VI.1.4.3.2
Restitution des données
La restitution des résultats des traitements dans
Hadoop n'est pas conviviale à cause des propriétés
intrinsèques de HDFS qui est un système de fichier et non outil
de présentation de données. De plus, les résultats de
traitement ne sont pas assez structurés pour faciliter leur
lisibilité.
La problématique qui se pose est de savoir comment
faciliter la lisibilité des résultats des traitements
stockés dans HDFS.
Dans l'écosystème Hadoop, plusieurs solution
sont possibles (utilisation de Sqoop, Pig), j'ai opté pour l'utilisation
de Hive car elle offre déjà la possibilité de connexion
à un outil de visualisation de données.
Requêtage des données via Hive
Le composant Hive permet de créer une structure des
données à partir des données stockées dans HDFS.
L'objectif était donc d'appréhender concrètement comment
Hive améliore la restitution des informations provenant de HDFS.
Les requêtes étant réalisées avec
HiveQL, langage similaire au langage SQL, l'appropriation du langage est plus
rapide.
J'ai testé des requêtes sur des données
stockées dans HDFS et visualisé les résultats depuis la
console Hive et l'interface web. Les données sont stockées sous
forme de tables. Les exemples sont présentés dans la suite du
document.
Hive se base sur des traitements MapReduce pour
réaliser les requêtes ce qui suscite des temps de réponse
assez long. Pour pallier ce problème, il est possible de partitionner
les tables pour réaliser les requêtes sur certaines parties de la
table au lieu de la table entière. Cela permet également de ne
recharger qu'une partie des données en cas de modification ou de
suppression ce qui est important dans le cas de grands volumes de
données.
VI.1.4.3.3 Test de
scalabilité et traitements distribués
Hadoop permet le stockage des données dans le
système de fichier HDFS et la réalisation des traitements
distribués sur ces données. L'infrastructure matérielle
contribue largement au traitement des données. Le traitement sur de gros
volumes de données qui augmentent continuellement suppose de disposer
d'une infrastructure qui supporte la montée en charge.
La scalabilité est considérée comme la
capacité d'un produit à s'adapter à un changement d'ordre
de grandeur de la demande ; elle est également
considérée comme la capacité d'un système à
accroître sa capacité de calcul sous une charge accrue quand des
ressources (généralement du matériel) sont
ajoutées.
La problématique est de savoir comment un cluster
Hadoop répond au besoin de scalabilité et la distribution des
traitements avec une scalabilité horizontale.
Dans un premier temps, j'ai testé un programme
MapReduce sur un échantillon de 100 Mo de données, dans un
cluster à 4 noeuds où j'avais mis un noeud hors service.
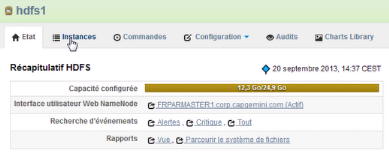
Figure 11 : Capacité de stockage initiale
du cluster
Le schéma ci-dessus présente la capacité de
stockage sur les trois noeuds actifs du cluster sur lequel le job MapReduce est
lancé. A partir de cette fenêtre de la console, on
peut accéder :
§ A l'interface utilisateur du NameNode
§ Aux évènements générés
par le service hdfs1
§ Aux différents rapports sur le système de
fichiers
§ Aux différentes instances du service
§ Aux commandes en cours d'exécution, utilisant ce
service
§ A la configuration du service
§ Etc
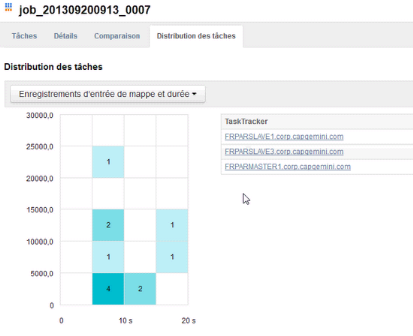
Figure 12 : Distribution des tâches du job
sur les 3 noeuds actifs
Sur ce schéma, on voit les TaskTrackers qui ont
participé au job. En cliquant sur chaque cellule colorée, on
observe le ou les TaskTracker(s) qui ont été sollicités
durant un intervalle de temps précis.
Dans un deuxième temps, j'ai testé le même
programme sur un échantillon de 5 Go de, dans un cluster à 4
noeuds dont un noeud hors service.
 Figure 13 : Etat
d'avancement du job Figure 13 : Etat
d'avancement du job
Mis à part la durée du job qui est un peu plus
longue, les tâches sont également distribuées sur les 3
noeuds actifs du cluster.
Dans un troisième temps, j'ai testé le
même programme sur un échantillon de 5Go de données, dans
un cluster à 4 noeuds avec tous les noeuds actifs.

Figure 14 : Capacité de stockage du
cluster après la remise en service du quatrième noeud
Lorsqu'on remet en service un noeud qui était inactif,
la capacité de stockage du cluster augmente.
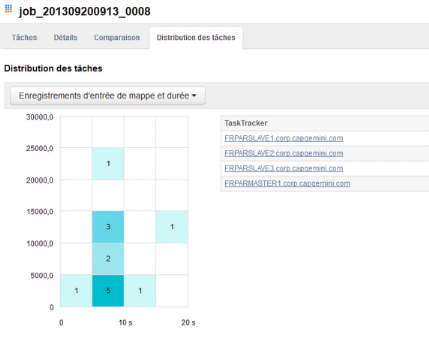
Figure 15 : Distribution des tâches sur les
4 noeuds actifs
Compte tenu de la capacité du poste physique et de
celle des machines virtuelles, je n'ai pas pu achever ce test ; par contre
avec un échantillon plus réduit
Les différents tests ci-dessus ont permis de montrer
que la scalabilité (horizontale) et la distribution de traitement sont
des concepts bien réels dans un cluster Hadoop, ceci me permet de dire
que l'extension de la capacité de stockage et de traitement est moins
coûteux sur un cluster Hadoop que sur des systèmes de gestions de
base de données traditionnelles.
| 

