3.3 Prétraitement des données
Le prétraitement des données se décompose en
deux phases principales : une phase de nettoyage des données et une
phase de transformation.
3.3.1 Nettoyage des données
Le nettoyage des données est une étape cruciale
dans le processus du WUM en raison du volume important des données
enregistrées dans les fichiers Log Web. En effet, la dimension de ces
fichiers dans les sites Web et les portails Web très populaires peut
atteindre des centaines de géga-octets par heure. L'étape du
nettoyage consiste à filtrer les données inutiles à
travers la suppression des requêtes ne faisant pas l'objet de l'analyse
et celle provenant des robots Web. La suppression du premier type de
requêtes dépend selon [Tan, 03] de l'intention de l'analyste. En
effet, si son objectif est de trouver les failles de la structure du site Web
ou d'offrir des liens dynamiques personnalisés aux visiteurs du site
Web, la suppression des requêtes auxiliaires comme celles pour les images
ou les fichiers multimédia est possible. Par contre, quand l'objectif
est le »Web pre-fetching* », il ne faut pas supprimer ces
requêtes puisque dans certains cas les images ne sont pas incluses dans
les fichiers HTML mais accessibles à travers des liens, ainsi
l'affichage de ces images indique une action de l'utilisateur.
La suppression du second type de requêtes i.e. les
entrées dans le fichier Log produites par les robots Web (WR) permet
également de supprimer les sessions non intéressantes. En effet,
les WRs suivent automatiquement tous les liens d'une page Web. Il en
résulte que le nombre de demandes d'un WR dépasse en
général le
nombre de demandes d'un utilisateur normal. [Tan, 03] a
utilisé trois heuristiques pour identifier les requêtes et les
visites issues des WRs :
1. Identifier les adresses IPs qui ont formulé une
requête à la page »robots .txt».
2. Utiliser des listes des »User agents» connus comme
étant des WRs.
3. Utiliser un seuil pour »la vitesse de
navigation» BS (Browsing Speed), qui représente le rapport entre le
nombre de pages consultées pendant une visite de l'utilisateur et la
durée de la visite. Si BS est supérieure à deux pages par
seconde et la visite dépasse 15 pages, alors la visite a
été initiée par un WR.
3.3.2 Transformation des données
Cette phase regroupe plusieurs tâches telles que
l'identification des utilisateurs et des sessions et l'identification des
visites.
Identification des utilisateurs et des sessions
Plusieurs méthodes ont été proposées
pour identifier les internautes:
L'adresse IP Les adresses IP toujours disponibles et ne
nécessitant au-
cun traitement préalable peuvent être
utilisées pour identifier les internautes. Cependant, leur utilisation
présente principalement deux limites. D'une part, les internautes
utilisant un serveur Proxy sont identifiés par l'unique adresse IP de ce
serveur. Ainsi, le site visité ne peut déceler s'il s'agit d'un
ou de plusieurs visiteurs. D'autre part, l'attribution dynamique des adresses
IPs ne permet une identification valable que pour une seule session
ininterrompue i.e. si l'internaute interrompt sa visite en se
déconnectant un bref instant, son adresse IP aura changé bien
qu'il s'agit toujours du même utilisateur.
Les Cookies (Client Side Storage) Ces fichiers peuvent contenir
des
information telles que la date et l'heure de la visite, la
page visitée, un code d'identification du client, .. etc. Chaque fois
que l'utilisateur introduit une URL, le navigateur parcourt les cookies. Si
l'un d'entre eux contient cette URL, la partie du cookie contenant les
données associées est transférée conjointement
à la requête afin de permettre au serveur d'identifier la
provenance de cette requête. Cette méthode présente
plusieurs avantages. En effet, les cookies permettent une identification
s'étalant sur plusieurs sessions. Ils permettent également de
stocker plus qu'un simple code d'identification et de collecter et
d'enregistrer des informations directement exploitables par le serveur (comme
le mot de passe); Cependant, l'identification par cookies présente des
inconvénients. D'une part, les
cookies identifient la machine, et non
l'utilisateur1, d'autre part, ils nécessitent l'acceptation
de l'utilisateur qui peut à tout moment désactiver leur
chargement. Deux autres problèmes sont également à
considérer. Le premier est celui des firewalls qui peuvent interdire
l'écriture de cookies. Le second est relié au nombre
limité des cookies. En effet, un client ne peut pas avoir plus de 300
cookies sur son disque et un serveur ne peut créer que 20 cookies
maximum chez le client.
Le Mot de passe Pour qu'un serveur puisse identifier un visiteur
de
manière certaine, l'internaute doit s'identifier
lui-même à l'aide d'un pseudonyme (Login) et un mot de passe
(Password). Ainsi, le serveur est sûr de l'identité de son
visiteur. Cette technique permet d'identifier les internautes de façon
permanente et fiable mais elle requiert la participation de l'utilisateur et ne
peut être réalisée à son insu. Le serveur devra donc
attendre que son visiteur s'enregistre et ne pourra profiter des requêtes
effectuées en dehors de l'identification. Pour remédier à
cet inconvénient, les mots de passe et les pseudonymes sont souvent
enregistrés dans un cookie. L'indentification établie lors d'une
session ultérieure portera alors sur la machine et non plus sur
l'utilisateur2.
L'identifiant de session Les identifiants de session permettent
à un site
entièrement dynamique d'identifier les internautes
individuellement. Ils reposent sur la technologie PHP. Cette technique permet
d'attacher un identifiant à chacun des liens hypertextes présents
sur une page. Lors de la première requête émise, le serveur
attribue arbitrairement à cette requête un identifiant de session,
la réponse du serveur sera une page préparée
dynamiquement. Le serveur peut ainsi insérer l'identifiant de session
dans tous les liens hypertextes de cette page. Lorsque l'utilisateur clique sur
l'un de ces liens, sa requête contiendra automatiquement l'identifiant
qui lui a été attribué au départ. Cette technique
est très fiable mais limite l'identification du visiteur à une
seule session.
D'autres méthodes ont été
proposées afin de résoudre le problème de l'identification
de l'utilisateur. Dans [Coo, 99], la méthode proposée combine
l'utilisation de la topologie du site et des informations contenues dans le
referrer. Si une requête de page provient de la même adresse IP que
les requêtes précédentes sans qu'il y'ait d'hyperliens
directs entre les pages demandées, alors l'utilisateur n'est plus le
même. Cependant cette méthode n'identifie pas complètement
l'utilisateur. [Sch, 01] emploie une technique différente pour
identifier l'utilisateur. Cette technique consiste à inclure, pour
chaque utilisateur, un identifiant unique généré par le
serveur Web dans les URLs des pages Web du site. Cependant, cette technique
nécessite l'intervention de l'internaute qui doit créer un
signet, qui inclut
1Si plusieurs personnes utilisent un même
ordinateur, la pertinence du cookie est fortement réduite. De
même, si une personne emploie plusieurs ordinateurs, le site est
incapable de reconnaître l'utilisateur. Le cookie est donc
inadapté à la mobilité des internautes.
2Un utilisateur différent peut cependant
accéder au site sous la même identité.
l'identifiant comme une partie de l'URL dans l'une des pages afin
d'identifier l'utilisateur s'il revient au site.
Le tableau ci-dessous proposé par [Gav, 02]
présente une comparaison entre les principales techniques
d'identification des internautes.
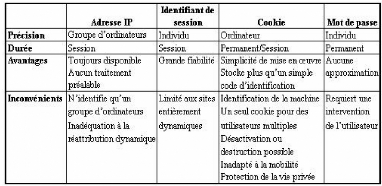
TAB. 3.2 : Principales techniques d'identification des
internautes Identification des visites
Une fois l'utilisateur identifié par l'une de
méthodes décrites ci-dessus, il est possible de reconstituer sa
session en regroupant les requêtes contenues dans les fichiers Log et
émises par cet utilisateur. Selon [Spi, 99], les méthodes
d'identification des sessions des utilisateurs peuvent être
classifiées en méthodes basées sur le contexte (exemple :
accès à des pages de types spécifiques) et méthodes
basées sur le temps (exemple : limite seuil de temps de consultation
d'une page). Les méthodes basées sur le temps sont les plus
couramment utilisées. Elles consistent à considérer que
l'ensemble des pages visitées par un utilisateur constitue une visite
unique si les pages sont consultées pendant un intervalle de temps ne
dépassant pas un certain seuil temporel3. Ce »temps de
vue de pages4» varie de 25,5 minutes [Cat, 95] à 24
heures [Yan, 96]. Le temps de vue de pages couramment utilisé est de 30
minutes [Coo, 99]. Cependant, l'utilisateur peut passer plus de trente minutes
à lire la même page ou quitter son poste pendant un moment et
retourner pour consulter la même page. De plus, l'utilisateur du cache
peut donner l'impression que la session est finie alors qu'il consulte les
pages enregistrées par le cache.
3Cet intervalle de temps correspond à une
absence de requêtes, on parle de seuil temporel d'inactivité.
4Page viewing time, terme introduit par Shahabi [Sha,
97].
Selon les critères empiriques de Kimball [Kim, 00], une
visite est caractérisée par une série d'enregistrements
séquentiellement ordonnés, ayant la même adresse IP et le
même nom d'utilisateur, ne présentant pas de rupture de
séquence de plus d'une certaine durée.
Identification des épisodes
L'objectif de l'identification des épisodes est de
créer des classes de référence significatives pour chaque
utilisateur. Selon [Coo, 97], les épisodes dépendent du
comportement de navigation de l'utilisateur. En se basant sur cette
hypothèse, les auteurs proposent de classifier les pages d'un site
en:
- Pages auxiliaires : contiennent les hyperliens primaires aux
autres pages Web et utilisées pour la navigation.
- Pages de contenu: contiennent des informations
intéressantes aux utilisateurs.
- Pages hybrides : contiennent les deux types d'information.
Cette classification basée sur le contexte
dépend de l'utilisateur. En effet, une page de navigation (ou
auxiliaire) pour un utilisateur peut être une page de contenu pour un
autre. Suivant cette classification, il existe trois méthodes
d'identification des épisodes : la référence-avant
maximale (MF-Maximal Forward reference), le typage des pages et la longueur de
la référence.
Selon la méthode »Référence-avant
maximale»5 , proposée par [Chen, 96], un épisode
est défini par un ensemble de pages visitées par un utilisateur
à partir de la première page enregistrée dans le fichier
Log jusqu'à l'apparition de la première référence
en arrière6. Ainsi, cette méthode ne considère
pas une deuxième fois les pages qui ont été
traversées par l'utilisateur lors de sa visite, ce qui ne convient pas
à certaines classes d'applications où il est important de
prédire les types de référence en arrière. D'autre
part, le Web caching empêche les références en
arrière d'être enregistrées dans les fichiers Log.
La méthode »typage de pages» [Coo, 99] est
semblable à la méthode »longueur de
référence». La différence entre les deux
méthodes consiste dans l'algorithme de classification basé sur
les données d'usage pour la méthode longueur de
référence et sur le contenu de la page pour la méthode
typage de page.
| 

