Couplage microfinance et micro assurance pour l’optimisation de la gestion du risque des crédits à Bukavu.par Audace Ntwali Université Libre des Pays des Grands Lacs de Bukavu (ULPGL) - Licence en Sciences économiques et de Gestion - Option : Gestion Financière 2016 |

Tableau n°2.1 : Outil de pré-enquête
Source : Nos investigations sur le terrain. Ce tableau montre que 30 acteurs, soit 73% ont manifesté que certainement le couplage micro assurances et micro crédits est un bon outil de réduction des risque dans les institutions de microfinance. C'est pourquoi, nous pouvons utiliser les résultats de cette pré-enquête pour déterminer la taille de l'échantillon. Ainsi, nous cherchons à tirer un échantillon représentatif en utilisant la formule de sondage55(*) : n = avec : n : la taille de l'échantillon p : la probabilité de réussite basée sur une étude antérieure
Ainsi, p = 0,73 Si nous maintenons le seuil de signification à 5%,
c'est-à-dire
L'échantillon de 315 bénéficiaires nous permet d'étudier les caractéristiques principales des enquêtés et de ressortir avec la même précision les garanties de l'optimisation issue de cette perspective. 2. Enquête proprement diteL'enquête porte sur 315 bénéficiaires des IMF sélectionnés à travers un choix issu de la pré-enquête menée dans les institutions de microfinance de Bukavu. - cette enquête a été réalisée sur 315 acteurs bénéficiaires de crédits des IMF à Bukavu ; - la répartition de l'échantillon était assurée par les méthodes aléatoires; - les interviews sont réalisées au cours des premier et deuxième trimestres 2016 et en même temps, les questionnaires sont recueillis auprès des acteurs. C.Techniques de traitement de donnéesTrois principales techniques nous ont permis de traiter les données, il s'agit des statistiques descriptives, de la statistique de Khi-Deux ainsi que le modèle économétrique de régression logistique. a. Les statistiques descriptives Ce sont les mesures de limite de tendance centrale et de dispersion, ainsi, elle existe souvent sous forme groupées et non groupées. a.1. La moyenne La moyenne est la mesure de tendance centrale qui permet de comparer les données d'une distribution autour de leur forte dispersion. · Pour les données non groupées Elle est calculée de cette manière : · Pour les données groupées Elle est calculée de cette manière : a.2. La variance La variance est la mesure du risque absolu.Cela étant, cette variable de dispersion nous permet de constater le point sur lequel les données s'éloignent autour du centre. Pour calculer, on utilise la formule suivante : · Les données groupées
Avec n le nombre d'observations · Les données non groupées
a.3. L'écart-type C'est aussi une mesure de dispersion qui consiste à mesurer le risque final dans une distribution des données. Pour le calculer, on retient le radical de la variance de cette manière. · Pour les données non groupées
· Pour les données groupées
a. La statistique de Khi-Deux La spécificité de cette statistique renvoie à un test populaire. En effet, pour la présenter, on tient souvent compte de deux approches inaliénables : les fréquences (ou les effectifs des observés) et les fréquences théoriques (ou les effectifs connues au départ). Son énoncé peut être appréhendé de cette façon :
Où fi : l'effectif observé et ddl : degrés de liberté ddl = (#c - 1). (#l - 1) - h dans le tableau de contingence avec h le nombre des contraintes liées avec le paramètre56(*). Les hypothèses : H0 : Pas de corrélation H1 : Présence de corrélation Règle de décision : * 55 G. KIMBUANI MABELLA, Théories et pratiques des sondages, Cours Inédit, ULPGL-Bukavu, FSEG, L2, 2015-2016. * 56 M.NGUBA MUNDALA, Statistique appliquée aux affaires, Cours,Inédit,UOB, FSEG, L1, 2013-2014. |
|


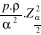
 : la probabilité d'échec (où
: la probabilité d'échec (où  = 1 - p)
= 1 - p) : la marge d'erreur
: la marge d'erreur 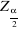 : le degré de confiance
: le degré de confiance = 1 - p
= 1 - p = 1 - 0,73
= 1 - 0,73 = 0,27
= 0,27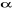 la marge d'erreur est égale à 0,05.
la marge d'erreur est égale à 0,05. 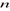 = 315
= 315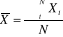 pour une population et
pour une population et 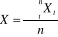 pour l'échantillon.
pour l'échantillon.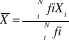 et pour un échantillon
et pour un échantillon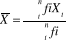 .
.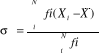 pour une population et
pour une population et 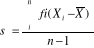 pour l'échantillon.
pour l'échantillon.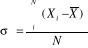 pour une population et
pour une population et 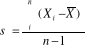 pour l'échantillon.
pour l'échantillon.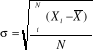 pour une population et
pour une population et 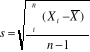 pour l'échantillon.
pour l'échantillon.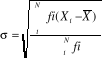 pour une population et
pour une population et 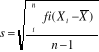 pour l'échantillon.
pour l'échantillon.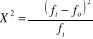
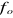 : est l'effectif théorique
: est l'effectif théorique 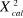 >
>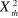 , on accepte H1, c'est-à-dire la relation entre les
variables étudiées existe.
, on accepte H1, c'est-à-dire la relation entre les
variables étudiées existe.