Couplage microfinance et micro assurance pour l’optimisation de la gestion du risque des crédits à Bukavu.par Audace Ntwali Université Libre des Pays des Grands Lacs de Bukavu (ULPGL) - Licence en Sciences économiques et de Gestion - Option : Gestion Financière 2016 |

Tableau 2.2 : Résumé des variables du premier modèle
Source : Notre confection des données Primaires D. Spécification du modèleDans ce point, il est proposé une discussion succincte sur le choix entre l'utilisation d'un modèle logit ou d'un modèle probit ; et afin la modélisation du modèle retenu. a. Modèle logit et modèle probit Comme notre variable expliquée (la mobilité professionnelle) est dichotomique, nous nous trouvons restreint de choisir un modèle d'analyse approprié et adapté. Dans cette perspective, Hurlin (2003) souligne que les modèles dichotomiques logit et probit admettent pour variable expliquée, non pas un codage quantitatif associé à la réalisation d'un événement (comme dans le cas de la spécification linéaire), mais la probabilité d'apparition de cet événement, conditionnellement aux variables exogènes. Cependant, le modèle Logit, exprimant la
probabilité pour qu'il existe ou non la difficulté de
remboursement pour les acteurs, sera approprié selon la
répartition logistique que nous associons au codage binaire dans le plan
d'analyse. Le modèle Pour que les perturbations soient normalement distribuées, les probabilités Pi prennent deux valeurs pi et 1 - pi respectivement. d.1. Modèle logistique
La fonction de répartition F (.) correspondant à ce modèle Logit est donné par la formule ci-dessous (Bourbonnais, 1998) :
Pour estimer la probabilité pi pour un individu de donner un avis favorable à sa capacité de remboursement, pendant la période étudiée, le modèle retenu devrait être soumis à une linéarisation nécessaire. Avec ln, le logarithme népérien et la probabilité relative de l'événement de mobilité professionnelle.
Toutefois, pour valider la pertinence de nos résultats de régression, certains tests doivent être utilisés dont les tests d'hypothèse sur les paramètres et le test des prédictions du modèle, mais aussi certains critères doivent être respectés pour se prononcer sur son optimalité. d.2. Test de prédiction du modèle Le but de ce test est de juger de la qualité de l'ajustement, c'est-à-dire l'adéquation du modèle aux données disponibles (Hurlin, 2003). Il s'agit de savoir si le modèle spécifié est un bon outil de prédiction de demande ou non de mobilité professionnelle pour les employés retenus dans l'échantillon. Et pour cela, le nombre des prédictions fausses est écrit sous la forme :
Où Et compte tenu de la caractéristique de la variable à expliquer codée en 0 ou 1, le coefficient de détermination R2 n'est pas interprétable en termes d'ajustement du modèle, c'est pourquoi la statistique utilisée est dite pseudo-R2 (Bourbonnais, 2009). Elle a été proposée par McFadden (1974, cité par Hurlin, 2003) et est considérée comme une quantité similaire à un coefficient de détermination. Le pseudo-R² est calculé par la formule suivante :
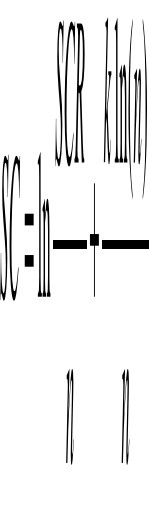
d.3. Sélection du modèle optimal La sélection du modèle optimal permet de choisir entre deux modèles concurrents, c'est-à-diredeux modèles comportant des variables différentes mais qui sont toutes significatives. Le modèle à retenir est celui qui minimise la fonction d'Akaike:
Et celle de Schwarz :
Avec SCR, la somme des carrés des résidus du modèle, n : le nombre d'observations, et k: le nombre des variables explicatives. Le critère d'information de Hannan-Quinn peut aussi être utilisé de la même façon que celui d'AIC et de SC (Bourbonnais, 2009). A cet effet, Bourbonnais (2009) distingue 5 méthodes qui peuvent être utilisées pour retenir le meilleur modèle. Il s'agit soit de considérer toutes les régressions possibles, soit d'utiliser l'élimination progressive (« Bachward Elimination »), soit la sélection progressive (« ForwardRegression »), soit la régression pas à pas (« StepwiseRegression) et la régression par étage (« StagewiseRegression »). Les 3 dernières méthodes étant appropriées pour les variables explicatives quantitatives, restent les deux premières méthodes pour la présente étude. A cela, l'élimination progressive (« Bachward Elimination ») est utilisée dans cetteétude. Et partant de l'estimation du modèle complet (ou le modèle comportant toutes les variablesexplicatives), elle consiste à éliminer de proche en proche (c'est-à-dire en ré-estimant l'équation après chaque élimination) les variables dont lesz-statistiques sont en-dessous du seuil critique. * 58LinearProbability Model |
|


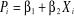 (1) est une équation à modèle de
probabilité linéaire58
(1) est une équation à modèle de
probabilité linéaire58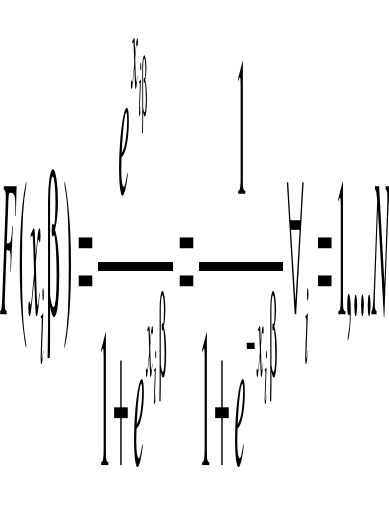
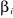 : Les paramètres à estimer et le terme
d'erreur ; le modèle ainsi obtenu peut être estimé
à l'aide des algorithmes de maximisation d'une fonction de
log-vraisemblance (Bourbonnais, 2009). Le logiciel SPSS a servi à
l'estimation du modèle utilisé dans cette étude.
: Les paramètres à estimer et le terme
d'erreur ; le modèle ainsi obtenu peut être estimé
à l'aide des algorithmes de maximisation d'une fonction de
log-vraisemblance (Bourbonnais, 2009). Le logiciel SPSS a servi à
l'estimation du modèle utilisé dans cette étude. 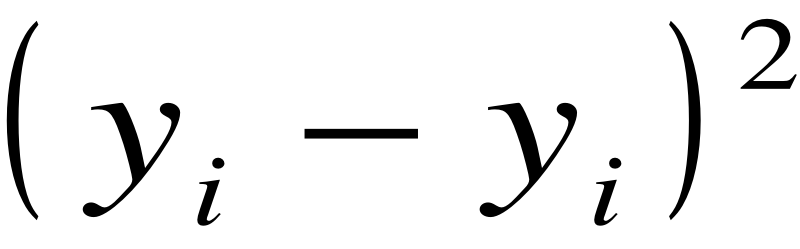
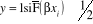 et
et  si
si  ½. En effet, la quantité donne le nombre de fausses
prédictions puisque = 1 si et seulement si
yi?
½. En effet, la quantité donne le nombre de fausses
prédictions puisque = 1 si et seulement si
yi?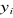 ; c'est-à-dire, dans le cas où
; c'est-à-dire, dans le cas où 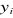 =1 alors que yi = 1 alors que yi
= 0 ou dans le cas contraire. Cependant, le problème avec ce
critère est que l'on considère de la même façon un
individu dont la probabilité pi est de 0,49 ;
on pénalise ces deux individus de la même façon dans le cas
d'un échec du modèle en termes de prédiction et on les
valorise de la même façon en cas de réussite (Hurlin,
2003).
=1 alors que yi = 1 alors que yi
= 0 ou dans le cas contraire. Cependant, le problème avec ce
critère est que l'on considère de la même façon un
individu dont la probabilité pi est de 0,49 ;
on pénalise ces deux individus de la même façon dans le cas
d'un échec du modèle en termes de prédiction et on les
valorise de la même façon en cas de réussite (Hurlin,
2003). 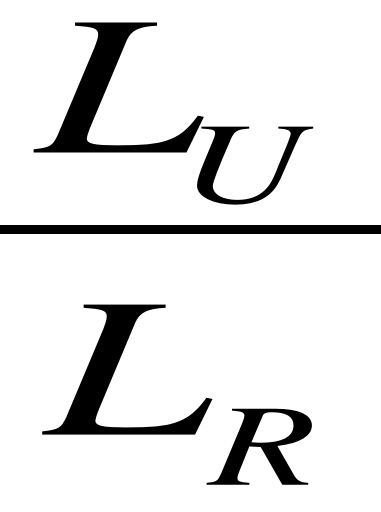
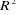 McFadden = 1 -
McFadden = 1 -