Administration d'un big data sous mongodb et extraction de connaissance par réseau de neurones.par Destin CUBAKA BENI Université Pédagogique Nationale (UPN) - Licence 2019 |

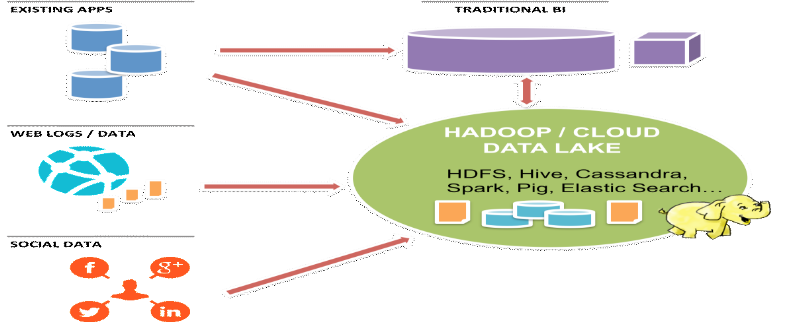
I.9. DIFFERENCES AVEC L'INFORMATIQUE TRADITIONNELLE OUDECISIONNELLELes principales différences entre les données traditionnelles et les données massives ne concernent donc presque pas le volume, même s'il a explosé, mais le type de données et la façon dont elles sont stockées. v Du point de vue modèle, les données traditionnelles stockées ou géré avec un modèle déjà préalablement défini d'avance dans de bases de données ou entrepôts. À contrario, les données du Big Data sont stockées sans construction d'un modèle préalable de rangement. v Du point de vue type des données, Les données traditionnelles ont un type bien définies à l'avance suivant un certain modèle préalable autrement dit que les données traditionnelles sont des données de type structurées. En revanche quand on parle du Big Data, il s'agit donc des données de types divers dont au moins une partie est constituées de données non structurées ou multi structurées. v Du point de vue langage, souvent, c'est le langage SQL qui est utilisé pour formuler des requêtes avec des données traditionnelles, cela est supposé d'avoir défini par avance les types d'informations (ou des données) qui doivent être stockées et établi un modèle permettant de relier ses informations entre elles. Avec le Big Data, on parle des données NoSQL car les normes du langage SQL ne permettent plus de les traiter. v Du point de vue stockage et technologique, les données traditionnelles sont stockées au sein des bases de données relationnelles ou entrepôts de données internes au sein des entreprises. Le stockage des données du type Big Data ou données massives se fait généralement dans le Cloud au sein d'un DataCenter. I.10. BIG DATA ET SES TECHNOLOGIESSi aujourd'hui leBig Data est possible, c'est grâce aux évolutions technologiques (logicielle ou hardware) qui permettent de répondre au 5Vs et aux usages nouveaux que l'on souhaite faire des données. Nous pouvons les subdiviser en 3, à savoir: · Les solutions de stockage( cloud computing (LaaS7(*))) ; · Les solutions logicielles ; · Les solutions matérielles et/ou architecturales. I.10.1. Solutions de stockagePour les solutions de stockage dans le domaine du Big Data, nous pouvons citer entre autre : Les Bases NoSQL, que nous utilisons pour notre travail, et les Outils MapReduce et Hadoop.
Figure 1.4: les solutions sur le cloud computing8(*). I.10.1.1. Bases des Données NoSQLLe terme NoSQL9(*) (de l'anglais Not only SQL) est apparu en 1989. C'est à cette année-là que Carlo Stozzi le prononça pour la première fois en public ; c'était lors de la présentation de son système de gestion de base des données relationnelles open source. Il l'a appelé ainsi à cause de l'absence de l'interface SQL pour communiquer. Plus tard en 2009, le mot réapparait lorsqu'Eric Evans l'utilisa pour spécifier le nombre grandissant des bases de données distribuées open source. NoSQL est une catégorie de systèmes de gestion de base de données (SGBD) qui ne repose plus sur l'architecture de base de données relationnelle classique. L'unité logique n'est plus la table et les données ne sont généralement pas manipulées avec le langage de requête SQL. * 7IaaS : Infrastructure as a Service, c'est-à-dire la capacité d'acheter de l'infrastructure déportée et de la consommer à la demande, de la même manière que ce que l'on fait pour les logiciels SaaS (Software as a Service). * 8BENSABAT Patrick, 2017 Op cit. * 9 KAMINGU Gradi L., 2014 Op cit. |
|