III.4.1.Algorithmes d'apprentissage
L'apprentissage avec des réseaux de neurones
multicouches se fait principalement suivant deux approches :
· Approche par retro propagation de gradient (RPG) La
retro propagation de gradient détermine les poids de minimisation d'un
cout. Cet algorithme nécessite l'introduction de l'architecture de
réseau.
· Approche constructive Avec cette approche, on apprend
en même temps le nombre d'unités et les poids, commençant
généralement avec une seule unité. Voici quelques
exemples des algorithmes d'apprentissage des réseaux de
neurones :
III.4.1.1. Algorithme de
HEBB
Cet algorithme se déroule en 5 étapes de la
manière suivante :
Etape 1 : initialisation des poids
Etape 2 : présentation d'une entrée ?? =
(??1,2, ...) de la base d'apprentissage.
Etape 3 : calcul de la sortie x pour l'entrée E telle
que :
?? = ? (????*????) - ??
?? = ??????????(??)
??????> 0 ???????????? = +1 ???????????? = -1
Etape 4 : si la sortie calculée x est différente
de la sortie désirée alors il y a modification des poids.
Etape 5 : Retour à l'étape 2.
III.4.1.2. Algorithme
d'apprentissage du perceptron
Cet algorithme nécessite :
ï Les exemples d'apprentissage ??.
ï Chaque exemple xi possède P attributs
dont les valeurs sont notées????.
ï Pour chaque donnée, ????,0 est un
attribut virtuel, toujours égal à 1. La classe de l'exemple
???? est ????
Nécessite :
Taux d'apprentissage ????]0,1]
Nécessite :
ï Un seuil ??
Initialiser les ???? aléatoirement
Répéter
// E mesure l'erreur courante
?? ? 0
Mélanger les exemples
Pour tous les exemples du jeu d'apprentissage?? faire
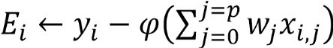
?? ? ?? + |????|
Pour tous les poids ????, ??? {0,1, ... ??} faire
???? ? ???? + ????i??i, ??
Fin pour fin pour jusque ??<??
III.4.1.3. Algorithme de
propagation de gradient pour un perceptron
Nécessite : les ?? instances d'apprentissage ??
Nécessite : taux d'apprentissage ????]0,1]
Nécessite : un seuil ??
Initialiser les ????,{0, ... ??}
aléatoirement Répéter
//E mesure de l'erreur courante
?? ? ??
Pour tous les poids ????,{0,...??} faire
(????) ? 0
fin pour mélanger les exemples pour tous les exemples
du jeu d'apprentissage ????,{1,??} faire
?? ? ?? + (???? - (????))2
Pour tous les poids ????,{0,...??}
faire
??(????) ? ??(????) +
??(????- ??(????)????,??
fin pour tous les poids
????,{0,...??} faire
????? ????+ (????) Avec
:?(??) = -???(??) fin pour jusque ??<??
Fin pour Fin tant que
Le choix de l'algorithme à utiliser dépend de
l'architecture du réseau des neurones. Si, les données sont
linéairement séparables, un perceptron suffit pour faire la
prédiction et dans ce cas, l'algorithme de Hebb ou perceptron peuvent
s'utiliser mais quand les données ne sont pas linéairement
séparables, c'est prouvé par Hornick (1991) que pour la tache de
classification, un réseau de neurones avec une seule couche
cachée de perceptron Sigmoïdes et une couche de sortie peut
résoudre tout problème de classification et dans ce cas , on peut
utiliser l'algorithme de retro-propagation du gradient.
| 

