SECTION II. PRESENTATION DES RESULTATS
Le traitement des données se fait à l'aide du
logiciel E-views 6 et Stata 11. 2.1. STATISTIQUES
DESCRIPTIVES
Tableau 3.3. Statistiques descriptives
|
Variables
|
Obs.
|
Moyenne
|
Ecart-type
|
Minimum
|
Maximum
|
|
ROA
|
42
|
1.346623
|
1.705477
|
0.0279251
|
10.26532
|
|
TB
|
42
|
25.67214
|
0.8797342
|
23.04978
|
27.12935
|
|
RCP
|
42
|
0.1055604
|
0.0395871
|
0.0480444
|
0.1947059
|
|
RCA
|
42
|
0.4039151
|
0 .1279691
|
0.2039009
|
0.8252997
|
|
TI
|
42
|
19.22143
|
7.701033
|
9.3
|
34.59
|
|
LPIBH
|
42
|
5.151307
|
0.0504834
|
5.077958
|
5.231206
|
|
RTSB
|
42
|
4.150651
|
2.81951
|
1.479542
|
9.981854
|
|
RCB
|
42
|
0.5701738
|
0.1184107
|
0.336123
|
0.6931543
|
Au regard du tableau ci-haut, nous remarquons que le ROA a
été en moyenne positif avec un pic de 10.26532
réalisé par la BCDC en 2009 et un creux de 0.0279251
réalisé par la BIC en 2006.
En moyenne, la taille des banques est presque la même
à quelques exceptions près. La RAWBANK est la banque qui
détient la plus grande taille avec un score de 27.129 en 2012 et la
PROCREDIT BANK détient la plus faible note de 23.04978 en 2006.
Les ratios capitaux propres ont été trop
volatiles avec un pic de 0.1947 et un creux de 0.048.
Le ratio crédit accordé a été
très volatile et son écart type le prouve bien avec une valeur
maximale de 0.048 et un pic de 0.2039
Les restes des variables n'ont visiblement pas trop
changé durant la période sous étude.
Egalement pour ce qui est de l'analyse de corrélation,
il sied de signaler une absence de la multicolinéraité entre les
variables.

BIC

TMB
BIC
RAWBANK
TMB
BIC
BCDC
PROCREDIT
TMB
BIAC
BCDC
RAWBANK
Page 52
Le graphique ci-après permet de visualiser le
comportement tendanciel de la rentabilité des banques exprimée en
ROA.
Figure 3.1. Evolution de la rentabilité des
banques
BCDC

2006 2008 2010 2012
annee
ROA Fitted values
BCDC
PROCREDIT BCDC
TMB
BCDC PROCREDIT RAWBANK
PROCREDIT RAWBANK RAWBANK
BIAC BIAC RAWBANK RAWBANK BIC
BIAC BIAC
PROCREDIT
BIC
L'évolution de la rentabilité a
été presque la même dans toutes les banques excepté
la BCDC qui a connu une évolution spectaculaire durant la période
2008 et 2010 pendant la crise financière de subprime.
2.2. RESULTAT DE L'ESTIMATION38
2.2.1. Investigation
L'investigation permet de nous rassurer que nos séries
sont stationnaires et de déterminer l'ordre d'intégration. Ainsi,
les données collectées doivent être testées avant de
les soumettre à l'estimation.
BALTAGI (2001) et HSIAO (1986) indiquent que la
méthodologie des données de Panel contrôle
l'hétérogénéité individuelle, réduit
les problèmes associés avec la multicolinéraité et
les biais des estimations, comme elle spécifie une relation variable
dans le temps entre les variables indépendantes et celle
dépendante39.
38 Notons que les
estimations ont été effectuées avec le logiciel E-views 6
et STATA 11, et les outputs des estimations sont placés en
annexe.
39 MAMOGHLI C., DHOUIBI R., op cit, P26
Page 53
L'estimation par les moindres carrés ordinaires (MCO)
sur des données de panel présuppose
l'homogénéité des individus qui composent
l'échantillon, sinon les estimateurs seront biaisés.
L'hétérogénéité des valeurs
moyennes des variables explicatives et de leurs écarts-types entre les
différentes banques de l'échantillon, montre la
nécessité de tests complémentaires afin de pouvoir choisir
l'estimateur approprié.
A. Test
d'homogénéité40
L'idée du test d'homogénéité est
de vérifier si les données de Panel sont homogènes ou
hétérogènes.
L'hypothèse de recherche (H1) stipule que la structure
modèle de panel est hétérogène ou présence
d'effets par contre l'hypothèse nulle (H0) stipule la structure du
modèle de panel est homogène ou absence d'effet.
Puisque la statistique de Fisher calculée est
supérieure au Fisher lue dans la table (autrement La probabilité
critique de la statistique de Fisher (0.0000) est inférieure au seuil de
signification), nous pouvons conclure que la structure du modèle de
données panel est hétérogène.
B. test de la bonne spécification du
modèle Nous formulons comme hypothèse :
H0 : le modèle est bien spécifié ( =0) H1
: le modèle est mal spécifié ( ?0)
La probabilité associée à la statistique
de RAMSEY est supérieure à 0,05 (prob?F=0,0822). (Voir annexes
A.2.2.)
40 Ce test est également appelé test
de la structure de panel. Si la structure est hétérogène,
il est recommandé d'abandonner la spécification du modèle
de donnée panel et d'estimer, pour chaque groupe d'individus, un
modèle de MCO.
La statistique du test d'homogénéité suit
une distribution de Fisher à (N-1, NT-N-K) degré de
liberté et se calcule comme suit :
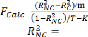
= ;
Avec R carré du modèle à effets fixes (MCO
dummy variable) =R carré du
modèle pooled (MCO empilé), m=le nombre de
variables explicatives du modèle LSDV, k : le nombre de variables
explicatives du modèle à effets fixes (LSDV), T est la taille de
l'échantillon.
Page 54
C. Le test de HAUSMAN41
Le test de HAUSMAN nous permet de discriminer les effets fixes
des effets aléatoires.
Le test de spécification de Hausman (1978) repose sur
le corps d'hypothèses suivant :
H0 : E ( ) = 0 (les estimateurs du modèle à erreurs
composées sont efficaces.)
H1 : E ( ) 0 (les estimateurs du modèle à erreurs
composées sont biaisées.)
La statistique du test est la suivante : H=
Où MEF et MEC désignent respectivement le
modèle à effet fixes et les modèle à erreurs
composées.
Etant donné que la probabilité critique
(p-value) de la statistique chi-carré (0.9191) est supérieure au
seuil de significativité de 5%, nous acceptons l'hypothèse nulle
selon laquelle il n'y a pas de différence significative entre les
coefficients estimés du modèle à effets fixes et ceux du
modèle à effets aléatoires.
Nous pouvons choisir entre le modèle à effets
fixes ou aléatoires). D'où il est intéressant de faire le
test de Breusch-Pagan pour faire discriminer entre les deux modèles.

Ho : H1 :
Où désigne la variance de l'erreur
spécifique à l'individu, )
Le test de Breusch-Pagan ou test du multiplicateur de Lagrange
permet de valider empiriquement le choix d'une structure à erreurs
composées. Le corps d'hypothèses à tester est le suivant
:
41 Cette statistique est asymptotiquement
distribuée selon une chi-deux à K degrés de
liberté, soit le nombre de facteurs variables dans le temps, introduits
dans le modèle.
Si le test est significatif (p-value < 5%), on retient les
estimateurs du Modèle à effets fixes qui sont non biaisés.
Dans le cas contraire on peut choisir soit le modèle à effets
fixes ou le modèle à effets aléatoires.
Page 55
La statistique du test est basée sur les résidus
estimés par les MCO. Elle prend la forme suivante :
Comme la probabilité du test est 0.0749 0.05, on
accepte l'hypothèse nulle.
Le test rejette la spécification d'une structure
à erreurs composées. Donc, le modèle retenu est à
effets fixes ou Last squares dummy variables.
C'est à ce titre que les tests de diagnostic concernant
la stationnarité ou test de racine unitaire seront appliqués.
Apres application des tests de racine unitaire, le tableau suivant
résume les différents résultats obtenus après la
mise en application du test de racine unitaire sur chaque variable.
Tableau 3.4. Test de la racine unitaire en données
de panel
|
VARIABLES
|
|
TESTS UTILISES
|
ORDRE D'INTEGRATION
|
CONCLUSION
|
|
ADF
|
PP
|
Levin, Lin & Chu
|
|
|
|
ROA
|
0.0047
|
0.0346
|
0.0000
|
I(0)
|
Stationnaire à niveau
|
|
TB
|
0.0007
|
0.0000
|
0.0000
|
I(0)
|
Stationnaire à niveau
|
|
RCP
|
0.3468
|
0.9407
|
0.0000
|
I(0)
|
Stationnaire à niveau
|
|
RCA
|
0.0004
|
0.0000
|
0.0000
|
I(0)
|
Stationnaire à niveau
|
|
TI
|
0.8232
|
0.7622
|
0.6256
|
I(1)
|
Non stationnaire
|
|
LPIBH
|
1.0000
|
1.0000
|
0.9931
|
I(1)
|
Non stationnaire
|
|
RTSB
|
1.0000
|
0.9190
|
1.0000
|
I(1)
|
Non stationnaire
|
|
RCB
|
0.0018
|
0.0000
|
0.0000
|
I(0)
|
Stationnaire à niveau
|
Le tableau suivant résume les différents
résultats obtenus après la mise en application du test de la
stationnarité en données de panel portant sur le test de
Augmented Duckey-Fuller, Fisher et Khi carré (ADF - Fisher Chi-square),
Phillip Perron, Fisher et Khi carré (PP - Fisher Chi-square) ; Fisher,
Levin, Lin & Chu ; Breitung ; Im, Pesaran and Shin ; Hadri sur chaque
variable.
|
|
|
Page 56
|
|
|
|
|
|
Tableau 3.5. Résultat de l'estimation
|
|
|
|
Méthodes d'estimation
|
|
Moindres carrés ordinaires (OLS)
|
Moindres carrés généralisés (GLS)
|
|
Modèle
|
(I)
|
(II)
|
(III)
|
(IV)
|
|
Régresseurs
|
|
|
|
|
|
Constante
|
-10.54
|
-211.80
|
-71.03
|
-231.35
|
|
(-0.08)
|
(-1.32)**
|
(-0.54)
|
(-6.44)***
|
|
Taille de la banque
|
0.49
|
-2.67
|
-0.44
|
-2.69
|
|
(0.78)*
|
(-1.48)**
|
(-0.41)
|
(-10.07)***
|
|
Capitaux propres
|
-4.94
|
-10.62
|
-4.85
|
-10.61
|
|
(-0.72)
|
(-0.99)*
|
(-0.56)
|
(-6.64)***
|
|
Crédits accordés
|
-1.55
|
-2.26
|
-1.46
|
-2.09
|
|
(-0.69)
|
(-0.78)*
|
(-0.57)
|
(-6.13)***
|
|
Taux d'inflation
|
0.07
|
0.17
|
0.09
|
0.18
|
|
(1.10)*
|
(2.29)***
|
(1.62)**
|
(8.93)***
|
|
Croissance économique
|
0.28
|
55.33
|
16.66
|
59.34
|
|
(0.01)
|
(1.43)**
|
(0.56)
|
(7.11)***
|
|
Taille du secteur bancaire
|
0.20
|
-0.34
|
-0.25
|
-0.43
|
|
(-0.37)
|
(-0.71)*
|
(-0.52)
|
(-4.34)***
|
|
concentration bancaire
|
-2.41
|
-5.55
|
-3.33
|
-6.61
|
|
(-0.29)
|
(-0.74
|
(-0.46)
|
(-4.58)***
|
Obs. 42 42 42 42
Note : les valeurs entre parenthèses renvoient aux
statistiques de t de Student. * seuil de signification : 10% ;** seuil de
signification : 5% ; *** seuil de signification : 1%. I et II représente
respectivement l'estimation du modèle sans effet, à effets fixes
et aléatoires. IV représente l'estimation du modèle
à effets fixes sur GLS ou la methode SUR (Seemingly Unrelated
Regression connu également sous le nom de la régression multi
variée ou la méthode de Zellner).
| 

