|
Ministère de
l'Enseignement Supérieur
Université de
Monastir
*-*-*-*-*
Institut Supérieur d'Informatique et de
Mathématiques de Monastir

Projet de Fin d'Etudes
En vue d'obtention du
Diplôme de Maîtrise en Informatique
Conception et développement d'un logiciel de gestion
commercial
Réalisé par
ISMAILA
Mchangama
Sous la direction de
Encadreur interne :
DIMASSI Sonia
Encadreur externe :
NCIR Mohamed
Année universitaire : 2006/2007
Dédicaces
À mes regrettés grands parents : ce
mémoire vous est dédié en souvenir de ce que vous avez
fait pour moi durant votre existence. Que Dieu vous élève au
rang de ses illustres amis.
À mes parents : mon père MCHANGAMA
Mdjassiri et ma mère ZAINABA Mdahoma, qui m'ont inculqué un
esprit de combativité et de persévérance et qui m'ont
toujours poussé et motivé dans mes études. Sans eux,
certainement je ne sériai pas à ce niveau.
À ma grande soeur Mounira, pour ses encouragements
incessants.
À mes frères Hamidou, Ousseine et Ahmada,
qui m'ont toujours soutenu au prix des sacrifices inoubliables.
À mon oncle MDAHOMA Bakary et sa famille. Oncle
vous étiez pour moi un père spirituel et un modèle
à suivre pour être au sommet des échelons.
À ma tante Moinabaraka, vous m'avez donné
trop de marque de bienveillance. Je garderai toujours un attachement profond
pour vous. Je vous serai toujours reconnaissant pour l'assistance que vous avez
apportée dans ma vie.
À tous mes, oncles, tantes, cousins et cousines,
en souvenir de toutes les joies et forces qui unissent notre chère
famille. À tous mes amis, pour votre sincère amitié,
votre soutien permanent me remonte le moral et vos conseils m'incitent
à relever les défis.
Aux habitants de Samba-Mbodoni. Je tiens
particulièrement à dédier ce travail à ces gens
qui m'ont manqué durant ces quelques années. Si mes voeux
pouvaient avoir quelques pouvoirs j'en serais profondément heureux car
je veux pour vous et vos familles toutes les réussites et satisfactions
de ce monde.
Remerciements
Je tiens à exprimer mes remerciements avec un grand
plaisir et un grand respect à mon encadreur Mme DIMASSI Sonia, Ses
conseils, Sa disponibilité et ses encouragements m'ont permis de
réaliser ce travail dans les meilleures conditions. J'exprime de
même ma gratitude à mon encadreur de CyberParc monsieur Ncir
Mohamed. Qui a cru en moi et qui n'a cessé de me faire profiter ses
précieux conseils et remarques.
Je remercie infiniment Mme GUALLOUZ Sonia et M ACHOUR
Wissam qui m'ont toujours encouragé dans les moments de
délicatesse.
J'adresse aussi mes reconnaissances à tous les
professeurs et au corps administratif de l'Institut Supérieur
d'informatique et de mathématiques de Monastir (ISIMM) qui depuis
quelques années leurs conseils et leurs connaissances m'ont bien
servis.
Je voudrais aussi exprimer ma gratitude envers tous ceux qui
m'ont accordé leur soutien, tant par leur gentillesse que par leur
dévouement, en particulier SELMI Samer qui m'a souvent aidé
à résoudre des difficultés techniques.
Je ne peux nommer ici toutes les personnes qui de près
ou de loin m'ont aidé et encouragé mais je les en remercie
vivement.
Enfin je tiens à dire combien le soutien quotidien de
ma famille a été important tout au long de ces quelques
années, je leur dois beaucoup.
Résumé
Dans l'entreprise, les données
représentent un grand capital, à considérer au même
niveau que le capital financier. Il faut les gérer donc convenablement.
Maîtriser ce facteur permet aujourd'hui aux entreprises de limiter les
risques.
De nos jours le défi est lancé, la gestion
automatique des documents est en essor. Les produits répondants à
ce domaine inondent le marché. Certains sont des sharewares tandis que
d'autres sont destinés à la vente avec des prix exorbitants. Pour
cela, petites voire moyennes entreprises, à cause de leurs budget
réduit, ils ne peuvent pas se permettre de payer des produits pareils.
C'est dans ce cadre que se situe notre projet, il consiste à concevoir
et à développer un logiciel de gestion commercial sur mesure pour
une société de ventes des matériels informatiques.
Table des
matières
Introduction
1
Chapitre I Analyse et spécification des
besoins
3
1 Analyse et spécification des
besoins
4
1.1 Introduction :
4
1.2 Présentation de l'environnement du
stage :
4
1.2.1 Présentation de CRISTAL
Info :
4
1.3 Contexte et motivation du projet
5
1.3.1 Contexte
5
1.3.2 Critique de l'existant
5
1.3.3 Travail demandé
5
1.3.4 Approche de solution
5
1.4 Conclusion
6
Chapitre II Méthodes et outils
7
2 Méthodes et outils
8
2.1 Introduction :
8
2.2 Avantages de l'approche orientée
objet :
8
2.3 Les architectures n-tiers :
8
2.3.1 Architecture utilisant un serveur
centré :
8
2.3.2 Architectures n-tiers :
9
2.4 Model View Control (MVC) :
9
2.5 Nuance entre MVC et 3-Tiers :
9
2.6 Méthodes et outils pour
l'application :
10
2.6.1 Choix des outils de
conception :
10
2.6.1.1 Choix du principe et du logiciel
de modélisation :
10
2.6.2 Choix des outils de
développement :
11
2.6.2.1 Choix du langage de
programmation :
12
2.6.2.2 Choix de l'outil de
développement :
13
2.6.2.3 Choix du SGBD :
14
2.6.2.3.1 Oracle Database
15
2.6.2.3.2 Access
17
Chapitre III La conception
18
3 La conception
19
3.1 Introduction :
19
3.2 La modélisation
dynamique :
19
3.2.1 Diagramme des cas
d'utilisation :
19
3.2.2 Diagramme de
séquence :
24
3.3 Modélisation Statique :
27
3.3.1 Diagramme de classes :
27
3.3.2 Modèle conceptuel des
données (modèle physique) :
30
Chapitre IV La réalisation
32
4 La réalisation :
33
4.1 Introduction :
33
4.2 Modèles de cycles de vie d'un
logiciel :
33
4.2.1 Modèle de cycle de vie en
cascade
33
4.2.2 Modèle de cycle de vie en V
33
4.2.3 Modèle de cycle de vie en
spirale
35
4.2.4 Modèle par
incrément :
36
4.2.5 Modèle de
prototypage :
36
4.3 Présentation de l'application
développée :
37
4.3.1 Fenêtre d'accueil :
38
4.3.2 Itinéraire suivi pour
l'édition d'une commande :
38
4.3.3 Quelques interfaces.
43
4.4 Déroulement du projet :
49
4.5 Conclusion :
49
Conclusion et perspectives
50
Bibliographie
52
Annexes
54
Liste des
tableaux
Tableau 1. Partage des
cas d'utilisation en catégories
24
Tableau 2. Tableau des
transformations.
29
Tableau 3. Tableau du
déroulement
49
Liste des
figures
Figure 1. Relation
entre les langages
12
Figure 2. Diagramme
global des cas d'utilisation
21
Figure 3. Diagramme
des cas d'utilisation d'un agent
22
Figure 4. Diagramme des
cas d'utilisation pour administrateur
23
Figure 5. Diagramme
de séquence de
l'authentification
25
Figure 6. Diagramme
de séquence de l'ajout d'un
produit
25
Figure 7. Diagramme de
séquence de l'édition d'une facture
26
Figure 8. Diagramme de
séquence de l'ajout d'un agent
27
Figure 9. Diagramme de
classes
28
Figure 11.
Modèle du cycle de vie en cascade
34
Figure 12.
Modèle du cycle de vie en V
34
Figure 13.
Modèle de cycle de vie en spirale
35
Figure 14.
Modèle de prototypage
37
Figure 15.
Fenêtre d'accueil (authentification)
38
Figure 16.
Fenêtre principale
39
Figure 17.
Fenêtre principale : click sur ventes
40
Figure 18. Bon de
commande
41
Figure 19. Ajout ligne
de commande
42
Figure 20. Ajout d'une
ligne et calcul automatique du prix.
43
Figure 21.
Ajout/mettre à jour un produit.
44
Figure 22. Liste des
articles
45
Figure 23. Liste des
clients
46
Figure 24. Ajout d'un
Client
47
Figure 25.
Ajouter/supprimer/chercher un agent
47
Figure 26. Clique
sur le bouton utilitaire
48
Figure 27.
Calendrier
48
Figure 28. Relation
extend
58
Figure 29. Relation
include
59
Figure 30. Relation
généralisation/spécification
59
Figure 31. Table et
clé primaire.
61
Figure 32. Relation
binaire (...,*) - (...,1).
61
Figure 33. Relation
binaire (0.1) - (1.1).
62
Figure 34. Relation
binaire et ternaire (...,*) - (...,*).
62
Liste des
annexes
Annexe 1 cas d'utilisation
55
Annexe 2 Règles de passage du modèle
conceptuel au modèle physique (MCD vers MLD)
61
Annexe 3 Ingénierie et
retro-ingénierie
63
Introduction
De l'âge de la pierre à nos jours, l'esprit
perfectionniste de l'homme n'a cessé de lui permettre
d'améliorer sa vie quotidienne. Le passage de la mécanique aux
domaines d'informatique, d'électronique, d'automatique et de domotique a
révolutionné la vie journalière de l'être humain.
Les nouvelles technologies de l'information et de communication illustrent ce
phénomène.
Aujourd'hui, vu l'intérêt croissant de vouloir
gagner en temps, de conserver les données, de limiter le nombre
d'employés et pas mal d'autres raisons, ont poussé petites,
moyennes et grandes entreprises à chercher des solutions informatiques
capables de répondre à leurs besoins.
Dans ce cadre s'inscrit notre projet de fin d'études
qui consiste à réaliser une application sur mesure de gestion
commerciale pour une société de ventes des matériels
informatiques.
Ce travail est réalisé en vue d'obtention du
diplôme de maîtrise en informatique à l'Institut
Supérieur d'Informatique et de Mathématiques de Monastir
(ISIMM).
Pour atteindre notre objectif on a partagé le travail
comme suit :Le premier chapitre s'agit d'une prise de connaissance de
l'existant pour savoir de ce que doit être capable de faire et de quoi
va servir notre futur application en d'autres termes il s'agit d'une analyse
et spécification des besoins. Dans le second chapitre on va faire notre
choix sur les méthodes et outils à utiliser pour réaliser
l'application. Le troisième chapitre sera consacré à la
conception de l'application il s'agit d'une phase de modélisation
théorique de l'application. Avant de clore on va essayer de
présenter les résultats obtenus dans le quatrième
chapitre.
1 Chapitre I
Analyse et
spécification des besoins
2 Analyse et spécification des
besoins
2.1
Introduction :
Il s'agit d'une étape cruciale dans la
réalisation d'une application donnée. Le futur d'un logiciel
dépend beaucoup de cette phase, elle nous permet d'éviter le
développement d'une application non satisfaisante. Pour cela le client
et le développeur doivent être en étroites relations,
voire avoir un intermédiaire entre eux s'il le faut.
Pour arriver à nos fins il nous faut prendre
connaissance de :
· L'analyse et la définition des besoins :
permet de trouver un commun accord entre les spécialistes et les
utilisateurs.
· L'étude de la faisabilité : Le
domaine d'application, l'état actuel de l'environnement du futur
système, les ressources disponibles, les performances attendues, etc.
· Etablissement du cahier des charges.
Le présent chapitre va nous donner un aperçu
global de l'application.
1.2
Présentation de l'environnement du stage :
1.2.1
Présentation de CRISTAL Info :
CRISTAL Info est une société informatique
basée à Monastir plus précisément dans les locaux
de CYBERPARC, elle fournit plusieurs services informatiques.
1.2.2 Activités de CRISTAL
Info :
Les activités de CRISTAL Info sont très
variées, on peut mentionner quelques unes :
· Conception et développement des sites web
· Conception, sécurisation et audit de
réseaux.
· Conception et mise en place des bases de
données.
· Développement d'applications.
· Rédaction des cahiers de charges.
2.3 Contexte et motivation du projet
2.3.1 Contexte
Comme on l'a cité précédemment, CRISTAL
Info n'est pas une société consommatrice, elle est plutôt
productrice. Toutes les applications développées sont
destinées alors à la vente.
L'application en question s'agit d'une commande d'une boutique
de vente des matériels informatiques. Il s'agit donc d'une application
de gestion commerciale spécialisée dans le domaine de vente
informatique cette solution doit être capable d'automatiser les taches
qui sont faites à l'heure actuelle manuellement.
2.3.2 Critique de l'existant
La solution actuelle est manuelle :
· L'abondance des documents dans l'entreprise peut
ralentir les services.
· On peut en avoir besoin de plus d'employés pour
se partager les taches.
· Risque de mélanger les documents : ce qui
peut être fatal.
· La suivie des clients et des fournisseurs peut
rencontrer beaucoup de problèmes.
· La perte de la clientèle est possible au cas
où le traitement de leurs demandes traine.
2.3.3 Travail demandé
Notre travail consiste à concevoir et à
développer une application informatique qui permettra la gestion
automatique des clients, des fournisseurs, du stock, etc.
Autrement dit notre but est de concevoir et
développer un logiciel de gestion commercial adaptable aux conditions
citées précédemment (gestion des clients, des
fournisseurs, du stock,...).
2.3.4 Approche de solution
En tenant compte des critiques et des besoins d'informatiser
les services cités ci-dessus la solution est de concevoir et
développer une application permettant de satisfaire au maximum possible
le client.
Pour cela l'application doit répondre aux besoins
suivants :
· Avoir un logiciel performant
· Avoir un logiciel qui respecte les principes des
Interfaces Homme/Machine (IHM) tels que l'ergonomie et la fiabilité.
· Réduire les taches manuelles qui nous
permettraient de gagner en spatio-temporel
· Archiver les informations
· Avoir un logiciel évolutif et
paramétrable
2.4 Conclusion
L'étude préalable appelée techniquement
ingénierie des exigences ou analyse et spécification des besoins,
constitue une phase capitale dans le cas où toute la suite du projet
dépend d'elle, elle doit être faite avec beaucoup de rigueur et
plus d'attention pour que le projet réussisse avec un grand
succès.
Dans ce chapitre, on a exposé les problèmes de
la société et de l'existant, puis nous avons fait les critiques
du travail manuel et enfin on a fait une approche de solution qui consiste
à concevoir et à développer une application qui facilitera
les services énumérés précédemment.
Après avoir fixé nos objectifs, pour atteindre
notre but on doit suivre plusieurs étapes ces dernières
constituent une partie du cycle de vie de tout projet informatique. Ainsi dans
l'étape suivante on va se consacrer sur le choix des méthodes et
outils de la réalisation.
Chapitre II
Méthodes et outils
3 Méthodes et outils
3.1 Introduction :
Il est évident que les méthodes et les outils
choisis pour concevoir et développer une application doivent être
en fonction de l'environnement et du domaine d'application de celle-ci. Cela
est bien expliqué par le génie logiciel..
Dans ce chapitre on va mettre l'accent sur les avantages de
l'approche orienté objet, les architectures n-tiers et l'approche du
Model View Control (MVC) et en dernier lieu justifier
notre choix sur les méthodes et outils à appliquer pour faciliter
notre tache.
3.2 Avantages de l'approche orientée objet :
Parmi les avantages de cette approche, on peut citer : la
réutilisabilité des éléments (objets), l'avantage
d'utiliser un objet de base afin de produire un autre qui peut être une
amélioration de cet objet (phénomène d'héritage),
etc.
L'objet est le coeur de cette approche. Tout objet
donné possède deux caractéristiques :
· Son état courant (attributs)
· Son comportement (méthodes)
En approche orientée objet on utilise le concept de
classe, celle-ci permet de regrouper des objets de même
nature.
Une classe est un moule (prototype) qui permet de
définir les attributs (champs) et les méthodes (comportement)
à tous les objets de cette classe.
3.3 Les architectures n-tiers :
L'informatique est une science évolutive. A nos jours
avec l'arrivée des nouvelles technologies de l'information et de la
communication (NTIC), en occurrence l'Internet. L'architecture logicielle ne
peut pas rester indemne, elle doit suivre l'évolution raison pour
laquelle on trouve plusieurs architectures sur le marché qu'on peut
subdiviser en deux catégories :
· Architecture utilisant un serveur centré
· Architecture n-tiers
3.3.1 Architecture utilisant un serveur
centré :
Il s'agit de la première
génération : l'ensemble des traitements et de données
se trouvent dans un serveur et les utilisateurs des applications utilisent des
terminaux pour appeler les fonctions se trouvant dans le serveur. Les terminaux
ont uniquement une fonction d'affichage.
3.3.2 Architectures n-tiers :
Comme son nom l'indique cette architecture est un prototype de
plusieurs architectures. Commençant du 2-tiers (appelée
régulièrement Client/serveur) qui est la base de notre
application allant du 3-tiers voire 4-tiers.
D'une manière générale les architectures
n-tiers suivent les mêmes principes qui sont l'affichage (User
interface), le traitement (Business logic) et la partie
accès et stockage des données (Data Access Object).
On peut regrouper les deux (Client/serveur) ou de les
séparer carrément (3-tiers et plus).
En ce qui nous concerne on a besoin de développer une
application qui sera utilisé localement.
3.4 Model View Control (MVC) :
Le modèle vue contrôleur est souvent
décrit comme simple design pattern (motif de conception) mais c'est plus
un architectural pattern (motif d'architecture) qui donne le ton à la
forme générale d'une solution logiciel plutôt qu'à
une partie restreinte.
Comme l'architecture 3-tiers il possède trois parties
qui sont :
· Model : le modèle défini
les données de l'application et les méthodes d'accès. Tous
les traitements sont effectués dans cette couche.
· View : la vue prend les informations en
provenance du modèle et les présente à l'utilisateur.
· Controller : le contrôleur
répond aux événements de l'utilisateur et commande les
actions sur le modèle. Cela peut entrainer une mise à jour de la
vue.
3.5 Nuance entre MVC et 3-Tiers :
MVC et 3-Tiers sont des mots souvent cités dans les
cours de génie logiciel. Souvent les gens ont tendance à les
confondre mais ils n'ont pas tord car ces deux pratiques sont à la fois
différentes et similaires.
La différence fondamentale se trouve dans le fait que
l'architecture 3-Tiers sépare la couche Business logic (couche
métier) de la couche Data Access (accès aux
données).
Pour qu'une application MVC soit une vraie application 3-Tiers
il faut lui ajouter une couche d'abstraction d'accès aux données
de type DAO (Data Access Object).
Inversement pour qu'une application 3-Tiers respecte MVC il
faut lui ajouter une couche de contrôle entre User interface et
Business logic.
Loin d'être antagonistes, ces deux pratiques se comblent
et sont la fondation de la plupart des frameworks de création
d'application web.
3.6 Méthodes et outils pour l'application :
3.6.1 Choix des
outils de conception :
En Génie Logiciel (GL) la conception constitue une
phase fondamentale dans le cycle de vie d'un logiciel. La réussite de ce
dernier dépend beaucoup de cette étape. Dans notre application on
va se baser sur deux conceptions : la conception architecturale et la
conception détaillée.
Conception globale (architecturale) :
Cette conception consiste à scinder les taches de
l'application en différentes petites parties afin de mieux organiser et
développer le logiciel. Ça se base sur la technique
« Diviser pour mieux régner ».
Les retombés directs de cette technique ne sont pas
négligeables, on peut mentionner quelques uns :
· Le développement de l'application peut
être partagé par plusieurs groupes de travail.
· La possibilité de réutiliser les
composantes dans d'autres applications.
· La portabilité de l'application.
Dans notre cas, on va utiliser entre autre le MVC
et une architecture client/serveur. On va essayer de scinder cette
dernière en trois partie une partie de présentation
(représentée par les interfaces), une partie qui permet
l'accès à la base et une dernière partie composée
par la base même.
Mieux encore le partage de l'application en sous
systèmes va nous permettre de faire une conception
détaillée de chaque partie.
Conception détaillée :
3.6.1.1 Choix du
principe et du logiciel de modélisation :
Merise et UML sont deux grands principes de « traduction
» ou modélisation d'un système d'information.
Néanmoins, ils ne sont pas aussi proches qu'on pourrait le penser.
Le choix de l'un ou de l'autre se fait selon trois axes
à savoir l'accessibilité, la précision et
l'exploitabilité.
Pour le premier axe (accessibilité) MERISE
présente l'intérêt d'avoir des modèles logiques
moins détaillés facilement compréhensibles par un
utilisateur moins avisé.
Tandis qu'UML conçu pour s'adapter à n'importe
quel langage de programmation orientée objet (POO), présente
plusieurs modèles (diagrammes) dont leurs compréhensions
nécessitent une grande attention.
En ce qui concerne le deuxième critère
(précision), MERISE est décevant. Malgré sa clarté,
il la manque une précision du fait qu'elle est éloignée du
langage donc difficile à implémenter alors qu'UML intègre
les éléments communs des différents langages, sa
volonté est d'être fidèle à la réalisation
finale. Elle est beaucoup plus complète avec ses différents
diagrammes.
Pour en finir avec l'exploitabilité, MERISE est une
méthode plus généraliste. Elle donne une vue globale de la
solution sans autant rentrer dans les petits détails. Contrairement
à UML qui est conçu pour l'implémentation objet avec ses
différents détails et sa portabilité (s'adapte à
n'importe quelle plateforme) elle est donc plus exploitable.
L'une ou l'autre présente des avantages et des
inconvénients. Il est réservé au concepteur de choisir la
méthode la mieux adaptée pour son cas. Si on cherche la
précision et l'exploitabilité comme dans notre cas UML devance de
loin MERISE. Tandis que, si c'est la clarté et l'accessibilité
qui sont en question MERISE est préférable.
La conception de notre application mérite bien une
grande précision et une exploitabilité maximale. C'est la raison
pour laquelle on va retenir UML. Les différences entres les logiciels de
modélisation UML sont infimes. N'empêche de mentionner quelques
logiciels qui sont à notre connaissance : Agro UML (open source),
Poseidon UML et le plus célèbre Rational Rose.
La facilité dotée au dernier (Rational Rose) de
pouvoir faire une « ingenierie » et une
« retro-ingenierie » a influée sur
notre choix.
3.6.2 Choix des
outils de développement :
Un parmi les avantages qui nous
ont permis de choisir UML comme méthode de modélisation est
l'orienté objet. Cette approche influe aussi sur le choix du langage
à adopter on peut rajouter quelques uns à savoir la
portabilité, la facilité, la multidisciplinarité et pas
mal d'autres comme la sécurité.
3.6.2.1 Choix du
langage de programmation :
Le schéma suivant nous fait un bref aperçu
concernant quelques langages. Il montre le domaine principal d'application,
de l'année de l'essor du langage ainsi que l'interdépendance
entre les différents langages.
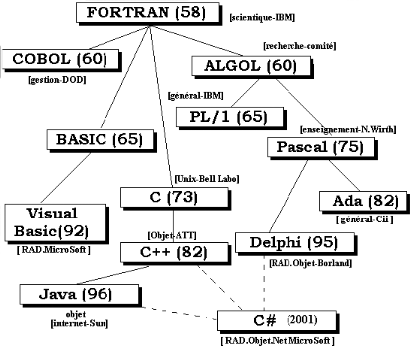
Figure 1.
Relation entre les langages
Comme on l'avait dit, le schéma ci-dessus nous donne
une vue globale de l'évolution des langages. La plupart des langages
présents dans ce schéma sont développés par des
sociétés privées et sont donc destinés pour le
marché ils subissent alors la loi du marché (des hauts et des
bas).
Souvent la sortie d'un nouveau langage n'est pas un fruit du
hasard mais il s'appuie sur les anciens en profitant de leurs qualités
et en essayant de remédier les défauts.
Ici on va essayer de faire une étude comparative sur
les langages de programmation orientés objets qui sont en vogue sur le
marché et essayer d'en sélectionner un qui répondra bien
les besoins d'implémentation de notre application.
On va s'intéresser surtout sur les langages Java, C++
et Visual Basic.
Ø Java :
Java est pourvu d'une grande sécurité, la
richesse de ses bibliothèques, son adaptation à plusieurs
plateformes, la qualité présentée par ses composantes
graphiques (Swing) qui suivent le modèle MVC, sa facilité de
déploiement en réseau (RMI) et le fait qu'on peut avoir plusieurs
« Look And Feel », en font de lui un langage redoutable
puissant et performant. Une grande partie de sa syntaxe est empruntée
de C et C++. La lenteur de sa machine virtuelle (JVM) constitue son principal
défaut.
Ø Visual Basic (VB) :
VB fait parti des langages suivant le concept orienté
objet il a un environnement de développement intégré (EDI)
qui permet de développer facilement des interfaces graphiques.
En appliquant quelques propriétés à ces
dernières et en écrivant quelques petits bouts de codes on
obtient des résultats satisfaisants.
VB est facilement accessible et assimilable
Ø C++ :
Comme on l'a dit précédemment Java puise une
grande partie de ses sources dans le C++ ce qui fait que les défauts
rencontrés par le deuxième sont améliorés voire
éliminés par le premier.
Les comparaisons faites ci-dessus nous permettent de choisir
Java comme langage d'implémentation de notre application. Avec ses
multiples avantages en comparaison avec VB qui peut servir un début pour
l'apprentissage des Langages Orientés Objets (LOO), Java s'impose. Quant
à C++, que Java a essayé de supprimer ses erreurs et
d'améliorer quelques points parait plus difficiles à
développer surtout les interfaces graphiques. Or ces dernières
constituent une grande partie de notre logiciel.
3.6.2.2 Choix de
l'outil de développement :
Vu la multidisciplinarité et sa domination
croissante, plusieurs outils de développement de Java ne cessent de voir
le jour. On peut rencontrer pas mal d'Environnement de Développement
Intégré (EDI) Java. Certains sont en open source et d'autres
commerciaux.
Citons quelques uns :
Ø Borland de JBuilder :
Doté d'un EDI, il est placé parmi les logiciels
les plus performants pour le développement des applications en java.
Ecrit en Java 2 permet ses applications d'être exécutés
sous plusieurs plateforme.
Ø IBM Visual Age for Java :
Il s'agit d'un EDI développé par IBM. Il est
trop puissant avec son ergonomie. L'utilisation au début est difficile
mais sa persévérance est intéressante.
Ø NetBeans:
NetBeans est un environnement de développement en java
open source écrit en java. Le produit est composé d'une partie
centrale à laquelle il est possible d'ajouter des modules tel que
Poseidon pour la création avec UML.
Ø JCreator :
JCreator existe en deux versions : la version "LE" est en
freeware et la version "PRO" est en shareware. Il est particulièrement
rapide car il est écrit en code natif.
Ø Le projet Eclipse :
Eclipse est un projet open source à l'origine
développé par IBM pour ces futurs outils de développement.
Le but est de fournir un outil modulaire capable non seulement de faire du
développement en java mais aussi dans d'autres langages et d'autres
activités. Cette polyvalence est liée au développement de
modules réalisés par la communauté ou des entités
commerciales.
Dans un esprit de défi, et vouloir mettre en oeuvre les
connaissances qu'on a acquis durant notre formation, on a opté JCreator
Pro pour le développement de notre application. Ce logiciel est
dépourvu d'un EDI donc pour arriver à nos fins on était
obligé d'écrire ligne par ligne le code de notre application ce
qui est fait malgré plusieurs problèmes rencontrés.
3.6.2.3 Choix du
SGBD :
De nombreux SGBD sont disponibles sur le marché, partant
des SGBD gratuits jusqu'aux SGBD destinés spécialement aux
professionnels, comportant de plus nombreuses fonctionnalités, mais plus
coûteux.
On va essayer de faire comme d'habitude une étude
comparative d'une sélection de quelques SGBD et choisir un pour notre
application.
En guise de cause on mentionne quelques facteurs subjectifs qui
influent souvent sur le choix du SGBD :
Ø La politique sécuritaire
Ø Le budget à disposition
Ø Les compétences déjà acquises en
terme de développement et d'administration et au besoin du prix de la
formation
Ø Le système d'exploitation hébergeant
Ø Les architectures logicielles et matérielles
Ensuite viendront des points tels que :
Ø La richesse fonctionnelle du SGBDR
Ø Les ressources (disques, mémoire, CPUs,
Transactions par secondes, nombre de connexions simultanées)
Ø L'attente que vous avez vis-à-vis du support
technique
Ø Les compétences déjà acquises en
termes de développement et d'administration
Ø Le type d'accès aux données (OLTP,
décisionnelle, reporting, mixte)
Faisons l'étude de quelques uns qui sont connus par un
grand nombre du public :
3.6.2.3.1 Oracle
Database
Oracle n'est pas un SGBDR optimisé pour de petites
bases de données. Sur de petits volumes de traitements (2 Go par
exemple) et peu d'utilisateurs (une trentaine).
Avantage :
· Procédures stockés en PL-SQL (langage
propriétaire Oracle, orienté ADA) ou ... en JAVA (depuis la
8.1.7) ce qui peut s'avérer utile pour les équipes de
développement.
· Assistants performants via Oracle Manager Server,
possibilité de gérer en interne des tâches et des alarmes
· Gestion centralisée de plusieurs instances
· Concept unique de retour arrière (Flashback)
· Pérennité de l'éditeur : avec plus de
40% de part de marché, ce n'est pas demain qu'Oracle disparaîtra
· Réglages fins : dans la mesure où l'on
connait suffisamment le moteur, presque TOUT est paramétrable.
· Accès aux données système via des
vues, bien plus aisément manipulable que des procédures
stockées.
· Services Web
· Support XML
· Ordonnanceur intégré
Inconvénients
· Prix exorbitant, tant au point de vue des licences que des
composants matériels (RAM, CPU) à fournir pour de bonnes
performances
· Fort demandeur de ressources, ce qui n'arrange rien au
point précité, Oracle est bien plus gourmand en ressource
mémoire que ses concurrents, ce qui implique un investissement
matériel non négligeable. La connexion utilisateur
nécessite par exemple près de 700 Ko/utilisateur, contre une
petite centaine sur des serveurs MS-SQL ou Sybase ASE. Gourmand aussi en espace
disques puisque la plupart des modules requièrent leur propre
ORACLE_HOME de par le versionning de patches incontrôlés.
· Porosité entre les schémas = difficile de
faire cohabiter de nombreuses applications sans devoir créer plusieurs
instances. Il manque réellement la couche "base de données" au
sens Db2/Microsoft/Sybase du terme.
· Méta modèle propriétaire, loin de la
norme.
· Tables partitionnées, RAC... uniquement possible
à l'aide de modules payants complémentaires. Parallélisme
mal géré sur des tables non-partitionnées.
· Gestion des verrous mortels mal conçue (suppression
d'une commande bloquante sans roll back)
· Pauvreté de l'optimiseur (ne distingue pas les
pages en cache ou en disque, n'utilise pas d'index lors de tris
généraux, statistiques régénérées par
saccade...)
· Pas de prise directe sur les tables système (vues
système)
· Une quantité de bugs proportionnels à la
richesse fonctionnelle, surtout sur les dernières versions
· Gestion erratique des rôles et privilèges
(pas possible de donner des droits sur des schémas particuliers sans
passer par leurs objets, désactivation des rôles lors
d'exécution de packages...)
· Nombreuses failles de sécurités liées
à l'architecture elle-même
3.6.2.3.2
Access
Access est aussi bien un outil grand public que
professionnel, selon les besoins qu'on a. Il est assez performant en tant que
SGBD allié à un outil de développement
intégré qui en facilite l'utilisation. Access peut, en tant
qu'outil de développement, être utilisé conjointement avec
un véritable Serveur de base de données SQL pour
bénéficier des avantages du Client/serveur, sous certaines
conditions. Un néophyte peut facilement utiliser Access et se
créer une base de données complète, grâce à
de nombreux assistants pour l'aider à remarquer son intégration
dans Office.
Le problème est qu'Access en tant que format de
données n'est pas un SGBD client/serveur mais seulement un SGBD fichier.
Le trafic qu'il génère sur le réseau en utilisation
réseau multiposte peut fortement perturber ses performances. Les
performances chutent rapidement lorsque plusieurs utilisateurs sont
connectés ou si la base dépasse les 100000 lignes. Cependant
Access en tant qu'outil de développement peut être utilisé
conjointement avec un véritable Serveur de base de données SQL
pour bénéficier des avantages du Client/serveur.
MS-Access reste un bon choix si vous souhaitez avoir une base
de donnée de petite taille mais facilement gérable, ou que vous
ne connaissez pas grand chose aux SGBD.
En se référant du domaine d'application du
logiciel à développer et de l'étude comparative faite
entre les deux SGBDs cités ci-dessus on a choisi Access.
Rappelons que le logiciel sera utilisé dans une
boutique de vente informatique donc il n'y aura pas une trop grande
quantité de données. D'autre part l'agent qui travail dans cette
société n'est pas censé d'être un informaticien donc
un SGBD comme Access sera mieux adapté pour lui à cause de sa
facilité d'utilisation.
Chapitre III
La
conception
4 La conception
4.1
Introduction :
La plupart des nouveaux langages sont orientés objet.
Le passage de la programmation fonctionnelle à l'orienté objet
n'était pas facile. L'un des soucis était d'avoir une idée
globale en avance de ce qu'on doit programmer.
L'algorithmique qui était utilisé dans la
programmation fonctionnelle ne pourrait pas suffire à lui seul. Le
besoin d'avoir des méthodes ou langages pour la modélisation des
langages orientés objet se faisait sentir. Ainsi plusieurs
méthodes ou langages on vu le jour. En occurrence UML qui nous a permis
de faire la conception de notre application.
De nos jours UML2 possède treize diagrammes qui sont
classés en deux catégories (dynamique et statique).
Pour ce faire on a commencé par les diagrammes de cas
d'utilisation (Use Case) qui permettent de donner une vue globale de
l'application. Pas seulement pour un client non avisé qui aura
l'idée de sa future application mais aussi le développeur s'en
sert pour le développement des interfaces.
En deuxième lieu on va présenter la chronologie
des opérations par les diagrammes de séquences.
Et finir par les diagrammes statiques qui sont celles des
classes et le modèle physique.
4.2 La
modélisation dynamique :
Comme on l'a dit UML2 possède treize diagrammes. Quant
à la catégorie dynamique à elle seule est associée
huit diagrammes.
Dans notre application on va s'en servir des deux seulement
énoncés ci-dessus.
On ne peut pas aller directement à la conception sans
faire une petite description du fonctionnement de l'application.
4.2.1 Diagramme des cas
d'utilisation :
Le but de ces diagrammes et d'avoir une vision globale sur
les interfaces du futur logiciel. Ces diagrammes sont constitués d'un
ensemble d'acteurs qui agit sur des cas d'utilisation.
Les acteurs :
UML n'emploi pas le terme d'Utilisateur mais d'acteur.
Les acteurs d'un système sont les entités
externes à ce système qui interagissent avec lui.
Suivant les besoins de notre système on peut
présenter deux acteurs. Il s'agit d'un administrateur et un agent
travaillant pour la société. La manière d'accéder
aux services de l'application pour l'un et pour l'autre est la même. La
différence réside sur les droits d'accès et les limites de
chacun.
Ø L'agent :
Celui-ci s'agit d'un simple employeur mais pour restreindre
l'accès à notre application personne ne peut y accéder
sans s'authentifier.
L'agent a comme rôle de :
· Gérer les ventes.
· Gérer les achats.
· Gérer les fournisseurs.
· Gérer les clients.
· Gérer le stock.
Ø L'administrateur :
« Qui paye le plus paye le
moins », comme l'administrateur se place en dessus de
l'agent celui-ci peut faire à part les taches de l'agent mais aussi
gérer ces derniers. Ceci est intéressant car UML présente
le critère d'héritage entre les acteurs. Donc on pourra faire
l'administrateur un héritier de l'agent et on va lui ajouter la
particularité de pouvoir gestion des agents.
Présentation globale des cas d'utilisation :
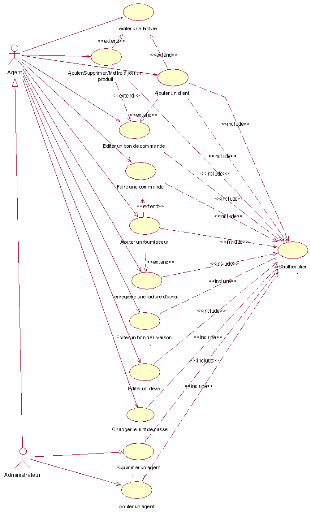
Figure 2.
Diagramme global des cas d'utilisation
En observant la figure ci-dessus on a presque l'idée
complète de l'application (interface).
Dans les parties qui suivent on va essayer de détailler
le diagramme de chaque acteur agissant sur le système
Diagramme des cas d'utilisation de l'agent :
Dans les paragraphes précédents on a
décrit ce que peut de chaque acteur ici on ne va pas
réécrire la même chose. Juste on va donner un
schéma qui montre l'interaction de l'agent aux interfaces de
l'application.
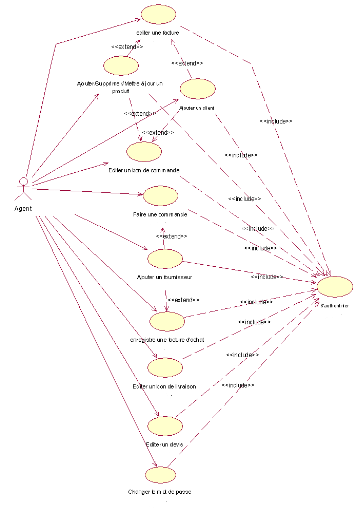
Figure 3.
Diagramme des cas d'utilisation d'un agent
Diagramme des cas d'utilisation de
l'administrateur :
L'administrateur est un héritier de l'agent
(Figure 2). Il peut gérer les agents comme il peut
faire les autres gestions.
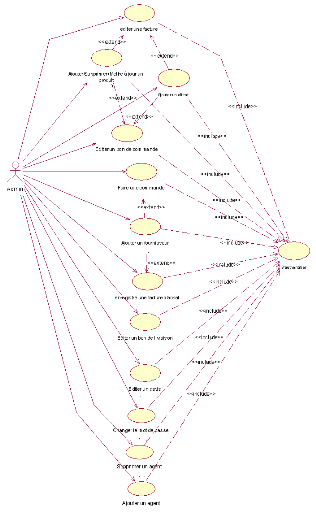
Figure 4.
Diagramme des cas d'utilisation pour administrateur
Les cas d'utilisations. Avec ses multiples relations
(extend, include, etc.), nous donne une vue presque
réelle de l'application. (Pour des informations complémentaires
voir Annexe 1).
Cette richesse nous montre une vue globale de l'application
mais pour voir réellement la succession des actions des acteurs il nous
faut un autre modèle (diagramme) qui nous détaille le
séquencement des opérations ce diagramme s'agit du diagramme des
séquences.
Ce dernier comme son nom l'indique il développe un cas
d'utilisation en montrant les différentes opérations permettant
de réaliser l'action du cas en question.
Vu le grand nombre de cas de notre application, en tenant
compte du nombre limite de pages imposées pour la rédaction de ce
présent mémoire, on a choisi quatre qu'on donnera leurs
diagrammes de séquences.
Ce choix n'est pas un fruit du hasard mais on a essayé
de regrouper les cas en différentes catégories qu'on a
classées selon l'importance et les ressemblances des cas et enfin
prendre dans chacune un pour illustrer.
Ces quatre catégories sont :
|
Catégorie
|
Cas choisi
|
|
Authentification
|
agent
|
|
Gérer les
fournisseurs/clients/produits
|
ajouter un produit
|
|
Gestion des ventes/achats
|
éditer une facture
|
|
Gérer les agents
|
ajouter un agent
|
Tableau 1.
Partage des cas d'utilisation en catégories
4.2.2 Diagramme de
séquence :
Il s'agit d'une explication détaillée d'un cas
d'utilisation. Les principales informations contenues dans un diagramme de
séquence sont les messages échangés entre les lignes de
vie, présentés dans un ordre chronologique.
Authentification :
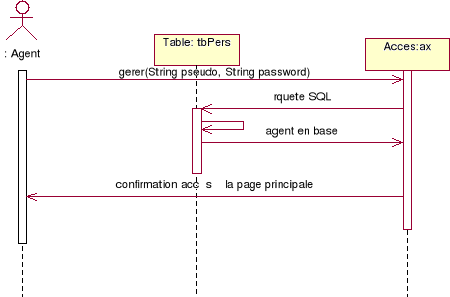
Figure 5.
Diagramme de séquence de
l'authentification
Ici on est entrain de décrire la manière de
s'authentifier. Elle est similaire pour l'agent que pour l'administrateur du
fait que ce denier hérite du premier.
Ajouter un produit :
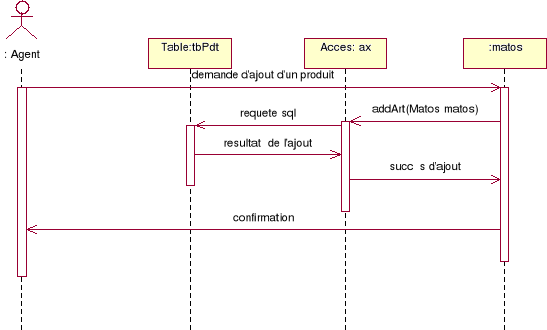
Figure 6.
Diagramme de séquence de l'ajout
d'un produit
Ci-dessus on a montré les différents processus
suivis pour ajouter un produit. Dans ce qui suit on va présenter les
étapes suivies pour éditer une facture.
Editer une facture :
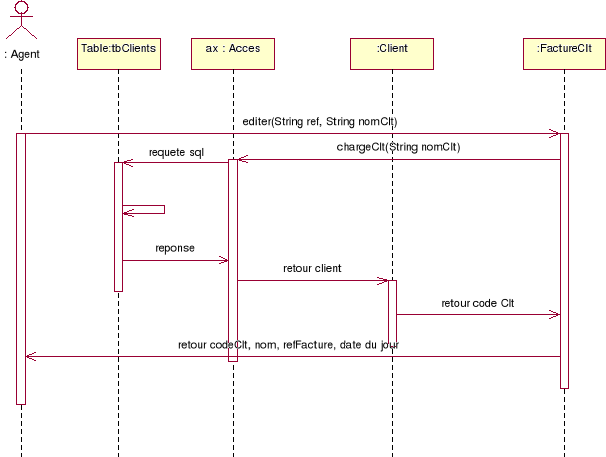
Figure 7.
Diagramme de séquence de l'édition d'une
facture
Diagramme pour l'ajout d'un agent :
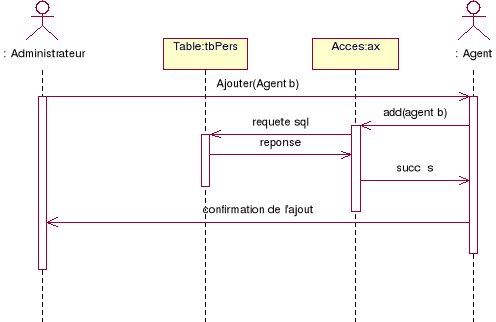
Figure 8.
Diagramme de séquence de l'ajout d'un agent
La figure 8 montre La différence d'accessibilité
aux services fournis par l'application.
Il est bien évident qu'un administrateur peut
gérer les agents alors que la réciproque est fausse.
4.3
Modélisation Statique :
Précédemment on a parlé des deux grandes
catégories de diagrammes UML (statique et dynamique) l'un des diagrammes
statiques nous intéresse beaucoup pour pouvoir implémenter le
code, il s'agit du diagramme de classes
4.3.1 Diagramme de classes :
Ce modèle nous permet d'avoir une vue statique de
l'application. Il nous montre les relations entre les différentes
entités (classes) composant notre application. Il nous mène vers
la solution finale. À partir de ce diagramme on retrouve les corps des
différentes classes de notre application. Mieux encore en utilisant la
technique de l'ingénierie (voir Annexe
3) on obtient une grande partie du code finale.
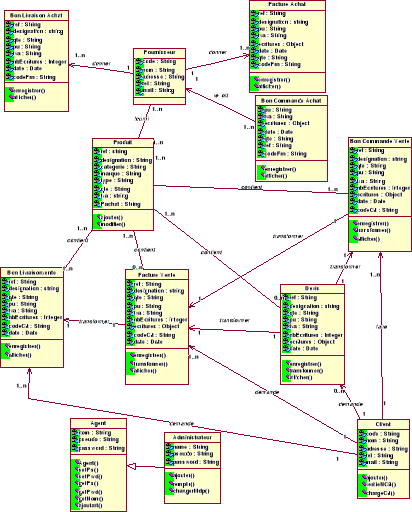
Figure 9.
Diagramme de classes
Le schéma ci-dessus nous donne une vue globale de
notre application. On a les classes principales qui vont nous servir à
réaliser l'application.
Pour avoir de plus amples informations sur l'autre partie de
notre application on peut penser à représenter le modèle
conceptuel de données (modèle physique) il s'agit de
représenter les données et les différentes relations entre
elles. Ce modèle nous a permis de construire notre base de
donnée, car chaque entité est associée à une table
dans la base de donnée.
Faisons un feed-back sur le diagramme des classes et
faisons quelques détails :
Ø Client :
Un client peut avoir plusieurs factures comme il peut avoir
plusieurs commandes et plusieurs devis, et quand il reçoit un produit il
doit avoir un bon de livraison.
Ø Fournisseur :
Il reçoit un ou plusieurs commandes de la
société, donc il va donner une facture et un bon de livraison au
moment de la livraison
Ø Facture, bon de commande, Devis, bon de
livraison:
Ici il s'agit du coté vente, donc ils doivent
posséder chacun une référence, un code client, une date et
un ou plusieurs produits.
On peut avoir des transformations comme l'indique la table
suivante :
|
Peut être transformé(e)
|
Facture
|
BL
|
BC
|
Devis
|
|
Facture
|
*******
|
Oui
|
Non
|
Non
|
|
BL
|
Non
|
*******
|
Non
|
Non
|
|
BC
|
Oui
|
Oui
|
*******
|
Non
|
|
Devis
|
Oui
|
Oui
|
Oui
|
*******
|
Tableau 2.
Tableau des transformations.
Peut être transformé(e)
A B
Ø Facture, bon de commande, bon de livraison:
Ici il s'agit du coté achat, donc ils doivent
posséder chacun une référence, un code fournisseur, une
date et un ou plusieurs produits. Ici on n'a pas besoin des
transformations.
Ø Produit :
Un produit est caractérisé par sa
référence, sa désignation, sa catégorie, son type,
la quantité, sa marque, tva et son prix d'achat.
Ø Administrateur/agent :
C'est seulement les deux personnes qui ont accès
physiquement à l'application. Ils gèrent les clients, les
fournisseurs, les factures, les commandes et les bons. Il est évident
que l'administrateur hérite de l'agent, car c'est lui seul qui peut
gérer les agents.
4.3.2 Modèle conceptuel des
données (modèle physique) :
On a utilisé MERISE pour pouvoir implémenter
notre base de données, ce modèle nous permet d'avoir une
idée sur les tableaux qui composent notre base. Evidemment il y'a des
règles qui permettent de passer d'un modèle à un autre.
(Pour plus d'informations voir Annexe 3).
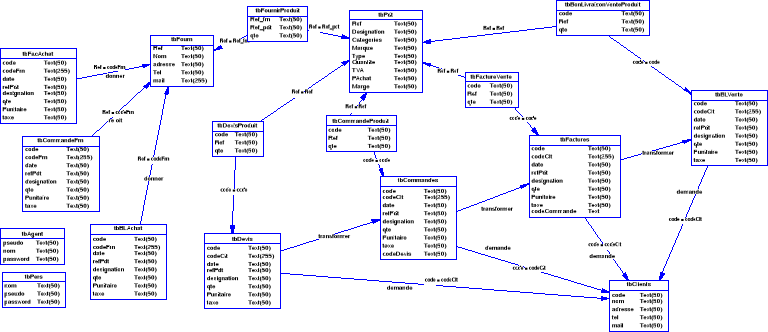
Figure 10.
Modèle physique des données
Chapitre IV
La
réalisation
5 La réalisation :
5.1
Introduction :
Arrivé à ce stade nous pouvons nous estimer
heureux, il ne reste qu'à commencer à écrire notre code en
se basant sur les résultats obtenus des chapitres
précédents. Mais cela se fait en suivant des critères. On
doit passer par plusieurs jalons pour avoir un produit de bonne
qualité.
Ces techniques qu'on les appelle modèles de cycles de
vie d'un logiciel sont bien expliquées par le génie logiciel. Ces
modèles nous ont accompagnés du début du projet
jusqu'à l'implémentation de celui-ci.
Ainsi dans ce chapitre on va essayer de donner un bref
aperçu sur quelques modèles et choisir le modèle à
adopter, présenter les résultats de notre travail et finir par
une petite conclusion.
5.2 Modèles
de cycles de vie d'un logiciel :
5.2.1 Modèle de cycle de vie en
cascade
Le modèle de cycle de vie en cascade a
été mis au point dès 1966, puis formalisé aux
alentours de 1970. Dans ce modèle le principe est très simple :
chaque phase se termine à une date précise par la production de
certains documents ou logiciels. Les résultats sont définis sur
la base des interactions entre étapes, ils sont soumis à une
revue approfondie et on ne passe à la phase suivante que s'ils sont
jugés satisfaisants. Le modèle original ne comportait pas de
possibilité de retour en arrière. Celle-ci a été
rajoutée ultérieurement sur la base qu'une étape ne remet
en cause que l'étape précédente, ce qui est dans la
pratique s'avère insuffisant. (Voir Figure 11)
5.2.2 Modèle de cycle de vie en
V
Le modèle en V demeure actuellement le cycle de vie le
plus connu et certainement le plus utilisé. Le principe de ce
modèle est qu'avec toute décomposition doit être
décrite la recomposition, et que toute description d'un composant doit
être accompagnée de tests qui permettront de s'assurer qu'il
correspond à sa description.
Ceci rend explicite la préparation des dernières
phases (validation-vérification) par les premières (construction
du logiciel), et permet ainsi d'éviter un écueil bien connu de la
spécification du logiciel : énoncer une propriété
qu'il est impossible de vérifier objectivement après la
réalisation. (Voir Figure 12).
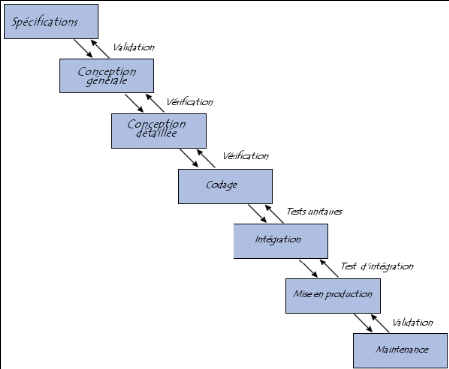
Figure 11.
Modèle du cycle de vie en cascade
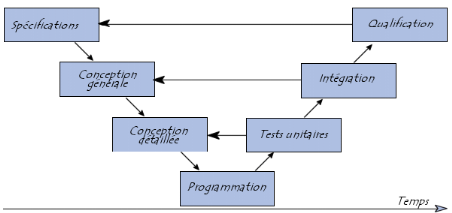
Figure 11. Modèle du cycle de vie
en V
Figure 12.
Modèle du cycle de vie en V
5.2.3 Modèle de cycle de vie en
spirale
Proposé par B. Boehm en 1988, ce modèle est
beaucoup plus général que le précédent. Il met
l'accent sur l'activité d'analyse des risques : chaque cycle de la
spirale se déroule en quatre phases :
· détermination, à partir des
résultats des cycles précédents, ou de l'analyse
préliminaire des besoins, des objectifs du cycle, des alternatives pour
les atteindre et des contraintes.
· Analyse des risques, évaluation des alternatives
et, éventuellement maquettage.
· Développement et vérification de la
solution retenue, un modèle « classique » (Cascade ou en V)
peut être utilisé ici ;
· Revue des résultats et vérification du
cycle suivant.
L'analyse préliminaire est affinée au cours des
premiers cycles. Le modèle utilise des maquettes exploratoires pour
guider la phase de conception du cycle suivant. Le dernier cycle se termine par
un processus de développement classique.
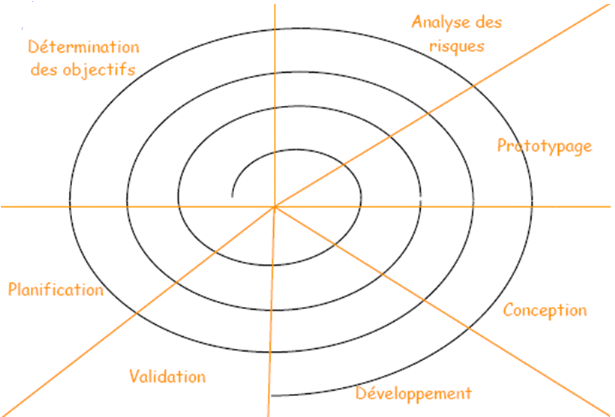
Figure 13.
Modèle de cycle de vie en spirale
5.2.4 Modèle par
incrément :
Dans les modèles précédents un logiciel
est décomposé en composants développés
séparément et intégrés à la fin du
processus.
Dans les modèles par incrément, un seul ensemble
de composants est développé à la fois : des
incréments viennent s'intégrer à un noyau de logiciel
développé au préalable. Chaque incrément est
développé selon l'un des modèles
précédents.
Les avantages de ce type de modèle sont les suivants
:
· chaque développement est moins complexe.
· les intégrations sont progressives.
· il est ainsi possible de livrer et de mettre en service
chaque incrément.
· il permet un meilleur lissage du temps et de l'effort
de développement grâce à la possibilité de
recouvrement (parallélisation) des différentes phases.
Les risques de ce type de modèle sont les suivants :
· Remettre en cause les incréments
précédents ou pire le noyau.
· Ne pas pouvoir intégrer de nouveaux
incréments.
Les noyaux, les incréments ainsi que leurs interactions
doivent donc être spécifiés globalement, au début du
projet. Les incréments doivent être aussi indépendants que
possibles, fonctionnellement mais aussi sur le plan du calendrier du
développement.
5.2.5 Modèle de
prototypage :
Un prototype : Un
modèle exécutable d'un système logiciel, qui souligne des
aspects spécifiques
· Caractéristiques :
Un degré élevé de participation du
client
Une représentation tangible des exigences du client
Très utile quand les exigences sont instables ou
incertaines
· Avantages: participation du
client :
Le client participe activement dans le développement
du produit
Le client reçoit des résultats tangibles
rapidement
Le produit résultant est plus facile à utiliser
et à apprendre
· Applicabilité :
Pour des systèmes interactifs de petite et moyenne
taille
Pour des parties de grands systèmes (par exemple
l'interface utilisateur)
Pour des systèmes avec une vie courte
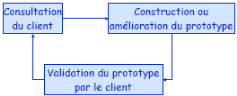
Figure 14.
Modèle de prototypage
Il existe pas mal de modèles, mais ici on a
essayé d'expliquer les plus connus et les plus utilisés
actuellement. Le choix du modèle est à prendre au sérieux
puisque il n'y a pas un modèle parfait et c'est difficile de se baser
sur un seul modèle, n'empêche d'avoir un modèle de
référence. Cependant, un ou plusieurs modèles peuvent bien
s'adapter à un cas donné par rapport à d'autres. En ce qui
concerne notre application, il s'agit d'un logiciel destiné à la
vente donc on doit être en relations étroites avec le client. Il
lui faut temps en temps des maquettes d'essai. Raison pour laquelle on a choisi
le modèle de prototypage qui nous permet de présenter au client
un prototype et l'améliorer jusqu'à avoir un produit fini
satisfaisant. On peut faire ici des feed-back.
5.3 Présentation de
l'application développée :
Notre application s'agit d'un logiciel commercial sur mesure
permettant de gérer les achats, les ventes, le stock et d'offrir
à l'utilisateur quelques accessoires à savoir un calendrier et
une aide sous fourme FAQ (Foire Aux Questions). La multitude des taches que
notre application est capable de faire engendre un grand nombre de
fenêtres. Pour des effets esthétiques on a essayé
d'utiliser deux types de container (JFrame et JDialog) selon les informations
à afficher. On va essayer de sélectionner quelques unes qui nous
paraissent important pour les intégrer dans ce présent
mémoire.
5.3.1 Fenêtre d'accueil :
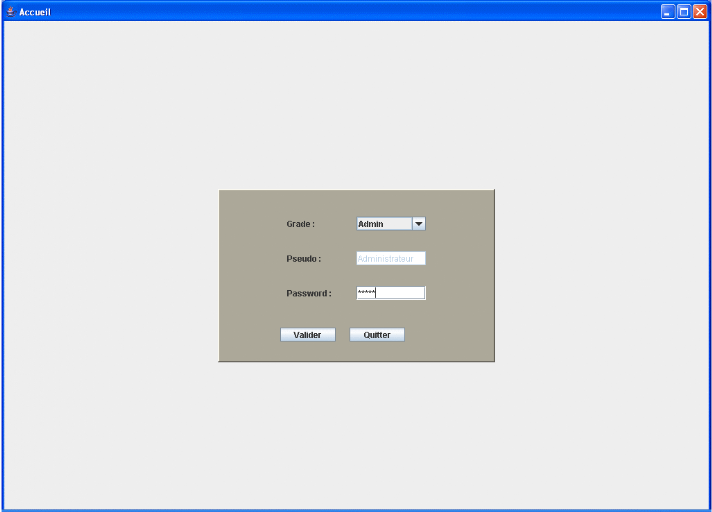
C'est la première fenêtre qui s'affiche si on
exécute l'application toute personne qui veut bénéficier
des services du logiciel doit s'authentifier (on rappelle que l'application est
livré avec un pseudo Administrateur et un mot de passe). Après
authentification une fenêtre principale s'affiche et les boutons sont
activés selon les droits d'accès de la personne
authentifiée.
On a le choix entre Admin et agent
Figure 15.
Fenêtre d'accueil (authentification)
5.3.2 Itinéraire suivi pour
l'édition d'une commande :
Cette fenêtre (Figure 16) gère
presque toute l'application la plupart des fenêtres qui vont s'ouvrir y
prennent source. La fenêtre est divisée en quatre grandes
parties :
La partie inferieure qui est composé par les taches de
gestion des ventes, des achats, du stock, et des utilitaires. En cliquant sur
une parmi ces taches, son icône est activé et un panel contenant
les boutons représentant les différentes sous taches s'ouvre
à droite. Au milieu on a deux boutons qui gèrent respectivement
les fournisseurs et les clients. Quant à gauche, on a la gestion du
personnel (ajout agent) et ce bouton n'est activé que si
l'administrateur s'est authentifié. Pour être objectif, traitons
le cas d'enregistrement d'une commande d'un client :
Après authentification de l'administrateur on a
l'interface suivante :

Gestion des Achats
Gestion des produits
Figure 16.
Fenêtre principale
Maintenant en cliquant sur le bouton vente on obtient
:

(1) Click sur le bouton vente
(2) Les sous taches de vente
Figure 17.
Fenêtre principale : click sur ventes
Maintenant on peut cliquer sur le bouton commande à
droite (premier bouton).
Après click on obtient le bon de commande vide
suivant:
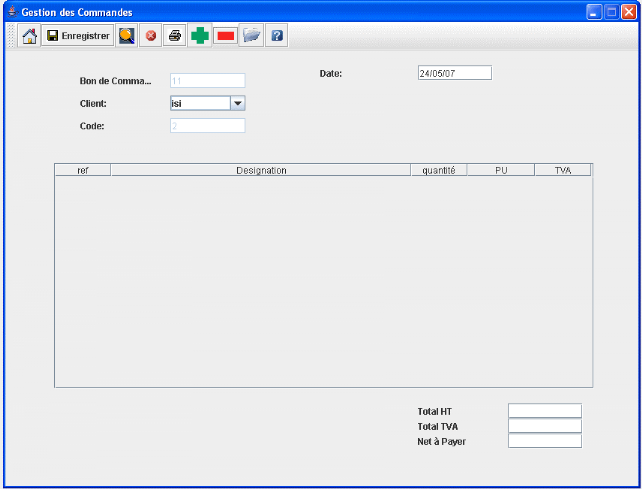
Ajouter une ligne dans le BC
Supprimer une ligne du BC
Les clients en base et on peut y ajouter d'autres
Figure 18. Bon
de commande
Cette fenêtre possède une barre d'outils dont ses
icones sont reconnaissables à part les symboles  et et  signifient respectivement, ajouter une ligne de commande et supprimer
une ligne sélectionnée de la commande. Tous les clients sont dans
le Combobox si on veut ajouter un nouveau client, il suffit de le saisir dans
le combo et appuyer Entrée. signifient respectivement, ajouter une ligne de commande et supprimer
une ligne sélectionnée de la commande. Tous les clients sont dans
le Combobox si on veut ajouter un nouveau client, il suffit de le saisir dans
le combo et appuyer Entrée.
On suppose qu'on veut ajouter une ligne de facture en
cliquent sur  on obtient : on obtient :
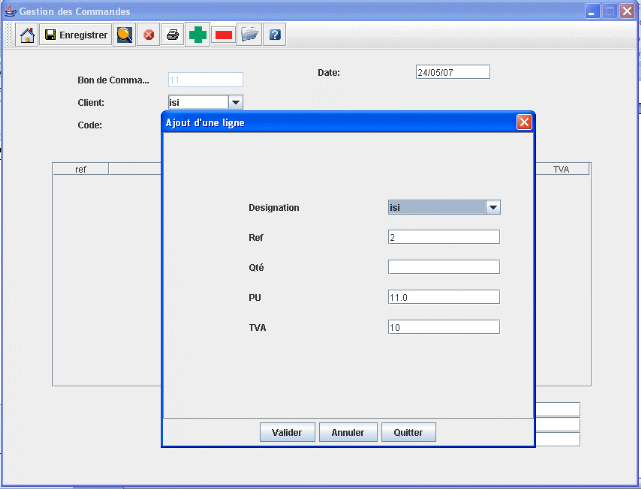
(1) Click
(2) fenêtre de saisie d'une ligne
(3) Remplir les champs
Figure 19.
Ajout ligne de commande
Ici on choisi la quantité et le produit, si la
différence entre la quantité restante et celle demandée
est inferieure à1 (qtéRestante - qtéDemandée <=
1). Un message nous indique une insuffisance de stock.
Sinon après avoir validé la ligne est
ajouté comme suit :
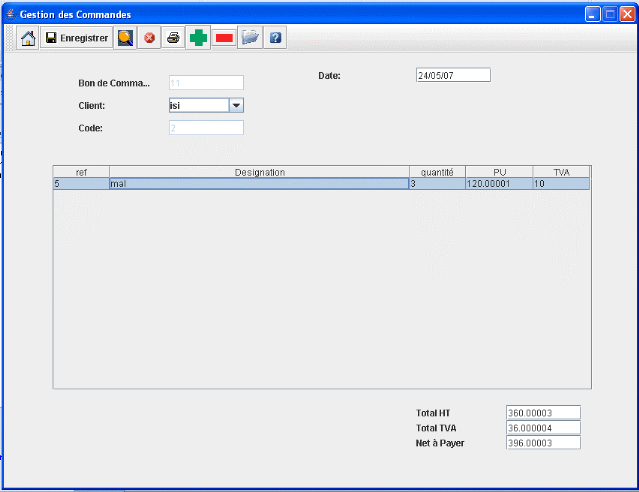
(1) ligne ajoutée
(2) Le calcul se fait automatiquement
Figure 20.
Ajout d'une ligne et calcul automatique du prix.
Et le processus continue comme ça. Pareil pour les
factures et devis.
De la même chose du coté achat.
Maintenant si on s'intéresse plutôt aux
matériels, dans la page principale on click sur matériel.
5.3.3 Quelques interfaces.
Dans cette interface on va voir toutes les
possibilités associées à nos produits. On peut ajouter un
nouveau matériel (sa référence est
générée automatiquement), mettre à jour un
matériel existant, consulter le stock, voir le catalogue de produits
existants dans l'entreprise, etc.
Ci-dessous l'interface d'ajout/de mise à jour d'un
produit dans la base. En donnant la marge, ici le prix de vente (HT) sera
calculé automatiquement et ajouté dans la table produit
(PvHT=Pachat*(1+marge)). Lors de l'édition d'une facture par exemple,
c'est le prix de vente hors taxe qui sera chargé dans la colonne prix
unitaire (PU)
Ajouter ou mettre à jour un produit
Saisir les champs
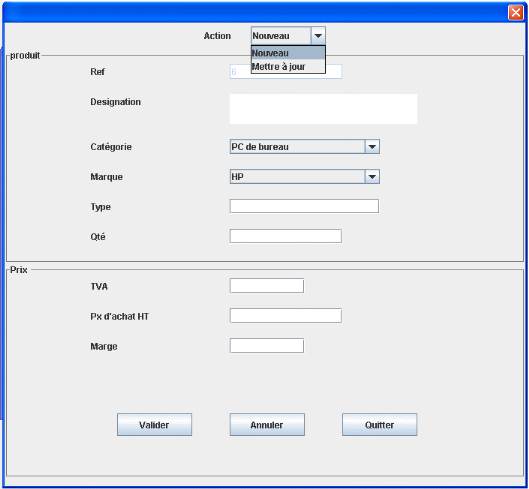
Figure 21.
Ajout/mettre à jour un produit.
En cliquant sur le bouton liste des articles, on a les
différentes informations des articles existants dans la base, il s'agit
en fait d'un catalogue des produits. Ci-dessous on a une maquette.
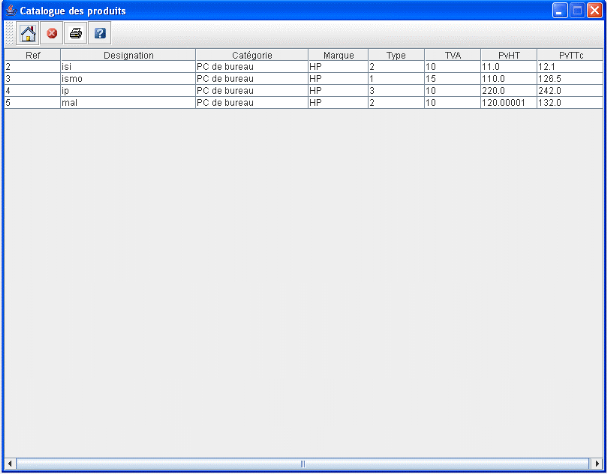
Liste
des articles existant dans la base
Figure 22.
Liste des articles
Liste des clients
(2) Actualiser pour que le client
ajouté soit dans la liste
(1) Permet d'ajouter un client
En cliquant sur le bouton client l'interface suivante
contenant la liste des clients s'affiche et on peut ajouter un client, imprimer
la liste, etc.
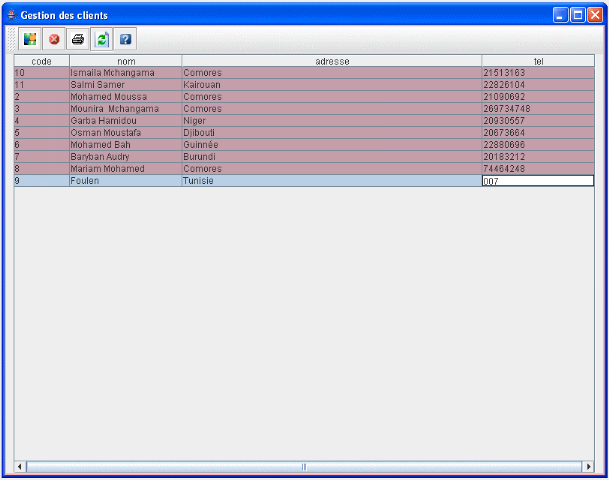
![]()
Figure 23.
Liste des clients
On a presque les mêmes interfaces pour les clients que
pour les fournisseurs. Pour un gain d'espace on omet de présenter les
interfaces fournisseurs. De même pour l'achat et la vente.
Supposons si on clique sur nouveau client : l'interface
de la Figure 24 s'affiche. On rempli les champs et puis on
valide.
Si on revient dans la fenêtre principale (Figure
16) et on clique sur gérer les agents la Figure 16
s'affiche et on peut soit supprimer, soit ajouter ou chercher un
agent.
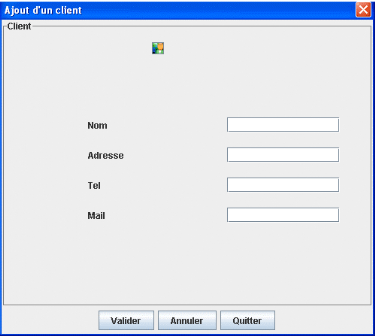
Figure 24.
Ajout d'un Client
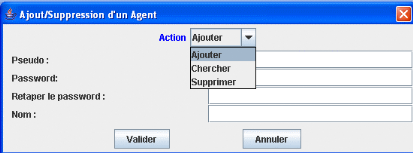
Choix de l'action
Figure 25.
Ajouter/supprimer/chercher un agent
Pour finir avec les interfaces on va revenir à la
fenêtre principale (Figure 16) et on clique sur le
bouton utilitaire comme suit :

(1) Click
(2) cliquer pour avoir
(3)
Figure 26.
Clique sur le bouton utilitaire
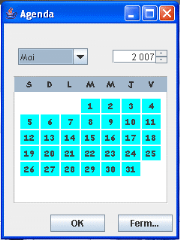
Calendrier
Figure 27.
Calendrier
Remarque :
Dans la plupart des interfaces il y'a un message
d'information qui nous indique le résultat de l'exécution de
l'action demandée par l'utilisateur.
5.4
Déroulement du projet :
|
Tache
|
Durée
|
Pourcentage
|
|
Etude préalable
|
5 jours
|
10%
|
|
Conception
|
15 jours
|
30%
|
|
Développement
|
20 jours
|
40%
|
|
Rédaction du rapport
|
10 jours
|
20%
|
Tableau 3.
Tableau du déroulement
5.5
Conclusion :
Dans ce chapitre on a présenté en premier lieu
quelques modèles du cycle de vie d'un logiciel. On a justifié
notre choix sur le modèle de référence qu'on a choisi
(prototypage).
Vu le grand nombre des interfaces composant notre application,
en second lieu on s'est contenté de donner quelques unes qui nous
paraissent plus importantes. On a essayé au maximum possible
présenter une seule interface s'il y' a plusieurs ayant des
similarités. Et à la fin, on a donné un tableau
résumant le déroulement du projet.
Conclusion et perspectives
Ce projet était bénéfique pour nous dans
plusieurs sens. Il nous a permis :
o de nous perfectionner en améliorant nos connaissances
en programmation et en conception.
o De bien comprendre et mettre en oeuvre le déroulement
d'un cycle de vie d'un logiciel.
o De découvrir le monde de l'entreprise
(fonctionnement).
Nous avons essayé de réaliser ce projet pour le
but de faciliter l'entreprise en question, d'améliorer la gestion et le
suivi de ses clients, de ses fournisseurs et de son stock.
On a appliqué au maximum possible les règles de
bases permettant d'avoir une application performante. Nous avons
appliqué UML pour concevoir une grande partie de notre travail. Nous
avons utilisé aussi Java et Access pour implémenter notre
application.
Grâce aux architectures que nous avons utilisé
(MVC et client/serveur) et du fait que Java est un langage adaptable dans
plusieurs domaines, notre application peut avoir des extensions ou des
modifications dans le futur. Citons quelques unes :
o On peut lier cette application à un site web
dynamique qui nous permettra le suivi des clients et des fournisseurs en
ligne.
o On peut changer le SGBD au cas où l'entreprise aura
des données volumineuses à stocker.
o Dans l'avenir quand l'entreprise aura besoin de plusieurs
agents travaillant en même temps en réseau, on peut utiliser le
concept Remote Method Invocation (RMI) : appels des méthodes
à distant
Bibliographie
Ouvrages
électroniques
KELLER, Nicolas ROUQUET, Maxime. -
KellerRouquet [ FORMTEXT en ligne ],
03/03/2006.
AUDIBERT, Laurent - Cours-UML.[en ligne]
GOLLOT, Eric - les cas utilisation.
DI SCALA, Robert - Initiation à la programmation.
http://www.developpez.com
Wikipédia :
http://fr.wikipedia.org
LATIRI Chiraz.-Cours Génie
logiciel.
M.DIMASSI Jamil.- Méthodologie de conception
UML.
Travaux universitaires
GHARSALLI Alia et BEN AMMAR Amel.
- Conception et développement d'une application de gestion de
société de services. - Projet de fin d'études, ISIMM.
Annexes
Annexe 1 cas
d'utilisation
Le diagramme des cas d'utilisation qui fait partie des
modèles dynamique d'UML2 sert entre- autre un moyen de communication
entre les spécialistes et le client, et d'un outil nous permettant
d'avoir une idée sur les principales interfaces de l'application.
Utilisateurs - Acteurs
UML n'emploi pas le terme d'Utilisateur mais d'acteur. Les
acteurs d'un système sont les entités externes à ce
système qui interagissent avec lui. Quand on dit « qui
interagissent », on veut dire qui envoient des
évènements comme, cliquer sur un bouton OK ou encore
envoyer un fichier de données ou une trame XML. On veut aussi dire qui
reçoivent des informations de la part du système
comme, recevoir une facture, mettre à jour un référentiel
de données ou encore mettre à jour une application back-office.
Les acteurs sont donc à l'extérieur
du système et dialoguent avec lui. Ces acteurs permettent de
cerner l'interface que le système va devoir offrir à son
environnement. Oublier des acteurs ou en identifier de faux conduit donc
nécessairement à se tromper sur l'interface et donc la
définition du système à produire. On fera attention
à ne pas confondre acteurs et utilisateurs d'un système. Non pas
que cela soit faux car tout dépend du sens donné au mot
utilisateur mais trop souvent, le mot utilisateur est vu comme un raccourci
pour désigner ceux qui vont cliquer dans les fenêtres de
l'application. Les acteurs sont plus que les « simples » utilisateurs
humains d'un système. D'une part parce que les acteurs inclus les
utilisateurs humains mais aussi les autres systèmes informatiques ou
hardware qui vont communiquer avec le système.
Pour trouver les acteurs d'un système, on va identifier
quels sont les différents rôles que vont devoir jouer ses
utilisateurs. Car les acteurs sont en fait les rôles joués par ces
différents Utilisateurs (ex : Responsable clientèle, Responsable
d'agence, Administrateur, Approbateur,...). On regardera ensuite quels sont les
autres systèmes avec lesquels le système va devoir communiquer
soit en mode réception soit en mode émission
d'évènements (ex : Hardware d'un distributeur de billet,
Système d'information partenaire, ERP,...).
Un biais classique dans l'identification des acteurs est
dû au fait que les acteurs peuvent aussi être d'autres
systèmes. Aussi, il est fréquent de vouloir identifier comme
acteur les référentiels de données existant dans le
système d'information. Effectivement, le
Système à produire aura sûrement à
récupérer ou à mettre à jour des données
issues de ces référentiels, mais le risque d'identifier ces
systèmes comme acteur est qu'ensuite, lors de la rédaction des
cas d'utilisation, on risque de rentrer trop tôt dans la solution et
oublier l'expression première du besoin. Je ne dis pas qu'identifier ce
type d'acteur est une erreur fondamentale mais l'expérience montre que
l'intérêt est minime et que les biais induits sont néfastes
: une description des cas d'utilisation plus proche de la solution que du
besoin.
Les cas d'utilisation
Les cas d'utilisation vont ici nous aider à
décrire ces attendus. On entend souvent que les cas d'utilisation
permettent de décrire les fonctionnalités attendues du
système de point de vue des acteurs. Ce n'est pas faux mais attention
car «fonctionnalités» se transforme souvent en «
fonctions ». On en arrive donc à utiliser les cas d'utilisation
pour faire un découpage fonctionnel au sens procédures des
langages procéduraux. Et là, on se trompe complètement
d'objectif.
Ces fonctionnalités que l'on documente avec les cas
d'utilisation doivent avoir un sens pour le métier des acteurs. Pour
identifier les cas d'utilisation, il faut donc se poser les questions :
?? « Mais que va faire cet acteur avec le système
en arrivant le matin au boulot ? »
?? « Pourquoi démarre t-il le système,
avec quel objectif métier ? »
En se posant ce type de question, on verra que
généralement des cas d'utilisation comme «Rechercher client
» ou « Imprimer facture » ne sont pas des cas d'utilisation mais
plutôt des fonctions du système. L'important avec les cas
d'utilisation est de bien décrire ce que l'on pourrait désigner
savamment par « unité d'intention complète
». C'est-à-dire une série d'envois
d'évènements de la part de l'acteur au système et de
réponses du système pour atteindre un objectif
métier précis. Et non les différentes fonctions
du système qui seront en fait déduites des différents cas
d'utilisation.
Un cas d'utilisation est donc composé des
éléments suivants :
· Un nom : Utiliser un verbe à
l'infinitif (Ex : Réceptionner un colis)
· Une description résumée
permettant de comprendre l'intention principale du cas d'utilisation. Cette
partie est souvent renseignée au début du projet dans la phase de
découverte des cas d'utilisation.
· Des acteurs déclencheurs : ceux
qui vont réaliser le cas d'utilisation (la relation avec le cas
d'utilisation est illustrée par le trait liant le cas d'utilisation et
l'acteur dans un diagramme de cas d'utilisation)
· Des acteurs secondaires : ceux qui ne
font que recevoir des informations à l'issue de la réalisation du
cas d'utilisation (Ex : client ou autre système informatique. La
relation avec le cas d'utilisation est illustrée par le trait liant le
cas d'utilisation et l'acteur dans un diagramme de cas d'utilisation)
· Des pré-conditions qui
décrivent dans quel état doit être le système
(l'application) avant que ce cas d'utilisation puisse être
déclenché (Ex : un contrat existe avec le client).
· Des scénarii. Ces
scénarii sont décrits sous la forme d'échanges
d'évènements entre l'acteur et le système. On classe les
scénarii en : Un scénario nominal (celui qui est
déroulé quand il n'y a pas d'erreur, celui qui est principalement
réalisé dans 90% des cas), des scénarii alternatifs qui
sont les variantes du scénario nominal et enfin les scénarii
d'exception qui décrivent les cas d'erreurs.
· Des post-conditions qui
décrivent l'état du système à l'issue des
différents scénarii (Ex : un contrat est créé et le
système back-office est mis à jour avec le nouveau contrat
créé)
· Des informations sur l'utilisation du
cas d'utilisation comme : le nombre de personnes exécutant ce cas
d'utilisation dans une journée type, le nombre d'objets
(métiers !) traités par le cas
d'utilisation dans une journée type (Ex : 120 contrats
créés
entre septembre et novembre, 2000 consultations des
contrats par jour).
Eventuellement une description des besoins en termes
d'interface graphique. Ce chapitre étant réservé
à des cas simples car généralement traité en dehors
de la description même du cas d'utilisation. Dans ce cas une
cohérence doit d'ailleurs être assurée entre l'IHM et la
description du cas d'utilisation.
Les relations entre cas d'utilisation
UML définit 3 grands types de relations entre cas
d'utilisation : généralisation/spécialisation, include,
extends.
Il est important de noter que l'utilisation de ces relations
n'est pas primordiale dans la rédaction des cas d'utilisation et donc
dans l'expression du besoin. Ces relations peuvent être utiles dans
certains cas mais une trop forte focalisation sur leur usage conduit souvent
à une perte de temps ou à un usage faussé, pour une valeur
ajoutée, au final, relativement faible.
Extends :
La relation « d'extend » est probablement la plus
utile car elle a une sémantique qui a un sens du point de vue
métier au contraire des 2 autres qui sont plus des artifices
d'informaticiens.
On dit qu'un cas d'utilisation X étend un cas
d'utilisation Y lorsque le cas d'utilisation X peut être appelé au
cours de l'exécution du cas d'utilisation Y comme :
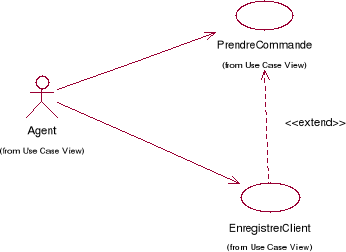
Figure 28.
Relation extend
Ce type de relation est primordial pour l'écriture de
l'application. Imaginer dans le cas précédent que l'on n'ait pas
mis la relation « extends ». Cela signifierait que lors de la prise
de commande pour un nouveau client, le processus de prise de commande devrait
être annulé au moment de la saisie des informations client, pour
d'abord exécuter « Enregistrer client » afin que le client
soit connu puis ensuite, reprendre le processus de prise de commande depuis le
début ; pas cool pour notre responsable clientèle et bonjour
l'image commerciale donnée au client !
Include :
La relation d'include n'a pour seul objectif
que de factoriser une partie de la description d'un cas
d'utilisation qui serait commune à d'autres cas
d'utilisation. Le cas d'utilisation inclus dans les autres cas
d'utilisation n'est pas à proprement parlé un vrai cas
d'utilisation car il n'a pas d'acteur déclencheur ou receveur
d'évènement2. Il est juste un artifice pour faire de la
réutilisation d'une portion de texte.
Une erreur classique est d'utiliser la relation «
d'include » pour faire du découpage fonctionnel d'un cas
d'utilisation en plusieurs « sous cas d'utilisation » qui
s'enchaînent en fonction de certains critères. On en arrive alors
à se demander : Comment documenter l'enchaînement des sous cas
d'utilisation avec UML ? Mais cette question n'a en fait pas lieu d'être,
tout simplement.
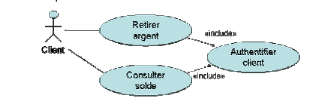
Figure 29.
Relation include
Généralisation / spécialisation
Cette relation est de mon point de vue la relation la plus
discutable du point de vue de son utilité pratique. Elle consiste
à dire que l'on a un cas d'utilisation dit « de base »,
générique, qui décrit des séquences
d'évènements et d'autres cas d'utilisation qui héritent de
ce comportement de base et le spécialise suivant différents
critères (le comment de la chose reste nébuleux). On pourra par
exemple avoir une situation comme
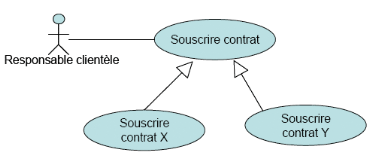
Figure 30.
Relation généralisation/spécification
Conclusion
On espère vous avoir un peu éclairé sur
cette espèce que sont les cas d'utilisation et surtout sur leur bon
usage. On espère aussi que vous aurez compris qu'il est inutile de
compliquer leur utilisation en introduisant la notion de relation et que les
cas d'utilisation deviennent « simples » si on s'en tient à
répondre à la question : Mais est ce que ce cas d'utilisation
à un sens du point de vue métier pour l'acteur, n'est ce pas une
vision informaticienne de son besoin ? Les détails d'informaticiens
seront abordés lors des activités d'analyse et de conception.
Ne soyons pas pressé et exprimons d'abord le besoin et
ensuite la solution.
Annexe 2 Règles de
passage du modèle conceptuel au modèle physique (MCD
MLD)
Table et clé
primaire :
Toute classe ou entité (=objet de gestion) est
transformée en table. Les attributs de l'entité deviennent les
attributs de la table. L'identifiant de la classe/entité devient la
clé primaire de la table.
Figure 31.
Table et clé primaire.
Relation binaire (...,*) -
(...,1) :
La clé primaire de l'entité reliée par
(..., 1) devient clé étrangère de
l'entité reliée par (...,*).
Figure 32.
Relation binaire (...,*) - (...,1).
Relation binaire (0.1) -
(1.1) :
La clé primaire de l'entité reliée par
(0, 1) devient clé étrangère de
l'entité reliée par (1, 1).
Figure 33.
Relation binaire (0.1) - (1.1).
Relation binaire et
ternaire (...,*) - (...,*) :
On crée une table supplémentaire ayant comme
clé primaire une clé composée des clés primaires
des deux entités. Lorsque la relation contient elle-même des
propriétés, celles-ci deviennent attributs de la table
supplémentaire.
Figure 34.
Relation binaire et ternaire (...,*) - (...,*).
Annexe 3 Ingénierie et
retro-ingénierie
Aujourd'hui les concepts ingénierie et
rétro-ingénierie, jouent un rôle important en informatique
plus particulièrement dans le domaine de génie logiciel. Les
développeurs de logiciels ne peuvent pas s'empêcher de profiter
d'un tel marché. Les logiciels répondants à ces deux
concepts commencent à inonder le marché. Le principe de base est
simple : en ayant une conception on peut retrouver le corps du programme
à développer (ingénierie), et inversement on peut trouver
la conception (retro-ingénierie). En voici ce qu'on peut lire dans
Wikipédia :
La rétro-ingénierie (traduction littérale
de l'anglais Reverse engineering), également appelée
rétro-conception, est l'activité qui consiste à
étudier un objet pour en déterminer le fonctionnement. L'objectif
peut être par exemple de créer un objet différent avec des
fonctionnalités identiques à l'objet de départ sans
contrefaire de brevet. Ou encore de modifier le comportement d'un objet dont on
ne connaît pas explicitement le fonctionnement.
La démarche utilisée peut être celle de
l'étude d'une
boîte
noire : on isole l'objet à étudier, on détermine
les entrées et les sorties actives. On essaie ensuite de
déterminer la réponse du système en fonction du signal
d'entrée. Mais il est également possible de démonter le
système jusqu'à un certain point pour en analyser les
constituants.
| 

