Incidence du cout du risque de défaut sur les marges de taux des banques camerounaises( Télécharger le fichier original )par Joseph EVAGLE DIME Université de Yaoundé II-soa - Diplome dà¢â¬â¢Etudes Supérieures Spécialisées de Gestion Bancaire et des Etablissements Financiers 2007 |

Tableau 4 : Test de l'ADF
Source : Nos calculs Les variables MTB et PROCRED appartiennent respectivement aux modèles (3) et (2) du test d'ADF, ce qui signifie qu'elles présentent une tendance déterministe68(*), donc, elles ne sont pas stationnaires. En différenciant69(*) les variables MTB et PROCRED une fois, on se rend compte qu'elles deviennent stationnaires. Autrement dit, elles sont intégrées d'ordre 1. De l'analyse de la stationnarité des variables, il ressort qu'une régression70(*) linéaire sur les séries n'est pas appropriée parce qu'elles ne sont pas stationnaires. Pour étudier l'incidence des provisions pour créances douteuses sur les marges de taux, il est préférable de retenir un modèle VAR71(*) (Vector autoregressive model). La régression de séries temporelles, c'est-à-dire de variables indexées par le temps, peut poser des problèmes, en particulier à cause de la présence d' autocorrélation72(*) dans les variables, donc aussi dans les résidus. Lorsque les variables ne sont pas stationnaires, on aboutit au cas de régression fallacieuse: des variables qui n'ont aucune relation entre elles apparaissent pourtant significativement liées selon les régressions linéaires classiques. La régression de séries temporelles demande donc dans certains cas l'application d'autres modèles de régression, comme les modèles vectoriels autorégressifs (VAR) ou modèles à correction d'erreur (VECM). Le modèle VAR est une généralisation des modèles autorégressifs (AR) au cas multivarié. Dans un processus autorégressif d'ordre p, l'observation présente est générée par une moyenne pondérée des observations passées, jusqu'à la p-ième période. L'analyse multivariée par contre recouvre un ensemble de méthodes destinées à synthétiser l'information issue de plusieurs variables, pour mieux l'expliquer. Dans un modèle VAR, le phénomène observé s'explique par les variations des valeurs passées de la variable explicative et de celles de la variable à expliquer. L'étude préalable de la cointégration du modèle spécifié permet de retenir, soit un VAR simple, soit un VAR à correction d'erreur. I-2-2-Spécification du modèleLorsqu'il existe une relation de long terme (cointégration) entre les variables, il est impossible de retenir un modèle VAR simple à la place d'un modèle VAR à correction d'erreur ECM73(*) (Error Correction Model). Par conséquent, un test de cointégration est effectué afin de spécifier le type de VAR à adopter. I-2-2-1- Test de cointégrationLa cointégration permet de traiter les séries non stationnaires. Elle teste l'existence d'un équilibre75(*) de long terme entre plusieurs variables non stationnaires. La cointégration est basée sur deux conditions : 1°) l'ordre d'intégration des séries doit être le même ; 2°) la combinaison linéaire des séries doit donner une série d'ordre d'intégration inférieur ou égal à la différence en valeur absolue à l'ordre d'intégration des séries à étudier. Dans cette étude, les variables MTB et PROCRED sont toutes intégrées d'ordre 1, ce qui permet de leur appliquer le test de cointégration de Johansen. Il existe plusieurs tests de cointégration, mais le test de Johansen (1990) est généralement retenu dans la littérature parce qu'il est le plus général de tous76(*). * 67 Le LNPROCRED est utilisé pour des raisons d'échelle. Les PROCRED sont exprimés en millions, tandis que les MTB sont des unités. * 68 En règle générale, on distingue deux types de processus non-stationnaires : les tendances déterministes (Trend stationnary ou TS) et les processus non- stationnaires aléatoires (Differency stationnary ou DS). Une série est de type Trend Stationnary lorsqu'il faut supprimer la tendance pour la rendre stationnaire. De même, la série est de typre Differency Stationnary lorsqu'il faut la différencier pour la rendre stationnaire. * 69 Une série est dite intégrée d'ordre d s'il convient de la différencier d fois pour la rendre stationnaire. Différencier une série revient à réaliser la différence des valeurs de la série par rapport à sa valeur antérieure, soit DXt = Xt-Xt-1. * 70 En règle générale, la tendance constitue la composante la plus importante des séries chronologiques. Cette composante peut être étudiée à travers l'utilisation de techniques de lissage pour modérer les contrastes dans la représentation de l'évolution des valeurs de la variable étudiée, ou par les techniques de régression afin d'ajuster une tendance aux données de la variable étudiée. Lorsque la tendance de la chronique est déterministe, c'est-à-dire bien marquée, les méthodes de régression sont adaptées (Manga, 2006). * 71 Lorsqu'une série
comporte une tendance, l'ajustement de la tendance peut être
réalisé à l'aide d'une droite de type * 72 La corrélation de deux variables mesure leur dépendance réciproque. L'autocorrélation est un outil mathématique souvent utilisé en traitement du signal. Elle mesure les dépendances internes d'un signal, c'est - à- dire, la corrélation croisée d'un signal par lui-même. En présence d'autocorrélation, les estimateurs des Moindres Carrés Ordinaires sont sans biais, mais ne sont plus à variance Minimale et, les écarts types usuels des MCO et les tests ne sont plus valides. * 7374 « En 1987, Granger et Engel ont démontré que toutes les séries cointégrées peuvent être représentées par un modèle à correction d'erreur » (Manga 2005). Le modèle à correction d'erreurs est une forme particulière des modèles autorégressifs à retard échelonnés (ARDL). Il peut-être interprété à cet égard comme un modèle d'ajustement. A l'instar du modèle d'ajustement, le coefficient du terme d'erreur n'est pertinent que lorsqu'il est significatif et compris entre -1 et 0 (Voir Dupont L.). * 75 La notion d'équilibre renvoit à celle de stationnarité : pendant que l'économiste parle d'équilibre, le statisticien parle de stationnarité (Manga, 2006) * 76 Voir à ce sujet Dupont L, « Cointegration et causalité entre développement touristique, croissance, économique et réduction de la pauvreté : cas de Haïti. », The George Washington University, p.11. |
| ||||||||||||||||||||||||||||||||||||


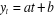 . Lorsque la variable
. Lorsque la variable  varie d'un montant absolu b d'une date a l'autre on a
varie d'un montant absolu b d'une date a l'autre on a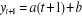 . Lorsque cette variable croit à un taux constant on ajuste la
tendance observée par une fonction de type
. Lorsque cette variable croit à un taux constant on ajuste la
tendance observée par une fonction de type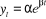 . Une autre procédure d'ajustement de la tendance est d'utiliser
un modèle de trend autorégressif, donné par
. Une autre procédure d'ajustement de la tendance est d'utiliser
un modèle de trend autorégressif, donné par 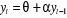 (Manga, 2006).
(Manga, 2006).