|
: std_logic_vector(0 to
|
0);
|
|
signal
|
sram_rst_OBUF
|
: std_logic;
|
|
|
signal
|
sram_wen_OBUF
|
: std_logic;
|
|
|
signal
|
system_reset_IBUF
|
: std_logic;
|
|
signal tx_OBUF : std_logic;
ATTRIBUTE BOX_TYPE : STRING;
-IIIIIIIIIIIIIIIIIIII composant system
IIIIIIIIIIIIIIIIIIIIIIIIIIIIII
component system is
port (
sys_clk : in std_logic;
HALTNEG : in std_logic;
system_reset : in std_logic;
rx : in std_logic;
tx : out std_logic;
sram_addr : out std_logic_vector(0 to 31);
sram_cen : out std_logic_vector(0 to 0);
sram_oen : out std_logic_vector(0 to 0);
sram_wen : out std_logic;
sram_ben : out std_logic_vector(0 to 3);
sram_rst : out std_logic;
sram_cefn : out std_logic;
leds_I : in std_logic_vector(0 to 7);
leds_O : out std_logic_vector(0 to 7);
leds_T : out std_logic_vector(0 to 7);
sram_data_I : in std_logic_vector(0 to 31);
sram_data_O : out std_logic_vector(0 to 31);
sram_data_T : out std_logic_vector(0 to 31)
);
end component;
ATTRIBUTE BOX_TYPE OF system : COMPONENT IS "BLACK_BOX";
-IIIIIIIIIIIIIIIIIIIIIIII COMPONENT compteur
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII
component compteur is
Port (
s_cpt : OUT STD_LOGIC_VECTOR(7 DOWNTO 0);
clk : IN STD_LOGIC;
cen : IN STD_LOGIC;
clr : IN STD_LOGIC
);
end component;
ATTRIBUTE BOX_TYPE OF compteur : COMPONENT IS "BLACK_BOX";
IIII Buffer Clk BUFG : Peut-on utiliser BUFGP? BUFG marche
IIIIIIIIII component BUFG is
port (
I : in std_logic;
O : out std_logic
);
end component;
ATTRIBUTE BOX_TYPE OF BUFG : COMPONENT IS "BLACK_BOX";
--IIIIIIIIIIIIIIIIII Buffer d'entree IBUF
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII component IBUF is
port (
I : in std_logic;
O : out std_logic
);
end component;
ATTRIBUTE BOX_TYPE OF IBUF : COMPONENT IS "BLACK_BOX";
IIIIIIIIII Buffer d'entre/sortie tri-states IOBUF
IIIIIIIIIIIIIIIIIIIIIIIIII component IOBUF is
port (
I : in std_logic;
IO : inout std_logic;
O : out std_logic;
T : in std_logic
);
end component;
ATTRIBUTE BOX_TYPE OF IOBUF : COMPONENT IS "BLACK_BOX";
-----IIIIIIIIIIII Buffer de sortie OBUF
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII component OBUF is
port (
I : in std_logic;
O : out std_logic
);
end component;
ATTRIBUTE BOX_TYPE OF OBUF: COMPONENT IS "BLACK_BOX";
----IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII BEGIN TOP
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII Begin
----IIIIIIIIII Instanciation du module reconfigurable COMPTEUR
et
connexions aux signaux internes
count : compteur PORT MAP (
clk => sys_clk_sig,
cen => cen_sig,
clr => clr_sig,
s_cpt => s_cpt_sig);
----IIIIII instanciation des Buffers I/Os et...
---- ...connexions des signaux internes du module cOMPTEUR
clr_buf : IBUF PORT MAP (I=>clr, O=>clr_sig);
cen_buf : IBUF PORT MAP (I=>cen, O=>cen_sig);
loop_buf1: for i in 0 to 7 generate
s_cpt_buf : OBUF PORT MAP (I=>s_cpt_sig(i),
O=>s_cpt(i));
end generate;
----IIIIII Instanciation du module fixe SYSTEM et ...
connexions aux signaux internes
ppc_subsystem : system
port map (
sys_clk => sys_clk_sig,
HALTNEG => HALTNEG_IBUF,
system_reset => system_reset_IBUF,
rx => rx_IBUF,
tx => tx_OBUF,
sram_addr => sram_addr_OBUF,
sram_cen => sram_cen_OBUF(0 to 0),
sram_oen => sram_oen_OBUF(0 to 0),
sram_wen => sram_wen_OBUF,
sram_ben => sram_ben_OBUF,
sram_rst => sram_rst_OBUF,
sram_cefn => sram_cefn_OBUF,
leds_I => leds_I,
leds_O => leds_O,
leds_T => leds_T,
sram_data_I => sram_data_I,
sram_data_O => sram_data_O,
sram_data_T => sram_data_T
);
IIIIII Distribution du CLK aux 2 modules
ibuf_0 : IBUF port map ( I => clk, O => clk_in );
bufgp_0 : BUFG port map ( I => clk_in , O => sys_clk_sig
);
End CLK Distribution
----### instanciation des Buffers I/Os et...
---- ...connexions des signaux internes du module SYSTEM
ibuf_1 : IBUF port map ( I => HALTNEG, O => HALTNEG_IBUF
);
ibuf_2 : IBUF port map ( I => system_reset, O =>
system_reset_IBUF );
buffer sortie inout leds
loop_leds_iobuf : for i in 0 to 7 generate leds_iobuf : IOBUF
port map ( I=>leds_O(i), IO=>leds(i), O => leds_I(i), T
=> leds_T(i) );
end generate ;
buffer sortie inout sram
loop_sram_data_iobuf : for i in 0 to 31 generate
sram_data_iobuf : IOBUF
port map ( I=>sram_data_O(i), IO=>sram_data(i),
O => sram_data_I(i), T => sram_data_T(i) );
end generate ;
ibuf_11 : IBUF port map (I => rx, O => rx_IBUF );
obuf_12 : OBUF port map (I => tx_OBUF, O => tx );
obuf_13 : OBUF port map (I => sram_addr_OBUF(0), O =>
sram_addr(0) );
obuf_14 : OBUF port map (I => sram_addr_OBUF(1), O =>
sram_addr(1));
obuf_15 : OBUF port map (I => sram_addr_OBUF(2),O =>
sram_addr(2));
obuf_16 : OBUF port map (I => sram_addr_OBUF(3), O =>
sram_addr(3));
obuf_17 : OBUF port map (I => sram_addr_OBUF(4), O =>
sram_addr(4));
obuf_18 : OBUF port map (I => sram_addr_OBUF(5), O =>
sram_addr(5) );
obuf_19 : OBUF port map (I => sram_addr_OBUF(6), O =>
sram_addr(6) );
obuf_20 : OBUF port map ( I => sram_addr_OBUF(7), O =>
sram_addr(7));
obuf_21 : OBUF port map ( I => sram_addr_OBUF(8), O =>
sram_addr(8) );
obuf_22 : OBUF port map ( I => sram_addr_OBUF(9), O =>
sram_addr(9) );
obuf_23 : OBUF port map ( I => sram_addr_OBUF(10), O =>
sram_addr(10) );
obuf_24 : OBUF port map ( I => sram_addr_OBUF(11), O =>
sram_addr(11) );
obuf_25 : OBUF port map ( I => sram_addr_OBUF(12), O =>
sram_addr(12) );
obuf_26 : OBUF port map ( I => sram_addr_OBUF(13), O =>
sram_addr(13) );
obuf_27 : OBUF port map ( I => sram_addr_OBUF(14), O =>
sram_addr(14) );
obuf_28 : OBUF port map ( I => sram_addr_OBUF(15), O =>
sram_addr(15) );
obuf_29 : OBUF port map ( I => sram_addr_OBUF(16), O =>
sram_addr(16) );
obuf_30 : OBUF port map ( I => sram_addr_OBUF(17), O =>
sram_addr(17) );
obuf_31 : OBUF port map ( I => sram_addr_OBUF(18), O =>
sram_addr(18) );
obuf_32 : OBUF port map ( I => sram_addr_OBUF(19), O =>
sram_addr(19) );
obuf_33 : OBUF port map ( I => sram_addr_OBUF(20), O =>
sram_addr(20) );
obuf_34 : OBUF port map ( I => sram_addr_OBUF(21), O =>
sram_addr(21) );
obuf_35 : OBUF port map ( I => sram_addr_OBUF(22), O =>
sram_addr(22) );
obuf_36 : OBUF port map ( I => sram_addr_OBUF(23), O =>
sram_addr(23) );
obuf_37 : OBUF port map ( I => sram_addr_OBUF(24), O =>
sram_addr(24) );
obuf_38 : OBUF port map ( I => sram_addr_OBUF(25), O =>
sram_addr(25));
obuf_39 : OBUF port map ( I => sram_addr_OBUF(26), O =>
sram_addr(26) );
obuf_40 : OBUF port map ( I => sram_addr_OBUF(27), O =>
sram_addr(27) );
obuf_41 : OBUF port map (I => sram_addr_OBUF(28), O =>
sram_addr(28) );
obuf_42 : OBUF port map ( I => sram_addr_OBUF(29), O =>
sram_addr(29) );
obuf_43 : OBUF port map ( I => sram_addr_OBUF(30), O =>
sram_addr(30) );
obuf_44 : OBUF port map ( I => sram_addr_OBUF(31), O =>
sram_addr(31) );
obuf_77 : OBUF port map ( I => sram_cen_OBUF(0), O =>
sram_cen(0) );
obuf_78 : OBUF port map ( I => sram_oen_OBUF(0), O =>
sram_oen(0) );
obuf_79 : OBUF port map ( I => sram_wen_OBUF, O => sram_wen
);
obuf_80 : OBUF port map ( I => sram_ben_OBUF(0), O =>
sram_ben(0) );
obuf_81 : OBUF port map ( I => sram_ben_OBUF(1), O =>
sram_ben(1) );
obuf_82 : OBUF port map ( I => sram_ben_OBUF(2), O =>
sram_ben(2) );
obuf_83 : OBUF port map ( I => sram_ben_OBUF(3), O =>
sram_ben(3) );
obuf_84 : OBUF port map ( I => sram_rst_OBUF, O => sram_rst
);
obuf_104 : OBUF port map ( I => sram_cefn_OBUF, O =>
sram_cefn );
end architecture STRUCTURE;
4.2 Code VHDL d'un design du module reconfigurable
################### compteur_lent.vhd
########################
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.STD_LOGIC_ARITH.ALL;
use IEEE.STD_LOGIC_UNSIGNED.ALL;
entity compteur is Port (
s_cpt : OUT STD_LOGIC_VECTOR(7 DOWNTO 0);
clk : IN STD_LOGIC;
cen : IN STD_LOGIC;
clr : IN STD_LOGIC
);
end compteur;
architecture compt_lent of compteur is
SIGNAL cpt: STD_LOGIC_VECTOR (7 DOWNTO 0);
SIGNAL clk_1h : STD_LOGIC; -- horloge 1 hertz
SIGNAL X : STD_LOGIC_VECTOR (24 DOWNTO 0);
CONSTANT N : INTEGER:= 24999999 ; --- modulo 50 000 000
Begin
proc_div: process (clk,clr,cen, X)
begin
if clr='0' -- push1
then X<="0000000000000000000000000"; elsif cen='1' then
if clk'event and clk='1'then
if X>N then X<="0000000000000000000000000";
else X<=X+1;
end if;
end if ;
if X>12499999 then -- rapport cyclique 1/2
clk_1h<='1';
else clk_1h<='0';
end if;
end if;
end process;
proc_cpt : process (clk_1h,clr,cen)
begin
if clr='0' then cpt<="00000000";
elsif cen='1' then
if clk_1h'event and clk_1h='1'then cpt<=cpt+1;
end if;
end if;
end process;
s_cpt<=not cpt;
end compt_lent;
4.3 Fichier de contraintes
################### top.ucf
########################
#####Constraints For Virtex II - Pro Design
# Timing Ignore Constraints #
# Non-critical Reset Nets
# Level Interrupt from Uart
# Non-critical Nets
# Clock Period Constraints #
# 100 MHz Ref Clk to DCM Produces PLB(1X), CPU(FX=3X) #
(Over-Constrain Period by 250 ps to allow for Jitter,
# Skew, Noise, Etc)
# Multicycle Path Constraints for DCR #
# IO Pad Location Constraints (2VP4/7 AFX Board)
# CLK commun aux deux modules -#
NET "clk" PERIOD = 10.00;
NET "clk" LOC = "v12" ;
##### module reconfigurable count situé à gauche,
instance "count"####
NET "cen" LOC = "W5" | PULLUP ; # PUSH2 NET "clr" LOC = "V7" |
PULLUP ; # PUSH1
# sorties compteur 8 bits, module de gauche;
NET "s_cpt<0>" LOC = "W6" ; # LED2 DS8
NET "s_cpt<1>" LOC = "V8" ; # LED1 DS7
NET "s_cpt<2>" LOC = "D5" ; # LCD Data Bit 2 D2 sur main
board
NET "s_cpt<3>" LOC = "D6" ; # LCD Data Bit 3 D3 sur main
board
NET "s_cpt<4>" LOC = "C7" ; # LCD Data Bit 4 D4 sur main
board
NET "s_cpt<5>" LOC = "D8" ; # LCD Data Bit 5 D5 sur main
board
NET "s_cpt<6>" LOC = "C8" ; # LCD Data Bit 6 D6 sur main
board
NET "s_cpt<7>" LOC = "E8" ; # LCD Data Bit 7 D7 sur main
board
#NET "clk_out" LOC = "D7" ; # LCD Data Bit 0 D0 sur main board
##### module SYSTEM situé à droite, instance
"ppc_subsystem" ##### #PACE: Start of Constraints generated by PACE
#PACE: Start of PACE I/O Pin Assignments
NET "system_reset" LOC = "v15" ;
##### UART
NET "tx" LOC = "E14" ;
NET "rx" LOC = "F14" ;
###### ETHERNET
NET "HALTNEG" LOC = "AA11" | PULLUP ;
NET "leds<0>" LOC = "u10" ;
NET "leds<1>" LOC = "v10" ;
NET "leds<2>" LOC = "W13" | PULLUP ;
NET "leds<3>" LOC = "Y13" | PULLUP ;
NET "leds<4>" LOC = "W14" | PULLUP ;
NET "leds<5>" LOC = "W15" | PULLUP ;
NET "leds<6>" LOC = "Y15" | PULLUP ;
NET "leds<7>" LOC = "W16" | PULLUP ;
#### Connexion a la SRAM externe de la carte d'extension P160
Comm
NET "sram_addr<0>" LOC = "u11" ;
NET "sram_addr<10>" LOC = "J22" ;
NET "sram_addr<11>" LOC = "P20" ;
NET "sram_addr<12>" LOC = "N20" ;
NET "sram_addr<13>" LOC = "L17" ;
NET "sram_addr<14>" LOC = "J17" ;
NET "sram_addr<15>" LOC = "P22" ;
NET "sram_addr<16>" LOC = "L21" ;
NET "sram_addr<17>" LOC = "K22" ;
NET "sram_addr<18>" LOC = "J18" ;
NET "sram_addr<19>" LOC = "K17" ;
NET "sram_addr<1>" LOC = "d18" ;
NET "sram_addr<20>" LOC = "K21" ;
NET "sram_addr<21>" LOC = "J21" ;
NET "sram_addr<22>" LOC = "AB21" ;
NET "sram_addr<23>" LOC = "U18" ;
NET "sram_addr<24>" LOC = "T18" ;
NET "sram_addr<25>" LOC = "P17" ;
NET "sram_addr<26>" LOC = "N19" ;
NET "sram_addr<27>" LOC = "R18" ;
NET "sram_addr<28>" LOC = "P18" ;
NET "sram_addr<29>" LOC = "N18" ;
NET "sram_addr<2>" LOC = "d17" ;
NET "sram_addr<30>" LOC = "w18" ;
NET "sram_addr<31>" LOC = "v11" ;
NET "sram_addr<3>" LOC = "BANK1" ;
NET "sram_addr<4>" LOC = "BANK4" ;
NET "sram_addr<5>" LOC = "BANK4" ;
NET "sram_addr<6>" LOC = "u14" ;
NET "sram_addr<7>" LOC = "v14" ;
NET "sram_addr<8>" LOC = "u13" ;
NET "sram_addr<9>" LOC = "v13" ;
NET "sram_ben<0>" LOC = "F20" ;
NET "sram_ben<1>" LOC = "G19" ;
NET "sram_ben<2>" LOC = "1" ;
NET "sram_ben<3>" LOC = "2" ;
NET "sram_cefn" LOC = "L20" ;
NET "sram_cen<0>" LOC = "Y22" ;
NET "sram_data<0>" LOC = "L19" ;
NET "sram_data<10>" LOC = "T19" ;
NET "sram_data<11>" LOC = "M18" ;
NET "sram_data<12>" LOC = "U20" ;
NET "sram_data<13>" LOC = "M19" ;
NET "sram_data<14>" LOC = "N17" ;
NET "sram_data<15>" LOC = "M20" ;
NET "sram_data<16>" LOC = "R22" ;
NET "sram_data<17>" LOC = "J20" ;
NET "sram_data<18>" LOC = "J19" ;
NET "sram_data<19>" LOC = "T22" ;
NET "sram_data<1>" LOC = "L18" ;
NET "sram_data<20>" LOC = "U21" ;
NET "sram_data<21>" LOC = "K20" ;
NET "sram_data<22>" LOC = "V22" ;
NET "sram_data<23>" LOC = "K18" ;
NET "sram_data<24>" LOC = "R21" ;
NET "sram_data<25>" LOC = "P21" ;
NET "sram_data<26>" LOC = "U22" ;
NET "sram_data<27>" LOC = "T21" ;
NET "sram_data<28>" LOC = "K19" ;
NET "sram_data<29>" LOC = "V21" ;
NET "sram_data<2>" LOC = "R19" ;
NET "sram_data<30>" LOC = "Y21" ;
NET "sram_data<31>" LOC = "W22" ;
NET "sram_data<3>" LOC = "T20" ;
NET "sram_data<4>" LOC = "U19" ;
NET "sram_data<5>" LOC = "V20" ;
NET "sram_data<6>" LOC = "M17" ;
NET "sram_data<7>" LOC = "V19" ;
NET "sram_data<8>" LOC = "R20" ;
NET "sram_data<9>" LOC = "AA22" ;
NET "sram_oen<0>" LOC = "W21" ;
NET "sram_rst" LOC = "E13" ;
NET "sram_wen" LOC = "H18" ;
IIIIIIIIIIIIIIIIPACE: Start of PACE Area Constraints
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII
IIIIIIIIII module de gauche, reconfigurable
AREA_GROUP "AG_count" RANGE = SLICE_X0Y79:SLICE_X15Y0 ;
AREA_GROUP "AG_count" MODE = RECONFIG ;
INST count AREA_GROUP = AG_count ;
######## Module de droite, systeme a processeur
AREA_GROUP "AG_ppc_subsystem" RANGE = SLICE_X16Y79:SLICE_X67Y0
;
AREA_GROUP "AG_ppc_subsystem" MODE = RECONFIG ;
INST ppc_subsystem AREA_GROUP = AG_ppc_subsystem ;
#PACE: End of Constraints generated by PACE
4.4 Les codes sources des programmes
développés en C pour le processeur PPC
/***************************** Include Files
*********************************/ #include <xstatus.h>
#include <xbasic_types.h>
#include <xparameters.h>
#include <xhwicap_i.h>
#include <xuartlite_l.h>
#include <string.h>
#include "xuartlite.h"
unsigned int* xfert_rbt_file(unsigned int*, int ); // fonction de
xfert de fichier RBT en SRAM int read_frame_icap(void); // fonction de lecture
des frames par ICAP
int write_frame_icap(unsigned int** , unsigned int *);
void write_frame(void);
void init_icap(void);
void intro(void);
#define NBRE_MAX_CONFIG_FILE 10 /* Nombre maximum de modules
bitstreams à
charger en SRAM */
#define ADDR_DEBUT_CONFIG 0x81000000 // adresse de debut SRAM
unsigned char nom_fichier[NBRE_MAX_CONFIG_FILE][35]; // tableau noms
fichiers
unsigned int nbr_lignes[NBRE_MAX_CONFIG_FILE]; // tableau taille
des configurations
XHwIcap MyIcap;
main()
{
int r, i, l;
int nbre_config;
unsigned int* config_pt[NBRE_MAX_CONFIG_FILE]; /* pointeur des
configurations en
mémoire SRAM */
unsigned int taille_config =0;
Xuint8 Ch, caract;
r=0;
config_pt[0] = (unsigned int*)ADDR_DEBUT_CONFIG; // donc unsigned
int** config_pt;
intro ();
xil_printf("\n\r\n\r Entrez un nombre de Modules a charger <
10 ");
Ch=XUartLite_RecvByte ( XPAR_MYUART_BASEADDR ); xil_printf("
%c\n\r", Ch);
nbre_config=atoi(&Ch);
// Transfert des fichiers RBT en mémoire SRAM
while (r<nbre_config) {
xil_printf("\n\r Transfert fichier RBT %d..", r+1);
/* config_pt[r+1] = pointeur sur la prochaine configuration,
retournée par la fonction unsigned int*
xfert_rbt_file(unsigned int*, int ) */
config_pt[r+1]=xfert_rbt_file(config_pt[r], r);
/* xil_printf("\n\r&Debut: %x --> %x &Fin : %x -->
%x " , config_pt[r], *(config_pt[r]), config_pt[r+1]-1,
*(config_pt[r+1]-1)); */
/* xil_printf(" &Fin : %x --> %x " , config_pt[r+1]-1,
*(config_pt[r+1]-1)); */
// xil_printf("\n\rr=%d adresse debut config: %x\n\r" ,r+2 ,
config_pt[r+1]);
// taille_config=config_pt[r];
// xil_printf("\n\r Nom Design %d : %s" ,r+1, nom_fichier[r]
);
// xil_printf("\n\r Taille(mots 32 bits) : %d \n\r
",nbr_lignes[r]);
r++;
} // END while (r<nbre_config)
/*
// Affichage des adresses SRAM et Noms fichiers pour
vérification
for(r=0; r<nbre_config; r++ )
{
xil_printf("\n\r Nom fichier RBT %d --> %s Taille -->
%d\n\r " ,r+1, nom_fichier[r], nbr_lignes[r]); xil_printf("\n\r Configuration
%d & debut: %x Contenu %x ",r+1, config_pt[r],*(config_pt[r]));
xil_printf("\n\r Configuration %d & fin : %x Contenu %x
",r+1, config_pt[r+1]-1, *(config_pt[r+1]-1));
// for(i=0; i<config_pt[r+1]-config_pt[r]; i++)
// xil_printf( "\n\rSRAM & %x = %x ", config_pt[r]+i,
*(config_pt[r]+i));
}
*/
init_icap();
// write_frame();
// xil_printf("\n\r\n\r Dans main(): Taille=%d Config_pt[0]=
%x",nbr_lignes[0], config_pt[0]);
// l=read_frame_icap();
// l=write_frame_icap( config_pt[0], nbr_lignes );
// l=write_frame_icap( config_pt, nbr_lignes );
// A chaque fois, l pourra etre utilisé pour controle
d'erreur
xil_printf("\n\r Choix du Module a charger:");
while(1) {
for (i=0;i<r;i++) xil_printf("\n\r%s tapez --> %d
",nom_fichier[i], i+1 ); caract=XUartLite_RecvByte ( XPAR_MYUART_BASEADDR );
// xil_printf(" \n\r caract= %c", caract);
l=atoi(&caract);
// xil_printf("\n\r l= %d ",l);
if((l<1)||(l>=r))
xil_printf(" \n\r Erreur tapez le bon chiffre");
else {
xil_printf(" %d", l);
l=write_frame_icap( config_pt+l-1, nbr_lignes+l-1 ); // l pourra
etre utilisé pour controle d'erreur
xil_printf("\n\r\n\r Fin Reconfiguration %s ",
nom_fichier[l-1]);
}
}
while(1);
} // fin main
/********************* Constant Definitions for
ICAP ***********************/
#define ICAP_BUFFER_SIZE 512 /* Nombre de mots du bitstream
à envoyer ds le buffer_bram
d'ICAP, sachant que sa taille maxi est 4 Ko, soit 512 mots de 32
bits maxi *\
#define XHI_EX_MY_ID 0 /* IdCode de l'instance ICAP donné
par l'utilisateur, n'a rien a voir avec
l'IdCode constructeur */
#define XHI_EX_MAX_RETRIES 100
#define XHI_EX_ONE_WORD 1
#define XHI_EX_ADDRESS_OFFSET 0
/***********************END Constant Definitions for ICAP
***********************/
/* Implements the Assert callback function defined by
xbasic_types.h.
* It potentially enters an infinite loop depending on the value
of the XWaitInAssert variable.
* @param File is the name of the filename of the source (indique
nom du fichier du code en cours d'execution * @param Line is the linenumber
within File (indique la ligne d'erreur dans le code)
**************************************************************************/
void XHwIcap_AssertHandler (char* FilenamePtr, int LineNumber)
{
//xil_printf("\n\rAssert occured in file: %s at line %d
\n\r",FilenamePtr,LineNumber);
return;
}
void init_icap(void)
{
// Xuint32 IdCode;
// Holds status of XHwIcap calls.
XStatus Status;
// Instance of HwIcap
// XHwIcap MyIcap;
XAssertCallback MyCallBack;
// Setup assert handler.
MyCallBack = &XHwIcap_AssertHandler;
XAssertSetCallback(MyCallBack);
Status = XHwIcap_Initialize( &MyIcap, XHI_EX_MY_ID,XHI_XVP7);
// added by me if (Status != XST_SUCCESS) {
// xil_printf("\n\r Failed to initialize: %d \n\r",Status);
exit(-1);
}
else xil_printf("\n\r Succeed to initialize Icap: %d
\n\r",Status);
}
/*********** FUNCTION RECONFIGURER UN MODULE VIA L'ICAP
***************/
int write_frame_icap( unsigned int** config_pt, unsigned int
*taille)
{
/* Instance of HwIcap */
int *t;
unsigned int icap_buffer_size;
// unsigned int reste;
unsigned int cpt_mot; // pour parcourir tous les mots de
configuration en partant du pointeur // sur le debut de configuration
*t=*taille;
// xil_printf("\n\r Beginning Module Reconfiguration");
cpt_mot=0;
while (*t>0){
for (icap_buffer_size=0;
icap_buffer_size<ICAP_BUFFER_SIZE;icap_buffer_size++)
{
XHwIcap_StorageBufferWrite(&MyIcap, icap_buffer_size,
*(*config_pt+cpt_mot)); // BRAM icap
/* xil_printf( "\n\r__trace *t=%d icap_buffer_size = %d compteur
mot = %d", *t,
icap_buffer_size, cpt_mot); */
cpt_mot++;
}
// xil_printf( "\n\r Test de *t= %d ", *t );
if (*t<ICAP_BUFFER_SIZE) /* si le reste de mots a
écrire est inférieur a la taille du
buffer...évite d'aller au-delà de la fin des mots
de configuration du module */
{
XHwIcap_DeviceWrite(&MyIcap, XHI_EX_ADDRESS_OFFSET,*t);
/* if((*taille-*t)%10==0) xil_printf( "\n\r__trace
*(*config_pt+*taille-*t) = & %x *t= %d ",
*(*config_pt+*taille-*t),*t);
// xil_printf( "\n\r__trace Ecriture ICAP %d valeurs", *t); */
}
else
{ XHwIcap_DeviceWrite(&MyIcap,
XHI_EX_ADDRESS_OFFSET,ICAP_BUFFER_SIZE);
/* xil_printf( "\n\r__trace Ecriture ICAP %d valeurs",
ICAP_BUFFER_SIZE);
* /
}
(*t)-=ICAP_BUFFER_SIZE;
} //END while (*t)
/* xil_printf( "\n\r__SRAM & %x --> %x icap_buffer_size=
%d",
*config_pt+*taille-*t,
*(*config_pt+*taille-*t),icap_buffer_size); */
// xil_printf("\n\r Fin Reconfiguration Module");
return 0;
} /********** END FUNCTION Reconfiguration d'un Module
*******/
/********** FUNCTION CHARGEANT LES FICHIERS RBT EN
MEMOIRE *******/ /********** SRAM VIA HYPERTERMINAL ET PORT SERIE
****************/ unsigned int* xfert_rbt_file(unsigned int* config_pt, int
r)
{
unsigned char reception=0;
int i=0; // pour parcourir tout le fichier
int j=0;
int ligne=0;
int ligne_temp=0;
int l=0;
unsigned int data=0;
// int r=0;
unsigned int* tab_data ; // bitstream en mémoire
unsigned int nbr_lignes_temp;
unsigned int taille_bits;
unsigned int p=0;
int q=0;
int k=0; // pour chercher fin de lignes et tabulations...
int m=0; int n=0; // int nbr_lignes=0;
unsigned char tab_char[250]; // tableau pour stocker
l'entête du fichier RBT
// unsigned char nom_fichier[20];
unsigned char nbr_bits[8];
// xil_printf("\n\r\n\r_transferez votre fichier RBT:\n\r\n\r
");
// Analyse des 7 lignes d'entête du fichier RBT, de ligne 0
à 6 while(ligne<7)
{
reception=XUartLite_RecvByte ( XPAR_MYUART_BASEADDR );
tab_char[i]=reception;
i++;
// 10= saut ligne; 13= retour chariot; 9= tabulation, // Comptage
des lignes
if (reception==10) ligne++;
/* à la fin de ce while() on a parcouru toute
l'entête du fichier RBT , ligne =7 */
}
ligne_temp=ligne; // ligne vaut 7 ici
// xil_printf("\n\r_ valeur de ligne fin entête: %d \r\n\r
", ligne);
/*
xil_printf("\n\r Transfert en cours ");
xil_printf("\n\r Analyse entete fichier RBT ");*/
for ( k=0; k<i-1; k++) { /* parcours tableau entete tab_char[]
*/
/* Recherche nom du fichier dans tableau - entête et
stockage dans tableau nom_fichier[30] */
if ((tab_char[k]==9)&(j==0))
/* j=0 pour la 1ère tabulation(9) dans entête */
{
while(tab_char[k+1]!=13)
{ /* fin ligne 1ère tabulation */
k++;
nom_fichier[r][n]=tab_char[k]; n++;
j=n;
/* surveiller de près l'utilisation de j ailleurs, peut
perturber le programme */
}
nom_fichier[r][n]='\0'; /* pour boucler la chaîne
nom_fichier */
// xil_printf("\n\r \n\r");
// xil_printf("\n\r Nom Design Config %d: %s",r+1,
nom_fichier[r]);
}
/* Recherche nombre de bits dans tableau-entete et stockage dans
tableau nbr_bits[20] */
if (tab_char[k]==10) /* lignes */
{
ligne_temp--;
/* avant décrémentation, ligne=7, à la fin
ligne=1 => 7ème ligne */
}
if ((tab_char[k]==9)&&(ligne_temp==1)) /* tabulation de
la 7ème ligne */
{
n=0;
while (tab_char[k+1]!=13)
{
k++;
nbr_bits[n]=tab_char[k];
j++;
n++;
}
nbr_bits[n]='\0'; /* pour boucler la chaîne nombre de bits
*/
taille_bits=atoi(&(nbr_bits[0]));
}
} /* Fin boucle for (k=0; k<i-1; k++) de parcours du tableau
entête*/
tab_data=config_pt; // on affecte à tab_data le pointeur
sur config reçu en argument l=0; p=0; data=0;
nbr_lignes[r]=taille_bits/32; // calcul de la taille de
tab_data
/* xil_printf("\n\r Fin Analyse entête fichier RBT ");
xil_printf("\n\r Nom Design Config %d: %s",r+1,
nom_fichier[r]);
xil_printf("\n\r Taille du Design %d (mots 32 bits) = %d \n\r
",r+1,nbr_lignes[r]); */
nbr_lignes_temp=taille_bits/32;
n=nbr_lignes_temp/10;
while(nbr_lignes_temp)
{
reception=XUartLite_RecvByte ( XPAR_MYUART_BASEADDR ); if
((reception=='0')||(reception=='1')) {
data = 2*data + (unsigned int)reception-(unsigned int)48; }
// Sinon atteinte fin de ligne
else if((int)reception==13) {
*(tab_data+p)=data;
}
else if(reception==10) {
// if(ligne%300==0) xil_printf("\r\n %d --> %x", ligne,
*(tab_data+p));
if((ligne-7)%n==0) xil_printf("%d%c..", 10*ligne/n,'%'
);
ligne++;
p++;
nbr_lignes_temp-- ; data=0; //
}
} // Fin while(nbr_lignes_temp)
/* xil_printf("\n\r taille_bits =%d Nombre de lignes = %d",
taille_bits, nbr_lignes_temp); */
/* xil_printf("\r\n derniere ligne:%d & %x --> mot
%x\n\r", ligne-1,tab_data+p-1, *(tab_data+p-1)); */
return (tab_data+p); //
retourne le pointeur sur la configuration suivante
} /******* END FUNCTION ************/
/************** FUNCTION INTRO_ACCUEIL
*********************/
void intro( )
{
char Ch;
xil_printf("\n\r"); xil_printf("\n\r"); xil_printf("\n\r");
xil_printf("\n\r"); xil_printf("\n\r");
xil_printf("\n\r******************************************************");
xil_printf("\n\r******************************************************");
xil_printf("\n\r********** STAGE ETIS_ARCHI 2005 *************");
xil_printf("\n\r************ by G. Wassi
****************");
xil_printf("\n\r******************************************************");
xil_printf("\n\r******************************************************");
xil_printf("\n\r");
xil_printf("\n\r******************************************************");
xil_printf("\n\r******************************************************");
xil_printf("\n\r***********
******************");
xil_printf("\n\r*********** SELF RECONFIGURING
******************");
xil_printf("\n\r*********** PLATFORM DEMO
******************");
xil_printf("\n\r***********
******************");
xil_printf("\n\r******************************************************");
xil_printf("\n\r******************************************************");
xil_printf("\n\r");
xil_printf("APPUYEZ UNE TOUCHE POUR CONTINUER "); Ch=inbyte();
} /***************** END FUNCTION INTRO_ACCUEIL ************/
################### Linker script
#####################
// $xilinx_legal_disclaimer */
_STACK_SIZE = 1k;
MEMORY { extmem : ORIGIN = 0x81000000, LENGTH = 1M
}
STARTUP(boot.o)
ENTRY(_boot)
GROUP(libxil.a libc.a)
SECTIONS
{
.vectors BLOCK (64k):
{
*(.vectors)
} > extmem
.text :
{ *(.text)
*(.text.*)
*(.gnu.linkonce.t*) } > extmem
.data :
{ *(.data)
*(.got2) *(.rodata)
*(.fixup) *(.data.*)
*(.gnu.linkonce.d*)
*(.rodata.*)
*(.gnu.linkonce.r*)
*(.eh_frame)
} > extmem
/* small data area (read/write): keep together! */ .sdata :
{ *(.sdata) } > extmem
.sbss :
{
. = ALIGN(4); *(.sbss)
. = ALIGN(4); } > extmem
__sbss_start = ADDR(.sbss); __sbss_end = ADDR(.sbss) +
SIZEOF(.sbss);
/* small data area 2 (read only) */ .sdata2 : { *(.sdata2) } >
extmem
.bss :
{
. = ALIGN(4); *(.bss)
*(COMMON)
. = ALIGN(4);
__bss_end = .;
/* add stack and align to 16 byte boundary */
. = . + _STACK_SIZE;
. = ALIGN(16);
__stack = .;
_heap_start = .;
. = . + _HEAP_SIZE; . = ALIGN(16);
_heap_end = .;
} > extmem
__bss_start = ADDR(.bss);
.boot0 :
{
*(.boot0) _end = .; } > extmem
.boot : { *(.boot) } > extmem
}
4.5 Les fichiers batch pour le modular design
################ Fichier batch copy_ucf_ngc
####################
copy ..\ISE\top.ucf .\Top\Initial\top.ucf
copy ..\ISE\top.ucf .\Top\Assemble\top.ucf
copy ..\ISE\top.ucf .\Modules\compteur_lent\top.ucf copy
..\ISE\top.ucf .\Modules\clignotant\top.ucf
copy ..\ISE\top.ucf .\Modules\ppc_subsystem\top.ucf copy
..\ISE\top.ucf .\Modules\compteur_rapide\top.ucf copy ..\ISE\top.ngc
.\Top\Initial\top.ngc
copy ..\ISE\top.ngc .\Top\Assemble\top.ngc
copy ..\ISE\top.ngc .\Modules\compteur_lent\top.ngc copy
..\ISE\top.ngc .\Modules\compteur_rapide\top.ngc copy ..\ISE\top.ngc
.\Modules\clignotant\top.ngc
copy ..\ISE\top.ngc .\Modules\ppc_subsystem\top.ngc
copy ..\ISE\compteur.ngc .\Modules\compteur_lent\compteur.ngc
copy ..\ISE2\compteur.ngc .\Modules\compteur_rapide\compteur.ngc
copy ..\ISE3\compteur.ngc .\Modules\clignotant\compteur.ngc copy
..\ISE4\compteur.ngc .\Modules\clignotant_rap\compteur.ngc
copy ..\ISE\system.ngc .\Modules\ppc_subsystem\system.ngc
pause
################ Fichier batch build_ppc_subsystem
###############
copy ..\ISE\top.ucf .\Modules\ppc_subsystem\top.ucf copy
..\ISE\top.ngc .\Modules\ppc_subsystem\top.ngc cd .\Modules\ppc_subsystem
.\active.bat
################ Fichier batch build_compteur_lent
#####################
copy ..\ISE\top.ucf .\Modules\compteur_lent\top.ucf copy
..\ISE\top.ngc .\Modules\compteur_lent\top.ngc
copy ..\ISE\compteur.ngc .\Modules\compteur_lent\compteur.ngc cd
.\Modules\compteur_lent
.\active.bat
pause
############# Fichier batch build_compteur_rapide
################ copy ..\ISE\top.ucf .\Modules\compteur_rap\top.ucf
copy ..\ISE\top.ngc .\Modules\compteur_rap\top.ngc
copy ..\ISE2\compteur.ngc .\Modules\compteur_rap\compteur.ngc
cd .\Modules\compteur_rap
.\active.bat
pause
################ Fichier batch build_clignotant_lent
################### copy ..\ISE\top.ucf
.\Modules\clignotant\top.ucf
copy ..\ISE\top.ngc .\Modules\clignotant\top.ngc
copy ..\ISE3\compteur.ngc .\Modules\clignotant\compteur.ngc
cd .\Modules\clignotant
.\active.bat
pause
################ Fichier batch build_clignotant_rapide
##################### copy ..\ISE\top.ucf
.\Modules\clignotant_rap\top.ucf
copy ..\ISE\top.ngc .\Modules\clignotant_rap\top.ngc
copy ..\ISE4\compteur.ngc
.\Modules\clignotant_rap\compteur.ngc
cd .\Modules\clignotant_rap .\active.bat
pause
################ Fichier active.bat du design
compteur_lent #############
ngdbuild -p xc2vp7-fg456-7 -modular module -active compteur -uc
top.ucf top.ngc compteur_lent.ngd >trace.txt map -p xc2vp7-fg456-7
compteur_lent.ngd -o compteur_map.ncd >>trace.txt
par -w -ol high compteur_map.ncd compteur_lent_map_routed.ncd
>>trace.txt
pimcreate -ncd compteur_lent_map_routed.ncd ..\..\Pims
bitgen -d -w -g ActiveReconfig:yes -b
compteur_lent_map_routed.ncd compteur_lent.bit
########### Fichier active.bat du design compteur_rapide
###############
ngdbuild -p xc2vp7-fg456-7 -modular module -active compteur -uc
top.ucf top.ngc clignotant_rapide.ngd >trace.txt map -p xc2vp7-fg456-7
clignotant_rapide.ngd -o compteur_map.ncd >>trace.txt
par -w -ol high compteur_map.ncd clignotant_rapide_map_routed.ncd
>>trace.txt
# pimcreate -ncd clignotant_rapide_map_routed.ncd ..\..\Pims
bitgen -d -w -g ActiveReconfig:yes -b
clignotant_rapide_map_routed.ncd clignotant_rap.bit
############# Fichier active.bat du design
clignotant_lent ############
ngdbuild -p xc2vp7-fg456-7 -modular module -active compteur -uc
top.ucf top.ngc clignotant.ngd >trace.txt
map -p xc2vp7-fg456-7 clignotant.ngd -o compteur_map.ncd
>>trace.txt
par -w -ol high compteur_map.ncd clignotant_lent_map_routed.ncd
>>trace.txt
# pimcreate -ncd clignotant_lent_map_routed.ncd ..\..\Pims
bitgen -d -w -g ActiveReconfig:yes -b clignotant_map_routed.ncd
clignotant.bit
pause
######## Fichier active.bat du design clignotant_rapide
##############
ngdbuild -p xc2vp7-fg456-7 -modular module -active compteur -uc
top.ucf top.ngc clignotant_rapide.ngd >trace.txt map -p xc2vp7-fg456-7
clignotant_rapide.ngd -o compteur_map.ncd >>trace.txt
par -w -ol high compteur_map.ncd clignotant_rapide_map_routed.ncd
>>trace.txt
# pimcreate -ncd clignotant_rapide_map_routed.ncd ..\..\Pims
bitgen -d -w -g ActiveReconfig:yes -b
clignotant_rapide_map_routed.ncd clignotant_rap.bit
pause
########## Fichier active.bat du module ppc_subsystem
##############
copy ..\..\..\implementation\*wrapper.ngc .\*wrapper.ngc
ngdbuild -p xc2vp7-fg456-7 -modular module -active system -uc
top.ucf top.ngc system.ngd
map -p xc2vp7-fg456-7 system.ngd -o system_map.ncd
par -w -ol high system_map.ncd system_map_routed.ncd
pimcreate -ncd system_map_routed.ncd ..\..\Pims
bitgen -d -w -g ActiveReconfig:yes system_map_routed.ncd
system.bit
############# Fichier Top/Assemble/assemble.bat du design
complet ########
ngdbuild -p xc2vp7-fg456-6 -modular assemble -pimpath ../../Pims
top.ngc
map -pr b top.ngd -o top_map.ncd top.pcf
par -w top_map.ncd top_map_routed.ncd top.pcf
bitgen -w -g startupclk:jtagclk -b top_map_routed.ncd
cptlent_systemppc.bit
pause
############# Fichier Top/Assemble updatelf.bat du
bitstream final ##########
data2mem -bm system -bt cptlent_systemppc.bit -bd
..\..\..\Running_from_BRAM\executable.elf tag bram1 -o b chargement.bit
pause
REFERENCES BIBLIOGRAPHIQUES
[1] Configuration Handbook, Volume 2. Chapitre Using
Altera Enhanced Configuration Devices, page 2-15, Aout 2005.
[2] P. Benoit et al., Architectures Reconfigurables
Dynamiquement pour Applications TSI. 3ème Colloque de CAO de
circuits et systèmes intégrés, Mai 2002, Paris.
[3] B. Blodget, P. James-Roxby, E. Keller, S. McMillan, P.
Sundararajan. «A Self-reconfiguring Platform», In
Proc. of the Intern. Conference on Field Programmable Logic and Applications
(FPL2003), Lisbon, Portugal, Sept. 2003.
[4] K. Compton, S. Hauck, Reconfigurable Computing: A
Survey of Systems and Software. ACM Computing Surveys, Vol. 34, No. 2,
June 2002, pp. 171-210.
[5] K. Danne, C. Bobda, H. Kalte. Increasing Efficiency
by Partial Hardware Reconfiguration, Case Study of a Multi-Controller
System, ERSA, 2003
[6] J-P. Delahaye. Systèmes Radio Dynamiquement
Reconfigurables sur des Architectures
Hétérogènes. Mémoire DEA SETI
Université Paris XI, septembre 2003.
[7] D. Demigny, R. Bourguiba, L. Kessal et M. Leclerc.
La reconfiguration dynamique des FPGAs: Que doit-on en
attendre? 17ème colloque GRESTI, Vannes, Septembre 1999.
[8] M. Ericson, A. Nilsson. Runtime Reconfiguration
System On a Chip. Master's Thesis in
Computer Science and
Technology. School of Information Science, Computer and Electrical Engineering,
Halmstad University.
[9] Cours Architecture des Systems Embarques de Gilliot J-M.
ENST Bretagne. [En ligne] :
http://perso-info.enst-bretagne.fr/~jgilliot/
[10] Y. Li, T. Callahan, E. Darnell, R. Harr, R. Kurkure.
Hardware-software codesign of embedded reconfigurable
architectures. Design Automation Conference, 507-512, 2000
[11] G. Meardi. FPGA-coupled Microprocessors : The challenge of
Dynamic Reconfiguration, 1998
[12] Mermoud, G., A Module-Based Dynamic Partial
Reconfiguration Tutorial. Logic Systems Laboratory, Ecole
Polytechnique Fédérale de Lausanne, November 2004
[13] S. Pillement, O. Sentieys et R. David.
Architectures Reconfigurables : un survol. LASTI - ENSSAT
26/04/2002
[14] Circuits reconfigurables:Les FPGAs, Eduardo Sanchez,
Laboratoire des Systemes Logiques, EPFL.
http://lslwww.epfl.ch/pages/teaching/cours_lsl/sl_info/12.FPGA.pdf
[15] J. Thorvinger. Dynamic Partial Reconfiguration of
an FPGA for Computational Hardware Support. Master's thesis, Lund
Institute of Technology, June 2004.
[16] A. Tisserand, Introduction aux circuits
FPGA. Arénaire INRIA LIP, Séminaire Perpignan, juin
2004
[17] Leray, P., Weiss, J., Technologies SOC (System On
Chip), Journée Recherche de Supélec Campus de Rennes le
28/02/ 2002.
[18]
http://www.xilinx.com/literature/index.htm
[19] Development System Reference Guide, Xilinx
2005.
http://toolbox.xilinx.com/docsan/xilinx7/books/data/docs/dev/dev0001_1.html
[20] Two flows for partial reconfiguration: Module based
or difference based. Application Note 290, Xilinx, 2004.
[21] Virtex-II ProTM Platform FPGAs,
«Introduction and Overview»,
http://direct.xilinx.com/bvdocs/publications/ds083-1.pdf,
current June 2003.
[22] Modular Design,
http://toolbox.xilinx.com/docsan/xilinx6/books/data/docs/dev/dev0026_7.html
[23] Virtex-II Pro and Virtex-II Pro X Platform FPGAs:
Complete Data Sheet,
http://direct.xilinx.com/bvdocs/publications/ds083.pdf
(Oct. 2005)
[24] Virtex-II Pro and Virtex-II Pro X FPGA User Guide
UG012 (v4.0), 23 March 2005.
http://direct.xilinx.com/bvdocs/userguides/ug012.pdf
[25] OPB HWICAP Product Specification DS 280
(v1.3), March 15, 2004
http://www.xilinx.com/bvdocs/ipcenter/data_sheet/opb_hwicap.pdf
[26] EDK 7.1 PowerPC Tutorial in Virtex-4 v3.0,
April 1, 2005
http://direct.xilinx.com/direct/ise7_tutorials/EDK7.1_ML403.pdf
[27] ISE 7 In-Depth Tutorial,
http://direct.xilinx.com/direct/ise7_tutorials/ise7tut.pdf
[28] Constraints Guide ISE 7.1i,
www.xilinx.com
[29] Virtex-II ProTM (P4/P7) Development Board User's Guide,
Version 4.0, June 2003.


