Conception d'une ontologie pour une plate forme d'enseignement à distance( Télécharger le fichier original )par Saloua & Amina Chettibi & Rouibah université de jijel - ingénieur informatique 2005 |

Implémentation
L'éditeur d'ontologie « Protégé version 3.1.1 » avec lequel l'ontologie de ce projet a été éditée, maintient un espace de nommage unique pour les classes, attributs et instances. Il est sensible à la casse, et il ne permet l'apparition des espaces dans les noms, les délimiteurs autorisés sont bien « _ » et «-». C'est pour ces considérations que les noms déjà présentés dans l'ontologie conceptuelle ont été légèrement modifiés, lors de leurs éditions sous « Protégé ». IV.1.3. Les étapes de l'édition Dans ce qui suit nous allons présenter comment nous avons édité l'ontologie de ce projet, à partir de lancement de « Protégé » jusqu'à la génération du code OWL et de la documentation HTML correspondante.
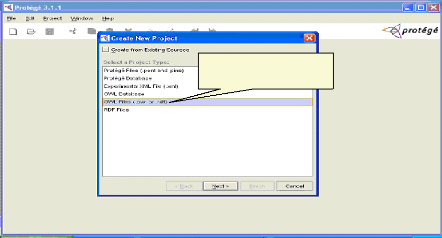
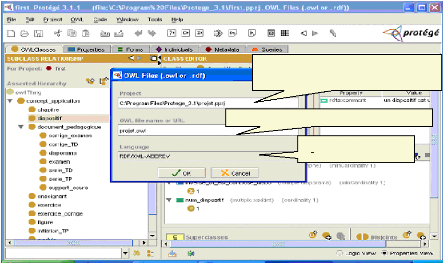
Choisir OWL files (.owl or .rdf) Fig.IV.6 : Choix de type de projet
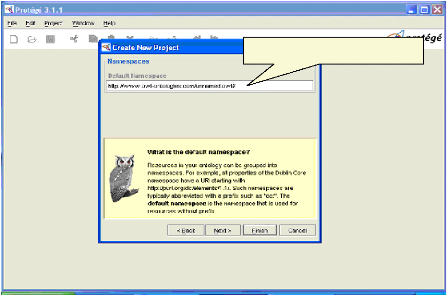
Protégé propose un espace des noms Fig.IV.7 : Choix d'un espace des noms
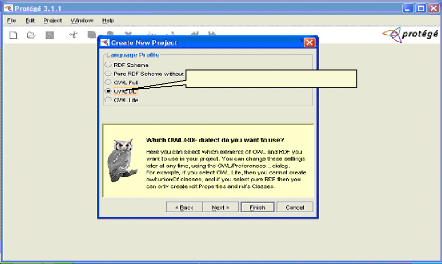
Choisir OWL DL comme langage Fig.IV.8 : Choix d'un langage
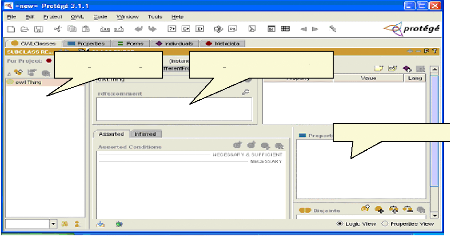
Champ des concepts Champ des commentaires Champ des propriétés Fig.IV.9 : Page d'édition
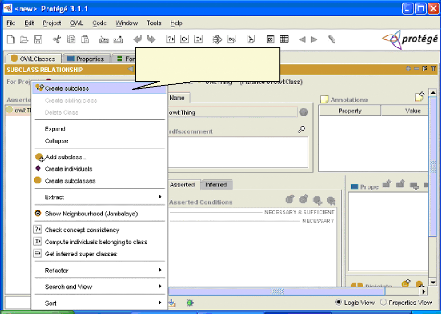
Création d'une Sous classe de `'OWL : Thing» Fig.IV.10 : Création des classes
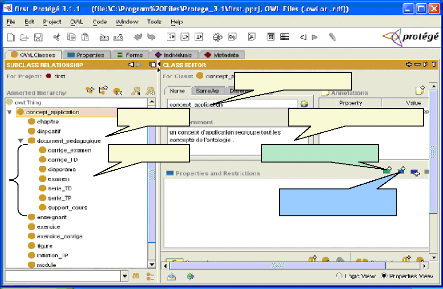
Sous concepts Sur concept Nom de concept Ajouter des propriétés Ajouter des relations Définition de concept Fig.IV.11 : Les champs à remplir
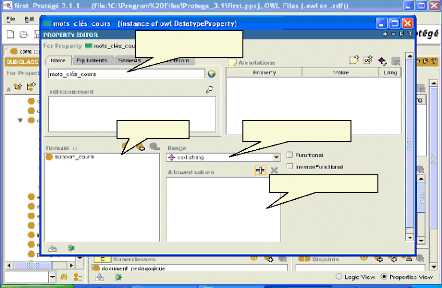
Domaine Nom de la propriété Type de propriété Valeurs permises Fig.IV.12 : Ajout d'une propriété
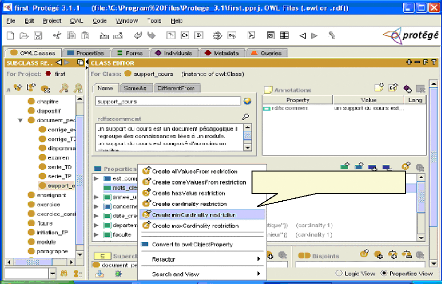
Contraintes de cardinalités Fig.IV.13 : Spécification des contraintes de cardinalité
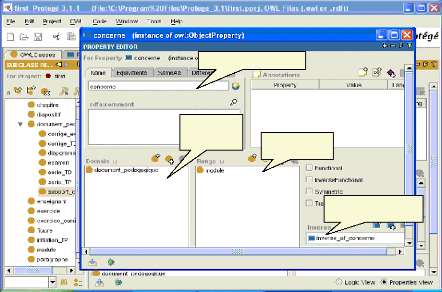
Domaine Nom de la relation Image Relation inverse Fig.IV.14: Ajout d'une relation
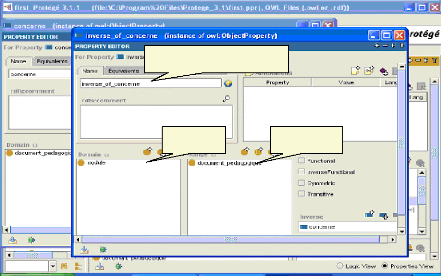
Nom de la relation inverse Domaine Image fig.IV.15 : Ajout de la relation inverse
5) Après avoir terminer l'édition de l'ontologie, on sauvegarde le projet :
Spécifier un nom pour le fichier OWL Spécifier un nom pour le projet, et un emplacement Spécifier un format
<owl:Ontology rdf:about=""> <owl:imports rdf:resource=""/> Concept Chapitre </owl:Ontology> Définition de concept <owl:Class rdf:ID="chapitre"> <rdfs:comment rdf:datatype=" http://www.w3.org/2001/XMLSchema#string"> un chapitre est un concept d'application, il est le composant de base d'un support du cours il regroupe un ensemble de connaissance nécessaires pour la compréhension du module. un chapitre est composé d'un ou plusieurs paragraphes. </rdfs :comment> <rdfs:subClassOf> <owl:Restriction> <owl:minCardinality rdf:datatype=" http://www.w3 .org/200 1 /XMLSchema#int" Relation inverse de Est_composé_chapitre >1</owl:minCardinality> 69 Fig.IV.16 : Enregistrement de projet Voici un fragment de code OWL généré :
<owl:onProperty> <owl:ObjectProperty rdf:ID="inverse_of_est_compose_chapitre"/> </owl:onProperty> </owl:Restriction> </rdfs:subClassOf> <rdfs:subClassOf> <owl:Restriction> <owl:onProperty> <owl:DatatypeProperty rdf:ID="num_chapitre"/> </owl:onProperty> <owl:cardinality rdf:datatype=" http://www.w3.org/2001/XMLSchema#int" >1</owl:cardinality> </owl:Restriction> </rdfs:subClassOf> <rdfs:subClassOf> <owl:Restriction> <owl:cardinality rdf:datatype=" http://www.w3.org/2001/XMLSchema#int" >1</owl:cardinality> <owl:onProperty>
Propriété num_chapitre Fig.IV.17 : un fragment de code OWL généré 6) Finalement, on génère la documentation HTML de l'ontologie :
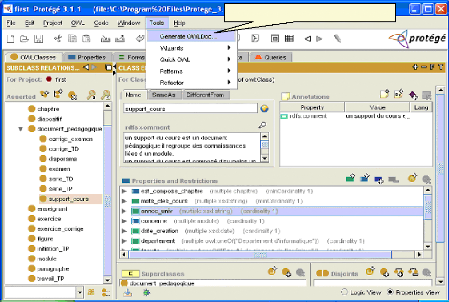
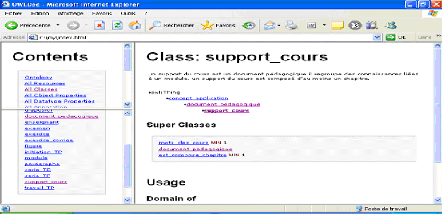
Génération de la documentation Fig.IV.18 : Génération de la documentation La page suivante fait partie de la documentation généré, elle correspond à la classe « Support de cours »:
Fig.IV.19 : Documentation de l'ontologie
IV.1.4. Schéma résumant la phase de l'opérationnalisation
Génération du code OWL Ontologie Edition de l'ontologie conceptuelle Code Ontologie opérationnelle Fig.IV.20 : Phase de l'opérationnalisation IV.2. Exploitation de code OWL dans un programme JAVA Après avoir générer le code OWL correspondant à notre ontologie on a été très vite confronté au problème de son exploitation dans un programme JAVA, surtout que peu d'articles sont ceux qui parlent de détail d'implémentation chose qui nous a demandé plus d'effort pour trouver une solution. En consultant quelques documents [14] et [15], on s'est rendu compte qu'il existe une API appelée Jena qui sert de lien entre un code OWL et un programme JAVA et que Plus de 70% des applications de Web sémantique sont développées en Jena. Après avoir répondre à la question « comment exploiter le code OWL avec Java », il fallait résoudre un autre problème car tout simplement lorsqu'on a testé Jena sous JBuilder7 elle n'a pas fonctionné, le problème était dans la version de JDK (JAVA Development Kit) qui a été la version « 1.3.1 » et dans la version du serveur Web JSP « Jakarta Tomcat » qui a été la version « 3.3 » il était indispensable qu'on passe à des versions plus récentes. On a testé Jena avec « JDK version 1.4.2 » et avec « Tomcat version 4.0 » et ça très bien marché, en ce qui concerne le serveur Tomcat, JBuilder7 est muni de la version « 4.0 » tandis que pour le « JDK 1.4.2 » il fallait qu'on le télécharge à partir de site http://java.sun.com.
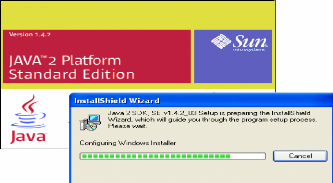
1) Installation de JDK 1.4.2 :
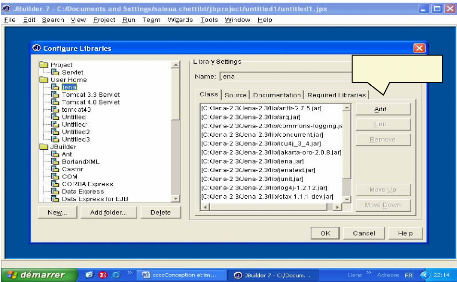
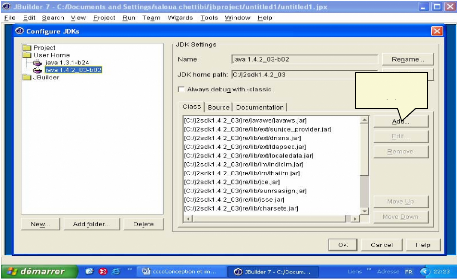
Fig.IV.21 : Installation de JDK 1.4.2 2) Pour la configuration des JDKs et des Librairies avec JBuilder7, il faut aller au menu Tools/configure librairies et Tools/configure JDKs
Ajouter Jena Fig.IV.22: Ajout de la librairie Jena
Ajouter JDK Fig.IV.23 : Ajout de JDK 1.4.2 IV.2.1. Suivi de session Le protocole HTTP est un protocole non connecté (on parle aussi de protocole sans états) cela signifie que chaque requête est traitée indépendamment des autres et qu'aucun historique des différentes requêtes n'est conservé. Il s'agit donc de maintenir la cohésion entre l'utilisateur et la requête, c'est-ce qu'on appelle « suivi de session ». Il existe 3 méthodes pour garantir le suivi de session :
Pour notre application, on a travaillé avec des champs "hidden", car c'était pour nous une méthode simple ce qui ne veut pas dire qu'elle est forcément la meilleure solution.
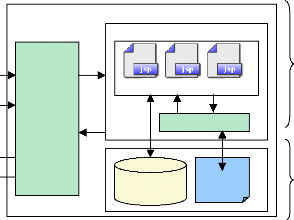
IV.2.2. Architecture de l'application développée Internet/Intranet Serveur Environnement d'exécution API JENA SERVEUR Tomcat Réponse
Documents Code OWL
Niveau2 : Applicatif Niveau3 : Données Client Requête (http)
Navigateur Web Niveau1 : Présentation Fig.IV.24 : Architecture de l'application
La dernière étape de ce projet était de faire exécuter notre application en dehors de son environnement de développement « JBuilder7 », de manière qu'elle sera intégrable sur la plate forme « PLone », pour réaliser ça on a :
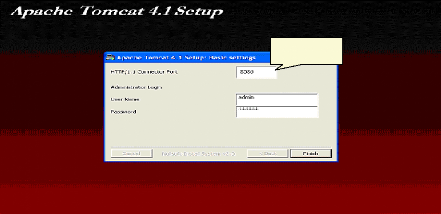
> Installer le serveur « Tomcat version 4.1» sur le port « 8086 » au lieu du port «8080 » pour le faire cohabiter avec le serveur de la plate forme « Plone » qui réside sur le port « 8080 » :
Port 8086 Fig.IV.25 : Installation de serveur Tomcat > Placer notre application sous le répertoire « Webapps » de Tomcat :
Notre application Fig.IV.26 : Emplacement de l'application
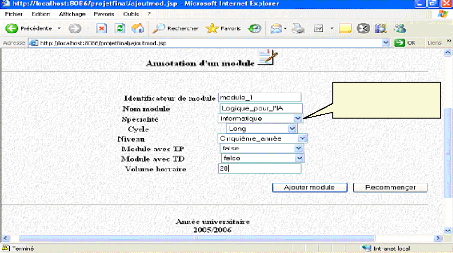
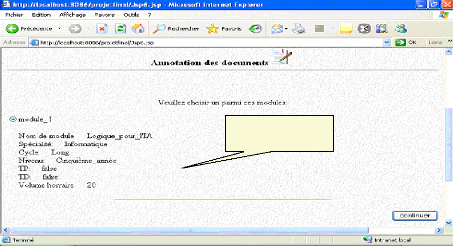
> Problème rencontré Durant l'exécution de notre application, et en particulier en exécutant les JSP faisant appel à Jena, un problème a survenu sur le serveur Tomcat. Après avoir faire quelques recherches sur le net pour déterminer la cause du problème, et plus exactement en consultant les FAQ (Frequently Asked Questions) de Jena, on s'est rendu compte qu'il s'agit d'un problème de version du parseur XML « Xerces» de Tomcat, qui était une version plus ancienne que celle requise par Jena, problème qui n'était pas posé sous JBuilder7. Pour résoudre ce problème il fallait qu'on change le fichier « xmlParserAPIs.jar», ainsi que le fichier « xercesImpl.jar » qui se trouvent sous le répertoire « endorsed » de Tomcat, par ceux associés avec Jena. VI.1. Images d'exécution de l'application Dans ce qui suit nous allons présenter quelques captures d'écran d'exécution de notre application, mais avant de commencer en voici quelque remarques : > La génération des identificateurs des enseignants des modules, et tous les individus de l'ontologie est automatique ce qui décharge l'administrateur ainsi que les enseignants de gérer eux même les identificateurs qui doivent être unique pour chaque individu. > La recherche est insensible à la casse. > Un champ vide dans une requête implique que l'utilisateur accepte toute valeur possible pour ce champ. > Pour tester sur le format de certains champs : les champs numérique, champ de date etc. on a utiliser quelque « Java Script». Les images suivantes présentent un scénario complet de l'utilisation de notre application, afin de mieux expliquer son fonctionnement: VI.1.1 Annotation d'un module L'administrateur effectue l'annotation d'un module, qu'il soit le module « Logique pour l'IA », qui est un module de 5 ING informatique, option « Intelligence Artificielle » ayant pour identificateur « module_1 » :
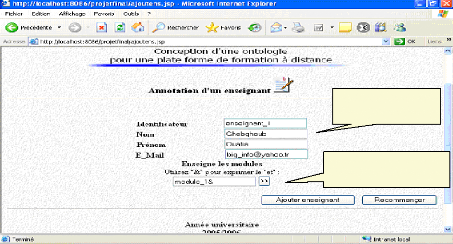
Module Logique pour l'IA Fig.IV.27 : Annotation d'un module VI.1 .2. Annotation d'un enseignant *L'administrateur effectue l'annotation d'une enseignante, qu'elle soit Melle « Ghebghoub Ouafia » ayant pour identificateur (login) «enseignant_1 » :
Le choix des modules se fait sur un autre écran Enseignante Fig.IV.28: Annotation d'un enseignant
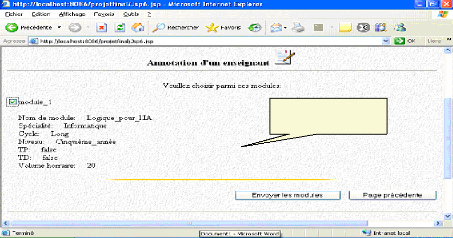
* l'administrateur affecte le module « Logique pour l'IA » à « Melle : Ghebghoub Ouafia » :
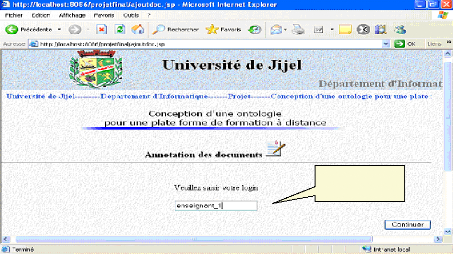
Liste des modules non encore affectés Fig.IV.29 : Affectation d'un module à un enseignant VI.1.3. Annotation d'un document *Un enseignant commence à annoter un document par saisir son login :
Login de Fig.IV.30 : Saisie de login de l'enseignant
*L'enseignant doit choisir un module parmi ceux qu'il enseigne :
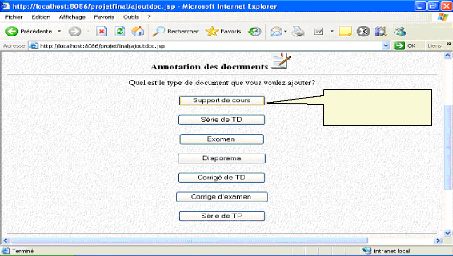
Choix de module Logique pour l'IA Fig.IV.31: choix d'un module *L'enseignant doit préciser le type de document qu'il veut annoter :
Choix d'un support Fig.IV.32 : Choix de type de document à annoter
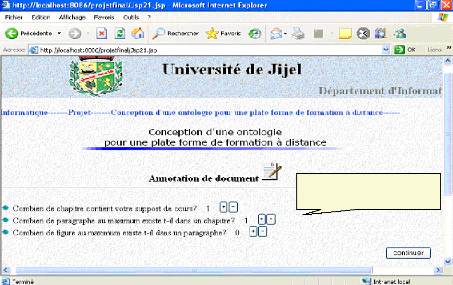
*L'enseignant doit préciser les caractéristiques de sont support de cours (nombre de chapitre, de paragraphe par chapitre..), afin qu'on lui génère automatiquement un formulaire d'acquisition de métadonnées :
Un cours avec un chapitre, un paragraphe et sans figure. Fig.IV.33 : préparation à la génération de formulaire d'acquisition des métadonnées *L'enseignant doit maintenant annoter son document :
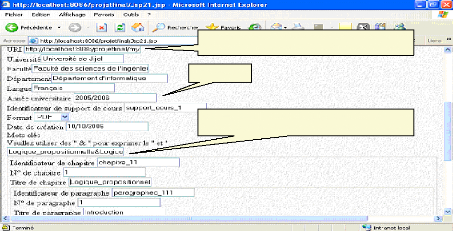
2005/2006 http://localhost:8086/projetfinal/my/cours.pdf Logique propositionnelle&Logique des prédicats Fig.IV.34 : Annotation d'un support de cours
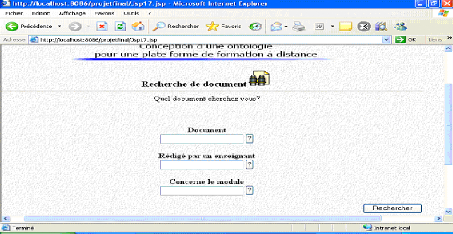
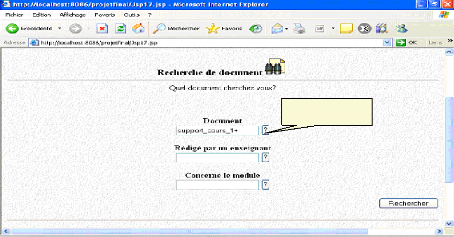
VI.1.4. Recherche de documents *Une recherche de document commence à cet écran, ce dernier permet grâce aux boutons « ? » de passer vers d'autres écrans pour lancer des requêtes à propos de document, de l'auteur de document et de module que concerne ce document :
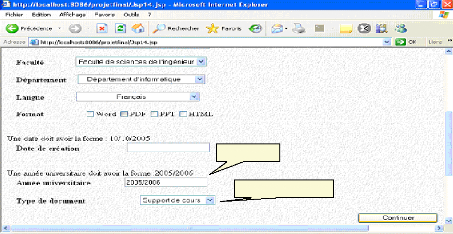
Fig.IV.35 : écran de recherche de document *Un utilisateur cherche un document de type support de cours, qui a été rédigé à l'année universitaire « 2005/2006 »
2005/2006 Support de cours Fig.IV.36: Recherche d'un support de cours
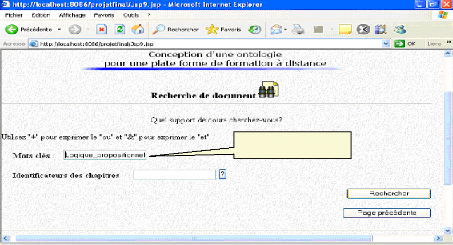
*Toujours dans la même requête, l'utilisateur passe vers un autre écran où il spécifie qu'il cherche un support de cours ayant pour mots-clés « Logique propositionnelle »:
Logique propositionnelle Fig.IV.37: Recherche d'un support de cours (suite) *Le résultat de la requête sera envoyé vers la page de départ :
Support_cours_1 Fig.IV.38: Recherche d'un support de cours (suite)
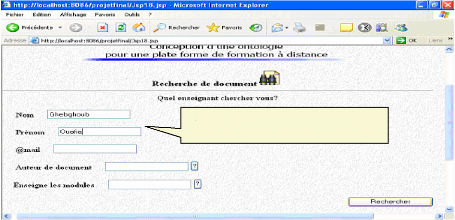
* Si encore il veut continuer sa requête en cherchant un auteur particulier :
L'utilisateur spécifie le nom et le prénom
de Fig.IV.39 : Recherche d'un support de cours (suite) * L'identificateur de l'enseignant qui correspond à sa requête sera envoyé aussi à la page initiale :
Fig.IV.40 : Recherche d'un support de cours (suite)
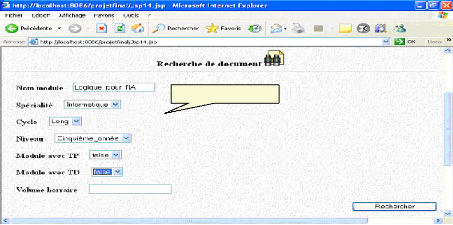
*de plus il cherche un document concernant un module particulier, il passe à l'écran suivant :
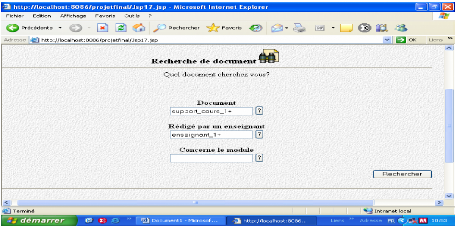
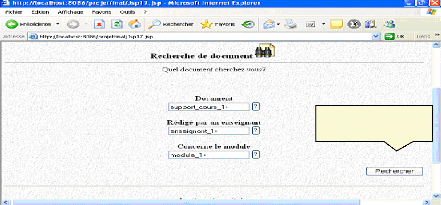
Logique pour l'IA Fig.IV.41: Recherche d'un support de cours (suite) * Une fois terminer, il lance la recherche de l'URI de document qui correspond à sa requête : Rappelons nous « un support de cours avec un mot clés «logique propositionnelle », rédigé à l'année universitaire « 2005/2006 » par un enseignant ayant pour nom « Ghebghoub » et pour prénom « Ouafia » et qui concerne un module ayant pour nom « logique pour l'IA », et pour niveau «cinquième année » et qui est un module de cycle « long » qui est sans TD et sans TP.
Lancer la recherche de Fig.IV.42 : Lancement de la recherche de l'URI
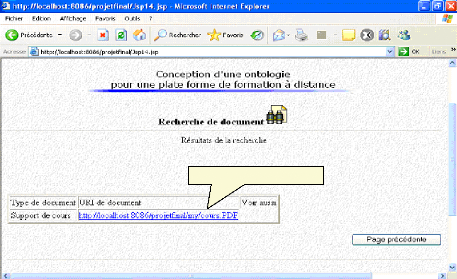
*Le résultat de la recherche est bien le document ayant pour URI « http://localhost : 8086/projetfinal/cours.pdf », par un simple clique sur le lien le document se visualise :
Le résultat de la recherche Fig.IV.43 : Résultat de la recherche
VI.2. Intégration de l'application sur la plate forme « Plone » L'intégration de notre application sur la plate forme Plone, consistait à ajouter des lien dans L'espace de travail réservé à chacun des acteurs vers les tâche qui lui sont propres : > L'administrateur
Fig.IV.44 : Espace administrateur
> L'enseignant
Fig.IV.45 : Espace enseignant
> Les étudiants
Fig.IV.46: Espace étudiant |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||