III.9 Les principaux algorithmes 43
III.9.2 Les K plus proches voisins
L'algorithme des K plus proche voisins (KNN pour K Nearest
Neighbors) est un algorithme de classification supervisé et non
paramétrique.
On suppose qu'une observation est similaire a celle de ses
voisins,de par les distance qui les sépare.on cherche par ailleurs les K
points les plus proches de celui que l'on souhaite classer la classe ce la
variable cible est alors la majorité parmi les classes des k plus
proches.(S. MADEH PIRYONESI , 2009)
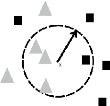
FIG. 15 : KNN
· Avantages : Simple à interpréter
· Inconvénients :Sensible au bruit
III.9.3 Les arbres de décision
Les arbres de décision sont des modèles de ML
supervisés et non paramétriques connu pour leurs
flexibilité.
Ils sont utilisables aussi bien pour la classification que
pour la régression.
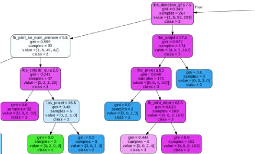
L'idée consiste a classer (ou attribuer une valeur
dans le cas de la régression) à une observation a l'aide d'une
succession de questions,ou chaque question est représentée par un
noeud et chaque réponse correspond à une branche de l'arbre,la
classe (ou valeur)de la variable cible est alors déterminer par le noeud
terminal dans lequel parvient l'observation a l'issue des
questions.(B.JAKuBczYK , 2017) pour la phase d'apprentissage,elle consiste a
trouver les bonnes questions et de bien les ranger.
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
44 CHAPITRE III. TRAITEMENT
Amassin NACERDDINE Université Paris 8 Vincennes
FIG. 16 : Arbres de décision
· Avantages: Phase de préparation de données
simple
· Inconvénients : Risque de sur-apprentissage
dans le cas d'un mauvais élagage
III.9.4 Les forêts aléatoire
C'est un algorithme de classification et de régression
supervisé et non paramétrique.
Le but de l'algorithme des forêts aléatoires est
de tirer partie des avantages des arbres de décision tout en
éliminant leurs inconvénients a savoir la
vulnérabilité au sur-apprentissage.
· Avantages: En plus de regrouper tout les avantages des
arbres cité précédemment ces dernier ne souffrent pas du
problème du sur-apprentissage.
· Inconvénients: La complexité de
ce type d'algorithme rend leur implémentation délicate.
III.9.5 Les machines à vecteurs de support
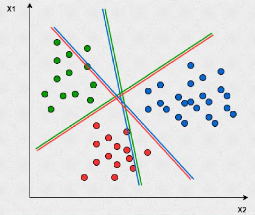
Les SVM sont des algorithmes de classification binaire non
supervisé et non li-néaire(mais qui peuvent s'adapter au
multi-classe).Leurs principe est simple il consiste à construire une
séparation non linéaire entre les groupes d'observations,et
utiliser cette séparation comme repaire pour faire la
prédiction.
· Avantages : Traite des problèmes avec un grand
nombre de dimensions.
· Inconvénients: Le choix de la fonction
noyau k est délicate.
III.9 Les principaux algorithmes 45
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 17 : SVM
| 

