II-
Résultats d'estimation du modèle d'étude et test de
spécification
Nous présentons les résultats obtenus des
différentes estimations du modèle à court terme et du
modèle à long terme, et mettons en exergue les tests de
spécification.
A- Différents résultats de
spécification des modèles de long terme et de court terme
1- Résultats du modèle de
long terme
L'estimation de notre modèle de long terme est
réalisée sur une période 1990-2015, soit un
échantillon de 26 observations. Nous avons utilisé le logiciel
eviews 8 pour estimer notre modèle. L'estimation de cette relation de
long terme a consisté à mener plusieurs régressions afin
d'en déduire celle dont les variables auraient un pouvoir explicatif
meilleur. Ce faisant après une première régression, nous
avons enlevé au fur et à mesure les variables dont le pouvoir
prédictif était faible, jusqu'à obtenir le modèle
satisfaisant. La première variable retirée était le taux
de scolarisation. Puis nous avons retiré la variable POP. Le nouveau
modèle se ramenait donc à six variables indépendantes au
lieu de huit. Et les six variables étaient toutes significatives.
Seulement par la suite le nouveau modèle ne s'est pas montré
stable à long terme, en plus d'autres entorses. C'est ainsi que nous
nous sommes finalement résolu à utiliser le modèle de
départ.
Tableau 17:
résultats du modèle de long terme
|
Variables explicatives
|
Coefficients (probabilités)
|
|
C
|
5.359947
(0.0000)
|
|
LogM2
|
0.267618**
(0.0179)
|
|
LogCP
|
0.094930**
(0.0231)
|
|
Kp
|
-0.027766**
(0.0198)
|
|
logCO
|
0.114151
(0.1621)
|
|
logDPU
|
-0.185046
(0.2070)
|
|
SCO
|
-0.000152
(0.8296)
|
|
TINF
|
-0.001162**
(0.0375)
|
|
POP
|
-0.058406
(0.4039)
|
|
R2
|
0.921067
|
|
R2 ajusté
|
0.883922
|
|
F-statistic
|
24.79652
|
|
Prob (F-statistic)
|
0.000000
|
|
Durbin-watson stat
|
1.355332
|
Source : auteur
NB : les valeurs entre parenthèses sont les
probabilités, * représente la significativité à
10%, ** signifie la significativité au seuil de 5%, tandis que ***
représente la significativité au seuil de 1%.
L'estimation de notre modèle nous amène à
écrire le modèle suivant :
LogPIB = â0 + â1*logM2 +
â2*logCP + â3*KP + â4*logCO
+ â5*logDPU + â6*SCO â7*TINF
+ â8*POP + åt
Après substitutions des coefficients par leurs valeurs
respectives, le modèle estimé devient :
LogPIB = 5.35994730857 + 0.267617629954*logM2 +
0.0949300408495*logCP - 0.0277660799737*KP + 0.114150865077*logCO -
0.185045956772*logDPU - 0.000151626599424*SCO - 0.00116237615008*TINF -
0.0584062489537*POP
Figure 16 : évolution du PIB et de ses
variables explicatives
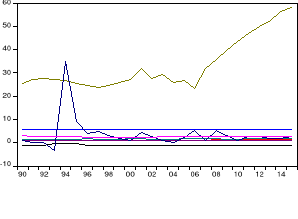
Source : auteur
L'analyse des différents coefficients de cette
équation sera faite dans la section consacrée aux
interprétations. Mais en considérant les résidus issus de
cette relation de long terme, lesquels résidus s'étaient
révélés stationnaires en niveau, nous pouvons utiliser le
modèle à correction d'erreur. Cela nous permet d'effectuer la
régression dynamique, objet de cette section.
| 

