VI.2.2
Scénario d'exécution des cas d'utilisation
Le schéma ci-dessous présente les
enchaînements à suivre pour dérouler complètement un
cas d'utilisation.
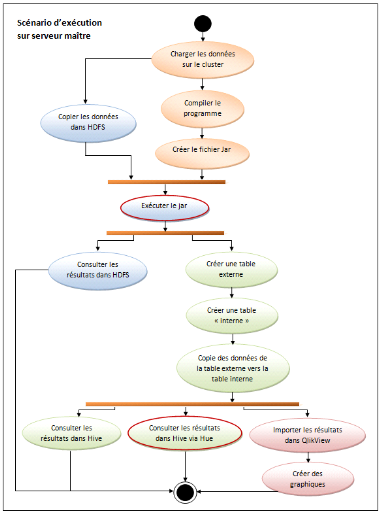
Figure 16 :
Scénario d'exécution des cas d'utilisation
VI.2.3
Création des programmes MapReduce
Pour chacun des fichiers csv présent dans les tableaux
précédents, j'ai crée un programme java qui
sélectionne pour chaque ligne du fichier, les champs utiles et les
formate afin de faciliter leur intégration dans Hive.
Exemple de résultat des programmes
exécutés :
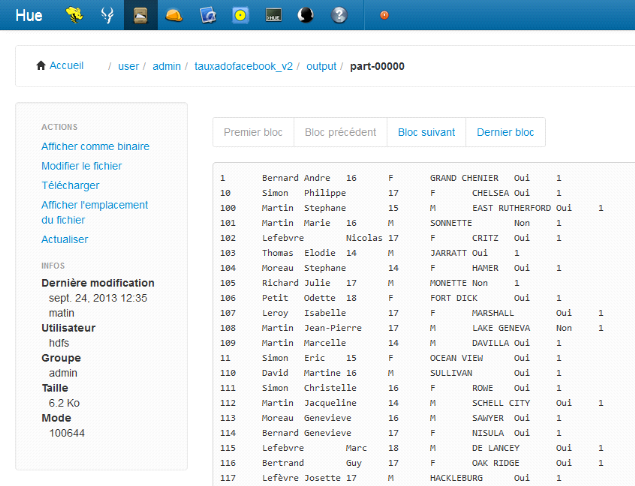
Figure 17 : Résultat d'un job MapReduce
via l'interface Hue
VI.2.4 Restitution
des données via Hive
Comme mentionnée un peu plus haut dans ce document, pour
améliorer la lisibilité des données dans HDFS, j'ai
importé les résultats des traitements dans Hive.
Dans hive, lorsqu'une table est crée avec des
données stockées dans HDFS, les données sont
déplacées de HDFS vers Hive, il n'y plus les données
aucune copie sur HDFS pour d'éventuelles utilisation. Pour éviter
que les données ne soient supprimer de HDFS, il faut créer une
table externe qui pointer vers les données présentes sur HDFS et
une table simple ; copier les données de la table externe vers la
table simple, ceci permettra de pouvoir réutiliser les données
présentes sur HDFS. Ainsi pour chaque résultat de traitement j'ai
crée une table externe, une table simple et j'ai copié les
données la table externe vers la table simple.
Exemple du cas d'utilisation 1
§ Création de la table externe
CREATE EXTERNAL TABLE types_utilisateurs_ex (id int, age int,
genre string, amis int, nombre_inscription int, duree_connexion_par_sem double,
frequence_utilisation_par_jour int, mapreduce int) ROW FORMAT DELIMITED FIELDS
TERMINATED BY '\t' LOCATION
'hdfs://Master.corp.capgemini.com:8020/user/admin/typesutilisateurs_rs/output/';
§ Création de la table simple
CREATE TABLE types_utilisateurs_in (id int, age int, genre
string, amis int, nombre_inscription int, duree_connexion_par_sem double,
frequence_utilisation_par_jour int);
§ Copie des données de la table externe vers la
table simple
FROM types_utilisateurs_ex ue INSERT OVERWRITE TABLE
types_utilisateurs_in SELECT ue.id, ue. age, ue.genre, ue.amis,
ue.nombre_inscription, ue. duree_connexion_par_sem,
ue.frequence_utilisation_par_jour ;
Avec Hive, il est possible de visualiser les contenus des
tables soit en sur la console, soit sur l'interface graphique. Le schéma
ci-dessous présente un extrait du résultat de la requête
« select * from utilisateurs_in; » sur l'invite de commande.
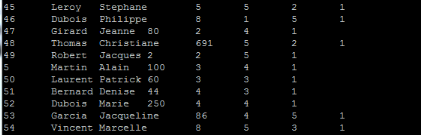
Figure 18 : Résultat de requête sur
l'invite de commande de Hive
J'ai traité tous les résultats présents
dans HDFS de la même façon pour améliorer leur
visualisation dans Hive.
Les données ainsi structurées, sont
importées dans un outil de visualisation qui va faciliter leur analyse
et la prise de décision.
| 

