CHAPITRE 4
zone lorsqu'ils planifient les prochaines trajectoires puisque
la fonction fitness pénalisera ces régions déjà
visitées.
Étant donné que les robots ne sont pas
conscients de la présence des autres robots, ils n'échangent pas
de messages entre eux par rapport à leurs chemins planifiés ou
des régions prévues à être visitées dans le
futur. Tout ce qu'ils échangent c'est la position des obstacles
détectés et les zones déjà visitées
auparavant. De ce fait, il arrive que plusieurs robots décident de se
diriger vers la même direction puisque cela maximise leur valeur de
fitness. Ce comportement est observé au départ de
l'expérience lorsqu'ils choisissent tous le chemin diagonal maximisant
la zone à observer, ou parfois au milieu de l'expérience tel
qu'on peut le voir sur la figure 4.1. Cependant, nous observons que dans
l'ensemble, le système arrive quand même à faire disperser
les robots dans des régions séparées, ce qui a pour effet
d'accélérer le temps d'exploration de la zone comparé aux
scénarios où on n'utilise qu'un seul robot.
Afin de montrer l'adaptabilité de l'approche à
des environnements beaucoup plus larges, nous avons effectué une autre
expérience en utilisant une carte inspirée d'une usine ayant une
superficie égale à 30x50 mètres. La figure 4.2 montre un
résultat intermédiaire enregistré pendant
l'exécution. Cette expérience a été
répétée plusieurs fois en changeant le nombre de robots,
elle a montré la capacité de l'approche à les pousser
à explorer la zone entière même en cas de forte
densité d'obstacles ou de l'augmentation de la superficie de
l'environnement.
Par ailleurs, cette série d'expériences a permis
aussi d'apprécier la facilité d'utilisation de notre simulateur,
puisqu'il s'adapte automatiquement à l'ajout de nouveaux
scénarios et au changement du nombre de robots. L'utilisateur n'aura
qu'à effectuer un paramétrage de
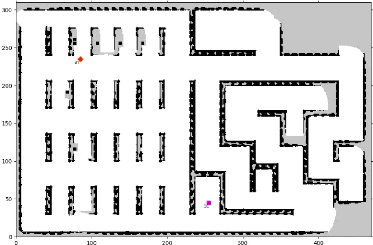
FIGURE 4.2 - Progression visuelle d'un scénario à
grande échelle en utilisant la méthode xBOA avec 2 robots
109
l'expérience sans se soucier des mécanismes
internes de détection des obstacles, de mise à jour de la carte
globale, ou de l'évitement des collisions entre les robots. Ce genre de
tâches sont souvent un frein à beaucoup de chercheurs venant de
domaines différents puisqu'elles nécessitent d'avoir une bonne
compréhension des problématiques de navigation robotique et du
fonctionnement des grilles d'occupation.
4.4 Expérience 2 : Comparaison entre les
stratégies d'ex-ploration à court terme et à long terme
Cette expérience vise à comparer deux
stratégies d'exploration. La première consiste à planifier
la mission à long terme en sélectionnant plusieurs points de
destination au départ de l'exécution; calculer un chemin pour
visiter ces points selon leur ordre de sélection; puis
répéter l'opération après avoir visité tous
ces points. Quant à la deuxième stratégie, elle consiste
à faire une planification à court terme en ne
sélectionnant qu'un seul point à la fois; le robot devra donc
attendre jusqu'à avoir visité sa destination actuelle avant de
choisir la prochaine.
La figure 4.3 montre un exemple d'exécution des deux
stratégies en utilisant la méthode xBOA. Cette visualisation
étape par étape montre que la stratégie à long
terme est moins efficace que la stratégie à court terme lorsque
l'environnement est inconnu à l'avance. En effet, la planification
à long terme de plusieurs points de destination au début de la
mission se base sur des informations très limitées puisque le
robot n'a aucune connaissance à priori de l'emplacement des murs et des
obstacles avant de les avoir détectés grâce à son
LIDAR. Le processus d'optimisation choisit donc ces destinations en ne tenant
compte que de l'information de distance à vue d'oiseau par rapport au
robot. Cependant, lorsque celui-ci commence à se déplacer pour
visiter ces points, il met à jour sa carte en collectant les
informations des positions des obstacles et des différents chemins
possibles. Toutefois, il n'utilisera ces informations que lors de la prochaine
phase de sélection après avoir visité tous les points
planifiés. En d'autres termes : le robot continuera donc à
visiter les destinations prévues initialement sans profiter de l'apport
des nouvelles informations récoltées en chemin, et tombera
souvent dans une redondance poussant le robot à revisiter une zone
déjà explorée auparavant.
Pour illustrer ce problème de redondance, la figure 4.3
montre un exemple où la visite du 3ème point en utilisant la
stratégie à long terme n'a apporté aucun gain, et ceci
à cause du manque de visibilité lors de la phase de
sélection. Alors que la stratégie à court terme a permis
d'éviter cette redondance en utilisant les informations
récoltées lors de la visite du 1er et 2ème point pour
pousser le robot à visiter une nouvelle zone.
Dans la stratégie à court terme, le robot ne
sélectionne qu'un seul point de destination. Il se déplacera pour
le visiter tout en mettant à jour la carte de l'environnement puis
resé-lectionnera un nouveau point en utilisant les nouvelles
informations récoltées en chemin. La qualité du choix est
donc meilleure puisqu'il élimine les destinations n'apportant aucun gain
supplémentaire ou qui sont trop coûteuses par rapport aux gains
qu'ils pourront apporter. Cette stratégie est aussi avantageuse dans le
cas des environnements dynamiques où les positions des obstacles
changent à cause de portes ouvertes et fermées par exemple,
110
| 

