Les déterminants des investissements directs étrangers en France.par Bastien FIGUREAU Université de Nantes - Master 1 en économétrie et statistique 2001 |

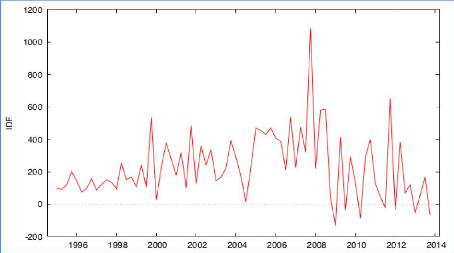
V.3 Détermination du modèle ARIMA (p, d, q)(P, D, O)s pour l'IDETout d'abord, soulignons que la série IDEt concerne l'investissement direct étranger en France du premier trimestre 1995 au quatrième trimestre 2013. Il s'agit donc d'une série temporelle car la série est exprimée en année. Nous allons commencer par déterminer le modèle ARIMA pour notre série IDEt. 57 Graphique 20 : Représentation de l'investissement direct étranger en France
Source : L'auteur sur Gretl, d'après les données de « fred.stlouisfed.org ». D'après le graphique 20, nous observons que notre série sur l'investissement direct étranger semble stationnaire au niveau de la moyenne. Rappelons, que pour pouvoir construire les modèles ARIMA, la série doit être obligatoirement stationnaire au niveau de la variance et de la moyenne. Graphique 21 : Corrélogramme pour l'investissement direct étranger
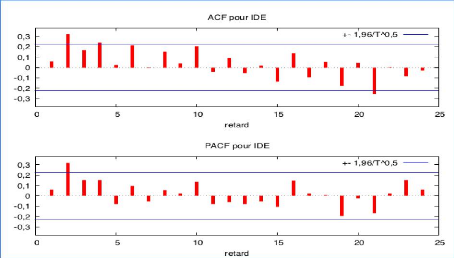
58 Nous observons très clairement que cette série est stationnaire. D'après le graphique 23, nous observons une décroissance rapide des corrélations V.3.1 Estimation de notre modèleTout d'abord, représentons le tableau de la fonction d'autocorrélation (FAC) et d'autocorrélation partielle (FACP) pour notre série IDEt portant sur l'investissement direct étranger. Nous n'avons pas effectué de différenciation car notre série brute était stationnaire. Tableau 17 : FAC et FACP
D'après le tableau 17, nous observons une corrélation significative et positive au seuil de risque de 1% concernant le second retard. Cette corrélation est visible aussi bien pour la FAC et la FACP. Nous observons également une corrélation au seuil de risque de 5% pour les retards quatre et vingt-un au niveau de la FAC. Notons que cette corrélation est négative pour le retard vingt-un. Enfin, nous observons pour les retards six et dix, une corrélation positive 59 au seuil de risque de 10% dans le cadre de la FAC uniquement ainsi qu'une corrélation négative au même seuil pour le retard dix-neuf dans le cadre de la FACP uniquement. Les autocorrélations significatives pour la FAC nous montre que le modèle peut être MA (2). Dans le cadre de la FACP, nous allons être amené à tester le modèle AR (2) grâce aux corrélations significatives. Il y a donc quatre modèles à tester, AR (2), MA (2), ARIMA (1, 0, 1) et enfin ARIMA (2, 0, 1). V.3.1.1 Modélisation du premier modèle AR (2) Nous rappelons tout d'abord que l'équation du modèle AR (2) est : idet = S + at +
çp1idet_1 + çp2idet_2 où
: Nous allons à présent vérifier à partir du modèle obtenu sous le logiciel GRETL la significativité des paramètres. Tableau 18 : Modélisation AR (2) avec la constante
60 Dans un premier temps, nous avons modélisé le modèle AR (2). D'après le tableau 18, nous observons que la probabilité de la constante est inférieure à 0,05. Par conséquent, elle est significative donc nous la conservons dans le modèle. De plus, PHI_2 est significatif au seuil de risque de 1%. La valeur de PHI_2 est égale à 0,323. En revanche, PHI_1 n'est pas significatif donc nous allons observer notre second modèle. Les graphiques de ce modèle AR (2) se trouvent en fin de dossier (annexe 5). V.3.1.2 Modélisation du second modèle MA (2) Pour commencer, rappelons que l'équation du modèle MA (2) est : ???????? = ?? + ???? - ??1????-1 - ??2????-2 où : ???????? représente la série ???????? ???? Représente le bruit blanc ?? Représente la tendance centrale de notre série Nous allons à présent contrôler à partir du modèle réalisé sous le logiciel GRETL la significativité des paramètres. Tableau 19 : Modélisation MA (2) avec la constante
61 RACINE 2
Ensuite, nous avons modélisé le modèle MA (2). D'après le tableau 19, nous observons que la probabilité de la constante est inférieure à 0,05. Par conséquent, elle est significative donc nous la conservons dans le modèle. De plus, THETA_2 est significatif au seuil de risque de 5%. La valeur de THETA_2 est égale à 0,263. En revanche, THETA_1 n'est pas significatif donc nous allons observer notre troisième modèle. Les graphiques de ce modèle MA (2) se trouvent en fin de dossier (annexe 5). V.3.1.3 Modélisation du troisième modèle ARIMA (1, 0, 1) Nous rappelons tout d'abord que l'équation du modèle ARIMA (1, 0, 1) est : idet = u + at - 81at_1 + (P1idet_1
où : Nous allons à présent s'assurer à partir du modèle obtenu sous le logiciel GRETL que les conditions de stationnarités sont vérifiées ainsi que la significativité des paramètres. Nous essayerons également d'observer si nos résidus suivent bien un bruit blanc. Tableau 20 : Modélisation ARIMA (1, 0, 1) avec la constante
62 Modèle
Dans ce modèle, nous envisageons des modèle mixtes : ARIMA (1, 0, 1), c'est une combinaison de AR (1) et MA (1). Cela veut dire que la performance présente est déterminée par la performance précédente et la valeur de référence évolue d'une mesure à l'autre. L'objectif essentiel de la modélisation est de déterminer combien de paramètre est nécessaires pour obtenir un modèle effectif. D'après le tableau 20, nous observons que la constante est significative. Par conséquent, elle est conservée dans ce modèle. De plus, PHI_1 et THETA_1 sont également significatifs au seuil de risque de 1%. La valeur de PHI_1 est égale à 0,920 et celle de THETA_1 est égale à -0,786. Comme on est dans un modèle mixte, il faut vérifier aussi les conditions de stationnarité et d'inversibilité avant l'estimation. Ici nous avons : |ö1| = |0,920| < 1, |e1| = |-0,786| < 1 Donc les conditions de stationnarité et d'inversibilité sont vérifiées. Nous allons à présent vérifier les résidus de notre modèle à partir d'un corrélogramme. Nous ferons également une représentation de la FAC et de la FACP. Graphique 22 : Corrélogramme pour les résidus
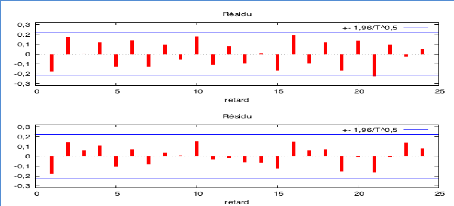
63 Dans cette étape de l'estimation, les vérifications essentielles à réaliser portent sur les résidus. Les valeurs de la fonction d'autocorrélation et d'autocorrélation partielle de la série des résidus doivent être toutes égales à zéro. Cela veut dire qu'ils ont une caractéristique qui correspond à celle d'un bruit blanc. Si les autocorrélations et les autocorrélations partielles ne sont pas nulles, on pourrait dire que le modèle ARIMA est probablement inapproprié. Ici on peut constater qu'aucun de nos résidus ne dépassent le seuil significatif, donc ils ont une caractéristique d'un bruit blanc. Tableau 21 : FAC et FACP pour les résidus
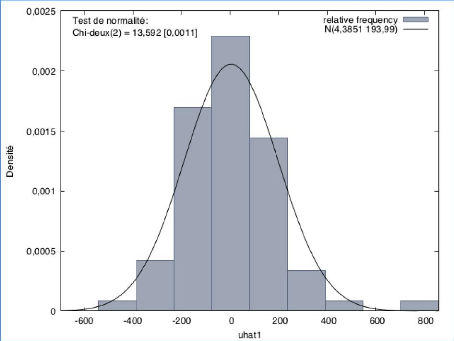
Dans cette approche de Box et Jenkins, un autre test statistique souvent employé pour évaluer un bruit blanc est le test Q. Ce test dont le but est de vérifier si les résidus sont indépendants entre eux. Nous devons vérifier l'hypothèse H0 d'indépendance entre les résidus. Si la p-value est supérieure à 0,05, on accepte l'hypothèse H0 et on dira que les résidus sont indépendants. Dans le cas où la p-value est inférieure à 0,05, on refuse 64 l'hypothèse H0 et par conséquent, les résidus ne seront pas indépendants. D'après le tableau 21, on constate que la p-value est inférieure à 0,05. Les résidus ne sont donc pas indépendants entre eux. Graphique 23 : Test de normalité des résidus
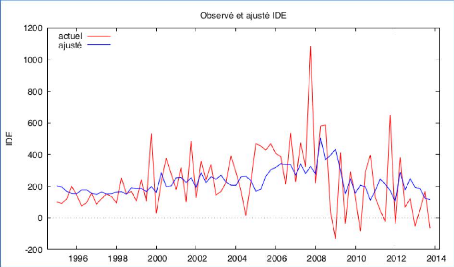
D'après le graphique 23, on peut voir si les résidus suivent une loi normale. On pose l'hypothèse H0 : les résidus suivent une loi normale. Il faut une p-value supérieure à 0,05 pour accepter H0, ici on a une p-value égale à 0,0011, ce qui est inférieure à 0,05, donc on rejette H0 et nos résidus ne suivent pas une loi normale. 65 Graphique 24 : Les valeurs observées et prédites
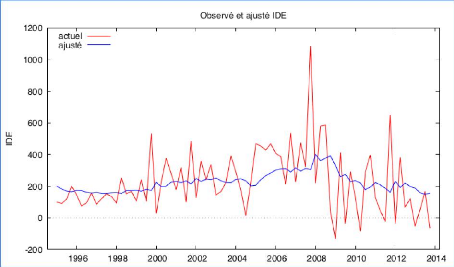
Tout d'abord, si le modèle est bien spécifié, l'ajustement réalisé selon ce modèle doit suivre les évolutions de la série empirique, donc on projette les valeurs observées et les valeurs prédites dans le même graphique. Selon le graphique 24, on constate visuellement que les deux lignes ont des tendances et des volatilités différentes. Nos qualités prédites ne sont pas satisfaisantes. V.3.1.4 Modélisation du quatrième modèle ARIMA (2, 0, 1) Nous rappelons tout d'abord que l'équation du modèle ARIMA (2, 0, 1) est : idet = u + at - 81at_1 + çP1idet_1 + çP2idet_2 où : idet représente la série IDEt at représente le bruit blanc u représente la tendance centrale de notre série Nous allons à présent poursuivre avec la vérification des conditions de stationnarité et la significativité des paramètres. Nous essayerons également de vérifier si nos résidus suivent bien un bruit blanc. 66 Tableau 22 : Modélisation ARIMA (2, 0, 1) avec la constante
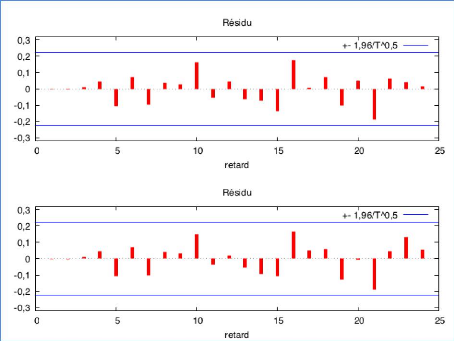
Dans ce modèle, nous envisageons également des modèle mixtes : ARIMA (2, 0, 1), c'est une combinaison de AR (2) et MA (1). D'après le tableau 22, nous observons que la constante est significative. Par conséquent, elle est conservée dans ce modèle. De plus, PHI_1, PHI_2 et THETA_1 sont également significatifs au seuil de risque de 5% pour PHI et de 1% pour THETA_1. La valeur de PHI_1 est égale à 0,534, PHI_2 est égale à 0,294 et celle de THETA_1 est égale à -0,569. Comme on est dans un modèle mixte, il faut vérifier aussi les conditions de stationnarité et d'inversibilité avant l'estimation. Ici nous avons : |ö2| = |0,294| < 1, P1 + P2 = 0,534 + 0,294 = 0,828 < 1, P2 - P1 = 0,294 - 0,534 = -0,240 < 1, |e1| = |-0,569| < 1 Donc les conditions de stationnarité et d'inversibilité sont vérifiées. 67 Nous allons à présent examiner les résidus de notre modèle à partir d'un corrélogramme. Nous réaliserons également une représentation de la FAC et de la FACP. Graphique 25 : Corrélogramme des résidus
D'après le graphique 25, on peut constater qu'aucun de nos résidus ne dépassent le seuil significatif, donc ils ont une caractéristique d'un bruit blanc. Tableau 23 : FAC et FACP pour les résidus
68 10
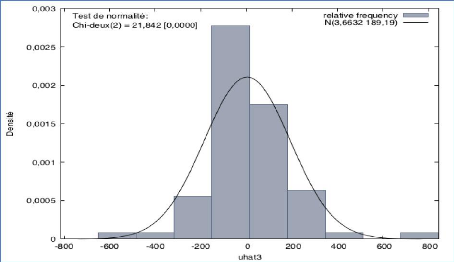
D'après le tableau 23, on constate que la p-value est égale à 0,683 ce qui est supérieure à 0,05. Les résidus sont donc indépendants entre eux. La p-value étant relativement élevée, on peut donc dire que le modèle est bon. Graphique 26 : Test de normalité des résidus
D'après le graphique 26, on a une p-value égale à 0,0000, ce qui est inférieure à 0,05, donc on rejette H0 et nos résidus ne suivent pas une loi normale. 69 Graphique 27 : Les valeurs observées et prédites
D'après le graphique 27, on observe visuellement que les deux lignes ont des tendances et des volatilités différentes. Nos qualités prédites semblent décevantes. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||