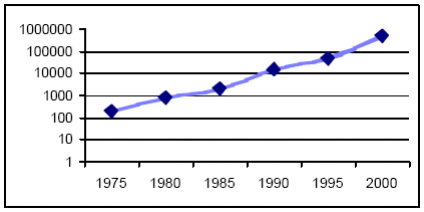
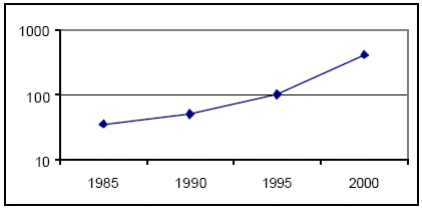
FPGA and Traffic Network Analysis( Télécharger le fichier original )par Jerry TEKOBON Ecole Nationale Supérieure Polytechnique de Yaounde Cameroun - Ingénieur de Conception en Génie Electrique et Télécommunication 2007 |

CHAPITRE 2 : LES COMPOSANTS FPGA (FIELD PROGRAMABLE GATE ARRAY)
Les progrès technologiques continus dans le domaine des circuits intégrés ont permis la réduction des coûts, de la consommation, et c'est maintenant un lieu commun d'affirmer que les circuits intégrés spécifiques d'une application ont permis une réduction de la taille des systèmes numériques ainsi que la réalisation de circuits de plus en plus complexes, tout en améliorant leurs performances et leur fiabilité. Aujourd'hui les techniques de traitement numérique occupent une place majeure dans tous les systèmes électroniques modernes grand public, professionnel ou de défense. De plus, les techniques de réalisation de circuits spécifiques, tant dans les aspects matériels (composants reprogrammables, circuits pré caractérisés et bibliothèques de macro fonctions) que dans les aspects logiciels (placement routage, synthèse logique) font désormais de la microélectronique une des bases indispensables pour la réalisation de systèmes numériques performants. Elle impose néanmoins une méthodologie de développement en CAO très structurée. Nous allons examiner les diverses technologies utilisables pour la conception de circuits logiques avec leurs avantages et leurs inconvénients afin d'expliciter l'intérêt de la technologie FPGA.
Dans un premier temps, nous allons rappeler quelques concepts autour des circuits intégrés pour applications spécifiques ASIC. Les circuits ASIC constituent la troisième génération de circuits intégrés qui a vu le jour au début des années 80. En comparaison des circuits intégrés standards et figés proposés par les fabricants, l'ASIC présente une personnalisation de son fonctionnement, selon l'utilisation, accompagnée d'une réduction du temps de développement, d'une augmentation de la densité d'intégration et de la vitesse de fonctionnement. En outre sa personnalisation lui confère un autre avantage industriel, c'est évidemment la confidentialité. Ce concept d'abord développé autour du silicium s'est ensuite étendu à d'autres matériaux pour les applications micro-ondes ou très rapides (GaAs par exemple). Par définition, les circuits ASIC regroupent tous les circuits dont la fonction peut être personnalisée d'une manière ou d'une autre en vue d'une application spécifique, par opposition aux circuits standards dont la fonction est définie et parfaitement décrite dans le catalogue de composants. Les ASIC peuvent être classés en plusieurs catégories selon leur niveau d'intégration, en fait un ASIC est défini par sa structure de base (réseau programmable, cellule de base, matrice, etc.). Sous le terme ASIC deux familles sont regroupées, les semi personnalisés et les personnalisés (Voir figure2.1) ASIC
PERSONNALISES SEMI-PERSONNALISES Circuits pré caractérisés Circuits à la demande Réseaux pré diffusés Logiques programmables FPGA
UFigure2.1 : Hiérarchie des circuits ASIC
Les semi personnalisés sont des réseaux prédéfinis de transistors ou de fonctions logiques qui nécessitent une personnalisation de l'utilisateur pour réaliser la fonction désirée. Cette famille comprend : 2.2.1.1 ULes réseaux logiques programmablesU Ce composant ne nécessite aucune étape technologique supplémentaire pour être personnalisé. Nous y trouvons les PAL/PLD, ce sont des circuits standard programmables par l'utilisateur grâce à différents outils de développement. La programmation consiste à établir des connexions en imposant un courant supérieur aux courants de fonctionnement normaux (claquage de fusibles ou de jonctions). Les circuits logiques programmables incluent un grand nombre de solutions, toutes basées sur des variantes de l'architecture des portes ET OU. Nous y trouvons : · Précisons que ces composants très souples d'emploi sont limités à des fonctions numériques et adaptés à des productions de petites séries et ne présentent aucune garantie quant à la confidentialité.
Les réseaux pré diffusés sont des circuits partiellement préfabriqués. L'ensemble des éléments (transistors, diodes, résistances, capacités, etc.) est déjà implanté sur le circuit suivant une certaine topologie, mais les éléments ne sont pas connectés entre eux. La réalisation des connexions dans le but de définir la fonction souhaitée est la tâche du concepteur, pour cela il dispose de bibliothèques de macro cellules et d'outils logiciels d'aide à la conception. A partir de cette liste d'interconnexions (netlist) le fondeur n'aura que quelques étapes technologiques à effectuer pour achever le circuit, c'est à dire le dépôt d'une ou plusieurs couches de métallisation. Cette technique est intéressante sur le plan de la conception et de la fabrication, par contre elle présente l'inconvénient de ne pas permettre une optimisation en terme de densité de composants puisque les éléments de base sont pré implantés et pas forcément utilisés et que leur positionnement a priori n'est pas forcément optimal pour le but recherché.
Ce sont des circuits non préfabriqués. Pour chaque application on optimise le circuit intégré, ce qui conduit à la création de son propre composant. Cette famille comprend :
Les solutions circuit à la demande (qu'on appelle full custom en anglais) présentent l'avantage d'autoriser une meilleure optimisation du placement puisque celui-ci n'est pas prédéfini. On dispose d'une bibliothèque de modèles mathématiques de comportement et via un "compilateur de silicium" logiciel très sophistiqué on peut concevoir toute l'architecture du circuit en faire une validation logicielle (simulation logique) puis dans une avant dernière étape en déduire le dessin des divers masques de fabrication. Toutes les opérations, de la conception à la fabrication, sont effectuées de façons spécifiques adaptées aux exigences de l'utilisation. L'ensemble des critères techniques est au choix du concepteur, que ce soit la taille du composant, le nombre de broches, le placement du moindre transistor. C'est l'ASIC le plus optimisé car aucune contrainte ne lui est imposée. Le placement des blocs fonctionnels et le routage des interconnexions, même si ces opérations sont assistées par ordinateur, sont effectués avec beaucoup plus d'interventions manuelles pour atteindre l'optimisation au niveau de chaque transistor. Cependant, les phases de mise au point sont longues et onéreuses, il va de soi que la rentabilisation des investissements de développement nécessite un fort volume de production.
Pour la réalisation de circuits pré caractérisés on dispose d'une bibliothèque de circuits élémentaires que le fondeur sait fabriquer et dont il peut garantir les caractéristiques et on les associe pour réaliser le circuit à la demande. Ici encore on utilisera en fabrication des masques personnalisés pour chacune des couches diffusées et des métallisations. Le concept est très semblable de celui des circuits à la demande. La seule différence réside dans la réalisation du schéma puisque l'on accède à une bibliothèque de cellules prédéfinies générant de très nombreuses fonctions élémentaires ou élaborées. Cette dernière constitue un véritable catalogue dans lequel le concepteur se sert pour constituer son schéma. Il existe trois types de cellules : UAvantages et inconvénients de l'utilisation d'ASIC U D'une manière générale l'utilisation d'un ASIC conduit à de nombreux avantages provenant essentiellement de la réduction de la taille des systèmes. Il en ressort : Dans l'approche des circuits pré diffusés et personnalisés, l'inconvénient majeur réside dans le fait du passage obligatoire chez le fondeur ce qui implique des frais de développement élevés du circuit. En général le fondeur ne souhaite pas intervenir dans la phase de conception ; sa tâche est de réaliser le composant à partir des masques. Dans le but de réduire les surcoûts dus aux modifications, il s'avère nécessaire d'être rigoureux lors de la phase de développement de telle sorte que le circuit prototype fonctionne dès les premiers essais : c'est réussi dans environ 60% des cas. De plus dans de nombreuses applications, l'utilisateur doit concevoir les programmes de testabilité. 2.3 UFPGA (Field Programmable Gate Arrays) U [9]2.3.1. UHistoriqueU 2.3.2. UUtilisation des puces FPGAU
Figure2.5 : vertex shader et pixel
shader techniques d'algorithmes génétiques.
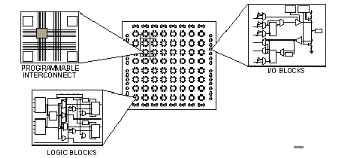
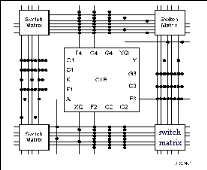
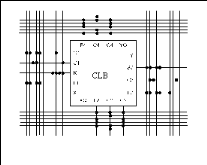
L'architecture, retenue par Xilinx, se présente sous forme de deux couches : · une couche appelée circuit configurable, · une couche réseau mémoire SRAM. La couche dite 'circuit configurable' est constituée d'une matrice de blocs logiques configurables CLB permettant de réaliser des H TUfonctions combinatoiresUTH et des H TUfonctions séquentiellesUTH. Tout autour de ces blocs logiques configurables, nous trouvons des blocs entrées/sorties IOB dont le rôle est de gérer les entrées-sorties réalisant l'interface avec les modules extérieurs (cf. figure2.7). La programmation du circuit FPGA appelé aussi LCA (logic cells arrays) consistera par le biais de l'application d'un potentiel adéquat sur la grille de certains transistors à effet de champ à interconnecter les éléments des CLB et des IOB afin de réaliser les fonctions souhaitées et d'assurer la propagation des signaux. Ces potentiels sont tout simplement mémorisés dans le réseau mémoire SRAM.
Figure2.7 :Architecture interne d'un FPGA. Les circuits FPGA du fabricant Xilinx utilisent deux types de cellules de base : · les cellules d'entrées/sorties appelés IOB (input output bloc), · les cellules logiques appelées CLB (configurable logic bloc). Ces différentes cellules sont reliées entre elles par un réseau d'interconnexions configurable.
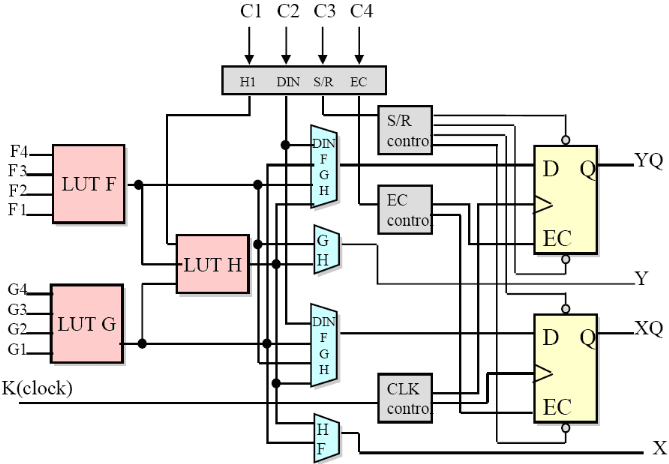
Figure2.8: Cellule logique (CLB) Voyons d'abord le bloc logique combinatoire qui possède deux générateurs de fonctions F' et G' à quatre entrées indépendantes (F1...F4, G1...G4), lesquelles offrent aux concepteurs une flexibilité de développement importante car la majorité des fonctions aléatoires à concevoir n'excède pas quatre variables. Les deux fonctions sont générées à partir d'une table de vérité câblée inscrite dans une zone mémoire, rendant ainsi les délais de propagation pour chaque générateur de fonction indépendants de celle à réaliser. Une troisième fonction H' est réalisée à partir des sorties F' et G' et d'une troisième variable d'entrée H1 sortant d'un bloc composé de quatre signaux de contrôle H1, Din, S/R, Ec. Les signaux des générateurs de fonction peuvent sortir du CLB, soit par la sortie X, pour les fonctions F' et G', soit Y pour les fonctions G' et H'. Ainsi un CLB peut être utilisé pour réaliser: · deux fonctions indépendantes à quatre entrées indépendantes, plus une troisième fonction de trois variables indépendantes · ou toute fonction à cinq variables · ou toute fonction à quatre variables et une autre avec quelques fonctions à six variables · ou certaines fonctions jusqu'à neufs variables. L'intégration de fonctions à nombreuses variables diminue le nombre de CLB nécessaires, les délais de propagation des signaux et par conséquent augmente la densité et la vitesse du circuit. Les sorties de ces blocs logiques peuvent être appliquées à des bascules au nombre de deux ou directement à la sortie du CLB (sorties X et Y). Chaque bascule présente deux modes de fonctionnement : un mode 'flip-flop' avec comme donnée à mémoriser, soit l'une des fonctions F', G', H' soit l'entrée directe DIN et un mode latch. La donnée peut être mémorisée sur un front montant ou descendant de l'horloge (CLK). Les sorties de ces deux bascules correspondent aux sorties du CLB XQ et YQ. Un mode dit de " verrouillage " exploite une entrée S/R qui peut être programmée soit en mode SET, mise à 1 de la bascule, soit en Reset, mise à zéro de la bascule. Ces deux entrées coexistent avec une autre entrée laquelle n'est pas représentée sur la figure, appelée le global Set/Reset. Cette entrée initialise le circuit FPGA à chaque mise sous tension, à chaque configuration, en commandant toutes les bascules au même instant soit à '1', soit à '0'. Elle agit également lors d'un niveau actif sur le fil RESET lequel peut être connecté à n'importe quelle entrée du circuit FPGA. Un mode optionnel des CLB est la configuration en mémoire RAM de 16x2bits ou 32x1bit ou 16x1bit. Les entrées F1 à F4 et G1 à G4 deviennent des lignes d'adresses sélectionnant une cellule mémoire particulière. La fonctionnalité des signaux de contrôle est modifiée dans cette configuration, les lignes H1, DIN et S/R deviennent respectivement les deux données D0, D1 (RAM 16x2bits) d'entrée et le signal de validation d'écriture WE. Le contenu de la cellule mémoire (D0 et D1) est accessible aux sorties des générateurs de fonctions F' et G'. Ces données peuvent sortir du CLB à travers ses sorties X et Y ou alors en passant par les deux bascules.
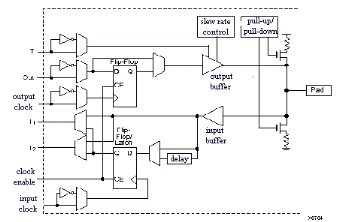
Figure2.9 : Input Output Block (IOB). 2.3.3.2.1Configuration en
entrée
Nous distinguons les possibilités suivantes : · inversion ou non du signal avant son application à l'IOB, · synchronisation du signal sur des fronts montants ou descendants d'horloge, · mise en place d'un " pull-up " ou " pull-down " dans le but de limiter la consommation des entrées sorties inutilisées, · signaux en logique trois états ou deux états. Le contrôle de mise en haute impédance et la réalisation des lignes bidirectionnelles sont commandés par le signal de commande Out Enable lequel peut être inversé ou non. Chaque sortie peut délivrer un courant de 12mA. Ainsi toutes ces possibilités permettent au concepteur de connecter au mieux une architecture avec les périphériques extérieurs.
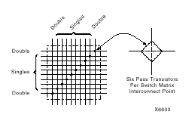
Les connexions internes dans les circuits FPGA sont composées de segments métallisés. Parallèlement à ces lignes, nous trouvons des matrices programmables réparties sur la totalité du circuit, horizontalement et verticalement entre les divers CLB. Elles permettent les connexions entre les diverses lignes, celles-ci sont assurées par des transistors MOS dont l'état est contrôlé par des cellules de mémoire vive ou RAM. Le rôle de ces interconnexions est de relier avec un maximum d'efficacité les blocs logiques et les entrées/sorties afin que le taux d'utilisation dans un circuit donné soit le plus élevé possible. Pour parvenir à cet objectif, Xilinx propose trois sortes d'interconnexions selon la longueur et la destination des liaisons. Nous disposons : · d'interconnexions à usage général, · d'interconnexions directes, · de longues lignes.
Ce système fonctionne en une grille de cinq segments métalliques verticaux et quatre segments horizontaux positionnés entre les rangées et les colonnes de CLB et de l'IOB.
Figure2.10 : Connexions à usage général et détail d'une matrice de commutation Des aiguilleurs appelés aussi matrices de commutation sont situés à chaque intersection. Leur rôle est de raccorder les segments entre eux selon diverses configurations, ils assurent ainsi la communication des signaux d'une voie sur l'autre. Ces interconnexions sont utilisées pour relier un CLB à n'importe quel autre. Pour éviter que les signaux traversant les grandes lignes ne soient affaiblis, nous trouvons généralement des buffers implantés en haut et à droite de chaque matrice de commutation.
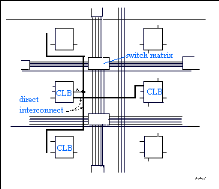
Ces interconnexions permettent l'établissement de liaisons entre les CLB et les IOB avec un maximum d'efficacité en terme de vitesse et d'occupation du circuit. De plus, il est possible de connecter directement certaines entrées d'un CLB aux sorties d'un autre.
Figure2.11 : Les interconnexions directes Pour chaque bloc logique configurable, la sortie X peut être connectée directement aux entrées C ou D du CLB situé au-dessus et les entrées A ou B du CLB situé au-dessous. Quant à la sortie Y, elle peut être connectée à l'entrée B du CLB placé immédiatement à sa droite. Pour chaque bloc logique adjacent à un bloc entrée/sortie, les connexions sont possibles avec les entrées I ou les sorties O suivant leur position sur le circuit.
Les longues lignes sont de longs segments métallisés parcourant toute la longueur et la largeur du composant, elles permettent éventuellement de transmettre avec un minimum de retard les signaux entre les différents éléments dans le but d'assurer un synchronisme aussi parfait que possible. De plus, ces longues lignes permettent d'éviter la multiplicité des points d'interconnexion.
Figure2.12 : Les longues lignes
Les performances des interconnexions dépendent du type de connexions utilisées. Pour les interconnexions à usage général, les délais générés dépendent du nombre de segments et de la quantité d'aiguilleurs employés. Le délai de propagation de signaux utilisant les connexions directes est minimum pour une connectique de bloc à bloc. Quant aux segments utilisés pour les longues lignes, ils possèdent une faible résistance mais une capacité importante. De plus, si on utilise un aiguilleur, sa résistance s'ajoute à celle existante.
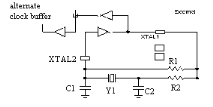
Placé dans un angle de la puce, il peut être activé lors de la phase de programmation pour réaliser un oscillateur. Il utilise deux IOB voisins, pour réaliser l'oscillateur dont le schéma est présenté ci-dessous. Cet oscillateur ne peut être réalisé que dans un angle de la puce où se trouve l'amplificateur prévu à cet effet. Il est évident que si l'oscillateur n'est pas utilisé, les deux IOB sont utilisables au même titre que les autres IOB.
Figure2.13 : L'oscillateur à quartz 2.3.4 ULes caractéristiquesU [7] Le tableau présenté ci-dessous désigne la quantité de ressources disponible pour les différents composants de la série 4000E proposée par le fabricant Xilinx.
UTableau2.1 : URessources de la série 4000EU Ces composants sont disponibles dans tous types de boîtiers adaptés au nombre de sorties et à la technologie utilisée pour le montage des circuits FPGA sur des cartes électroniques. Nous pouvons utiliser des boîtiers de type PGA, PLCC et PQFP. 2.3.5 Technique de programmation des FPGA [7]Les circuits FPGA ne possèdent pas de programme résident. A chaque mise sous tension, il est nécessaire de les configurer. Leur configuration permet d'établir des interconnexions entre les CLB et IOB. Pour cela, ils disposent d'une RAM interne dans laquelle sera écrit le fichier de configuration. Le format des données du fichier de configuration est produit automatiquement par le logiciel de développement sous forme d'un ensemble de bits organisés en champs de données. Le FPGA dispose de quatre modes de chargement et de trois broches M0, M1, M2 lesquelles définissent les différents modes. Ces modes définissent les différentes méthodes pour envoyer le fichier de configuration vers le circuit FPGA, selon deux approches complémentaires :
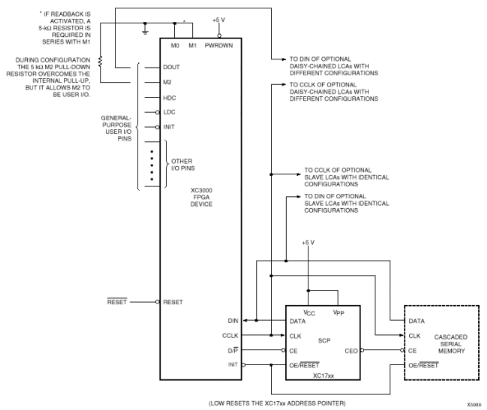
2.3.5.1 Mode maître série Le mode maître série utilise une mémoire à accès série de type registre à décalage commercialisée par le fabricant Xilinx. Le programme est préalablement chargé par le système de développement utilisé pour le circuit FPGA. Le FPGA génère tous les signaux de dialogue nécessaires pour la copie du contenu de la PROM dans sa RAM interne, lorsque la copie est terminée, il bascule le signal DONE pour le signaler au circuit. Comme nous pouvons le remarquer sur la figure, une seule PROM peut configurer plusieurs circuits FPGA avec la même configuration ou plusieurs PROM peuvent configurer plusieurs FPGA en chaîne où le premier des circuits FPGA est le maître et génère l'horloge. Les données en provenance des PROM sont envoyées aux autres circuits FPGA par la sortie DOUT de ce premier
Figure2.14 : Mode maître série
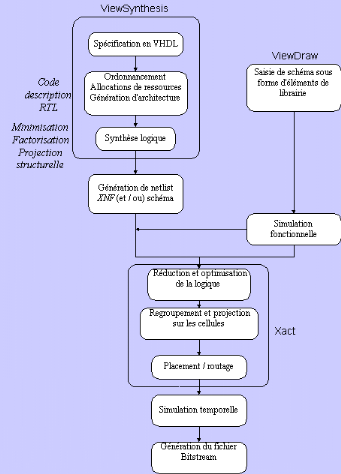
Figure2.15 : Schémas de programmation en mode maître série On dispose aussi d'un mode maître-parallèle où le FPGA est relié en parallèle à une EPROM classique, de même qu'un mode passif type périphérique dans lequel le FPGA est considéré comme un périphérique de uP et peut-être configuré à partir de celui-ci 2.3.5.2 Mode esclave Dans ce mode, le programme de configuration peut être envoyé à partir d'un PC, d'une station de travail ou à partir d'un autre circuit FPGA. Le circuit FPGA maître peut être interfacé à une mémoire en mode parallèle ou série sans apporter aucune modification au niveau du câblage des circuits FPGA esclaves. C'est souvent le mode exploité pour la mise au point d'une configuration. 2.3.6 Les outils de développement des FPGA [7] Xilinx a développé des logiciels de développement performants capables de fonctionner sur des stations de travail telles que Sun, Appolo, Dec et sur des PC AT disposant d'une mémoire suffisante. La programmation des circuits FPGA est réalisée à l'aide des logiciels Viewlogic (Workview Office 7.31) et Xact (Design Manager 6.01). Elle est décomposée en plusieurs étapes : · la synthèse logique, · la simulation fonctionnelle, · l'optimisation, la projection et le placement / routage, · la simulation temporelle, · la génération de fichier de configuration. 2.3.6.1 La synthèse logique La synthèse logique peut s'effectuer de diverses manières avec différentes interfaces afin de générer le circuit électrique, parmi lesquelles nous pouvons citer : · une entrée de type équations logiques de " haut niveau ", de table de vérité et de machine d'état avec une interface comme ABEL, · une entrée de type schématique " bas niveau " avec une interface comme ViewDraw, · une entrée de type textuelle " haut niveau " avec le VHDL à l'aide d'une interface comme ViewSynthesis, Synopsis, Alliance et ISE ou le HDL de Verilog à l'aide d'une interface comme Cadence Opus. Nous allons voir en détail la synthèse logique avec une entrée schématique et une entrée en VHDL. 2.3.6.1.1 Saisie de schéma A l'aide de l'interface ViewDraw, la réalisation de circuits se fait à base de cellules standards (portes logiques pré caractérisées). On décrit la structure d'un circuit à l'aide de connexions sur des cellules de base à partir d'une librairie. Il existe deux types de cellules dans la librairie Xilinx : · les soft-macros qui sont implantées en fonction des flips-flops et des générateurs de fonctions disponibles, · les hard-macros qui sont préroutées et utilisent complètement les CLB qu'elles occupent. La saisie de schéma à partir de cellules de base permet un développement " bas niveau " qui rend difficile la réalisation de circuits complexes où chaque changement ou amélioration remet en cause toute la description. Cette contrainte a conduit à étudier des techniques de génération de circuits à partir de spécifications de " haut niveau " tel que le VHDL (VHSIC Hardware Description Language avec VHSIC : Very High Speed Integrated Circuits) qui se traduit en français par : langage de description de matériel traitant des circuits intégrés à très grande vitesse. 2.3.6.1.2 La synthèse en VHDL La méthodologie [XILI98] [VIEW94] de la synthèse en VHDL se compose de trois étapes : · spécification en VHDL, · synthèse du code VHDL, · implantation physique. 2.3.6.1.2.1 Spécification en VHDL Le langage VHDL est un langage de description de matériel qui permet de synthétiser des fonctions logiques complexes. A l'aide de ce langage, la première description définit la fonctionnalité du circuit en terme de blocs définis " haut niveau ". Progressivement, les blocs sont détaillés précisément jusqu'à une description proche des ressources matérielles. En effet, le langage VHDL autorise trois niveaux de description : · le niveau structurel décrit le câblage des composants élémentaires, · le niveau flot de données décrit les transformations d'un flot de données de l'entrée à la sortie, · le niveau comportemental décrit le fonctionnement par des blocs programmes appelés Processus qui échangent des données au moyen de signaux comprenant des instructions séquentielles. 2.3.6.1.2.2 Synthèse du code VHDL La synthèse permet à partir d'une spécification VHDL, la génération d'une architecture au niveau transfert de registre RTL (register transfert level) qui permet l'ordonnancement et l'allocation de ressources sans une représentation physique, compilable par un outil de synthèse logique. Cette étape est réalisable à condition de se limiter à un sous ensemble du langage VHDL qui soit strictement synthétisable. 2.3.6.1.2.3 Implantation physique La spécification VHDL est directement émulée sur un support matériel tel qu'un circuit FPGA en précisant la famille utilisée pour une implantation physique du circuit. La compilation du code VHDL en code FPGA permet de générer le schéma correspondant et une netlist (XNF) constituée d'une liste d'équations booléennes et d'informations portant sur les entrées / sorties du circuit. L'outil de synthèse ViewSynthesis ne permet pas de faire une simulation comportementale à partir du code VHDL, par conséquent il faut réaliser ces trois étapes à tous les niveaux de conception avant de faire une simulation fonctionnelle. 2.3.6.2 Simulation fonctionnelle ViewSim est une interface qui, à partir de vecteurs d'entrée (reset, clk...etc.) appliqués sur certains noeuds du schéma et à partir d'une modélisation des composants, va générer sur chaque noeud du schéma des signaux représentant le fonctionnement réel du circuit. Nous pouvons visualiser la forme des signaux à l'aide de l'interface ViewTrace. La simulation fonctionnelle ne tient pas compte des capacités de liaison dues au routage entre les différentes cellules. Elle permet donc de vérifier uniquement la validité du circuit par rapport au cahier des charges d'un point de vue fonctionnel et non d'un point de vue temporel. 2.3.6.3 Optimisation, projection et placement / routage 2.3.6.3.1 Optimisation Avant l'utilisation de la netlist, celle-ci est optimisée. Cette étape gère les problèmes de sortance des signaux par la duplication des fonctions logiques de sortance insuffisante, afin de multiplier les sortances. Les signaux inutilisés sont retirés, les expressions booléennes sont simplifiées, les signaux équivalents sont détectés. 2.3.6.3.2 Projection La phase de projection dépend du circuit utilisé, les équations de la netlist sont transformées, regroupées en de nouvelles équations ayant un nombre d'arguments inférieur ou égal au nombre de paramètres du bloc logique correspondant à la famille de circuit utilisée. 2.3.6.3.3 Placement / routage L'étape suivante consiste à attribuer les cellules (CLB) du circuit à chaque équation délivrée par la projection et à définir les connexions. L'algorithme de placement place physiquement les différentes cellules et les chemins d'interconnexion dessinés entre les cellules afin de faciliter le routage. Des directives jointes à la netlist permettent une bonne répartition des cellules. Ces trois opérations sont réalisées par le logiciel Xact (Designer Manager). 2.3.6.4 Simulation temporelle Il s'agit de vérifier la fonctionnalité du circuit en prenant en compte par un calcul estimatif les longueurs d'interconnexion et les retards apportés par les capacités parasites liées au partionnement et au routage. La simulation temporelle vérifie que la fonctionnalité n'a pas été modifiée par l'introduction des délais de propagation et reste conforme au cahier des charges. 2.3.6.5 Génération du fichier de configuration La dernière étape consiste à générer un fichier de configuration appelé Bitstream dans une PROM. Ce fichier contient les informations fournies au composant FPGA Xilinx afin qu'il prenne la configuration souhaitée. Ci-dessous, l'organigramme représentant la procédure de programmation des circuits FPGA :
Figure2.16 : Programmation des composants FPGA [7] |
|