Mise en place d'un système informatisé pour la publication de résultats en lignepar Aristote ONJI KITOKO Institut supérieur de commerce de Bandundu - Graduat 2023 |

CONCLUSION PARTIELLENous sommes arrivés à la fin de notre premier chapitre qui porte sur l'approche théorique, il était concentré aux concepts informatiques, leurs définitions, nous avons aussi parlé de quelque notion de la programmation Web et la présentation complète l'institut KIKESA. Ce chapitre nous a également aidé à connaitre les fonctionnements, l'organisation de l'institut KIKESA pour la publication de résultat, son Historique, sa situation géographie. L'étape suivante nous allons aborder notre deuxième chapitre qui s'est intitulé : « conception du nouveau système d'information ». [32] CHAPITRE II : CONCEPTION DU NOUVEAU SYSTEME D'INFORMATIONINTRODUCTIONLa conception du nouveau système se fait étape par étape pour mettre en place un système d'informatisation, elle permet de mettre en place un modèle sur lequel on va s'appuyer. SECTION I : CONCEPTION DU SYSTEME D'INFORMATION ORGANISE.I.1.ETAPE CONCEPTUELLE DE DONNEES I.1.1. DEFINITION ET BUT Le modèle conceptuel des données (MCD) est une représentation statique de donnée qui a pour but d'écrire de façon formelle les données qui seront utilisées par le système d'information. Il s'agit donc d'une représentation des données, facilement compréhensible, permettant de décrire le système d'information à l'aide d'entités. (20) I.1.2. FORMALISME ET CONCEPTS DE BASE Le formalisme adopté par la méthode (merise) pour la description de données utilisée par le système d'information est basé sur l'entité À association, l'entité représente l'objet et association représente la relation. Une entité ou objet est représenté par un rectangle reprenant le nom de l'objet et toutes ses propriétés parmi lesquelles nous allons trouver l'identifiant qui est obligatoire souligner ou précédé du symbole #. Une relation est représentée par un cercle ovale avec le nom de la relation ainsi que ses propriétés. Cardinalité elle précise le nombre de fois une entité ou objet participe dans une relation. Elle est composée de deux parties (borne) maximum et minimum. 20 Encyclopédie informatique comment ça marche. [33] I.I.2.1. FORMALISME Cardinalité
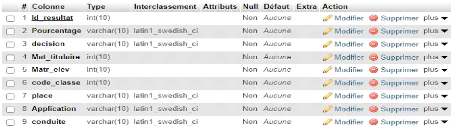
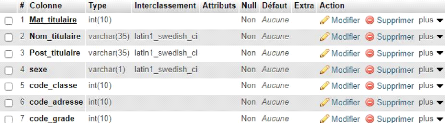
Objet A Objet B identifiant propriété 1 identifiant propriété 1 - - x,y - Relation - x,y - - Propriété N Propriété N Cardinalité Figure 14 Formalisme étape conceptuelle de donnée minimale I.I.2.2. CONCEPTS DE BASE Les concepts de base utilisés dans la modélisation conceptuelle de données sont : Â Objet : est une entité concrète ou abstraite ayant une existence autonome et présentant un certain intérêt dans un domaine de gestion donné. Autrement dit c'est un regroupement des propriétés. (21) Â Association ou relation : est un lien sémantique entre plusieurs entités. Elle est souvent exprimée sous forme de verbe à l'infinitif ou d'une locution verbale et cela, dans un cercle ovale. Â Propriété (attribut ou rubrique) : est une donnée élémentaire qui décrit un objet ou une entité. Â Identifiant : c'est une propriété permettant de distinguer une entité parmi tant d'autres et sans ambigüité. Â Cardinalités : Elle permet de caractériser le lien qui existe entre une entité et la relation à laquelle elle est reliée. La cardinalité d'un objet par rapport à une relation s'exprime par deux nombres appelés cardinalité minimale et cardinalité maximale. (21) CHRIST, J., Introduction de la base de données, 6ème Ed. Thomson, Paris, 1998, P.11 [34] ? Contrainte de cardinalité : exprime le nombre de fois minimum et maximum que l'objet participe dans une relation ; ? Contrainte d'Intégrité Fonctionnelle (CIF) : est une contrainte de cardinalité du type (0,1) ou (1,1) d'une part et de (0, n) ou (1, n) d'autre part. I.1.3. REGLES DE GESTION En ce qui concerne la gestion de publication des résultats des élèves, les règles de gestion suivantes ont été prises en compte : Règle 1 : - Un titulaire publie un ou plusieurs résultats; - Un résultat est publié par un et un seul titulaire. Règle 2 : - Un élève consulte un ou plusieurs résultat; - Un résultat est consulté par un et un seul élève ; Règle 3 : - Un élève étudie dans une et une seul classe ; - Dans une classe étudie un ou plusieurs élèves. Règle 4 : - Un titulaire appartient à une ou plusieurs classe; - Dans une classe appartient un et un seul titulaire. Règle 5 : - Un résultat concerne une et une seule classe; - Une classe est concernée par un ou plusieurs résultats. Règle 6 : - Une classe se trouve dans une et une seule option; - Dans une option se trouve une ou plusieurs classes. [35] I.1.4. DICTIONNAIRE DE DONNEES Tableau 3: Dictionnaire de données
I.1.5. RECENSEMENT ET DESCRIPTION DES OBJETS Un objet est une entité concrète ou abstraite ayant une existence autonome et présentant un certain intérêt dans un domaine de gestion donnée. (22) I.1 .5.1 . RECENSEMENT DES OBJETS En ce qui concerne notre étude, nous avons recensé les objets ci- dessous : ? Elève ; ? Classe ; ? Titulaire; ? Résultat ; ? Option. (22) Roche et Majorony, la Méthode Merise, 2e édition, Ex-Raller, Paris, 1998 [36] I.1 .5.2. DESCRIPTION DES OBJETS Tableau 5: Description des objets
I.1 .6. RECENSEMENT ET DESCRIPTION DES RELATIONS I.1.6.1. RECENSEMENT DES RELATIONS En ce qui concerne notre étude, nous avons recensé les relations ci-dessous : Â Publier ; Â Consulter ; Â Etudier ; Â Appartenir ; Â Concerner ; Â Trouver. [37] I.1 .6.2. DESCRIPTION DES RELATIONS Tableau 6: Description des relations.
I.1 .7. LES CONTRAINTES Une contrainte est un ensemble des règles spécifiant les valeurs permises pour certaines données, éventuellement en fonction des autres données permettant d'assurer une cohérence de la base de données. (23) Il en existe plusieurs type de contrainte que nous pouvons énumérer ci-dessous : ? Contrainte d'intégrité fonctionnelle : Elle sert à minimiser le nombre de caractères à stocker dans les mémoires de masse ; Elle permet aussi la recherche rapide des informations dans la base de données. ? Contrainte de cardinalité : Elles s'appliquent pour les cardinalités du type : 0, n et 1, n ou 1, n et 1, n. ? Les contraintes d'intégrité référentielle : Elles imposent que la valeur d'une clé étrangère d'une table, existe comme valeur de clé primaire dans la table à laquelle elle fait référence. I.1 .7.1 . CONTRAINTE DE CARDINALITE Caractérise le lien qui existe entre une entité et la relation à laquelle elle appartient. D'une manière générale les différentes cardinalités sont : 0,1 : l'occurrence participe à la relation zéro ou une fois ; 1,1 : l'occurrence participe à la relation une et une seule fois ; 0,n : l'occurrence participe à la relation zéro ou plusieurs fois ; 1,n : l'occurrence participe à la relation une ou plusieurs fois. (23) KITOKO, Notes de Cours de Méthode d'Analyse Informatique II, G3 info,ISC/KIN, 2021, p.57 inédit [38] I.1 .7.2. CONTRAINTE D'INTEGRITE FONCTIONNELLE On parle de contrainte d'intégrité fonctionnelle (CIF) c'est lorsqu'il y'a dépendance d'une entité (objet) par rapport à l'autre et est souvent représentée en paires. (1,1)-(1,n) ou (0,1)-(0,n). I.1.7.3. TABLEAU DESCRIPTIF DES CONTRAINTES Tableau 7: Descriptif des contraintes.
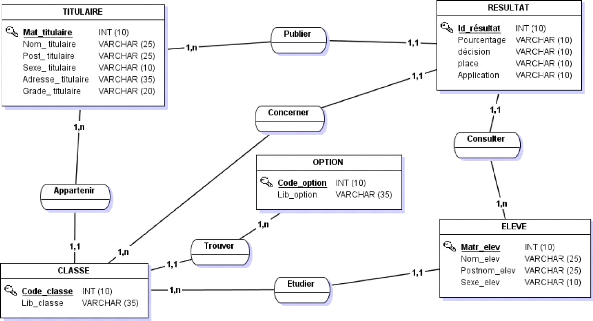
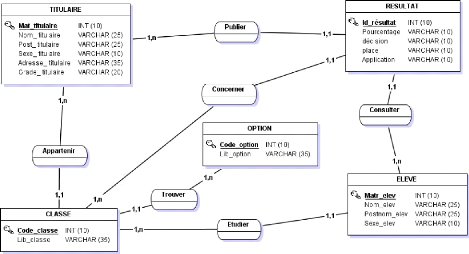
[- 39 -] I.1.8. PRESENTATION DU MODELE CONCEPTUEL DE DONNEES (MCD)
Figure 15 Présentation du MCD [- 40 -] I.2. ETAPE CONCEPTUELLE DE TRAITEMENTSI.2.1. DEFINITION ET BUT Le modèle conceptuel de traitement est un modèle permettant de représenter de façon schématique l'activité d'un système d'information sans faire référence à des choix organisationnels ou des moyens d'exécutions. C'est à dire qu'il permet de définir simplement ce qui doit être fait, mais il ne dit pas quand comment et où. (24) I.2.2. FORMALISME ET CONCEPTS DE BASE DU MCT Le Formalisme E-O-R est utilisé par la méthode MERISE et signifie « Evénement, Opération, Résultat et Synchronisation ». 1i Evénement : Un événement est défini comme un fait qui déclenche une action (opération). Il est symbolisé par un cercle ovale. 1i L'opération : La réponse à l'arrivé d'un événement est le déclenchement d'un ensemble de traitement appelé opération.
1i Résultat : C'est le produit de l'exécution d'une opération. En d'autres termes, le résultat est la réponse générée par une opération. 1i Synchronisation : c'est une condition booléenne traduisant les règles de gestion qui doivent vérifier les événements pour déclencher les actions. (25)
1i Règle d'émission : On parle d'une règle d'émission C'est une condition, traduisant les règles de gestion, qui permet d'exprimer des conditions de sortie des résultats.
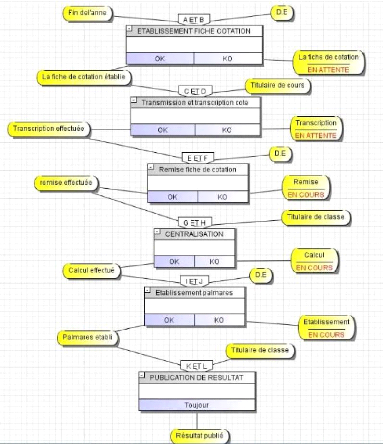
[41] 1.2.3. RECENSEMENT DES OPERATIONS Avec l'étude menée dans ce travail, nous avons recensé les opérations ci-après : Â Etablissement fiche de cotation ; Â Transmission et transcription cote ; Â Remise fiche de cotation ; Â Centralisation ; Â Etablissement palmarès ; Â Publication de résultat. I.2.4. PRESENTATION DU MODELE CONCEPTUEL DE TRAITEMENTS (MCT)
Figure 16 Présentation Modèle Conceptuel de Traitement. [42] I.3. ETAPE ORGANISATIONNELLE Le niveau organisationnel implique la prise de décisions concernant l'organisation des ressources humaines et matérielles, notamment en définissant les sites et les postes de travail (26). Le modèle organisationnel des données est une représentation des informations qui seront stockées informatiquement, en utilisant le formalisme entité-relation. Il tient compte des volumes, de la répartition et de l'accessibilité des données, sans encore considérer les contraintes de structure, de stockage et de performance liées à la technologie de stockage qui sera utilisée. Sur cette étude comme la méthode MERISE sépare les données ainsi que le traitement dans ce cas nous aurons (27) : Â Modèle organisationnel des données (MOD) ; Â Modèle organisationnel des traitements (MOT). I.3.1. ETAPE ORGANISATIONNELLE DE DONNEES La modélisation organisationnelle des données consiste à inclure les éléments liés à l'utilisation des ressources de stockage. Â La réparation dans l'organisation ; Â La modalité d'accès aux données ; Â La réparation d'exécution de traitement en tenant compte de l'organisation. Toutes ces préoccupations nous conduisent à définir Deux niveaux de modélisation organisationnelle de données. ? Le MOD Global, directement dérivé du modèle conceptuel des données, ? Le MOD valide, spécifique à une unité organisationnelle. Le MOD valide est dérivé du modèle global en prenant en compte des choix d'organisation, en particulier de répartition I.3.2. SCENARIOS D'ORGANISATION Sur ce point nous pouvons citer quelques scripts de manipulation de donnée qui sont beaucoup plus utilisé :
[43] ? Create cette requête permet de créer un type de donnée. ? INSERT : c'est une requête pour insérer ou ajouter un enregistrement dans la base de donnée; ? SELECT : cette requête permet de sélectionner un enregistrement ; ? UPDATE : permet de modifier un enregistrement ; ? DELETE : Permet de supprimer un enregistrement. I.3.3. PASSAGE DU MCD AU MOD Il s'agit ici de choisir, à partir des données formalisées sur le modèle conceptuel des données, celles qui devront être effectivement mémorisées informatiquement dans le système d'information informatisé. Le modèle organisationnel des données ainsi obtenu est de niveau global et ne prend pas en compte les choix d'utilisation reparties. Les règles de passage du modèle conceptuel des données au modèle organisationnel des données sont les suivantes :
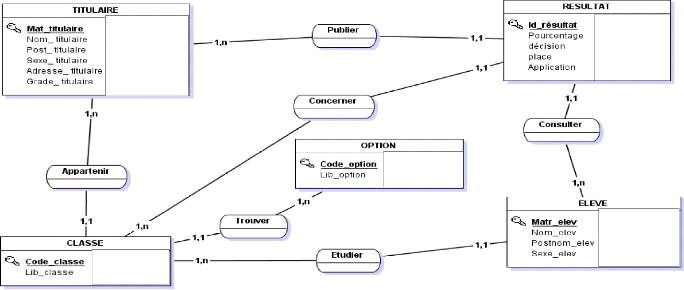
? Pour permettre de faire le lien entre les données mémorisées et les données restées manuelles ; par exemple la référence des fiches, des dossiers, etc. ; ? Pour mémoriser des états du système d'information, consécutifs au déroulement des traitements dans le MOT. En ce qui concerne notre domaine d'application, tous les objets et relation de MCD seront mémorisables sur des supports informatiques. D'où le MCD vaut le MOD global. [44] I.3.4. PRESENTATION DU MOD GLOBAL
Figure 17 Présentation MOD GLOBAL. I.3.5. EVALUATION DU VOLUME DU MOD GLOBAL Il s'agit ici de définir les caractéristiques et les limites des propriétés, ainsi que les contraintes sur les valeurs et le nombre d'occurrences des entités et des relations. Cette quantification est statique et permet principalement d'estimer initialement le volume de données à stocker. Le volume du MOD se fait principalement au niveau du MOD global. [45] I.3.5.1. QUANTIFICATION DES CARDINALITES MULTIPLES Tableau 4: Quantification des cardinalités multiples
A ce niveau, le travail du concepteur consiste à quantifier les cardinalités maximales (n) afin de calculer la cardinalité moyenne (CM) et le taux de participation (P). Pour y arriver, les formules sont les suivantes : P " CM= ((min+2 x Mo + max)/4)*P  Max : la cardinalité maximale  Mo : la valeur modale  Cm : la cardinalité moyenne  P : Taux de participation  Min : valeur minimale [46] La Cardinalité Moyenne d'un objet contenant la cardinalité (1,1) est toujours égale à 1. Tandis que la Cardinalité Moyenne d'un objet ayant pour cardinalité (0,1) est égale au taux de Participation. I.3.5.2. TABLEAU DES CARDINALITES ET TAUX DE PARTICIPATION Tableau 5: Tableau des cardinalités et taux de participation
I.3.5.3. CALCUL DU VOLUME DU MOD GLOBAL Le calcul de volume du MOD GLOBAL nous aide à prendre des décisions sur les types de supports de stockages et à déterminer les données qui seront stockées dans notre base de données. Le volume obtenu sera multiplié par un coefficient multiplicateur qui varie entre 2 et 3. Dans notre cas nous avons choisi un juste milieu (2,5). Calcul du volume des objets : Volume=Effectif * taille Tableau 6: Calcul du volume des objets
Volume Total du MOD global = 583 450 Octets x 2,5= 1 458 625 Octets = 1424,43 Mo [47] ? Répartition organisationnelle des données : MOD locaux La répartition organisationnelle des données est nécessaire lorsque le système d'information doit être utilisé sur plusieurs sites. Cependant, dans notre étude, toutes les opérations du système d'information se déroulent sur un seul site. Par conséquent, notre modèle organisationnel de donnée est considéré comme local, mais nous allons tout de même ajouter des mesures de sécurité pour protéger les données. ? L'accessibilité et la prise en compte de la sécurité du MOD L'accessibilité des données d'un MOD local s'exprime par les actions élémentaires que peuvent effectuer sur ce sous-ensemble de données les traitements réalisés dans le site organisationnel. Ces différents types d'accès, en Lecture ou consultation (L), Modification ou écriture (M), Création (C), Suppression (S) Sont précisés sur le MOD. Pour ce qui est de la sécurité des données définit des restrictions d'accès aux données mémorisées pour certaines catégories d'utilisateurs. Ces restrictions peuvent être un type limité d'actions (L, M, C, S) soit aux entités, relations ou propriétés du MOD global ou local, soit à une sous-population des occurrences d'entités ou des relations. La sécurité d'accès comprend la limitation d'actions à certaines personnes et intègre aussi les aspects de confidentialité. La sécurité d'accès passe par la définition de catégories ou de profils d'utilisateurs. Pour chaque profil, on précise les éventuelles restrictions d'accès envisagées. [48] I.3.5.4.SCHEMA DE SECURITE DES DONNEES DE LA PROCEDURE FONCTIONNELLE
L C S L M C S
L C S L M C Figure 18 Schéma de sécurité des données de la procédure fonctionnelle [49] I.4. ETAPE ORGANISATIONNELLE DES TRAITEMENTS Lors de l'étape organisationnelle du traitement, nous divisions les opérations en procédures fonctionnelles, qi sont une séquence de traitements déclenchés par un évènement spécifique. Pour faciliter cela, nous associons les procédures fonctionnelles à une heure de début et une de fin dans un tableau. Cela nous permet de visualiser la séquence des opérations et de planifier efficacement leur exécution. Le MOT permet de représenter l'ensemble des traitements en prenant en compte l'organisation de l'entreprise. Celle-ci sera matérialisée par les postes de travail. Chaque poste de travail correspond à une unité d'action élémentaire dotée des moyens d'exécution : moyen en personnel et moyen de traitement automatique selon les cas. Il complète la description conceptuelle des traitements en intégrant tout ce qui est d'ordre organisationnel dans le domaine étudié. Le Modèle Organisationnel des Traitements précise ou répond aux 3 questions suivantes : ? QUI ? : consiste à définir l'acteur qui fera le traitement :
? QUAND ? : consiste à définir la périodicité du déroulement des tâches qui peut être : journalière, hebdomadaire, décadaire, mensuelle, trimestrielle, semestrielle, annuelle, apériodique, etc. ? OU ? : permet de donner l'endroit où se déroulera le travail. En effet, un poste de travail constitue l'unité d'action élémentaire de l'entreprise qui est identifiée soit par la fonction qu'elle remplit, soit par les moyens qu'elle emploie [50] I.4.1. PASSAGE DU MCT AU MOT Ce passage est ténu en respectant les conditions suivantes :
3) Transformer le vocabulaire : les opérations deviennent des tâches et les processus des procédures fonctionnelles. Plusieurs tâches exécutées dans un même poste de travail deviennent une phase. I.4.2. PRESENTATION DES PROCEDURES FONCTIONNELLES Tableau 7: Présentation des procèdures fonctionnelles
[51] I.4.3. MODELISATION ORGANISATIONNELLE DES TRAITEMENTS Tableau 8: Presentation des procedures fonctionnelles
(28) PANET G.et LE TOUCHER R. Merise2 : Modèle et techniques merise avancée, édition organisation, Paris 2010, P 101. [52] SECTION II : CONCEPTION DU SYSTEME D'INFORMATION INFORMATISE. A ce stade nous allons répondre à la question « Comment » ce qui veut dire comment allons concevoir le système d'information informatisé répondant aux spécifications définies précédemment. II.1. ETAPE LOGIQUE DE DONNEES Le modèle logique des données consiste à décrire la structure de données utilisée sans faire référence à un langage de programmation. Il s'agit donc de préciser le type de données utilisées lors des traitements. Ainsi, le modèle logique dépende du type de base donnée utilisé. II.1 .1. DEFINITION ET BUT A ce niveau il est question de produire le modèle logique de données qui va décrire la structure permanente de données dans un formalisme compatible avec l'implémentation physique dans un SGBD. (28) II.1 .2. PASSAGE DU MOD AU MLD
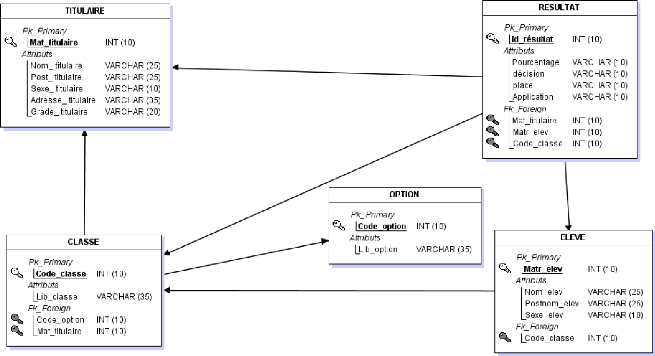
? 1er Cas : relation du type père-fils : contrainte d'intégrité fonctionnelle (CIF). Ce cas intervient, dans le MCD, lorsque nous retrouvons les couples (0,1) ou (1,1), d'une part, et (0,n) ou (1,n) d'autre part. Il peut y avoir les combinaisons suivantes : (1,1) et (1, n) (0, n) et (1, 1) (0,1) et (1, n) (0, n) et (0, 1) [53] Dans ce cas, la relation disparait mais sa sémantique demeure, car l'objet qui a la cardinalité (0,n) ou (1,n) est considère comme père cède son identifiant à l'objet fils (c.à.d. : l'objet ayant cardinalité (0,1) ou (1,1)) . Etant données que le fils possède une clé primaire, celle qu'elle hérite de son père est une clé étrangère parce qu'elle est la clé primaire dans sa table respective. Si la relation était porteuse des propriétés, elles migrent vers la table fils. ? 2ème cas : les relations du type autre que père et fils : contrainte d'intégrité multiple (CIM). Ce cas intervient lorsqu'on a d'une part le couple (o,n) ou (1,n), et d'autre part (o,n) ou (1,n). C'est-à-dire les combinaisons ci-après : (o,n) et (o,n) (1,n) et (1,n) (o,n) et (1,n) Dans ce cas, la relation devient une table de lien qui aura comme clé primaire la concaténation des identifiants des objets qu'elle reliait. Et si la relation était porteuse des propriétés, celles-ci deviennent des attributs de la nouvelle table. 3ème cas : les relations du type monstre ou fantôme : (1,1 À 1,1) : Dans ce cas, le père cède son identifiant au fils et vice versa, ensuite, la relation disparait. [54] II.1 .3. PRESENTATION DU MODELE LOGIQUE DE DONNEES BRUT (MLDB)
Figure 19 Présentation du modèle logique de données brut (MLDB) (29) MVIBUDULU, JA , KONKFIE,LD., Technique de base de données, étude et cas, 2ème Ed. CRIGED, Kinshasa, 2012. [55] II.1.4. NORMALISATION DU MLD BRUT La normalisation est un processus qui consiste à éliminer les dernières redondances et les valeurs nulles dans une table. En d'autre mot, la normalisation consiste à limiter le risque d'incohérences potentielles. Il existe cinq formes dites formes normales. Toutefois en pratique l'on se limite uniquement aux trois premières formes normales constituées des cas particuliers de la deuxième et troisième forme normale. En plus, pour arriver à la troisième forme normale, l'on est sûr d'avoir minimisé les risques de redondance.(29) Les formes normales 1ère forme normale (1FN) Une table est en première forme normale si elle a une clé primaire et que tous ses attributs non clés sont élémentaires, c'est à dire non décomposables et non répétitifs. 2ème forme normale (2FN) Une table est en deuxième forme normale, si elle est déjà à la 1FN et que ses attributs non clés dépendent pleinement ou totalement de la clé primaire. 3ème forme normale (3 FN) Une table est en 3ème troisième forme normale lorsqu'elle est déjà en deuxième forme normale et que ses attributs non clés dépendent directement de la clé primaire sans transition. Garder dans la table initiale les attributs dépendant directement de la clé primaire. Regrouper dans une autre table, les attributs dépendants transitivement de la clé primaire. L'attribut de transition reste dupliqué dans la relation initiale, et devient la clé primaire de la nouvelle relation. NB : En regardant tout ce qui précède, nous constatons que la table Titulaire n'est pas à la 3ème forme normale, car, l'attribut Adresse et grade dans la table Titulaire ne sont pas élémentaires, ils sont décomposable. Mais les restes des tables, respectent parfaitement les 3 formes normales. [56] II.1 .5. PRESENTATION DU MODELE LOGIQUE DE DONNEES VALIDE (MLDV)
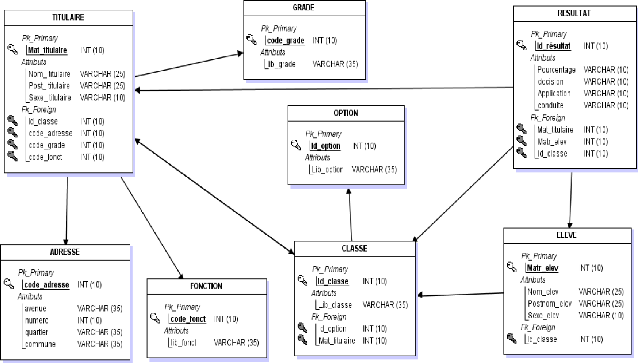
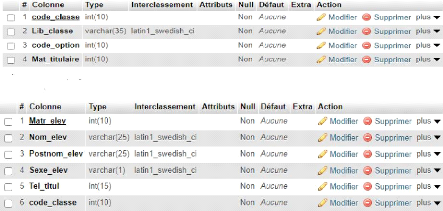
Figure 20 Présentation du modèle logique de données valide (MLDV) [57] II.1.6. SCHEMA RELATIONNEL ASSOCIE AU MLD VALIDE # Script MySQL. # Table: OPTION CREATE TABLE OPTION( Code_option Int NOT NULL , lib_option Varchar (10) NOT NULL ,CONSTRAINT OPTION_PK PRIMARY KEY (Code_option) )ENGINE=InnoDB; # Table: ADRESSE CREATE TABLE ADRESSE( Code_adresse Int NOT NULL , avenue Varchar (35) NOT NULL , numero Varchar (10) NOT NULL , quartier Varchar (35) NOT NULL , commune Varchar (35) NOT NULL ,CONSTRAINT ADRESSE_PK PRIMARY KEY (Code_adresse) )ENGINE=InnoDB; # Table: GRADE CREATE TABLE GRADE( code_grade Int NOT NULL , lib_grade Varchar (10) NOT NULL ,CONSTRAINT GRADE_PK PRIMARY KEY (code_grade) )ENGINE=InnoDB; # Table: TITULAIRE CREATE TABLE TITULAIRE( Mat_titulaire Int NOT NULL , Nom_titulaire Varchar (35) NOT NULL , post_titulaire Varchar (35) NOT NULL , Sexe Varchar (10) NOT NULL , Grade_tit Varchar (35) NOT NULL , Code_adresse Int NOT NULL , code_grade Int NOT NULL ,CONSTRAINT TITULAIRE_PK PRIMARY KEY (Mat_titulaire) ,CONSTRAINT TITULAIRE_ADRESSE_FK FOREIGN KEY (Code_adresse) REFERENCES ADRESSE(Code_adresse) ,CONSTRAINT TITULAIRE_GRADE0_FK FOREIGN KEY (code_grade) REFERENCES GRADE(code_grade) )ENGINE=InnoDB; # Table: CLASSE CREATE TABLE CLASSE( Id_classe Int NOT NULL , [58] Lib_classe Varchar (35) NOT NULL , Mat_titulaire Int NOT NULL , Code_option Int NOT NULL ,CONSTRAINT CLASSE_PK PRIMARY KEY (Id_classe) ,CONSTRAINT CLASSE_TITULAIRE_FK FOREIGN KEY (Mat_titulaire) REFERENCES TITULAIRE(Mat_titulaire) ,CONSTRAINT CLASSE_OPTION0_FK FOREIGN KEY (Code_option) REFERENCES OPTION(Code_option) )ENGINE=InnoDB; # Table: ELEVE CREATE TABLE ELEVE( Mat_elev Int NOT NULL , Nom_elev Varchar (25) NOT NULL , Postnom_elev Varchar (25) NOT NULL , Sexe_elev Varchar (10) NOT NULL , Id_classe Int NOT NULL ,CONSTRAINT ELEVE_PK PRIMARY KEY (Mat_elev) ,CONSTRAINT ELEVE_CLASSE_FK FOREIGN KEY (Id_classe) REFERENCES CLASSE(Id_classe) )ENGINE=InnoDB; # Table: RESULTAT CREATE TABLE RESULTAT( Id_resultat Int NOT NULL , Pourcentage Varchar (10) NOT NULL , decision Varchar (10) NOT NULL , place Varchar (10) NOT NULL , Conduite Varchar (10) NOT NULL , Mat_titulaire Int NOT NULL , Id_classe Int NOT NULL , Mat_elev Int NOT NULL ,CONSTRAINT RESULTAT_PK PRIMARY KEY (Id_resultat) ,CONSTRAINT RESULTAT_TITULAIRE_FK FOREIGN KEY (Mat_titulaire) REFERENCES TITULAIRE(Mat_titulaire) ,CONSTRAINT RESULTAT_CLASSE0_FK FOREIGN KEY (Id_classe) REFERENCES CLASSE(Id_classe) ,CONSTRAINT RESULTAT_ELEVE1_FK FOREIGN KEY (Mat_elev) REFERENCES ELEVE(Mat_elev) )ENGINE=InnoDB; [59] II.1.7. ESTIMATION DU VOLUME DE LA BASE DE DONNEES II.1.7.1. Calcul du volume des tables On calcule le volume d'une table en multipliant l'effectif de cette table par sa taille. D'où : N*Taille Tableau 9: Calcul du volume des tables
[60] II.2. ETAPE LOGIQUE DES TRAITEMENTS La modélisation logique de traitements est un processus qui consiste à créer des représentations abstraites des traitements informatiques dans un domaine donné. Cela comprend la création de modèles et de schémas qui décrivent en détail les différentes étapes nécessaires à la construction d'une solution technique répondant aux spécificités et aux besoins du modèle organisationnel des traitements. En d'autres termes, il s'agit de concevoir des plans logiques pour mettre en oeuvre des processus informatiques qui répondent aux besoins et aux exigences du domaine traité. II.2.1. CONCEPTION DU MLT Le formalisme de la conception du MLT utilise les concepts
? Site organisationnel : c'est le lieu où s'effectue un traitement autonome utilisant une ou plusieurs machines logiques. ? Machine logique : Une machine logique est définie comme un ensemble de ressources informatiques (matériel et logiciel) capables d'exécuter des traitements informatiques de façon autonome. ? Unité logique de traitement (ULT) : c'est une partie d'une tâche logique qui est exécutée d'une manière
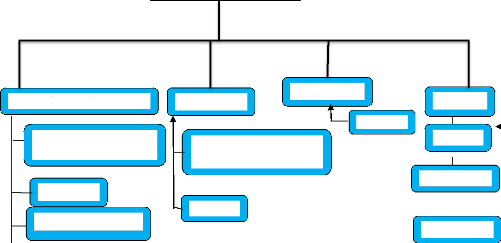
autonome. II.2.2. DECOMPOSITION DES TACHES DU MOT Le Modèle Logique des Traitements (MLT) est une représentation plus détaillée des traitements informatiques par rapport au Modèle Conceptuel de Données (MCD). Il permet d'ajouter des informations spécifiques qui ne sont pas fournies dans le MCD, telles que la durée, les ressources, le lieu, etc. Le MLT répond aux questions suivantes : Qui?, Où?, Comment?, Quand?, Le MLT se concentre sur les opérations clés nécessaires pour répondre aux besoins du domaine. Il peut inclure une ou plusieurs opérations en fonction des exigences spécifiques. Le MLT fournit des détails sur les différentes étapes, les acteurs impliqués, les ressources nécessaires, le calendrier et les lieux d'exécution des traitements informatiques. [61] En résumé, le MLT étend les informations fournies par le MCD en ajoutant des détails spécifiques sur les différentes dimensions des traitements informatiques, afin de mieux les modéliser et les planifier. II.2.3. DESCRIPTION DES ULT II.2.3.1. UTL O1 : Page d'accueil
ULT 01 Affiche des images de carrousel et historique de l'institut Démarrage du site de l'institut KIKESA Page d'accueil
Accueil Communiqué ULT 04 ULT 02 ULT 03 publication Admin
II.2.3.2. UTL O2 : COMMUNIQUE Cette partie permet aux internautes/élevés de connaitre toutes les nouvelles de l'école et les nombres des élèves par chaque option. ULT 02 option Affiche des informations ayant trait avec l'école ULT 02 ou Communiqué Quitter
ULT 02 Figure 22 (Ult 02) Communiqué Figure 21 (Ult 01) Page d'accueil [62] II.2.3.3 : (UTL O3) Publication Cette partie permet aux élèves et aux parents de consulter le résultat à partir du site. Figure 23 (Ult 03) Publication II.2.3.4 : (UTL O4) Admin
ULT 03 Consultation de résultat valider ULT 03 oui Publication Quitter
ULT 03 C'est la partie du gestionnaire (celui qui gère le site, il a la possibilité d'ajouter, modifier, supprimer.
ULT 04 Gestionnaire du
site ULT 04 oui Admin Quitter
ULT 04 Figure 24 (Ult 04) Admin [63] II.3. ETAPE PHYSIQUE DE DONNES II.3.1. DEFINITION ET BUT Le but modèle physique des données (MPD) est le transfert de la base de données dans le système de gestion de base de données (SGBD) choisi pour la réalisation du système d'information. II.3.2. REGLES DE PASSAGE DU MLDV AU MPD La mise en place du MLD nécessite trois principales règles (En d'autre terme, il s'agit de règles de passage de MLD vers MPD) : ? Les tables deviennent des Fichiers ? La clé primaire devient la clé d'accès au Fichier ? Les attributs deviennent des Champs. II.3.3. PRESENTATION DU MODELE PHYSIQUE DE DONNEES (MPD)
[64]
Figure 25 presentation de MPD II.4. ETAPE PHYSIQUE DES TRAITEMENTS Dans cette phase, nous sommes obligés de présenter une solution technique pour construire l'application. Le modèle physique de traitements se reconstruit à partir de modèle logique de traitements. [- 65 -] II.4.1. PRESENTATION DU MPT
Page d'accueil
Retour
Page d'accueil Option organisée Objectif Historique de l'institut kikesa Communiqué Retour Nombre des élèves par option Publication Retour Page Admin Admin Retour Login Figure 26 Presentation du mpt |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||