|
République Algérienne Démocratique et
Populaire
Ministère de l'Enseignement Supérieur et de la
Recherche Scientifique
Centre Universitaire Cheick Larbi Tébessi
TEBESSA
Département d'Informatique
MEMOIRE
Présenté en vue de l'obtention du diplôme
de magister en informatique
Option : Systèmes d'Informations
Avancés
et Systèmes à Base de Connaissances
Modélisation par un système
multi-agents d'un hypermédia éducatif
adaptatif dynamique
Par
Mounir Beggas
Soutenu le 14 Avril 2005 devant le jury
|
Pr. Mahmoud Boufaïda
|
Président
|
Professeur, Université de Constantine
|
|
Pr. Mohamed Tayeb Laskri
|
Rapporteur
|
Professeur, Université de Annaba
|
|
Pr. Zizette Boufaïda
|
Examinateur
|
Professeur, Université de Constantine
|
|
Dr. Amar Balla
|
Examinateur
|
Maître de Conférence INI Oued Smar Alger
|
MEMOIRE
Présenté en vue de l'obtention du diplôme
de magister en informatique
Option : Systèmes d'Informations
Avancés
et Systèmes à Base de Connaissances
Modélisation par un système
multi-agents d'un hypermédia éducatif adaptatif
dynamique
Par
Mounir Beggas
Résumé
Les systèmes hypermédias adaptatifs sont utiles
dans tout domaine où les utilisateurs ont différents buts et
connaissances dont l'hyperespace est considérablement large. Ils forment
un domaine de recherche pour plusieurs applications : systèmes
d'information en ligne, systèmes d'aide en ligne, assistants personnels
et moteurs de recherche etc. L'un des premiers domaines d'application des
hypermédias adaptatifs sont les hypermédias éducatifs.
Les agents fournissent plusieurs avantages, l'autonomie, la
flexibilité, la communicabilité. Les agents ont été
utilisés dans une variété de champs qui ont une
similarité avec les systèmes hypermédias éducatifs
adaptatifs : agents personnels, agents de filtrage de courriers,
systèmes tutoriels intelligents basés agents, hypermédias
adaptatifs basés agents, etc. Aussi, cette technologie a vu un vaste
succès dans le web.
Dans ce travail, on présente une modélisation
d'un hypermédia adaptatif dynamique éducatif par un
système multi agents. Ce système génère
dynamiquement les pages hypermédias de cours, ces pages s'adaptent au
modèle de l'apprenant. Il utilise les activités
pédagogiques pour présenter plusieurs vues d'un même
concept et spécifier les tâches définissant la structure la
mieux adaptée pour comprendre les concepts à enseigner.
Ce système est constitué de quatre agents :
agent de modèle de l'apprenant, qui incorpore et manipule le
modèle de l'apprenant, l'agent pédagogique d'adaptation, qui
incorpore le modèle du domaine et le modèle des activités
pédagogiques définis par l'enseignant ; il spécifie la
structure pédagogique du cours. L'agent de filtrage qui filtre les
documents constituant le cours. L'agent d'interface reçoit la
requête de l'apprenant et interagit avec les autres agents pour la
répondre.
Ces agents autonomes coopèrent pour accomplir les
tâches de génération de cours et de suivi de processus
d'apprentissage, en communicant entre eux par le langage KQML (Knowledge Query
and Manipulation Language).
Mot clés : système multi
agents, hypermédia éducatif, hypermédia adaptatif
dynamique, activités pédagogiques, communication entre agents,
KQML.
Remerciements
Mes remerciements vont tout d'abord à Mr Mohamed Tayeb
Laskri, professeur de l'université de Annaba pour avoir accepté
de diriger ce travail, pour ses précieux conseils et ses orientations
malgré ses multiples charges.
Je remercie Mr Mahmoud Boufaida, professeur de
l'université de Constantine, qui me fait l'honneur de présider ce
jury. Je lui remercie aussi pour tous ses efforts comme responsable de notre
poste graduation pour assurer notre formation.
Je remercie Mme Zizette Boufaide, professeur de
l'université de Constantine, qui me fait l'honneur d'avoir
accepté d'examiner ce travail.
Je remercie Mr Amar Balla, Maître de Conférence
de l'INI (Institut National d'Informatique) Alger, qui me fait l'honneur
d'avoir accepté d'examiner ce travail.
Je tiens à exprimer une profonde gratitude aux
enseignants de la post-graduation de l'année 2002/2003 de Tebessa.
Du fond du mon coeur je remercie mes parents. Aucun mot n'est
assez fort pour leur exprimer la reconnaissance sincère que je leur
porte pour la richesse de leurs enseignements. Merci à mes frères
et à ma soeur pour m'avoir supporté et encouragé, et qui
ont partagé avec moi toutes les peines dans la période de
réalisation de ce travail.
Je suis heureux d'avoir l'occasion de présenter ma
reconnaissance et ma gratitude à mes amis Rachid et Kamel et tous mes
amis qui m'ont bien soutenu durant mes études.
Je remercie mon ami Abdelkader, son oncle Abdelouahab et sa
famille, qui sont toujours prompts à m'accueillir et à
m'héberger lorsque je passais par Annaba.
Je remercie, autre fois, ma mère pour avoir relu ce
mémoire et avoir enlevé la majorité des fautes
d'orthographe que j'avais laissées.
Listes des figures
Figure1.1:Leprocessusglobald'adaptationdanslessystèmesadaptatifs______21
Figure1.2:Indexationparpage______________________________________29
Figure1.3:Indexationfragmenté_____________________________________29
Figure1.4:Relationdirecte_________________________________________30
Figure1.5:Principedeshypermédiasadaptatifsdynamiques________________36
Figure1.6:Exempledereprésentationdumodèledudomaine______________43
Figure1.7:Extractiondebriquesélémentairesàl'aidedesfiltres_____________45
Figure1.8:ModèleconceptuelledeMETADYNE_______________________46
Figure1.9:ArchitecturedesystèmeTANGOW_________________________48
Figure2.1:CouchesdeJATLite_____________________________________78
Figure2.2:Architectured'unsystèmetutorielintelligentmulti-stratégique______85
Figure 2.3 : L'architecture de
CMOS__________________________________86
Figure3.1:Niveaudecompréhensiond'unconceptpourunapprenant_______91
Figure3.2:Représentationdemodèledudomaine________________________92
Figure3.3:exempledecanevasdel'activitépédagogique«familiariser»________94
Figure3.4:Documentmultimédiaetsesattributs________________________95
Figure3.5:Documentmultimédiameta-concept_________________________96
Figure3.6:modèlegénérald'unagent_________________________________97
Figure3.7:Cycledebasedefonctionnementd'unagentcognitif_____________97
Figure3.8:ArchitecturedeHEDAYA_______________________________100
Figure3.9:Communicationparlessockets,cotéserveur__________________103
Figure3.10:Communicationparlessockets,cotéclient__________________104
Figure3.11:ClassedemessageKQML_______________________________104
Figure3.12:inscriptiond'unnouveauapprenant________________________108
Figure3.13:Protocolesdecommunicationpourlescénarioconnexiond'unapprenant______________________________________________________108
Figure3.14:pageindexducours____________________________________110
Figure3.15:protocoled'interactiondanslecasdegénérationetaffichagedepageindexducours__________________________________________________111
Figure3.16:pageindexducourspourleniveaufaiblepourquelquesconceptsetmoyenpourd'autresconceptsavecdesconceptsannotés_________________111
Figure3.17:pageindexdesconceptsprérequis_________________________112
Figure3.18:pagedeconceptconjonction_____________________________113
Figure3.19:protocoled'interactiondescénariodegénérationdepagedeconcept__________________________________________________________114
Figure3.20:Applettestd'évaluationassociéàchaqueconcept_____________114
Figure3.21:Testd'évaluationassociéauconceptEczéma________________115
Figure3.22:protocoled'interactionpourlescénariodemodificationdemodèledel'apprenant_____________________________________________________116
Figure3.23:ArchitecturelogicielledeHEDAYA_______________________119
Listes des tableaux
Tableau 3.1 : Exemple de message
KQML_____________________________102
Tables des matières
Introduction____________________________________________________12
Chapitre 1 : Enseignement par ordinateur et
système Hypermédia
1
Introduction________________________________________________17
2 L'ordinateur pour l'enseignement,
aspects historiques_____________17
2.1 Enseignement Assisté par Ordinateur
(E.A.O.)____________________________18
2.2 Enseignement Intelligemment Assisté par
Ordinateur (E.I.A.O.) et Système Tuteur Intelligent
(STI)____________________________________________________18
2.3 Les Environnements Interactifs d'Apprentissage
avec Ordinateur (EIAO)______20
3 Les
hypermédias____________________________________________20
3.1 Hypertexte et
hypermédia_____________________________________________20
3.2 Les hypermédias
adaptatifs____________________________________________21
3.2.1 Les composants principaux des systèmes
hypermédias adaptatifs____________________22
3.2.2 Modèle et Modélisation de
l'utilisateur________________________________________22
3.2.3 Système hypermédia adaptatif ou
adaptable____________________________________24
3.2.4 Technique
d'adaptation___________________________________________________25
3.2.5 L'interconnexion entre le modèle du domaine et les
pages hypermédias_______________28
3.3 Domaine d'application des hypermédias
adaptatifs_________________________30
3.3.1 Systèmes hypermédias
éducatifs____________________________________________31
3.3.2 Moteurs de recherche dans les
hypermédias____________________________________32
3.3.3 Systèmes d'information en
ligne____________________________________________33
3.3.4 Systèmes d'aide en
ligne___________________________________________________34
3.3.5 Assistants
personnels____________________________________________________34
3.4 Hypermédia adaptatif
dynamique_______________________________________35
3.5 Hypermédia dans l'éducation;
avantage et inconvénient____________________37
3.5.1 Les hypermédias
classiques________________________________________________37
3.5.2 Les hypermédias
adaptatifs________________________________________________39
3.5.3 Les hypermédias adaptatifs
dynamiques_______________________________________40
4 Les systèmes
hypermédias adaptatifs dynamiques METADYNE et
TANGOW_____________________________________________________40
4.1 Le système METADYNE, un hypermédia
adaptatif dynamique pour
l'enseignement___________________________________________________________41
4.1.1 Objectifs de
METADYNE________________________________________________41
4.1.2 Les connaissances nécessaires à la
génération d'un cours__________________________42
4.2 Le système TANGOW, Task-based Adaptive
learNer Guidance On the WWW__46
4.2.1 Teaching Tasks
(TT)____________________________________________________47
4.2.2 Rules
(règle)___________________________________________________________47
4.2.3 Architecture de
TANGOW________________________________________________47
4.2.4 Apprentissage adaptatif dans
TANGOW_____________________________________50
5
Conclusion_________________________________________________51
Chapitre 2 : Les systèmes multi-agents
1
Introduction________________________________________________54
2 Concept
d'agent_____________________________________________54
2.1 Définition d'un
agent_________________________________________________54
2.2 Caractéristiques
d'agent_______________________________________________57
2.2.1 Caractéristiques
primaires_________________________________________________58
2.2.2 Caractéristiques
secondaires_______________________________________________58
2.2.3 Caractéristiques
tertiaires__________________________________________________58
2.3 Typologies
d'agents__________________________________________________59
2.3.1 Les agents
collaboratifs___________________________________________________59
2.3.2 Les agents
d'interface____________________________________________________60
2.3.3 Les agents
mobiles______________________________________________________60
2.3.4 Les agents
d'information__________________________________________________61
2.3.5 Les agents logiciels
réactifs________________________________________________62
2.3.6 Les agents
hybrides______________________________________________________62
3 Système
multi-agents________________________________________62
3.1
Définition___________________________________________________________64
3.2 Propriété des
systèmes multi-agents_____________________________________65
3.3 Les composants d'un système
multi-agents_______________________________67
3.3.1
Agent________________________________________________________________67
3.3.2
Environnement_________________________________________________________67
3.3.3
Interactions____________________________________________________________68
3.3.4
Organisation___________________________________________________________69
3.4 Communication entre
agents___________________________________________70
3.4.1 Stratégies de
communication_______________________________________________71
3.4.2 Actes de
langages_______________________________________________________72
3.4.3 Langage de communication entre
agents______________________________________73
3.4.4 Protocole d'interaction entre
agents__________________________________________75
3.4.5 Transport de
messages___________________________________________________75
3.5 Interaction et coopération
entre agents___________________________________79
3.6 Coordination entre
agents______________________________________________80
3.7 Négociation entre
agents______________________________________________80
3.8 Utilisateur dans les systèmes
multi-agents________________________________81
3.9 Systèmes multi-agents et
formation______________________________________82
3.9.1 L'intelligence artificielle pour la
formation_____________________________________82
3.9.2 Les systèmes multi-agents pour la
formation___________________________________83
Chapitre 3: Hypermédia
Educatif Adaptatif dynamique basé Agent, HEDAYA
1
Introduction________________________________________________89
2 Architecture
détaillée de HEDAYA_____________________________89
2.1 Modélisation du
système______________________________________________90
2.1.1 Modèle de
l'apprenant____________________________________________________90
2.1.2 Modèle du
domaine______________________________________________________91
2.1.3 Modèle des activités
pédagogiques___________________________________________92
2.1.4 Base de documents
multimédias____________________________________________94
2.2 Architecture du
système_______________________________________________96
2.2.1 Modèle général d'un
agent_________________________________________________96
2.2.2 Agent
d'interface________________________________________________________98
2.2.3 Agent pédagogique
d'adaptation____________________________________________99
2.2.4 Agent de
filtrage________________________________________________________99
2.2.5 Agent de modèle de
l'apprenant___________________________________________100
3 Communication entre
agents_________________________________101
3.1 Le langage de communications
utilisé dans HEDAYA_____________________101
3.2 Implémentation de la
communication entre les agents de HEDAYA_________102
4 Sélection des liens et
utilisation de technique d'annotation des liens_105
4.1 Sélection des liens
hypertextes_________________________________________105
4.2 Annotation des
liens_________________________________________________106
4.3 Mode libre et mode
guidé_____________________________________________106
5 Scénarios d'utilisation de
HEDAYA et protocoles d'interaction entre
agents________________________________________________________107
5.1 Scénario 1 : Connexion d'un
apprenant__________________________________107
5.2 Scénario 2 :
génération et affichage de page Index du
cours_________________109
5.3 Scénario 3 : affichage de
page de concept________________________________111
5.4 Scénario 4 : modification de
modèle de l'apprenant________________________114
6 Architecture logicielle de
HYDAYA___________________________116
6.1 Choix de langage de
programmation____________________________________116
6.2 Choix de plateforme
agent____________________________________________117
6.3 Architecture logicielle et outils de
développement_________________________117
7
Conclusion________________________________________________116
Conclusion____________________________________________________121
Bibliographie__________________________________________________124
Introduction
Dès l'apparition des premiers systèmes
informatiques d'enseignement, dans les années soixante,
l'évolution de ces systèmes est très importante,
jusqu'à l'apparition d'hypertexte et d'hypermédia ; les
hypermédias éducatifs sont apparus dans une tentative d'exploiter
ces technologies dans l'enseignement.
La croissance exponentielle de Web dans quelques années
courtes a apporté la richesse de la connaissance humaine. Aujourd'hui le
Web est un milieu pour exprimer des idées, histoires, faits,
intérêts, etc. La simplicité du modèle d'hypertexte
(donc hypermédia) derrière le Web est la raison principale de
son succès. Ce qui encourage l'utilisation du Web et des
hypermédias dans la transmission du savoir.
Les recherches dans les hypermédias adaptatifs
produisent des systèmes, et des techniques visées à
orienter l'utilisateur et réduire la surcharge cognitive, ces
problèmes résultent de l'utilisation des hypermédias. Ces
systèmes établissent un profil et un modèle de
l'utilisateur, et utilisent ces connaissances pour simplifier la navigation en
guidant l'utilisateur dans un hyperespace modélisé par un
modèle du domaine, pour trouver la bonne information. Ces
systèmes sont utiles dans tous domaines où les utilisateurs ont
différents buts et connaissances dont l'hyperespace est
considérablement large. L'un des premiers domaines d'application des
hypermédias adaptatifs sont les hypermédias éducatifs.
Afin d'améliorer la qualité de l'adaptation et
de prendre en compte instantanément de nouvelles données ainsi de
permettre la réutilisation des documents didactiques; les chercheurs se
sont orientés vers les hypermédias adaptatifs dynamiques dont les
pages et les liens sont construits dynamiquement à partir des documents
multimédias élémentaires réutilisables.
Les agents fournissent plusieurs avantages, l'autonomie, la
flexibilité, la communicabilité, la résolution
distribuée des problèmes, etc. Les agents utilisent des plans et
des règles pour déduire ses actions dans des circonstances
spécifiques, tout en stockant l'information et la connaissance dans les
bases de connaissances. Cette technologie peut être utilisée pour
modéliser les hypermédias adaptatifs ; les règles
adaptatives et les plans donc sont utilisés pour personnaliser
l'information aux utilisateurs. En outre, les agents ont été
utilisés dans une variété de champs qui ont une
similarité avec ces systèmes; agents personnels, agents de
filtrage de courriers, systèmes tutoriels intelligents basés
agents, hypermédias adaptatifs basés agents, etc. Aussi, cette
technologie a vue un vaste succès dans le web, qui étend les
outils utilisés pour mettre en oeuvre des systèmes multi-agents
sur l'Internet.
L'objectif est de modéliser par un système multi
agents, un système hypermédia éducatif, adaptatif au
profile et à l'objectif de l'apprenant, dynamique générant
la page hypermédia dynamiquement, en présentant plusieurs visions
d'un même concept ; ce système est appelé HEDAYA
(Hypermédia EDucatif
Adaptatif dYnamique basé
Agent). Cette modélisation combine entre plusieurs
technologies :
·
Les systèmes multi agents, qui modélisent notre
système.
·
Les systèmes hypermédias adaptatifs car le cours
présenté s'adapte à l'apprenant [Brusilovsky 98]
·
Les tuteurs intelligents, par ce qu'il y a une stratégie
d'apprentissage obligeant l'apprenant d'apprendre des concepts avant d'autres
selon les relations dans le modèle du domaine [Capuano et al 01].
·
La réutilisation des items didactiques : la base de
documents multimédias contient un ensemble de documents
réutilisables [Delestre 00].
·
Les activités pédagogiques permettant plusieurs
vues d'un même concept selon le niveau de l'apprenant [Balla et al 03].
·
Les documents virtuels car la page hypermédia à
présenter à l'apprenant n'existe pas réellement, mais elle
est générée dynamiquement suite à une demande de
l'apprenant [Ranwez 00].
Notre contribution consiste à :
·
l'utilisation des systèmes multi-agents pour
modéliser les hypermédias adaptatifs dynamiques pour
bénéficier les avantages fournis par ces systèmes surtout
avec ses vastes utilisations sur l'Internent ; différents outils et
techniques existes. Le langage de communication utilisé est KQML
(Knowledge Query and Manipulation Language)
·
l'introduction des documents méta-concepts, permettant
une description générale d'un concept selon l'activité
pédagogique suivie, ces documents sont présentés dans la
page index du cours. Ces méta-concepts permettent à l'apprenant
de gagner tu temps par la vue générale sur le concept sans
consulter la page du concept.
·
L'utilisation de technique d'annotation des liens avec les
hypermédias adaptatifs dynamiques, permettant la distinction entre liens
étudiés et non étudiés.
·
L'introduction de deux modes d'apprentissages, donc de
navigation ; mode libre et mode guidé.
On a développé une démonstration du
système HEDAYA en utilisant JAVA comme langage de programmation
(l'environnement JBuilder 7), XML pour modéliser le modèle du
domaine et le modèle des activités pédagogiques, Interbase
comme SGBD pour les bases de données des modèles des l'apprenants
et la base de documents multimédias. Ce travail présente une
approche forte de communication entre les agents qui interagissent en utilisant
un sous ensemble des performatifs de KQML (Knowledge Query and Manipulation
Language).
Le présent mémoire est organisé en trois
chapitres :
Le premier chapitre présente les systèmes
d'enseignement par ordinateur, les hypertextes, les hypermédias, les
hypermédias adaptatifs et les hypermédias adaptatifs dynamiques,
ainsi les différents techniques utilisés dans ces types des
systèmes et les domaines de leurs applications. Enfin, on va
présenter deux systèmes hypermédias adaptatifs dynamiques
: METADYNE et TANGOW.
Le deuxième chapitre présente une étude
des concepts agent et système multi-agents ; les différents
techniques et outils de modélisation et d'implémentation de ce
type de système.
Le dernier chapitre, décrit l'architecture
détaillée de système HEDAYA, les différents
modèles et agents définis ainsi les différents outils et
moyens d'implémentation.
Chapitre 1
Enseignement par ordinateur et système
Hypermédia
1
Introduction
Les années soixante sont les années d'apparition
des premiers systèmes d'enseignement informatique, ils consistaient tout
simplement à présenter à l'apprenant une notion
particulière et ensuite à l'interroger et lui posant
différentes questions. Dès ces années l'évolution
des systèmes d'enseignement est très importante jusqu'à
l'apparition d'hypertexte et d'hypermédia, dans une tentative
d'exploiter ces technologies dans l'éducation, sont apparus les
hypermédias éducatifs et l'enseignement à distance. Les
hypermédias éducatifs ont plusieurs types, les hypermédias
classiques où un cours statique est créé par l'enseignent
sous forme de pages hypermédias, même cours pour tous les
étudiants. Les hypermédias adaptatifs modélisent
l'apprenant et adaptent le cours selon son niveau. Les hypermédias
adaptatifs dynamiques exploitent des documents multimédias
réutilisable et créent dynamiquement le cours selon le niveau de
l'apprenant.
Ce chapitre est organisé comme suit : La
première section présente des aspects historiques sur les
systèmes d'enseignement par ordinateur, la deuxième section
définit les systèmes hypermédias et présente les
domaines d'application de ce type des systèmes, il présente en
détail les hypermédias adaptatifs, les composants de ces
systèmes et les techniques utilisées pour l'adaptation. Il
présente une description générale des hypermédias
éducatifs et les hypermédias adaptatifs dynamiques. Cette section
présente aussi deux systèmes hypermédias adaptatifs
dynamiques; METADYNE et TANGOW.
2
L'ordinateur pour l'enseignement, aspects historiques
La période antérieure à 1970 a vu
l'émergence des systèmes d'Enseignement Assisté par
Ordinateur (EAO). A partir du constat de certaines limites de ces
systèmes, les recherches se sont appuyées sur les techniques
d'Intelligence Artificielle (IA) pour concevoir des systèmes plus
souples, plus interactifs, s'adaptant mieux à l'utilisateur pour l'aider
à apprendre. C'est ainsi que ce domaine de recherche s'est
développé depuis 1970 environ aux Etats-Unis, et depuis le
début des années 80 en France, sous l'appellation initiale
d'Enseignement Intelligemment Assisté par Ordinateur (EIAO). La
décennie 80-90 a été marquée par les
Systèmes Tutoriels Intelligents (STI), en très forte liaison avec
le développement en IA des systèmes à base de
connaissances. Elle s'est terminée en 1990 par un changement
d'appellation pour le sigle EIAO, signifiant Environnement Interactif
d'Apprentissage avec Ordinateur évoquant la volonté de concevoir
des systèmes interactifs d'aide à la résolution de
problèmes en recherchant la coopération des différents
acteurs du système.
2.1
Enseignement Assisté par Ordinateur (E.A.O.)
Les premiers systèmes d'enseignement assisté par
ordinateur sont nés au début des années soixante [Merlet
94]. C'est une démarche de formation utilisant des méthodes, des
techniques et des moyens informatiques comme outils de création et de
présentation du cours dans une session d'EAO. Elle se déroule de
manière cyclique : présentation d'informations et d'une question,
réponse de l'apprenant, analyse de la réponse puis continuation
ou branchement à une autre partie du cours. De façon
générale, ces logiciels sont assimilables à des automates
d'états finis déterministes
L'EAO a réalisé le passage de cours magistraux
présentés par l'enseignant à des systèmes plus
riches et plus performants utilisant différents outils d'enseignement.
Contrairement au cours magistral, dans lequel l'apprenant reçoit
passivement l'information, l'EAO permet d'introduire un genre
d'interactivité dans l'enseignement, tel que l'utilisation des moyens
multimédias (images fixes ou animées et son aux
côtés de texte écrit).
Les didacticiels de l'EAO sont incapables de résoudre
eux-mêmes les problèmes qu'ils posent, d'organiser ou de diriger
un dialogue correspondant au profil d'un apprenant et d'effectuer des
rétroactions. Ce manque de flexibilité dans l'interaction
homme-machine ne permet pas d'ajouter de nouvelles notions au sujet
d'enseignement ou nouvelles tâche s pédagogiques. Ils ne
permettent pas à un enseignant ou un expert du domaine de modifier la
manière à enseigner sans réimplanter le système
à chaque étape [Lafifi 00].
2.2
Enseignement Intelligemment Assisté par Ordinateur
(E.I.A.O.) et Système Tuteur Intelligent (STI)
Les applications des techniques et des principes de
l'intelligence artificielle (IA) à l'enseignement par ordinateur ont
donné une naissance à un certain nombre de dénominations
pour caractériser les produits qui en sont issus. Parmi les plus
fréquemment utilisés, on peut citer les termes «
Enseignement Intelligemment Assisté par Ordinateur » (Intelligent
Computer Aided Instruction), "Système Tuteur Intelligent" (Intelligent
Tutoring System) et "Environnement Intelligent d'Apprentissage" (Intelligent
Learning Environment)
L'EIAO [Bertrand 01] est une reprise de la
problématique de l'EAO par l'intelligence artificielle. Avec le
progrès des outils de représentation et de traitement des
connaissances, des interfaces homme-machine et des systèmes experts ;
l'espoir de développer des tutoriels réellement intelligents a vu
le jour, ces systèmes sont caractérisés par :
·
une modélisation des connaissances du domaine et des
mécanismes de raisonnement, qui dote les systèmes de la
capacité de résoudre des problèmes et de répondre
à des questions non explicitement prévues.
·
une modélisation (ou prise en compte) de l'apprenant pour
permettre au système de s'adapter dynamiquement et de façon
individualisée à son interlocuteur, connaissant son degré
de maîtrise des connaissances du domaine et son comportement.
·
une modélisation des stratégies tutorielles, qui
autorise le système à intervenir en fonction de la situation,
d'objectifs pédagogiques ou du modèle de l'apprenant
·
des capacités de communication souples et variées,
avec des possibilités d'intervention et de prise d'initiative de
l'apprenant.
Ces idées justifient l'adverbe « intelligemment
» ajouté au sigle EAO, à la fois en terme d'intelligence du
système et en terme de problématique et de techniques relevant de
l'IA.
En très forte liaison avec le développement en
IA des systèmes à base de connaissances et en particulier des
premiers systèmes experts, les STI (Intelligent Tutoring Systems - ITS)
sont nés dans les années 90 à partir d'une idée
simple : on dispose d'un système expert pour la résolution de
problèmes, d'une base de connaissances pour un domaine, on ajoute un
module pour assurer le transfert de connaissances du système vers
l'utilisateur et on obtient un système d'apprentissage
individualisé qui va servir à former les étudiants en
complément à un enseignement classique dispensé par
exemple sous forme de cours magistraux.
Généralement, l'architecture des STI comporte
quatre composants indépendants : le module «expert du domaine
», le module « modèle de l'élève », le
module « tuteur » et le module « interface » [Baron 94].
L'expert possède la maîtrise du domaine à enseigner, le
tuteur surveille et dirige l'acquisition des connaissances et des
raisonnements, le modèle de l'apprenant permet d'intégrer le
comportement de ce dernier dans le STI et l'interface assure le dialogue entre
l'apprenant et le système.
2.3
Les Environnements Interactifs d'Apprentissage avec
Ordinateur (EIAO)
C'est aux environs de 1990 que s'opère un changement
dans la vision de l'apprentissage. On passe d'une vision qui était
jusqu'alors centrée sur le transfert de connaissances à une
vision selon laquelle l'apprenant construit son apprentissage en interagissant
avec un environnement [Bruillard 94]. Il s'agit de confronter l'apprenant
à un environnement dont le niveau de connaissances est supérieur
au sien, provoquant ainsi un écart qu'il va essayer de combler en
acquérant et remettant en cause ses connaissances, au fur et à
mesure de ses interactions avec le système. Ainsi, l'appellation
Environnements Interactifs d'Apprentissage avec Ordinateur (EIAO) est
proposée pour se démarquer de l'ancien sigle, trop limité
aux travaux concernant les STI, et concevoir des environnements d'apprentissage
(Interactive Learning Environments - ILE) regroupant également les
approches du type micromonde.
A l'opposé des systèmes « tuteurs »,
un système de type « micromonde » laisse toute l'initiative
à l'élève. Ce type de système fournit un certain
nombre d'objets ou primitives de base que l'élève utilise pour
concevoir des objets plus complexes au fur et à mesure de l'exploration.
Une illustration de ce type de système est donnée par le logiciel
Cabri-Géomètre, un micromonde pour expérimenter la
géométrie. Il permet à son utilisateur de construire des
figures géométriques possédant certaines
propriétés à partir d'objets élémentaires
comme des points, droites, etc. Ces figures peuvent ensuite être
déformées tout en conservant leurs caractéristiques
géométriques.
L'évolution rapide des matériels, des logiciels
et interfaces de communication homme-machine ont permis d'accroître
fortement l'interactivité pour concevoir des systèmes interactifs
d'aide à la résolution de problèmes avec une forte
communication tout au long du processus d'apprentissage, tout en assurant des
tâches de guidage tutoriel et de contrôle des activités de
l'apprenant pour favoriser son apprentissage.
3
Les hypermédias
3.1
Hypertexte et hypermédia
Les termes hypertexte et hypermédia peuvent être
définis suivant deux points de vue [Delestre 00]. On peut en effet les
définir de point de vue de la structure et du point de vue de
l'interaction entre l'utilisateur et le système.
Définition structurelle : Un
hypertexte définit comme étant un système composé
de noeuds et de liens. Les noeuds peuvent être composés
d'informations textuelles, on parle alors d'hypertexte, ou d'informations
multimédias, tels que des images, des graphiques, des animations, des
vidéos ou bien des programmes informatiques, on parle alors
d'hypermédia. Les noeuds sont reliés les uns aux autres par des
liens.
Les liens peuvent être plus ou moins complexes : ils
peuvent être unidirectionnels permettant d'aller d'une page à une
autre, ou bidirectionnels, afin de faciliter le retour au point de
départ. Ils peuvent être aussi typés afin de
spécifier la sémantique de lien. Enfin les liens peuvent
être disposés n'importe où dans une page.
Définition fonctionnelle :
L'hypertexte peut être considéré comme
étant un procédé informatique permettant d'associer une
entité souvent minimale : un mot, une image ou une icône à
une autre entité souvent plus étendue comme un paragraphe, une
image ou une page. Ce mécanisme permet donc à l'utilisateur de se
diriger librement dans l'hypertexte. En activant, à l'aide d'un pointeur
une zone de document qui est l'origine d'une association. Il n'est donc plus
obligé de suivre le cheminement prévu par l'auteur, il
définit son parcours en fonction de ses envies et de ses centres
d'intérêt.
3.2
Les hypermédias adaptatifs
Les systèmes hypermédias adaptatifs sont des
systèmes hypermédias qui reflètent quelques
caractéristiques de l'utilisateur dans un modèle d'utilisateur et
utilisent ce modèle en adaptant différents aspects du
système à l'utilisateur [Brusilovsky 96]. Selon cette
définition un système hypermédia adaptatif doit remplir
les conditions suivantes (Figure 1.1) :
·
Doit être un système hypermédia permettant
la navigation dans un hyperespace du domaine d'application,
·
Doit inclure un modèle d'utilisateur pour décrire
l'utilisateur
·
Doit fournir un mécanisme d'adaptation pour permettre
l'adaptation de l'hypermédia selon l'état du modèle de
l'utilisateur
 Figure 1.5 : Principe des hypermédias adaptatifs
dynamiques Figure 1.5 : Principe des hypermédias adaptatifs
dynamiques
Les systèmes hypermédias adaptatifs utilisent un
modèle de l'utilisateur pour rassembler des informations sur sa
connaissance, buts, expériences, etc. pour adapter le contenu et la
structure de navigation. Par exemple, pour un utilisateur novice, on lui
présente des informations plus préliminaires avant d'entrer dans
les détails. Cependant, la même information ne serait pas
intéressante pour un expert. Ici, le choix de bonne information au bon
temps est la tâche du modèle de l'utilisateur.
3.2.1
Les composants principaux des systèmes hypermédias
adaptatifs
La plupart des systèmes hypermédias adaptatifs
se constituent de trois composants [Wu 02] :
·
Modèle du domaine contenant une représentation de
contenu de l'hyperespace. Ce modèle présente non seulement les
items de l'hyperespace (fragments, pages) mais aussi les relations entre ces
items.
·
Profil de l'utilisateur ; pour chaque utilisateur, il
représente ses caractéristiques appropriés à
l'adaptation. Par exemple, les préférences de l'utilisateur, les
connaissances, les buts et l'histoire de navigation.
·
Modèle d'adaptation, qui détermine la façon
de maintenir le profil de l'utilisateur en observant son comportement, et la
façon de produire de l'adaptation en utilisant le modèle du
domaine et le profil de l'utilisateur.
3.2.2
Modèle et Modélisation de l'utilisateur
Le modèle d'utilisateur est constitué de
descriptions de ce qui est considéré utile sur les connaissances
de l'utilisateur et/ou des aptitudes réelles d'un utilisateur, ce
modèle fournit des informations à l'environnement pour s'adapter
à un utilisateur individuel [Koch 00].
Une partie de ce modèle se relie au domaine de
l'information et autre partie se relie seulement à l'utilisateur et
à son environnement. Selon Eklund et Zeiliger [Koch 00] les cinq
caractéristiques principales représentées dans le
modèle de l'utilisateur sont :
1.
le but courant ou la tâche courante de l'utilisateur,
2.
les connaissances de l'utilisateur sur le domaine à
présenter dans l'hypermédia
3.
les connaissances générales de l'utilisateur
4.
l'expérience de l'utilisateur, par exemple dans
l'utilisation des applications semblables, ou dans l'hyperespace et
5.
les préférences ou les intérêts de
l'utilisateur.
Qu'est ce que la modélisation de l'utilisateur? Quel
est le modèle de l'utilisateur?
Dans le modèle de l'utilisateur ; l'utilisateur est
représenté comme une collection de données. C'est la
représentation explicite des aspects de l'utilisateur. Principalement le
modèle de l'utilisateur représente les croyances du
système sur l'utilisateur.
La modélisation de l'utilisateur est le processus de
suivi du cycle de vie entier d'un modèle de l'utilisateur ; comprenant
l'acquisition des connaissances sur l'utilisateur, construction, de la mise
à jour, l'exploitation du modèle de l'utilisateur.
Les buts principaux de la modélisation de l'utilisateur
sont pour:
·
aider un utilisateur pendant l'apprentissage,
·
offrir l'information adaptée à l'utilisateur,
·
adapter l'interface à l'utilisateur,
·
aider un utilisateur à trouver l'information,
·
donner à l'utilisateur son feedback sur ses
connaissances,
·
supporter le travail de collaboration, et/ou
·
donner l'aide personnalisé dans l'utilisation d'un
système.
Les connaissances de système sur l'utilisateur peuvent
être représentées de différentes manières,
telles que les modèles par recouvrement (en couches), réseaux
sémantiques, profils d'utilisateur, modèles basés
stéréotypes, réseaux bayésiens ou modèles
de logique floue. Les représentations les plus fréquemment
utilisées sont [Koch 00][Delestre 00] les modèles en couche, les
modèles des erreurs, les modèles
stéréotypés.
3.2.2.1
Le modèle en couche (overlay model)
Cette méthode, nommée aussi méthode de
représentation par recouvrement, apparue avec les premiers
systèmes d'enseignement, considère le modèle de
l'utilisateur comme un sous-ensemble du modèle du domaine, auquel il
manque des informations. Dans ce cas le but de l'apprentissage est d'obtenir
finalement une superposition parfaite du modèle de l'apprenant sur le
modèle du domaine.
La forme la plus simple et la plus ancienne de
représentation des connaissances de l'utilisateur est une valeur binaire
« connue - inconnue ». La majorité de systèmes utilise
ce modèle en associant à chaque concept du modèle du
domaine un poids qui peut distinguer plusieurs niveaux de connaissance de
l'utilisateur d'un concept en utilisant une valeur qualitative, une valeur
quantitative : nombre entier, ou une probabilité que l'utilisateur
connaît le concept. Dans le modèle en couche la connaissance de
l'utilisateur peut être représentée comme ensemble de
paires « valeur - concept », pour chaque concept de domaine. Le
modèle en couche est puissant et flexible parce qu'il peut mesurer
indépendamment la connaissance de l'utilisateur de différents
concepts.
3.2.2.2
Le modèle des erreurs (buggy model)
Cette deuxième méthode est une extension de la
précédente. Introduite par J.S. Brown et R.R. Burton [Delestre
00], elle consiste à adjoindre aux données issues de la
méthode en couche une liste d'erreurs qu'a commises l'apprenant. Le but
est alors d'examiner ces bugs et d'essayer de comprendre leurs origines en les
comparant à une liste d'erreurs typiques déjà
observées, permettant alors d'améliorer les stratégies
pédagogiques du système. Par la suite l'avènement de
l'intelligence artificielle distribuée et principalement
l'avènement des systèmes multi agents a permis de remplacer cette
liste statique d'erreur par la négociation entre agents.
Différents agents adoptent chacun un point de vue sur l'état de
connaissance et stratégie de résolution de l'apprenant. Ensuite,
de par les interactions entre l'apprenant et le système, les agents, par
échange de « points de vue », tentent alors de faire
émerger un profil cohérent.
3.2.2.3
Le modèle stéréotypé
Dans un modèle stéréotypé les
propriétés et les connaissances des utilisateurs sont
également représentées avec des combinaisons des valeurs,
qui sont assignées aux stéréotypes, tels que le :
débutant, intermédiaire, expert. Un utilisateur hérite
alors toutes les propriétés définies pour un
stéréotype.
3.2.3
Système hypermédia adaptatif ou adaptable
Une distinction claire doit être faite entre les
systèmes hypermédias personnalisables, appelés
adaptables, et les systèmes adaptatifs [Koch 00]. Dans les deux cas
d'utilisateur joue un rôle central et le but final est d'offrir un
système personnalisé. Ils diffèrent dans la manière
d'adaptation.
Un système hypermédia adaptable
permet à l'utilisateur de configurer le système en changeant
quelques paramètres, ce qui permet au système d'adapter son
comportement. C'est un système externe ou l'utilisateur qui
décide quand son modèle devrait être changé, par
exemple au début d'une session.
Un système hypermédia adaptatif
est un système qui s'adapte de façon autonome au modèle de
l'utilisateur. Il suit le comportement de l'utilisateur et l'enregistre dans
un modèle de l'utilisateur et adapte le système dynamiquement
à l'état actuel du modèle d'utilisateur. Le système
utilise les actions de la navigation de l'utilisateur, ses réponses aux
questionnaires et l'information initiale que l'utilisateur a fournie pour
adapter les noeuds et la navigation. Ces adaptations peuvent être faites
en changeant des présentations prédéfinies ou en
construisant les pages d'après des pièces d'informations. Dans le
dernier cas, une génération dynamique des pages est
effectuée, ces systèmes sont également connus en tant que
systèmes hypermédias dynamiques [De Bra 99] [Koch 00].
3.2.4
Technique d'adaptation
Un hypermédia est composé de pages et de liens,
pour qu'un hypermédia soit adaptatif, il doit pouvoir adapter le contenu
de ces pages et ces liens pour mieux guider l'utilisateur dans son cheminement.
Les techniques utilisées sont l'adaptation du contenu, l'adaptation de
présentation et l'adaptation pour faciliter la navigation [Delestre
00][Brusilovsky 96].
3.2.4.1
L'adaptation du contenu
L'objectif est d'adapter le contenu des pages de
l'hypermédia en fonction des caractéristiques, des
volontés et des buts de l'utilisateur. Ainsi, les utilisateurs qui
accèdent à une même page, mais en ayant des profils
différents, doivent visualiser en fait des pages différentes.
Pour l'instant, très peu de systèmes effectuent une adaptation du
contenu, et lorsqu'ils le font, l'adaptation n'a souvent lieu qu'au niveau des
données textuelles.
3.2.4.2
L'adaptation de présentation
L'objectif de l'adaptation de présentation est
d'adapter les dispositions visuelles aux préférences ou aux
besoins de l'utilisateur. Les méthodes pour la présentation
adaptative aident l'utilisateur avec une disposition ou une langue
appropriée. L'adaptation consiste à des changements dans la
présentation. Parfois ces changements se produisent simultanément
avec l'adaptation du contenu. Des méthodes et des techniques
d'adaptation de présentation sont souvent groupées avec celles de
l'adaptation du contenu. Dans ce travail elles sont présentées
séparément afin de distinguer les méthodes et les
techniques qui produisent des modifications dans la disposition et les
techniques qui changent le contenu montré à utilisateur.
Les méthodes de la présentation adaptative sont
: La méthode multi langues, l'objectif de cette méthode est
l'adaptation à la langue préférée à
l'utilisateur. La méthode de variation de disposition inclut toutes les
solutions de changement possibles dans une présentation, par exemple
couleur, taille de police ou type de police, taille maximum d'images,
orientation des textes, etc.
3.2.4.3
L'adaptation pour faciliter la navigation
Son objectif est d'aider l'utilisateur à se
repérer dans l'hyperespace ou à l'inciter, voire l'obliger,
à utiliser certains liens plutôt que d'autres. Différentes
techniques ont été développées, entre autres; le
guidage direct, l'ordonnancement des liens, le masquage des liens, l'annotation
des liens ou encore les cartes adaptatives [Brusilovsky 98].
3.2.4.3.1
Le guidage direct
Cette technique a été la première
utilisée régulièrement, car très simple et
facilement implémentable. Elle est basée sur l'ajout d'un lien
hypertexte nommé souvent « suivant » (next en anglais), qui
permet d'accéder à la meilleur page suivante, qui est en
adéquation avec les objectifs et/ou les capacités de
l'utilisateur.
On peut utiliser cette technique en laissant les autres
hyperliens existant au préalable ou en les supprimant. Dans ce dernier
cas l'hypertexte perd beaucoup de ses capacités d'exploration, puisque
le système devient totalement linéaire (il conserve toutefois son
aspect dynamique).
En fait, pour être réellement efficace, cette
technique doit être utilisée conjointement avec au moins une des
techniques suivantes.
3.2.4.3.2
L'ordonnancement des liens
L'ordonnancement des liens est une technique qui propose
d'afficher les liens hypertextes suivant un ordre définissant
l'intérêt ou l'importance des pages cibles.
Cette technique ne peut pas être utilisée dans
tous les cas. En effet, on ne peut pas l'utiliser avec des liens contextuels,
c'est-à-dire des liens qui se trouvent au sein de phrases. En fait, on
ne peut pas l'appliquer que sur des liens qui appartiennent à un index,
ou alors à une carte décrivant l'hyperespace du système.
L'intérêt de cette technique est très
controversé. Certaines études ont montré que la non
stabilité d'une liste de liens pour une page donnée pouvait
désorienter l'apprenant. Et au contraire d'autres études ont
montré qu'elle pouvait réduire le temps de navigation.
3.2.4.3.3
Le masquage des liens
La technique dite du masquage de lien consiste à
supprimer les liens hypertextes dont les pages cibles sont soit en
inadéquation avec le modèle de l'utilisateur (trop simples ou
trop compliqués), soit en inadéquation avec les objectifs de
l'utilisateur.
Cette technique est facile à mettre en oeuvre,
puisqu'il suffit, avant d'envoyer la page à l'utilisateur, d'enlever les
liens non désirés, elle permet de réduire la taille de
l'hyperespace pour l'utilisateur. Elle s'applique de plus sur tous les types de
liens, contextuels ou non, avec des activateurs très divers (texte,
bouton, icône, image, etc.).
Cette technique a aussi des défauts ; la suppression
des liens hypertextes peut en effet entraîner chez l'utilisateur une
mauvaise représentation mentale des tenants et aboutissants de chaque
page.
3.2.4.3.4
L'annotation des liens
L'annotation des liens part du principe que l'utilisateur doit
savoir où il va avant d'activer un lien. Il faut donc adjoindre à
chaque lien des explications sur la page cible ou alors définir une
syntaxe ou un codage particulier (par exemple telle icône pour dire que
c'est une aide, telle couleur pour dire qu'il s'agit d'un exemple, etc.)
[Brusilovsky et al 95].
A la différence des commentaires que l'on peut ajouter
à nos liens et images de pages HTML, les annotations de liens, pour
être efficaces, doivent être fonction de l'utilisateur.
Cette technique, assez simple à mettre en oeuvre, peut
être utilisée pour tous les types de liens, et ne semble pas avoir
d'effets de bord néfastes.
3.2.4.3.5
Les cartes adaptatives
Les cartes, ou map en anglais, permettent de présenter
à l'utilisateur, l'organisation de l'hyperespace, à l'aide de
liens, soit sous forme textuelle (dans ce cas nous avons souvent une
représentation hiérarchique de l'hyperespace), soit sous forme
graphique. Dès lors, il est possible de présenter à
l'utilisateur une organisation plus ou mois simplifié en fonction de son
profil.
Bien entendu, l'ensemble de ces méthodes peuvent et
même doivent être combinées. Par exemple le système
ISIS-Tutor [Brusilovsky 97] utilise les techniques de guidage direct, de
masquage de liens et d'annotation de liens.
3.2.5
L'interconnexion entre le modèle du domaine et les
pages hypermédias
Pour qu'un système s'adapte à l'utilisateur, il
faut qu'il aura au moins deux composantes : le modèle du domaine et le
modèle de l'utilisateur. Le modèle du domaine sert à
organiser les connaissances et le modèle de l'utilisateur permet
d'adapter le contenu et les liens hypertextuels que `on va présenter
à l'utilisateur.
Les pages hypermédias, qui présentent les
connaissances du domaine, doivent être interconnectés avec le
modèle du domaine. [Brusilovsky 03] a dénombré trois
méthodes permettant d'interconnecter ces deux composants : l'indexation
par page, l'indexation fragmentée et la relation directe.
3.2.5.1
La méthode d'indexation par page
L'objectif de cette méthode est d'indexer tout le
contenu des pages de l'hypermédia avec les concepts du modèle du
domaine. Ainsi chaque concept est associé à une page d'index qui
permet d'accéder à toutes les pages présentant ce concept.
Il est aussi possible de créer des index relatifs aux
relations définies dans le modèle du domaine. Ainsi le
système peut créer un index par concept et par relation. Cet
index réfère l'ensemble des pages de l'hypertexte qui contiennent
des références à des concepts et possède m type de
relation peut produire n*m index différents.
Cette méthode à été très
utilisée dans les hypermédias éducatifs, car le ou les
index que l'on peut présenter à l'utilisateur peuvent être
modifiés à l'aide des techniques d'adaptation vues
précédemment, et ainsi l'obliger, ou du moins d'inciter, à
suivre telle ou telle direction.
L'avantage de cette méthode est sa facilité de
mise en oeuvre, mais son système d'indexation est un peut grossier. En
effet, si une page de l'hypertexte présente ou explicite plusieurs
concepts, elle sera indexée plusieurs fois de la même
façon.
3.2.5.2
La méthode d'indexation fragmentée
Cette deuxième méthode est en fait une
évolution de la méthode précédente ; les pages de
l'hypertexte ne sont plus indexées dans leurs globalité, mais
indexées par fragment. Cela permet d'avoir une indexation plus fine.
Deux index peuvent alors référencer une même page de
l'hypertexte mais pas au même endroit.
Outre un guidage de l'utilisateur, cette méthode permet
aussi d'obtenir une adaptation au niveau du contenu, puisque les
éléments référencés au niveau des index
peuvent être très spécifiques et le système peut
dans certains cas avoir des informations décrivant chaque
élément. On voit en fait apparaître par ce biais
l'adjonction de sémantiques au sein des documents hypertextuels, ce qui
de nos jours semble assez normal, grâce à l'utilisation du XML
(eXtensible Markup Language).
Figure 1.3: Indexationfragmenté
Hypertexte
Index
Modèle du domaine 
Figure 1.2: Indexation par page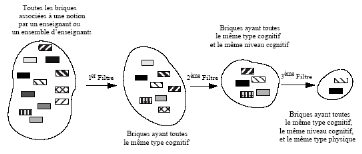
Hypertexte 
Index


3.2.5.3
La relation directe
Cette dernière méthode ce distingue des deux
méthodes précédentes par l'absence de page d'index. Ici,
la structure de l'hyperespace est totalement calqué sur la structure du
modèle du domaine : chaque concept du modèle du domaine est
représenté par une page de l'hypertexte (bien que certains
systèmes relient de temps à autre un concept à un hyper
document, c'est-à-dire une partie de l'hyperespace), et à chaque
relation on associe un lien hypertexte.
Vis-à-vis des deux méthodes
précédentes, la relation directe exige d'avoir une
représentation du modèle domaine sous forme de réseau
sémantique (ou tout autre technique) afin de pouvoir déterminer
les hyperliens, alors qu'auparavant il suffisait d'identifier les concepts sans
être obligés de les associer.
3.3
Domaine d'application des hypermédias
adaptatifs
Ces systèmes peuvent être construits pour toute
application dont l'hyperespace est assez large et les utilisateurs
diffèrent dans leurs connaissances, intérêts,
préférences et/ou tâches. Dans le passé, un nombre
important de systèmes hypermédias adaptatifs ont
été développés pour des buts éducatifs, ils
sont considérés dans plusieurs cas comme alternative des
systèmes tutoriels intelligents.
Figure 1.4: Relation directe
Hypertexte
Modèle du domaine

Les systèmes hypermédias adaptatifs peuvent
être classifiés selon leurs domaines d'application en [Koch 00] :
systèmes hypermédias éducationnels, moteurs de recherche
dans les hypermédias, systèmes d'information en ligne,
systèmes d'aide en ligne et assistants personnels. Quelques exemples
sont donnés pour chaque domaine d'application. Une comparaison des
systèmes adaptatifs hypermédias peut être trouvée
dans [Brusilovsky 96].
3.3.1
Systèmes hypermédias éducatifs
Les systèmes hypermédias adaptatifs les plus
populaires sont les systèmes liés au domaine éducatif. Ils
sont connus en tant qu'enseignement adaptatif, cours particuliers,
apprentissage et systèmes de formation ou connus par le terme
récent e-learning. Ces systèmes sont principalement basés
sur l'utilisation des connaissances de l'utilisateur pour l'adaptation. Ils
supposent que le système adaptatif sera utilisé par un groupe
hétérogène d'étudiants ou d'apprenants. Ils
observent les étudiants pendant leur travail ou apprentissage.
L'un des travaux les plus intéressants dans ce domaine
est le système d'ELM-ART qui enseigne de langage de programmation LISP
[Brusilovsky et al 96]. Les techniques d'adaptation utilisées sont le
guidage direct (le système choisit la prochaine meilleure étape)
et l'annotation des liens. L'annotation suit la métaphore de feu de
circulation, où la couleur verte est utilisée pour indiquer
qu'une section est prête et recommandée à être
apprise, jaune est employé pour prêt à être appris
mais non recommandé et le rouge indique non encore prêt à
être appris. L'adaptation (l'annotation de lien dans ce cas) est
effectuée par le principe de prérequis, i.e. une unité ne
doit pas être apprise qu'après toutes les unités
prérequises.
Plusieurs autres frameworks des systèmes
hypermédias adaptatifs pour l'enseignement connus, tel que : INTERBOOK,
TANGOW, KBS Hyperbook, SmexWeb, AHA, ISIS-Tutor et DCG.
INTERBOOK [Brusilovsky et al 96] est un système pour
délivrer les manuels électroniques adaptatifs sur le Web. Les
manuels électroniques fournis par INTERBOOK ont produit la table des
matières, un glossaire et une interface de recherche. Ces livres en
ligne (online books), comme dans ELM-ART, utilisent l'annotation colorée
pour informer l'utilisateur du statut du noeud de ce lien.
TANGOW [Carro et al 99] structure des cours sur le Web par
l'utilisation des tâches et des règles d'enseignement. Il
diffère de ELM-ART dans l'utilisation d'un arbre dynamique pour limiter
l'ensemble de tâches d'enseignement à examiner. Ceci est
réalisé en générant une page dynamiquement incluant
seulement ces tâches (fragments), qui sont considérées
appropriées à l'utilisateur par le système. Les
règles sont utilisées pour analyser les conditions
prérequises.
SmexWeb [Albrecht et al 99] est un framework qui permet le
développement des applications d'enseignement par l'instanciation d'une
collection de classes abstraites et concrètes. Semblable à
TANGOW le processus d'apprentissage consiste principalement en
définition des concepts (tâches) et des règles
d'adaptation. Tous les types d'adaptation sont utilisés par SmexWeb :
adaptation de contenu, l'adaptation pour faciliter la navigation, l'adaptation
de présentation.
AHA (Adaptive Hypermedia Applications) [De Bra et al 98] est
un système générique d'hypermédia basé sur
l'adaptation des pages en utilisant des blocs conditionnels dans le code de la
page en utilisant XHTML, dont les documents de concept spécifient la
connaissance requise de l'utilisateur. La structure du domaine est semblable
à la structure de SmexWeb. Des concepts sont liés à
d'autres concepts par des liens évalués.
Le système ISIS-Tutor [Brusilovsky 97] utilise
différentes formes de navigation adaptative, telles que guidance
directe, annotation et masquage de liens. Le but est de souligner les liens
correspondant au but de l'étudiant et masquer les concepts appartenant
aux objectifs futurs d'étude.
Le système DGC (Dynamic Course Generation)
proposé par [Vassileva 97] représente une approche tout à
fait différente. Il consiste d'une structure de domaine de concept
représentée comme plan, qui relie des concepts connus pour
l'étudiant avec le concept but du cours. Le plan est alors adapté
dynamiquement selon le progrès de l'étude. Ceci a comme
conséquence les changements dans les sous tâches et les
étapes à suivre par l'étudiant.
3.3.2
Moteurs de recherche dans les hypermédias
Les moteurs de recherche dans les hypermédias combinent
les systèmes de recherches traditionnelles avec les
caractéristiques des hypermédias. L'objectif est d'obtenir un
ensemble maniable de réponses à une requête mise à
un hyperespace d'information. Les réponses sont un ensemble de liens
obtenus par le moteur de recherche. Ces systèmes habituellement limitent
le choix de navigation et donnent les conseils ; les liens les plus
appropriés.
Un exemple très réussi est le système
HyperMan conçu par Mathé et Chen [Mathé et al 96]. Ce
système aide des contrôleurs de vol de navette spatiale de la NASA
à accéder et organiser la grande quantité d'information.
L'utilisateur peut marquer n'importe quelle partie d'un document en tant que
pièces d'intérêt et indexer une partie avec des concepts
définis pour l'utilisateur. Il peut alors rechercher les parties
marquées de documents.
Le système Personal WebWatcher [Mladenic 00]
basé sur le système WebWatcher [Armstrong et al 1995], c"est un
agent qui observe l'utilisateur sans demander de l'utilisateur des
mots-clés, des préférences ou des évaluations. Il
analyse les pages demandées dans le passé récent.
L'adaptation consiste d'annoter les liens apparus au système
intéressant à l'utilisateur.
3.3.3
Systèmes d'information en ligne
Les systèmes d'information en ligne fournissent une
référence d'accès à l'information dans un
hyperespace. Ce groupe inclut les applications de e-commerce, des
systèmes de recommandation, des bibliothèques numériques,
des catalogues électroniques et toutes classes de documentation en
ligne. L'objectif de l'adaptation est d'offrir les concepts ou les informations
demandées à l'utilisateur d'une manière appropriée,
c.-à-d. selon ses objectifs, ses connaissances de base et ses
préférences. Un exemple typique est l'administration d'un menu
adaptatif de signet (book mark). Les signets peuvent être choisis,
assortis et/ou annotés selon la fréquence absolue, relative ou
séquentielle de l'utilisation de documents, i.e. pour le temps entier
d'utilisation du système, dans le récent passé ou
l'utilisation successive.
Les applications de ce groupe diffèrent des
systèmes hypermédias adaptatifs éducationnels, car elles
ne présentent pas une introduction systématique à un sujet
d'étude. Les exemples des applications dans ce domaine sont: PUSH, Swan,
MetaDoc, AVANTI, CiteSeer et des produits commerciaux, tels que les
systèmes Amazon.com et FindMe.
Le système PUSH (Plan and User Sensitive Help)
[Höök 98] est un système d'information qui adapte seulement le
contenu à l'utilisateur en appliquant la technique d'ajustement de
texte. Il n'affecte pas comment la navigation de l'utilisateur entre les pages,
il affecte seulement le volume d'information présentée dans une
page.
Swan [Garlatti et al 99] est un serveur Web adaptatif et
navigateur pour des systèmes d'information en ligne au sujet des
publications nautiques. La structure de son modèle de l'utilisateur est
basée sur des stéréotypes. Elle se compose de classes
d'utilisateurs, d'un modèle de tâche et d'un modèle
individuel. La classe du marin est utilisée pour la présentation
adaptative. Pour la navigation adaptative, il utilise le modèle de
tâche qui utilise la classe du navire, un modèle individuel pour
chaque utilisateur et le contexte de navigation.
3.3.4
Systèmes d'aide en ligne
Des systèmes d'aide en ligne sont toujours
attachés aux outils ou à d'autres systèmes. D'un
côté ils sont des systèmes d'information en ligne, mais
l'objectif est d'aider l'utilisateur quand elle a des difficultés avec
l'outil ou le système. Cette aide consiste à présenter
l'information d'aide une fois demandée (comme dans les systèmes
d'information en ligne) et identifier automatiquement quand l'utilisateur a
besoin d'aide. Les systèmes d'aide en ligne adaptatifs ont l'avantage de
connaître le contexte dans lequel l'utilisateur travaille.
Un très connu système d'aide adaptatif, mais
n'est pas très efficace ni très accepté, est l'assistant
de Microsoft Word.
ORIMUHS [Encarnaçao 97] est un framework pour les
systèmes d'aide en ligne adaptatifs. Il est basé sur la gestion
de discours d'action-niveau, l'évaluation statistique et probabiliste et
les techniques de modélisation de l'utilisateur, telles que des
stéréotypes et des modèles en couches. L'assistance
intelligente de l'utilisateur est initialisée et peut être
contrôlée par l'utilisateur, mais la présentation
réelle est calculée par le système.
3.3.5
Assistants personnels
Des assistants personnels sont développés pour
contrôler d'une manière personnalisée un vaste hyperespace
et un hyperespace changeant dynamiquement. Ils sont utiles aux utilisateurs qui
ont besoin d'accéder certains types d'information dans un hyperespace,
tel que le Web, fréquemment. Les assistants personnels sont des agents
qui recherchent dans un espace défini identifiant l'information utile
à l'utilisateur. Pour décider quelle information est utile pour
l'utilisateur, le système se base sur un modèle de l'utilisateur.
Ces agents recherchent l'espace de l'information à une certaine
fréquence recherchant la nouvelle information, mettant à jour les
items déjà identifiés et éliminant les items qui ne
sont pas mis à jour.
Le système ifWeb est un agent adaptatif basé sur
le modèle de l'utilisateur qui soutient l'utilisateur dans leur
navigation dans le Web, c.-à-d. un assistant de recherche dans
l'hypermédia. Il navigue de façon autonome, rassemble des
documents et les classifie. Le mécanisme adaptatif laisse maintenir le
modèle de l'utilisateur, il inclue les intérêts et les non
intérêts de l'utilisateur [Asnicar et al 97].
Les assistants personnalisés de e-commerce forment un
type spécial d'assistants, qui visent à augmenter l'acceptation
du e-commerce en offrant un service personnalisé. Les exemples des
magasins électroniques adaptatifs dans le Web sont AMPres, TELLIM [Koch
00], Web Shop [Aberg et al 99] et SETA [Ardissono et al 99].
3.4
Hypermédia adaptatif dynamique
Afin d'améliorer la qualité de l'adaptation et
de prendre en compte instantanément de nouvelles données, les
chercheurs se sont orientés également vers les hypermédias
adaptatifs dynamiques [Delestre 00].
La principale caractéristique de ces systèmes
est d'offrir un hypermédia virtuel. Le système n'est plus
constitué de pages et de liens prédéfinis; ils sont
construits dynamiquement (Figure 1.5). L'architecture de ces systèmes
repose sur quatre composantes principales : le modèle du domaine, le
modèle de l'utilisateur, une base de documents et un
générateur de pages. Le modèle du domaine, comme celui des
hypermédias adaptatifs, permet de définir l'architecture globale
du système. Il y a par conséquent une adéquation entre les
noeuds du modèle du domaine et les pages de l'hypermédia virtuel,
ainsi qu'entre les relations du modèle du domaine et les liens de
l'hypermédia virtuel.
L'utilisation d'un tel système présente
plusieurs avantages :
Tout d'abord, l'adjonction d'un nouveau support peut
être immédiatement prise en compte, puisque encore une fois, les
pages du système sont construites dynamiquement.
Ensuite, les concepteurs de l'hypermédia ne sont pas
obligés de penser à la façon d'agencer les
différents documents, ils doivent juste définir l'architecture
générale du système (le modèle du domaine) et
déterminer, récupérer ou créer les documents qui
vont servir à présenter chaque concept.
Ils sont généralement constitués de trois
composants essentiels à savoir [Behaz et al 04] : modèle du
domaine, modèle de l'apprenant et générateur du cours.
Une des principales caractéristiques de modèle
du domaine est sa compétence en termes de capacité de
représentation des connaissances. Il permet de définir des
fragments d'information en spécifiant leurs taille, type, contenu,
indexation, mécanisme de filtrage, organisation et assemblage afin de
suivre l'apprenant.
Le modèle de l'apprenant est le noyau de tout
système adaptatif. Il a pour but de représenter le plus
fidèlement possible l'apprenant. Il permet d'adapter le contenu, la
présentation d'un document ainsi que la navigation. Il constitue un
modèle individuel puisqu'il permet de gérer des informations
individuelles.
La base de documents multimédias didactiques (teaching
materials)
Le générateur du cours est un moteur qui a pour
but de générer un document personnalisé à partir de
l'espace d'information du modèle de l'apprenant. Ce composant est en
mesure de créer des page qui vont être présentées
à l'apprenant en appliquant des règles de structuration et de
présentation
Le principal attrait de ce type de systèmes est
d'assurer une meilleure adaptation aussi bien au niveau contenu qu'au niveau
lien. Ceci permet de fournir un Document Virtuel Personnalisé (DVP). En
revanche ces systèmes souffrent d'une limite assez importante, en
occurrence leur complexité. Cette complexité est due d'une part
aux différents traitements de sélection et de combinaison
(assemblage) effectués sur les données, et d'autre part à
la manière de caractériser les ressources pédagogiques
impliquées.

3.5
Hypermédia dans l'éducation; avantage et
inconvénient
Dès sa création, les hypermédias par leur
structure ont semblé être un nouvel outil pour la transmission du
savoir, et donc utile dans un cadre éducatif. Aujourd'hui, cet
intérêt est encore de mise, voire plus, grâce au
développement exponentiel du réseau planétaire Internet,
avec toutes les nouveautés qui l'accompagnent, tant au niveau technique
(applications distribuées, vidéo en temps réel - ou
streaming -, visioconférence à bas prix, etc.) qu'au niveau
conceptuel; comme par exemple de classe virtuelle.
Nous allons maintenant énumérer les avantages et
les inconvénients de l'utilisation des hypermédias dans un cadre
éducatif.
3.5.1
Les hypermédias classiques
3.5.1.1
Avantages
Deux grands atouts ; issue de la structure intrinsèque
des hypermédias, émergent de leur utilisation dans un cadre
éducatif : la composante multimédia et la composante hypertexte.
L'apport du multimédia dans l'éducation est
très controversé : le multimédia apporte-t-il de
réel bénéfices au transfert de la connaissance dans un
cycle d'apprentissage, ou le multimédia est il un
phénomène de mode? A ses débuts, pour l'ensemble de la
communauté scientifique, il semblait logique l'utilisation de
données multimédias dans des logiciels éducatifs, et plus
généralement dans les systèmes d'information,
apportât obligatoirement un plus. On se basait alors sur des
hypothèses, telles que : plus on stimule nos sens, plus l'information
est compréhensible, le multimédia permet de capter plus longtemps
l'attention de l'utilisateur, l'aspect ludique du multimédia est
bénéfique.
Les hypertextes, par leur structure, aident l'apprenant
à mieux se représenter la connaissance, à mieux
appréhender les tenants et les aboutissants de chaque concept. La non
linéarité de la progression de l'apprenant l'oblige à se
construire sa connaissance en créant des connections entre les concepts.
Les hypertextes ont les avantages suivants [Delestre 00] :
·
Les hypertextes favorisent la pensée associative,
puisqu'ils permettent de présenter les tenants et les aboutissements de
chaque concept.
·
Les hypertextes favorisent l'initiative de l'apprenant, puisque
l'apprenant interagit avec le système, il ne peut pas rester passif.
·
Les hypertextes sont un support à l'apprentissage
collaboratif, car contrairement aux autres supports pédagogiques tels
que les livres, plusieurs apprenants peuvent l'utiliser simultanément.
Les hypermédias sont alors un outil propice à la
résolution de problèmes en groupe, ce qui peut amener des
discussions, des négociations entre les apprenants.
·
Les hypertextes facilitent l'apprentissage interdisciplinaire.
Il est en effet tout à fait envisageable de construire des ponts entre
différents hypermédias. On peut imaginer par exemple que la
présentation d'une notion de science physique par un hypertexte fasse
référence à des notions mathématiques dans un autre
hypertexte, et fasse aussi référence au découvreur de
cette notion ou théorie dans un troisième hypertexte historique.
3.5.1.2
Inconvénients
Malheureusement ces avantages peuvent devenir
préjudiciables. Rhéaume [Delestre 00] souligne en effet que
plusieurs problèmes peuvent apparaître lorsqu'on utilise les
hypermédias à des fins éducatives. L'apprenant peut
rencontrer deux problèmes que tout utilisateur d'Internet a
déjà rencontré; la désorientation et la surcharge
cognitive.
La désorientation est issue de la facilité de
déplacement entre les noeuds dans le système. Cette
liberté de déplacement peut finir par troubler l'apprenant. Il
risque de se poser des questions de type : « Où suis-je? »,
« pourquoi suis-je là? » ou encore « Que doit-je faire?
». Ceci est principalement dû à notre mémoire à
court terme, puisque les êtres humains ne sont pas capable de
mémoriser sur le moment qu'un nombre limité d'informations.
La surcharge cognitive est provoquée par «
l'avalanche d'information » que risque de déverser le
système. En effet, la redondance, pour être
bénéfique, doit être construite de façon
intelligente. En aucun cas, il ne faut présenter la même
information à l'aide de différents médias ne
nécessitant pas le même niveau de connaissance.
3.5.2
Les hypermédias adaptatifs
3.5.2.1
Avantages
Les hypermédias adaptatifs représentent une
avancée non négligeable vis-à-vis des hypermédias
classiques. Ils sont un atout pour les utilisateurs de système : les
enseignants et les apprenants.
Tout d'abord, les différentes techniques
utilisées permettent à l'étudiant d'être
guidé dans son apprentissage. Ainsi, sans toutefois annihiler la
liberté de navigation intrinsèque aux hypermédias,
l'étudiant est constamment guidé dans son cheminement. Plusieurs
études ont montré l'intérêt des hypermédias
dynamiques vis-à-vis des hypermédias dits classiques ou
statiques. Les hypermédias dynamiques peuvent améliorer
l'assimilation des connaissances, ils peuvent réduire de façon
considérable le parcours de l'utilisateur dans l'hyperespace.
Les hypermédias adaptatifs (surtout pour ceux qui
effectuent une relation directe entre le modèle du domaine et les pages
de l'hypermédia) permettent aux enseignants de mieux structurer leur
travail. En effet, le fait de distinguer la connaissance des outils qui
permettent de la présenter, éclaircit le travail de l'enseignant.
Ce dernier peut alors mieux structurer son travail en pensant tout d'abord
à l'organisation des connaissances, et ensuite à la façon
de les exposer.
3.5.2.2
Inconvénients
Tout d'abord, l'accent a surtout été mis sur
l'adaptation des liens afin de guider l'apprenant dans son cheminement. Or
l'adaptation du contenu qui a souvent été mise à
côté. Parce que la méthodologie de développement et
l'architecture de ces systèmes hypermédias adaptatifs sont issues
de systèmes hypermédias classiques déjà
définis. Auxquels les chercheurs ont ajouté des techniques
d'adaptation. Or, alors qu'il est assez aisé de cacher des liens, ou
bien de les annoter. Il est beaucoup plus difficile de remplacer un item d'une
page ou bien modifier la structure d'une autre.
Ensuite, on sait qu'un bon système éducatif doit
être un système ergonomiquement uniforme (par exemple dans les
livres scolaires, les différents cours ont, à peut près,
la même architecture et le même enchaînement logique). Or
rien n'oblige les hypermédias à suivre cette démarche, ce
qui peut être dommageable pour l'apprenant.
Enfin, tout comme un enseignant, il faut que le système
puisse utiliser immédiatement toute nouvelle connaissance, ou tout
nouveau média pour présenter une nouvelle connaissance. C'est une
des caractéristiques d'un bon enseignant, il doit par exemple utiliser
au maximum l'actualité pour agrémenter son cours. Ainsi, si une
personne trouve ou construit un nouveau média en rapport avec un des
concepts enseignés, le fait de l'ajouter doit permettre au
système d'enrichir instantanément les cours sur ce concept, ce
qui pour l'instant n'est pas très aisé à réaliser.
3.5.3
Les hypermédias adaptatifs dynamiques
L'utilisation de ce type de système apporte les
avantages suivants :
·
Tout d'abord l'adjonction d'un nouveau support peut être
immédiatement pris en compte, puisque les pages du système sont
construites dynamiquement.
·
Ensuite, les enseignants ne sont pas obligés de penser
à la façon d'agencer les différents médias, ils
doivent juste définir l'architecture générale du
système (le modèle du domaine) et déterminer,
récupérer ou créer les matériaux
pédagogiques qui vont être utilisés pour présenter
les notions introduites dans les cours.
En revanche ces systèmes souffrent d'une limite assez
importante, en occurrence leur complexité. Cette complexité est
due d'une part aux différents traitements de sélection et de
combinaison (assemblage) effectués sur les données, et d'autre
part à la manière de caractériser les ressources
pédagogiques impliquées.
4
Les systèmes hypermédias adaptatifs
dynamiques METADYNE et TANGOW
Nous présentons dans ce qui suit deux systèmes
hypermédias adaptatifs dynamiques caractérisant les concepts
présentés ci-dessus : METADYNE [Delestre 00], un
hypermédia dont le but est de fournir un cours en ligne adapté
aussi bien aux connaissances qu'aux préférences de l'utilisateur.
Le deuxième système est TANGOW,
4.1
Le système METADYNE, un hypermédia adaptatif
dynamique pour l'enseignement
D'après ce que l'on a vu précédemment,
l'architecture des hypermédias adaptatifs dynamiques doit reposer sur
quatre composantes principales : le modèle du domaine, le modèle
de l'utilisateur, une base de documents multimédias et un
générateur du cours. Cependant l'utilisation des
hypermédias adaptatifs dynamiques soulève quelques questions :
·
Quelles connaissances doit intégrer le système?
·
Comment construire dynamiquement les pages de
l'hypermédia?
·
Comment développer ce type de projet pour qu'il soit
accessible depuis un simple navigateur Web?
4.1.1
Objectifs de METADYNE
·
Distinguer le fond de la forme afin d'inciter les enseignants
à suivre une méthodologie de construction, le système ne
doit pas leur permettre d'agencer les items didactiques pour construire leurs
cours. Il doit tout d'abord leur permettre d'identifier les notions qui sont
introduites dans les cours, en les reliant par différents types de
relations.
·
Permettre aux enseignants de changer leurs points de vues.
·
Améliorer l'adaptabilité : cette distinction entre
le fond et la forme va permettre d'étendre l'adaptabilité du
système. En effet alors qu'auparavant, seule les volontés de
l'enseignant transparaissaient dans les cours, avec METADYNE les apprenants
vont pouvoir spécifier certaines caractéristiques qui seront
utilisés par le générateur du cours.
·
Vers un système adaptatif : si l'on insère dans
METADYNE le profil de l'apprenant, le générateur de cours pourra
en tenir compte, ce qui modifiera les cours produits. Dès lors tout
cours produit par le système, sera fonction des informations fournies
par l'enseignant, des caractéristiques fournies par l'apprenant et du
profil de l'apprenant.
·
Fournir des outils intuitifs : les possibilités actuelles
des navigateurs nous permettent de concevoir un système dont les outils
sont de véritables applications qui peuvent être activées
comme une page Web et s'exécuter au sein du navigateur.
4.1.2
Les connaissances nécessaires à la
génération d'un cours
Nous allons commencer par analyser les connaissances
liées aux enseignants, c'est à dire le modèle du domaine.
Puis nous nous intéressons au modèle de l'apprenant, nous
définirons par la suite les composants qui vont permettre de construire
les cours ; qui sont les briques élémentaires. Nous finirons en
indiquant comment le générateur de cours utilise ces
différentes connaissances.
4.1.2.1
Le modèle du domaine
Un modèle du domaine représente le savoir des
enseignants, il est modélisé par un réseau
sémantique. Les différentes connaissances sont organisées
de façon hiérarchique, il incombe aux enseignants de
définir cette hiérarchie ; un cours est induit des notions qui
peuvent elles-mêmes référencer d'autres notions, les
différents agencements doivent être représentés, il
en a la définition de quatre relations caractérisant les liens
entre les notions:
·
La relation de prérequis qui indique que l'apprentissage
d'une notion A est assujettie à la maîtrise de la notion B.
·
La relation d'analogie qui indique que la maîtrise d'une
notion A peut aider l'apprentissage d'une nouvelle notion B.
·
La relation de conjonction qui indique que l'apprentissage d'une
notion A s'effectue via l'apprentissage séquentiel d'une succession de
notions Aj
·
La relation de disjonction forte qui indique que l'apprentissage
d'une notion A peut s'effectuer via l'apprentissage de l'un des notions Aj.
Comme l'analogie entre deux notions peut être plus ou
moins importante ainsi que la relation de prérequis, ces deux relations
seront pondérées suivant l'importance que l'enseignant accorde
à chacune d'elles.
La Figure 1.6 présente un exemple de
représentation du modèle du domaine présentant le cours
« Oscillation électrique libre » par l'enseignant X.
4.1.2.2
Le modèle de l'apprenant 2.2 Le modèle de
l'apprenant
Le modèle de l'apprenant doit intégrer aussi
bien les connaissances de l'apprenant sur le modèle du domaine, ce qui
l'on nomme le modèle épistémique, que les
particularités non épistémiques, c'est-à-dire les
préférences de l'apprenant ou ses objectifs pédagogiques.
Ce deuxième sous modèle rarement utilisé, se nomme le
modèle comportemental. Le modèle de l'apprenant doit
intégrer aussi bien les connaissances de l'apprenant sur le
modèle du domaine, ce qui l'on nomme le modèle
épistémique, que les particularités non
épistémiques, c'est-à-dire les préférences
de l'apprenant ou ses objectifs pédagogiques. Ce deuxième sous
modèle rarement utilisé, se nomme le modèle
comportemental.
-
Le modèle épistémique : Le
modèle épistémique peut être considéré
comme un dérivé du modèle du domaine. Ainsi, chaque
concept du modèle du domaine est associé au modèle
épistémique de l'apprenant par une relation
pondérée. Afin d'améliorer ce modèle, le facteur
temps est introduit comme une variable d'une fonction d'oubli. Le modèle
épistémique n'existe donc que par les relations qui le relient au
modèle du domaine. La pondération de celles-ci indique la
connaissance qu'a le système sur la connaissance de l'utilisateur sur ce
un concept. Cette valeur peut être soit « j'ignore l'état de
connaissance de l'utilisateur » et dans ce cas on associe une valeur
réelle, proportionnelle au niveau de connaissance de l'utilisateur, et
remise à jour régulièrement en fonction de la date de la
dernière relecture de ce concept par l'apprenant. -
Le modèle épistémique : Le modèle
épistémique peut être considéré comme un
dérivé du modèle du domaine. Ainsi, chaque concept du
modèle du domaine est associé au modèle
épistémique de l'apprenant par une relation
pondérée. Afin d'améliorer ce modèle, le facteur
temps est introduit comme une variable d'une fonction d'oubli. Le modèle
épistémique n'existe donc que par les relations qui le relient au
modèle du domaine. La pondération de celles-ci indique la
connaissance qu'a le système sur la connaissance de l'utilisateur sur ce
un concept. Cette valeur peut être soit « j'ignore l'état de
connaissance de l'utilisateur » et dans ce cas on associe une valeur
réelle, proportionnelle au niveau de connaissance de l'utilisateur, et
remise à jour régulièrement en fonction de la date de la
dernière relecture de ce concept par l'apprenant.
-
Le modèle comportemental :
Alors que le modèle épistémique est
toujours présent dans les systèmes d'enseignement, le
modèle comportemental est le plus souvent très limité
voire absent. Or le système adaptatif se veut très proche de
l'apprenant, ce qui signifie qu'il doit prendre en compte aussi bien ses
préférences, ses objectifs, que ses capacités
naturelles:
1.
Les préférences de l'apprenant vont avoir un
impact sur l'organisation des pages qui lui seront présentées.
Lors de l'initialisation de son modèle, l'apprenant spécifiera
les caractéristiques de ce que l'on nomme un canevas. Ce canevas
servira de modèle pour la construction de toutes les pages qui lui
seront adressées.
2.
Les objectifs de l'apprenant auront une influence sur le
comportement du système. En effet, que l'utilisateur veuille
réviser pour un examen, ou qu'il veuille approfondir de façon
informelle ses connaissances.
3.
Enfin, les capacités de l'apprenant seront pris en
compte, non pas de façon globale, mais par type de matière.

4.1.2.3
Le générateur du cours
Cette dernière composante est chargée de la
création des pages qui vont être présentées à
l'apprenant. Ainsi, une fois que l'apprenant a précisé le cours
qu'il voulait suivre, il indique au système les objectifs de ce cours
(par exemple en vue d'un examen ou d'un simple apprentissage). Le
système peut alors récupérer le concept correspondant
ainsi que les notions en relation avec ce dernier.
Le générateur du cours va essayer pour chaque
élément du canevas de l'apprenant de trouver le meilleur
média. Pour cela, il va récupérer l'ensemble des briques
élémentaires, associées à la notion courante en se
restreignant au point de vue choisi par l'apprenant.
Pour choisir la meilleure brique élémentaire, le
générateur du cours applique trois filtres:
·
Le premier permet d'extraire un sous-ensemble de brique pour un
type cognitif donné.
·
Le second permet d'effectuer la même opération mais
pour un ensemble de niveau cognitif déterminé.
·
Le troisième effectue l'extraction pour un type physique
donné.
Comme le montre la Figure 1.7, l'utilisation successive de ces
trois filtres permet d'extraire « la meilleure brique
élémentaire ». Si l'utilisation des filtres induise un
ensemble vide en sortie, les règles suivantes sont appliquées:
·
Si nous n'obtenons aucune brique comme résultat du
troisième filtre, nous élargissons la recherche en prenant en
considération l'ordonnancement des types physiques définis.
·
Si à l'issue du deuxième filtre, nous n'obtenons
aucune brique dont le niveau cognitif est équivalent à la
connaissance de l'apprenant, nous réitérons l'opération en
recherchant des briques dont le niveau cognitif est inférieur au niveau
de l'apprenant.
·
Si à l'issue du deuxième filtre, nous n'obtenons
aucune brique dont le niveau cognitif est inférieur ou égal
à la connaissance de l'apprenant, nous réitérons
l'opération en cherchant des briques dont le niveau cognitif est
supérieur au niveau de l'apprenant.
·
Si à l'issue du premier filtre, nous n'obtenons aucune
brique, nous réitérons la recherche en prenant un point de vue
plus large, c'est-à-dire en ajoutant successivement le point de vue des
enseignants du même domaine, puis ceux des champs d'enseignement «
supérieur » dans la hiérarchie des domaines d'enseignement.
4.1.2.4
La sélection des liens hypertextuels
Une fois que le contenu d'une page est construit, il faut
déterminer les liens hypertextes permettant à l'utilisateur
d'accéder à des notions sous-jacentes, pour cela il suffit de
prendre en compte :
·
Les relations du modèle du domaine;
·
Le modèle épistémique;
·
Le type de cours désiré ; en vue d'un examen, en
vue d'un parcours plus libre
Enfin, il faut déterminer le type de page ou de lien
hypertexte pour chaque type de relation du modèle du domaine.
La Figure 1.8 résume l'architecture du système
4.2
Le système TANGOW, Task-based Adaptive learNer
Guidance On the WWW
Le système TANGOW (Task-based Adaptive learNer Guidance
On the WWW) [Carro et al 99] est un outil pour développer des cours sur
Internet. Ce système facilite la construction des environnements
adaptatifs d'apprentissage sur le Web et permet de guider les étudiants
pendant leur apprentissage, basé sur les profils des étudiants et
l'historique des actions précédentes. Les cours sont
structurés au moyen de tâches d'enseignement (Teaching Tasks) et
de règles, qui sont stockées dans une base de données.
Dans TANGOW un processus d'étudiant est lancé pour chaque
étudiant relié au système. Chaque processus
d'étudiant se compose de deux modules principaux : un directeur de
tâche (Task Manager) qui guide les étudiants dans leur
apprentissage, et un générateur de page qui produit des pages
HTML. Le processus d'étudiant maintient aussi des informations sur les
actions effectuées par l'étudiant. Cette information est
utilisée par TANGOW pour adapter le contenu de cours au progrès
de l'apprentissage de l'étudiant. TANGOW a également les
informations sur des profils d'étudiant, qui sont utilisées pour
choisir, au temps d'exécution, le contenu de chaque page HTML à
présenter.

4.2.1
Teaching Tasks (TT)
Un cours est décrit en termes de tâches
d'enseignement (TT : Teaching Tasks) et de règles. Un TT est
l'unité de base qui apparaît dans l'apprentissage, qui peut
être atomique ou composé. La connaissance est
représentée au moyen de TTs qui doivent être
réalisés. TTs peuvent être théoriques, pratiques ou
un ensemble d'exemples. En outre, un TT peut avoir une liste
d'éléments de médias (texte, images, vidéos,
applet, animations...) associés. Un langage de description qui indique
les positions relatives de ces éléments de médias est
utilisé dans la construction de pages HTML, qui seront
présentées aux étudiants. Les éléments
spécifiques inclus en ces pages dépendrent aux informations sur
le profil de l'étudiant et son processus d'apprentissage.
4.2.2
Rules (règle)
Les règles décrivent comment un TT est
divisé en sous tâches. Il peut y avoir plusieurs règles
pour le même TT, chacune d'eux représente une manière
spécifique de décomposer le TT en sous tâches. Il peut
être nécessaire d'exécuter toutes ces sous tâches
suivant un ordre fixe (AND sequencing), dans n'importe quel ordre (ANY
sequencing), ou seulement certains d'entre eux (OR/XOR sequencing). En outre,
les règles définissent les conditions à appliquer, qui
peuvent dépendre des informations sur les tâches
déjà réalisées, le profil de l'étudiant et
la stratégie d'apprentissage suivie.
4.2.3
Architecture de TANGOW
L'architecture de TANGOW est basée sur le paradigme
standard de Web, où le serveur reçoit des demandes des
étudiants par leurs navigateurs. Pour chaque étudiant
connecté au système, il y a un processus : Task Manager, qui
contrôle l'apprentissage de l'étudiant pendant la session. Si le
même étudiant suit plus d'un cours, il y aura un Task Manager pour
chacun d'eux. Tous ces processus sont contrôlés par un Process
Manager qui reçoit des informations sur les actions de l'étudiant
d'un programme CGI exécuté sur le serveur Web. Le Task Manager
stocke des informations sur les actions de l'étudiant et envoie
l'information appropriée au Page Generator qui produit des pages HTML
dynamiquement et les envoie de nouveau à l'étudiant par le
programme CGI. Tous ces modules utilisent l'information stockée dans les
bases de données suivantes :
Users DB, Il contient des données sur
les profils des étudiants et leurs actions pendant l'apprentissage. Un
profil d'étudiant inclut l'information personnelle telle que son
âge, langue choisie et préférences en ce qui concerne la
stratégie d'étude.
Course Content DB, Il contient tous les
éléments de médias (textes, images, vidéos,
animations, simulations, applet, etc.) qui apparaîtront dans les pages
HTML. Ils sont classifiés selon des attributs définissant le
profil d'étudiant (i.e. langue, âge...).
Teaching Tasks Repository, Il contient une
description générale de toutes les tâches d'enseignement
qui ont été définies par le concepteur de cours. Cette
description inclut des attributs généraux de tâche tels que
son nom, description, type de contenu (théorique, pratique ou exemple),
type de composition (atomique ou composé), conditions
d'achèvement (une fonction qui décide, au temps
d'exécution, si des tâches ont été accomplies), et
une liste facultative d'éléments de médias utilisés
pour la génération de page.

Tous les composants mentionnés ci-dessus du
système sont illustrés sur la , où les flèches
pointillées représentent l'écoulement de l'information et
les solides représentent la communication interprocessus. La
flèche blanche représente un appel de fonction.
4.2.3.1
Programme CGI
Le programme CGI vérifie les paramètres
reçus du navigateur de client et les envoie au Process Manager. Si la
demande correspond au commencement d'une session, des données
liées à l'endroit de client sont envoyées avec ces
derniers. Enfin, le programme CGI attend une réponse de page generator
et envoie les pages HTML produites à l'étudiant.
4.2.3.2
Process Manager
Process Manager travaille comme serveur, attendant des
demandes du programme CGI. Si les paramètres de demande correspondent au
commencement d'une session, le Process Manager lance un nouveau Task Manager et
lui attribue un identificateur. Si la demande identifie une session
déjà commencée, le Process Manager obtient
l'identificateur chez le Task Manager correspond. Enfin, le Process Manager
envoie les paramètres de demande au Task Manager.
4.2.3.3
Task Manager
Comme déjà mentionné, Task Manager guide
les étudiants dans leur apprentissage en décidant le prochain
ensemble de tâches réalisables offertes à
l'étudiant. Les éléments dans cet ensemble
dépendent de la stratégie d'étude active, les
données personnelles de l'étudiant et les actions
précédemment exécutées. Cette information est
transférée au Task Manager. De plus, les informations
stockées de Task Manager sur les actions exécutées par
l'étudiant et leurs résultats (le nombre de pages
visitées, le nombre d'exercices accomplis, le nombre d'exercices
résolus avec succès, etc.). Finalement, le Task Manager fournit
au Page Generator les paramètres nécessaires à la
génération dynamique de page.
4.2.3.4
Page Generator
Page Generator reçoit les paramètres utiles
associés à la tâche active pour produire des pages HTML
dynamiquement. Ces paramètres sont liés au profil de
l'étudiant et aux actions de l'étudiant. Basé sur cette
information Page Generator décide quel type d'éléments de
médias (i.e. textes, images, vidéos, animations, simulations,
applet, etc.) à utiliser dans le document de HTML et comment ils doivent
présenter. Des informations sur le profil de l'étudiant seront
utilisées pour choisir les éléments spécifiques de
médias selon des caractéristiques, tels que la difficulté
de contenu, langue dans lesquelles ils sont écrits, etc. Une fois la
page HTML générée, elle est envoyée de nouveau
à l'étudiant par le programme CGI.
4.2.4
Apprentissage adaptatif dans TANGOW
Quand un étudiant accède TANGOW pour la
première fois, le système lui demande ses données
personnelles telles que l'âge, la langue et la stratégie
d'étude préférées. Ces informations sont
stockées dans users DB.
Si l'étudiant a accédé le système
avant, Task Manager utilise les informations stockées sur des actions
précédentes de l'étudiant liées au cours choisi,
elles sont utilisées pour demander de Page Generator de fournir à
l'étudiant la page appropriée du cours. Sinon, la page initiale
du cours sera présentée.
A chaque étape de la session d'apprentissage, Task
Manager construit une liste des tâches réalisables qui peuvent
être présentées à l'étudiant par le choix des
sous tâches qui (1) appartiennent à l'ensemble de sous
tâches dans lesquelles la tâche courante est
décomposée dans l'arbre dynamique (dynamic tree : partie de
Dynamic Workspace de Figure 1.9), (2) n'ont pas été
étudiées encore, et (3) sont actionnable. Une tâche est
actionnable s'il existe au moins une règle qui la définit dont
ces conditions d'activation est satisfaites. Cette liste sera
présentée à l'étudiant comme page de menu. Si la
liste de tâches réalisables contient un élément
simple, ceci sera directement présenté.
Chaque fois qu'une tâche est finie, Task Manager
vérifie ses résultats d'exécution (i.e. le nombre des
exercices accomplis, le nombre d'exercices bien accomplis, le nombre de pages
visitées, etc.) comme stockés dans l'arbre dynamique et calcule
la valeur de succès de la tâche. Les résultats de
l'exécution de la tâche sont alors propagés vers le haut
dans l'arbre dynamique à utiliser à l'avenir pour le guidage
d'étudiant. Puis, Task Manager vérifie si les conditions
d'achèvement de la tâche d'ancêtre sont satisfaites. Si
c'est le cas, l'étudiant n'a pas besoin d'exécuter aucune autre
tâche secondaire et les extrémités de tâche
d'ancêtre automatiquement. Task Manager monte l'arbre dynamique
vérifiant les conditions d'achèvement de tâches
ancêtres jusqu'à qu'il trouve une tâche qui n'a pas
été accomplie encore. Enfin, il construit une liste avec des
tâches réalisables suivant le processus décrit ci-dessus.
En utilisant l'arbre dynamique seulement un sous-ensemble des tâches
d'enseignement existantes va être examiné afin de construire la
liste des tâches réalisables. Ceci rend le programme
d'études ordonnançant le processus très efficace.
En ce qui concerne l'adaptation, TANGOW utilise trois
mécanismes différents; le premier est une décomposition de
tâche, qui peut être différente selon le profil de
l'étudiant. Par exemple, une tâche peut être
décomposée de deux manières différentes : une
décomposition peut inclure des sous tâches liées à
la théorie et les exercices et l'autre peut contenir une sous
tâche additionnelle avec des exemples. Différents critères
seraient établis pour choisir. La deuxième manière
d'adaptation est d'inclure dans les règles des prés conditions
liées à d'autres tâches accomplies. De cette façon,
les cours sont adaptés aux étudiants selon ses actions
précédentes. L'adaptation est aussi présente lors de la
construction de pages HTML en utilisant différents
éléments multimédias selon le profil de l'étudiant;
les médias qui apparaissent dans les pages sont choisis selon la langue
et l'âge d'étudiant. Les textes et les sons seront
différents selon la langue de l'étudiant. De plus, le même
concept peut être expliqué dans différentes manières
selon l'âge de l'étudiant en utilisant des mots de
difficultés différentes. Le même critère s'applique
aux graphiques, aux animations et aux vidéos, qui peuvent changer selon
les caractéristiques de l'étudiant.
Ce sont les manières principales d'adapter les cours
à chaque étudiant, elles dépendent des décisions
prises par le concepteur de cours en décrivant le cours en termes de
tâches et règles, mais elles ne sont pas les seules. Les
stratégies d'enseignement ont également une influence sur l'ordre
dans lequel les sous tâches sont exécutées. En ce moment,
il y a deux stratégies prédéfinies : «
présentation de théorie d'abord » et « exercices
pratiques d'abord ». L'étudiant peut choisir sa stratégie
préférée au début d'une session.
5
Conclusion
Dans ce chapitre, nous avons rapidement étudié
l'évolution des systèmes d'enseignement assisté par
ordinateur, on peut souligner quelques grandes évolutions. L'ordinateur,
notamment de par l'évolution des interfaces et des possibilités
d'action et d'exploration qu'il offre, tend à devenir un poste de
travail intégrant de multiples environnements, allant de simples outils
de traitement de textes à des environnements hautement interactifs
donnant accès via Internet à de multiples ressources. De
l'apprentissage individualisé, l'intérêt s'est
déplacé vers l'apprentissage coopératif et de
systèmes cherchant à établir un dialogue avec l'apprenant
se sont substitués des environnements favorisant l'action et la
production de l'élève, ce dernier gardant une grande marge de
contrôle.
Or aujourd'hui, le Web, l'un des services du réseau
Internet, est l'une des clés de voûtes des Nouvelles Technologies
de l'Information et de la communication, dont l'acquisition de l'information
est basée sur le principe de l'hypertexte.
Les hypermédias représentent une nouvelle
méthode de transmission de l'information, leur utilisation dans un cadre
éducatif, qui pour les premiers types d'hypermédias posaient
quelques problèmes (la désorientation, la surcharge cognitif).
Certaines études ont tenté de minimiser l'impact cognitif des
hypermédias avec l'apparition des hypermédias adaptatifs puis les
hypermédias adaptatifs dynamiques ; qu'on a présenté deux
types de ces système METADYNE et TANGOW.
Chapitre 2
Les systèmes multi-agents
1
Introduction
Le thème des systèmes multi-agents, s'il n'est
pas récent, est actuellement un champ de recherche très actif.
Cette discipline est à la connexion de plusieurs domaines en particulier
de l'intelligence artificielle, des systèmes informatiques
distribués et du génie logiciel. C'est une discipline qui
s'intéresse aux comportements collectifs produits par les interactions
de plusieurs entités autonomes et flexibles appelées agents, que
ces interactions tournent autour de la coopération, de la concurrence ou
de la coexistence entre ces agents. Ce chapitre introduit, tout d'abord, les
notions d'agents et de systèmes multi-agents, et détaille par la
suite
Les travaux sur les systèmes éducatifs et
surtout les systèmes tutoriels intelligents (STI) se sont poursuivis
activement depuis le début des années 90. Des nouvelles tendances
se sont concrétisées telles l'accent mis sur l'apprentissage
collaboratif, les interfaces adaptatives et les systèmes multi-agents.
Ces recherches sur les agents sont guidées par la
nécessité d'avoir des environnements interactifs qui tracent
à la fois le comportement du système informatique et celui des
usagers (tuteur ou apprenant). En effet, lorsqu'il s'agit de concevoir des
systèmes informatiques distribués qui manipulent des
connaissances hétérogènes, la technologie agent se
révèle bien adaptée. Les systèmes multi-agents
permettent non seulement le partage ou la distribution de connaissance, mais
aussi, de faire coopérer un ensemble d'agents et de coordonner leurs
actions pour l'accomplissement d'un but commun.
2
Concept d'agent
La notion d'agent n'est pas simple à définir. Il
existe en effet plusieurs définitions ou significations données
à cette notion. C'est la raison pour laquelle plusieurs auteurs essayent
d'en donner une définition avant de se pencher sur l'utilisation de ce
paradigme dans tel ou tel contexte.
2.1
Définition d'un agent
Ferber [Ferber 95] définit un agent comme une
entité physique ou virtuelle
a.
qui est capable d'agir dans un environnement,
b.
qui peut communiquer directement avec d'autres agents,
c.
qui est mue par un ensemble de tendances (sous la forme
d'objectifs individuels ou d'une fonction de satisfaction, voire de survie,
qu'elle cherche à optimiser),
d.
qui possède des ressources propres,
e.
qui est capable de percevoir (mais de manière
limitée) son environnement,
f.
qui ne dispose que d'une représentation partielle de cet
environnement (et éventuellement aucune),
g.
qui possède des compétences et offre des services,
h.
qui peut éventuellement se reproduire,
i.
dont le comportement tend à satisfaire ses objectifs, en
tenant compte des ressources et des compétences dont elle dispose, et en
fonction de sa perception, de ses représentations et des communications
qu'elle reçoit.
Ferber [Ferber 95] opère une différence entre
les agents logiciels et les agents purement situés (qui sont davantage
des entités physiques). Un agent logiciel ou agent purement communiquant
est une entité informatique qui :
j.
se trouve dans un système ouvert,
k.
peut communiquer directement avec d'autres agents,
l.
est mue par un ensemble d'objectifs propres,
m.
possède des ressources propres,
n.
ne dispose que d'une représentation partielle des autres
agents,
o.
possède des compétences (services) qu'elle peut
offrir aux autres agents,
p.
a un comportement tendant à satisfaire ses objectifs, en
tenant compte des ressources et des compétences dont elle dispose, et en
fonction de ses représentations et des communications qu'elle
reçoit.
[Jennings et al. 98] définissent un agent
comme un système informatique situé dans un certain
environnement, capable d'exercer de façon autonome des
actions sur cet environnement en vue d'atteindre ses objectifs.
D'après cette définition un agent intelligent se
caractérise par les propriétés suivantes :
·
autonomie : un agent possède un état interne (non
accessible aux autres) en fonction duquel il entreprend des actions sans
intervention d'humains ou d'autres agents ;
·
réactivité : un agent perçoit des stimuli
provenant de son environnement et réagit en fonction de ceux-ci ;
·
capacité à agir : un agent est mû par un
certain nombre d'objectifs qui guident ses actions, il ne répond pas
simplement aux sollicitations de son environnement;
·
sociabilité : un agent communique avec d'autres agents ou
des humains et peut se trouver engager dans des transactions sociales
(négocier ou coopérer pour résoudre un problème)
afin de remplir ses objectifs.
Plusieurs chercheurs définissent la notion d'agent par
rapport à celle d'objet, arguant du fait que la maîtrise d'une
nouvelle technologie ou d'un nouveau concept est facilitée par une
référence à des technologies ou concepts voisins et d'ores
et déjà maîtrisés [Odell et al. 00]. Les objets se
définissent comme des entités informatiques qui encapsulent un
état, sont capables d'accomplir des actions, ou méthodes dans cet
état, et communiquent par échange de messages. Bien qu'il existe
plusieurs similitudes entre les agents et les objets, il n'en existe pas moins
d'importantes différences. La première concerne le degré
d'autonomie. La propriété la plus caractéristique des
objets est le principe d'encapsulation, l'idée selon laquelle les objets
contrôlent leur propre état interne. Dans ce sens, un objet peut
être considéré comme ayant une autonomie sur son
état. Mais un objet n'a pas de contrôle sur son comportement : si
une méthode m est rendue accessible aux autres objets, alors ceux-ci
peuvent les invoquer chaque fois qu'ils le veulent. En d'autres termes, une
fois qu'un objet a rendu une méthode publique, il n'a plus de
contrôle sur l'exécution ou la non exécution de cette
méthode. Les agents, quant à eux, n'invoquent pas des
méthodes mais adressent des requêtes pour l'exécution des
actions. Si un agent i demande à un autre agent j d'exécuter une
action a, j exécutera l'action ou ne l'exécutera pas. On voit
donc que dans le cas des objets, la décision d'exécuter l'action
appartient à l'objet qui invoque la méthode alors que pour les
agents, cette décision revient à celui qui reçoit la
requête. La seconde différence entre les objets et les agents
réside au niveau des caractéristiques de
réactivité, de dynamisme et de sociabilité. La
troisième différence entre les objets et les agents vient du fait
que ces derniers sont censés avoir chacun leur fil d'exécution
(thread). Il faut noter une évolution dans la communauté des
adeptes de la POO vers la notion d'objet actif. Un objet actif est un objet
possédant son propre fil d'exécution. Les objets actifs sont
généralement autonomes, c'est-à-dire qu'ils peuvent
exhiber un comportement sans avoir été sollicités par un
autre objet. [Odell et al. 00] présentent les agents comme une extension
d'objets actifs possédant une prise d'initiative (la capacité
à initier des actions sans intervention externe) et un libre arbitre (la
capacité à refuser ou à modifier une requête
externe). Odell et ses collègues définissent un agent comme un
objet qui peut prendre des initiatives (an objet that can say `go'...)
et refuser de répondre à une sollicitation (... and `no').
Finalement ces auteurs définissent un agent comme toute entité
autonome capable de communiquer avec son environnement. Il faut noter que
l'auteur utilise cette mise en perspective des agents par rapport aux objets
pour proposer une extension au langage UML pour spécifier des agents. Le
résultat en est le AUML pour Agent UML.
Par ailleurs, sur le plan pratique, l'approche agent est plus
générale et apporte des outils qui s'intègrent à de
multiples applications. Leur développement est motivé par un
très grand nombre de champs d'application, on peut, entre autre, citer
[Bourdon 01] :
·
Le commerce électronique
·
La gestion et le suivi en temps réel des réseaux
de télécommunication
·
La modélisation et l'optimisation de flux de marchandises
ou de données
·
Le traitement de l'information dans des systèmes sur
Internet (recherche, filtrage, présentation, etc.).
·
La gestion de trafic routier et aérien
·
L'optimisation des processus industriels de fabrication;
·
Les jeux électroniques;
·
L'étude et la simulation de phénomènes
complexes dans des organisations humaines ou naturelles, comme la
réaction à une situation de crise (tremblement de terre), et
l'évolution des rôles ou des normes dans une société
2.2
Caractéristiques d'agent
En utilisant quelques définitions de la
littérature, il est possible de créer un ensemble de
caractéristiques d'agent primaires, secondaires et tertiaires [Baily
02]. Les caractéristiques primaires sont inhérentes de la plupart
des définitions populaires d'agent, les caractéristiques
secondaires sont l'ensemble de caractéristiques, liées aux
agents, prolongées habituellement. Le troisième ensemble de
caractéristiques contient davantage les caractéristiques
abstraits, désirables et qui ressemblent à celles de l'humain.
2.2.1
Caractéristiques primaires
Autonome : l'agent peut spontanément
effectuer certaines tâches, peut prendre des initiatives.
Communicative/sociale : Un agent devrait
avoir un niveau élevé de communication avec d'autres agents. Le
protocole de communication entre agent le plus commun KQML (Knowledge Query
and Manipulation Language).
Réactive : Un agent devrait pouvoir
percevoir son environnement (qui peut être un monde physique, un
utilisateur via une interface graphique ou une collection d'autres agents) et
réagir à ses changements, que ce soit la modification des
objectifs de l'utilisateur ou des ressources disponibles.
2.2.2
Caractéristiques secondaires
Proactive : les agents n'agissent pas
simplement en réponse à leur environnement, ils son capables
d'exposer un comportement dirigé but en prenant l'initiative.
Adaptatif : un agent adaptatif est un agent
capable de contrôler et d'adapter ses aptitudes (communicationnelles,
comportementales, etc.) en réponse aux connaissances internes ou aux
changements de l'environnement.
Orienté-but/intentions : ces agents
ont un plan d'action interne explicite pour accomplir un but ou ensembles des
objectifs.
Persistance : les agents persistants ont un
état interne qui reste cohérent.
Mobilité : les agents mobiles peuvent
décider d'émigrer à une machine différente ou
à un autre réseau tout en maintenant la persistance.
2.2.3
Caractéristiques tertiaires
Emotion : agents avec la capacité
d'exprimer l'émotion ou l'humeur comme un être humain. De tels
agents pourraient également avoir une certaine forme de caractère
ou d'aspect anthropomorphe.
L'intelligence : agents avec la
capacité de raisonner, apprennent et adaptent dans le temps. Un agent
est intelligent s'il est capable de réaliser des actions flexibles et
autonomes pour atteindre les objectifs qui lui ont été
fixés. La flexibilité signifie la réactivité, la
proactivité et les attitudes sociales.
2.3
Typologies d'agents
Nwana [Mbala 03] propose une typologie des agents à
partir de plusieurs critères de classification :
·
Mobilité : statique ou mobile ;
·
Présence d'un modèle de raisonnement symbolique :
délibératif ou réactif ;
·
Existence d'un objectif et de propriétés initiales
comme l'autonomie, la coopération et l'apprentissage. A partir de ces
propriétés, Nwana déduit quatre types d'agents :
collaboratifs, collaboratifs et apprenants, d'interface et intelligents ;
·
Rôles : recherche d'informations ou travail sur Internet
·
Philosophies hybrides : combinaison entre deux ou plusieurs
approches dans un seul agent.
De cette typologie, Nwana propose sept catégories
d'agents : agents collaboratifs, agents d'interface, agents mobiles, agents
d'information ou d'Internet, agents réactifs, agents hybrides et agents
intelligents.
2.3.1
Les agents collaboratifs
Les agents collaboratifs ont davantage des
caractéristiques d'autonomie et de coopération avec les autres
agents dans la réalisation de leurs objectifs. Ils doivent pouvoir
négocier afin d'arriver à des compromis acceptables. La
faculté d'apprendre peut exister mais n'est pas une
caractéristique fondamentale requise pour ce type d'agents. Plusieurs
chercheurs en intelligence artificielle leur prêtent des états
mentaux comme les croyances, les désirs et les intentions. Ils sont
alors qualifiés d'agents collaboratifs de type BDI (Beliefs, Desires,
Intentions). Les propriétés caractéristiques des agents
collaboratifs sont : l'autonomie, la réactivité, le dynamisme
(capacité à initier des actions) et la sociabilité. Les
principales raisons pour lesquelles l'on peut être amené à
implémenter les agents collaboratifs relèvent de l'intelligence
artificielle distribuée ; elles sont les suivantes :
·
résoudre des problèmes trop importants pour un
seul agent à cause des limitations des ressources et des risques de
systèmes centralisés ;
·
permettre l'interconnexion et l'interopérabilité
de plusieurs legacy systems comme les systèmes experts, les
systèmes décisionnels, etc. ;
·
résoudre des problèmes fondamentalement
distribués comme le contrôle du trafic aérien ou des
problèmes inhérents aux systèmes d'information
distribués ;
·
résoudre des problèmes pour lesquelles l'expertise
disponible est distribuée ;
·
encourager la modularité, la vitesse d'exécution
et la flexibilité.
2.3.2
Les agents d'interface
Les agents d'interface disposent d'une autonomie et d'une
capacité à apprendre. Ils sont caractérisés par la
métaphore d'assistant personnel collaborant avec l'utilisateur dans le
même environnement. Alors que les agents collaboratifs collaborent avec
les autres agents, les agents d'interface collaborent avec l'utilisateur. La
collaboration avec l'utilisateur ne nécessite pas l'existence explicite
d'un langage de communication entre agents comme dans le premier cas. Les
agents d'interface apprennent les préférences des utilisateurs
afin de mieux les assister. Ils apprennent :
·
en observant et en imitant leurs utilisateurs ;
·
à travers le feed-back des utilisateurs suite à
leurs actions ;
·
en recevant des instructions de l'utilisateur ;
·
en demandant les conseils des autres agents.
La collaboration avec les autres agents lorsqu'elle existe se
limite à la demande de conseils, et diffère ainsi du type de
collaboration qui a cours entre les agents collaboratifs. Un agent d'interface
est doté d'un minimum de connaissances au départ et acquiert
lui-même, par la suite, la connaissance dont il a besoin pour assister
l'utilisateur. La principale raison qui amène à considérer
de tels agents est le souci de déléguer certaines tâches
répétitives et fastidieuses (il faut d'ailleurs signaler que la
répétitivité de certaines actions ou attitudes dans le
comportement de l'utilisateur est le gage de la réussite de tels agents,
autrement ils ne pourraient rien apprendre de ce comportement).
2.3.3
Les agents mobiles
Les agents mobiles sont des processus capables de se
déployer à travers de grands réseaux d'information comme
Internet, interagissant avec différents hôtes, recueillant des
informations pour leurs propriétaires et accomplissant des tâches
qui leur sont confiées. Ces tâches vont de la réservation
de vols d'avions à l'administration de réseaux de
télécommunications. Il faut dire que la mobilité n'est pas
une caractéristique des agents, les agents mobiles sont des agents du
fait qu'ils sont autonomes et coopèrent (certes différemment des
agents collaboratifs). Un agent mobile peut ainsi communiquer ou
coopérer avec un autre agent chargé d'informer les autres agents
de la localisation de ses attributs et méthodes ; ceci dispense cet
agent de rendre publique toutes les informations et données le
concernant. Les raisons qui poussent à recourir aux agents mobiles sont
les suivantes :
·
réduction des coûts de communication : en
permettant à l'agent d'aller s'exécuter là où se
trouvent les informations brutes, on évite ainsi de les rapatrier sur
son système local pour n'en utiliser qu'une petite partie ;
·
l'insuffisance des ressources locales : les capacités de
traitement et de stockage peuvent être limitées au point de
justifier l'usage des agents mobiles qui iraient s'exécuter sur des
systèmes distants plus performants ;
·
une coordination plus facile : il est plus simple de coordonner
un nombre de requêtes distantes et d'en collecter simplement les
résultats ;
·
un traitement asynchrone : on peut initialiser ses agents
mobiles et faire autre chose pendant que ceux-ci s'exécutent ;
·
une architecture distribuée plus flexible : les agents
mobiles offre une architecture distribuée unique.
2.3.4
Les agents d'information
Les agents d'information ou agents d'Internet sont apparus du
fait de l'explosion de l'information et du besoin de disposer d'outils de
manipulation de ces informations. Les agents d'information ont pour rôle
d'administrer, manipuler ou collecter les informations à partir de
plusieurs sources d'informations distribuées. Du fait de
l'avènement et du succès d'Internet, la distinction entre les
autres types d'agents, tels que les agents d'interface ou de collaboration, et
les agents d'information est subtile : en effet, tous manipulent des
informations. Il faut néanmoins garder à l'esprit que les agents
d'information sont définis par ce qu'ils font, alors que les autres sont
définis par ce qu'ils sont, c'est-à-dire par leurs attributs et
propriétés caractéristiques. Les raisons qui
président à la mise en oeuvre des agents d'information sont de
deux ordres. D'une part, il y a la nécessité de faire face
à l'explosion des sources d'informations et donc de répondre
à un besoin similaire à celui rempli par les moteurs de
recherche. D'autre part, sur le plan financier, de tels agents rapporteraient
à leur éditeur un succès comparable à celui de
Netscape avec son navigateur sur Internet.
2.3.5
Les agents logiciels réactifs
Les agents réactifs sont une catégorie
spéciale d'agents ne disposant pas de modèles internes et
symboliques de leur environnement : ils ne font que réagir aux stimuli
provenant de l'environnement. Les agents réactifs sont relativement
simples et interagissent avec les autres agents de façon basique. La
mise au point de tels agents n'exige pas une spécification
complète de leur comportement. Les agents réactifs peuvent en
outre être considérés comme une collection de modules
autonomes chargés chacun d'une tâche spécifique. La
communication entre les différents modules est minimale. Les agents
réactifs opèrent sur des données brutes provenant des
capteurs contrairement aux précédents types d'agents qui
utilisent des représentations symboliques de haut niveau. L'existence et
la mise en oeuvre d'agents réactifs se justifient dans les situations
où l'on ne veut prendre en compte que des hypothèses
basées sur l'environnement physique. Ces agents réactifs sont
supposés aussi être plus robustes et plus tolérants aux
pannes que les autres types d'agents, la perte d'un tel agent n'entraîne
pas de conséquences catastrophiques. Ce sont des agents situés
qui n'ont pas besoin d'avoir une représentation de leur environnement,
ils ne réagissent qu'aux sollicitations du moment.
2.3.6
Les agents hybrides
Nous avons passé en revue cinq types d'agents :
collaboratifs, d'interface, mobiles, d'information et réactifs. Le
débat sur l'opportunité d'avoir tel ou tel type d'agent est
davantage un débat théorique et plutôt stérile.
Chaque type d'agent possède ses points forts et faibles, ses avantages
et ses inconvénients. Une approche consiste donc souvent dans la
réalité à bâtir des agents hybrides. Un agent
hybride consiste en la combinaison de plusieurs caractéristiques au sein
d'un même agent ; ces caractéristiques concernent la
mobilité, la collaboration, l'autonomie, la capacité à
apprendre, etc. L'utilisation d'agents hybrides reste toujours guidée
par le souci de minimiser les faiblesses et d'augmenter les forces de tel ou
tel type d'agents que l'on mettrait en oeuvre dans une application.
3
Système multi-agents
Les Systèmes Multi-Agents (SMA) constituent un des deux
axes de recherche en Intelligence Artificielle Distribuée (IAD), l'autre
étant la Résolution Distribuée de Problèmes (RDP en
anglais DPS pour Distributed Problem Solving). La résolution des
problèmes distribuées se préoccupe de la façon dont
un problème donné peut être résolu par plusieurs
modules (appelés noeuds) qui coopèrent en divisant et en
partageant la connaissance à propos du problème et des solutions
développées. Les systèmes multi-agents implémentent
des stratégies de résolution basées sur le comportement
d'un ensemble d'agents autonomes qui, éventuellement, peuvent
déjà exister. Un système multi-agents peut être vu
comme un ensemble faiblement interconnecté d'agents qui travaillent
ensemble pour résoudre un problème en s'appuyant sur les
capacités et les connaissances individuelles de chaque entité.
Les agents sont autonomes et sont de nature hétérogène.
Les systèmes multi-agents se caractérisent dès lors par :
·
une perception partielle de l'environnement par chaque agent;
·
des compétences limitées pour chaque agent,
c'est-à-dire insuffisantes pour résoudre entièrement le
problème;
·
une absence de contrôle du système global;
·
une décentralisation des données;
·
des traitements en mode asynchrone.
L'intérêt pour l'utilisation des systèmes
multi-agents se fonde sur leur capacité [Mbala 03] : à fournir
robustesse et efficacité ; à permettre
l'interopérabilité de systèmes existants ; à
résoudre des problèmes pour lesquels les données,
l'expertise (la connaissance) et le contrôle sont distribués.
Les systèmes multi-agents sont des systèmes
idéaux pour représenter des problèmes possédant de
multiples méthodes de résolution, de multiples perspectives et/ou
de multiples résolveurs [Chaib 99]. Ces systèmes possèdent
les avantages traditionnels de la résolution distribuée et
concurrente de problèmes comme la modularité, la vitesse (avec le
parallélisme), et la fiabilité (due à la redondance). Ils
héritent aussi des bénéfices envisageable de
l'intelligence artificielle comme le traitement symbolique (au niveau des
connaissances), la facilité de maintenance, la réutilisation et
la portabilité mais surtout, ils ont l'avantage de faire intervenir des
schémas d'interaction sophistiqués. Les types courants
d'interaction incluent la coopération (travailler ensemble à la
résolution d'un but commun) ; la coordination (organiser la
résolution d'un problème de telle sorte que les interactions
nuisibles soient évitées ou que les interactions
bénéfiques soient exploitées) ; et la négociation
(parvenir à un accord acceptable pour toutes les parties
concernées).
Bien que les systèmes multi-agents offrent de nombreux
avantages potentiels, ils doivent aussi relever beaucoup de défis. Voici
les problèmes inhérents à la conception et à
l'implémentation des systèmes multi-agents, d'après [Chaib
99] :
1.
Comment formuler, décrire, décomposer, et allouer
les problèmes et synthétiser les résultats?
2.
Comment permettre aux agents de communiquer et d'interagir? Quoi
et quand communiquer?
3.
Comment assurer que les agents agissent de manière
cohérente i) en prenant leurs décisions ou actions, ii) en
gérant les effets non locaux de leurs décisions locales et iii)
en évitant les interactions nuisibles?
4.
Comment permettre aux agents individuels de représenter
et raisonner sur les actions, plans et connaissances des autres agents afin de
se coordonner avec eux? Comment raisonner sur l'état de leurs processus
coordonnés (comme l'initialisation ou la terminaison)?
5.
Comment reconnaître et réconcilier les points de
vue disparates et les intentions conflictuelles dans un ensemble d'agents
essayant de coordonner leurs actions?
6.
Comment trouver le meilleur compromis entre le traitement local
au niveau d'un seul agent et le traitement distribué entre plusieurs
agents (traitement distribué qui induit la communication)? Plus
généralement, comment gérer la répartition des
ressources limitées?
7.
Comment éviter ou amoindrir un comportement nuisible du
système global, comme les comportements chaotiques ou oscillatoires?
8.
Comment concevoir les plates-formes technologiques et les
méthodologies de développement pour les systèmes
multi-agents?
3.1
Définition
Ferber [Ferber 95] définit un système
multi-agents (SMA) comme étant un système composé des
éléments suivants :
·
un environnement E, c'est-à-dire un espace disposant
généralement d'une métrique;
·
un ensemble d'objets O. Ces objets sont situés,
c'est-à-dire que, pour tout objet, il est possible, à un moment
donné, d'associer une position dans E. Ces objets sont passifs,
c'est-à-dire qu'ils peuvent être perçus,
créés, détruits et modifiés par les agents;
·
un ensemble A d'agents, qui sont des objets particuliers (A ****
O), lesquels représentent les entités actives du système;
·
un ensemble de relations R qui unissent les objets (et donc les
agents) entre eux ;
·
un ensemble d'opérations Op permettant aux agents de A de
percevoir, produire, consommer, transformer et manipuler les objets de O;
·
des opérateurs chargés de représenter
l'application de ces opérations et la réaction du monde à
cette tentative de modification, que l'on appellera les lois de l'univers.
Un SMA communiquant est un systèmes multi-agents dont
les agents communiquent entre eux par le biais de messages. Un systèmes
multi-agents purement communicant est un systèmes multi-agents ne
disposant pas d'environnement et dans lequel les agents ne font que communiquer
entre eux (O = A et E est l'ensemble vide). Un système multi-agents
situé est un système multi-agents dont les agents sont
positionnés dans un environnement. Un système multi-agents
purement situé est un systèmes multi-agents situé dans
lequel les agents ne communiquent pas par l'envoi de messages, mais par
propagation de signaux.
3.2
Propriété des systèmes multi-agents
Les systèmes multi-agents sont à l'intersection
de plusieurs domaines scientifiques [Chaib 99] : informatique répartie,
génie logiciel, intelligence artificielle, vie artificielle. Ils
s'inspirent également d'études issues d'autres disciplines
connexes notamment la sociologie, la psychologie sociale, les sciences
cognitives et bien d'autres. C'est ainsi qu'on les trouve parfois à la
base de :
·
systèmes distribués;
·
interface hommes-machines;
·
bases de données et bases de connaissances
distribuées coopératives;
·
systèmes pour la compréhension du langage naturel;
·
protocoles de communication et réseaux de
télécommunications;
·
programmation orientée agents et génie logiciel;
·
robotique cognitive et coopération entre robots;
·
applications distribuées comme le Web, l'Internet, le
contrôle de trafic routier, le contrôle aérien, les
réseaux d'énergie, etc.
Un systèmes multi-agents est généralement
caractérisé par [Jarras 02][Bourdon 01]:
·
chaque agent a des informations ou des capacités de
résolution de problèmes limitées, ainsi chaque agent a un
point de vue partiel ;
·
il n'y a aucun contrôle global du système
multi-agents ;
·
les donnés sont décentralisées ;
·
le calcul est asynchrone.
Par leur nature répartie, les systèmes
multi-agents offrent en outre des propriétés intéressantes
comme :
·
L'efficacités des traitements : les agents travaillent en
parallèle et se communiquent de façon asynchrone;
·
La robustesse et la sûreté de fonctionnement : la
mise hors fonctionnement de quelques agents ne modifie pas sensiblement le
comportement global du système;
·
La flexibilité et le traitement de système
à grande échelle : on peut augmenter le nombre d'agents pour
développer le système sans perturber le travail des agents
existants ;
·
Coût de fonctionnement faible : la répartition des
traitements entre de nombreuses unités simples (agents) conduit à
des coûts faibles. En effet, il est extrêmement difficile de
maîtriser ou prévoir des comportements à l'échelle
macroscopique issus de l'interaction de comportements individuels complexes
(à l'échelle microscopique);
·
un coût de développement et de réutilisation
intéressant : théoriquement, il est simple de faire
développer par des spécialistes des agents indépendant les
uns des autres (comme dans l'approche objet) pour les réutiliser dans
plusieurs scénarios applicatifs ; mais l'une des différences
essentielles entre l'agent et l'objet dans les notions et de flexibilité
liée aux comportements des agents, il parait difficile d'affirmer quoi
que soit de concret sur ces notions de coût et de développement et
de réutilisation des agents.
·
Les schémas d'interaction sophistiqués : tels que,
la coopération, la coordination et la négociation.
Les systèmes multi-agents présentent de
nombreuses propriétés dans son utilisation dans la formation
comme, par exemple [Querrec 02]:
·
Permettre aux agents d'avoir un comportement indépendant
de l'expertise de la tâche à enseigner grâce à des
mécanismes de prise de décisions identiques à tous les
agents.
·
Permettre au formateur et à l'auteur de scénario
de décrire aisément des plans en assemblant des sous plans
modulaires.
·
Décrire des architectures de façon
distribuée. Ainsi le formateur et le concepteur peuvent décrire
facilement pour chaque tâche : les conditions de déclenchement et
de réussite, les comportements de bon fonctionnement et ceux
problématiques associés à cette tâche et les
solutions pédagogiques pour chaque problème.
3.3
Les composants d'un système multi-agents
On définit généralement un système
multi-agents comme étant un modèle informatique composé
d'entités de base, les agents. Ces derniers possèdent une
autonomie en terme de décisions et d'actions et sont
organisés en société au sein d'un
environnement dans lequel et avec lequel ils interagissent. Ils
doivent, de ce point de vue, être capables de percevoir, de
décider, d'agir et de communiquer [Erceau 91]. Cette définition
fait apparaître quatre composantes de base aux systèmes
multi-agents: les agents, l'environnement, les interactions et l'organisation.
3.3.1
Agent
Un agent se caractérise par son rôle, sa
spécialité et ses fonctionnalités, ses buts, ses croyances
et ses différentes capacités : décisionnelles, de
raisonnement, de communication et éventuellement d'apprentissage. Donc,
les agents ne disposent pas des mêmes aptitudes.
3.3.2
Environnement
Un environnement est un espace représentant le monde
dans lequel les agents évoluent. On fait généralement une
distinction entre les agents qui sont les entités actives, et les objets
passifs qui se situent dans l'environnement. Lorsque ce dernier dispose d'une
métrique (cas général), la capacité de perception
d'un agent et sa capacité à reconnaître les objets
situés (position, relations entre objets) et la capacité d'action
d'un agent et celle de transformer l'état du système en modifiant
les positions et relations qui existent entre les objets. Par exemple dans un
univers de robots, l'environnement est l'espace géométrique
euclidien dans lequel se déplacent les robots (agents) et où sont
situés des objets physiques que les robots peuvent manipuler ou doivent
éviter.
Cependant, Boissier distingue l'environnement du
système multi-agents et l'environnement de l'agent. L'environnement du
système multi-agents est l'environnement physique support des actions
des agents et disposant de ressources. L'environnement de l'agent est
l'environnement du système multi-agents et les autres agents. C'est la
source des données du problème et le lieu où l'agent peut
trouver des ressources.
Russel et Norvig définissent les principales
propriétés de l'environnement [Querrec 02] :
·
Accessibilité : l'agent dispose de capteurs lui
permettant d'accéder à l'état de l'environnement (en
général localement).
·
Déterminisme : le prochain état de l'environnement
est fonction de son état courant et de l'action de l'agent.
·
Episodisme : les prochaines évolutions ne
dépendent pas des actions déjà réalisées.
·
Dynamisme : l'environnement peut changer pendant la
réflexion de l'agent.
·
Discret : le nombre de percepts et d'actions de l'agent est
limité.
·
Concurrence d'accès : d'autres agents souhaitant
interagir existent dans l'environnement.
3.3.3
Interactions
Le principe d'implémentation des systèmes
multi-agents est localisé, c'est-à-dire que le concepteur ne se
soucie pas du comportement global du système, mais uniquement des
différentes entités autonomes en décrivant leur
comportement localement. Pour obtenir un comportement global cohérent,
il faut alors décrire la manière dont les entités vont
interagir entre elles et avec l'environnement.
Selon Ferber [Ferber 95], l'interaction est définit
comme étant la mise en relation dynamique de deux ou plusieurs agents
par le biais d'un ensemble d'actions réciproques. Les agents peuvent
interagir soit en accomplissant des actions linguistiques (en communiquant
entre eux), soit en accomplissant des actions non-linguistiques (en modifiant
leur environnement).
Boissier [Zeguida 03] définit une interaction comme une
mise en relation dynamique de deux ou plusieurs agents par le biais d'un
ensemble d'actions réciproques. Il rajoute : il y a interaction lorsque
la dynamique propre d'un agent est perturbée par les influences des
autres. Cela sous-entend différentes formes d'interactions selon les
agents et les systèmes.
Le premier type d'interaction s'opère sans
communication et sans contact direct entre les agents, ils n'ont donc pas
besoin d'avoir conscience des autres. L'agent utilise l'environnement comme
média d'interaction en le modifiant à travers ses actions. Le
principal exemple d'interaction de ce type est : les applications faisant
intervenir des agents réactifs ; tel qu'en éthologie ou en
traitement d'images. Le deuxième cas d'interaction sans communication
fait intervenir un mécanisme d'un niveau de cognition beaucoup plus
élevé. L'agent doit avoir conscience des autres agents, mais
comme il n'y a toujours pas de contact direct, il doit inférer sur ces
actions. L'agent doit alors disposer d'un modèle des autres agents
(grâce aux cartes cognitives floues par exemple) [Querrec 02].
Le second type d'interaction est le plus fréquent dans
les applications des systèmes multi-agents. Il s'agit d'envoi de
messages dont le type est connu à l'avance par les agents. Ces messages
peuvent être diffusés, ou être destinés à un
agent en particulier. Ce genre de communication est considéré
comme la capacité minimum de communication d'un agent. C'est ce qui doit
au minimum différencier un agent d'un objet. La réception d'un
message par un agent s'apparente à un appel de méthode sur un
objet. C'est l'agent lui même qui traite le message et décide (ou
non) d'invoquer une méthode. C'est ce qui fait en partie son autonomie.
Enfin les actes de langage constituent la forme d'interaction
la plus évoluée. Pour pouvoir faire interagir des agents
hétérogènes dans une même application, il a fallu
définir un protocole de communication. De plus, dans certaines
applications, l'utilisateur doit interagir avec les agents de la manière
la plus naturelle possible. Il a donc fallu définir un type de
communication de plus haut niveau et plus évolué. Les recherches
se sont alors portées sur la définition de concepts de
communication d'un point de vue social. Ces recherches ont donné lieu
aux actes de langage.
3.3.4
Organisation
Les agents qui ont un comportement à tendance «
individuelle » résultant des règles de fonctionnement
interne, ont aussi un comportement à tendance « sociale »,
tourné vers la collectivité, régit par les règles
de participation d'un individu à la vie d'un groupe. Ces règles
correspondent dans une organisation, aux relations qui existent ou peuvent
exister entre les différents agents. Ainsi dans un système
multi-agents, on distingue essentiellement deux niveaux d'organisation : les
groupes et les populations. C'est vers ces aspects sociaux de la connaissance
et de l'action que s'orientent désormais les recherches par rapport
à l'attention qui était portée jusqu'alors aux
architectures individuelles des agents.
On peut définir une organisation comme une structure
(pattern) décrivant comment les membres d'une organisation sont en
relation et interagissent afin d'atteindre un but commun. Cette structure peut
être statique, donc conçue a priori par le programmeur du
système ou dynamique, comme on peut en trouver dans les systèmes
multi-agents ouverts [Baeijs 98].
Dans un système multi-agents, il existe de nombreuses
interrelations entre les agents, par le biais de délégation de
tâches, de transfert d'information, d'engagements, de synchronisations
d'actions, etc. Ces interrelations ne sont possibles qu'à
l'intérieur d'une organisation qui constitue le support et la
manière dont se passent ces interrelations (la façon de
répartir les tâches, les informations et les ressources, et de
coordonner les actions). Elle désigne aussi à la fois le
processus d'élaboration d'une structure et le résultat même
de ce processus. C'est d'ailleurs ce qui rend ce terme difficile à
cerner.
Une organisation peut être [Querrec 02]:
·
Explicite : les rôles sont définis à priori.
Avant la simulation, le concepteur connaît la structure
organisationnelle.
·
Emergente : les rôles sont observés à
posteriori. Aucune structure organisationnelle n'est connue du concepteur.
C'est en observant les interactions entre les agents qu'il se fait une
représentation de l'organisation.
·
Statique : la structure ou les entités organisationnelles
sont fixées à priori et ne peuvent pas évoluer
durant la simulation.
·
Dynamique : la structure ou les entités
organisationnelles peuvent évoluer au cours de l'exécution.
En pratique, il est difficile de véritablement
dissocier les aspects interaction et organisation dans les systèmes
multi-agents. Une organisation n'a pas de raison d'existence si elle est
découplée des interactions entre agents et réciproquement,
une interaction entre deux agents ne peut s'exprimer qu'à
l'intérieur d'une organisation.
3.4
Communication entre agents
Les agents peuvent interagir soit en accomplissant des actions
linguistiques (en communiquant entre eux), soit en accomplissant des actions
non-linguistiques qui modifient leur environnement. En communiquant, les agents
peuvent échanger des informations et coordonner leurs activités.
Pour qu'un agent puisse coopérer avec d'autres agents
et réagir à son environnement, il a besoin de langage de
communication entre agents. La communication entre agents permet aux programmes
écrits par différents programmeurs, en différents
langages, en utilisant différentes interfaces de se communiquer. Pour
que ceci soit possible, les agents ont besoin d'un langage commun de
communication qui, davantage est concerné par l'échange de
l'information que son contenu. La communication est généralement
décomposée en trois sous-sections, qui sont:
1.
Protocole d'interaction : ceci se rapporte
à la stratégie de niveau élevé poursuivi par les
agents logiciels qui interagissent avec d'autres agents.
2.
Le langage de communication, c'est le medium
par lequel les attitudes concernant le contenu du message échangé
sont communiquées.
3.
Le protocole de transport, c'est le
mécanisme réel de transport utilisé pour la communication
en utilisant le langage de communication. Ces protocoles incluent TCP/IP,
SMTP, HTTP, IIOP, etc.
Dans les systèmes multi-agents deux stratégies
principales ont été utilisées pour supporter la
communication entre agents :
Envoi de message : les agents peuvent échanger des
messages directement
Partage de ressources : les agents peuvent accéder
à une base de données partagées (appelée tableau
noir ou blackboard) dans laquelle les informations sont postées.
3.4.1
Stratégies de communication
3.4.1.1
Transfert de plans ou de messages
Dans l'approche de transfert de plans, un agent X communique
son plan en totalité à un agent Y et Y communique son plan en
totalité à X. Cette approche présente plusieurs
inconvénients : le transfert de plans est coûteux en ressources de
communication et c'est une approche difficile à mettre en oeuvre dans
des applications réelles car il y a en général un fort
degré d'incertitude au sujet des états actuel et futurs du monde.
Dans des situations réelles en plus, il n'est pas
possible de formuler à l'avance des plans en totalité. Par
conséquent, on a besoin de communiquer des stratégies
générales aux agents plutôt que des plans, et donc il est
nécessaire que les agents puissent échanger des messages.
3.4.1.2
Échange d'informations grâce à un tableau
noir
En intelligence artificielle la technique du tableau noir
(blackboard) est très utilisée pour spécifier une
mémoire partagée par divers systèmes. Dans un
système multi-agents utilisant un tableau noir, les agents peuvent
écrire des messages, insérer des résultats partiels de
leurs calculs et obtenir de l'information. Le tableau noir est en
général partitionné en plusieurs niveaux qui sont
spécifiques à l'application. Les agents qui travaillent sur un
niveau particulier peuvent accéder aux informations contenues dans le
niveau correspondant du tableau noir ainsi que dans des niveaux adjacents.
Ainsi, les données peuvent être synthétisées
à n'importe quel niveau et transférées aux niveaux
supérieurs alors que les buts de haut niveau peuvent être
filtrés et passés aux niveaux inférieurs pour diriger les
agents qui oeuvrent à ces niveaux.
3.4.2
Actes de langages
On considère que les agents sont dotés de
structure de données appelées états mentaux à
partir desquelles ils peuvent raisonner. Diverses catégories
d'états mentaux ont été retenues par les chercheurs dont
notamment les croyances, les désirs, les intentions ou buts, les
capacités, etc. Ce sont ces mêmes états mentaux qui
caractérisent les modèles des agents cognitifs en intelligence
artificielle distribuée. Ainsi, un agent cognitif raisonne sur des
croyances qui représentent sa compréhension du monde dans lequel
il évolue. Il raisonne aussi sur ses désirs et intentions en
relation avec ses croyances et capacités afin de prendre des
décisions auxquelles sont associés les plans qu'il va accomplir
pour agir dans le monde.
Les actes de langage
L'idée est d'utiliser ce que l'on comprend du dialogue
entre humains comme modèle pour la communication entre agents. Dans
cette approche la production d'un énoncé, est un acte qui sert
avant tout à produire des effets sur son destinataire [Bourdon 01]. Les
principaux actes de langage décrits sont les suivants :
1.
assertifs, servent à donner une
information sur le monde en affirmant quelque chose (ex. il fait beau) ;
2.
directifs, sont utilisés pour donner des
directives au destinaire (donne moi ta montre) ;
3.
promissifs, engageant le locuteur à
accomplir certains actes dans l'avenir (ex. je viendrai à la
réunion) ;
4.
expressifs, servent à donner au
destinataire des indications concernant l'état mental du locuteur (ex.
je suis heureux) ;
5.
déclaratifs, accomplissent un acte par
le fait même de prononcer l'énoncé (ex. je déclare
la séance ouverte) ;
Les actes de langage, considérés comme des
structures complexes, sont définis par trois composantes :
1.
la locutoire : c'est la composante physique de
la communication (envoi d'ondes sonores ou production de caractères) ;
production de phrases à l'aide d'une grammaire et d'un lexique
donné.
2.
l'illocutoire : elle se rapporte à la
réalisation de l'acte effectué par le locuteur sur le
destinataire de l'énoncé. En pragmatique du langage, un acte
illocutoire est caractérisé par une force illocutoire (ex.
affirmer, questionner, demander de faire, promettre, prévenir, etc.) et
par un contenu propositionnel, objet de la force illocutoire. Par exemple
« affirmer qu'il pleut » prend la forme « affirmer (il pleut)
».
3.
la perlocutoire : cette composante porte sur
les effets que les actes illocutoires peuvent avoir sur l'état du
destinataire, ses actions, ses croyances et ses jugement. Par exemple,
convaincre, inspirer, effrayer, persuader, etc.
3.4.3
Langage de communication entre agents
Le ACL (Agent Communication Language) a été
créé par ARPA pour assurer l'interopérabilité entre
des agents autonomes et distribués. Le ACL a trois composants : un
vocabulaire, un langage de communication entre agent appelé KQML
(Knowledge and Query Manipulation Language) et un langage spécifiant le
contenu appelé KIF (Knowledge Interchange Format). Un message de ACL est
alors un message KQML contenant une directive de communication et un contenu
sémantique dans KIF, exprimé en termes de vocabulaire.
KQML fournit la couche linguistique pour rendre la
communication efficace en considérant le contexte des messages. Il a
été conçu comme format de message et comme protocole qui
permet l'identification, le raccordement et l'échange de l'information
entre des programmes. Selon [Finin et al. 95], KQML est
caractérisé par trois caractéristiques importantes :
1.
Les messages KQML sont opaques au contenu qu'ils transportent,
ce qui implique que les messages KQML ne communiquent qu'avec des sentences en
certain langage, mais aussi une attitude ou à une intention sur le
contenu.
2.
Des primitifs s'appellent performatives indiquent les actions ou
les opérations valides.
3.
Un environnement dans lequel les agents communiquent avec KQML
peut être enrichi avec un genre spécial d'agents appelés
les facilitateurs.
3.4.3.1
Le langage KQML
Le langage KQML (Knowledge Query Manipulation Language) a
été conçu comme format de message pour supporter la
communication entre agents. Les caractéristiques principales de KQML
sont les suivantes :
·
Les messages KQML sont opaques au contenu qu'ils portent. Les
messages KQML ne communiquent pas simplement des phrases en un certain langage,
mais communiquent plutôt une attitude au sujet du contenu (affirmation,
requête, réponse, etc.).
·
Les primitifs du langage s'appellent performatives (ces termes
vient directement de la théorie d'acte de langage). Les performatifs
définissent les actions (opérations) permises utilisées
par des agents communiquant entre eux.
·
KQML suppose qu'au niveau d'agent, la communication point
à point.
·
Un environnement dans lequel les agents communiquent avec KQML
peut être enrichi avec un genre spécial d'agents appelés
les facilitateurs, qui fournissent aux fonctions additionnelles d'agents la
gestion de réseau, telle que l'association des adresses physiques en
noms symboliques, registration des agents, etc.
KQML utilise un ensemble de types de messages standards. Un
exemple est comme suit :
(ask-one
:content (PRICE IBM ?price)
:receiver stock-server
:language LPROLOG
:ontology myOntology )
Dans la terminologie de KQML, "ask-one" est un performatif.
Les paramètres de performatif sont présentés par des
mots-clés tels que "sender", "language", etc. Le message ci-dessus
représente une question au sujet du prix d'un stock partagé
d'IBM. Ontology assumé par la question est l'identification par
"myOntology", le récepteur du message est "stock-server" et le langage
utilisé est "LPROLOG".
Les types de messages KQML sont de diverses natures :
·
Simples requêtes et assertions, tel que : ask, tell, ...
·
Instructions de routage de l'information, tel que forward,
broadcast, ...
·
Commandes persistantes, tel que subscribe, monitor, ...
·
Commandes permettent aux agents consommateurs de demander
à des agents intermédiaires de trouver les agents fournisseurs
pertinents, tel que advertise, recommend, ...
3.4.4
Protocole d'interaction entre agents
Un système multi-agents peut être
considéré comme société artificielle virtuelle,
dans laquelle les agents peuvent coopérer ou coordonner pour accomplir
des tâches. L'interaction entre agent exige un ensemble de messages
convenus, de règles pour des actions basées sur la
réception de divers messages, et d'acceptations des voies de
transmission [Chen et al 03]. Ces contraintes, règles et modèles
peuvent être soustraits et formalisés comme AIP (Agent
Interaction Protocol), qui font base de la négociation et la
coopération d'agents. En utilisant les protocoles, les comportements
autonomes des agents peuvent être de façon ou d'autre
prévisibles.
L'AIP sont des modèles représentant les messages
de communication et les contraintes correspondantes sur le contenu de tels
messages. Ils décrivent un ordre permis des messages et du contenu de
message entre les agents [Odell et al 00]. L'AIP peut également
être considéré en tant que modèles
réutilisables de conception de logiciel décrivant des
problèmes se produisant fréquemment dans les systèmes
multi-agents [Bauer et al 00]. Les rôles et les détails de
messages dans un AIP peuvent être modifiés pour s'adapter
à différents scénarios pour résoudre des
problèmes [Inverno et al 98].
3.4.5
Transport de messages
La communication entre agents est nécessaire aussi bien
pour échanger les données entre les agents que les connaissances.
Pour cela, plusieurs moyens existent : au niveau le plus bas, il existe des
sockets qui permettent aux différents agents codés en
Java de communiquer entre eux ; il existe aussi d'autres technologies (en Java
notamment). On peut citer l'invocation de méthodes distantes (RMI pour
Remote Method Invocation) et la technologie CORBA (Common Request
Broker Architecture).
Plusieurs travaux concernent la mise en oeuvre
d'infrastructures de communication qui dispensent le programmeur
d'implémenter lui-même la communication entre les agents. Avec ce
type d'outils, le fonctionnement typique consiste à fournir une adresse
à chaque agent. Cette adresse lui permettra d'émettre et de
recevoir des messages de la part des autres agents. L'avantage est la
possibilité d'avoir des communications asynchrones et d'être
dispensé de la nécessité de localiser un agent avant de
lui envoyer un message. JATLite est une infrastructure de ce type, elle permet
aux agents de communiquer via Internet.
3.4.5.1
Sockets, RMI et CORBA
3.4.5.1.1
Sockets
Une socket est une abstraction de programmation
représentant les extrémités d'une connexion entre deux
ordinateurs. Pour chaque connexion donnée, il existe une socket
sur chaque machine, on peut imaginer un câble virtuel reliant les
deux ordinateurs, chaque extrémité étant enfichée
dans une socket. En Java, on crée un objet Socket pour
établir une connexion vers une autre machine, puis on crée un
InputStream et un OutputStream à partir de ce
Socket, afin de traiter la connexion en tant qu'objet flux
d'entrée/sortie.
3.4.5.1.2
RMI
L'invocation de méthodes distantes se base sur le
raisonnement selon lequel la meilleure manière d'exécuter des
instructions à travers un réseau sur d'autres ordinateurs est de
considérer qu'un objet est présent sur une autre machine et qu'on
lui envoie un message et l'on obtient le résultat comme si cet objet
était instancié sur la machine locale. L'invocation de
méthodes distantes exige de créer une interface distante
(remote interface) sur la machine serveur ; ainsi,
l'implémentation sous-jacente est masquée aux différents
clients. Les étapes suivantes de la création des objets RMI sont
l'implémentation de l'interface distante, la mise en place du registre,
la création des stubs et des skeletons qui assurent
les opérations de connexion réseau et permettent de donner
l'illusion que l'objet distant est situé sur la machine locale.
L'utilisation de l'objet distant consiste simplement pour le programme client
à rechercher et à rapatrier depuis le serveur, l'interface
distante.
3.4.5.1.3
CORBA
Lorsque les applications distribuées deviennent plus
importantes et exigent des fonctionnalités telles que
l'intégration de bases de données existantes ou l'accès
aux services d'un objet serveur sans se soucier de sa localisation physique, on
a besoin d'effectuer des appels à des procédures distantes ou RPC
(Remote Procedure Call) et il peut être nécessaire
d'avoir une indépendance par rapport au langage. Dans ces cas, il est
nécessaire de recourir à une technologie d'intégration
comme CORBA. Il s'agit d'une spécification que les fabricants peuvent
suivre afin d'implémenter des produits supportant une intégration
CORBA. La norme CORBA fait partie du travail réalisé par l'OMG
(Object Management Group) pour définir des standards
d'interopérabilité des objets distribués et
indépendants du langage. Elle fournit la possibilité de faire des
appels à des procédures distantes dans des objets Java et
non-Java, d'interfacer des systèmes existants sans se soucier de leur
emplacement. La spécification de l'interopérabilité objet
est généralement désignée comme l'Object
Manager Architecture (OMA). L'OMA définit deux composants : le
Core Object Model et l'OMA Reference Architecture. CORBA est
un raffinement du Core Object Model dans ce sens qu'il met en place
les concepts de base d'objet, d'interface, d'opération, etc. L'OMA
ReferenceArchitecture définit les services et les mécanismes
qui permettent aux objets d'inter-opérer, il contient l'Object
Request Broker (ORB), les services CORBA et les outils communs. L'ORB est
le bus de communication par lequel les objets peuvent réclamer des
services auprès des autres objets, sans rien connaître de leur
localisation physique. La norme CORBA n'a pas pour but d'expliquer comment
implémenter les ORB, mais permet une compatibilité entre les
différents ORB des fournisseurs. Ainsi, l'OMG définit un ensemble
de services qui sont accessibles par l'intermédiaire d'interfaces
standard. Afin d'assurer l'indépendance vis-à-vis du langage,
CORBA dispose d'un langage de définition d'interface, IDL (Interface
Definition Language), qui précise les types de données, les
attributs, les opérations, les interfaces, etc. Le compilateur IDL
génère le code stub et le code skeleton
utilisés pour réunir les arguments des méthodes et
réaliser les appels distants. En résumé, on pourrait dire
que CORBA est le support de RPC, qui permet à des objets locaux
d'appeler des méthodes d'objets distants. Cette fonctionnalité
est intégrée à Java à travers les RMI ; toutefois,
là où le RMI rend possible les RPC entre des objets Java, CORBA
le fait entre des objets implémentés dans n'importe quel langage.
3.4.5.2
Plateformes agents Conformes à KQML
Il est difficile d'implémenter et déboguer des
systèmes multi-agents à partir du zéro. Cependant, il y a
un certain nombres des réalisations des infrastructures d'agents
basées sur KQML actuellement disponibles. Dans le suivant nous
présentons brièvement quelques unes d'elles.
Java Agent Template, Lite (JATLite),
développé à l'université de Stanford, est un
package des programmes Java qui permettent à des utilisateurs de
créer des agents logiciels qui communiquent à travers l'Internet.
JATLite facilite particulièrement la construction des agents qui
envoient et reçoivent des messages en utilisant le langage de
communication KQML.
L'architecture de JATLite, comme représentée sur
la Figure 2.1, est organisée comme hiérarchie des couches de plus
en plus spécialisées, de sorte que les réalisateurs
puissent choisir la couche appropriée pour commencer à
développer leurs systèmes.
·
La couche abstraite fournit un ensemble de classes abstraites
nécessaires à l'implémentation de JATLite.
·
La couche de base fournit des communications TCP/IP et donne
accès à la couche abstraite.
·
La couche KQML fournit le stockage et l'analyse des messages
KQML. Des extensions au KQML standard proposées par l'Université
de Stanford [Pietrie, 03] ont été implémentées afin
de permettre un protocole standard pour l'inscription, la connexion, la
déconnexion, etc.
·
La couche de routage offre aux agents l'inscription, le routage
et la mise en file des messages.
·
La couche de protocoles supporte différents protocoles et
services Internet comme SMTP, FTP, POP3, HTTP.


Magenta, développé à
l'université de Stanford, est un ensemble d'API (Application Processing
Interface) pour le langage de communication entre d'agents. Il facilite la
communication entre des agents situés dans un environnement de calcul
hétérogène. Bien que les utilisateurs de l'API puissent
communiquer de pair à pair, l'API est particulièrement utile pour
l'interaction anonyme d'agents.
JKQML (Java-based Knowledge Query
Manipulation Language), développée à IBM, est un framework
et API pour construire des programmes basés Java communicant par KQML
à travers l'Internet. JKQML permet l'échange d'information et de
services entre les systèmes logiciels.
3.5
Interaction et coopération entre agents
Un système multi-agents se distingue d'une collection
d'agents indépendants par le fait que les agents interagissent en vue de
réaliser conjointement une tâche ou d'atteindre conjointement un
but particulier. Les agents peuvent interagir en communiquant directement entre
eux ou par l'intermédiaire d'un autre agent ou même en agissant
sur leur environnement.
La coopération peut être considérée
comme une attitude intentionnelle adoptée par les agents qui
décident de travailler ensemble [Ferber 95]. Dans ce cas les agents
s'engagent dans une action après avoir identifié et
adopté un but commun considéré comme un
élément essentiel de l'activité sociale.
Les protocoles d'interaction s'intéressent à des
séries des messages échangés entre les agents; ce que l'on
appelle des conversations. Il existe différentes formes de protocoles
d'interaction suivant les systèmes recherchés. Dans le cas
d'agents compétitifs (buts conflictuels ou simplement des
intérêts propres), l'objectif des protocoles est de maximiser
l'utilité de chaque agent. Dans le cas où des agents ont des buts
identiques ou des problèmes communs, comme c'est le cas de
résolution distribuée de problèmes, les protocoles
d'interaction cherchent à maintenir des invariants globaux sans
intervenir sur l'autonomie de chaque agent, ni avoir recours à un
contrôle centralisé [Bourdon 01].
3.6
Coordination entre agents
De nombreux exemples de coordination existent dans la vie
quotidienne : deux déménageurs déplaçant un meuble
lourd, deux jongleurs échangeant des balles avec lesquelles ils
jonglent, des personnes qui parlent à tour de rôle en se passant
un micro, etc. [Malone 94] note que deux des composantes fondamentales de la
coordination entre agents sont l'allocation de ressources rares et la
communication de résultats intermédiaires. Dans ce contexte, les
agents doivent être capables de communiquer entre eux de façon
à pouvoir échanger les résultats intermédiaires.
Pour l'allocation des ressources partagées, les agents doivent
être capables de faire des transferts de ressources.
Bien entendu, la coordination est une question centrale pour
les systèmes multi-agents et la résolution de systèmes
distribués. En effet, sans coordination un groupe d'agents peut
dégénérer rapidement en une collection chaotique
d'individus.
3.7
Négociation entre agents
La négociation joue un rôle fondamental dans les
activités de coopération en permettant aux personnes de
résoudre des conflits qui pourraient mettre en péril des
comportements coopératifs. La négociation est définie
comme étant le processus d'améliorer les accords (en
réduisant les inconsistances et l'incertitude) sur des points de vue
communs ou des plans d'action grâce à l'échange
structuré d'informations pertinentes. En général les
chercheurs en IA distribués utilisent la négociation comme un
mécanisme pour coordonner un groupe d'agents.
Un des protocoles les plus étudiés pour la
négociation s'appuie sur une métaphore organisationnelle. Le
protocole du réseau contractuel (Contract-Net) a été une
des approches les plus utilisées pour les systèmes multi-agents
[Bourdon 01][Jarras 02]. Les agents coordonnent leurs activités
grâce à l'établissement de contrats pour atteindre des buts
spécifiques. Un agent, agissant comme un gestionnaire (manager)
décompose son contrat (une tâche ou un problème) en
sous-contrats qui pourront être traités par des agents
contractants potentiels. Le gestionnaire annonce chaque sous-contrat sur un
réseau d'agents. Les agents reçoivent et évaluent
l'annonce.
Les agents qui ont les ressources appropriées,
l'expertise ou l'information requise envoient au gestionnaire des soumissions
(bids) qui indiquent leurs capacités à réaliser la
tâche annoncée. Le gestionnaire évalue les soumissions et
accorde les tâches aux agents les mieux appropriés. Ces agents
sont appelés des contractants (contractors). Enfin, gestionnaires et
contractants échangent les informations nécessaires durant
l'accomplissement des tâches. Par exemple, [Parunak 96] a utilisé
ce protocole pour développer un système de contrôle de
production.
3.8
Utilisateur dans les systèmes multi-agents
L'intégration de l'utilisateur dans un système
multi-agents est un problème qui a souvent été
évoque par la communauté des systèmes multi-agents, mais
qui n'a pas souvent été résolu. La plupart du temps,
l'utilisateur intervient dans le système pour fixer les
paramètres, observer un possible comportement émergent et
analyser les résultats, mais il est rarement intègre dans
l'environnement comme élément à part entière de la
simulation.
L'utilisateur interagit avec le système multi-agents
via une Interface Homme-Machine (IHM). Ainsi des travaux ont été
menés sur la réalisation de telles IHM [Brown et al. 98]. Le but
de ces travaux est de fournir une interface intelligente, c'est-à-dire
qui s'adapte aux actions de l'utilisateur. Dans ces travaux, le système
essaie de prévoir les actions futures de l'utilisateur pour lui proposer
la bonne interface. Pour cela, le système multi-agents se construit un
modèle de l'utilisateur a partir de l'observation de ses actions. Dans
de telles applications, l'utilisateur est considéré comme un
maître dans le système.
La plupart des travaux menés pour intégrer
l'utilisateur dans le système multi-agents se sont développes
autour des services sur Internet et l'informatique mobile [Burg 00]. Le
principe est alors de fixer des paramètres représentant
l'utilisateur dans un agent autonome qui le représente dans ses
différentes tâches sur Internet. ABROSE, est un exemple de ces
systèmes multi-agents [Gleizes et al. 00]. Le but de ABROSE est d'aider
l'utilisateur au courtage sur Internet. Le système est composé de
deux domaines. Le domaine du courtage et le domaine utilisateur. Le domaine du
courtage contient essentiellement les agents de transactions (TA)
représentant chacun un utilisateur. Cet agent connaît la
requête de l'utilisateur et dispose de croyances sur les autres agents de
transactions. Il peut ainsi collaborer avec les agents pertinents. Le domaine
de l'utilisateur fournit des utilitaires qui permettent à l'utilisateur
de se connecter au système, de formuler sa requête et de
réaliser les transactions. Dans de tels systèmes multi-agents,
l'utilisateur n'est intégré à l'environnement que via
l'agent qui le représente, il ne participe pas directement à
l'évolution de cet environnement.
3.9
Systèmes multi-agents et formation
L'intelligence artificielle est utilisée dans la
conception des tuteurs intelligents. Elle permet de représenter les
connaissances et les raisonnements de l'étudiant, de l'expert et du
tuteur. Cette modélisation est principalement réalise par des
règles d'inférences. Mais des travaux plus récents
proposent d'utiliser les systèmes multi-agents pour représenter
les connaissances. Les systèmes multi-agents sont également
utilises pour simuler les différentes stratégies
pédagogiques ou les différents composants de l'outil
pédagogique.
3.9.1
L'intelligence artificielle pour la formation
Le but des systèmes tuteurs intelligents (ou ITS
Intelligent Tutoring System) est de permettre à un étudiant
d'apprendre seul. Un tel système vise à rendre un retour
immédiat sur les actions de l'étudiant. En général,
les ITS alternent entre les phases où, l'étudiant mène
l'exercice et le tuteur valide les actions, et les phases où le tuteur
réalise les tâches et les explique à l'étudiant.
Différentes stratégies de formation [Aïmeur
et al. 00] ont été développées pour
améliorer l'utilisation des ITS. Les principales sont les
stratégies coopératives (compétitif) ou au contraire
perturbatrices. Dans les stratégies coopératives, le professeur
est vu comme un partenaire qui va échanger, contrôler et
construire des connaissances avec l'apprenant. Il y a trois types d'agent. Le
professeur (joué par le système), le compagnon (également
simulé) et l'apprenant (l'utilisateur humain). Le compagnon et
l'apprenant coopèrent pour la réalisation de la tâche,
échangent des idées sur le problème et partagent les
mêmes buts. A l'inverse, dans les stratégies perturbatrices, le
but est de perturber l'apprenant en lui proposant des solutions qui peuvent
être erronées. Cela force l'apprenant à évaluer la
confiance qu'il a dans les solutions qu'il propose. Dans ce type
d'apprentissage, il y a également trois types d'agent. Un professeur
(simulé) qui gère l'évolution de la session et
évalue les résultats, un apprenant (humain) et un étudiant
perturbateur (simulé). Le perturbateur et l'apprenant humain doivent
réaliser la même tâche. Le perturbateur propose des
solutions parfois fausses et parfois vraies. Cela provoque un débat
entre l'apprenant et le perturbateur. Ils doivent alors argumenter leurs
solutions. Le professeur se construit un modèle de l'utilisateur pour
connaître les points non maîtrisés par l'apprenant. Un autre
type de stratégie inclut un compagnon compétitif et un
deuxième compagnon perturbateur; afin de bénéficier les
avantages des deux stratégies d'apprentissage [Zeghida 03].
L'explication et l'évaluation sont des concepts
importants dans un ITS. En effet, un ITS doit savoir ce que l'étudiant a
effectivement compris pour évaluer ses performances et expliquer. Pour
pouvoir expliquer, le système doit comprendre exactement la dynamique de
l'environnement et les interactions entre ses composants pour détecter
la source de l'erreur. Cette tà ache peut devenir tr`es difficile dans
le cas de systèmes complexes [Zouaq et al. 00]. Ces explications doivent
également être personnalisées. Pour cela l'ITS doit avoir
des connaissances sur l'apprenant. Ces connaissances sont appelées
modèle de l'étudiant.
3.9.2
Les systèmes multi-agents pour la formation
Un EIAO et particulièrement un STI est un environnement
composé de plusieurs éléments, chacun d'entre eux
regroupant différents concepts. Plusieurs auteurs ont donc
proposé une implémentation fondée sur la
méthodologie des systèmes multi-agents. Les raisons
avancées sont souvent leurs capacités
d'incrémentalité (ajout ou modification d'une
fonctionnalité sans modifier l'ensemble de l'application) et
d'interfaçage entre modules hétérogènes.
Dans beaucoup d'STI, les agents représentent les
différents modules (expert, tuteur, interface...) C'est le cas, par
exemple, dans [Fenton et al 98], qui décrit différents types
d'agent, chacun ayant un rôle particulier [Querrec 02] :
·
Source d'informations (cours, sons, images...),
·
Tuteur,
·
Expert,
·
Motivateur, dont le rôle est d'encourager l'apprenant,
attirer son attention sur des éléments de l'environnement,
·
Médiateur qui permet de faciliter les
interactions entre les différents intervenants.
Cependant, pour pouvoir illustrer le rôle des agents
nous avons passé en revue les différentes recherches effectuer
dans ce domaine durant les deux dernières décennie. On peut
regrouper ces nouveaux STI en deux domaines suivant les stratégies
d'apprentissage employés:
1.
Les systèmes d'apprentissage sociaux ;
2.
Les systèmes adaptatifs.
Bien entendu cette distinction est largement artificielle car
on peut retrouver des systèmes qui sont à la fois sociaux et
adaptatifs.
L'ensemble de ces travaux se base sur un modèle de
l'apprenant pour adapter l'intervention de leurs composants. Des travaux ont
donc également été menés pour construire le
modèle apprenant par un système multi-agents. En effet,
l'objectif de la construction d'un tel modèle est de reconnaître
le raisonnement de l'étudiant à partir de l'analyse de ses
interactions avec l'environnement.
3.9.2.1
Les environnements d'apprentissage sociaux et les SMA
Ces prétendus systèmes d'apprentissage avec
compagnon (LCS) sont une variation des systèmes tuteurs intelligents.
Ils essayent de modeler des groupes d'étudiant comme dans une salle de
classe visant à créer un contexte «social» plus riche.
Il se compose au moins de trois agents : le tuteur, l'étudiant et le
compagnon d'apprentissage (LC : Learning Compagnon).
Ainsi, dans un environnement d'apprentissage social,
l'apprenant et le compagnon peuvent collaborer ou concurrencer. Cependant, si
des systèmes coopératifs et de collaboration peuvent être
considérés en tant que systèmes d'apprentissage sociaux,
il y a une différence entre la coopération et la collaboration :
Systèmes collaboratifs : La
collaboration exige une action commune des agents et une compréhension
mutuelle de la tâche à exécuter, chacun ayant ses propres
objectifs.
Systèmes coopératifs : La
coopération, quant à elle, exige de partager les
responsabilités entre les agents pour exécuter une tâche et
la connaissance des objectifs mutuels.
Une autre utilisation des agents dans les systèmes
sociaux dans un réseau est de remplacer un des participants
éloignés lors d'un apprentissage, ou de jouer le rôle de
compagnon ou de tuteur privé pour aider chaque participant humain. Par
exemple, dans l'absence de l'apprenant, il peut déléguer un
compagnon pour participer à sa place à une certaine formation
avec d'autres étudiants, en utilisant le modèle apprenant.
Un autre apport des systèmes multi-agents est de
pouvoir gérer simultanément différentes stratégies
de formation. Ainsi les travaux de [Frasson et al 97] se fondent sur le constat
qu'une stratégie de formation peut ne pas être adaptée pour
un apprenant dans un domaine spécifique, un STI doit alors
intégrer plusieurs stratégies de formation. Dans l'architecture
proposée [Frasson et al 97] (Figure 2.2), un agent (Session manager)
choisit la stratégie adaptée puis active l'agent correspondant en
fonction du domaine et du modèle de l'étudiant. Cette
sélection est dynamique. La stratégie globale de formation
émerge donc résulte d'une collaboration entre les agents
pédagogiques.
C'est ce principe d'émergence de la fonction
pédagogique à partir des interactions entre les composants d'un
EIAO qui est implémentée dans le système Baghera [Pesty et
al 01].
3.9.2.2
Les environnements d'apprentissage adaptatifs et les
systèmes multi-agents
Un système adaptatif perçoit le comportement de
l'utilisateur à travers ses actions sur l'interface et adapte alors sa
propre organisation interne, et donc son propre comportement, à cette
perception. Par conséquent, le module d'interface avec l'usager n'est
plus un simple module de communication entre l'apprenant et le système,
mais il détient une partie de l'intelligence du système lui
permettant de s'adapter à différentes caractéristiques de
l'usager.
Pour y arriver, le système doit posséder une
structure qui permette un changement d'organisation. Lorsqu'il s'agit de
concevoir un tel système, la technologie « agent » se
révèle bien adaptée. Le système essaie de
prévoir les actions futures de l'utilisateur pour lui proposer
l'interface adéquate. Pour cela, le système multi-agents se
construit un modèle de l'utilisateur à partir de l'observation de
ses actions [Querrec 02].


Dans le travail de L. Richard, le système CMOS [Richard
99], le principe est sensiblement le même. L'architecture du
système multi-agents est donnée en figure 2. Dans cette
architecture trois types d'agent coexistent, des agents humains (apprenant et
instructeur), des agents cognitifs (qui sont permanents et dont il n'existe
qu'un seul individu par classe) et des agents réactifs
(créés par les agents cognitifs et dont il existe 0 ou n
individus par classe). Les agents cognitifs sont appelés ainsi car,
d'une part ils ont la capacité d'apprendre, c'est-à-dire que leur
base de connaissances évolue, et d'autre part leurs connaissances
portent sur des capacités cognitives et pédagogiques du
système et de l'apprenant (interactions, erreurs ...) [Querrec 02].
Ainsi, un agent Détecteur d'écart surveille les
interactions entre l'apprenant et son environnement. S'il détecte un
écart avec la base de savoir-faire (méthodes
préenregistrées par l'instructeur), il crée un agent
réactif « Evaluateur d'écart » qui, en relation avec
l'agent cognitif Dépositaire de l'expérience instructeur (qui
contient les instructions pédagogiques de l'instructeur), évalue
la gravité de cet écart. Cette évaluation est transmise
sous forme de note à l'agent cognitif Curriculum qui gère la
progression de l'étudiant et l'organisation des sessions
d'apprentissage. En fonction de cette évaluation, l'agent Evaluateur
d'écart prend contact avec l'agent cognitif Gestionnaire des ressources
didactiques qui présente à l'apprenant la ressource
adaptée à son erreur.


Dans ce type d'utilisation, le professeur n'intervient
qu'avant la formation pour définir les exercices et les
préférences pédagogiques, et après la formation
pour analyser le curriculum. C'est le principe même des STI qui partent
de l'hypothèse de la distribution géographique des intervenants.
Des travaux ont alors été menés pour distribuer ces
applications sur le réseau Internet et pour permettre au professeur
d'avoir des informations sur les activités des apprenants et agir pour
les aider lorsque les tuteurs n'y arrivent pas. La difficulté
réside alors dans la conception d'un agent qui va permettre au
professeur de bien percevoir la situation chez l'apprenant [Querrec 02].
Chapitre 3
Hypermédia Educatif Adaptatif dynamique
basé Agent
- HEDAYA -
1
Introduction
Dans ce chapitre, nous présentons le système
multi-agents HEDAYA (Hypermédia
EDucatif Adaptatif dYnamique
basé Agent) que nous avons développé en
vue de créer un système hypermédia éducatif,
adaptatif au profile et à l'objectif de l'apprenant, dynamique
générant les pages hypermédias dynamiquement, en
présentant plusieurs visions d'un même concept, dont le cours est
le résultat de l'interaction entre ses agents collaboratifs. Ces agents
autonomes coopèrent pour accomplir des tâches en communicant entre
eux. Le problème central de ce type d'agent est le langage de
communication qui doit être bien défini, le langage utilisé
dans HEDAYA et KQML (Knowledge Query and Manipulation Language).
Nous avons développé une démonstration du
système HEDAYA en utilisant JAVA comme langage de programmation
(l'environnement JBuilder 7), XML pour modéliser le modèle du
domaine et le modèle des activités pédagogiques, Interbase
comme SGBD pour les bases de données des modèles des l'apprenants
et la base de documents multimédias.
Nous présentons dans ce chapitre l'architecture
détaillée de notre système où on décrit les
modèles utilisés et les agents constituant le système.
Ensuite, on aborde les techniques utilisées pour assurer la
communicabilité dans notre système multi-agents. La
quatrième section montre les règles de sélections des
liens hypertextes et la méthode d'introduction des techniques
d'annotation des liens. Les différents scénarios d'apprentissage
et les protocoles de communications sont illustrés dans la
cinquième section. La sixième section parle de l'architecture
logicielle de HEDAYA et de différents outils utilisés pour
implémenter ce système.
2
Architecture détaillée de HEDAYA
Le système est constitué des composants
standards des hypermédias éducatifs adaptatifs dynamiques
[Delestre 00] et les hypermédias générant des
activités pédagogiques [Balla et al 03][Balla 04][Laoudi 02]:
modèle de l'apprenant, modèle du domaine, modèle des
activités pédagogiques et la base de documents
multimédias.
Par couplage avec les hypermédias basés-agents
[Bailey 02], les système tutoriels intelligents basés agents
[Hospers et al 03] [Capuano et al 01] et les environnements de formation
à distance basés agents [Bergia 01][Mbala 03], on a
développé une architecture d'un système multi-agents
collaboratif, constitué de quatre agents : agent d'interface, agent
pédagogique d'adaptation, agent du modèle de l'apprenant et agent
de filtrage [Beggas 04].
2.1
Modélisation du système
2.1.1
Modèle de l'apprenant
Le modèle de l'apprenant permet au système de
s'adapter à l'apprenant qui interagit avec lui. C'est-à-dire, il
présente des connaissances compréhensibles et utilise ce que
l'apprenant connaît déjà. Ceci ne peut être atteint
que par la connaissance de profile de l'apprenant. Ce profile doit
intégrer les connaissances de l'apprenant sur le domaine, mais aussi on
peut ajouter des particularités de l'apprenant comme ses objectifs
pédagogiques et ses préférences (couleur, police, etc.).
Pour modéliser les connaissances de l'apprenant sur le
domaine, le plus fréquent paradigme de représentation des
connaissances de l'apprenant est le modèle de couches (overlay model)
[Koch 00]. Son principe est de refléter les connaissances individuelles
de l'apprenant comme une couche d'une certaine épaisseur du
modèle du domaine. A chaque concept du modèle de du domaine,
s'associée une valeur d'estimation des connaissances de l'apprenant sur
ce concept, cette estimation peut être une valeur binaire « connu -
inconnu », une mesure qualitative « bien - satisfait - mauvais »
ou une probabilité définissant la connaisse sur le concept.
L'ensemble des couples « concept - valeur » constituent alors le
modèle de couches ; i.e. les connaissances de l'apprenant sur le
domaine.
On choisit la mesure qualitative; on associe une valeur
d'estimation des connaissances de l'apprenant à chaque concept du
modèle de du domaine; « concept - valeur » (valeur : faible,
moyen ou bien), qui permettra d'assigner à chacune des mesures une
activité pédagogique « mesure - activité
pédagogique ». On aura donc les correspondances suivantes : «
faible - familiarisation », « moyen - clarification » et «
bien - renforcement ». Ces correspondances permettent de déclencher
l'activité pédagogique adéquate.
Le modèle de l'apprenant contient aussi, le classement
de type physique de média préféré et le mode
d'apprentissage suivi.
2.1.2
Modèle du domaine
Le modèle du domaine est la composante de
système, qui permet à l'ordinateur de connaître ce qui va
enseigner à l'étudiant [Delestre 00] ; il contient le
matériel à enseigner. Ce modèle est défini par les
experts du domaine qui sont dans ce cas les enseignants. Pour avoir une
effective personnalisation du cours, le matériel doit être bien
structuré et bien granulé.
Le modèle de domaine est représenté par
un graphe contient des noeuds et des arcs; les noeuds constituent les concepts,
les relations entre eux sont définis par les arcs. On distingue quatre
types de relations [Delestre 00]:
1.
La relation de prérequis qui indique que
l'apprentissage d'une notion A est assujettie à la maîtrise de la
notion B.
2.
La relation d'analogie qui indique que la
maîtrise d'une notion A peut aider l'apprentissage d'une nouvelle notion
B.
3.
La relation de conjonction qui indique que
l'apprentissage d'une notion A s'effectue via l'apprentissage séquentiel
d'une succession de notions Ai.
4.
La relation de disjonction forte qui indique
que l'apprentissage d'une notion peut s'effectuer via l'apprentissage de telle
ou bien telle notion.
La Figure 3.2 représete le modèle du domaine de
notre démonstration.
Le modèle du domaine permet par sa définition
des relations entre concept :
°
L'adaptativité de système par le modèle de
domaine et le modèle de l'apprenant defini comme une couche sur lui et
par:
°
L'organisation pédagogique des differents concepts par
les relations entre concepts
Connaît rappel
Apprenant   Figure 3.3Figure 3.3: exemple de canevas de l'activité
pédagogique «familiariser»
Figure 3.3Figure 3.3: exemple de canevas de l'activité
pédagogique «familiariser»
Concept Figure 3.4:Document multimédia et
ses attributs
Niveau de compréhension Niveau cognitif : familiariser
Figure 3.1 : Niveaude compréhension d'un
concept pour un apprenant Type cognitif : Histologie, Introduction
2.1.3
Modèle des activités pédagogiques
Ce modèle constitue par activités
pédagogiques qui permettent au système de présenter les
concepts de différente façon de sorte à trouver la
meilleure présentation possible. A partir de ces activités, le
système déduit l'ensemble des tests à présenter
à l'apprenant afin de renforcer ses connaissances.
L'intérêt de l'utilisation des activités
pédagogiques réside dans le fait que celle-ci permettent d'avoir
plusieurs vues d'un même concept ce qui facilite sa compréhension.
Les activités pédagogiques sont [Balla et al
03][Laoudi 02] :
1.
Familiarisation : permet à l'apprenant de manipuler le
concept, ses taches sont :
·
Introduction
·
Simplification
·
Comparaison
·
Rappel
·
Digression
2.
Clarification : nécessaire pour clarifier le concept, ses
taches sont :
·
Observation
·
Démonstration
·
Description
·
Reformulation
3.
Renforcement : utile pour consolider le concept, ses taches sont
:
·
Illustration
·
Justification
·
Discussion
·
Récapitulation
·
Corroboration
  4 :
ordre 4 :
ordre
HistologieType Physique: texte + image
EczémaAdresse : URL
Mélanome
InfectionConcept ; Eczéma,
UlcèresActivité pédagogique :
Clarifier
SyphilisTache : Description
générale
Acné
Impétigo Concept ; Psoriasis,
Erysipèle Activité pédagogique :
Familiariser
Pré-requis Analogie Tache :
Description générale
Disjonction ConjonctionFigure 3.5:
Document multimédia meta-concept
Figure 3.2: Représentation de
modèle dudomaine Figure 3.2
A chaque concept du domaine, l'auteur associé un
certain nombre d'activité suivant le degré de difficulté
de compréhension et à la nature du concept. Dans la phase
d'apprentissage le système choisira l'activité adéquate.
Les taches induites par les activités
pédagogiques ont utilisé pour définir le canevas du
document qui sera présenter à l'apprenant. Ces canevas sont
prédéfinis par les enseignants.
L'utilisation des activités pédagogiques permet
d'avoir plusieurs visions de même concept, par exemple, dans le cas de
l'activité familiariser on peut considérer différentes
structures telles que :
1.
Introduction
2.
Rappel
3.
Comparaison
4.
Simplification
Ou bien
5.
Simplification
6.
Digression
7.
Comparaison
8.
Rappel
Le choix de la structure dépend des
préférences de l'apprenant quant au média utilisé
et au mode d'apprentissage. Ces préférences peuvent être
représentées par un graphe des taches comme illustré dans
la .
2.1.4
Base de documents multimédias
Les documents multimédias constituent les fragments du
cours à présenter à l'apprenant, ils sont stockés
dans la base de documents multimédias. Chaque document est lié
à un concept, une activité pédagogique (donc un niveau de
l'apprenant), une tâche de canevas de cours par quatre types d'attribut
[Recker 95][Delestre 00]
1.
Le type physique de documents (texte, image, vidéo, etc.)
2.
Le type cognitif, issu des tâches de l'activité en
cours, par exemple dans le cas de l'activité clarifier, l'attribut de
document choisi est parmi la liste suivante : description,
démonstration, observation et reformulation
3.
Le niveau cognitif, qui permet de spécifier, pour une
notion, le niveau de connaissance de l'apprenant pour appréhender
correctement le document.
4.
Adresse : l'adresse du document
La Figure 3.4 montre un exemple de document multimédia
avec ses attributs.
2 : ordre Perception
digression Action
1 : ordre Agent de modèle de
l'apprenant
simplification Modèle des activités
pédagogiques
4: ordreBase de documents Multimédia
simplification
3: ordreAgent d'Interface
comparaison Utilisation de modèle par un agent
2: ordreFigure 3.8: Architecture deHEDAYA
rappel Figure 3.13: Protocoles de communication
pour le scénario connexion d'un apprenant
1: ordreAMA
canevasPOST
introductionTell
familiariserAMA
comparaison Reply
3 : ordre Apprenant Inscrit

Dans notre système, on distingue quatre types de
documents multimédias :
°
Les documents multimédias définissant une
tâche d'un concept
1.
Le document associe à une tâche d'un concept
(Figure 3.4)
°
Et autres types de documents auxiliaires introduits pour
améliorer la qualité d'adaptation et pour le bon
déroulement du système
2.
Le document méta concept contenant une description
générale sur le concept selon l'activité
pédagogique suivi (pour chaque concept on définit trois documents
méta concepts, un pour chaque activité pédagogique; le
type cognitif dans ce cas est : concept + description générale).
Ces documents seront utilisés pour construire la page index du cours
(Figure 3.5).
3.
Le document test d'évaluation; ce type de documents est
construit en utilisant des Applets java permettant l'évaluation de
réponses.
4.
Le document page Web, par exemple, la page d'inscription de
nouveau apprenant
 Attente de connexion d'un agent (ie. d'un socket client);
Attente de connexion d'un agent (ie. d'un socket client);

2.2
Architecture du système
En basant sur les modèles présentés dans
la section précédente, on peut proposer une architecture
multi-agents constituée de quatre agents : agent d'interface, agent
pédagogique d'adaptation, agent du modèle de l'apprenant et agent
de filtrage.
2.2.1
Modèle général d'un agent Modèle
général d'un agent
Dans notre contexte un agent est considéré comme
entité logiciel qui travaille d'une manière continue et autonome
dans un environnement particulier, généralement avec d'autres
agents, capable d'intervenir dans cet environnement d'une manière
flexible et intelligente, n'exigeant pas l'intervention ou le guidage humain
[Silveira et al 02]. Dans notre contexte un agent est considéré
comme entité logiciel qui travaille d'une manière continue et
autonome dans un environnement particulier, généralement avec
d'autres agents, capable d'intervenir dans cet environnement d'une
manière flexible et intelligente, n'exigeant pas l'intervention ou le
guidage humain [Silveira et al 02].
Le choix d'un modèle d'agent se fait essentiellement en
fonction de besoins exprimés pour cet agent au cours de la phase
d'analyse. Tous les agents doivent disposer de moyens de communication de haut
niveau, de capacité de raisonnement et de prise de décision. Ces
besoins nous conduisent à choisir un modèle d'agent cognitif pour
nos agents. La Figure 3.6 présente le modèle
général de cet agent. Ce modèle est inspiré du
modèle d'agent BDI (Beliefs Desires Intentions) de Rao et Georgeff [Rao
et al 95]. Le choix d'un modèle d'agent se fait essentiellement en
fonction de besoins exprimés pour cet agent au cours de la phase
d'analyse. Tous les agents doivent disposer de moyens de communication de haut
niveau, de capacité de raisonnement et de prise de décision. Ces
besoins nous conduisent à choisir un modèle d'agent cognitif pour
nos agents. La Figure 3.6 présente le modèle
général de cet agent. Ce modèle est inspiré du
modèle d'agent BDI (Beliefs Desires Intentions) de Rao et Georgeff [Rao
et al 95].
Le module de communication reçoit les messages (dans
notre cas KQML) et passe le contenu au module de raisonnement. Dans le cas
où l'action spécifiée est une action de communication, il
détermine les coordonnées de l'agent récepteur, de la B.C.
(Base de connaissance) puis envoie le message. Le module de communication
reçoit les messages (dans notre cas KQML) et passe le contenu au module
de raisonnement. Dans le cas où l'action spécifiée est une
action de communication, il détermine les coordonnées de l'agent
récepteur, de la B.C. (Base de connaissance) puis envoie le message.
La base de connaissances (B.C.) contient les croyances de
l'agent sur l'environnement et sur les autres agents. La base de connaissances
(B.C.) contient les croyances de l'agent sur l'environnement et sur les autres
agents.
 Figure 3.9 : Communication par les sockets, coté
serveur Figure 3.9 : Communication par les sockets, coté
serveur
 Figure 3.10 : Communication par les sockets,
coté client Figure 3.10 : Communication par les sockets,
coté client
Le modèle Buts/Plans contient les plans à suivre
pour atteindre des buts spécifiés ; chaque but est associé
à un plan. Le plan détermine les actions à
exécuter.
Le module de raisonnement détermine le plan et
contrôle l'exécution de ce plan. Les actions sont soit action de
communication ou action sur l'environnement de l'agent (par exemple, action sur
une base de données ou action de consultation d'un modèle).
Les agents cognitifs fonctionnent suivant un processus en
boucle de type Perception-Décision-Action (). on ().
La perception et l'action correspondent respectivement
à la réception asynchrone de messages et à l'envoi de
messages. La décision dépend des états internes de l'agent
La perception et l'action correspondent respectivement à la
réception asynchrone de messages et à l'envoi de messages. La
décision dépend des états internes de l'agent et des
messages reçus. Elle consiste à l'interprétation de
message, la détermination de but et, donc le choix d'un plan.
Décision
Figure 3.7Figure 3.7Figure 3.7 : Cycle de base
de fonctionnement d'un agent cognitif
Communication
Moteurde raisonnement etde contrôle
B.C.
Buts/Plans
Action
Environnement interne de l'agent
Figure 3.6:modèle général
d'un agentFigure 3.6


Les mécanismes de perception et d'action peuvent
être génériques pour nos agents, sauf l'agent d'interface
qu'il a besoin en plus d'un mécanisme de perception de requête
HTTP, alors que la fonction de décision est spécifique à
chaque agent, elle dépend de son rôle et des tâches qu'il
doit réaliser. Ainsi, nous identifions trois couches dans l'architecture
de nos agents :
La couche 1 :
correspondant aux ressources de communication bas niveau
disponibles (les sockets Java et le protocoles TCP/IP),
La couche 2 :
est la couche support à la gestion des protocoles
d'interaction ; les messages KQML échangés entre les agents
La couche 3 :
est la couche applicative ; c'est la partie spécifique
à chaque agent.
L'agent d'interface a besoin d'une sous couche de
communication en utilisant le protocole HTTP.
2.2.2
Agent d'interface
L'agent d'interface joue le rôle d'une interface entre
l'apprenant et, l'agent pédagogique d'adaptation, l'agent du
modèle de l'apprenant et l'agent de filtrage. L'agent d'interface
utilise deux moyens de communication; le protocole HTTP pour la communication
avec l'apprenant (le navigateur Web), le langage KQML pour la communication
avec les autres agents.
Il reçoit la demande de concept ou de page index du
cours sous forme d'une requête HTTP, il formule une requête KQML et
l'envoie à l'agent pédagogique d'adaptation.
Il reçoit la demande d'inscription d'un nouveau
apprenant ou la demande de connexion d'un apprenant déjà inscrit
(requête HTTP) et l'envoie à l'agent de modèle de
l'apprenant en KQML, il lui envoie aussi le résultat d'évaluation
d'un exercice pour modifier le modèle de l'apprenant.
Après la réponse sur la demande de concept ou de
page index du cours de l'agent pédagogique d'adaptation contenant les
adresses des documents et les liens ordonnés, l'agent d'interface
récupère les documents de la base de documents,
génère la page puis l'envoie à l'apprenant.
2.2.3
Agent pédagogique d'adaptation
Le rôle de l'agent pédagogique d'adaptation est
la structuration pédagogique de la page de concept ou la page index du
cours selon les relations entre concepts dans le modèle du domaine, le
modèle des activités pédagogiques et le niveau
pédagogique de l'apprenant par requête à l'agent de
modèle de l'appreant.
Suite à une demande de l'agent d'interface, il
spécifie la structure pédagogique de page de cours (ou de la page
index du cours) par la définition des tâches à utiliser
selon le modèle des activités pédagogiques (par la
spécification des concepts de page index et l'activité
pédagogique de chacun d'eux).
Il demande de l'agent de modèle de l'apprenant le
niveau de l'apprenant sur le(s) concept(s), puis il demande de l'agent de
filtrage de filtrer les documents adéquats aux critères qu'il a
déjà spécifiés, après la réponse de
l'agent de filtrage, il crée la structure de page (séquence de
documents et de liens) puis l'envoie à l'agent d'interface comme
réponse à la damnde de page de concept (ou page index du cours).
2.2.4
Agent de filtrage
Le rôle de l'agent de filtarge est le fitrage de
documents multimédias selon les critères spécifiés
par l'agent pédagogique d'adaptation, puis il lui répond par
l'envoi des adresses de ces documents.
Il applique deux types de filtres :
°
Filtrage de documents pour la génération de page
d'un concept (la requête de demande de filtrage contient : concept, liste
de tâches, activité pédagogique). ie. filtrage des
tâches constituant le canevas de cours
°
Filtrage de documents pour la génération de page
index (la requête de demande de filtrage contient une liste de (concept,
activité pédagogique, tâche = « description
générale »).
L'agent de filtrage lorsqu'il reçoit la demande de
filtrage de documents de concept de l'agent pédagogique d'adaptation, il
applique quatre filtres
1-
Pour filtrer les documents de concept choisi
2-
Pour filtrer, parmi l'ensemble résultat du 1er filtre,
les documents satisfaisant le niveau cognitif (l'activité
pédagogique à suivre)
3-
Pour filtrer les documents des tâches induites de
l'activité pédagogique demandée
4-
Pour chaque tâche, il filtre le document adéquat au
type physique de média préféré à
l'apprenant.
2.2.5
Agent de modèle de l'apprenant
Le rôle de l'agent du modèle de l'apprenant est
de créer, initialiser, mémoriser et traiter le modèle de
l'apprenant.
Il ajoute le nouveau apprenant suite à une demande de
l'agent d'interface et initialise son niveau par faible pour tous les concepts.
Il modifie le niveau de l'apprenant sur un concept
après l'évaluation de réponse de l'apprenant sur les tests
et l'envoi de nouveau niveau par l'agent d'interface
Il consulte le modèle d'un apprenant pour
spécifier son niveau pour un ou plusieurs concepts, réponse
à une demande de l'agent pédagogique d'adaptation.
Modèle du domaine
Agent Pédagogique .d'adaptation
Modèle de l'apprenant
Agent de filtrage
Communication entre agents
Relation entre modèles

La Figure 3.8 illustre l'architecture détaillée
de système HEDAYA ; les modèles utilisés, les agents et
les différents canaux de communication entre eux.
3
Communication entre agents
L'interaction entre agents définit par l'aptitude
d'échanger des informations et des connaissances qui peuvent être
mutuellement comprises. Comme l'interaction entre les personnes, l'interaction
entre les agents a besoin d'un langage de communication commun, une
capacité d'échanger les connaissances et une compréhension
mutuelle des connaissances échangées [Barceinas at al 98].
Le ACL (Agent Communication Language) a été
créé par ARPA pour assurer l'interopérabilité entre
des agents autonomes et distribués. Le ACL a trois composants : un
vocabulaire, un langage de communication entre agent appelé KQML
(Knowledge and Query Manipulation Language) et un langage spécifiant le
contenu appelé KIF (Knowledge Interchange Format). Un message de ACL est
alors un message KQML contenant une directive de communication et un contenu
sémantique dans KIF, exprimé en termes de vocabulaire.
KQML fournit la couche linguistique pour rendre la
communication efficace en considérant le contexte des messages. Il a
été conçu comme format de message et comme protocole qui
permet l'identification, le raccordement et l'échange de l'information
entre des programmes. Selon [Finin et al. 95], KQML est
caractérisé par trois caractéristiques importantes :
1.
Les messages KQML sont opaques au contenu qu'ils transportent,
ce qui implique que les messages KQML ne communiquent qu'avec des sentences en
certain langage, mais aussi une attitude ou à une intention sur le
contenu.
2.
Des primitifs s'appellent performatives indiquent les actions ou
les opérations valides.
3.
Un environnement dans lequel les agents communiquent avec KQML
peut être enrichi avec un genre spécial d'agents appelés
les facilitateurs.
3.1
Le langage de communications utilisé dans HEDAYA
Le langage utilisé pour la communication entre les
agents de système HEDAYA est KQML. On a utilisé parmi les
performatifs standard de KQML un sous ensemble, permettant l'interaction entre
les agents de notre système.
Les performatifs utilisés sont :
Acheive : l'émetteur demande au
récepteur de rendre le contenu de message vrai dans son environnement
(l'environnement de récepteur).C'est à dire de réaliser la
tache qui rend le contenu de message vrai.
Tell : le contenu de message est vrai dans
l'environnement de l'émetteur.
Ask-if : l'émetteur veut la sentence
de récepteur qui assortit le contenu de message.
Reply : l'émetteur
croit que le contenu de message est une réponse appropriée
à une demande ou à une question précédente.
Ask-about : l'émetteur veut toutes les
sentences qui assortissent le contenu de message.
Voici un exemple de message KQML
|
Paramètre
|
Valeur
|
|
Performatif
Sender
Reciever
Ontology
Language
Content
|
Achieve
AI (Agent d'interface)
APA (Agent pédagogique d'Adaptation)
MyOntology (vocabulaire utilisé)
Java
générerPageConcept(eczéma, 1)
|
Tableau 3.1 : Exemple de message KQML
Le massage de tableau ci-dessus est un message de l'agent
d'interface (sender) vers l'agent pédagogique d'adaptation (receiver),
le performatif de message est une demande de réalisation (acheive) de
générerPageConcept(eczéma, 1), c'est-à-dire l'agent
d'interface demande de l'agent pédagogique d'adaptation de
générer la page de concept eczéma pour
l'apprenant qui a l'identificateur 1.
Un autre moyen de communication est utilisé pour la
communication entre l'apprenant (le navigateur Web) et l'agent d'interface,
c'est le protocole HTTP qui fonctionne au mode requête réponse.
Les méthodes utilisées sont GET et POST.
3.2
Implémentation de la communication entre les
agents de HEDAYA
Pour implémenter la communication entre agents,
plusieurs moyens existent : au niveau le plus bas, il existe les sockets
qui permettent aux différents agents codés en Java de
communiquer entre eux ; il existe aussi d'autres technologies (en Java
notamment). On peut citer l'invocation de méthodes distantes (RMI Remote
Method Invocation) et la technologie CORBA (Common Request Broker
Architecture).
Une socket est une abstraction de programmation
représentant les extrémités d'une connexion entre deux
ordinateurs. Pour chaque connexion donnée, il existe une socket
sur chaque machine, on peut imaginer un câble virtuel reliant les
deux ordinateurs, chaque extrémité étant enfichée
dans une socket. En Java, on crée un objet Socket pour
établir une connexion vers une autre machine, puis on crée un
InputStream et un OutputStream à partir de ce Socket,
afin de traiter la connexion en tant qu'objet flux d'entrée/sortie.
Le principe de l'invocation de méthodes distantes et de
permettre à un objet présent sur une autre machine de lui envoyer
un message et l'on obtient le résultat comme si cet objet était
instancié sur la machine locale. L'invocation de méthodes
distantes exige de créer une interface distante (remote interface) sur
la machine serveur ; ainsi, l'implémentation sous-jacente est
masquée aux différents clients.
La norme CORBA fait partie du travail réalisé
par l'OMG (Object Management Group) pour définir des standards
d'interopérabilité des objets distribués et
indépendants du langage. Elle fournit la possibilité de faire des
appels à des méthodes distantes dans des objets Java et non Java,
d'interfacer des systèmes existants sans se soucier de leur emplacement.
CORBA dispose d'un langage de définition d'interface, IDL (Interface
Definition Language), qui précise les types de données, les
attributs, les opérations, les interfaces, etc.
Nous avons choisi de faire communiquer nos agents par les
sockets Java, qui assure une communication en utilisant le protocole
TCP/IP. Chaque agent lors de son fonctionnement ouvre son socket serveur et
attend les messages des autres agents, si un message arrive il lance un thread
pour le traiter, donc il n'y a pas de message en attente de traitement ;
c'est-à-dire plusieurs messages peuvent être traités en
parallèle (Figure 3.9).
Création de socket serveur
While (true){
Création de thread de traitement de requête
Lancement de thread(traite la requête et établit
la réponse)
}
Un agent lorsqu'il a besoin de communiquer avec les autres
agents il ouvre une communication avec un socket client, qui communique avec
socket serveur de l'agent récepteur, en spécifiant l'adresse de
la machine et le port puis il envoie le message (Figure 3.10).
Les messages KQML sont implémentés en
définissant la classe Java KQMLmessage illustré dans la Figure
3.11.
La communication consiste à l'instanciation d'un objet
de la classe KQMLmessage, la définition des ses attributs, puis l'envoi
de cet objet. La classe KQMLmessage implémente l'interface Serializable,
ce qui permet l'envoi et la réception des objets de cette classe par les
sockets comme stream (flot).
Création de socket client (Nom Haute ou adresse IP, port)
Envoie de massage
...Attente de réponse ...
Réception de réponse
public class KQMLmessage
implements Serializable {
private String performative;
private String sender;
private String receiver;
private String in_reply_to;
private String reply_with;
private String language;
private String ontology;
private Content content;
....
....
}
Figure 3.11:Classede message KQML


4
Sélection des liens et utilisation de
technique d'annotation des liens
La génération de structure de page et la
sélection des liens sont réalisées par l'agent
pédagogique d'adaptation ; l'agent d'interface génère la
page HTML et crée les liens selon la structure déjà
définie.
La technique d'annotation des liens est utilisée dans
notre système pour distinguer les concepts étudiés et non
étudiés.
4.1
Sélection des liens hypertextes
Une fois qu'on a construit la structure d'une page, il faut
déterminer les liens permettant à l'apprenant d'accéder
à d'autre notions, en prenant en compte les relations du modèle
du domaine et le modèle de l'apprenant. Donc on doit déterminer
les types des liens hypertextes pour la page index du cours ou la page index
des concepts prérequis et pour chaque relation dans le modèle du
domaine, comme suit :
1.
Dans la page index du cours, on associe à chaque concept
représenté par un méta document un lien vers le concept en
spécifiant l'activité pédagogique, la de la section
suivante illustre les liens dans la page index du cours.
2.
Dans le cas de pré-requis, on génère la
page et les liens des concepts prérequis de la même façon
que celle de la page index du cours. la de la section suivante illustre les
liens dans la page de concepts prérequis.
3.
Dans le cas de relation d'analogie, on associe à chaque
concept analogue un lien dans la zone haute de la page de concept.
4.
Dans le cas de relation disjonction, on génère une
page index de concepts de disjonction de la même façon que celle
de la page index du cours.
5.
Dans le cas de relation de conjonction, la page de ce concept
contient les liens des concepts de conjonction. , la Figure 3.18 de la section
suivante illustre les liens dans la page d'un concept conjonction.
Figure 3.14Figure 3.14: page index du cours
Figure 3.17Figure 3.17: page index des concepts
prérequis
4.2
Annotation des liens
La technique d'annotation des liens est utilisée dans
notre système pour distinguer les concepts étudiés et non
étudiés dans la page index du cours et selon les relations entre
concepts dans le modèle du domaine ; dans le cas des concepts
conjonction d'un ensemble de sous concepts, disjonction d'un ensemble de sous
concepts ou un concept qui a des analogues.
1.
Dans le cas de page index du cours ou page index de concept
disjonction, les concepts étudiés pour tous les concepts sont
annotés par « concept bien étudié ». La Figure
3.16 de la section suivante illustre les annotations dans la page index du
cours.
2.
Dans le cas de relation d'analogie, les concepts analogues
étudiés sont annotés par « concept
étudié ».
3.
Dans le cas de relation de conjonction, chaque lien de sous
concepts de conjonction étudié est annoté par «
concept étudié », le concept en cours (affiché dans
la page en cours) est annoté par « ** », i.e. concept
courant. La de la section suivante illustre les annotations dans la page d'un
concept conjonction.
Nous verrons dans la section suivante comment s'organisent sur
l'écran les différents liens et annotations.
4.3
Mode libre et mode guidé
On a defini deux modes d'apprentissage (ou navigation) ; mode
guidé et mode libre. Le mode guidé est inspiré des
systèmes tutoriels intelligents dont l'apprenant doit suivre
l'organisation pédagogique des concepts définis par les relations
entre concept dans le modèle du domaine. Le mode libre est
inspiré des hypermédias classiques, il permet de garder les
avantages des hypermédias classiques surtout la liberté de
navigation
Un apprenant lorsqu'il inscrit de la première fois pour
suivre un cours, il choisit le mode d'apprentissage.
Figure 3.18Figure 3.18: page deconcept
conjonction
5
Scénarios d'utilisation de HEDAYA et
protocoles d'interaction entre agents
Pour démontrer le comportement du système
multi-agents ; la présentation adaptative du cours et la
génération dynamique des pages du cours hypermédia, on a
utilisé un cours sur la dermatologie spécifié pour deux
activités pédagogiques « Familiariser » et «
Clarifier » ; en définissant le modèle du domaine (), les
documents méta concepts (Figure 3.5) pour générer la page
index du cours et les documents multimédias (Figure 3.4) pour
générer la page de concept.
Nous illustrons, dans la suite, le fonctionnement du
système par les scénarios possibles pendant les sessions
d'apprentissage, en associant à chaque scénario les
différents messages envoyés entre les agents, qui
définissent les différents protocoles d'interaction.
Notant que :
-
AI : Agent d'Interface
-
AMA: Agent de Modèle de l'Apprenant
-
APA: Agent Pédagogique d'Adaptation
-
AF: Agent de Filtrage
5.1
Scénario 1 : Connexion d'un apprenant
Lorsque un nouveau apprenant demande l'inscription pour
apprendre le cours:
1.
Quand l'apprenant demande l'inscription l'agent d'interface
affiche la page d'inscription (Figure 3.12).
2.
Après l'appui sur le bouton (« Inscription et
connexion ») ; la demande d'inscription sera envoyée à
l'agent d'interface (requête HTTP : POST: nom, password, mode
d'apprentissage)
3.
L'agent d'interface envoie un message KQML à l'agent de
modèle de l'apprenant demandant l'ajout d'un nouveau apprenant (Acheive
: ajoutApprenant(nom, password, mode))
4.
L'agent de modèle de l'apprenant ajout un nouveau
apprenant à la base de données et initialise son niveau avec
faible pour tous les concepts, puis répond l'agent d'interface par (tell
; appreanantAjouter(idApprenant))
Si l'apprenant est déjà inscrit,
1.
Il demande la connexion pour suivre l'apprentissage, la
requête HTTP (POST : nom, password) sera envoyé à l'agent
d'interface.
2.
L'agent d'interface envoie un message à l'agent de
modèle de l'apprenant demandant la vérification de l'apprenant
(Ask-if : apprenantEstInscrit(nom, password))
3.
L'agent de modèle de l'apprenant vérifie puis
répond l'agent d'interface par (reply : apprenatInscrit(idApprenant) ou
apprenantNomInsrit())
Après la connexion la page index du cours sera
affichée. La Figure 3.13 présente les différents
protocoles d'interaction.
Nouveau apprenant
A.I
Apprenant
Achieve
A.I
Apprenant
POST
Ask-if
Figure 3.12: inscription d'un nouveau
apprenant


5.2
Scénario 2 : génération et affichage de
page Index du cours
1.
Suite à une requête de l'apprenant (GET : index,
idApprenant, la requête HTTP de la forme http://url?index
=oui&idapprenant=...)
2.
L'agent d'interface envoie un message KQML à l'agent
pédagogique d'adaptation contenant (Acheive:
génèreIndexePage(Idappreant))
3.
L'agent pédagogique d'adaptation demande pour chaque
concept le niveau de l'apprenant (Ask-about: niveauApprenant(idApprenant,
concepts))
4.
l'agent de modèle de l'apprenant répond par une
liste contenant le niveau de l'apprenant pour chaque concept (reply:
niveauApprenantEst(concpt/niveau))
5.
L'agent pédagogique d'adaptation demande de l'agent de
filtrage de filtrer les documents constituants la page index du cours (Acheive:
filtrerMetaDoc(concepts))
6.
L'agent de filtrage filtre les documents et envoie les adresses
à l'agent pédagogique (tell :
metaDocFiltré(concpts/adresses))
7.
L'agent pédagogique construit la structure de la page et
ses liens et les envoie avec les adresses des documents à l'agent
d'interface comme réponse à la demande de
génération de page index du cours (tell:
indexPageGénérer(structure, adresses))
8.
l'agent d'interface récupère les documents
multimédias selon leurs adresses, puis génère la page et
les liens selon la structure spécifiée par l'agent
pédagogique d'adaptation, puis envoie la page à l'apprenant comme
réponse à la requête GET.
La Figure 3.14(a) présente la page index du cours pour
le niveau faible (activité pédagogique Familiariser) pour tous
les concepts et la Figure 3.14(b) présente la page index du cours pour
le niveau faible (activité pédagogique Familiariser) pour
quelques concepts et moyen (activité pédagogique Clarifier) pour
d'autres concepts.
Le protocole d'interaction dans le cas de
génération et affichage de page index du cours est
présenté dans la Figure 3.15.
(a) page index du cours pour le niveau faible
pour tous les concepts
(b) page index du cours pour le niveau faible
pour quelques concepts et moyen pour d'autres concepts
 Achieve Achieve
 A.I
A.I

S'il y a des concepts bien étudiés, les liens
vers ces concepts sont annotés par : « Concept bien
étudié » ; c'est-à-dire bien étudié
pour toutes les activités pédagogiques. La Figure 3.16
présente la page index du cours dont le niveau est faible pour quelques
concepts et moyen pour d'autres concepts avec des annotations pour les concepts
« Histologie » et « infections ».
5.3
Scénario 3 : affichage de page de concept
1.
L'apprenant demande le concept (GET: concept, idApprenant).
2.
L'agent d'interface envoie un message KQML à l'agent
pédagogique d'adaptation demandant la page de concept (acheive:
génèrePageConcept(concept, idApprenant)).
3.
L'agent pédagogique consulte le modèle du domaine
pour déterminer les concepts prérequis, et demande de l'agent du
modèle de l'apprenant le niveau de l'apprenant sur ces concepts
prérequis (Ask-about: niveauApprenant(idApprenant, concepts)).
4.
L'agent de modèle de l'apprenant répond par une
liste contenant le niveau de l'apprenant pour chaque concept (reply:
niveauApprenantEst(concept/niveau)).
5.
S'il y a des concepts prérequis non
étudiés, il génère une page index des concepts
prérequis de la même façon que celle de la page index du
cours (Figure 3.17).
6.
S'il n'y a pas de concepts prérequis non
étudiés, l'agent pédagogique d'adaptation consulte le
modèle du domaine pour déterminer le type de concept ;
conjonction de sous concepts, disjonction de sous concepts ou il a des concepts
analogue. Dans ces cas, il applique les règles de paragraphe 4.1
ci-dessus. Dans notre démonstration, le modèle du domaine ne
contient que la relation de conjonction.
Achieve
A.I
A.P.A
Tell
A.F
Achieve
Tell
Figure 3.15 : protocole d'interaction dans le
cas de génération et affichage de page index du cours
GET
Apprenan
Figure 3.16 : page index du cours pour le niveau
faible pour quelques concepts et moyen pour d'autres concepts avec des concepts
annotés


 POST
POST

7.
Si le concept est une conjonction, on crée la page de ce
concept, qui contient les liens des concepts de conjonction dont chaque lien
est annoté par « concept étudié » ou « **
», « ** » indique le concept courant, et contient la page du
premier sous concept non étudié. La Figure 3.18 présente
la page de concept « Infections » qui est une conjonction des
concepts « Erysipèle », « Impétigo »
et « Acnés » dont
le concept courant est « Impétigo », le concept «
Erysipèle » est étudié, le concept «
Acnés » est non étudié. Pour construire cette page,
les mêmes messages de cas de concept simple de l'étape 8 sont
envoyés entre les agents.
8.
Si le concept est simple, l'agent pédagogique
d'adaptation consulte le modèle des activités pédagogiques
pour extraire les tâches induites par l'activité
pédagogique suivie, puis envoie un message à l'agent de filtrage
en demandant le filtrage des documents associés aux tâches
déjà spécifiées, (Acheive:
filtrerTâchesDoc(concepts, tâches)).
9.
L'agent de filtrage filtre les documents et envoie les adresses
à l'agent pédagogique (tell : tâchesDocFiltré
(tâches/adresses)).
10.
L'agent pédagogique construit la structure de la page et
ses liens et les envoie avec les adresses des documents à l'agent
d'interface comme réponse à la demande de
génération de page de concept (tell:
conceptPageGénérer(structure, adresses)).
11.
l'agent d'interface récupère les documents
multimédias selon leurs adresses, génère la page et les
liens selon la structure spécifiée par l'agent pédagogique
d'adaptation, puis envoie la page à l'apprenant comme réponse
à la requête GET.
 Tell Tell
Le protocole d'interaction entre agents de scénario de
génération de page de concept est présenté dans la
Figure 3.19.
5.4
Scénario 4 : modification de modèle de l'apprenant
On associe à chaque concept pour chaque activité
pédagogique, un document test d'évaluation sous forme d'un Applet
contenant un ou plusieurs QCM (Questionnaire à choix multiple)
permettant l'évaluation de l'apprenant sur le concept (Figure 3.20).
Le scénario d'évaluation et de mise à
jour de modèle de l'apprenant est le suivant :
1.
L'apprenant après l'étude de concept, il doit
demander le test par clique sur le bouton « Test d'évaluation
» de l'Applet chargé avec la page. La boite de teste s'affiche
(Figure 3.21), après la réponse, il clique sur le bouton «
Valider ».
2.
Si la réponse est considérée suffisante,
l'Applet envoie le résultat d'évaluation à l'agent
d'interface par une requête HTTP, (POST: concept, act-pédag,
idApprenant)
3.
l'agent d'interface formule un message KQML et l'envoie à
l'agent du modèle de l'apprenant pour modifier le niveau de l'apprenant
sur le concept spécifié (Achieve:
modierNiveauApprenant(idApprenant, concept))
4.
l'agent du modèle de l'apprenant modifie le modèle
de l'apprenant et envoie le message (tell :
niveauApprenantModifié(concept, idApprenant)) à l'agent
d'interface.
A.P.A
Tell
A.F
Achieve
Tell
Figure 3.19: protocole d'interaction de
scénario de génération de page de concept
GET
Apprenant
Figure 3.20 : Applettest d'évaluation
associé à chaque concept


Le protocole d'interaction entre agents du scénario de
modification de modèle de l'apprenant est présenté dans la
.
Figure 3.21 : Test d'évaluation
associé au concept Eczéma
Figure 3.22Figure 3.22 : protocole d'interaction
pour le scénario de modification de modèle de l'apprenant
 SGBD SGBD

6
Architecture logicielle de HYDAYA
PourimplémenterlesystèmeHEDAYA,ondoitchoisirunlangagedeprogrammation,unoutild'implémentationdesagentsetdecommunicationentreagents(lacommunicationentreagentsestdétailléedanslasection3.23.2)etdesoutilsdereprésentationdesmodèlesutilisés.irunlangagedeprogrammation,unoutild'implémentationdesagentsetdecommunicationentreagents(lacommunicationentreagentsestdétailléedanslasection)etdesoutilsdereprésentationdesmodèlesutilisés.
6.1
Choix de langage de programmation 6.1 Choix de langage de
programmation
Java fournit la portabilité de code sur plusieurs
plateformes ; un programme Java s'exécute dans un environnement virtuel
standardisé dénommé JVM (Java Virtual Machine)
indépendant de toute plateforme telle que MacOS, Windows, Linux,
Solaris, etc. Le compilateur Java permet de convertir un code source à
une liste d'instructions proche au langage machine appelées pseudo-code,
le JVM contient un interpréteur Java chargé d'exécuter le
pseudo-code sur n'importe quel plateforme. Java fournit la portabilité
de code sur plusieurs plateformes ; un programme Java s'exécute dans un
environnement virtuel standardisé dénommé JVM (Java
Virtual Machine) indépendant de toute plateforme telle que MacOS,
Windows, Linux, Solaris, etc. Le compilateur Java permet de convertir un code
source à une liste d'instructions proche au langage machine
appelées pseudo-code, le JVM contient un interpréteur Java
chargé d'exécuter le pseudo-code sur n'importe quel plateforme.
Java organise la mémoire ; il dispose d'un excellent
mécanisme de la récupération automatique de la
mémoire (garbage collector), qui constitue une fonction du
système d'exécution du langage, restitue spontanément les
zones de mémoire qui ne sont plus utilisés. Java organise la
mémoire ; il dispose d'un excellent mécanisme de la
récupération automatique de la mémoire (garbage
collector), qui constitue une fonction du système d'exécution du
langage, restitue spontanément les zones de mémoire qui ne sont
plus utilisés.
Java est un langage orienté objet, largement
accepté comme standard dans la programmation Internet (applet, servelt,
etc.). Java est un langage orienté objet, largement accepté comme
standard dans la programmation Internet (applet, servelt, etc.).
Beaucoup de technologies reliées aux agents sont
étroitement associées à Java ; comme, par exemple, JADE et
JATLite décrits dans la section suivante. Beaucoup de technologies
reliées aux agents sont étroitement associées à
Java ; comme, par exemple, JADE et JATLite décrits dans la section
suivante.
A.I
AMA
Apprenant
Achieve

6.2
Choix de plateforme agent
Pour mettre en oeuvre l'implémentation multi-agents de
notre système, dans un premier temps, nous avons envisagé les
possibilités offertes par des plateformes multi-agents existantes et
gratuites développées aux universités comme : JATLite
(Java Agent Template, Lite) [Jeon et al 00] est une collection de packages Java
conçus pour fournir un mécanisme de communication et
d'interaction aux programmes distribués à travers l'Internet.
JADE (Java Agent DEvelopment Framework) [Bellifemine et al. 99] est une
plateforme Multi-agents développée en Java par CSELT (Groupe de
recherche de Gruppo Telecom, Italie) qui a comme but la construction des
systèmes Multi-agents et la réalisation d'applications conformes
à la norme FIPA.
Ces plateformes sont très puissantes et
génériques ; mais elles sont relativement trop complexes et
offrent trop de fonctionnalités par rapport à une application
comme la notre.
6.3
Architecture logicielle et outils de développement
Les agents de système HEDAYA sont
implémentés en utilisant le langage de programmation Java. Chaque
agent est défini par son nom, qui indique au module de communication ()
le nom de la machine (ou l'adresse IP) et le port de socket serveur
L'agent d'interface est implémenté en utilisant
le servlet java. Un servlet est un programme java qui s'exécute dans un
serveur Web, et qui peut interagir avec n'importe quel client et peut
accéder le serveur par le biais de requêtes et de réponses,
le serveur Web transmit les requêtes aux servlet et les réponses
aux clients. L'interaction avec l'apprenant (le navigateur Web) se fait par les
requêtes HTTP, par l'intermédiaire du serveur Web ; avec les
autres agents par KQML en utilisant les sockets.
Les bases de données contenant les modèles des
différents apprenants et les attributs des documents multimédias
(méta données de documents multimédias) sont
gérés par le SGBD Interbase, dont l'agent peut connecter la base
de données par le JDBC (Java DataBase Connectivity).
Les documents multimédias sont des documents HTML dans
le Web, ses adresses sont stockées dans la base de documents
multimédias, l'agent d'interface génère la page par
l'agencement des documents et la création des liens (la structure de la
page est définie par l'agent pédagogique d'adaptation, les
adresses des documents sont spécifiées par l'agent de filtrage).
Le modèle du domaine et le modèle des
activités pédagogiques sont exprimés en XML (eXtensible
Markup Language). XML est un langage de balises comme le HTML mais il est
extensible, évolutif. Nous avons choisi XML par ce qu'il ne met aucune
restriction sur le format d'information représentée. Aussi, il
existe plusieurs outils permettant la manipulation des documents XML par un
programme Java.
Dans notre système, on a utilisé BorlandXML pour
la génération des classes Java pour la liaison avec le document
XML à partir de DTD (Document Type Definition). Un DTD est l'ensemble
des règles et des propriétés que le document XML doit les
suivre. Ces règles définissent généralement le nom
et le contenu de chaque balise et le contexte dans lequel elles doivent
exister. La liaison de données permet d'accéder à des
données et de les manipuler, Il consiste de lier des objets Java
à un document XML par une structure de marshalling, qui effectue un
dé-marshalling (lecture) et un marshalling (écriture) de
données. La liaison de données est implémentée en
générant des classes Java pour représenter les contraintes
contenues dans DTD. Vous pouvez ensuite utiliser ces classes pour créer
et lire des documents XML conformes au DTD, ainsi que valider des documents XML
par rapport au DTD.
La figure suivante présente l'architecture logicielle
de système HEDAYA
7
Conclusion Conclusion
Dû à la nature dynamique et modulaire d'agents,
aux avantages qui les fournissent, ainsi son succès dans la vaste
utilisation avec les systèmes hypermédias dans le Web, on a
développé une architecture d'un hypermédia éducatif
adaptatif dynamique basée agents HEDAYA. Cette architecture
définit un système multi-agents couplés avec les
composants des hypermédias adaptatifs dynamiques existant en
introduisant les documents méta-concept et utilisant la technique
d'annotation des liens. La génération de cours adaptative
dynamiquement résulte de l'interaction entre les agents constituant le
système. Dû à la nature dynamique et modulaire d'agents,
aux avantages qui les fournissent, ainsi son succès dans la vaste
utilisation avec les systèmes hypermédias dans le Web, on a
développé une architecture d'un hypermédia éducatif
adaptatif dynamique basée agents HEDAYA. Cette architecture
définit un système multi-agents couplés avec les
composants des hypermédias adaptatifs dynamiques existant en
introduisant les documents méta-concept et utilisant la technique
d'annotation des liens. La génération de cours adaptative
dynamiquement résulte de l'interaction entre les agents constituant le
système.
Cette architecture est démontrée en
implémentant nos agents en utilisant le langage de programmation java,
langage de communication entre agents KQML et le protocole HTTP pour la
communication avec l'apprenant. La démonstration Cette architecture est
démontrée en implémentant nos agents en utilisant le
langage de programmation java, langage de communication entre agents KQML et le
protocole HTTP pour la communication avec l'apprenant. La démonstration
Figure 3.23:Architecture logiciellede HEDAYA
Navigateur Web
Serveur HTTP
Requête HTTP
Agent d'interface (Servlet JAVA)
Documents Multimédias HTML
Agent d'Interface
Agent de Modèle de l'Apprenant
SGBD
Agent Pédagogique .d'Adaptation
Agent de Filtrage
Base de donnéesdes attribues des documents
multimédias
Base de donnéescontenant les modèles des
apprenants
M e s s a g e K Q M L
Modèle des activités
pédagogiques
Modèle du domaine

Conclusion
Dû à la nature dynamique et modulaire d'agents,
aux avantages qui les fournissent, ainsi son succès dans la vaste
utilisation avec les systèmes hypermédias dans le Web, on a
développé une architecture d'un hypermédia éducatif
adaptatif dynamique basée agents HEDAYA. Cette architecture
définit un système multi-agents couplés avec les
composants des hypermédias adaptatifs dynamiques existant en
introduisant les documents méta-concept et utilisant la technique
d'annotation des liens, permettant deux mode d'apprentissage ; libre et
guidé. La génération de cours adaptative dynamiquement
résulte de l'interaction entre les agents constituant le système.
Afin de construire l'intérieur de nos agents, nous
avons identifié un modèle d'architecture interne basée sur
le modèle d'états mentaux BDI. Le lagage de communication entre
agents utilisé est KQML. L'implémentation concrète des
mécanismes de communication entre nos agents s'est faite en ayant
recours à la programmation des sockets en Java.
Cette architecture est démontrée en
implémentant nos agents en utilisant le langage de programmation java,
langage de communication entre agents KQML et le protocole HTTP pour la
communication avec l'apprenant. La démonstration présente un
cours de la dermatologie spécifié pour deux activités
pédagogiques, « familiariser » et « clarifier ».
Le système HEDAYA est un système
générique ; on peut construire avec ce système n'importe
quel cours adaptatif dynamique en spécifiant le modèle du domaine
et les documents multimédias. Pour faciliter cette tâche, comme
perspective, on va définir un système d'acquisition et de
validation de modèle du domaine et de documents multimédias, en
lui associant un agent de recherche de documents sur Internet pour aider les
enseignants dans la tâche de construction de documents
pédagogiques.
Une autre perspective de nos travaux est l'utilisation d'une
infrastructure de communication de plus haut niveau que les sockets que nous
avons utilisés pour l'implémentation de la communication entre
nos agents, qui va permettre, malgré la complexité ajouté
au système, l'interopérabilité de notre système
multi-agents avec tout autre type d'agents utilisant la même
infrastructure et leur offrir une interface de communication connu.
Ce système peut être utilisé comme un
support de cours adaptatif dynamique sur Internet. Il peut être aussi
intégré facilement dans un environnement d'apprentissage comme un
support de cours adaptatif dynamique.
Bibliographie
[Aberg et al 99] Aberg J. and Shahmemehri N., Web Assistants:
Towards an Intelligent and PersonalWeb Shop. Proceedings of the 2nd Workshop on
Adaptive Systems and User Modeling on the WWW, 1999.
[Aïmeur et al. 00] Aïmeur, E., Frasson, C., et
Dufort, H., Cooperative learning strategies for intelligent tutoring systems.
Applied Artificial Intelligence, 2000.
[Albrecht et al 99] Albrecht F., Koch N. and Tiller T.,
SmexWeb: An Adaptive Web-based Hypermedia Teaching System. Journal of
Interactive Learning Research, Special Issue on Intelligent Systems/Tools in
Training and Lifelong Learning. Kommers P. & Mizoguchi R. (Eds.), 2000.
[Ardissono et al 99] Ardissono L. and Goy A., Tailoring the
Interaction with Users in Electronic Shops. In User Modeling Conference, 1999.
[Armstrong et al 95] Armstrong R., Freitag D., Joachims T. and
Mitchell T. WebWatcher: A Learning Apprentice for the World Wide Web. AAAI
Spring Symposium on Information Gathering from Distributed Heterogeneous
Environments. 1995
[Asnicar et al 97] Asnicar F. & Tasso C., ifWeb: A
Prototype of User-Model-Based Intelligent Agent for Document Filtering and
Navigation in the World Wide Web. Proceedings of the Workshop Adaptive Systems
and User Modeling on the World Wide Web. User Modeling Conference'97. 1997.
[Baeijs 1998] Baeijs, C. Fonctionnalité Emergente dans
une Société d'Agents Autonomes. Thèse de Doctorat INP
Grenoble, Novembre 1998.
[Balla 04] Amar Balla, Un modèle
générique d'environnement de développement des
hypermédias adaptatifs et dynamiques générant des
activités pédagogiques, thèse doctorat, Institut national
d'informatique, INI, Alger. Décembre 2004.
[Balla et al 03] Amar Balla, Med Tayeb Laskri, Soraya Laoudi,
HYPERGAP: un hypermédia éducatif dynamique générant
des activités pédagogiques, Document numérique Volume 7,
pages 39 à 47, n° 1-2/2003
[Bailey 02] Christopher Paul Bailey, An agent-based framework
to support adaptive hypermedia. PhD thesis of Southampton university, United
Kingdom. December 2002.
[Barceinasatal98]AdolfoBarceinas,J.AlfredoSánchezandJohnSchnase,MICK:AKQMLInter-AgentCommunicationFrameworkinaDigitalLibrary
[Baron 94] Baron, M., EIAO, quelques repères.
Technologie de l'information, culture et société, n°65,
Editions Harmattan, 1994
[Bauer et al 00] B. Bauer, J. P. Muller, and J. Odell. An
extension of UML by protocols for multiagent interaction. In International
Conference on MultiAgent Systems (ICMAS'00), Boston, Massachussetts, july 2000.
[Beggas 04] Mounir Beggas, Modeling by a multi agent system an
educational adaptive dynamic hypermedia system, Proceedings of the
international arab conference on information technology ACIT 2004, Constantine,
Algeria.
[Behaz et al 04] Behaz a. et Djoudi M., Modélisation et
adaptation des documents pédagogiques hypermédias en enseignement
à distance, Proceedings de 4ème séminaire national en
informatique - Biskra, SNIB'04, 2004
[Bellifemine et al. 99] Bellifemine, F., Rimassa, G. &
Poggi, A. (1999). JADE - A FIPA-Compliant Agent Framework. Proceedings of the
Forth International Conference and Exhibition on the Practical Application of
Intelligent Agents and Multi-Agents (PAAM '99), 1999.
[Bergia 01] Loris Bergia, Conception et réalisation
d'une plate-forme multi-agents pour l'apprentissage et l'enseignement à
distance, Mémoire présenté en vue d'obtenir le
diplôme d'Ingénieur CNAM, Laboratoire Leibniz-IMAG, Grenoble,
France, Février 2001
[Bertrand 01] Claude Bertrand; les enjeux pédagogiques
des TICE : questions pour un usage raisonné ; IUFM Aix-Marseille,
Septembre 2001.
[Bourdon 2001] François Bourdon, Systèmes
multi-agents ; cours sur les systèmes multi-agents, université de
Caen, 2001
[Brown et al. 98] Brown, S., Santos, E., et Banks, S., Utility
theory-based user models for intelligent interface agents. In Canadian
Conference on AI, pages 1998.
[Bruillard et al 94] Bruillard, E. et Vivet M., Concevoir des
EIAO pour des situations scolaires, approche méthodologique. Didactique
et Intelligence Artificielle. La Pensée Sauvage, éditions 1994.
[Brusilovsky et al 95] P. Brusilovsky and L. Pestin, Visual
annotation of link in adaptive hypermedia, CHI 95, Denver, United States, 1995
[Brusilovsky, 96] Peter Brusilovsky, Methods and Techniques of
Adaptive Hypermedia. International Journal of User Modeling and User-Adapted
Interaction. Kluwer Academic Publishers, Vol 6, 2-3, 87-129. 1996
[Brusilovsky et al 96] Brusilovsky P., Schwarz E. and Weber
G., A Tool for Developing Adaptive Electronic Textbooks on WWW, Proceeding of
WebNet'96, World Conference of the Web Society, 64-69. 1996
[Brusilovsky 97] Peter Brusilovsky, Efficient Techniques for
Adaptive Hypermedia. Intelligent Hypertext: Advanced Techniques for the World
Wide Web. Nicholas C. & Mayfield J. (Eds.), Springer Verlag, 12-30. 1997
[Brusilovsky 98] Peter Brusilovsky, Methods and techniques of
adaptive hypermedia. In: P. Brusilovsky, A. Kobsa and J. Vassileva (eds.):
Adaptive Hypertext and Hypermedia. Dordrecht: Kluwer Academic Publishers. 1998.
[Brusilovsky 99] Peter Brusilovsky, Adaptive Hypermedia: From
Intelligent Tutoring Systems to Web-Based Education, Carnegie Technology
Education and HCI Institute, Carnegie Mellon University, 1999.
[Brusilovsky 03] Peter Brusilovsky, Developing adaptive
educational hypermedia systems: from design models to authoring tools, School
of Information Sciences University of Pittsburgh Pittsburgh PA 15260, USA 2003
[Burg 00] Burg, B., Toward the deployment of an open agent
world. In JFIADSMA'00, 2000.
[Chaib 99] Brahim Chaib-draa, Agents et systèmes
multiagents, Notes de cours, Département d'informatique, Faculté
des sciences et de gnie, Université Laval, Québec, Novembre 1999
[Capuano et al 01] Nicola Capuano, Massimo De Santo, Marco
Marsella, Mario Molinara, Saverio Salerno, A Multi-Agent Architecture for
Intelligent Tutoring, CRMPA, Salerno, Italy ; DIIIE - Università di
Salerno, Italy 2001
[Carro et al 99] Rosa María Carro, Estrella Pulido,
Pilar Rodríguez , Designing Adaptive Web-based Courses with TANGOW. 7th
International Conference on Computers in Education, ICCE'99. November 4 - 7,
1999.
[Chen et al 03] Bo Chen and Samira Sadaoui, A Generic Formal
Framework for Multi-agent Interaction Protocols, Department of Computer
Science, University of Regina 3737 Waskana Parkway, Regina SK, Canada, S4S 0A2,
2003
[Danius et al 01] Danius T. Michaelides, David E. Millard,
Mark J. Weal, David De Roure Auld Leaky: A Contextual Open Hypermedia Link
Server. Intelligence, Agents, Multimedia, Dept. of Electronics and Computer
Science, University of Southampton, U. K. 2001
[De Bra et al 98] De Bra P. & Calvi L. AHA: A Generic
Adaptive Hypermedia System. Proceeding of the 2nd Workshop on Adaptive
Hypertext and Hypermedia, HYPERTEXT'98, 1998.
[De Bra 99] De Bra P. Design Issues in Adaptive Web-Site
Development. Proceedings of the 2nd Workshop on Adaptive Systems and User
Modeling on the WWW. 1999
[Delestre 00] Nicolas Deletstre, METADYNE, un
hypermédia adaptatif dynamique pour l'enseignement, Thèse
doctorat de l'université de Rouen, janvier 2000
[Encarnaçao 97] Encarnaçao M., Concept and
Realization of Intelligent Support in Interactive Graphics Applications. Ph.D.
Thesis.
[Erceau 91] Erceau, J., Feber, J. L'Intelligence Artificielle
Distribuée. La recherche, Volume 22, juin 1991.
[Fenton et al 98] : Fenton-Kerr, T., Clark, S., Chenzy, G.,
Koppi, T., et Chaloipka, M., Multi-agent design in flexible learning
environments. In ASCILITE 98, 1998.
[Ferber 95] Jacques Ferber, Les systèmes mutli-agents,
vers une intelligence collective, interedition Paris 1995.
[Finin et al. 95] Finin, T., Labrou, Y., and Mayfield, J.
1995. KQML as an agent communication language. Technical Report. Computer
Science Department. Maryland Baltimore County University. Baltimore, MD, 1995.
[Frasson et al. 97] Frasson, C., Mengelle, T., et Aimeur, E.,
Using pedagogical agents in a multi-strategic intelligent tutoring system. In
Proceedings of the AI-ED '97 Workshop on Pedagogical Agents, 1997.
[Garlatti et al 99] Garlatti S., Iksal S. and Kervella P.,
Adaptive On-line Information System by Means of a Task Model and Spatial Views.
Second Workshop on Adaptive Systems and User Modeling on the WWW, 1999.
[Gleizes et al. 00] Gleizes, M. P. et Glize, P., ABROSE: Des
systèemes multiagents pour le courtage adaptatif. In JFIADSMA'00, 2000.
[Höök 98] Höök K., Evaluating the Utility
and Usability of an Adaptive Hypermedia System. Knowledge-Based Systems,
Elsevier, 10, 311-319. 1998.
[Hospers et al 03] M. Hospers, E. Kroezen, A. Nijholt, R. op
den Akker & D. Heylen, Developing a Generic Agent-based Intelligent
Tutoring System, Center of Telematics and Information Technology University of
Twente, Enschede, the Netherlands, 2003.
[Inverno et al 98] Mark d'Inverno, David Kinny, and Michael
Luck. Interaction protocols in agentis. In Third International Conference on
Multi-Agent Systems (ICMAS98), 1998.
[Jarras 02] Imed Jarras et Brahim Chaib-Draa, Aperçu
sur les systèmes multi-agents, Série scientifique, 2002s-67.
Montréal, Juillet 2002.
[Jennings et al 98] Jennings, N. R., Wooldridge M.,
Applications of Intelligent Agents in Agent Technology: Foundations,
Applications, and Markets (eds. N. R. Jennings and M. Wooldridge)
Springer-Verlag : Berlin, Germany. 1998.
[Jeon et al 00] Jeon, H., Petrie, C. & Cutkosky, M. R.
JATLite: A Java Agent Infrastructure with Message Routing. IEEE Internet
Computing, Mars 2000.
[Joël 03] Joël Quinqueton, Fondements des
Systèmes Multi-Agents, LIRMM, EMA option Informatique, Janvier 2003.
[Koch 00] Nora Parcus de Koch, Software Engineering for
Adaptive Hypermedia Systems, Reference Model, Modeling Techniques and
Development Process. PhD thesis, Munich university, Germany. October 2000.
[Lafifi 00] Yacine Lafifi, Architecture d'un hypermédia
éducatif et coopératif, mémoire de magister de
l'université de Annaba, novembre 2000.
[Laoudi 02] Soraya Laoudi, Structure d'un hypermédia
éducatif générant des activités
pédagogiques, mémoire de magister, Institut National
d'Informatique INI, 2002. Algérie.
[Lourdeaux 01] Lourdeaux, D., Réalité Virtuelle
et Formation : Conception d'Environnements Virtuels Pédagogiques.
Thèse doctorat, Ecole des Mines de Paris, 2001.
[Malone 94] T. W. Malone. Organizing information processing
systems : parallels between human organizations and computer systems. In W. W.
Zachary and S. P. Robertson, editors, Cognition, Computation and Cooperation,
pages 56_83. Ablex, 1990.
[Mathé et al 1996]. Mathé N. and Chen J..
User-centered Indexing for Adaptive Information Access. User Modeling and
User-Adapted Interaction, 6 (2-3), 225-261. 1996
[Mbala 03] Aloys Mbala Hikolo, Analyse, conception,
spécification et développement d'un système multi-agents
pour le soutien des activités en formation à distance,
thèse doctorat de l'Université de Franche-Comté, France,
2003
[Mladenic 00] Mladenic D.
http://www.cs.cmu.edu/afs/cs/project/theo4/text/-learning/www/pww/index.html
[Merlet 94] Jean François Merlet, Elaboration d'une
méthode de conception orientée objet de systèmes de
formation multimédia : COSYF ; thèse de doctorat d'informatique
de l'université des sciences sociales Toulouse I, Avril 1994.
[Odell et al 00] Odell J., Van Dyke P. and Bauer B., Extending
UML for Agents. Proceedings of the Agent-Oriented Information Systems. Workshop
at the 17th National conference on Artificial Intelligence, Gerd Wagner, Yves
Lesperance, and Eric Yu eds., Austin, TX, 2000.
[Parunak 96] H. V. D. Parunak. Applications of distributed
artificial intelligence in industry. In G. M. P. O'Hare and N. R. Jennings,
editors, Foundations of Distributed AI. John Wiley & Sons : Chichester,
England, 1996.
[Pesty et al 01] Sylvie Pesty, Carine Webber et Nicolas
Balacheff, Baghera : une architecture multi-agents pour l'apprentissage humain.
Laboratoire Leibniz - IMAG 2001.
[Pietrie, 03] Pietrie, C.
http://cdr.stanford.edu/ProcessLink/kqmlproposed.html.
[Querrec 2002] Ronan Querrec, Les Systèmes Multi-Agents
pour les Environnements Virtuels de Formation, Application à la
sécurité civile, thèse de doctorat Informatique,
Laboratoire d'Informatique Industrielle (LI2/ENIB), Université de
Bretagne Occidentale. Octobre 2002
[Ranwez 00] Sylvie Chabert-Ranwez, Composition Automatique de
Documents Hypermédia Adaptatifs à partir d'Ontologies et de
Requêtes Intentionnelles de l'Utilisateur. Thèse doctorat de
l'université de Montpellier II, 2000
[Rao et al 95] Rao, A, Georgeff, M., BDI Agents : From Theory
to Practice. In Proceedings of the First International Conference on
Multi-Agents Systems (ICMAS-95), San Francisco, USA, June, 1995.
[Recker 95] M. Recker, Cognitive Media Types for Multimedia
Information Access, Journal of Education Multimedia and Hypermedia, 1995.
[Richard 99] Richard, L., Un système Multi-agents pour
la modélisation d'Environnements Interactifs d'Apprentissage avec
Ordinateur basés sur la simulation. Application à la formation de
personnels de maintenance aéronautique. Thèse doctorat,
Université de Paul Sabatier, Toulouse III. 1999.
[Silveira et al 02] Ricardo Azambuja Silveira and Rosa Maria
Vicari, Improving interactivity in e-learning with JADE - Java Agent framework
for Distance learning Environments. International Conference on Engineering
Education, August 18-21, 2002, Manchester, U.K.
[Vassileva 97] Vassileva J., Dynamic Course Generation on the
WWW. Proceedings of Workshop Intelligent Educational Systems on the World Wide
Web in AI-ED'97: Eighth World Conference on Artificial Intelligence in
Education. 1997
[Wu 02] Hongjing Wu, A Reference Architecture for Adaptive
Hypermedia Applications ; PhD thesis, Eindhoven, September 2002
[Zeghida 03] Djamel Zeguida, Une architecture multi-agents
d'un système d'apprentissage avec compagnons, memoire de magister,
Université de Annaba, 2003
[Zouaq et al. 00] Zouaq A., Frasson C., et Rouane K. The
explanation agent. In International Conference in Intelligent Tutoring Systems,
Lecture Notes in Computer Science, 2000
présente un cours de la dermatologie
spécifié pour deux activités pédagogiques «
Familiariser » et « Clarifier ».
| 

