|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
46
CHAPITRE V: RESULTATS ET DISCUSSIONS
Dans cette étape on portera particulièrement notre
attention sur les tests réalisés ainsi que les résultats
obtenus. Elle consistera donc à analyser et interpréter nos
résultats obtenus.
1- RESULTATS
Ø Entrainement 1
nombre d'époque 05 et 2205 images pour 108 sujets
Constat

Figure 34 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 1er
Entrainement.
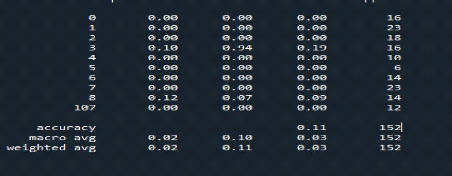
Figure 1 : Moyenne performance 0.11
1er Entrainement
Ø Entrainement 2
Nombre d'époque 10 et 2205 images d'empreinte digitale
pour 108 sujets
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
47
Constat
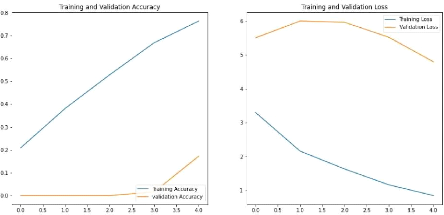
Figure 3 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 2ème
Entrainement.

Figure 4 : Moyenne performance 0.1720 2eme
entrainement
Ø Entrainement 3
Nombre d'époque 20 et 756 images d'empreinte digitale
pour 108 sujets
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
48
Constat

Figure 3 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 3ème
Entrainement.
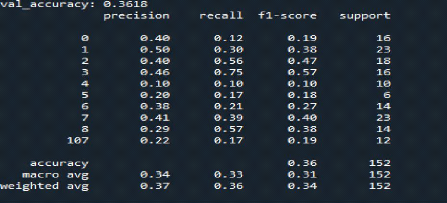
Figure 4 : Moyenne performance 0.3618
Ø
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
63
Entrainement 4
Nombre d'époque 30 et 3000 images d'empreinte digitale
pour 108 sujets Constat

Figure 5 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 4ème
Entrainement.

Figure 5 :Moyenne performance 0.9748
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
64
64
65
II. DISCUSSIONS
Ø 1er entrainement
Après l'analyse du résultat obtenu, On constate
que la précision de l'apprentissage et de test n'est pas performante.
Ø 2ème entrainement
Après l'analyse du résultat obtenu, On constate
qu'avec un nombre limité d'époques et avec une quantité
insuffisante de données notre modèle de
classification d'iris n'est pas performant et donne des
prédictions avec des probabilités proches de 0 ou même
égale à 0 pour certains sujets.
Ø 3ème entrainement
Après l'analyse du résultat obtenu, nous avions
essayé de mettre les mêmes données
précédentes, On constate que plus la quantité
d'information pour l'apprentissage est basse plus le model est mal
entrainé et ne pourra classifier les empreintes digitales.
Ø 4ème entrainement
Après l'analyse du résultat obtenu, nous
observons que la précision de l'apprentissage et de test augmente avec
le nombre d'époque, ce qui signifie qu'à chaque époque le
model apprend plus. Alors nous devons augmenter le nombre d'époque et
des images pour avoir de meilleures performances.
Afin d'avoir une meilleure performance, nous avions
trouvé mieux d'effectuer plusieurs tests. A la suite de ces tests nous
avions obtenu une meilleure performance possible.
Ø Après l'analyse du résultat
obtenu dans la Figure, On constate que malgré qu'on ait
une quantité d'informations suffisante pour
l'apprentissage et que nous donnons moins d'époque au modèle pour
son apprentissage, nous remarquons que le modèle n'est pas
performant.
Le choix d'avoir effectué plusieurs tests
d'entraînement aura donc permis de récupérer le meilleur
modèle possible qui est celui du dernier entrainement avec une
performance de 0.97.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
| 

