|
|
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR ET DE LA RECHERCHE
SCIENTIFIQUE
|
Année académique
2019-2020
|
|
oire de Master option Bases de Données et
Génie
RÉPUBLIQUE DE CÔTE D'IVOIRE
UNION - DISCIPLINE - TRAVAIL
|
|
|
|
|
UNIVERSITE FELIX HOUPHOUET BOIGNY
UFR de Mathématiques et Informatique
MEMOIRE DE MASTER
Présenté
à
L'UNIVERSITÉ FÉLIX HOUPHOUËT
BOIGNY
Mention : Informatique
Spécialité
: Bases de Données et Génie
Logiciel
par
DASSE Jean-Edmond
SUR LE SUJET :
ETUDE DES METHODES DE
RECONNAISSANCE D'EMPREINTE DIGITALE
Soutenu le 09/03/2021
Devant le jury composé de :
Président : Dr COULIBALY Adama Maitre de
conférences, UFRMI, UFHB, Abidjan
Superviseur : Pr ADOU Kablan Jérôme Professeur
Titulaire, UFRMI, UFHB, Abidjan
Directeur : Dr MAMADOU Diarra Maître-Assistant, UFRMI,
UFHB, Abidjan
UNIVERSITE FELIX HOUPHOUËT-BOIGNY
UFR
Mathématiques et Informatique
MASTER
Pour obtenir le grade de
MASTER EN BASE DE DONNEES ET GENIE LOGICIEL (BDGL)
DE
L'UNIVERSITÉ FÉLIX HOUPHOUËT-BOIGNY
Présenté par
DASSE Jean-Edmond
Sur le sujet :
ETUDE DES METHODES DE RECONNAISSANCE
D'EMPREINTE DIGITALE
Soutenu le 09/03/2021
Devant le jury composé de :
Président : Dr COULIBALY Adama Maitre de
conférences, UFRMI, UFHB, Abidjan
Superviseur : Pr ADOU Kablan Jérôme Professeur
Titulaire, UFRMI, UFHB, Abidjan
Directeur : Dr MAMADOU Diarra Maître-Assistant, UFRMI,
UFHB, Abidjan
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
I
DEDICACE
A
Mon Dieu, le Dieu d'Isaac, le Dieu d'Abraham, le Dieu de Jacob
par son fils notre Seigneur Jésus Christ celui qui m'a envoyé
ici...
Mes parents et mes collaborateurs de service sans oublier ma
hiérarchie qui m'ont toujours soutenu.
Merci au Ministre de l'Enseignement Supérieur et de la
Recherche Scientifique de Côte d'Ivoire pour ses conseils,
Merci au Président de l'Université Felix
Houphouët Boigny,
Merci Au Directeur des Affaires financières et moyens
généraux de l'Université Félix Houphouët
Boigny,
Merci au Contrôleur Budgétaire de
l'Université Félix Houphouët Boigny, Merci à L'Agent
Comptable de l'Université Félix Houphouët Boigny,
Merci aux différents sous -directeurs de la
comptabilité et du Budget de l'Université Félix
Houphouët Boigny,
Merci à toute l'équipe de la DAFMG.
Mme Monsan - Ma deuxième maman conseillère
Interpol
Mon épouse DASSE née TAFFA Tadjuideen Samira et
nos enfants Ariella et Khalida pour mon indisponibilité pendant
l'élaboration de ce travail. A mes collègues de bureau pour leur
soutien.
A toux ceux que nous aimons et qui ne manquent de nous rendre
cet amour, que vous trouviez en cette oeuvre toute notre gratitude pour vos
efforts consentis à notre égard.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
II
REMERCIEMENTS
Nos remerciements vont à l'endroit de toute
l'administration et les enseignants de l'UFR Mathématiques et
Informatique (UFR MI). Ils ont été les canaux par lesquels le
savoir et le savoir-faire nous ont été transmis.
Nous tenons à remercier particulièrement :
M. MAMADOU DIARRA, Maitre-Assistant, UFRMI, Université
Félix Houphouët-Boigny (UFHB), notre Directeur de mémoire
qui n'a ménagé aucun effort pour que ce travail arrive à
son terme ;
M. ADOU JEROME KABLAN, Professeur Titulaire UFR MI, mon
superviseur pour ce travail, pour mon insertion, sa facilité jusqu'
à mon arrivée ici devant vous ;
M. MONSAN, Professeur Titulaire UFR MI, Mon doyen qui par sa
sagesse a su m'encadrer ; M. COULIBALY ADAMA, Maitre de Conférences UFR
MI, qui a su augmenter ma foi ; M. AYIPKA, UVCI, Assistant UVCI qui nous a
toujours montré la route ;
Mme OSSAIN née Bah Koulaï Joëlle, UFRMI,
Secrétariat, vraiment merci pour la routine car sans vous vraiment...Que
Dieu bénisse vos enfants et générations ;
A toute l'équipe et Professeur de l'UFRMI.
Nos remerciements à tous ceux qui, d'une manière
ou d'une autre ont contribué à notre épanouissement et
à la réalisation de ce travail que nous aurions omis de citer.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
III
AVANT-PROPOS
Née de l'ex-FAST (Faculté des Sciences et
Techniques) suite à une réforme de l'enseignement
supérieur, l'Unité de Formation et de Recherches de
Mathématiques et Informatique (UFRMI) de l'Université
Félix Houphouët-Boigny (ex-Université de Cocody), a pour
mission de former des chercheurs et des ingénieurs opérationnels.
L'objectif visé est de permettre aux étudiants de répondre
d'une part aux exigences du monde de la recherche (fondamentale et
appliquée) et d'autre part, aux besoins sans cesse croissants des
entreprises.
L'UFRMI, à l'instar des autres UFR de
l'Université Felix Houphouët-Boigny, s'est inscrite depuis la
rentrée académique 2012-2013 dans le système LMD
(Licence-Master-Doctorat).
C'est dans ce cadre qu'elle a ouvert des Masters de recherches
et professionnels pour réaliser ses missions de formation et de
recherche. Au nombre de ces masters se trouve le Master Bases de Données
et Génie Logiciel (BDGL) à la suite duquel nous avons produit ce
travail.
A la fin de notre formation de Master BDGL, nous devons
soutenir un mémoire pour l'obtention du diplôme de Master. C'est
conformément à cette exigence que nous avons travaillé
dans le laboratoire de Mathématiques appliquées et informatique
de l'UFRMI.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
IV
SOMMAIRE
DEDICACE I
REMERCIEMENTS II
AVANT-PROPOS III
LISTE DES FIGURES V
ABREVIATIONS VII
RESUME IX
ABSTRACT X
INTRODUCTION GENERALE 1
ETAT DE L'ART 2
CHAPITRE I : LA BIOMETRIE 3
CHAPITRE II : EMPREINTE DIGITALE 14
I- GENERALITES 14
CHAPITRE III : MACHINE LEARNING 21
CHAPITRE IV: MATERIELS ET METHODES 32
CHAPITRE V: RESULTATS ET DISCUSSIONS 46
CONCLUSION 64
CONCLUSION ET PERSPECTIVES 66
REFERENCES BIBLIOGRAPHIQUES 67
TABLE DES MATIERES 70
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
V
VI
LISTE DES FIGURES
Figure 1.1: Système biométrique basé sur les
empreintes digitales 7
Figure 1.2 : Le visage de l'être humain en tant que
modalité biométrique. 7
Figure 1.3 : Système biométrique basé sur
l'Iris. 8
Figure 1.4 : système biométrique basé sur
les articulations des doigts 8
Figure 1.5 : Système biométrique basé sur
les empreintes palmaires. 8
Figure 1.6 : Système biométrique basé sur la
voix 9
Figure 1.7 : Système biométrique basé sur la
signature manuscrite 9
Figure 1.8 : Système biométrique basé sur la
frappe dynamique sur le clavier
I.8.4. Démarche 9
Figure 1.9 : Système biométrique basé sur la
démarche. 10
Figure 1.10 : Système biométrique basé sur
les veines de la main 10
Figure 1.11 : Système biométrique basé sur
l'ADN 10
Figure 1.12 : Système biométrique basé sur
le thermo-gramme facial 11
Figure 1.13: Les minuties 14
Figure 1.14 : Reconnaissance des Empreintes Digitales 14
Figure 1.15 : Exemple des catégories principales des
empreintes digitales 15
Figure 1.16 : Différentes formes de minuties 16
Figure 1.17 : Les points singuliers d'une empreinte 16
Figure 1.18 : Diagramme des différentes étapes d'un
système de reconnaissance
d'empreinte digitale 17
Figure 1.19 : Architecture
générale d'un système complet de reconnaissance
d'empreintes 19
Figure 1.20 : Architecture de réseaux 20
Figure 1.21: À travers un processus d'autoapprentissage
23
Figure 1.22: Couche de réseau de neurone 26
Figure 1.23 : La méthode de k-fold 28
Figure 1.24 : Support SVM 29
Figure 1.25 : Schéma de l'algorithme de gradient 29
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
Figure 1.26 : Schéma forêt aléatoire 30
Figure 1.27 : Logo de spyder 33
Figure 1.28 : Environnement Python /spyder 33
Figure 1.29 : Base de données SOCOFING (empreinte
digitale d'individu) 37
Figure 1.30 : les deux parties de l'architecture des
réseaux de neurones convolutifs 39
Figure 1.31 : Définition du modèle 42
Figure 1.32: La compilation 43
Figure 1.33 : l'entrainement des cas 43
Figure 1.34 : Performance par rapport aux jeux
d'entraînement et validation
à gauche et Erreur par rapport aux jeux
d'entraînement et validation à droite 46
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
VII
ABREVIATIONS
3D : 3 Dimensions
ADN : Acide Désoxyribo Nucléique
COO : Conception Orientée Objet
ISCI : Institut des Sciences Internationales
IRD : Institut de Recherche pour le
Développement
JADE : Java Agent DEvelopment framework
LED : Light-Emetting Diode
NGS : Next Generation Sequencing
DP : Deep Learning
OMT : Object Modeling Technique
OOD : Object Oriented Design
OOSE : Object Oriented Software Engineering
PCR : Polymerase Chain Reaction
RAM
: Random Access Memory
RMN : Résonance Magnétique
Nucléaire SMA : Système Multi Agents
SNP : Single Nucleotid
Polymorphism
UML : Unified Modeling Language
US : United State
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
IX
RESUME
Notre objectif est de mettre en oeuvre un système de
reconnaissance d'individus à base d'empreintes digitales en utilisant
les méthodes du deep learning.
Le travail s'est focalisé autour des points suivants :
premièrement, nous avons préparé la base de données
: des empreintes digitales. Une fois le traitement préliminaire sur les
empreintes digitale est effectué, les points caractéristiques de
l'empreinte digitale dites minuties ont été localisés et
classifiés. Dans une dernière étape l'identification des
individus est réalisée en utilisant une classification à
base d'un réseau de neurones : les réseaux de neurones
convolutionnels.
Mots clés : Reconnaissance d'empreintes digitales,
réseau de neurones, machine learning.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
X
ABSTRACT
Our goal is to implement a fingerprint-based individual
recognition system using machine learning methods.
The work focused on the following points : first, we prepared
the database: fingerprints. Once the preliminary processing on the fingerprints
is carried out, the characteristic points of the fingerprint called minutiae
have been located and classified. In a final step, the identification of
individuals is carried out using a classification based on a neural network :
convolutional neural networks.
Key words: Fingerprint recognition, neural network, machine
learning.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
1
INTRODUCTION GENERALE
De nos jours on parle de plus de l'insécurité
dans divers secteurs ainsi que des moyens informatiques à mettre en
oeuvre pour contrer cette tendance : le contrôle d'accès aux
ordinateurs, l'e-commerce, les opérations bancaires basées sur
l'identification du demandeur, etc. Il existe traditionnellement deux
manières d'identifier un individu. La première méthode est
basée sur une connaissance à priori de la personne telle que la
connaissance de son mot de passe. La seconde méthode est basée
sur la possession d'un objet. Il peut s'agir d'une pièce
d'identité, d'une clé, d'un badge, etc. Ces deux modes
l'identification peuvent être utilisée de manière
complémentaire afin d'obtenir une sécurité accrue.
Cependant, elles ont chacune leurs faiblesses. Dans le premier cas, le mot de
passe peut être oublié par son utilisateur ou bien deviné
par une autre personne. Dans le second cas, le badge, la pièce
d'identité ou la clé peut être perdu ou volé. La
biométrie possède des applications très
intéressantes dans le domaine de la sécurité. Pour
remédier à ces inconvénients, notre méthode sera
une contribution qui permettra d'optimiser en utilisant les méthodes du
deep learning. Notre étude sera structurée comme suit :
1. Dans le premier chapitre nous verrons quelques notions de la
biométrie
2. Dans le deuxième chapitre nous parlerons de
l'empreinte digitale
3. Dans le troisième chapitre nous présenterons
les différentes composantes du Machine learning
4. Dans la quatrième partie nous verrons les
différentes Méthodes d'extractions et de détections de
l'empreinte digitale.
5. Dans la cinquième partie nous donnerons les
différents résultats et interprétations de notre
étude.
En définitive, la conclusion générale
résumera notre contribution et donnera quelques perspectives sur les
futurs travaux.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
ETAT DE L'ART
2
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
3
CHAPITRE I : LA BIOMETRIE I-
GÉNÉRALITÉS
La biométrie est une alternative aux deux
précédents modes d'identification. Elle consiste à
identifier une personne à partir de ses caractéristiques
physiques ou comportementales. Le visage, les empreintes digitales, l'iris,
etc. sont des exemples de caractéristiques physiques. La voix,
l'écriture, le rythme de frappe sur un clavier, etc. sont des
caractéristiques comportementales. Les systèmes
biométriques sont de plus en plus utilisés depuis quelques
années. L'apparition de l'ordinateur et sa capacité à
traiter et à stocker les données ont permis la création
des systèmes biométriques informatisés. Il existe
plusieurs caractéristiques physiques uniques pour un individu, ce qui
explique la diversité des systèmes appliquant la biométrie
:
» La reconnaissance de l'Iris.
» La reconnaissance de Visages.
» La reconnaissance des Empreintes digitales.
» La reconnaissance de la Rétine.
» La reconnaissance de la Main.
» La reconnaissance Vocale.
» La reconnaissance de la dynamique de Signature.
Nous vous présenterons premièrement la
biométrie de manière générale et
deuxièmement de manière spécifique celle de l'empreinte
digitale.
II - DEFINITION DE LA BIOMETRIE
Le terme "biométrie" provient des mots grecs «
bios » qui veut dire la vie et du mot « métrique » qui
signifie mesure. Donc, La biométrie est une technologie
permettant la reconnaissance instantanée d'un individu par la mesure de
ses caractéristiques biologiques (les empreintes digitales, l'iris, les
traits du visage, etc) ou de ses caractéristiques comportementales
(reconnaissance vocale, la signature, la démarche) ou encore
morphologique uniques avec un haut degré de fiabilité. Cette
technologie de pointe est devenue en quelques années le moyen le plus
fiable d'identification d'une personne et elle vient remplacer ou renforcer les
dispositifs à clé ou à badges pouvant présenter des
failles en matière de sécurité. L'avantage de
l'identification biométrique est que chaque individu a ses propres
caractéristiques physiques qui ne peuvent être changées,
perdues ou volées.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
4
III - LES DIFFERENTES ANALYSE DE LA BIOMETRIE
La biométrie est basée sur l'analyse de
données liées à l'individu et peut être
classée en trois grandes catégories :
? L'analyse morphologique : les empreintes digitales, l'iris,
la forme de la main, les traits du visage, le réseau veineux de la
rétine.
? L'analyse biologique : l'ADN, le sang, la salive, l'urine,
l'odeur, la thermographie.
? L'analyse comportementale : la reconnaissance vocale, la
dynamique de frappe au clavier, la dynamique de signature, la manière de
marcher. [5]
III.1. Les caractéristiques biométriques
Les caractéristiques d'un système basé sur
la biométrie doivent être à la fois [1] [2]. Universelles :
pour être utilisables par tous
Ø Uniques : pour distinguer les personnes sans
équivoque
Ø Invariables : stables et invariantes au cours du temps
pour permettre une utilisation tout au long de la vie
Ø Enregistrables : possibilité d'enregistrer
les caractéristiques d'un individu à l'aide d'un capteur
approprié qui ne cause aucun dérangement pour l'individu (la
collecte).
Ø Mesurable : pour permettre la comparaison
III.2. Les systèmes biométriques
Un système biométrique est un système de
reconnaissance d'individus qui permet d'identifier une personne sur la base de
ses caractères physiologiques ou comportementaux [3]. Selon le contexte
de l'application, un système biométrique comporte toujours deux
phases de fonctionnement :
III.2.1. La phase d'enrôlement ou d'apprentissage
Cette phase consiste à créer un modèle
biométrique d'un individu qui doit être une
référence pour la phase de reconnaissance. Pour ce faire, les
caractéristiques biométriques de l'individu sont mesurées
par un capteur biométrique, puis représentées sous forme
numérique et enfin stockées dans une base de données. Pour
assurer une certaine puissance du système aux variations temporelles de
données, plusieurs échantillons d'acquisitions de la même
donnée
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
5
peuvent être réalisés. Le traitement
lié à l'enrôlement n'a pas de contrainte de temps,
puisqu'il s'effectue « hors-ligne » [4].
III.2.2. La phase de reconnaissance
La reconnaissance peut être une vérification ou une
identification : III.2.2.1. Le mode vérification ou
d'authentification
Dans la vérification ou l'authentification, Aussi
appelée comparaison 1 pour 1, l'authentification répond à
la question « Êtes-vous la personne que vous prétendez
être ? ».
L'identité de la personne est supposée, ses
données biométriques sont comparées à celles
enrôlées auparavant. Autrement dit Le système
biométrique demande à l'utilisateur son identité et essaye
de répondre à la question, « est-ce la personne X ?».
Dans une application de vérification, l'utilisateur annonce son
identité par l'intermédiaire d'un mot de passe, d'un
numéro d'identification, d'un nom d'utilisateur ou la combinaison de
toutes les trois.
Le système sollicite également une information
biométrique provenant de l'utilisateur et compare la donnée
caractéristique obtenue à partir de l'information entrée
enregistrée correspondante à l'identité
prétendue.
C'est une comparaison un à un. Le système
trouvera ou ne trouvera pas de correspondance entre les deux. La
vérification est communément employée dans des
applications de contrôle d'accès et de paiement par
authentification [5].
III.2.2.2. Le mode d'identification
Avec l'identification ou la reconnaissance aussi
appelée comparaison 1 pour n (c'est une comparaison un à
plusieurs), l'identification répond à la question «
Êtes-vous dans la base de données ? ». Les données
biométriques de la personne sont comparées à l'ensemble
des données biométriques de personnes enrôlées dans
une base de données spécifique. Autrement dit le système
biométrique pose et essaye de répondre à la question
« qui est la personne X ?».
III.3. Processus
Tout système biométrique comporte deux processus
qui se chargent à réaliser les opérations d'enregistrement
et de tests :
Processus d'enregistrement : Ce processus a
pour but d'enregistrer les caractéristiques des utilisateurs dans la
base de données.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
6
Processus de tests (identification
/vérification) : Ce processus réalise l'identification
ou la vérification d'une personne.
Dans chacun des deux processus précédents, le
système exécute quatre opérations fondamentales, à
savoir [1]:
L'acquisition : Cette phase consiste
à utiliser un capteur pour acquérir une caractéristique
spécifique de l'individu, plusieurs processus peuvent être
utilisés
pour l'acquisition tels que : le microphone dans le cas de la
voix.
L'extraction : Après l'acquisition
d'une image, nous réalisons l'extraction des
caractéristiques dont le processus d'authentification a besoin. Donc, ce
module sert à traiter l'image afin d'extraire uniquement les
caractéristiques biométriques, sous forme d'un vecteur, qui
peuvent être ensuite utilisées pour reconnaitre les personnes.
La classification (comparaison) : En
examinant les modèles stockés dans la base de données
(vecteurs), les caractéristiques biométriques extraites sont
comparées avec ce vecteur et en marquant le degré de similitude
(différence ou distance).
La décision : En ce qui concerne
l'authentification, la stratégie de décision nous permet de
vérifier l'identité affirmée par un utilisateur ou
déterminer l'identité d'une personne basée sur le
degré de similitude entre les caractéristiques extraites et le(s)
vecteur(s) stocké(s).
III.4. Les principaux avantages de biométrie
Ø Un système simple à installer et à
utiliser : quel que soit le mode d'authentification
choisi, reconnaissance de l'empreinte digitale, du
réseau veineux, faciale...un bref passage rapide du doigt ou du visage
devant ou sur le lecteur suffit à détecter la personne et
à l'authentifier.
Ø Une sécurité renforcée et
dissuasive
Ø Vol, copie, oubli et perte impossible : contrairement
aux codes, badges et autres clés, la biométrie supprime tous les
risques connus
III.5 La biométrie physique
La reconnaissance des individus par empreintes digitales est
la technique biométrique la plus utilisée. Les empreintes
digitales sont composées de lignes localement parallèles
présentant des points singuliers (minuties) et constituent un motif
unique, universel et permanant, comme montré
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
7
dans la Figure 1.1. Les lecteurs d'empreintes
digitales scannent puis relèvent des éléments permettant
de différencier les empreintes. Il existe plusieurs types de minuties.
Ce type de technique biométrique est utilisé par les institutions
financières pour leurs clients et se

Figure 1.1: Système biométrique
basé sur les empreintes digitales III.5.1. Visage
Nos visages sont des objets complexes avec des traits qui peuvent
varier dans le temps, comme montré dans la Figure 1.2.
L'écart entre les deux yeux, l'écartement des narines ou encore
la largeur de la bouche peuvent permettre d'identifier un individu. Cette
méthode doit pouvoir tenir compte de certain changement de la
physionomie (lunettes, barbe, chirurgie esthétique) et de
l'environnement (conditions d'éclairage). Parfois, il est impossible de
différencier deux jumeaux

Figure 1.2 : Le visage de
l'être humain en tant que modalité biométrique.
1.6 Iris
L'iris est une région sous forme d'anneau, située
entre la pupille et le blanc de l'oeil, elle est
unique. L'iris a une structure extraordinaire et offre de
nombreuses caractéristiques de texture qui sont uniques pour chaque
individu. La reconnaissance de l'iris a été
développée dans les années 80, elle est donc
considérée comme une technologie récente. L'image de
l'iris est capturée par un appareil qui contient une caméra
infrarouge, lorsque la personne se place à une
courte distance de l'appareil (Figure 1.3)
[8].

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
8
Figure 1.3 : Système biométrique
basé sur l'Iris. 1.7. Empreintes des articulations des
doigts
C'est une technologie biométrique basée sur la
surface arrière du doigt, elle contient des caractéristiques
distinctives telles que les lignes principales, les lignes secondaires et les
crêtes, qui peuvent être extraites à partir des images
à basse résolution (Figure 1.4). La main
contient plusieurs doigts, pour cela, il faut conserver les informations
à

Figure 1.4 : système biométrique
basé sur les articulations des doigts. 1.8. Empreinte
palmaire
Cette technique utilise la surface intérieure de la paume
pour l'identification et/ou la vérification des personnes
(Figure 1.5). Elle est bien adaptée pour les
systèmes à moyenne sécurité telle que le
contrôle d'accès physique ou logique [7]

Figure 1.5 : Système biométrique
basé sur les empreintes palmaires. I.8.1. Biométrie
comportementale
I.8.2. Voix
La voix humaine varie d'une personne à une autre et peut
se constituer de composantes
physiologiques et comportementales. L'identification par la voix
est basée sur la forme et la taille
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
des appendices (bouche, cavités nasales et les
lèvres) et utilisées dans la synthèse du son [4]. La
reconnaissance des locuteurs est plus utilisée par les
téléphones, les corps policiers, les hôpitaux...etc.
(Figure 1.6).

Figure 1.6 : Système biométrique
basé sur la voix.
C'est une écriture personnelle d'un individu
(Figure 1.7), la vérification de la signature est
basée sur deux modes :
· Mode statique : la vérification de la signature
statique met l'accent sur les formes géométriques de la
signature, dans ce mode, en générale, la signature est
normalisée à une taille connue ensuite décomposer en
élément simple.
· Mode dynamique : il utilise les caractéristiques
dynamiques telles que l'accélération, la vitesse et les profils
de trajectoire de la signature [7]

Figure 1.7 : Système biométrique
basé sur la signature manuscrite
I.8.3. Frappe dynamique sur le clavier
C'est un système de reconnaissance d'un individu
basé sur la manière de ses écritures par un dispositif
logiciel qui calcule la vitesse de la frappe, la suite des lettres, le temps de
frappe et la pause entre chaque mot [4]. (Figure 1.8).

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
Figure 1.8 : Système biométrique
basé sur la frappe dynamique sur le clavier I.8.4. Démarche
Chaque personne a une façon particulière de marche, nous pouvons
identifier les individus à partir de la nature du mouvement des jambes,
des bras et des articulations ou le mouvement spécial obtenu par une
caméra vidéo afin de l'envoyer à un ordinateur pour
l'analyse afin de déterminer la vitesse et l'accélération
de chaque individu [4]. (Figure 1.9).

Figure 1.9 : Système biométrique
basé sur la démarche.
I.8.4. Biométrie Biologique I.8.4.1. Veines de la
main
Les veines de la main sont des réseaux qui varient
d'une personne à une autre (Figure 1.10). L'analyse de
cette différence permet de maintenir des points pour différencier
une personne à une autre.

10
Figure 1.10 : Système biométrique
basé sur les veines de la main. I.8.4.2. L'analyse de
l'ADN
L'analyse des empreintes génétiques est une
méthode extrêmement précise pour déterminer
l'identité de la personne. Il est impossible de trouver deux personnes
qui ont le même ADN. Cette modalité possède l'avantage
d'être unique et permanente durant toute la durée de vie [7].
(Figure 1.11).

Figure 1.11 : Système biométrique
basé sur l'ADN.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
11
I.8.4.3. Thermo gramme faciale
La quantité de la chaleur émise par les
différentes parties du visage caractérise chaque individu
(Figure 1.12). Elle dépend de la localisation des
veines mais aussi de l'épaisseur du squelette, la quantité de
tissus, de muscles, de graisses, etc. Contrairement à la reconnaissance
de visage, la chirurgie plastique n'a que peu d'influence sur les
thermo-grammes faciaux. Pour capturer l'image, il est possible d'utiliser un
appareil photo ou une caméra numérique dans le domaine de
l'infrarouge. La capture peut se faire dans n'importe quelle condition
d'éclairage et même dans le noir complet ce qui est un avantage
supplémentaire par rapport à la reconnaissance de
visage classique [7].

Figure 1.12 : Système biométrique
basé sur le thermo-gramme facial. I.9. Les Applications de la
biométrie
On peut distinguer quatre grands types d'applications de la
biométrie le contrôle d'accès (access control),
l'authentification des transactions (transactions authentication), la
répression (law enforcement) et la personnalisation
(personalization).
I.9.1. Contrôle d'accès
Le contrôle d'accès peut être
lui-même subdivisé en deux sous catégories : le
contrôle d'accès physique et le contrôle d'accès
virtuel. On parle de contrôle d'accès physique lorsqu'un
utilisateur cherche à accéder à un lieu
sécurisé. On parle de contrôle d'accès virtuel dans
le cas où un utilisateur cherche à accéder à une
ressource ou un service.
I.9.1.1. Contrôle d'accès
physique
Il y a longtemps, l'accès à des lieux
sécurisés (bâtiments ou salles par exemple) se faisait
à l'aide de clefs ou badges. Les badges étaient munis d'une photo
et un garde était chargé de la vérification. Grâce
à la biométrie, la même opération peut être
effectuée automatiquement de nos jours. L'une des utilisations les plus
célèbres de la géométrie de la main pour le
contrôle d'accès est le système INSPASS (Immigration and
Naturalization Service Passenger
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
12
Accelerated Service System) [10] déployé dans
plusieurs grands aéroports américains (New-York, Washington, Los
Angeles, San Francisco, etc.). Cette application permet aux passagers
répertoriés dans le système, d'éviter les files
d'attente pour le contrôle des passeports. Ceux-ci possèdent une
carte magnétique qui contient l'information sur la
géométrie de leur main. Lorsqu'ils présentent leur main au
système, celle-ci est comparée à l'information contenue
dans la carte.
I.9.1.2. Contrôle d'accès
virtuel
Le contrôle d'accès virtuel permet par exemple
l'accès aux réseaux d'ordinateurs ou l'accès
sécurisé aux sites web. Le marché du contrôle
d'accès virtuel est dominé par les systèmes basés
sur une connaissance, typiquement un mot de passe. Avec la chute des prix des
systèmes d'acquisition, les applications biométriques devraient
connaître une popularité croissante. Un exemple d'application est
l'intégration par Apple dans son système d'exploitation MAC OS 9
d'un module de reconnaissance de locuteur de manière à
protéger les fichiers d'un utilisateur, tout particulièrement
lorsque l'ordinateur est utilisé par plusieurs individus ce qui est de
plus en plus souvent le cas [11].
I.9.2. Authentification des transactions
L'authentification des transactions représente un
marché gigantesque puisqu'il englobe aussi bien le retrait d'argent au
guichet des banques, les paiements par cartes bancaires, les transferts de
fond, les paiements effectués à distance par
téléphone ou sur Internet, etc.
Mastercard estime ainsi que les utilisations frauduleuses des
cartes de crédit pourraient être réduites de 80 % en
utilisant des cartes à puce qui incorporeraient la reconnaissance des
empreintes digitales [30]. Les 20 % restants seraient principalement dus aux
paiements à distance pour lesquelles il existerait toujours un risque.
Pour les transactions à distance, des solutions sont déjà
déployées en particulier pour les transactions par
téléphone. Ainsi, la technologie de reconnaissance du locuteur de
Nuance (Nuance VerifierTM) [12] est utilisée par les clients du Home
Shopping Network, une entreprise de téléshopping, et de
Charles
I.9.3. Répressions
Une des applications les plus immédiates de la
biométrie à la répression est la criminologie. La
reconnaissance d'empreintes digitales en est l'exemple le plus connu. Elle fut
acceptée dès le début du XXe siècle comme moyen
d'identifier formellement un individu et son utilisation
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
13
s'est rapidement répandue. Il existe aussi des
applications dans le domaine judiciaire. T-Netix [13] propose ainsi des
solutions pour le suivi des individus en liberté surveillée en
combinant technologies de l'internet et de reconnaissance du locuteur.
I.9.4. Personnalisation
Les technologies biométriques peuvent être aussi
utilisées afin de personnaliser les appareils que nous utilisons tous
les jours. Cette application de la biométrie apporte un plus grand
confort d'utilisation. Afin de personnaliser les réglages de sa voiture,
Siemens propose par exemple d'utiliser la reconnaissance des empreintes
digitales [14]. Une fois l'utilisateur identifié, la voiture ajuste
automatiquement les sièges, les rétroviseurs, la climatisation,
etc.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
14
CHAPITRE II : EMPREINTE DIGITALE
I- GENERALITES
Les empreintes digitales sont le dessin formé par les
lignes de la peau des doigts, ils appelées aussi dermatoglyphes - sont
une signature que nous laissons derrière nous à chaque fois que
nous touchons un objet. Les motifs dessinés par les crêtes et plis
de la peau sont différents pour chaque individu ; c'est ce qui motive
leur utilisation par la police criminelle depuis le 19è siècle.
On distingue deux types d'empreintes : l'empreinte directe ou visible qui
laisse une marque visible à l'oeil nu et l'empreinte latente ou
invisible qui est composée de lipides, de sueur et de saletés
déposés sur un objet touché. [5] Une empreinte digitale se
compose principalement de crêtes (Ridges) et de vallées (Valleys.
C'est l'étude des minuties qui permet d'identifier de façon
certaine un individu.

Figure 1.13: Les minuties
L'empreinte digitale scientifiquement est composée des
crêtes qui contiennent des pores et des sillons, et les pores permettent
de sortir 80% eaux et 20% matières organiques, ces matières
laissent des marques sous formes des lignes.
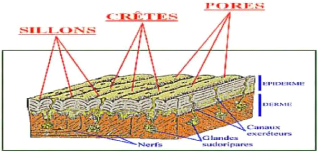
Figure 1.14 :
Reconnaissance_des_Empreintes_Digitales.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
15
16
17
18
19
20
II.1 - Les caractéristiques de l'empreinte
digitale
Une empreinte digitale est une marque laissée par les
crêtes des doigts, des mains, des orteils ou des pieds lorsqu'elles
touchent un objet.
Il en existe deux types :
· L'empreinte directe (qui laisse une marque visible) et
· L'empreinte latente (saleté, sueur ou autre
résidu déposé sur un objet).
Les empreintes digitales sont regroupées en trois
catégories principales regroupant à elles seules 95% des doigts
humains: l'arche ou l'arc (arch), le tourbillon (whorl) et la boucle (loop).
À l'intérieur de chacune de ces catégories, il y a un
très grand nombre d'éléments qui nous différencient
les uns des autres. En plus des cicatrices, il y a les fourches, les
îlots et les espaces qui donnent un caractère unique aux
empreintes latentes.
Les« boucles » constituent les motifs les plus
répandus qui représentent 60% des doigts humains : dans ce type
d'empreinte se replient sur elles même soit vers la droite, soit vers la
gauche. Viennent ensuite les « tourbillons », qui correspondent
à 30% des doigts humains : cette empreinte, dite en verticille, comprend
des lignes qui viennent s'enrouler autour d'un point, formant un genre de
tourbillon. Pour finir, les motifs les moins répandus sont « les
arches » qui regroupent seulement 5% des doigts humains : cette empreinte,
en arc, contient des lignes disposées les unes au-dessus des autres qui
forment des A.

Figure 1.15 : Exemple des catégories
principales des empreintes digitales
On différencie les motifs entre eux à l'aide de
"points singuliers" appelés "minuties" sur les boucles, tourbillons ou
arcs :
a)
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
points singuliers globaux :
- noyau ou centre : lieu de convergences de stries ; - delta :
lieu de divergences de stries ;
b) points singuliers locaux (appelés aussi minuties) :
ce sont les points d'irrégularité se trouvant sur les lignes
papillaires (terminaisons, bifurcations, ilots assimilés à deux
terminaisons, lacs).
Quelle que soit sa forme, une empreinte digitale
possède des points précis différents appelés
minuties.
On estime qu'il y a plus de cent points de convergence entre
deux empreintes identiques relevées. Souvent, ces points de convergence
sont des irrégularités sur les lignes papillaires. Les points les
plus fréquemment utilisés dans les algorithmes lors de la
comparaison sont de quatre types : les lacs, les terminaisons (à droite
et à gauche), les bifurcations (à droite et à gauche) et
les îles. Plus précisément, une minutie est un point qui se
situe sur le changement de continuité des lignes papillaires. Ce sont
grâce à elles que les empreintes digitales peuvent être
différenciées.

Figure 1.16 : Différentes formes de
minuties

Figure 1.17 : Les points singuliers d'une
empreinte
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
La validation d'une identification peut mettre en
évidence jusqu'à quatorze points de comparaison (autrement
appelés points caractéristiques ou minutie). Selon Francis
Galton, la probabilité que deux personnes aient la même empreinte
digitale est de 1 sur 64 milliard, ce qui est très faible à
l'échelle de la population humaine et donc quasiment impossible.
L'utilisation de l'empreinte digitale comme moyen d'identification d'une
personne n'est pas nouvelle. En fait, la police scientifique utilise cette
technique depuis plus de 100 ans.
Aujourd'hui, les empreintes digitales sont recueillies sur une
scène de crime et sont ensuite comparées à celles
contenues dans un serveur central.
Mémoire Online - Mise en oeuvre d'un système
distribué pour l'identification et le suivi du casier judiciaire -
Juslin TSHIAMUA MUDIKOLELE
II.2. Le Système Biométrique basé
sur l'empreinte digitale II.2.1. Définition
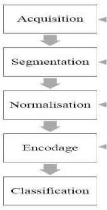
Un système de reconnaissance d'empreinte digital est un
système biométrique qui a pour fonction d'identifier les
personnes à partir des images de l'empreinte digitale. Il est
composé d'un certain nombre de sous-systèmes, qui correspondent
à chaque étape de la reconnaissance de l'empreinte digital. Une
fois l'image de l'empreinte acquise, des techniques de traitement d'image sont
utilisées pour en extraire l'empreinte, construire la signature
biométrique représentant l'empreinte digitale et finalement
trouver l'identité de l'empreinte digitale (figure). L'ensemble des
opérations de traitement d'images est divisé en 4 étapes :
la segmentation, la normalisation, l'encodage et la
classification. Le diagramme ci-dessous (figure 1.16) présente
l'architecture et le traitement séquentiel d'un système de
reconnaissance d'empreinte digitale.
Figure 1.18 : Diagramme des différentes
étapes d'un système de reconnaissance d'empreinte digitale
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
II.2.2. Acquisition
La première phase d'un système de reconnaissance
consiste à obtenir une image de l'empreinte du doigt. [36] La capture de
l'image d'une empreinte digitale consiste à trouver les lignes
tracées par les crêtes (en contact avec le capteur) et les
vallées (creux). L'image d'une empreinte est acquise par des
procèdes directs (online) ou indirects (offline). Celle acquise par des
procèdes indirects, l'est par le biais d'un objet
intermédiaire.
Il existe deux méthodes pour avoir une impression
d'empreinte indirecte :
1. L'empreinte acquise par encre (inked fingerprint) :
après l'avoir enduit d'encre, le doigt
est imprimé sur un bout de papier. Ce papier passe
ensuite au scanner standard pour être numérisé. Cette
ancienne technique a perduré pendant environ un siècle et a
été couramment utilisée dans les phases
d'enrôlement. L'image ainsi prise présente de larges crêtes
mais souffre d'une grande déformation due à la nature du
processus d'acquisition. Il est clair que cette méthode n'est pas
adaptée aux procèdes automatiques temps réel.
2. ii. Les empreintes latentes : elles sont formées
suite a une légère trace laissée sur un objet due à
la sécrétion constante de la sueur. Les services de
sécurité décèlent ce genre de détails sur
les lieux du crime à l'aide d'une poudre spéciale. Le terme
procède directe (live-scan) est un terme collectif englobant les images
d'empreintes directement obtenues sans l'étape intermédiaire de
l'impression sur du papier. En l'occurrence un dispositif spécial est
utilisé, les capteurs. [15]
II.2.3. Segmentation
La segmentation d'image est une opération de traitement
d'images qui a pour but de rassembler des pixels entre eux suivant des
critères prédéfinis. Les pixels sont ainsi
regroupés en régions, qui constituent un pavage ou une partition
de l'image. Il peut s'agir par exemple de séparer les objets du fond,
Les images d'empreintes digitales qui sont capturées à partir du
scanner, se composent de deux régions principales, la région
d'intérêt et le fond. La région d'intérêt
(ROI) est la zone de la surface du scanner qui a été en contact
avec une surface de doigt et qui comprend l'ensemble d'informations
nécessaires à la reconnaissance des empreintes digitales, tandis
que la zone restante est une région bruitée qui ne contient
aucune information importante appelée fond. La séparation de la
région d'intérêt de l'image de fond est nommée la
segmentation des empreintes digitales.
Afin d'améliorer la performance du système
d'identification, il est nécessaire, d'extraire les
minuties à partir de la région
d'intérêt.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
II.2.4. Normalisation
La segmentation de l'empreinte digitale du reste de l'image
produit, selon les images, des empreintes de tailles différentes.
L'empreinte segmentée peut être une empreinte complète ou
une fraction d'empreinte complète, de petite taille ou de grande taille.
Ainsi une comparaison entre deux empreintes de tailles différentes ne
sera possible qu'à partir d'une représentation consistante entre
toutes les images.
II.2.5. Encodage (extraction des
caractéristiques)
Dans cette étape, l'empreinte est bien segmentée
et normalisé. L'encodage consiste à extraire de l'empreinte les
caractéristiques les plus discriminantes et les plus pertinentes,
nécessaires et utiles pour son identification. Des filtres de type
passe-bande, des ondelettes, et d'autres outils peuvent ainsi être
utilisés. Le résultat obtenu peut être gardé dans
des valeurs réelles ou peut être quantifié en valeurs
discrètes. Le processus de l'encodage de l'empreinte résulte
finalement en un profil d'empreinte représentant la signature de
l'empreinte. Ce profile est unique pour chaque empreinte, insensible aux
variations de dimensions ou aux rotations crées lors de l'acquisition de
l'empreinte et sera utilisé ensuite pour la classification de
l'empreinte [17] [18].
II.2.6. Classification
Pour comparer les représentations
générées par le processus d'encodage, une métrique
qui mesure la similarité des profils d'empreintes codés est
utilisée. Idéalement si la mesure de similarité entre deux
profils d'empreintes comparés est supérieure à un certain
seuil, cela signifie que les deux profils comparés appartiennent
à des iris différents. Le cas contraire survient quand les deux
profils comparés appartiennent aux mêmes empreintes [16] [17].

Figure 1.19 : Architecture
générale d'un système complet de reconnaissance
d'empreintes.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
II.2.1.6. L'utilisation des Réseaux de Neurones
L'utilisation des réseaux de neurones (RN) pour la
classification de modèle d'empreinte digitale d'une personne se
déroule comme suit : Les empreintes détectées après
la normalisation et le prétraitement pour réduire la taille du
réseau de neurone. Alors les images sont représentées par
des matrices. Ces matrices (images) contiennent les valeurs de gris de la
texture du modèle d'empreinte. Ces valeurs sont des signaux
d'entrée pour le réseau de neurones. La structure neuronale du
réseau utilisé
par Rahib Hidayat Abiyev et Koray Altunkaya est donnée
par la figure (1.27).
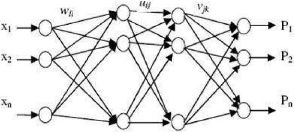
Figure 1.20 : Architecture de réseaux.
Où : x1, x2, ..., xm sont des valeurs d'entrée des
niveaux de gris qui caractérise l'information de texture de l'iris, P1,
P2, ..., Pn sont des modèles de sortie qui caractérisent
l'empreinte.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
21
22
CHAPITRE III : MACHINE LEARNING
Définition
Le Machine Learning est une technologie d'intelligence
artificielle permettant aux ordinateurs d'apprendre sans avoir
été programmés explicitement à cet effet. Pour
apprendre et se développer, les ordinateurs ont toutefois besoin de
données à analyser et sur lesquelles s'entraîner. De fait,
le Big Data est l'essence du Machine Learning, et c'est la technologie qui
permet d'exploiter pleinement le potentiel du Big Data.
Machine Learning et Big Data : définition et
explications de la combinaison (
lebigdata.fr)
https://www.lebigdata.fr/machine-learning-et-big-data
I - LES DIFFÉRENTS CATÉGORIES DE MACHINE
LEARNING Trois categories de machine learning:
3. L'apprentissage par renforcement
4. L'apprentissage supervisé et
5. L'apprentissage non supervisé
dit « très important », cela peut signifier
jusqu'à plusieurs millions d'images pour la base Image Net. C'est
à partir de cette base que l'algorithme peut apprendre ans le cadre de
l'apprentissage supervisé, la machine connaît déjà
les réponses qu'on attend d'elle. Elle travaille à partir de
données étiquetées
Cette méthode permet de réaliser deux types de
tâches :
Ces tâches consistent à attribuer une classe
à des objets. Par exemple, dans le milieu bancaire, on peut identifier
si une transaction est frauduleuse ou non frauduleuse de manière
automatique. On parle de détection d'anomalie. Dans l'industrie, on peut
déterminer si oui ou non une machine est susceptible de tomber en
panne.
Ici, on n'attribue pas une classe mais une valeur
mathématique : un pourcentage ou une valeur absolue. Par exemple, une
probabilité pour une machine de tomber en panne (15 %, 20 %, etc.)
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
ou le prix de vente idéal d'un appartement en fonction de
critères comme la surface, le quartier,
etc.
II- APPRENTISSAGE NON SUPERVISE
Une différence lorsqu'on parle du type d'apprentissage
non-supervisé, c'est que les réponses que l'on cherche à
prédire ne sont pas disponibles dans les jeux de données. Ici,
l'algorithme utilise un jeu de données non étiquetées. On
demande alors à la machine de créer ses propres réponses.
Elle propose ainsi des réponses à partir d'analyses et de
groupement de données. Pour y voir plus clair, voici des exemples de
tâches réalisables grâce à cette méthode.
Mémoire de Master option Bases de Données et Génie
Logiciel 28
Ici, on demande à la machine de grouper des objets dans
des ensembles de données les plus homogènes possibles. Cette
technique peut sembler proche de celle de la classification dans
l'apprentissage supervisé, mais à la différence de cette
dernière, les classes ne sont pas préremplies par un humain,
c'est la machine qui «invente» ses propres classes, à un
niveau de finesse pas toujours évident pour un humain. Une technique
très utile dans le marketing pour faire de la segmentation client
notamment.
1- Deep learning Définition
Le deep learning ou apprentissage profond est un type
d'intelligence artificielle dérivé du machine learning
(apprentissage automatique) où la machine est capable d'apprendre par
elle-même, contrairement à la programmation où elle se
contente d'exécuter à la lettre des règles
prédéterminées.
2 - Le fonctionnement du deep learning
Le deep Learning s'appuie sur un réseau de neurones
artificiels s'inspirant du cerveau humain. Ce réseau est composé
de dizaines voire de centaines de « couches» de neurones, chacune
recevant et interprétant les informations de la couche
précédente. Le système apprendra par exemple à
reconnaître les lettres avant de s'attaquer aux mots dans un texte, ou
détermine s'il y a un visage sur une photo avant de découvrir de
quelle personne il s'agit.

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
23
Figure 1.21: À travers un processus
d'autoapprentissage, le deep Learning est capable d'identifier un chat sur une
photo. À chaque couche du réseau neuronal correspond à un
aspect particulier de (l'image MapR, C.D, Futura).
Explications: À chaque étape,
les « mauvaises» réponses sont éliminées et
renvoyées vers les niveaux en amont pour ajuster le modèle
mathématique. Au fur et à mesure, le programme réorganise
les informations en blocs plus complexes. Lorsque ce modèle est par la
suite appliqué à d'autres cas, il est normalement capable de
reconnaître un chat sans que personne ne lui ait jamais indiqué
qu'il n'ai jamais appris le concept de chat. Les données de
départ sont essentielles : plus le système accumule
d'expériences différentes, plus il sera performant.
3-Les Réseaux de neurons artificiels
4-Définition
Un réseau de neurones artificiels ou Neural Network est
un système informatique s'inspirant du fonctionnement du cerveau humain
pour apprendre.
5-Les différents types de réseau de
neurone
Il existe de nombreux types de réseaux neuronaux, on
peut les diviser en deux grandes catégories selon la nature de leur
algorithme d'apprentissage. Les réseaux de neurones les plus populaires
sont:
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
24
- Les réseaux de neurone convolutionnels - Les
réseaux de neurone récurent - Réseau de neurone
artificiel
Ce sont des réseaux de neurones
spécialisés qui utilisent le contexte des entrées lors du
calcul de la sortie. La sortie dépend des entrées et des sorties
calculées précédemment.
Ainsi, les RNN conviennent aux applications où les
informations historiques sont importantes. Ces réseaux nous aident
à prévoir les séries chronologiques dans les applications
commerciales et à prévoir les mots dans les applications de type
chatbot. Ils peuvent fonctionner avec différentes longueurs
d'entrée et de sortie et nécessitent une grande quantité
de données.
6- Réseau de neurones de convolution -
Convolution Neural Network (CNN):
Ces réseaux reposent sur des filtres de convolution
(matrices numériques). Les filtres sont appliqués aux
entrées avant que celles-ci ne soient transmises aux neurones.
Ces réseaux de neurones sont utiles pour le traitement et
la prévision d'images.
https://moncoachdata.com/blog/comprendre-les-reseaux-de-neurones/
7- Les réseaux de neurone
récurent
Les réseaux récurrents (ou RNN pour
Récurrent Neural Networks) sont des réseaux de neurones dans
lesquels l'information peut se propager dans les deux sens, y compris des
couches profondes aux premières couches. En cela, ils sont plus proches
du vrai fonctionnement du système nerveux, qui n'est pas à sens
unique. Ces réseaux possèdent des connexions récurrentes
au sens où elles conservent des informations en mémoire : ils
peuvent Mémoire de Master option Bases de Données et Génie
Logiciel 30 prendre en compte à un instant t un certain nombre
d'états passés. Pour cette raison, les RNNs sont
particulièrement adaptés aux applications faisant intervenir le
contexte, et plus particulièrement au traitement des séquences
temporelles comme l'apprentissage et la génération de signaux,
c'est à dire quand les données forment une suite et ne sont pas
indépendantes les unes des autres. Néanmoins, pour les
applications faisant intervenir de longs écarts temporels (typiquement
la classification de séquences vidéo), cette «
mémoire à court-terme » n'est pas suffisante. En effet, les
RNNs « classiques » (réseaux de neurones récurrents
simples ou Vanilla RNNs) ne sont capables de mémoriser que le
passé dit proche, et commencent
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
25
à « oublier » au bout d'une cinquantaine
d'itérations environ. Ce transfert d'information à double sens
rend leur entrainement beaucoup plus compliqué, et ce n'est que
récemment que des méthodes efficaces ont été mises
au point comme les LSTM (Long Short Term Memory). Ces réseaux à
large « mémoire court-terme » ont notamment
révolutionné la reconnaissance de la voix par les machines
(Speech Recognition) ou la compréhension et la génération
de texte (Natural Langage Processing). D'un point de vue théorique, les
RNNs ont un potentiel bien plus grand que les réseaux de neurones
classiques : des recherches ont montré qu'ils sont « Turing-complet
» (ou Turing-complete), c'est à dire qu'ils permettent
théoriquement* de simuler n'importe quel algorithme. Cela ne donne
néanmoins aucune piste pour savoir comment les construire pour cela dans
la pratique. NB : Ne pas confondre les réseaux de neurones
récurrents avec les réseaux de neurones aléatoires (Random
Neural Network) aussi traduits par RNN. * Siegelmann, H. T. (1997). Computation
beyond the Turing limit. Neural Networks and Analog Computation, 153164 Dans le
cadre de notre étude nous utiliserons les réseaux de neurones
convolution car ils sont plus adaptés au traitement ou la manipulation
des images.
8- Les réseaux de neurones
artificiels
Un réseau de neurones artificiels est un
système de technologie de l'information basé sur le
fonctionnement du cerveau humain, dont sont équipés les
ordinateurs dotés de fonctions d'intelligence artificielle.
Mémoire de Master option Bases de Données et Génie
Logiciel 31 Les réseaux de neurones artificiels permettent aux
ordinateurs de résoudre des problèmes de façon autonome et
renforcent leurs capacités d'une manière générale.
Certains nécessitent une supervision initiale, en fonction de la
méthode d'intelligence artificielle utilisée.
9- Comment fonctionne un réseau neuronal
artificiel ?
La conception des réseaux de neurones artificiels
s'appuie sur la structure des neurones biologiques du cerveau humain. Les
réseaux de neurones artificiels peuvent être décrits comme
des systèmes composés d'au moins deux couches de neurones - une
couche d'entrée et une couche de sortie - et comprenant
généralement des couches intermédiaires (« hidden
layers »). Plus le problème à résoudre est complexe,
plus le réseau de neurones artificiels ne doit comporter de couches.
Chaque couche contient un grand nombre de neurones artificiels
spécialisés.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
26
10- Traitement de l'information au sein du réseau
de neurones
Au sein d'un réseau de neurones artificiels, le
traitement de l'information suit toujours la même séquence : les
informations sont transmises sous la forme de signaux aux neurones de la couche
d'entrée, où elles sont traitées. À chaque neurone
est attribué un « poids » particulier, et donc une importance
différente. Associé à la fonction dite de transfert, le
poids permet de déterminer quelles informations peuvent entrer dans le
système. À l'étape suivante, une fonction dite
d'activation associée à une valeur seuil calculent et
pondèrent la valeur de sortie du neurone. En fonction de cette valeur,
un nombre plus ou moins grand de neurones sont connectés et
activés. Cette connexion et cette pondération dessinent un
algorithme qui fait correspondre un résultat à chaque
entrée. Chaque nouvelle itération permet d'ajuster la
pondération et donc l'algorithme de façon à ce que le
réseau donne à chaque fois un résultat plus précis
et fiable.

Figure 1.22: Couche de réseau de
neurone
III- RESEAU DE NEURONES ARTIFICIELS : UN EXEMPLE
D'APPLICATION
Les réseaux de neurones artificiels peuvent être
utilisés en matière de reconnaissance d'images. Contrairement au
cerveau humain, un ordinateur ne peut p as déterminer d'un coup d'oeil
si une photographie montre un être humain, une plante ou un objet. Il est
obligé d'examiner l'image pour en discerner les caractéristiques
individuelles. C'est l'algorithme mis en place qui lui permet de savoir quelles
caractéristiques sont pertinentes ; à défaut, il peut le
découvrir par lui-même grâce à l'analyse des
données. Au sein de chaque couche du réseau de neurones, le
système vérifie les signaux d'entrée, c'est-à-dire
les images, décomposées en critères individuels tels que
la couleur, les angles ou les formes. Chaque nouveau teste permet à
l'ordinateur de déterminer avec
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
27
28
29
plus de justesse ce que montre l'image. Initialement, les
résultats sont nécessairement sujets à un certain nombre
d'erreurs. Si le réseau de neurones reçoit un retour
d'information d'origine humaine qui lui permet ainsi Figure 10 : Fonctionnent
des réseaux de neurone Figure 9 : Couche de réseau de neurone
d'adapter son algorithme, on parle d'apprentissage machine. Le concept
d'apprentissage profond a pour but d'éliminer le besoin en intervention
humaine. Le système apprend alors de sa propre expérience ; il
s'améliore à chaque fois qu'une image lui est soumise. En
théorie, on obtient à l'arrivée un algorithme capable
d'identifier sans erreur le contenu d'une photographie, qu'elle soit en
couleurs ou en noir et blanc, quelle que soit la position du sujet ou l'angle
sous lequel il est représenté.
1- Les différents types de réseaux de
neurones artificiels
On fait appel à différentes structures de
réseaux de neurones artificiels en fonction de la méthode
d'apprentissage utilisée et de l'objectif recherché.
2- Apprentissage par renforcement
Le Renforcement Learning est une méthode
d'apprentissage pour les modèles de Machine Learning. Pour faire simple,
cette méthode consiste à laisser l'algorithme apprendre de ses
propres erreurs. Afin d'apprendre à prendre les bonnes décisions,
l'intelligence artificielle se retrouve directement confrontée à
des choix. Si elle se trompe, elle est » pénalisée «.
Au contraire, si elle prend la bonne décision, elle est »
récompensée «. Afin d'obtenir toujours plus de
récompenses, l'IA va donc faire de son mieux pour optimiser sa prise de
décisions. Le développeur du modèle de Machine Learning se
contente de fixer les règles qui déterminent si l'IA sera punie
ou récompensée. Cependant, elle ne donne à cette
dernière aucun indice ni aucune suggestion pour l'aider à prendre
les bonnes décisions. Une équipe de recherche de
l'université de Tokyo a mis au point un système de reconnaissance
de signature manuscrite ayant un taux de réussite de 98,2 %. Ce
système est le seul à tenir compte de l'angle d'inclinaison du
stylo, en plus du style d'écriture et de la pression comme c'est le cas
dans les systèmes traditionnels qui ont un taux de reconnaissance de 95
%. L'équipe de chercheurs, dirigée par Seiichiro Hangai et Fumio
Mizoguchi, a développé ce système après avoir
constaté que l'angle d'inclinaison du stylo est un trait personnel
déterminé par la taille de la main et la façon dont la
personne tient et fait bouger un stylo. Ce système est également
capable de détecter une signature contrefaite par recopie d'une
signature originale. Les chercheurs pensent que cette technique pourra
améliorer la sécurité des
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
cartes à puces puisque la signature d'un titulaire
d'une telle carte Mémoire de Master option Bases de Données et
Génie Logiciel 34 peut être stockée dans sa puce et
utilisée pour comparaison avec la signature du possesseur de la carte au
moment de son utilisation. Cette technique, indépendante de la langue
employée, fait l'objet d'une demande de brevet.
3- Quelques algorithmes du deepLearning
Grid Search est un algorithme d'optimisation
.le but est de déterminer méthodiquement la meilleure combinaison
d'hyper paramètres pour optimiser une métrique de
précision d'un modèle, tout en minimisant le nombre de
simulations effectuées.
K fold
K-fold est une méthode de validation dont le principe
est le suivant: Sur la figure ci-dessous, on peut remarquer que le da taset
ayant 20 points a été divisé en 4 folds, chaque fold
contenant 5 points ou observations. Lors de la première
itération, le premier fold sert de données de Test, pendant qu'un
modèle est entrainé sur le reste des folds. A la seconde
itération, le modèle est de nouveau entrainé, mais cette
fois-ci, sur les données des folds 1, 3 et 4, le second fold servant de
données de Test, et ainsi de suite ... Avec cette méthode, on
s'assure que chaque point de notre dataset a servi une fois au moins au Test et
à l'entrainement, tout en respectant le principe selon lequel on ne fait
pas de Test que des données qui ont servi à l'entrainement.

Figure 1.23 : La méthode de k-fold
Support Vector Machine (SVM)
SVM est un algorithme utilisant la composante vectorielle des
éléments du jeu de données d'apprentissage afin d'en
déterminer une orientation préférentielle. Ainsi selon que
l'on se place dans un contexte de régression ou de classification, il va
être possible de ? soit définir une droite
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
porté par cette orientation donnée par la
composante vectorielle ? soit de construire une droite perpendiculaire à
ce même vecteur.

Figure 1.24 : Support SVM Gradient
descent
L'algorithme du gradient désigne un algorithme
d'optimisation différentiable. Il est par conséquent
destiné à minimiser une fonction réelle
différentiable définie sur un espace euclidien (par exemple, R n
{\displaystyle \mathbb {R} ^{n}} , l'espace des n-uplets de nombres
réels, muni d'un produit scalaire) ou, plus g énéralement,
sur un espace hilbertien. L'algorithme est itératif et procède
donc par améliorations successives. Au point courant, un
déplacement est effectué dans la direction opposée au
gradient, de manière à faire décroître la fonction.
Le déplacement le long de cette direction est déterminé
par la technique numérique connue sous le nom de recherche
linéaire. Cette description montre que l'algorithme fait partie de la
famille des algorithmes à directions de descente.

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
30
Figure 1.25: Schéma de l'algorithme de
gradient FORET ALEATOIRE
Algorithme de classification composé de nombreux arbres
de décisions. Formellement proposé en 2001 par Leo Breiman et
Adèle Cutler, il fait partie des techniques d'apprentissage automatique.
Cet algorithme combine les concepts de sous-espaces aléatoires et de
ré-échantillonnage avec remise ensembliste (bagging).
L'algorithme des forêts d'arbres décisionnels effectue un
apprentissage sur de multiples arbres de décision entraînés
sur des sous-ensembles de données légèrement
différents. Principe du foret aléatoire

Figure 1.26: Schema forêt
aléatoire
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
MATERIELS ET METHODES
31
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
32
CHAPITRE IV: MATERIELS ET METHODES
I - LE MATERIELS
Ici nous parlerons :
- de l'architecture qui a été crée
- de la base de SOCOFING utilisée ensuite nous utiliserons
les bibliothèques Tensorflow et Keras pour l'apprentissage et la
classification à partir de python dans un environnement de Deep learning
créé à cet effet.
I.1 - L'Environnement de travail
1- Matériel
La machine utilisée est une machine personnelle, elle
possède : - un processeur Intel core i7 de fréquence 4.2 Mhz V
pro, - 8 Go de RAM,
- Carte graphique Intel® UHD Graphics
2- Logiciels et librairies Utilisés dans
l'implémentation
- Windows 10 est le système d'exploitation de notre
machine qui a servi à élaborer notre projet.
I.2 - Langages de programmation
L'environnement logiciel utilisé pour la
réalisation de notre application est python. Python est
un puissant outil de calcul numérique, de programmation et de
visualisation graphique. Python est un langage de programmation de haut niveau
interprété (il n'y a pas d'étape de compilation) et
orienté objet avec une sémantique dynamique. Il est très
sollicité par une large communauté de développeurs et de
programmeurs. Python est un langage simple, facile à apprendre et permet
une bonne éduction du cout de la maintenance des codes. Les
bibliothèques (packages) python encouragent la modularité et la
réutilisabilité des codes. Python et ses bibliothèques
sont disponibles (en source ou en binaires) sans charges pour la
majorité des plateformes et peuvent être redistribués
gratuitement.
Mode exécutif : il exécute ligne par ligne un
"fichier PY" (programme en langage Python).
Fenêtres Graphique : comme Spyder elle permet de faire
des graphiques dans ces fenêtres. Fichiers PY : Ce sont des programmes en
langage Python (écrits par l'usager),

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
33
Figure 1.27 : Logo de spyder
Figure 1.28 : Environnement Python /spyder
I.3 - Quelques bibliothèques de python.
3- NumPy
NumPy est une bibliothèque pour langage de programmation
Python, destinée à manipuler des matrices ou tableaux
multidimensionnels ainsi que des fonctions mathématiques opérant
sur ces tableaux
4- TENSORFLOW
TensorFlow est un framework de programmation pour le calcul
numérique qui a été rendu Open Source par Google en
Novembre 2015. Depuis son release, TensorFlow n'a cessé de gagner en
popularité, pour devenir très rapidement l'un des frameworks les
plus utilisés pour
le Deep Learning et donc les réseaux de neurones. Son nom
est notamment inspiré du fait que les opérations courantes sur
des réseaux de neurones sont principalement faites via des tables de
données multi-dimensionnelles, appelées Tenseurs (Tensor). Un
Tensor à deux dimensions
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
34
est l'équivalent d'une matrice. Aujourd'hui, les
principaux produits de Google sont basés sur TensorFlow: Gmail, Google
Photos, Reconnaissance de voix.
Et La raison pour laquelle TensorFlow a été la
librairie choisie pour la réalisation de ce travail, est que cette
librairie est la plus utilisée en ce moment dans le monde du deep
learning. TensorFlow est une librairie codée en C++ afin d'obtenir une
performance élevée lors des phases d'apprentissage de nouveaux
modèles statistiques mais elle propose quelques APIs dans d'autres
langages, comme Python, R, Java et C# (Unruh, 2017). Il est important de noter
que Google propose plusieurs APIs, mais qu'elle recommande que l'apprentissage
soit fait avec le langage Python et qu'ensuite la mise en production se fasse
sur d'autres langages, comme Java par exemple (TensorFlow, 2018b).
5- THEANO
Theano est une bibliothèque logicielle Python
d'apprentissage profond développé par Mila - Institut
québécois d'intelligence artificielle, une équipe de
recherche de l'Université McGill et de l'Université de
Montréal.
6- KERAS
Keras est une API de réseaux de neurones de haut
niveau, écrite en Python et capable de fonctionner sur TensorFlow ou
Theano. Il a été développé en mettant l'accent sur
l'expérimentation rapide. Être capable d'aller de l'idée
à un résultat avec le moins de délai possible est la
clé pour faire de bonnes recherches. Il a été
développé dans le cadre de l'effort de recherche du projet
ONEIROS (Open-ended Neuro-Electronic Intelligent Robot Operating System), et
son principal auteur et mainteneur est François Chollet, un
ingénieur Google. En 2017, l'équipe TensorFlow de Google a
décidé de soutenir Keras dans la bibliothèque principale
de TensorFlow. Chollet a expliqué que Keras a été
conçue comme une interface plutôt que comme un cadre
d'apprentissage end to end. Il présente un ensemble d'abstractions de
niveau supérieur et plus intuitif qui facilitent la configuration des
réseaux neuronaux indépendamment de la bibliothèque
informatique de backend. Microsoft travaille également à ajouter
un backend CNTK à Keras aussi.
7- Scikit-learn
Scikit-learn est une bibliothèque libre Python
dédiée à l'apprentissage automatique. Elle est
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
35
développée par de nombreux contributeurs
notamment dans le monde académique par des instituts français
d'enseignement supérieur et de recherche comme Inria et
Télécom ParisTech. Elle comprend notamment des fonctions pour
estimer des forêts aléatoires, des régressions logistiques,
des algorithmes de classification, et les machines à vecteurs de
support. Elle est conçue pour s'harmoniser avec des autres
bibliothèques libre Python, notamment NumPy et SciPy.
8- OS
OS est un module fournit par Python dont le but d'interagir
avec le système d'exploitation, il permet ainsi de gérer
l'arborescence des fichiers, de fournir des informations sur le système
d'exploitation processus, variables systèmes, ainsi que de nombreuses
fonctionnalités du système.
9- OPENCV
OpenCV est une bibliothèque libre de vision par
ordinateur. Cette bibliothèque est écrite en C et C++ et peut
être utilisée sous Linux, Windows et Mac OS X. Des interfaces ont
été développées pour Python, Ruby, Matlab et autre
langage. OpenCV est orientée vers des applications en temps réel.
Un des buts d'OpenCV est d'aider les gens à construire rapidement des
applications sophistiquées de vision à l'aide d'infrastructure
simple de vision par 57 ordinateurs. La bibliothèque d'OpenCV contient
près de 500 fonctions. Il est possible grâce à la «
licence de code ouvert » de réaliser un produit commercial en
utilisant tout ou partie d'OpenCV. La version d'Opencv que nous avons
utilisé est opencv 3.4
10- MAXPOOLING
Maxpooling est un processus de discrétisation
basé sur des échantillons. L'objectif est de
sous-échantillonner une représentation d'entrée (image,
matrice de sortie de couche cachée, etc.), en réduisant sa
dimensionnalité et en permettant de faire des hypothèses sur les
caractéristiques contenues dans les sous-régions
regroupées.
Ceci est fait en partie pour aider à sur-ajuster en
fournissant une forme abstraite de la représentation. De plus, il
réduit le coût de calcul en réduisant le nombre de
paramètres à apprendre et fournit une invariance de traduction de
base à la représentation interne.
11-
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
36
RELU
ReLU ( Rectified Linear Unit ) : Ce sont les fonctions les
plus populaires de nos jours. Elles permettent un entrainement plus rapide
comparé aux fonctions sigmoid et tanh, étant plus
légères.
12- SOFMAX
La fonction softmax est utilisée pour transformer les
logits dans un vecteur de probabilités, indiquant la
probabilité que x appartienne à chacune des classes de
sortie T. Mais on peut travailler sur d'autres caractéristiques, et
ainsi obtenir d'autres probabilités, afin de déterminer l'animal
sur la photo. Au fur et à mesure que l'intelligence artificielle aura
d'exemples, plus la matrice de poids s'affinera, et plus le système sera
performant.
II - METHODES DE RECONNAISSANCES
II.1 - Base de données d'empreinte
digitale
Les problèmes de sécurités se sont
multipliés et le marché de la biométrie a connu une
croissance rapide. Aujourd'hui il existe différents types
de biométries technologies tels que les
empreintes digitales, l'iris, les veines, les voix
identification. Ici dans notre contexte, notre étude
consistera à utiliser le deep Learning pour la
résolution de nos problèmes.
L'identification des empreintes digitales a été
utilisée dans notre étude. Une gigantesque
base de données d'empreintes digitales existantes a
été déjà établie et fut donné par nos
différents
encadreurs.
Cette base de données est constituée d'empreinte
digitale de plusieurs individus repartis
dans plusieurs fichiers :
- Altered-easy
- Altered-hard
- Altered-medium
Ici, nous avons utilisé la base de données
d'empreinte digital SOCOFING comprenant Sokoto
Coventry Fingerprint Dataset (SOCOFing) qui est une base de
données biométrique
d'empreintes digitales conçue à des fins de
recherche universitaire. SOCOFing est composé de
6 000 images d'empreintes digitales de 600 sujets africains et
contient des attributs uniques tels
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
que des étiquettes pour le sexe, le nom des mains et des
doigts ainsi que des versions modifiées
synthétiquement avec trois niveaux différents
d'altération pour l'effacement.
37
II.2 - Le Prétraitement
L'étape du prétraitement devrait être
effectuée avant l'extraction des caractéristiques. Nous centrons
l'empreinte dans un canevas ensuite nous supprimons l'arrière-plan en
définissant les pixels d'arrière-plan sur un blanc et en laissant
les pixels du premier plan en niveau de gris. Certaines étapes de
prétraitements doivent être effectuées avant l'extraction
des données. Il s'agit de l'importation des bibliothèques
(numpy,os,sklearn,open cv...).
Apres importation des bibliothèques on importera la base
de données :
Sokoto Coventry Fingerprint Dataset (SOCOFing) | Kaggle
L'étape suivante consistera à pixeler les images
ensuite mettre les images dans une même
dimension compris entre 0 et 1.
Le Dataset sera subdivisé en deux étapes :
-Trainning(entrainement)
-Test(test)
Importation de la fonction Train_set(permet la division de la db
)

Figure 1.29 : Base de données SOCOFING
(empreinte digitale d'individu)
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
38
39
II.2.1 - La Binarisation
II.3. Méthodologie utilisée
Dans notre exercice nous allons utiliser un algorithme de Deep
Learning c'est-à-dire les réseaux de neurones convolutifs car ils
sont qualifiés comme étant les modèles les plus
performants pour la classification d'images.
II.3.1. Les réseaux de neurones convolutifs
II.3.1.1. Définition
Les réseaux de neurones convolutifs désignent
une sous-catégorie de réseaux de neurones et sont conçu
pour extraire automatiquement les caractéristiques des images
d'entrée. Ils reçoivent des images en entrée,
détectent les features de chacune d'entre elles, puis entraînent
un classifieur dessus. Leur architecture est alors plus spécifique :
elle est composée de deux parties principales bien distinctes.
Ø La partie convolutive : en entrée, une image est
fournie sous la forme d'une matrice de
pixels. Elle a 2 dimensions pour une image en niveaux de
gris. La couleur est représentée par une troisième
dimension, de profondeur 3 pour représenter les couleurs fondamentales
[Rouge, Vert, Bleu].
La première partie d'un CNN est la partie convolutive
à proprement parler. Elle fonctionne comme un extracteur de
caractéristiques des images. Une image est passée à
travers une succession de filtres, ou noyaux de convolution, créant de
nouvelles images appelées cartes de convolutions. Certains filtres
intermédiaires réduisent la résolution de l'image par une
opération de maximum local. Au final, les cartes de convolutions sont
mises à plat et concaténées en un vecteur de
caractéristiques, appelé code CNN. [19]
Ø La partie classification : ce code CNN en sortie de la
partie convolutive est ensuite
branché en entrée d'une deuxième partie,
constituée de couches entièrement connectées (perceptron
multicouche). Le rôle de cette partie est de combiner les
caractéristiques du code CNN pour classer l'image.
La sortie est une dernière couche comportant un
neurone par catégorie. Les valeurs numériques obtenues sont
généralement normalisées entre 0 et 1, de somme 1, pour
produire une distribution de probabilité sur les catégories.

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
Figure 1.30 : les deux parties de
l'architecture des réseaux de neurones convolutifs II.3.1.2. Les
différentes couches des CNN
Il existe quatre types de couches pour un réseau de
neurones convolutifs : la couche de convolution, la couche de pooling, la
couche de correction ReLU et la couche fully-connected :
» La couche de convolution (CONY) qui traite les
données d'un champ récepteur.
» La couche de pooling (POOL), qui permet de compresser
l'information en réduisant la taille de l'image intermédiaire
(souvent par sous-échantillonnage).
» La couche de correction (ReLU), souvent appelée
par abus 'ReLU' en référence à la
fonction d'activation (Unité de rectification
linéaire).
» La couche "entièrement connectée" (FC),
qui est une couche de type perceptron.
1- La couche de convolution
La couche de convolution est la composante clé des
réseaux de neurones convolutifs, et constitue toujours au moins leur
première couche.
Son but est de repérer la présence d'un
ensemble de features dans les images reçues en entrée. Pour cela,
on réalise un filtrage par convolution : le principe est de faire
"glisser" une fenêtre représentant la feature sur l'image, et de
calculer le produit de convolution entre la feature et chaque portion de
l'image balayée. Une feature est alors vue comme un filtre : les deux
termes sont équivalents dans ce contexte.
Trois hyperparamètres permettent de dimensionner le
volume de la couche de convolution
» Profondeur de la couche : nombre de noyaux de
convolution (ou nombre de neurones associés à un même champ
récepteur).
» Le pas contrôle le chevauchement des champs
récepteurs. Plus le pas est petit, plus les
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
40
champs récepteurs se chevauchent et plus le volume de
sortie sera grand.
Ø La marge (à 0) ou zero padding : parfois, il est
commode de mettre des zéros à la frontière
du volume d'entrée. La taille de ce zero-padding est
le troisième hyperparamètre. Cette marge permet de
contrôler la dimension spatiale du volume de sortie. En particulier, il
est parfois souhaitable de conserver la même surface que celle du volume
d'entrée.
2- Couche de pooling (POOL)
Ce type de couche est souvent placé entre deux couches de
convolution : elle reçoit en entrée plusieurs feature maps, et
applique à chacune d'entre elles l'opération de pooling.
L'opération de pooling (ou sub-sampling) consiste
à réduire la taille des images, tout en préservant leurs
caractéristiques importantes.
Pour cela, on découpe l'image en cellules
régulière, puis on garde au sein de chaque cellule la valeur
maximale. En pratique, on utilise souvent des cellules carrées de petite
taille pour ne pas perdre trop d'informations. Les choix les plus communs sont
des cellules adjacentes de taille 2 × 2 pixels qui ne se chevauchent pas,
ou des cellules de taille 3 × 3 pixels, distantes les unes des autres d'un
pas de 2 pixels (qui se chevauchent donc). On obtient en sortie le même
nombre de feature maps qu'en entrée, mais celles-ci sont bien plus
petites.
La couche de pooling permet de réduire le nombre de
paramètres et de calculs dans le réseau. On améliore ainsi
l'efficacité du réseau et on évite le
sur-apprentissage.
Il est courant d'insérer périodiquement une
couche Pooling entre les couches Conv successives dans une architecture
ConvNet. Sa fonction est de réduire progressivement la taille spatiale
de la représentation afin de réduire la quantité de
paramètres et de calculs dans le réseau, et donc de
contrôler également le sur-ajustement. La couche de pooling
fonctionne indépendamment sur chaque tranche de profondeur de
l'entrée et la redimensionne spatialement, en utilisant
l'opération MAX.
Ainsi, la couche de pooling rend le réseau moins
sensible à la position des features : le fait qu'une feature se situe un
peu plus en haut ou en bas, ou même qu'elle ait une orientation
légèrement différente ne devrait pas provoquer un
changement radical dans la classification de l'image.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
41
3- Couches de correction (RELU)
Pour améliorer l'efficacité du traitement en
intercalant entre les couches de traitement une couche qui va opérer une
fonction mathématique (fonction d'activation) sur les signaux de sortie.
dans ce cadre on trouve ReLU (Rectified Linear Units) désigne la
fonction réelle non-linéaire définie par ReLU(x)=max(0,x).
La couche de correction ReLU remplace donc toutes les valeurs négatives
reçues en entrées par des zéros. Elle joue le rôle
de fonction d'activation.
Souvent, la correction Relu est préférable, mais
il existe d'autre forme
Ø La correction par tangente hyperbolique
f(x)=tanh(x),
Ø La correction par la tangente hyperbolique saturante :
f(x)=|tanh(x)|,
4- Couche entièrement connectée
(FC)
La couche fully-connected constitue toujours la
dernière couche d'un réseau de neurones, convolutif ou non - elle
n'est donc pas caractéristique d'un CNN.
Ce type de couche reçoit un vecteur en entrée et
produit un nouveau vecteur en sortie. Pour cela, elle applique une combinaison
linéaire puis éventuellement unefonction d'activation aux valeurs
reçues en entrée.
La couche fully-connected permet de classifier l'image en
entrée du réseau : elle renvoie un vecteur de taille N, où
N est le nombre de classes dans notre problème de classification
d'images. Chaque élément du vecteur indique la probabilité
pour l'image en entrée d'appartenir à une classe.
III. ARCHITECTURE DE NOTRE RESEAU, ENTRAINEMENT ET
COMPILATION DU MODELE
1. Architecture de notre réseau
Notre modèle est composé de trois couches de
convolution, trois couches maxpooling, trois couches et deux couches de fully
connect.

|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
42
Figure 1.31 : Définition du
modèle
» L'image en entrée est de taille 96*96, l'image
passe d'abord à la première couche de
convolution
» La première couche de convolution est
composée de 32 filtres de taille 5*5, la seconde
couche de convolution est composée de 64 filtres de
tailles 5*5 et la dernière est composée de 128 filtres de tailles
3*3 et ont toute la fonction ReLU comme fonction
d'activation.
» Une couche de Maxpooling est appliquée au 32
features obténues après l'application d'une
normalisation par lot (BatchNormalization), pour réduire
la taille des images tout
en préservant leurs caractéristiques
importantes.
» On répète la même chose avec les
couches de convolutions deux et trois. Une couche
de Maxpooling est appliquée après l'application
de la normalisation par lot (BatchNormalization) à la sortie de la
couche de convolution précédente. A la sortie de la
deuxième couche de Maxpooling on obtient 64 features et à la
sortie de la troisième couche de Maxpooling on obtient 128 features
» Après ces trois couches de convolution, nous
utilisons un réseau de neurones composé
de deux couches fully connected. La première couche a
256 neurones où la fonction d'activation utilisée est le ReLU, et
la deuxième couche a 108 neurones où la fonction d'activation
utilisée softmax qui permet de calculer la distribution de
probabilité des
108 classes (nombre de classe dans la base d'image).
» Nous avons utilisé la méthode Flatten qui a
permis de mettre bout à bout toutes les
images (matrices) que nous avons pour en faire un vecteur.
Ø
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
43
Et la méthode Dropout qui nous a permis d'éviter le
sur-apprentissage en éteignant temporairement et aléatoirement
certains neurones au cours de l'apprentissage.
2. Compilation
C'est au moment de la compilation que nous allons définir
le type d'algorithme d'optimisation et la fonction de coût à
utiliser.

Figure 1.32: La compilation
Dans le cadre de cette mise en pratique nous avons opté
pour l'algorithme d'optimisation Adam et une fonction de coût d'entropie
croisée catégorielle.
3. L'entrainement
Premier cas : Le modèle est entraîné pendant
05 époques Deuxième cas : Le modèle est
entraîné pendant 10 époques Troisième cas : Le
modèle est entraîné pendant 20 époques

Figure 1.33 : l'entrainement des deux
1er cas
Avec l'avènement du deeplearning, l'accent est
placé sur les méthodes d'apprentissage en profondeur dont les
réseaux de neurones à convolution (CNN),qui sont les premier dans
l'évolution de l'apprentissage en profondeur. La CNN se compose de
plusieurs couches, effectuant des opérations telles que les
convolutions, la mise en pool maximale et les produits dot (couches
entièrement connectées), où dans les couches convolutives
et les couches entièrement connectées ont des paramètres
prenables qui sont optimisés pendant la formation.
Le type d'architecture de CNN détermine comment sont
de nombreuses couches, quelle est la fonction de chaque couche et comment les
couches sont connectées.
Il existe quatre architectures pour les CNN, à savoir
:
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
44
LeNet, AlexNet, VGG et GoogleNet. Parmi ceux-ci, nous avons
étudié LeNet et AlexNet. Choisir une bonne architecture est
crucial pour un apprentissage réussi des CNN. L'Alex Net de
l'architecture CNN contient 11 couches comprenant la convolution, la mise en
commun et le couches entièrement connectées. Le réseau
choisi contient 7 couches.
Ce chapitre nous a permis de monter de manière
détaillée les différents outils et la méthode de
réseaux de neurones convolutifs qui ont été
utilisés durant ce travail. Aussi les réseaux de neurones
convolutifs sont adaptés aux images, sont composés de deux
parties qui sont la partie convolutive et la partie de classification et dans
leur architecture, on a quatre couches. Ils tiennent leur particularité
de leur couche clé qui est la couche convolutive. Nous avons par la
suite montré notre modèle construit, donner les paramètres
de notre compilation et de notre entrainement.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
RESULTATS ET DISCUSSIONS
45
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
46
CHAPITRE V: RESULTATS ET DISCUSSIONS
Dans cette étape on portera particulièrement notre
attention sur les tests réalisés ainsi que les résultats
obtenus. Elle consistera donc à analyser et interpréter nos
résultats obtenus.
1- RESULTATS
Ø Entrainement 1
nombre d'époque 05 et 2205 images pour 108 sujets
Constat

Figure 34 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 1er
Entrainement.
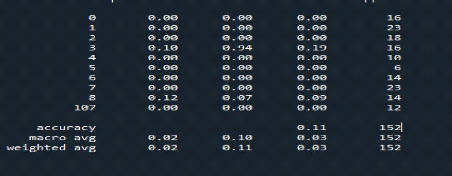
Figure 1 : Moyenne performance 0.11
1er Entrainement
Ø Entrainement 2
Nombre d'époque 10 et 2205 images d'empreinte digitale
pour 108 sujets
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
47
Constat
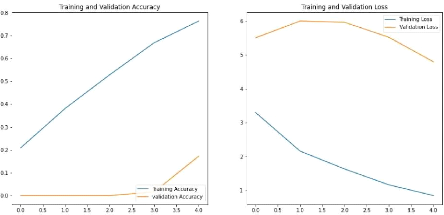
Figure 3 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 2ème
Entrainement.

Figure 4 : Moyenne performance 0.1720 2eme
entrainement
Ø Entrainement 3
Nombre d'époque 20 et 756 images d'empreinte digitale
pour 108 sujets
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
48
Constat

Figure 3 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 3ème
Entrainement.
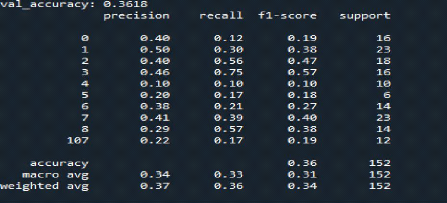
Figure 4 : Moyenne performance 0.3618
Ø
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
63
Entrainement 4
Nombre d'époque 30 et 3000 images d'empreinte digitale
pour 108 sujets Constat

Figure 5 : Performance par rapport aux jeux
d'entraînement et validation à gauche et Erreur par rapport aux
jeux d'entraînement et validation à droite 4ème
Entrainement.

Figure 5 :Moyenne performance 0.9748
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
64
64
65
II. DISCUSSIONS
Ø 1er entrainement
Après l'analyse du résultat obtenu, On constate
que la précision de l'apprentissage et de test n'est pas performante.
Ø 2ème entrainement
Après l'analyse du résultat obtenu, On constate
qu'avec un nombre limité d'époques et avec une quantité
insuffisante de données notre modèle de
classification d'iris n'est pas performant et donne des
prédictions avec des probabilités proches de 0 ou même
égale à 0 pour certains sujets.
Ø 3ème entrainement
Après l'analyse du résultat obtenu, nous avions
essayé de mettre les mêmes données
précédentes, On constate que plus la quantité
d'information pour l'apprentissage est basse plus le model est mal
entrainé et ne pourra classifier les empreintes digitales.
Ø 4ème entrainement
Après l'analyse du résultat obtenu, nous
observons que la précision de l'apprentissage et de test augmente avec
le nombre d'époque, ce qui signifie qu'à chaque époque le
model apprend plus. Alors nous devons augmenter le nombre d'époque et
des images pour avoir de meilleures performances.
Afin d'avoir une meilleure performance, nous avions
trouvé mieux d'effectuer plusieurs tests. A la suite de ces tests nous
avions obtenu une meilleure performance possible.
Ø Après l'analyse du résultat
obtenu dans la Figure, On constate que malgré qu'on ait
une quantité d'informations suffisante pour
l'apprentissage et que nous donnons moins d'époque au modèle pour
son apprentissage, nous remarquons que le modèle n'est pas
performant.
Le choix d'avoir effectué plusieurs tests
d'entraînement aura donc permis de récupérer le meilleur
modèle possible qui est celui du dernier entrainement avec une
performance de 0.97.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
CONCLUSION
Ce dernier chapitre a fait l'objet d'une étude
concernant la façon dont notre modèle réagit en fonction
de la variation de certains paramètres (le nombre d'époque, la
quantité d'information) qui pourraient affecter notre modèle
biométrique basé sur l'empreinte digitale.
MEILLEUR PERFORMANCE DE NOTRE
MODEL
Résultat obtenu avec 30 Epoques et 3000 images
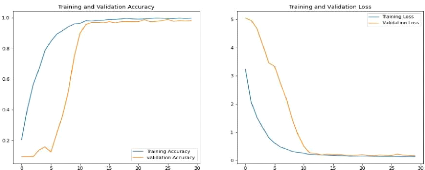
accuracy 0.9748
macro avg 0.98 0.98 0.98 436
weighted avg 0.98 0.97 0.97 436
Les objectifs fixés dans le cadre de ce projet de
recherche est de produire la reconnaissance d'emprunte digital basé sur
le deep learning .Nos recherches nous ont menés à la mise en
place d'un programme informatique de reconnaissance basé sur des
réseaux de neurones à convolution. Ces différentes
étapes se sont déroulées dans les points suivants :
- Importation des bibliothèques
- Importation du dataset
- Pixelisation des images
- Diviser les données en deux étapes (une partie
entrainement et une autre en test)
- Entrainement et Test
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
Il faut noter que l'architecture logicielle mise en oeuvre
nous garantit une exploitation optimale des ressources des infrastructures par
l'exécution.
Ainsi, la solution apporte à l'informatique
(précisément dans ce travail de recherche) une évolution
notable et répond bien à la question de la performance. Notre
model arrive à faire la reconnaissance des images avec une
précision de 97%. Pendant l'entrainement, nous constations que le
pourcentage augmentait progressivement; ce qui signifia que le model n'a pu
faire de surapprentissage.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
66
CONCLUSION ET PERSPECTIVES
Au terme de notre étude, nous pouvons conclure que la
technologie des machines Learning apporte une contribution significative dans
l'élaboration des solutions de la biométrie. Les réseaux
de neurones reposent à présent sur des bases mathématiques
solides qui permettent d'envisager des applications dans presque tous les
domaines notamment dans le domaine de la classification.
Notre projet de fin d'étude consiste à faire la
reconnaissance des empreintes digitales par le réseau de neurone(carte
de kohonen) qui permet de réaliser un système biométrique
qui fait l'authentification des individus selon leurs empreintes digitales.
Au cours de ce mémoire, nous avons
présentées les différentes étapes du deep learning
et approcher les différentes méthodes de traitement d'images et
de classification.
Nous estimons avoir réalisé un système
répondant à l'objectif que nous nous sommes fixés au
départ, à savoir la mise en oeuvre d'un système de
reconnaissance d'individus à base d'empreintes digitales en utilisant le
Deep learning. Dans le domaine de la reconnaissance d'empreinte digitale
surtout dans le deep learning, certains améliorations ont
été effectué mais il y reste de nombreux efforts encore.
La difficulté que nous pouvons constater à cet effet est aussi
l'absence de puissants équipements pour les différents
entrainements.
Il serait avantageux de travailler sur des calculateurs afin
de permettre au machine de mieux apprendre et d'obtenir de meilleurs
performances. Actuellement, il existe quelques sociétés ayant
cette technologie, mais l'équipement est particulièrement
coûteux.
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
67
REFERENCES BIBLIOGRAPHIQUES
[1] S. AKROUF, »Une Approche Multimodale pour
l'Identification du Locuteur», thèse de doctorat, Université
Ferhat Abbas- Setif , Mars 2021.
https://ch.mathworks.com/help/deeplearning/getting-started-with-deep-learning-toolbox.html?s_tid=CRUX_lftnav,
Mars 2021
Université de : université mentouri de
Constantine. Promotion : Mars 2021.
[2] introduction à la biométrie
ww2.ac-poitiers.fr/electronique/IMG/doc/introduction_a_la_biometrie.doc.
[3] L. ALLANO, `La Biométrie multimodale :
stratégies de fusion de scores et mesures de dépendance
appliquées aux bases de personnes virtuelles', thèse de doctorat,
Université D'every Val D'essonne, Mars 2021
[4]
http://www.memoireonline.com/09/09/2694/Systeme-de-reconnaissance-hors-ligne-des-mots-manuscrits-arabe-pour-multi-scripteurs.html.
Mars 2021
[4] T. AMELLAL, K. BENAKLI, »Système de
reconnaissance de visage basé sur les GMM », Mars 2021
mémoire fin d'étude d'ingéniera en
informatique, Institut National de formation en Informatique (I.N.I) Oued-Smar
Alger, 2007.fev.2021
[5] Reconnaissance automatique des empreintes digitales
http://www.isir.upmc.fr/UserFiles/File/LPrevost/Biometrie%20Empreintes.pdf.
Mars 2021
[6] Pierre Jolicour, Introduction à la
biométrie, 32,78 €
[7]
http://empreintesdigitales.free.fr/index.php?page=grand1,
Fev.2021
[8] J.J. Hopfield, «Neural networks and physical systems
with emergent collective computational abilities», in Roc. Nat, Academy of
Sciences, USA 79, 1982, pp. 2,554
[9] Réseaux de
neurones.
www.uqtr.uquebec.ca/~biskri/Personnel/mol/RRN.doc . Mars 2021
[10] [6] S. BOUDJELAL, »Détection et identification
de personne par méthode biométrique », Mémoire de
magister en électronique, Université de Tizi Ouzou, 2014
[11] Deep learning
https://ch.mathworks.com/fr/solutions/deeplearning.html?s_tid=hp_brand_deeplearning,
fev.2021
[12] Principe de l'intelligence artificielle,
https://www.r2i.ca/principe-intelligence
artificielle, fev.2021
[13]
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
|
68
69
Comment les machines apprennent
https://webcache.googleusercontent.com/search?q=cache:BuMqvml4LuYJ:https://www.di.
ens.fr/eloise.berthier/hs.pdf+&cd=6&hl=fr&ct=clnk&gl=ci,
mars 2021
[14] A. BENAGGA et L. TELIB, » Reconnaissance des personnes
basée sur l'empreinte de l'articulation de doigt», Mémoire
de master académique, université Kasdi Merbah Ouargla, fev.
2021
Apprentissage non supervisé -- Wikipédia (
wikipedia.org), dec.2020
[15] Deep learning
https://datascientest.com/deep-learning,
fev.2020
[16] L. Masek, «Recognition of Human Iris Patterns for
Biometric Identification», thèse de Master présentée
à l?Université de Western Australia, Australie, 2003
[17] N. Morizet, «Reconnaissance Biométrique par
Fusion Multimodale du Visage et de l?Iris», thèse de Doctorat
présentée à l?Ecole Nationale Supérieure des
Télécommunications, France, 2009
[18] J. Zuo, A. Natalia, «On a methodology for robust
segmentation of nonideal iris images», IEEE Transactions on Systems, Man,
and Cybernetic B, Vol. 40, No. 3, p.p.
703-718, 2010
[19] Daugman, J.G.; High confidence visual recognition of
persons by a test of statistical independence?, IEEE Transactions on Pattern
Analysis and Machine Intelligence, Vol. 15, No. 11, pp. 1148-1161, Nov. 1993
[20] Wildes, R.P., "Iris Recognition: An Emerging Biometric
Technology", Proceedings of the IEEE, Vol. 85, No. 9, pp.1348-1363, 1997
[21] An algorithm for iris extraction (
infona.pl), mars 2020
[22] W. Ryan, D. Woodard, A. Duchowski, and S. Birchfield,
«Adapting starburst for elliptical iris segmentation», 2nd IEEE
International Conference on Biometrics,2020
Theory, Applications and Systems, Vol., No., p.p. 1-7,
Arlington, VA, Janv. 2021
[23] J. Daugman, «New methods in iris recognition»,
IEEE Transactions on Sytems, Man, Cybernetics. B., Vol. 37, No. 5, p.p.
1168-1176, Mars. 2021
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
[24] S. Shah, A. Ross, «Iris segmentation using geodesic
active contours», IEEE Transactions on Information Forensics Security,
Vol. 4, No. 4, p.p. 824-836, 2009
[25] E. Krichen, «Reconnaissance des personnes par l'iris
en mode dégradé», thèse de Doctorat
présentée à Institut National des
Télécommunications, France, 2007
[26] Hunny Mehrotra, Banshidhar Majhi, and Phalguni Gupta.Multi-
algorithmic Iris Authentication System». Proceedings of Worde academy of
science,engineering and technology volume ISSN 2070-374034 ,October 2008
Définition | Deep Learning - Apprentissage profond |
Futura Tech,(
futura-sciences.com)
(fev.2021)
https://fr.wikipedia.org/wiki/R%C3%A9seau_de_neurones_artificiels,(
mars 2021)
https://fr.wikipedia.org/wiki/Intelligence_artificielle
(fev.2021)
https://ml4a.github.io/ml4a/fr/neural_networks/(mars
2021)
https://fr.wikipedia.org/wiki/NumPy,
(fev.2021)
https://stateofther.github.io/finistR2018/atelier2_tensorflow.html,fev.2020
https://www.tensorflow.org/resources/learn-ml?hl=fr,
mars 2021
https://www.actuia.com/keras/
(fev.2021)
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
70
71
72
73
TABLE DES MATIERES
DEDICACE I
REMERCIEMENTS II
AVANT-PROPOS III
SOMMAIRE IV
LISTE DES FIGURES V
ABREVIATIONS VII
RESUME IX
ABSTRACT X
INTRODUCTION GENERALE 1
ETAT DE L'ART 2
CHAPITRE I : LA BIOMETRIE 3
I- GÉNÉRALITÉS 3
II - DEFINITION DE LA BIOMETRIE 3
III - LES DIFFERENTES ANALYSE DE LA BIOMETRIE 4
III.1. Les caractéristiques biométriques 4
III.2. Les systèmes biométriques 4
III.2.2.1. Le mode vérification ou d'authentification
5
III.2.2.2. Le mode d'identification 5
III.3. Processus 5
III.4. Les principaux avantages de biométrie 6
III.5 La biométrie physique 6
III.5.1. Visage 7
1.6 Iris 7
1.7. Empreintes des articulations des doigts 8
1.8. Empreinte palmaire 8
I.8.1. Biométrie comportementale 8
I.8.2. Voix 8
I.8.3. Frappe dynamique sur le clavier 9
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
I.8.4. Biométrie Biologique 10
I.8.4.1. Veines de la main 10
I.8.4.2. L'analyse de l'ADN 10
I.8.4.3. Thermo gramme faciale 11
I.9. Les Applications de la biométrie 11
I.9.1. Contrôle d'accès 11
I.9.1.1. Contrôle d'accès physique 11
I.9.1.2. Contrôle d'accès virtuel 12
I.9.2. Authentification des transactions 12
I.9.3. Répressions 12
I.9.4. Personnalisation 13
CHAPITRE II : EMPREINTE DIGITALE 14
I- GENERALITES 14
II.1 - Les caractéristiques de l'empreinte digitale
15
II.2. Le Système Biométrique basé sur
l'empreinte digitale 17
II.2.1. Définition 17
II.2.2. Acquisition 18
II.2.3. Segmentation 18
II.2.4. Normalisation 19
II.2.5. Encodage (extraction des caractéristiques)
19
II.2.6. Classification 19
II.2.1.6. L'utilisation des Réseaux de Neurones 20
CHAPITRE III : MACHINE LEARNING 21
I - LES DIFFÉRENTS CATÉGORIES DE MACHINE
LEARNING 21
II- APPRENTISSAGE NON SUPERVISE 22
1- Deep learning 22
2 - Le fonctionnement du deep learning 22
3-Les Réseaux de neurons artificiels 23
4-Définition 23
5-Les différents types de réseau de neurone
23
6-
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
Réseau de neurones de convolution - Convolution Neural
Network (CNN): 24
7- Les réseaux de neurone récurent 24
8- Les réseaux de neurone artificiel 25
9- Comment fonctionne un réseau neuronal artificiel ?
25
10- Traitement de l'information au sein du réseau de
neurones 26
III- RESEAU DE NEURONES ARTIFICIELS : UN EXEMPLE D'APPLICATION
26
1- Les différents types de réseaux de neurones
artificiels 27
2- Apprentissage par renforcement 27
3- Quelques algorithmes du deepLearning 28
MATERIELS ET METHODE 31
CHAPITRE IV: MATERIELS ET METHODES 32
I - LE MATERIEL 32
I.1 - L'Environnement de travail 32
1- Matériel 32
2- Logiciels et librairies Utilisés dans
l'implémentation 32
I.2 - Langages de programmation 32
I.3 - Quelques bibliothèques de python. 33
3- NumPy 33
4- TENSORFLOW 33
5- THEANO 34
6- KERAS 34
7- Scikit-learn 34
8- OS 35
9- OPENCV 35
10- MAXPOOLING 35
11- RELU 36
12- SOFMAX 36
II - METHODES DE RECONNAISSANCES 36
II.1 - Base de données d'empreinte digitale 36
II.2 - Le Prétraitement 37
|
Mémoire de Master option Bases de Données
et Génie Logiciel
|
|
II.2.1 - La Binarisation 38
II.3. Méthodologie utilisée 38
II.3.1. Les réseaux de neurones convolutifs 38
II.3.1.1. Définition 38
II.3.1.2. Les différentes couches des CNN 39
1- La couche de convolution 39
2- Couche de pooling (POOL) 40
3- Couches de correction (RELU) 41
4- Couche entièrement connectée (FC) 41
III.
ARCHITECTURE DE NOTRE RESEAU, ENTRAINEMENT ET
COMPILATION DU MODELE 41
1. Architecture de notre réseau 41
2. Compilation 43
3. L'entrainement 43
RESULTATS ET DISCUSSIONS 45
CHAPITRE V: RESULTATS ET DISCUSSIONS 46
1- RESULTAT 46
II. DISCUSSIONS 64
CONCLUSION 64
CONCLUSION ET PERSPECTIVES 66
REFERENCES BIBLIOGRAPHIQUES 67
| 

