Chapitre 1
Les systèmes d'informations
hospitaliers et la gestion hospitalière
1.1 Introduction
Actuellement, les établissements de soins font face
à une forte croissante du nombre de cas d'hospitalisation, et ceci,
c'est depuis l'apparution de la pandémie à COVID-19 où le
nombre d'hospitalisation a accru dans plusieurs pays du monde [7]. Pour ce
faire, il est donc question pour les services de santé,
d'améliorer leurs conditions de fonctionnement par une bonne gestion des
structures sanitaires et ainsi, parvenir à consolider la qualité
de soin pour permettre les entrées et sorties au sein de n'importe
quelle unité médicale. Ceci sera alors effectif, par le fait de
bien conserver les informations médicales, pour savoir administrer un
médicament à un quelconque patient et ne pas le faire
fortuitement.
D'une manière plus générale, les
Systèmes d'Informations Hospitaliers (SIH) s'occupent de la gestion de
l'ensemble des informations, de leurs règles d'utilisation et de leur
circulation. De plus, ils font face au stockage et au traitement des
données pour répondre aux besoins quotidiens des
établissements de soins ([11] et[19]).
Les performances et la qualité des services de soins
reposent sur la qualité et la quantité des informations
collectées dans les SIH. La DDS constitue un des indicateurs
d'évaluation le plus utilisé et sa prédiction basée
sur les données disponibles dans les SIH a été au centre
d'un grand nombre de travaux de recherche. Le problème de la
prédiction des durées
6
de séjours hospitaliers a été
abordé sous différents angles dans des recherches
précédentes. [19].
Le but de ce chapitre est de vouloir mettre à la
lumière du soleil certaines informations sur le Système
d'Information Hospitalier en partant de la sorte : tout d'abord nous allons
décrire les systèmes d'Information Hospitalier d'une
manière générale en parlant de la sources de ces
informations ainsi que des propriétés y afferantes. En suite,
nous allons parler de la durée de séjour hospitalier et les
facteurs influençant cette dernière pour enfin chutter avec le
rôle des machines learning dans tout ceci.
1.2 Les systèmes d'informations hospitaliers 1.2.1
Terminologie
Définition 1.1 Un Système
d'Information Hospitalier (SIH) est un Système
informatique destiné à faciliter la gestion de l'ensemble des
informations médicales et administratives d'un hôpital. Selon
[19], on appelle système d'information l'ensemble des
outils matériels, des logiciels et des réseaux de
télécommunications utilisés pour recueillir, créer
et distribuer des données utiles dans des organisations.
En particulier, un Système d'Informations Hospitalier
(SIH) désigne un système conçu pour gérer
l'ensemble des données médicales et administratives d'un
hôpital. Il se constitue d'un groupe d'éléments en
communication qui rassemblent, traitent et fournissent les informations
nécessaires à son activité.
Définition 1.2 Un Système
d'information de l'hôpital est un ensemble des
éléments en interaction ayant pour objectif de rassembler,
traiter et fournir les informations nécessaires à son
activité.
Définition 1.3 Un Système
d'Information de Santé (SIS) est un Système
d'information global, regroupant tous les types d'acteurs et ressources de
santé.
1.2.2 Type d'informations
Dans un milieu hospitalier, plusieurs informations sont
récueillies, tantôt lors de l'admission du patient et au fur et
à mesure que le patient augmente son séjour à l'hopital.
On a donc besoin souvent des informations antérieures du patient et
quelques informations administratives. Selon [19], ces informations comprennent
les données démographiques sur les patients, les
étapes de son suivi, les complications, les médicaments, les
signes vitaux, les antécédents médicaux, les
immunisations, les données de laboratoire et les rapports de radiologie
[HIM]. Les informations administratives concernent la gestion
opérationnelle d'un hôpital en matière de soins de
santé. Elles englobent les informations de la gestion des patients
(parcours, facturation, actes médicaux), la gestion de la finance et de
la comptabilité (budget, ressources matérielles, achats) et la
gestion des ressources humaines (affectations, planning, payement).
Le SIH est scindé en trois sous-systèmes comme
illustre la figure 1.1 ([11], [18] et[19] )
:

7
FIGURE 1.1 - Composantes des Systèmes d'Informations
Hospitaliers [11]
8
Le sous-système de production des
soins
Ce volet s'occupe de l'administration des données
patients, les unités de soins, la communication entre ces unités
et la gestion de la recherche et de l'enseignement médicaux. Il contient
toutes les données liées au patient comme par exemple : le
diagnostic médical, les prescriptions et la réalisation des actes
médicaux, l'édition des comptes rendus et les
résumés de dossier sont présentes au sein de ce
sous-système.
Le sous-système d'information
logistique
L'objectif est donc de mieux organiser les activités et
les structurer afin d'assurer une meilleure qualité de soins des
patients. Le sous-système d'information logistique permet de
gérer les différents ressources matérielles, humaines,
physiques et financières de l'hôpital. Il englobe la gestion de
stocks et des approvisionnements, la gestion des locaux, la gestion des
facturations et des commandes, la gestion des lits d'hospitalisation et de
soins ainsi que les archives et la documentation des établissements de
soins.
Le sous-système de pilotage
Il veille à la prise en charge de la gestion
médicoéconomique de l'hôpital. Il concerne la
qualité des soins et la gestion des risques. De plus, il
s'intéresse à l'allocation budgétaire des
différentes unités de soins .
Ces sous-systèmes sont souvent en interaction afin
d'assurer la continuité des services de soins, améliorer leur
qualité et gérer les ressources et les contraintes
budgétaires. Compte tenu du grand volume des données des SIH,
divers formats de stockage sont apparus. Ces données proviennent de
multiples sources et font l'objet de plusieurs études dans le domaine
médical. Quoi que ces données existent, elles proviennent de
quelque part effectivement. Dans la partie suivante, nous allons parler des
différentes sources des données hospitalières.
9
1.3 Sources des données des SIH
Les progrès technologiques et les progrès des
processus de traitement des données ont permis une augmentation
exponentielle de la quantité des données collectées dans
le domaine de la santé. Le volume des données contenues dans les
SIH ne cessent de croître. En fonction de leur type, les données
sont recueillies à partir de différentes sources. Ces sources de
données sont nombreuses et diffèrent selon le type de collecte,
le format de représentation et la nature des informations. Les
principales sources des données médicales sont : les dossiers
médicaux, les enquêtes auprès des patients et les
données administratives utilisées pour payer les factures ou
gérer les soins ([20],[19]). Dans ce qui suit, nous détaillons
les sources de données .
1.3.1 Dossier médical du patient
Il comporte les données démographiques du
patient acquises au moment de son admission : sa date de naissance, son
adresse, son statut marital et son sexe. Il contient également les
données liées à son état de santé comme les
résultats des analyses biologiques et les transcriptions
médicales, les résultats d'examens radiologiques, le diagnostic
médical, les antécédents médicaux et les rapports
textuels cliniques.
1.3.2 Les données administratives
Elles peuvent inclure les données des facturations et
des remboursements des séjours hospitaliers des patients. Les
données de facturation sont souvent liées aux motifs
d'hospitalisation représentés à l'aide de la Codification
Internationale des Maladies (CIM) et aux procédures que le patient a
subi au cours de son séjour. Les données administratives
comportent aussi des informations sur le type de l'unité
médicale, l'admission du patient, le nombre d'unités dans
lesquelles le patient est passé (ou le nombre de jours passés
dans chaque unité).
10
1.3.3 Les données issues des enquêtes et de
la recherche clinique
Une source importante des données médicales est
apparue avec l'explosion de l'utilisation d'internet comme moyen de
communication. Les données de santé peuvent provenir des
échanges des patients sur les réseaux sociaux et des recherches
effectuées sur le web. Elles proviennent également des
études cliniques réalisées par les professionnels de
santé, les scientifiques et les industriels.
1.4 Propriétés des données
médicales
"S'agissant des données de santé,
informations éminemment sensibles, la tentation est exacerbée de
se prévaloir d'un droit de propriété pour se garantir une
meilleure protection contre tout usage préjudiciable" N.
MALLET-POUJOL cité dans [9].
Vu que les données médicales doivent être
protégées comme vu dans la section 1.3, il existe des
données à caractère privé. Des lois pour palier
à un quelconque dérapage des données médicales sont
aussi de structe application.
Les données médicales sont à conserver
jalousement non seulement du fait qu'elles sont sensibles, mais aussi car elles
sont utilisées par des chercheurs, les hopitaux eux-mêmes, ... ces
dernières nous aident même à l'organisation des
établissements de soins, l'identification de profils homogènes de
patients, le suivi des parcours des patients et la recherche de leur diagnostic
médical. Cependant, avant d'utiliser ces données, il est
primordial de procéder à leur annotation, de les intégrer
et de les pré-renseigner de manière appropriée afin de
faciliter leur compréhension. La compréhension et la manipulation
des données médicales se heurtent à des défis
liés à leur complexité, la richesse des informations aussi
qu'à des contraintes de confidentialité [19]. Il existe donc des
garentis juridiques pour n'importe quel dérapage de la part des
données médicales [20].
La figure 1.2 nous illustre les différentes
propriétés des données médicales ainsi que leurs
sources. Particulièrement, les données que nous avons
utilisées dans l'analyse de ce présent travail ne sont pas loin
de respecter ces critères ici.
Les sous-sections suiventes nous servirons de détail
pour les propriétés du SIH en paraphrasant [19].

11
FIGURE 1.2 - Données médicales : sources et
propriétés [19]
1.4.1 Confidentialité
Selon l'article 4 du Règlement Général
sur la Protection des Données (RGPD) de l'Union Européenne :
« les données relatives à la santé physique ou
mentale d'une personne physique, y compris la prestation de services de soins
de santé, qui révèlent des informations sur l'état
de santé de cette personne » sont définies comme
données à caractère personnel. Ces donnes doivent donc
être protégées et une politique et une démarche de
sécurité de ces données doivent être définies
pour les protéger. Si la protection des données est un enjeu
majeur, d'autres risques liés au matériel et à
l'infrastructure informatique sont également des points d'attention
récurrents. Les données médicales sont exploitées
dans plusieurs recherches et études académiques et industrielles.
Elles peuvent être utilisées dans la conception des
systèmes d'aide à la décision du domaine médical,
l'amélioration des prestations de soins de santé, l'optimisation
des ressources matérielles et humaines des hôpitaux. Un processus
d'anonymisation ou de pseudo-anonymisation des données est donc utile
avant toute manipulation. L'anonymisation des données médicales
est définie comme la suppression de tout caractère identifiant un
ensemble de données d'une
12
manière irréversible. Toutes les informations
directement ou indirectement identifiables sont supprimées ou
modifiées afin d'empêcher toute ré-identification des
personnes. Quant à la pseudo-anonymisation, elle permet le retour
à l'information originale en cas de besoin particulier. Elle consiste
à remplacer les données à caractère personnel par
des pseudonymes. Cette technique est réversible et permet donc la
ré-identification ou l'étude de corrélations entre les
informations codifiées en cas de besoin particulier. De cette
manière, la réutilisation des données médicales est
possible ce qui suscite un intérêt et une demande croissante.
1.4.2 Données incrémentales
A l'aire du Big data, les données médicales ne
sont plus à ignorer. L'analyse des données massives est un
domaine en pleine croissance qui peut fournir des informations utiles dans le
domaine des soins de santé. Dans les systèmes d'aide à la
décision ou de prédiction, les éléments
collectés sont insérés dès leur
disponibilité dans le modèle comme des évènements
successifs. Un exemple qui caractérise cette particularité est de
modéliser le séjour hospitalier par un processus de trois
étapes : moment d'admission du patient, le séjour
hospitalier et la sortie du patient.
Lors de l'admission du (de la) patient(e), des informations
démographiques comme l'âge, l'adresse, le genre et l'état
civil sont acquises ainsi que des informations administratives comme le type
d'admission au service concerné, le motif d'hospitalisation et
l'unité médicale dans laquelle le patient est admis.
Au cours du séjour hospitalier, d'autres informations
médicales et administratives s'ajoutent. Par exemple les actes
médicaux réalisés pour le patient, les complications
médicales et les transferts entre unités médicales.
Et au finish, à la sortie du (de la) patient(e), les
rapports médicaux effectués par les médecins ou les
infirmiers sont élaborés. La régularisation de la facture,
la durée de séjour du patient et son mode de sortie sont
prélevés.
13
1.4.3
Hétérogénéité
De nos jours, il est nécessaire d'utiliser conjointement
des données provenant de systèmes d'information qui utilisent
différentes sources de connaissances comme par exemple, les rapports
médicaux textuels et les résultats d'imagerie médicale
pour l'enregistrement des données et les utiliser dans la
résolution de nombreux problèmes dans le domaine médical.
L'exploration de ces données dites hétérogènes pour
extraire des connaissances est un processus fastidieux imposant des contraintes
opérationnelles importantes. Les données
hétérogènes sont des données dont les types et les
formats présentent une grande variabilité. Il existe
principalement 4 types d'hétérogénéité :
- L'hétérogénéité
syntaxique : Elle se produit lorsque deux sources de données ne sont pas
exprimées dans le même langage.
- L'hétérogénéité
sémantique ou conceptuelle : Elle désigne les différences
de modélisation d'un même domaine d'intérêt.
- L'hétérogénéité
terminologique : Elle désigne les variations de noms lorsqu'on se
réfère aux mêmes entités à partir de
différentes sources de données.
- L'hétérogénéité
pragmatique : Elle correspond à des interprétations
différentes des entités.
De plus, nous rajoutons
l'hétérogénéité par type de données.
Elle réside dans ce cas dans la présence de données
quantitatives ou dites numériques et qualitatives ou dites
catégorielles. Les données quantitatives sont celles qui peuvent
être comptées ou comparées sur une échelle
numérique. On distingue alors les données quantitatives continues
et discrètes. Pour le type qualitatif, on sépare le qualitatif
nominal et le qualitatif ordinal. Par exemple l'âge d'un patient est une
donnée numérique discrète, sa taille est une donnée
numérique continue, son genre est une donnée catégorielle
nominale et son niveau d'étude est une donnée catégorielle
ordinale. Nous définissons aussi le type de donnée
catégorielle multivaluée comme par exemple les diagnostics
médicaux si le patient possède plusieurs diagnostics. Le format
des données médicales peut être structuré ou non
structuré. Le format des données structurées est
organisé et formaté. Par conséquent, il est facile de
saisir, rechercher et manipuler les données structurées. A
l'inverse, les données non structurées comme par exemple les
rapports médicaux en format textuel ou les images de
14
radiologie médicale, souvent classées comme des
données qualitatives, sont plus difficiles à traiter et à
analyser. Un processus d'intégration des données
hétérogènes est crucial pour permettre aux utilisateurs de
définir leurs requêtes sans connaître leurs sources et
donner une vue uniforme de l'ensemble de ces sources.
1.4.4 Complexité
La grande quantité d'informations
générées par les systèmes d'informations de
santé, la variété des sources des données
médicales et l'hétérogénéité des
données rendent leur traitement et leur analyse plus difficile et plus
complexe soulevant ainsi plusieurs défis. Parmi ces défis, nous
retrouvons la présence de plusieurs variables ce qui engendre une grande
dimension. De plus, ces données sont souvent incomplètes et
contiennent des variables fortement corrélées entre elles
résultant de la redondance de l'information. Les données
médicales présentent également d'autres problèmes
comme la présence des données aberrantes ou des erreurs dans les
informations enregistrées. Ces problèmes imposent des
méthodes de pré-traitement des données avant de les
utiliser afin de rendre leur exploitation plus facile et fiable. La
complexité des données médicales rend primordiale
l'implication de l'expertise médicale dans leur exploitation par les
utilisateurs afin de valider, interpréter et mieux valoriser leur
contenu.
1.5 Durée De Séjour hospitalier
Définition 1.4 La Durée de
Séjour Hospitalier peut être définie
comme un séjour pendant lequel le patient peut être
hospitalisé dans plusieurs services, que l'on appelle actuellement des "
unités médicales "[4].
La figure 1.3 explique en quelques sortes la durée de
séjour hospitalier dans un hopital en passant par une ou plusieurs
unités médicales.
Face à un accroissement sans précédent du
nombre de cas d'hospitalisation, l'apparution des nouvelles maladies et ou
épidémies, la famine en RDC, les institutions sanitaires font
face à un nombre accru des patients pouvant même dépasser
la capacité d'accueil de ces derniers.
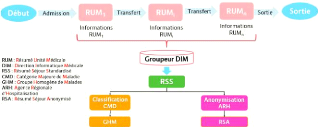
15
FIGURE 1.3 - Évaluation des systèmes de
santé : DDS [19]
Pour faire face à tout ceci, la prédiction de la
durée de séjour hospitalier est un facteur clé dans un
service de santé, car contribue à la planification et à
l'organisation des activités de soins, ainsi qu'au management des lits
réduisant leur occupation inutile [19], mais aussi savoir gérer
le personnel soignant et ouvrier pour l'assurance des malades. Chaque structure
sanitaire est donc confrontée à faire face à un
système de santé sans pareil pour permettre une bonne
compétitivité au marché des hopitaux.
Selon [19], il existe trois facteurs importants pour
définir la pertinance d'un système de santé, on peut citer
: le taux de mortalité, le nombre de réadmissions et
la durée de séjour hospitalier (DDS) .
Quant à l'unité de mesure de la DDS, elle est
mesurée en journée. Cette définition peut changer
constamment dans d'autres contextes. Dans les services d'urgence et
ambulatoire, l'admission et la sortie du patient sont réalisées
dans la même journée. De ce fait, la DDS est égale à
0 jour. La valeur de la DDS est alors calculée en nombre d'heures et
peut s'étaler sur 24 heures au maximum. Plusieurs travaux ont
étudié les flux des patients en service d'urgence en se basant
sur l'estimation du nombre d'heures du séjour du patient dans ce
service. Nous distinguons donc deux définitions majeures de la DDS : la
DDS dans des unités médicales dites « programmées
» calculée en nombre de jours passés dans ces unités
et la DDS dans des services dits « non programmés »
calculée en nombre d'heures. Dans ces deux cas, la DDS est
quantifiée par une valeur numérique discrète.
Ce qui nous permet d'affirmer qu'une Durée de
Séjour Hospitalier au délà de la moyenne provoquerait des
coûts matériels que financiers suplémentaires à
l'hopital. C'est ainsi alors
16
que la prédiction de DDS dans un service sanitaire est
d'une importance capitale pour palier à ce problème.
1.6 Facteurs influençant la DDS
La durée de séjour hospitalieur est souvent
dû à plusieurs facteurs qui sont tantôt d'origine du patient
lui-même ( c'est à dire de son âge, de sa maladie, de son
état psychique, ...) ou d'un autre facteurs exterieur. D'où alors
la durée de séjour hospitalier dépend aussi de
l'Unité médicale dans laquelle le patient est admis ([19]).
Parmi les facteurs influançant la DDS, on peut citer
([18]) :
1. Les facteurs démographiques :
l'âge, le genre et la situation familiale du patient;
2. L'historique médicale du patient
3. Les mesures des signes vitaux et des résultats
du laboratoire,
4. Etc.
Ce travail étant borné dans le service de
Gynécologie, à part les facteurs vus ci-haut, les hopitaux aussi
jouent un rôle dans la prédiction de la DDS. C'est comme le cas
par exemple de la Gynécologie obstétrique où, pour un
accouchement eutocique la DDS va de 2 à 5 jours selon les hopitaux
consultés et pour un accouchement distocique, elle va de 4 à 9
jours.
1.7 Que vient faire l'intelligence artificielle dans tous
ça ?
L'intelligence artificielle (Artificial intelligence en
anglais) englobe plusieurs techniques comme par exemple l'apprentissage
automatique (Machine Learning), la vision par ordinateur, le raisonnement, la
représentation des connaissances et la fouille de données. Ces
techniques font partie des techniques les plus utilisées de nos jours
dans les différents domaines de recherche. Les applications de l'IA
s'étendent à des domaines que l'on pensait auparavant
réservés aux experts humains des données
numérisées, d'infrastructure informatique, d'amélioration
de la puissance et de la capacité de stockage des ordinateurs,
17
le domaine médical est identifié comme l'un des
domaines les plus promoteurs de l'IA. L'apprentissage automatique ou le Machine
Learning (ML) en anglais, est une technique de l'IA largement employée
dans les recherches cliniques. Elle est apparue dans les années
1950 avec Alan Turing quand il a écrit
un article sur « Computing machinery and intelligence » dans
lequel il explique que pour démontrer l'intelligence d'une machine, elle
doit être capable d'exécuter des tâches humaines de telle
sorte que personne ne peut la différencier de celle d'un être
humain.
La figure 1.4 illustre les principales techniques de
l'Intelligence Artificielle et leurs applications [19].

FIGURE 1.4 - Techniques de l'Intelligence Artificielle et leurs
applications [19]
L'apprentissage automatique consiste à doter les machines
de capacités d'analyse, d'apprentissage et de
généralisation à partir des données. L'objectif est
de résoudre des problèmes pour lesquels il aurait
été difficile de trouver une solution avec des approches
informatiques traditionnelles. Il existe quatre types d'apprentissage
automatique : l'apprentissage supervisé, l'apprentissage
non-supervisé, l'apprentissage semi-supervisé et l'apprentissage
par renforcement. En médecine, selon les nouvelles techniques de l'IA,
plusieurs solutions sont en train de voir le jour comme c'est le cas par
exemple de la prédiction du cancer, dans la prédiction d'une
quelconque réadmission à l'hopital [13], ...
Comme nous pouvons le constanter, la Nouvelle Technologie de
l'Information et de la Communication (NTIC) est au service de toute la
communauté et ceci par l'apparution de l'Intelligence Artificielle
où les machines prennent certaines décisions que prennaient
18
les humains dans l'ancien temps. Faudra-t-il que ceci soit
possible sans nous interroger comment ça marche ? La mise en place d'un
Algorithme de Machine Learning se fait le plus souvent par le canal de certains
algorithmes (Modèles de prédiction). La partie suivante sera
concencrée à certains modèles de machine learning qui nous
servirons dans les deux derniers chapitres.
19
| 

