Chapitre 3
Processus du Web Usage Mining
Le processus du Web Usage Mining (WUM) est communément
divisé en trois étapes principales : prétraitement des
données, fouille de données et analyse des résultats. Une
étape préalable consiste à collecter les données du
Web à analyser. Nous présentons dans ce chapitre chacune de ces
étapes ainsi qu'une description détaillée des
données et traitements nécessaires à sa
réalisation.
3.1 Processus du Web Usage Mining
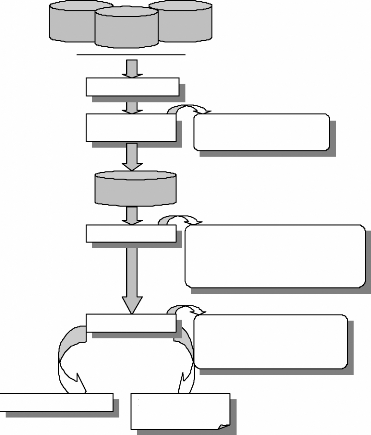
Le WUM (fig. 3.1) consiste en »l'application des
techniques de fouille des données pour découvrir des patrons
d'utilisation à partir des données du Web dans le but de mieux
comprendre et servir les besoins des applications Web» [Coo, 00]. La
première étape dans le processus de WUM, une fois les
données collectées, est le prétraitement des fichiers Logs
qui consiste à nettoyer et transformer les données. La
deuxième étape est la fouille des données permettant de
découvrir des règles d'association, un enchainement de pages Web
apparaissant souvent dans les visites et des »clusters»
d'utilisateurs ayant des comportements similaires en terme de contenu
visité. L'étape d'analyse et d'interprétation clôt
le processus du WUM. Elle nécessite le recours à un ensemble
d'outils pour ne garder que les résultats les plus pertinents.
Serverside data
Intermediary
data
Client-side
data
Collecte des données
Prétraitement des
données
- Nettoyage des données
- Transformation des données
Data Webhouse
Fouille des données
- Méthodes statistiques unidimensionnelles -
Méthodes statistiques multidimensionnelles
- Méthodes d'association
- Méthodes basées sur l'IA
Analyse
- Visualisation
- OLAP
- Bases des données relationnelles - Agents
intelligents
Personnalisation du Web
Rapport d'évaluation
du Web
FIG. 3.1 : Processus du Web Usage Mining
3.2 Collecte des données
La première phase dans le processus du WUM consiste
à collecter les données du Web à analyser. Les deux
sources principales des données collectées sont les
données enregistrées au niveau du serveur et les données
enregistrées au niveau du client. Une autre source consiste aux
données enregistrées au niveau du serveur Proxy,
intermédiaire dans la communication client-serveur.
3.2.1 Données enregistrées au niveau du serveur
Chaque demande d'affichage d'une page Web de la part d'un
utilisateur, peut générer plusieurs requêtes. Des
informations sur ces requêtes (notamment les noms des ressources
demandées et les réponses du serveur Web) sont stockées
dans les fichiers Log du serveur Web. L'enregistrement des données dans
les Logs du serveur (server-side Log files) permet d'identifier l'ensemble
d'utilisateurs accédant au site Web. De plus, les Logs du serveur
fournissent des données sur le contenu, des informations sur la
structure et des méta-informations sur les pages Web (taille du fichier,
date de la dernière modification) [Sri, 00]. Cependant, les fichiers Log
des serveurs Web présentent des problèmes majeurs comme
signalé dans le chapitre précédent.
3.2.2 Données enregistrées au niveau du client
Les données sont collectées au niveau du poste
client à travers des agents implémentés en Java ou en Java
script. Ces agents sont incorporés dans les pages Web (sous forme
d'appliquettes java, par exemple) et utilisés pour une collecte directe
des informations à partir du poste client (exemples d'informations : le
temps d'accès et d'abandon du site, l'historique de navigation) .Une
autre technique de collecte des données consiste à utiliser une
version modifiée du navigateur [Tau, 97]. Cette technique permet
d'enregistrer les pages Web visitées par un utilisateur ainsi que le
temps d'accès et le temps de réponse et les envoyer au serveur.
La première méthode permet de collecter des données sur un
utilisateur navigant sur un seul site Web. Par contre, un browser
modifié permet la collecte des données sur un utilisateur
navigant sur plusieurs sites Web. Le problème qui se pose dans le second
cas est comment convaincre les internautes d'utiliser ce navigateur
modifié dans leurs navigations sachant qu'il peut être
considéré comme une menace de leur vie privée [Sri, 00].
Les informations enregistrées au niveau du poste client sont plus
fiables que les informations enregistrées au niveau du serveur
puisqu'elles permettent de résoudre le problème du caching et
l'identification des sessions [Pie, 03].
3.2.3 Données enregistrées au niveau du Proxy
Le serveur Proxy joue le rôle d'intermédiaire
entre des clients Web et des serveurs Web. C'est également un vaste
espace disque servant au stockage des pages Web consultées par les
utilisateurs (Web-cache server). En effet, pour toute requête
émise sur une page, le Proxy, après consultation de son disque
local, transmet la requête au serveur Web si le document n'est pas
disponible à son niveau. Une fois l'information retournée par le
serveur, le Proxy en effectue une copie locale sur son disque puis la transmet
à l'initiateur de la requête. Le serveur Proxy garde la trace de
toutes les communications établies dans des fichiers Logs
semblables à ceux des serveurs Web. Ces traces peuvent
révéler les requêtes HTTP émises par plusieurs
clients vers plusieurs serveurs Web et servir ainsi de source de données
pour caractériser le comportement de navigation d'un groupe anonyme
d'utilisateurs partageant un même serveur Proxy [Sri, 00]. Cependant, les
mêmes problèmes cités précédemment
(problème du caching et d'allocation des adresses IP) sont
présents au niveau du Proxy. Le tableau suivant présente les
différents niveaux de collecte des données résultant de la
navigation d'un ou de plusieurs utilisateurs sur un ou plusieurs sites.

TAB. 3.1 : Niveaux de collecte des données
| 

