VI.1.3
Déploiement de la plateforme
Le déploiement du cluster peut se faire soit
manuellement (utilisation des packages), soit automatique avec Cloudera
Manager. J'ai fait une installation automatique pour limiter des
éventuelles erreurs d'installation et aussi compte tenu du temps donc je
disposais pour mon stage.
La figure ci-dessous présente la page d'accueil de la
console web de Cloudera Manager après l'installation du cluster, listant
les différents composants installés sur le cluster Hadoop.
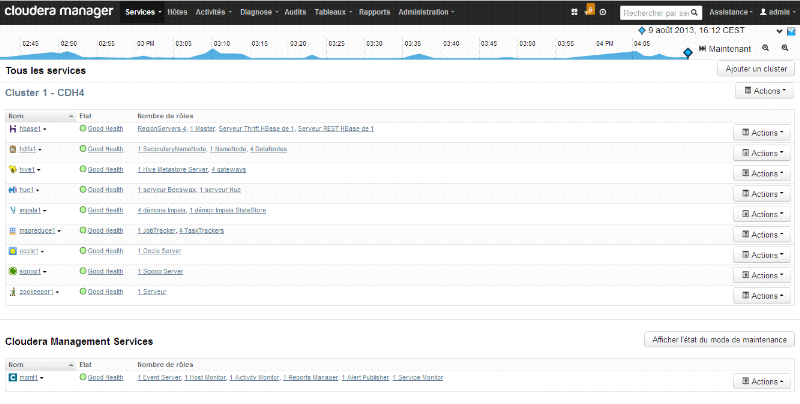
Figure 10 : Page
d'accueil de Cloudera Manager après l'installation du
cluster
VI.1.4 Tests techniques réalisés
VI.1.4.1 But des tests
Lorsqu'on réalise un test, il est important de
d'utiliser une démarche précise et de définir les
objectifs à atteindre à la fin du test, ce qui permettra de faire
un contrôle à la fin, par rapport aux résultats obtenus
pour savoir si le test à été satisfaisant ou non.
La démarche a consisté à tester les
composants séparément ou conjointement, à identifier les
fonctionnalités de chacun.
Les objectifs des différents tests
étaient :
§ D'acquérir une meilleure connaissance de chaque
composant
§ Pouvoir présenter le fonctionnement de chaque
composant
§ Faire des recommandations par rapport à
l'utilisation d'un composant
§ Montrer la mise en oeuvre de certains concepts
VI.1.4.2 Test de l'environnement existant
Avant de compléter les tests, il fallait que je refasse
des tests précédemment réalisées pour mieux
appréhender l'environnement. Ainsi j'ai redéployé le
précédent environnement, puis j'ai testé les composants
HDFS, Mapreduce, Flume, Hbase, Hive, Hue et Coudera Manager.
VI.1.4.3 Test sur le nouvel environnement
VI.1.4.3.1
Traitement de données avec Mapreduce et HDFS
Lorsque les données sont collectées sans un
outil spécifique, elles sont d'abord stockées sur le
système de fichier local, puis l'utilisateur les déplace sur le
système de fichier HDFS. HDFS repartit et réplique les
données sur les différents noeuds du cluster en tenant compte du
facteur de réplication pour assurer une certaine tolérance
à d'éventuelles pannes. Lors du traitement, toutes les
données concernées sont mobilisées quelque soit leur
emplacement.
La problématique sous-jacente est celle de savoir
comment les traitements sont réalisés sur des données
dispersées dans le cluster.
Ce sont les composants du noyau Hadoop qui participent au
traitement : MapReduce et HDFS. Pour réaliser le traitement, il
faut développer un programma java composé de deux fonctions
principales : map et reduce.
Pour le test, j'ai crée un programme dans une classe
java nommée « Election », je me suis procurée
des open data sur les élections françaises et européennes.
Le programme devait parcourir le répertoire sur HDFS, contenant les
différents fichiers relatifs aux élections et pour chaque
scrutin, il devait retourner le libellé du scrutin et le nombre
d'inscrit à ce scrutin.
Par la suite j'ai compilé le programme et crée
un fichier JAR exécuté via cette commande :
Nombre de fichier en entrée (input)
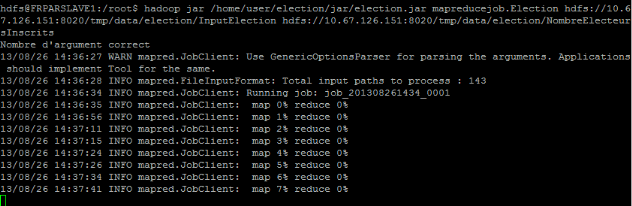
Hadoop jar : c'est la commande
permettant de lancer un programme MapReduce
/home/user/election/jar/election.jar :
c'est le chemin d'accès au fichier JAR qui s'appelle
« election.jar »
mapreducejob.Election : c'est le nom de
la classe java contenant l'entrée du programme (méthode main)
précédé du nom du package qui le contient
hdfs://10.67.126.151 :8020/tmp/data/election/InputElection :
c'est le chemin d'accès aux données sur lesquelles le traitement
s'effectue
hdfs://10.67.126.151 :8020/tmp/data/election/NombreElecteursInscrits
: c'est le chemin d'accès au répertoire qui stocke le
résultat du traitement
L'exécution du fichier jar a bien fonctionné et
le résultat est bien en registré dans HDFS, dans le
répertoire indiqué lors de l'exécution, ce qui est
perceptible via le commande ci-dessous

| 

