III.1.3.2. Méthodes prédictives
Les méthodes prédictives consistent à
partir d'une collection des données, produit une prédiction d'une
valeur quelconque.Un prédicateur est une procédure, une
fonction mathématique ou un algorithme qui, à partir d'un
ensemble d'exemples, produit une prédiction d'une valeur quelconque.
Mathématiquement, la base d'apprentissage est un
doublet 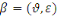 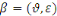 où où 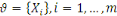 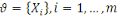 est l'ensemble des observations définies sur est l'ensemble des observations définies sur 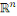 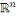 décrivant les formes et : décrivant les formes et :
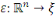
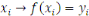
Est la fonction de prédiction. Les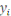 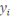 sont les sorties et sont les sorties et   est appelé prédicteur. est appelé prédicteur.
§ Si 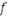 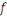 est une fonction continue, on parle alors de
régression. Dans ce cas, la fonction de prédiction (ou
le prédicteur) est alors appelée un régresseur.
Un régresseur est donc une fonction mathématique ou un algorithme
qui réalise les tâches de régression. est une fonction continue, on parle alors de
régression. Dans ce cas, la fonction de prédiction (ou
le prédicteur) est alors appelée un régresseur.
Un régresseur est donc une fonction mathématique ou un algorithme
qui réalise les tâches de régression.
En clair, le problème de prédiction est dit de
régression si la valeur à sortie est numérique, par
exemple la température qu'il fera le mois prochain, etc.
Il existe plusieurs modèles de régression
actuellement, à savoir : la régression linéaire, la
régression non-linéaire, qui peuvent être simple ou
multiple, la régression logistique, etc.
§ Si 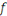 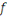 est une fonction discontinue, on parle alors de classement.
Dans ce cas, le prédicteur est appelé classifieur. Un
classifieur est donc une fonction mathématique ou un algorithme qui
réalise les tâches d'affectation. est une fonction discontinue, on parle alors de classement.
Dans ce cas, le prédicteur est appelé classifieur. Un
classifieur est donc une fonction mathématique ou un algorithme qui
réalise les tâches d'affectation.
Ce qui veut dire, le problème de prédiction est
dit de classement si la valeur de sortie est catégorielle ou une
étiquette, par exemple lors de l'analyse des données fiscales, la
valeur, la valeur « frauduleux » ou « non frauduleux ».
Plusieurs modèles sont utilisés pour résoudre le
problème de classement, à savoir : Réseaux de
neurones, l'Arbre de décision, le Séparateur à Vaste Marge
(SVM) ou les Réseaux de Bayes, etc.
On peut alors synthétiser les méthodes de
Fouille de données sous forme de tableau suivant :
Tableau 3.3: Méthodes de
Fouille de données.
|
Méthodes (Algorithmes)
|
Types de methodes
|
Exemples
|
|
Méthodes Descriptives
|
Méthodes factorielles
|
Analyse en Composante Principale (A.C.P), Analyse Factorielle
des Correspondances (A.F.C), Analyse Factorielle Discriminante (A.F.D), Analyse
de Correspondances Multiples (ACM).
|
|
Méthodes de classification (ou segmentation)
|
Méthodes de partitionnement :
La méthode de k-means (Centres mobiles), la
méthode de nués dynamiques, le modèle de mélange
gaussien, les réseaux de Kohonen.
|
|
Méthodes hiérarchiques :
La Classification Ascendante Hiérarchique (C.A.H) et la
Classification Descendante Hiérarchique (C.D.H)
|
|
Méthodes Prédictives
|
Méthodes de régression
|
Modèle de régression linéaire, Modèle
de régression non linéaire, Modèle de régression
logistique, Modèle log-linéaire, Réseaux de neurones,
l'Arbre de décision, le Séparateur à Vaste Marge (SVM),
les Réseaux de Bayes, Méthode de   -plus proche voisin. -plus proche voisin.
|
|
Méthodes de classement
|
Analyse Discriminante Prédictive, Réseaux de
neurones, l'Arbre de décision, le Séparateur à Vaste Marge
(SVM), les Réseaux de Bayes, Méthode de   -plus proche voisin. -plus proche voisin.
|
| 

